| CHAPTER |
|
| 31 |
Security Operations Management |
| |
|
This chapter is about the ongoing, day-to-day management of security functions—the processes and procedures that need to be put in place to provide a smooth-running, efficient, and effective operation. Security operations management is the on-the-ground process by which security incidents are managed, security controls are implemented and maintained, and people with a higher level of access to systems and data are subject to oversight.
Communication and Reporting
One of the most important responsibilities of security operations is that of providing management with measurements of success through metrics and key performance indicators (KPIs). Metrics are numbers that represent either the compliance of security controls with a preferred goal (for example, the number of antivirus installations that are complete and up to date) or the effectiveness of those controls (for example, the number of attacks blocked by a firewall). Metrics usually take the form of numbers, counts, and sums. Metrics tend to include an enormous amount of data that can be useful to the people on the security team, but can’t easily be understood by executives. Therefore, metrics are mostly used internally to tune performance and root out problems.
Figure 31-1 shows some example security metrics that might be used in a typical organization to manage security vulnerabilities, incidents, and operations. Notice that these are raw numbers, which are not necessarily meaningful by themselves except to experienced system administrators or managers responsible for activities. You wouldn’t want to show these to executive management, because you’d spend a lot of time explaining what the numbers mean and whether they are good, bad, or normal—and ultimately, you’d leave the executives confused and unenlightened. But, in the hands of experienced people who have a built-in context for understanding and translating them already, these numbers can be extremely useful for managing a security team’s resources and priorities.

Figure 31-1 Example security metrics that could be used for security management
Key performance indicators, or KPIs, are based on metrics, but they are much simpler. They represent the meaning of the data. KPIs usually take the form of a percentage or a simple dashboard-style red-yellow-green score such as a pass-fail statistic. For example, the percentage of antivirus installations that are operational, responsive, and up to date might be 75 percent, compared to a desired baseline of 95 percent, resulting in a red status. KPIs tend to focus on highlighting things that are out of compliance and need attention, so they often result in a remediation plan.
Figure 31-2 shows some example KPIs. Consider how these are different from the metrics shown in
Figure 31-1. Instead of just raw numbers, this representation shows more context through the use of percentages, targets, and green/yellow/red status. It does include raw numbers as well, because those help depict the intensity or severity of the percentages. This chart is immediately informative to anybody who looks at it, regardless of their background. The eye is drawn naturally to the red items in the Percent column, which highlight the areas needing the most attention. Green items are under control, and the amounts indicate how much effort is required to keep them that way. Items in yellow are in jeopardy and either on the rise because they are being improved or on the decline because they are falling out of compliance.

Figure 31-2 Key performance indicators highlight issues at a glance
Another type of report that gives executives useful information is a
heat map. In this kind of diagram, green, yellow, and red are used to indicate areas that are under control and those that need attention. More information is embedded in a heat map than in a simple chart or table of numbers, but it is also a lot easier to understand at a glance. Consider the heat map shown in
Figure 31-3.

Figure 31-3 Heat map chart showing maturity levels based on the CMM model
The heat map chart depicted in
Figure 31-3 shows maturity levels based on the Capability Maturity Model (CMM), in which a value of 1 indicates a process that is completely unmanaged and ad hoc, 2 means documented and repeatable, 3 means well defined and standardized but managed qualitatively, 4 means managed quantitatively with the use of metrics and KPIs like those shown in
Figure 31-2, and
5 means completely mature with formal optimization and improvement processes built in.
The heat map is particularly useful in pinpointing exactly where the problems are. Unlike a simple score for an entire process area, which may indicate a problem without showing how to fix it, the heat map helps an executive zero in on what aspect of the process needs attention. Consider the example of “Identity & Access Management” in
Figure 31-3. That process is quantitatively managed, with a well-defined strategy and consistent delivery. But it is lacking standardized metrics. Evidently, in this situation, reporting is an issue. Another example is “Security Awareness & Education”—the management and strategy of this process is defined, but it’s not yet ready to deliver and measure. All of this information is present in the chart in a clear, understandable format that even somebody completely unfamiliar with the methodologies can interpret.
Change Management
Change management processes are meant to manage risks associated with planned changes by carefully considering and minimizing the impact of each change. A subset of information security, change management is concerned with protecting the availability of services as well as the integrity of data. When changes such as updates, patches, new releases, and reconfigurations are made to software and systems, these changes can cause unexpected and unintended consequences. A change management process not only reduces these consequences, but also ensures that the right people are informed and ready to take action when things don’t go as expected.
NOTE Change Management = Risk Management
ITIL, a service-oriented framework for information technology service delivery, provides a set of best practices for change management that are highly formalized and rigorous. When you evaluate change management processes in deciding how to implement change management in your organization, you want to take into account the complexity and resource availability of your environment and determine how much process is really required in your situation. ITIL (version 3) provides a very complete reference model for change management with plenty of best practices to choose from.
In the ITIL framework, change management is a complementary process to
service management (the process by which IT services are delivered and charged to the end users) and
incident management (the process of handling errors and outages).
Figure 31-4 depicts this relationship.
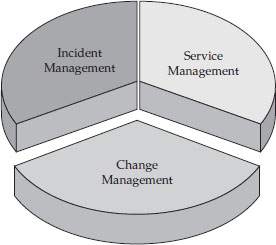
Figure 31-4 ITIL processes for information technology
ITIL change management components include
• Change Not just a modification, but also the addition or removal of a component of an IT service that might carry a risk of unexpected consequences.
• Change advisory board (CAB) A group of people who review and approve changes, composed of stakeholders from IT and business groups. The CAB may also have responsibility for prioritizing and/or scheduling changes (in more dynamic environments with a high level of change activity).
• Change request (CR) or request for change (RFC) A detailed description of a proposed change, with a business case, analysis of risk, and remediation plan for unexpected results. ITIL version 3 prefers the term RFC, but the term CR is also prevalent.
• Change model A repeatable process for implementing a known change that has been successfully done in the past, often preapproved for simple changes that carry no risk.
• Change management system A database (or knowledgebase) of all changes that have been requested and/or performed over the history of the process.
• Change schedule or forward schedule of changes (FSC) The list of upcoming changes that have been approved and scheduled for implementation.
Figure 31-5 shows the steps in the ITIL change management process. The complete nine-step process at the top is for mature IT organizations in large, mature environments. A condensed version, shown at the bottom, combines some of the steps to streamline the process.

Figure 31-5 ITIL change management process steps
The first step is to record the change request (RFC). In this step, the request is added to the system of record so it can be tracked and evaluated. In a full ITIL implementation, this change request should originate from an incident or service request tracked elsewhere in the system. In other words, change requests do not come up on their own; they are always driven by a problem or a need for enhancement.
Next, a change manager performs a cursory evaluation of the change request to make sure it is appropriately documented and classified. This is just a brief check to ensure all required fields are filled out and that this really is a request for change, not a miscategorized item of information.
The request is then classified based on the information provided, such as impact, severity, complexity, need for downtime, and other factors that determine how much review and approval is needed. At this stage, the request can be prioritized in comparison to other change requests already in the system.
Planning the change follows, based on the change calendar and the urgency of the business need that’s driving the request for change.
Based on all the information provided so far, the CAB evaluates the change and determines whether it is approved or denied. In a full implementation of an ITIL-based change management process, this evaluation and approval is done in a meeting with all stakeholders present, after presentation by the change requestor and discussion with the CAB. Smaller environments may simplify this process using e-mail to substitute for the in-person meeting.
The build, test, and implement steps are performed after approval is granted. These stages represent a standard IT approach to putting a change through testing and deployment in development, staging, and testing environments, followed by full deployment into the production environment. Not all organizations have the luxury of multiple environments that are identical to production environments, so smaller environments may need to condense these steps. In cases where testing opportunities are limited, a change can be deployed to a limited group first; however, a solid backout plan, representing the steps required to undo the change, must be in place.
The final step in the process is evaluation—which can be done in front of the CAB during a meeting or described separately in e-mail or in the change management system in smaller environments or for low-impact changes.
See the ITIL specification, which can be found at the web site listed in the “References” section of this chapter, for more details on change management practices and principles. You can also refer to the books listed in the “References” section for additional information.
Acceptable Use Enforcement
As part of an overall security policy program, every organization should have an acceptable use policy (AUP) that dictates what employees can do with the computers they use and the networks and data they have access to. The job of enforcing this policy is usually shared between the security operations department and HR. Security operations is responsible for detecting and reporting violations and subsequent investigations, and HR is responsible for taking action against the violators. This separation of duties is important and similar to law enforcement, where police collect evidence (and, in some cases, put a stop to a violation in progress), but penalties are decided by a judge.
Examples of Acceptable Use Enforcement
The following examples of AUP enforcement statements are provided to demonstrate the enforcement statements that go into AUPs, and what kinds of things a security operations team is likely to enforce.
Access to the organization’s services may be terminated or suspended without notice if, in its discretion, the organization determines that a violation of the policy has occurred.
In this simply worded example, which might be found at an Internet service provider (ISP), a security operations team would monitor the terms of the policy and cut off connections when they find violations.
Violations of the Acceptable Use Policy that are not promptly remedied by the customer may result in action including the termination of service or the forfeiture of membership.
In this case, the security operations team would monitor the activities specified in the AUP and either disconnect service or escalate concerns to the appropriate department.
The following list includes some policies that might be found in an AUP pertaining to a company’s employees.
• Do not forward, provide access to, store, distribute, and/or process confidential information to unauthorized people or places, or post confidential information on Internet bulletin boards, chat rooms, or other electronic forums.
• Do not access information resources, company records, files, information, or any other data when there is no proper, authorized, job-related need for such information.
• Do not view offensive web sites, send or forward offensive e-mail.
• Do not connect any personally owned equipment to the company’s network.
• Do not install personally owned software or nonlicensed software on company computers.
In this example, the security operations team might be expected to monitor employee e-mail, external web sites for company confidential information and access to information resources, web site categories, network connections, and software installations. In these cases, the team would use security tools that produced reports and alerts that the security operations staff would then review and escalate as part of their defined processes.
Proactive Enforcement
AUP enforcement is not just a matter of taking administrative action against people who violate the terms of a policy. Enforcement also means detecting abuses and proactively stopping infractions from occurring. Technologies such as URL blocking, web content filtering, e-mail filtering, and application control use filtering technologies to block access to sites or even to block keywords that an organization has deemed unacceptable. Filtering products may also automatically scan e-mail for regulated topics. Other products may take a more passive approach, such as simply recording every page visited and allowing reports to track user activity on the Internet.
Web content filtering applications make it possible, for example, to block access to gambling, file-sharing, political, shopping, and adult content sites, using a database of URLs organized into these categories. Application control products can manage employee use of media-rich network protocols, instant messaging, streaming media, and so forth, allowing access when bandwidth permits and blocking access when the organization needs that capability for business-related activity.
Administrative Security
When considering controls that determine the availability and integrity of computing systems, data, and networks, consider the potential opportunities an authorized administrator has compared to a less privileged ordinary user. Systems administrators, operators who perform backups, database administrators, maintenance technicians, and even help desk support personnel, all have elevated privileges within your network. To ensure the security of your systems, you must also consider the controls that can prevent administrator abuse of privilege. The automated controls that manage access of day-to-day transactions and data within your organization cannot ensure integrity and availability on their own, without control over administration tasks. If the controls governing the use of administrative authority are not strong as well, any other controls are weakened.
Preventing Administrative Abuse of Power
Two security principles of security will help you avoid abuse of power: limiting authority and separation of duties. You can limit authority by assigning each IT employee only the authority needed to do his or her job. Within your IT infrastructure, you have various systems, and each can be naturally segmented into different authority categories. Examples of such segmentation are network infrastructure, storage, servers, desktops, and laptops.
Another way to distribute authority is between service administration and data administration. Service administration is that which controls the logical infrastructure of the network, such as domain controllers and other central administration servers. These administrators manage the specialized servers on which these controls run, segment users into groups, assign privileges, and so on. Data administration, on the other hand, is about managing file, database, web content, and other servers. Even within these structures, authority can be further broken down—that is, roles can be devised and privileges limited. File server backup operators should not be the same individuals that have privileges to back up the database server. Database administrators may be restricted to certain servers, as may file and print server administrators.
In large organizations, these roles can be subdivided ad infinitum—some help desk operators may have the authority to reset accounts and passwords, whereas others are restricted to helping run applications. The goal is to recognize that all administrators with elevated privileges must be trusted, but some should be trusted more than others. The fewer the number of individuals who have all-inclusive or wide-ranging privileges, the fewer who can abuse those privileges.
Management Practices
The following management practices can contribute to administrative security:
• Place controls on remote access and access to consoles and administrative ports.
• Implement controls on out-of-band access to devices, such as serial ports and modems, and physical controls on access to sensitive devices and servers.
• Limit which administrators can physically access these systems, or who can log on at the console. Just because an employee has administrative status, that doesn’t mean his or her authority can’t be limited.
• Vet administrators. IT administrators have enormous power over an organization’s assets. Every IT employee with these privileges should be thoroughly checked out before employment, including reference checks and background checks.
• Use automated software distribution methods. Using automated OS and software installation methods not only ensures standard setup and security configuration, thus preventing accidental compromise but also is a good practice for inhibiting the abuse of power. When systems are automatically installed and configured, there are fewer opportunities for the installation of back door programs and other malicious code or configuration to occur.
• Use standard administrative procedures and scripts. The use of scripts can mean efficiency, but the use of a rogue script can mean damage to systems. By standardizing scripts, there is less chance of abuse. Scripts can also be digitally signed, which can ensure that only authorized scripts are run.
Accountability Controls
Accountability controls are those that ensure activity on the network and on systems can be attributed to an actual individual. These controls include
• Authentication controls Passwords, accounts, biometrics, smart cards, and other such devices and algorithms that sufficiently guard the authentication practice
• Authorization controls Settings and devices that restrict access to specific users and groups
When used properly, accounts, passwords, and authorization controls can hold people accountable for their actions on your network. Proper use means the assignment of at least one account for each employee authorized to use systems. If two or more people share an account, how can you know which one was responsible for stealing company secrets? A strong password policy and employee education also help enforce this rule. When passwords are difficult to guess and employees understand they should not be shared, proper accountability is more likely.
Authorization controls ensure that access to resources and privileges is restricted to the proper person. For example, if only members of the Schema Admins group can modify the Active Directory Schema in a Windows 2000 domain, and the Schema is modified, then either a member of that group did so or somebody else has accessed that person’s account.
Chapter 7 explains more about authentication and authorization practices and algorithms.
In some limited situations, a system is set up for a single, read-only activity that many employees need to access. Rather than provide every one of these individuals with an account and password, a single account is used and restricted to this access. This type of system might be a warehouse location kiosk, a visitor information kiosk, or the like. But, in general, every account on a system should be assigned only to a single individual.
All administrative employees should have at least two accounts: a “normal” account with regular privileges, used when they access their e-mail, look up information on the Internet, and do other mundane things; and a different account that they can use to fulfill their administrative duties.
For some highly privileged activities, a single account might be assigned the privilege, while two trusted employees each create half of the password. Neither can thus perform the activity on their own; it requires both of them to do so. In addition, since both may be held accountable, each will watch the other perform the duty. This technique is often used to protect the original Administrator account on a Windows server. This account can also be assigned a long and complex password and then not be used unless necessary to recover a server where the administrative account’s passwords are forgotten or lost, when key administrators leave the company, or some other emergency occurs. Other administrative accounts are then created and used for normal administration. Another special account might be an administrative account on the root certification authority. When it is necessary to use this account, for instance to renew this server’s certificate, two IT employees must be present to log on, lessening the chance that the keys will be compromised.
Security Monitoring and Auditing
Monitoring and auditing activity on systems is important for two reasons. First, monitoring activity tells the systems administrator which systems are operating the way they should, where systems are failing, where performance is an issue, and what type of load the system is carrying at any given time. These details allow proper maintenance and discovery of performance bottlenecks, and they point to areas where further investigation is necessary. The wise administrator uses every possible tool to determine general network and system health and then acts accordingly. Second, and of interest to security, is the exposure of suspicious activity, audit trails of normal and abnormal use, and forensic evidence that is useful in diagnosing attacks or misuse, and potentially catching and prosecuting attackers. Suspicious activity may consist of obvious symptoms such as known attack codes or signatures, or may be patterns that, to the experienced, mean possible attempts or successful intrusions.
To benefit from the information available in logs and from other monitoring techniques, you must understand the type of information available and how to obtain it. You must also know what to do with it. Three types of information are useful:
• Activity logs
• System and network monitoring
• Vulnerability analysis
We will consider some examples of each of these three types of information in the following sections.
Activity Logs
Each operating system, device, and application may provide extensive logging activity. Administrators do, however, have to make decisions about how much activity to record. The range of information that is logged by default varies, as does what is available to log, and there is no clear-cut answer on what should be logged. The answer depends on the activity and the reason for logging.
NOTE When examining log files, understanding what gets logged and what does not is important. The information contained in a log varies by the type of log, the type of event, the operating system and product, whether there are additional things you can select, and the type of data. In addition, if you are looking for “who” participated in the event or “what” machine they were using, this information may or may not be a part of the log. Windows event logs prior to Windows Server 2003, for example, did not include the IP address of the computer, just the hostname. And web server logs do not include exact information no matter what brand they are. Much web activity goes through a proxy server, so you may find that you know the network source but not the exact system it came from.
Determining What to Log In general, you must answer the following questions:
• What is logged by default? This includes not just the typical security information, such as successful and unsuccessful logons or access to files, but also the actions of services and applications that run on the system.
• Where is the information logged? It may be logged to several locations.
• Do logs grow indefinitely with the information added, or is log file size set? If the latter, what happens when the log file is full?
• What types of additional information can be logged? How do you turn these options on?
• When is specific logging activity desired? Are there specific items that are appropriate to log for some environments but not for others? For some servers but not others? For servers but not desktop systems?
• Which logs should be archived and how long should archives be kept?
• How are logs protected from accidental or malicious change or tampering?
A System and Device Log File Example Not every operating system or application logs the same types of information. Knowing what to configure, where to find the logs, and what information within the logs is useful requires understanding the specific system. Looking at an example log on one system is useful, however, because it gives meaning to the types of questions that you need to ask and answer. Windows and Unix logs are different, but for both, you might want to be able to identify who, what, when, where, and why things happened. The following example discusses Windows logs.
Windows audit logging is turned off, by default, in Windows NT, XP, Windows 2000, Vista, and Windows 7. Windows Server 2003 and later versions have some audit logging turned on by default, and the kinds of things that can be logged are shown in
Figure 31-6. An administrator can turn on security logging for all or some of the available categories and can set additional security logging by directly specifying object access in the registry, a directory, and the file system. It’s even possible to set auditing requirements for all servers and desktops in a Windows 2000 or Windows Server 2003 domain using Group Policy (a native configuration, security, application installation, and script repository utility).
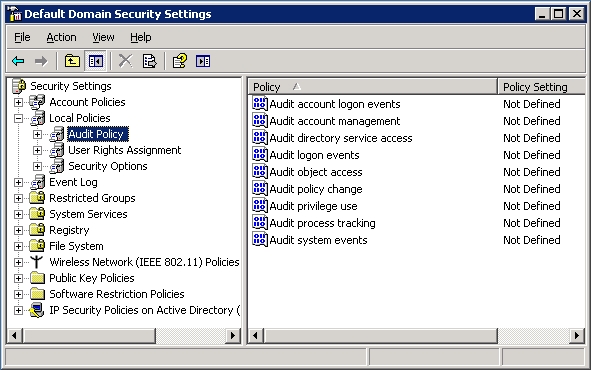
Figure 31-6 Windows audit log options
Even when using Windows Server 2003, understanding what to log is important because the Windows Server 2003 default policy logs only a minimum amount of activity. Needless to say, turning on all logging categories is not appropriate either. For example, in Windows security auditing, the category Audit Process Tracking would be inappropriate for most production systems because it records every bit of activity for every process—way too much information for normal drive configurations and audit log review. In a development environment, however, or when vetting custom software to determine that it only does what it says it does, turning on Audit Process Tracking may provide just the amount of information necessary for developers troubleshooting code or analysts inspecting it.
Audit events are logged to a special local security event log on every Windows NT (and later) computer that is configured to audit security events. Event logs are located in the %windir%\system32\config folder. In addition to security events, many other events that may provide security or activity tracking information are logged to the application log, the system log—or, on a Windows 2000 and later domain controller—the DNS Server log, Directory Service log, or File Replication Service log.
In addition, many processes offer additional logging capabilities. For example, if the DHCP service is installed, it, too, can be configured to log additional information such as when it leases an address, whether it is authorized in the domain, and whether another DHCP server is found on the network. These events are not logged in the security event log; instead, DHCP events are logged to %windir%\system32\dhcp.
Typically, you can turn on additional logging for many services and applications, and that activity is logged either to the Windows event logs, to system or application logs, or to special logs that the service or application creates. Microsoft’s IIS follows this pattern, as do Microsoft server applications such as Exchange, SQL Server, and ISA Server. The wise systems administrator, and auditor, will determine what is running on systems in the Windows network and what logging capabilities are available for each service or application. Although most log information relates only to system or application operation, it may become part of a forensics investigation if it is necessary or warranted to reconstruct activity. Keep a journal that includes what information is being logged on each system and where it is recorded.
Many of the special application logs are basic text files, but the special “event logs” are not. These files have their own format and you can manage access to them. Although any application can be programmed to record events to these log files, events cannot be modified or deleted within the logs.
Event logs do not automatically archive themselves; they must be given a size; and they may be configured to overwrite old events, halt logging until manually cleared, or in Security Options, stop the system when the log file is full. Best practices advise creating a large log file and allowing events to be overwritten, but monitoring the fullness of files and archiving frequently so no records are lost.
Auditable events produce one or more records in the security log. Each record includes event-dependent information. While all events include an event ID, a brief description of the event and the event date, time, source, category, user, type, and computer, and other information are dependent on the event type.
Log File Summarization and Reporting Early security and systems administrator advice emphasizes that logs must be reviewed on a daily basis and assumes that there is time to do so. We now know that except in unusual circumstances that does not happen. Today’s best practice advises that the following actions be taken:
• Post log data to external server.
• Consolidate logs to a central source.
• Apply filters or queries to produce meaningful results.
Posting log data to an external server helps to protect the log data. If a server is compromised, attackers cannot modify the local logs and cover their tracks. Consolidating logs to a central source makes the data easier to manage because queries only need to be run on one batch of data. The Unix utility syslog, when utilized, lets you post and consolidate log data to a central syslog server. A version of syslog is also available for Windows.
Examples of other techniques for log consolidation include
• Collecting copies of security event logs on a regular basis and archiving them in a database, and then developing SQL queries to make reports or using an off-the-shelf product to query this database directly for specific log types.
• Investing in a third-party security management tool that collects and analyzes specific types of log data.
• Implementing a Security Information and Event Management (SIEM) system that collects log data and alerts from many sources—security logs, web server logs, IDS logs, and so forth.
Chapter 18 covers SIEM in more detail.
• Using the log management capabilities of systems management tools or service management platforms or services.
System and Network Activity Monitoring
In addition to log data, system and network activity can alert the knowledgeable administrator to potential problems. Systems and networks should be monitored not only so that repairs to critical systems can be made and bottlenecks in performance investigated and resolved, but also so you know that all is well or that an attack is underway. Is that system unreachable due to a hard disk crash? Or the result of a denial of service attack? Why today is there a sudden surge in packets from a network that is too busy?
Some SIEM tools seek also to provide a picture of network activity, and many management tools report on system activity. In addition, IDS systems, as described in
Chapter 18, and protocol analyzers can provide access to the contents of traffic on the network.
Continuous monitoring is perhaps the best defense for security operations. Security operations must be able to produce, collect, and query log files such as host logs and proxy, authentication, and attribution logs. Security operations must have the skill set to perform deep packet inspection that covers all the critical “choke points” (ingress and egress) of the network. Many commercial monitoring packages are available, as well as event correlation engines. Open source alternatives are available as well, but do not come with professional support teams that are often needed during a security incident in progress or during a post mortem. Deciding what to monitor and how to monitor it is a major endeavor.
Security professionals will do well to reference the National Institute of Standards and Technology (NIST) Special Publication 800-37, “Guide for Applying the Risk Management Framework to Federal Information Systems: A Security Life Cycle Approach.” This document provides guidance on continuous monitoring strategies. High-value targets (assets) require monitoring priority. Security operations, armed with current and relevant threat intelligence, combined with broad and targeted monitoring strategies and techniques, may catch the cyber-criminal in the act of committing an APT attack.
Vulnerability Analysis
No security toolkit is complete without its contingent of vulnerability scanners. These tools provide an audit of currently available systems against well-known configuration weaknesses, system vulnerabilities, and patch levels. They can be comprehensive, capable of scanning many different platforms; they can be operating system–specific; or they can be uniquely fixed on a single vulnerability or service such as a malware detection tool. They may be incredibly automated, requiring a simple start command, or they may require sophisticated knowledge or the completion of a long list of activities.
Before using a vulnerability scanner, or commissioning such a scan, take time to understand what the potential results will show. Even simple, single-vulnerability scanners may stop short of identifying vulnerabilities. They may, instead, simply indicate that the specific vulnerable service is running on a machine. More complex scans can produce reports that are hundreds of pages long. What do all the entries mean? Some of them may be false positives; some may require advanced technical knowledge to understand or mitigate; and still others may be vulnerabilities that you can do nothing about. For example, running a web server does make you more vulnerable to attack than if you don’t run one, but if the web server is critical to the functioning of your organization, then it’s a risk you agree to take.
Although vulnerability scanning products vary, it’s important to note that a basic vulnerability assessment and mitigation does not require fancy tools or expensive consultants. Free and low-cost tools are available, and many free sources of vulnerability lists exist. Operating system–specific lists are available on the Internet from operating system vendors.
The National Institute of Standards and Technology has published a freely downloadable “Self-Assessment Guide for Information Technology Systems.” Although some of the specifics of this guide may only be applicable to government offices, much of the advice is useful for any organization; and the document provides a questionnaire format that, like an auditor’s worksheets, may assist even the information security neophyte in performing an assessment. Items in the questionnaire cover such issues as risk management, security controls, IT lifecycle, system security plans, personnel security, physical and environmental protection, input and output controls, contingency planning, hardware and software maintenance, data integrity, documentation, security awareness training, incident response capability, identification and authentication, logical access controls, and audit trails.
Keeping Up with Current Events
Security professionals face the daunting task of keeping up with the current security landscape. You should keep abreast of current threats and corresponding protective measures applicable to your organization’s core business processes and high-value targets.
You can draw from numerous resources to learn more about the current threat landscape. Leading security vendors—including Symantec, which publishes an annual Internet Security Threat Report; McAfee Labs, which delivers a quarterly threat report; IBM X-Force, which produces threat and trend risk reports; and Cisco, which publishes security threat whitepapers—are all valid resources for keeping up to date on the threat landscape. Additionally, there are various organizations that provide threat intelligence, including Carnegie Mellon Software Engineering Institute (CERT), which studies Internet security vulnerabilities and conducts long-term security studies; United States government emergency readiness team (US-CERT), which provides technical security alerts and bulletins; the SANS Institute, which publishes the top cyber security risks list; and the Computer Security Institute (CSI), which publishes an annual Computer Crime and Security Survey. In addition to these resources, professional associations such as the International Information Systems Security Certification Consortium, Inc. (ISC2) provide vendor-neutral training, education, and certifications, including the CISSP, for the security professional. The Information Systems Audit and Control Association (ISACA) engages in the development, adoption, and use of globally accepted, industry-leading knowledge and practices for information systems such as COBIT standards and CISA certification.
For each asset identified, you are responsible for implementing the recommended protection measures. The problem that security professionals encounter is how to know when a system or application needs a patch or fix applied. Most vendors provide a mailing list for security updates and provide security alerts and information when a maintenance subscription is purchased. There are numerous security mailing lists, but the most popular in recent years is the Bugtraq and Full Disclosure lists provided by
Insecure.org. Remember that the latest exploits and hacks are not published on any web site, nor are vendors aware of “zero-day exploits” until the exploit occurs. Subscribing to these mailing lists, however, will keep you informed—as informed as anyone can ever be.
Incident Response
An organization’s ability to detect and respond to a sophisticated attack is dependent on the effectiveness and capabilities of an incident response team. This team consists of more than one person—because the response to an incident will be performed by a variety of roles ranging from managers to employees and internal to external professionals, such as IT staff, business partners, security operations, human resources, legal, finance, audit, public relations, and law enforcement. A Computer Security Incident Response Team (CSIRT) is an important component of any security operations function.
Carnegie Mellon’s CERT program offers an excellent model and useful materials for incident response. CERT was formed in 1988, funded by the U.S. Department of Defense DARPA agency, to deal with the outbreak of the first self-propagating Internet malware known as the Morris Worm. Released onto the early Internet by Cornell graduate student Robert Morris, the Morris Worm reproduced and spread itself onto computers, causing denial of service by overloading the victim computers with endless tasks.
CERT offers a Handbook for Computer Security Incident Response Teams (CSIRT). The guide covers everything from a proposed framework to basic issues encountered by response teams.
Figure 31-7 shows the increasing trend in computer security incidents over the years that CERT tracked these statistics. The increase in incidents may be related to the increased adoption of Internet usage, and it may also be related to the increase in known vulnerabilities. In any case, we can see a strong upward trend indicating that security incidents are on the rise, and they need to be dealt with.
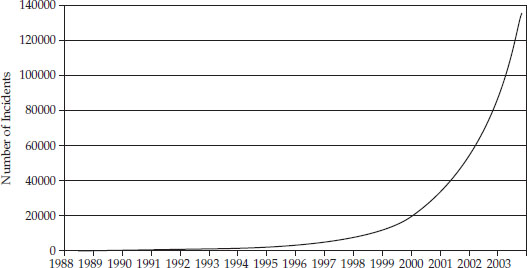
Figure 31-7 Computer security incidents reported to CERT
CERT’s process for establishing your own incident response team is available to the public and can be found at
www.cert.org—it includes the following steps.
The first step, as in most security endeavors, is to get sponsorship from your organization’s senior management. Funding and resources are dependent on this support, and so is the authority of the team to borrow staff from various departments within the organization. Ultimately, the success of the team is correlated with the support of top management.
The next step is to define the high-level strategic plan for the incident response team. Planning the goals, timeframes, and membership in consideration of the dependencies and constraints the team faces provides a roadmap and project plan for implementing the CSIRT.
Collecting information from the organization is the important next step in determining the role of the CSIRT and the resources it will need. In this step, you find out what other organizations have resources that you need and how you can use them. For example, HR, Legal, Audit, and Communications (and maybe Marketing) representatives and, of course, IT—all of these folks, and probably more, have roles to play, and they will each have their own goals and priorities they want to see represented on the team. In the information gathering phase, you will also determine what outside resources need to be involved, such as law enforcement and public CSIRT organizations.
Creating and communicating a vision, mission, charter, and plan for the team are next, and these steps provide a focus that helps the team members understand what is required of them and how the organization interacts with the CSIRT. CERT includes budgeting in this step as well.
The next step, after all the planning is completed, is to create the team. In this step, staff is brought together and trained, and equipment is procured to support the functions defined in the team’s charter. Once the team is up and running, announcements are sent to the entire organization and a communication program is put into effect. In the spirit of a plan-do-check-act cycle, the final step is to evaluate the team’s effectiveness to gain insight into improvements that can be made.
The Forum of Incident Response and Security Teams (FIRST) is another CSIRT organization, similar to CERT. They are self-described as “an international confederation of trusted computer incident response teams who cooperatively handle computer security incidents and promote incident prevention programs.” According to their mission statement, the members of the FIRST organization develop and share technical information, tools, methodologies, processes, and best practices; encourage and promote the development of quality security products, policies, and services; develop and promulgate best computer security practices; and use their combined knowledge, skills, and experience to promote a safer and more secure global electronic environment.
With today’s blended threat environment, a single organization’s incident response team will not be sufficient to provide the required coverage. Security operations must align itself with a reputable incident response organization. In addition, security operations needs to have some degree of either in-house or out-of-house malware analysis, as this skill set is in high demand. Security operations must give priority to continuous monitoring and incident response in order to meet the challenges presented in today’s complex, networked, global economy. The ability to stop cyber criminals depends on the organization’s commitment to detection and response.
Summary
We have discussed the wide range of security operations responsibilities, including identifying what must be protected, what it needs to be protected from, and how to determine what threats are likely to occur. We reviewed metrics, change management, communications, the importance of continuous monitoring, and incident response. Security professionals have a more difficult job than they did in the past. Security operations requires executive-level commitment and involvement and a team of highly qualified security professionals.
The secure management of your network is important because it reinforces, controls, and makes whole the rest of your security framework. If security management is not properly controlled, it obviates all of the data and transaction controls placed elsewhere in the system. Security management controls span acceptable use enforcement, administrative security, accountability controls, logging, and auditing—a range of activities that impacts the entire network infrastructure.
References
Publications
Brotby, Krag. Information Security Management Metrics: A Definitive Guide to Effective Security Monitoring and Measurement. Auerbach, 2009.
Brudan, Aurel (ed). Top 25 Information Technology KPIs of 2010. CreateSpace, 2011.
Fry, Chris, and Martin Nystrom. Security Monitoring: Proven Methods for Incident Detection on Enterprise Networks. O’Reilly, 2009.
Hayden, Lance. IT Security Metrics: A Practical Framework for Measuring Security & Protecting Data. McGraw-Hill, 2010.
Jackson, Chris. Network Security Auditing. Cisco Press, 2010.
Jaquith, Andrew. Security Metrics: Replacing Fear, Uncertainty, and Doubt. Addison-Wesley, 2007.
Klosterboer, Larry. Implementing ITIL Change and Release Management. IBM Press, 2008.
Manzuik, Steve, Andre Gold, and Chris Gatford. Network Security Assessment: From Vulnerability to Patch. Syngress, 2006.
McNab, Chris. Network Security Assessment: Know Your Network. O’Reilly, 2007.
Roebuck, Kevin. Vulnerability Management: High-impact Strategies. Tebbo, 2011.
Steinberg, Randy. Measuring ITIL: Measuring, Reporting and Modeling. Trafford Publishing, 2001.
Online Resources
Forum of Incident Response and Security Teams (FIRST).
www.first.orgInformation Systems Audit and Control Association (ISACA).
www.isaca.org