A hash table is a fixed-sized data structure in which the size is defined at the start. This chapter explains how hash tables work by focusing on hashing, the method of generating a unique key. By the end of this chapter, you will understand various hashing techniques and know how to implement a hash table from scratch.
Introducing Hash Tables
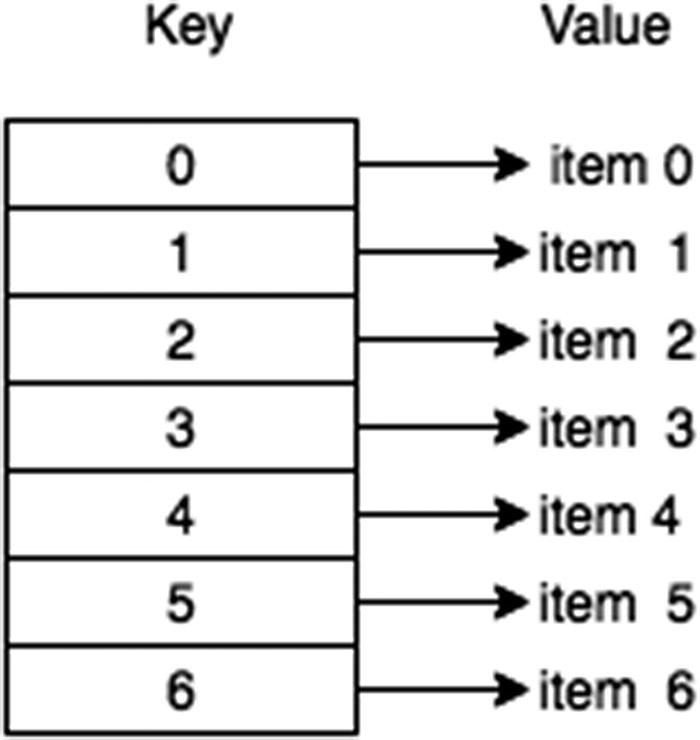
Simple hash table overview
A hash table contains two main functions: put() and get() . put() is used for storing data into the hash table, while get() is used for retrieving data from the hash table. Both of these functions have a time complexity of O(1).
In a nutshell, a hash table is analogous to an array whose index is calculated with a hashing function to identify a space in memory uniquely.
Hashing Techniques
Deterministic: Equal keys produce equal hash values.
Efficiency: It should be O(1) in time.
Uniform distribution: It makes the most use of the array.
The first technique for hashing is to use prime numbers. By using the modulus operator with prime numbers, a uniform distribution of the index can be guaranteed.
Prime Number Hashing
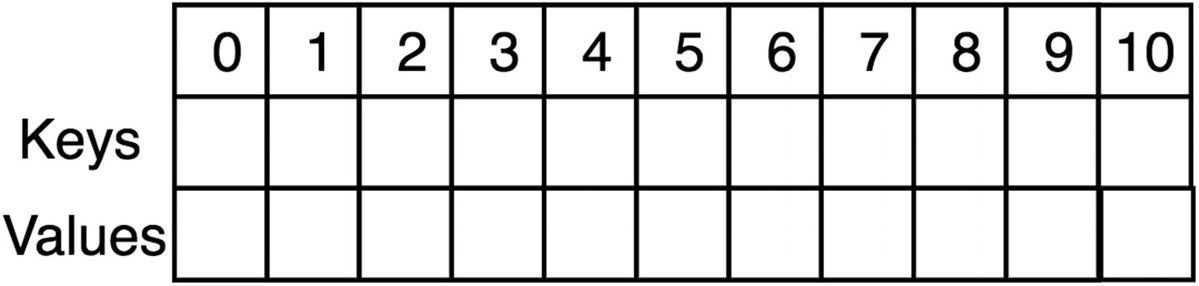
Hash table of size 11, with all empty elements
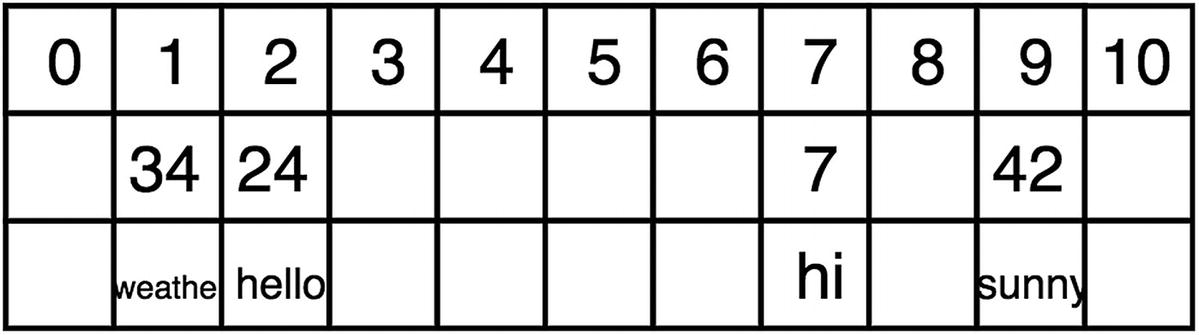
Hash table after inserting the value pairs
This is a problem because 7 already exists in the index of 7 and causes an index collision. With a perfect hashing function, there are no collisions. However, collision-free hashing is almost impossible in most cases. Therefore, strategies for handling collisions are needed for hash tables.
Probing
To work around occurring collisions, the probing hashing technique finds the next available index in the array. The linear probing technique resolves conflicts by finding the next available index via incremental trials, while quadratic probing uses quadratic functions to generate incremental trials.
Linear Probing

Hash table 1 after using linear probing
However, now when the get(key) function is used, it has to start at the original hash result (7) and then iterate until 18 is found.
The main disadvantage of linear probing is it easily creates clusters, which are bad because they create more data to iterate through.
Quadratic Probing
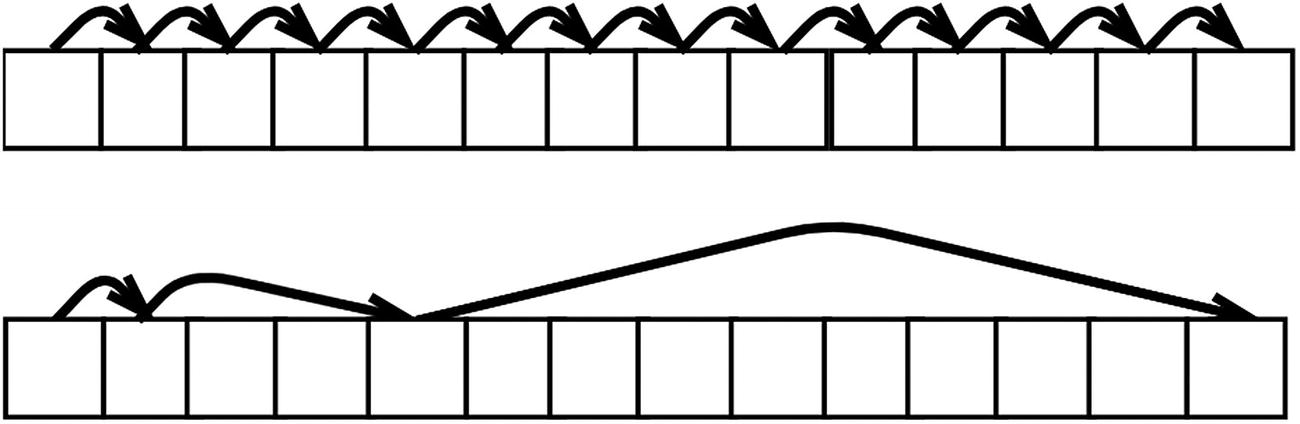
Linear probing (on top) and quadratic probing (on bottom)
Rehashing/Double-Hashing
Different: It needs to be different to distribute it better.
Efficiency: It should still be O(1) in time.
Nonzero: It should never evaluate to zero. Zero gives the initial hash value.
hash2(x) = R − (x % R)
i * hash2(x)
Hash Table Implementation
7, “hi”
20, “hello”
33, “sunny”
46, “weather”
59, “wow”
72, “forty”
85, “happy”
98, “sad”
Using Linear Probing
Using Quadratic Probing
This result is more uniformly distributed than the result from linear probing. It would be easier to see with a bigger array size and more elements.
Using Double-Hashing with Linear Probing
Again, double-hashing results in a more uniformly distributed array than the result from linear probing. Both quadratic probing and double-hashing are great techniques to reduce the number of collisions in a hash table. There are collision resolution algorithms far more advanced than these techniques, but they are beyond the scope of this book.
Summary
A hash table is a fixed-sized data structure in which the size is defined at the start. Hash tables are implemented using a hash function to generate an index for the array. A good hash function is deterministic, efficient, and uniformly distributive. Hash collisions should be minimized with a good uniformly distributive hash function, but having some collisions is unavoidable. Hash collision-handling techniques include but are not limited to linear probing (incrementing the index by 1), quadratic probing (using a quadratic function to increment the index), and double-hashing (using multiple hash functions).
The next chapter explores stacks and queues, which are dynamically sized data structures.