| CHAPTER |
|
| 32 |
Disaster Recovery, Business Continuity, Backups, and High Availability |
| |
|
In this chapter, we consider the practices necessary to provide service reliability and resumption in an IT environment. We will start with the concepts of disaster recovery and business continuity planning, which require analysis of the ways in which business is dependent on information technology and the impact of an outage. This analysis is useful in determining the strategies and investment needed to raise the level of reliability in the environment to an acceptable level.
We will look at some common backup strategies that are used to protect data, and how those backup strategies can be used in a recovery scenario. The disaster recovery practices are dependent on those backups, as well as other data replication strategies. Finally, we will consider how high availability can be built into computers and networks to reduce the likelihood of an outage.
Disaster recovery and business continuity planning are separate but related concepts. In fact, disaster recovery is part of business continuity. Disaster recovery (DR) concerns the recovery of the technical components of your business, such as computers, software, the network, data, and so on. Business continuity planning (BCP) includes disaster recovery along with procedures to restore business operations and the underlying functionality of the business infrastructure needed to support the business, along with the resumption of the daily work of the people in your workplace. Business continuity planning is vital to keeping your business running and to providing a return to “business as usual” during a disaster. DR and BCP professionals work together to ensure the recoverability and continuity of all aspects of an organization that are affected by an outage or security event.
A disaster is defined generally by DRI International as a “sudden, unplanned calamitous event causing great damage or loss” or “any event that creates an inability on an organization’s part to provide critical business functions for some predetermined period of time.” With this general definition in mind, the disaster recovery planner or business continuity professional would sit down with all the principals in the organization and map out what would constitute a disaster for that organization. This is the initial stage of creating a business impact analysis (BIA), which is an important input into the planning of service reliability and resumption.
Disaster Recovery
When you put together a disaster recovery plan, you need to understand how your organization’s information technology (IT) infrastructure, applications, and network support the business functions of the enterprise you are recovering.
For example, a particular business unit may claim not to need a certain application or function on day three of a disaster, but the technology process may dictate that the application should be available on day one, due to technological interdependencies. In this example, the DR planner should work with (and educate) the business unit to help them understand why they need to pay for a day-one recovery as opposed to a day-three recovery. The business unit’s budget will typically include a sizeable expense for the IT department, and this may cause the business unit to think that any disaster recovery or business continuity efforts will be cost prohibitive. In working with the IT subject matter experts (SMEs), you can sometimes figure out a way to bypass a particular electronic feed or file dependency that may be needed to continue the recovery of your system.
All of this will work well if you know who and what you are recovering. The responsible business continuity or disaster recovery professional should work with the IT group and the business unit to achieve one purpose—to operate a fine, productive, and lucrative organization. You can come to know who and what you are recovering by gathering experts together, such as the programmer, business analyst, system architect, or any other SME that is necessary. These experts will prove to be invaluable when it comes to creating your DR plan. They are the people who know what it takes to technically run the business systems in question and can explain why a certain disaster recovery process will cost a certain amount. This information is important for the manager of the business unit, so that she or he can make informed decisions.
Business Continuity Planning
The business continuity professional is more concerned with the business functions that the employees perform than with the underlying technologies. In order to figure out how the business can resume normal operations during a disaster, the business continuity professional needs to work with each business unit as closely as possible. This means they need to meet with the people who make the decisions, the people who carry out the decisions in the management team, and finally the “worker bees” who actually do the work.
You can think of the “worker bees” as power users. These are the users who know an application intimately. They know the nuances and idiosyncrasies of the business function—they are looking at the trees as opposed to the forest. This is important when it comes to preparing the business unit’s business continuity plan. The power users should participate in your disaster recovery rehearsals and business continuity tabletop exercises.
The business unit management team is vital because its members see the business unit from a business perspective—at a higher level—and will help in determining the importance of the application, as they are acquainted with the mission of the business unit. The business unit also needs to keep in mind the need for a disaster recovery plan as it introduces new or upgraded program applications. The disaster recovery and/or business continuity professional should be kept informed about such changes.
For example, a member of management in a business unit might talk to a vendor about a product that could make a current business function quicker, smarter, and better. Being the diligent manager, he or she would bring the vendor in to meet with upper management, and the decision would be made to buy the product, all without informing the IT department or the disaster recovery or business continuity professional.
As you can see, the business continuity professional needs to have a relationship with every principal within the business unit so that, should a new product be brought into the organization, the knowledge and ability to recover the product will be taken into consideration.
The Four Components of Business Continuity Planning
There are four main components of business continuity planning, each of which is essential to the whole BCP initiative:
• Plan initiation
• Business impact analysis or assessment
• Development of the recovery strategies
• Rehearsal or exercise of the disaster recovery and business continuity plans
Each business unit should have its own plan. The organization as a whole needs to have a global plan, encompassing all the business units. There should be two plans that work in tandem: a business continuity plan (recovery of the people and business function) and a disaster recovery plan (technological and application recovery).
Initiating a Plan
Plan initiation puts everyone on the same page at the beginning of the creation of the plan. A disaster or event is defined from the perspective of the specific business unit or entire organization. What one business unit or organization considers a disaster may not be considered a disaster by another business unit or organization, and vice versa.
A BIA is important for several reasons. It provides an organization or business unit with a dollar value impact for an unexpected event. This indicates how long an organization can have its business interrupted before it will go out of business completely.
Here are three examples of possible events that could impact your business and compel you to implement your disaster recovery or business continuity plan, along with some possible responses:
• Hurricane Since a hurricane can be predicted a reasonable amount of time before it strikes, you have time to inform employees to prepare their homes and other personal effects. You also have the time to alert your technology group so that they can initiate their preparation strategy procedures.
• Blackout You can ensure that your enterprise is attached to a backup generator or an uninterruptible power supply (UPS). You can conduct awareness programs, and perhaps give away small flashlights that employees can keep in their desks.
• Illness outbreak You can provide an offsite facility where your employees can relocate during the outbreak and investigation.
Analyzing the Business Impact
With a BIA, you must first establish what the critical business function is. This can only be determined by the critical members of the business unit. You might want to outline it in the fashion shown in
Figure 32-1.

Figure 32-1 Sample of a business impact analysis
As shown in
Figure 32-1, the information needs to be populated in a spreadsheet with different columns for Day 1, Day 3, Day 5, and so on.
The BIA should be completed and reviewed by the business unit, including upper management, since the financing of the business continuity plan and disaster recovery project will ultimately come from the business unit’s coffers.
Developing Recovery Strategies
The next step is to develop your recovery strategy. The business unit will be paying for the recovery, so they need to know what their options are for different types of recoveries. You can provide anything from a no-frills recovery to an instantaneous recovery. It all depends on the business functions that have to be recovered and on how long the business unit can go without the function. The question is essentially how much insurance the business unit wants to buy. If it is your business, you are the only one who can make that decision. Someone who does not have as large a stake in the growth of the business cannot look at the business from the same perspective.
For example, you could have your IT group perform regularly scheduled media backups—that would be the least expensive option. You could also have the IT group connect your local server to a server in another location and configure them such that a transaction made on the local server is also made on the remote server. This option, called a hot site, is more expensive, but it means that if the local server fails for some reason, the hot site can immediately take over with no loss of service.
This is where you need to utilize the expertise of the SMEs. Your software architect will be able to tell you the workflow of the applications and should also be aware of any ancillary or legacy systems that are necessary in the workflow process. Your network expert will be able to advise you of any network implications outside of your network or even within your network, such as interactions with the demilitarized zone (DMZ). The network recovery will assist in providing you with redundancy, and immediate recovery if the mirroring paradigm is used in a hot site scenario, but it will have a significant cost.
In a business recovery situation, there must be written procedures that all employees in your business unit can quickly access, understand, and follow. Information needs to be readily available about the business function that has to be performed. The procedures should be stored in multiple, accessible locations to ensure they are accessible in a disaster scenario.
You also need to make readily available a list of people to contact, along with their contact information. This list must be of the current employees to contact, and it should include members of the Human Resources, Facilities, Risk Management, and Legal departments. The list of contacts should also include the local fire and rescue department, police department, and emergency operations center.
Rehearsing Disaster Recovery and Business Continuity Plans
The fourth BCP component, and the most crucial, is to rehearse, exercise, or test the plan. This is “where the rubber meets the road.” Having the other three components in place is important, but the plan is inadequate if you’re not sure whether it will work. It is vital to test your plan. If the plan has not been tested and it fails during a disaster, all the work you put into developing it is for naught. If the plan fails during a test, though, you can improve on it and test again.
Third-Party Vendor Issues
Most organizations make use of various third-party vendors (Enterprise Resource Planning [ERP], Application Service Provider [ASP], et al.) in their recovery efforts. In such cases, the information about the third-party vendor is just as critical in your business or technology recovery. When you need to make use of such resources, it is beneficial, if not crucial, to make inquiries into the third-party’s operations prior to the implementation of its product or services.
In the real world, the disaster recovery and/or business continuity professional has to integrate the vendor’s information into the business unit’s continuity plan. If a critical path in your DR plan depends on the involvement of a third-party vendor, you can’t get your operation up and running if that third-party vendor isn’t prepared to assist you. For example, suppose that processing loans is the bread and butter of your business, and your business relies on credit bureau reports to process loans. In this scenario, you need to ensure that if your organization experiences an outage, you will still receive these reports in order to conduct business.
The vendor’s ability to recover from a failure will also affect how robust your recovery is. Although your recovery may be technically sound, you have to make sure you can conduct business. The same standards you apply to your own organization should apply to the third-party vendors you do business with. They should be available to you to conduct business. The disaster recovery or business continuity coordinator should make the appropriate inquiries with third party vendors to ensure that they can support a DR scenario.
Awareness and Training Programs
Another important element of disaster recovery and business continuity planning is an awareness program. The business continuity or disaster recovery professional can meet with each business unit to hold what are known as tabletop exercises. These exercises are important, because they actually get the members of the business unit to sit down and think about a particular event and how to first prevent or mitigate it, and then how to recover from it. The event can be anything from a category 3 hurricane to workplace violence. Any work stoppage can potentially impede the progress of an organization’s recovery or resumption of services, and it is up to the management team to design or develop a plan of action or a business continuity plan. The business continuity or disaster recovery professional must facilitate this process and make the business unit aware that there are events that can bring the business to a grinding halt.
Holding a Hazard Fair
While it’s important for disaster recovery and business continuity practitioners to prevent disruptions to your business functions, it’s also important to inform your organization’s people. DR and BCP programs for business functions and technologies should offer information to the employees, and the Hazard Fair serves that purpose.
If you work for a firm that supports effective disaster recovery program activities, you should have an established budget for your event. If you do not have a budget, have a discussion with your senior management to help them understand and appreciate the win–win situation created for employees by putting on the Hazard Fair for them, and to convince them of the importance of funding this activity. The employees will benefit from a Hazard Fair by learning who they can contact in the event of a disaster or outage in their local community. They can be informed about agencies ranging from the nearest fire and rescue department for local emergencies, to the Federal Bureau of Investigation (FBI) and Department of Homeland Security (DHS) in the event of a federal security incident. They can be also be informed about which stores in the area supply disaster recovery materials. Awareness is an important tool in the BCP toolbox.
Next, schedule a meeting with the management team so that you can help them understand and appreciate the value of the Hazard Fair. Assuming you used your negotiating skills to secure a budget, the next step is to set a date for the fair. You do not want to interfere with daily activities. Once you have the date selected, you’ll need to reserve an area for the fair, typically a cafeteria or large break room.
Next, determine an overall theme for the event. Something like “How to Be a Survivor” or “Surviving the Worst Case Scenario” might be appropriate. That will help your staff understand the purpose of the event and the importance of attending it.
Develop an event logo and advertise the event; for example, prepare and send e-mails, pass out flyers, and display posters in the halls, the cafeteria, and washrooms. If you have an intranet, be sure to post a notice of the event on the home page. In your messages, include the date and time of the fair, selected activities, vendors who will be exhibiting, prizes to be given out, and any other relevant facts. Make sure you describe how people can benefit from attending the fair, such as by learning how they and their families can be prepared for a disaster.
Vendors are very important to the fair, as they offer great ideas and information. You might consider inviting representatives from the FBI, the local police department, the local fire and rescue department, the local chapter of the American Red Cross, the city’s Emergency Operations Center, the Humane Society, NOAA (National Oceanic and Atmospheric Administration), home improvement stores, supermarkets, shutter companies, and local weather forecasters and television stations. Given the nature of your event, these people are likely to attend for nothing more than the cost of a meal. Your vendors will also appreciate the opportunity to get involved with the community. This way, everyone completes his or her community service for the month.
To get vendors to attend the fair, call them first, describing the event and the opportunity and its benefit to them. Next, you can follow up with a request on the organization’s letterhead, with an invitation stating how your organization is committed to assisting employees during a disaster and how the vendors can help in this effort. You can also mention that you’ll be feeding them!
For prizes, you can take a portion of the budgeted funds to purchase various “disaster items,” such as flashlights, bottled water, weather radios, matches, and even toilet paper. The idea is to stimulate thought about what is needed during a disaster. Obtain these and other items from local department stores. Create a game that encourages employees to visit each of the vendors, such as a special card that has to be stamped by each vendor. Each completed card is then entered in drawings for the prizes. Of course, serving free food will also cheer up the proceedings.
Schedule the fair to last a few hours; a good time to hold your event is during an extended lunchtime. With good planning and the support of your management and local vendors, you should be able to conduct your own successful Hazard Fair. It will help your employees appreciate the value of being prepared for disasters.
Backups
Backups may be used for complete system restoration, but they can also allow you to recover the contents of a mailbox, for example, or an “accidentally” deleted document. Backups can be extended to saving more than just digital data. Backup processes can include the backup of specifications and configurations, policies and procedures, equipment, and data centers.
However, if the backup is not good, or is too old, or the backup media is damaged, then it will not fix the problem. Just having a backup procedure in place does not always offer adequate protection.
In addition, many organizations can no longer depend on traditional backup processes—doing an offline backup is unacceptable, doing an online backup would unacceptably degrade system performance, and restoring from a backup would take so much time that the organization could not recover. Such organizations are using alternatives to traditional backups, such as redundant systems and cloud services.
Backup systems and processes, therefore, reflect the availability needs of an organization as well as its recovery needs. This section describes traditional data backup methodologies and provides information on newer technologies.
Traditional Backup Methods
In the traditional backup process, data is copied to backup media, primarily tape, in a predictable and orderly fashion for secure storage both onsite and offsite. Backup media can thus be made available to restore data to new or repaired systems after failure. In addition to data, modern operating systems and application configurations are also backed up. This provides faster restore capabilities and occasionally may be the only way to restore systems where applications that support data are intimately integrated with a specific system.
Backup Types
There are several standard types of backups:
• Full Backs up all data selected, whether or not it has changed since the last backup. The definition of a full backup varies on different systems. On some systems a full backup includes critical operating system files needed to completely rebuild a system, but on other systems it backs up only the user data.
• Copy Data is copied from one disk to another.
•
Incremental When data is backed up, the archive bit on a file is turned off. When changes are made to the file, the archive bit is set again. An incremental backup uses this information to back up only files that have changed since the last backup. An incremental backup turns the archive bit off again, and the next incremental backup backs up only the files that have changed since the last incremental backup. This sort of backup saves time, but it means that the restore process will involve restoring the last full backup and every incremental backup made after it.
Figure 32-2 illustrates an incremental backup plan. The circle encloses all of the backups that must be restored.
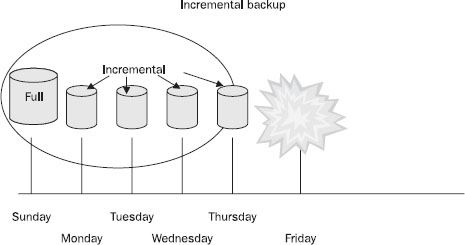
Figure 32-2 Restoring from an incremental backup requires that all backups be applied.
•
Differential Like an incremental backup, a differential backup only backs up files with the archive bit set—files that have changed since the last backup. Unlike an incremental backup, however, a differential backup does not reset the archive bit. Each differential backup backs up all files that have changed since the last backup that reset the bits. Using this strategy, a full backup is followed by differential backups. A restore consists of restoring the full backup and then only the last differential backup made. This saves time during the restore, but, depending on your system, creating differential backups takes longer than creating incremental backups.
Figure 32-3 illustrates an incremental backup plan. The circle encloses all of the backups that must be restored. (Compare this to
Figure 32-2.)
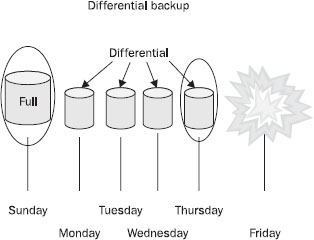
Figure 32-3 Restoring from a differential backup requires applying only the full backup and the last differential backup.
Backup Rotation Strategies
In the traditional backup process, old backups are usually not immediately replaced by the new backup. Instead, multiple previous copies of backups are kept. This ensures recovery should one backup tape set be damaged or otherwise be found not to be good. Two traditional backup rotation strategies are Grandfather-Father-Son (GFS) and Tower of Hanoi.
NOTE No backup strategy is complete without plans to test backup media and backups by doing a restore. If a backup is unusable, it’s worse than having no backup at all, because it has lured users into a false sense of security. Be sure to add the testing of backups to your backup strategy, and do this on a test system.
In the GFS rotation strategy, a backup is made to separate media each day. Each Sunday a full backup is made, and each day of the week an incremental backup is made. The Sunday backups are kept for a month, and the current week’s incremental backups are also kept. On the first Sunday of the month, a new tape or disk is used to make a full backup. The previous full backup becomes the last full backup of the prior month and is re-labeled as a monthly backup. Weekly and daily tapes are rotated as needed, with the oldest being used for the current backup. Thus, on any given day of the month, that week’s backup is available, as well as the previous four or five weeks’ full backups, along with the incremental backups taken each day of the preceding week. If the backup scheme has been in use for a while, prior months’ backups are also available.
Figure 32-4 depicts the GFS strategy.
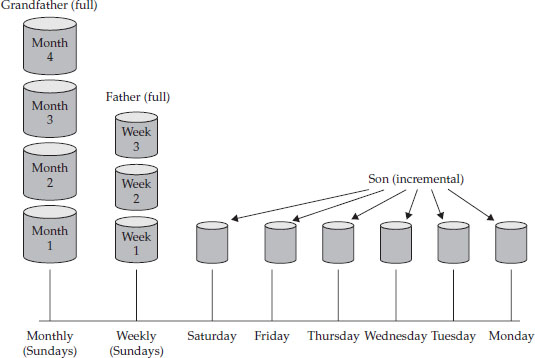
Figure 32-4 GFS backup tape rotation strategy
The Tower of Hanoi strategy is based on a game played with three poles and a number of rings. The object is to move the rings from their starting point on one pole to the other pole. However, the rings are of different sizes, and you are not allowed to have a ring on top of one that is smaller than itself. In order to accomplish the task, a certain order must be followed. Consider a simple version of the Tower of Hanoi, in which you are given three pegs, one of which has three rings stacked on it from largest at the bottom to smallest at the top. Call these rings A (small), B (medium), and C (large). You need to move the rings to the right-hand peg. How do you solve this puzzle?
The solution is to move A to the right-hand peg, then B to the middle peg, A on top of B on the middle peg, then C to the right-hand peg, then A to the now-empty left-hand peg, B on top of C on the right-hand peg, and finally A on top of B to complete the stack on the right-hand peg. The rings were moved in this order: A B A C A B A. If you solve this puzzle with four rings labeled A through D, your moves would be A B A C A B A D A B A C A B A. Five rings are solved with the sequence A B A C A B A D A B A C A B A E A B A C A B A D A B A C A B A. As you can see, there is a recursive pattern here that looks complicated but is actually very repetitive. Small children solve this puzzle all the time.
To use the same strategy with backup tapes requires the use of multiple tapes in this same complicated order. Each backup is a full backup, and multiple backups are made to each tape. Since each tape’s backups are not sequential, the chance that the loss of one tape or damage to one tape will destroy backups for the current period is nil. A fairly current backup is always available on another tape. This backup method gives you as many different restore options as you have tapes.
Consider a three-tape Tower of Hanoi backup scheme and its similarity to the sequence of the game mentioned above. On day one, you perform a full backup to tape A. On day two, your full backup goes to tape B. On day three, you back up to tape A again, and on day four you introduce tape C, which hasn’t been used yet. At this point, you now have three tapes containing full backups for the last three days. That’s pretty good coverage. On days 5, 6, and 7, you use tapes A, B, and A again, respectively. This gives you three tapes containing full backups that you can rely on, even if one tape is damaged.
Figure 32-5 shows this strategy using three tapes.
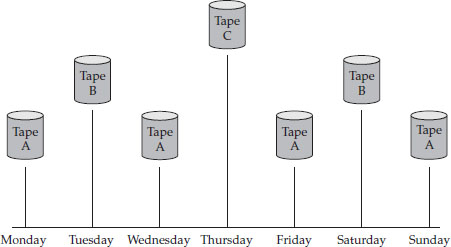
Figure 32-5 Tower of Hanoi backup tape rotation strategy
For additional coverage, you can use a four-tape or five-tape Tower of Hanoi scheme. You would perform the same rotation as in the game, either A B A C A B A D A B A C A B A in a four-tape system or A B A C A B A D A B A C A B A E A B A C A B A D A B A C A B A in a five-tape system. Higher numbers of tapes can be used as well, but the system is complicated enough that human error can become a concern. Backup software can assist by prompting the backup operator for the correct tape if it is configured for a Tower of Hanoi scheme.
Backup Alternatives and Newer Methodologies
Many backup strategies are available for use today as alternatives to traditional tape backups.
• Hierarchical Storage Management (HSM) HSM is more of an archiving system than a strict “backup” strategy per se, but it is a valid way of preserving data that can be considered as part of a data retention strategy. Long available for mainframe systems, it is also available on Windows. HSM is an automated process that moves the least-used files to progressively more remote data storage. In other words, frequently used and changed data is stored online on high speed, local disks. As data ages (as it is not accessed and is not changed), it is moved to more remote storage locations, such as disk appliances or even tape systems. However, the data is still cataloged and appears readily available to the user. If accessed, it can be automatically made available—it can be moved to local disks, it can be returned via network access, or, in the case of offline storage, operators can be prompted to load the data. Online services or cloud storage can be used for the more remote data storage, and this approach is commonly found in e-mail archiving solutions.
• Windows shadow copy This Windows service takes a snapshot of a working volume, and then a normal data backup can be made that includes open files. The shadow copy service doesn’t make a copy; it just fixes a point in time and then places subsequent changes in a hidden volume. When a backup is made, closed files and disk copies of open files are stored along with the changes. When files are stored on a Windows system, the service runs in the background, constantly recording file changes. If a special client is loaded, previous versions of a file can be accessed and restored by any user who has authorization to read the file. Imagine that Alice deletes a file on Monday, or Bob makes a mistake in a complex spreadsheet design on Friday. On the following Tuesday, each can obtain their old versions of the file on their own, without a call to the help desk, and without IT getting involved.
• Online backup or data vaulting An individual or business can contract with an online service that automatically and regularly connects to a host or hosts and copies identified data to an online server. Typically, arrangements can be made to back up everything, back up data only, or back up specific data sets. Payment plans are based both on volume of data backed up and on the number of hosts, ranging up to complete data backups of entire data centers.
• Dedicated backup networks An Ethernet LAN can become a backup bottleneck if disk and tape systems are provided in parallel and exceed the LAN’s throughput capacity. Backups also consume bandwidth and thus degrade performance for other network operations. Dedicated backup networks are often implemented using a Fibre Channel storage area network (SAN) or Gigabit Ethernet network and Internet Small Computer Systems Interface (iSCSI). iSCSI and Gigabit Ethernet can provide wire-speed data transfer. Backup is to servers or disk appliances on the SAN.
• Disk-to-disk (D2D) technology A slow tape backup system may be a bottleneck, as servers may be able to provide data faster than the tape system can record it. D2D servers don’t wait for a tape drive, and disks can be provided over high-speed dedicated backup networks, so both backups and restores can be faster. D2D can use traditional network-attached storage (NAS) systems supported by Ethernet connectivity and either the Network File System (NFS, on Unix) protocol or Common Internet File System (CIFS, on Windows) protocol, or dedicated backup networks can be provided for D2D.
Backup Policy
Many benefits can be obtained from backing up as a regular part of IT operations:
• Cost savings It takes many people-hours to reproduce digitally stored data. The cost of backup software and hardware is a fraction of this cost.
• Productivity Users cannot work without data. When data can be restored quickly, productivity is maintained.
• Increased security When backups are available, the impact of an attack that destroys or corrupts data is lessened. Data can be replaced or compared to ensure its integrity.
• Simplicity When centralized backups are used, no user needs to make a decision about what to back up.
The way to ensure that backups are made and protected is to have an enforceable and enforced backup policy. The policy should identify the goals of the process, such as frequency, the necessity of onsite and offsite storage, and requirements for formal processes, authority, and documentation. Procedures can then be developed, approved, and used that interpret policy in light of current applications, data sets, equipment, and the availability of technologies. The following topics should be specifically detailed in the policy:
• Administrative authority Designate who has the authority to physically start the backup, transport and check out backup media, perform restores, sign off on activity, and approve changes in procedures. This should also include guidelines for how individuals are chosen. Recommendations should include separating duties between backing up and restoring, between approval and activity, and even between systems. (For example, those authorized to back up directory services and password databases should be different from those given authority to back up databases.) This allows for role separation, a critical security requirement, and the delegation of many routine duties to junior IT employees.
• What to back up Designate which information should be backed up. Should system data or just application data be backed up? What about configuration information, patch levels, and version levels? How will applications and operating systems be replaced? Are original and backup copies of their installation disks provided for? These details should be specified.
• Scheduling Identify how often backups should be performed.
• Monitoring Specify how to ensure the completion and retention of backups.
• Storage for backup media Specify which of the many ways to store backup media are appropriate. Is media stored both onsite and offsite? What are the requirements for each type of storage? For example, are fireproof vaults or cabinets available? Are they kept closed? Where are they located? Onsite backup media needs to be available, but storing backups near the original systems may be counterproductive. A disaster that damages the original system might take out the backup media as well.
• Type of media and process used Specify how backups are made. How many backups are made, and of what type? How often are they made, and how long are they kept? How often is backup media replaced?
High Availability
Not too long ago, most businesses closed at 5 p.m. Many were not open on the weekends, holidays were observed by closings or shortened hours, and few of us worried when we couldn’t read the latest news at midnight or shop for bath towels at 3 a.m. That’s not true anymore. Even ordinary businesses maintain computer systems around the clock, and their customers expect instant gratification at any hour. Somehow, since computers and networks are devices and not people, we expect them just to keep working without breaks, or sleep.
Of course, they do break. Procedures, processes, software, and hardware that enable system and network redundancy are a necessary part of operations. However, they serve another purpose as well. Redundancy ensures the integrity and availability of information.
What effect does system redundancy have? Calculations including the mean time to repair (how long it takes to replace a failed component) and uptime (the percentage of time a system is operational) can show the results of having versus not having redundancy built into a computer system or a network. However, the importance of these figures depends on the needs and requirements of the system. Most desktop systems, for example, do not require built-in redundancy; if one fails and our work is critical, we simply obtain another desktop system. The need for redundancy is met by another system. In most cases, however, we do something else while the system is fixed. Other systems, however, are critical to the survival of a business or perhaps even of a life. These systems need either built-in hardware redundancy, support alternatives that can keep their functions intact, or both.
NOTE Critical systems are those systems a business must have, and without which it would be critically damaged, or whose failure might be life-threatening. Which systems are critical to a business must be determined by the business. For some it will be their e-commerce site, for others the billing system, and for still others their customer information databases. Everyone, however, recognizes the critical nature of air traffic control systems, and life support systems used in hospitals.
Two methods can be used to evaluate where redundancy is needed, and how much. The first, more traditional method is to weigh the cost of providing redundancy against the cost of downtime without redundancy. These costs can be calculated and compared directly (is the cost of downtime greater or less than the cost of redundancy?). The second method, which is harder to calculate but is increasingly easier to justify, is to decide based on the likelihood that customers will gravitate to the organization that can provide the best availability of service. This, in turn, is based on the increasing demands that online services, unlike traditional services, be available 24×7×365. High availability can be a selling point that directly leads to more business. Indeed, some customers will demand it.
There are automated methods for providing system redundancy, such as hardware fault tolerance, clustering, and network routing, and there are operational methods, such as component hot-swapping and standby systems.
Automated Redundancy Methods
It has become commonplace to expect significant hardware redundancy and fault tolerance in server systems. A wide range of components are either duplicated within the systems or effectively duplicated by linking systems into a cluster. Here are some typical components and techniques that are used:
• Clustering Entire computers or systems are duplicated. If a system fails, operation automatically transfers to the other systems. Clusters may be set up as active-standby, in which case one system is live and the other is idle, or active-active, in which case multiple systems are kept perfectly in synch, and even dynamic load sharing is possible. Active-active is ideal, as no system stands idle and the total capacity of all systems can always be utilized. If there is a system failure, there are just fewer systems to carry the load. When the failed system is replaced, load balancing readjusts. Clustering does have its downside, though. When active-standby is used, duplication of systems is expensive. These active-standby systems may also take seconds for the failover to occur, which is a long time when systems are under heavy loads. Active-active systems, however, may require specialized hardware and additional, specialized administrative knowledge and maintenance.
• Fault tolerance Components may have backup systems or parts of systems that allow them either to recover from errors or to survive in spite of them. For example, fault-tolerant CPUs use multiple CPUs running in lockstep, each using the same processing logic. In the typical case, three CPUs are used, and the results from all CPUs are compared. If one CPU produces results that don’t match those of the other two CPUs, it is considered to have failed, and it is no longer consulted until it is replaced. Another example is the fault tolerance built into Microsoft’s NTFS file system. If the system detects a bad spot on a disk during a write, it automatically marks it as bad and writes the data elsewhere. The logic to both these strategies is to isolate failure and continue on. Meanwhile, the system can raise alerts and record error messages to prompt maintenance.
• Redundant System Slot (RSS) Entire hot-swappable computer units are provided in a single unit. Each system has its own operating system and bus, but all systems are connected and share other components. Like clustered systems, RSS systems can be either active-standby or active-active. RSS systems exist as a unit, and systems cannot be removed from their unit and continue to operate.
• Cluster in a box Two or more systems are combined in a single unit. The difference between these systems and RSS systems is that each unit has its own CPU, bus, peripherals, operating system, and applications. Components can be hot-swapped, and therein lies its advantage over a traditional cluster.
•
High-availability design Two or more complete components are placed on the network, with one component serving either as a standby system (with traffic being routed to the standby system if the primary fails) or as an active node (with load balancing being used to route traffic to multiple systems sharing the load, and if one fails, traffic is routed only to the other functional systems).
Figure 32-6 represents such a configuration; note that multiple ISP backbones are available, and duplicate firewalls, load-balancing systems, application servers, and database servers support a single web site.

Figure 32-6 A high-availability network design supporting a web site
• Internet network routing In an attempt to achieve redundancy for Internet-based systems similar to that of the Public Switched Telephone Network (PSTN), new architectures for Internet routing are adding or proposing a variety of techniques, such as these:
• Reserve capacity
• System and geographic diversity
• Size limits
• Dynamic restoration switching
• Self-healing protection switching
• Fast rerouting (which reverses traffic at the point of failure so that it can be directed to an alternative route)
• RSVP-based backup tunnels (where a node adjacent to a failed link signals failure to upstream nodes, and traffic is thus rerouted around the failure)
• Two-path protection (in which sophisticated engineering algorithms develop alternative paths between every node)
Two examples of such architectures are Multiprotocol Label Switching (MPLS), which integrates IP and data-link layer technologies in order to introduce sophisticated routing control, and Automatic Switching Protection (ASP), which provides the fast restoration times that modern technologies, such as voice and streaming media, require.
Operational Redundancy Methods
In addition to technologies that provide automated redundancy, there are many processes that help you to quickly get your systems up and running, if a problem occurs. Here are a few of them:
• Standby systems Complete or partial systems are kept ready. Should a system, or one of its subsystems, fail, the standby system can be put into service. There are many variations on this technique. Some clusters are deployed in active-standby state, so the clustered system is ready to go but idle. To quickly recover from a CPU or other major system failure, a hard drive might simply be moved to another, duplicate, online system. To quickly recover from the failure of a database system, a duplicate system complete with database software may be kept ready. The database is periodically updated by replication, or by export and import functions. If the main system fails, the standby system can be placed online, though it may be lacking some recent transactions.
• Hot-swappable components Many hardware components can now be replaced without shutting down systems. Hard drives, network cards, and memory are examples of current hardware components that can be added. Modern operating systems detect the addition of these devices on the fly, and operations continue with minor, if any, service outages. In a RAID array, for example, drive failure may be compensated for by the built-in redundancy of the array. If the failed drive can be replaced without shutting down the system, the array will return to its pre-failure state. Interruptions in service will be nil, though performance may suffer depending on the current load.
Compliance with Standards
If you are following a specific security framework, here’s how ISO 27002 and COBIT tie in to this chapter. Both ISO 27002 and COBIT have a lot to say about disaster recovery. They both have entire sections devoted to contingency plans, disaster recovery, and business continuity plans. The relevant sections of each standard are provided.
ISO 27002
ISO 27002 has an entire section devoted to business continuity management (Section 14), which contains the following provisions:
• 14.1.1 Information security should be included in the business continuity management process. A managed process should be put in place to develop and maintain business continuity throughout the organization, which includes information security requirements. The business continuity plan should be formalized, and regularly tested and updated.
• 14.1.2 Business continuity and risk analysis should include consideration of events that could cause interruptions to business process such as equipment failure, flood, and fire. A risk assessment should be conducted to determine impact of such interruptions, and a strategic plan should be developed based on the risk assessment results to inform the overall approach to business continuity.
• 14.1.3 The development and implementation of business continuity plans should include information security, and plans to restore business operations within the required time frame following an interruption or failure should be regularly tested and updated.
• 14.1.4 There should be a single business continuity plan framework, maintained to ensure that all plans are consistent and priorities are identified for testing and maintenance. Consideration should also be given to conditions for activation of the plan, and individuals should be assigned responsibility for executing each component of the plan.
• 14.1.5 Business continuity plans should be tested regularly to ensure that they are up to date and effective, and they should be maintained by regular reviews and updates to ensure their continuing effectiveness. In addition, the organization’s change management program should include measures to ensure that business continuity is addressed when systems are modified, introduced, and retired.
COBIT
COBIT contains the following provisions, to which this chapter’s contents are relevant:
• DS4.1 A framework should be developed for IT continuity to support business continuity management for the organization, using a consistent process. The objective should be to assist in determining the required fault tolerance of the infrastructure and to drive development of disaster recovery and IT contingency plans. The framework should address the organizational structure for continuity management, including the roles, tasks, and responsibilities of internal and external service providers, their management and their customers, and the planning processes that create the rules and structures to document, test, and execute the disaster recovery and IT contingency plans. The plan should also identify critical resources, key dependencies, monitoring and reporting of availability of critical resources, alternative processing, and backup and recovery.
• DS4.2 IT continuity plans should be developed based on the framework, and designed to reduce the impact of a major disruption on key business functions and processes. The plans should be based on risk analysis of potential business impacts and they should address requirements for resilience, alternative processing, and recovery capability of all critical IT services. They should also cover usage guidelines, roles and responsibilities, procedures, communication processes, and testing.
• DS4.3 Attention should be focused on items specified as most critical in the IT continuity plan, to build in fault tolerance and establish priorities in recovery situations. Less-critical items should not be recovered first, and response and recovery should be done in line with prioritized business needs while ensuring that costs are kept at an acceptable level, and regulatory and contractual requirements are met. Availability, response, and recovery requirements should be specified for different tiers, including outage tolerances such as 1 to 4 hours, 4 to 24 hours, more than 24 hours, and critical business operational periods.
• DS4.4 IT management should define and execute change control procedures to ensure that the IT continuity plan is kept up to date and continually reflects actual business requirements. Changes in procedures and responsibilities should be clearly and timely communicated.
• DS4.5 The IT continuity plan should be tested on a regular basis to ensure that IT systems can be effectively recovered, shortcomings are addressed, and the plan remains relevant. This requires careful preparation, documentation, reporting of test results, and, according to the results, implementation of an action plan. Recovery testing should proceed from single applications, to integrated testing scenarios, to end-to-end testing and integrated vendor testing.
• DS4.6 All stakeholders should be provided with regular training sessions regarding the procedures and their roles and responsibilities in case of an incident or disaster. Training should be improved based on the results of the contingency tests.
• DS4.7 A distribution strategy should be defined and managed to ensure that continuity plans are properly and securely distributed and available to appropriately authorized parties when and where needed. Consideration should be given to making the plans accessible under all disaster scenarios.
• DS4.8 Actions to be taken for the period when IT is recovering and resuming services should be planned in advance. This may include activation of backup sites, initiation of alternative processing, customer and stakeholder communication, and resumption procedures. The business should understand IT recovery times and the necessary technology investments to support business recovery and resumption needs.
•
DS4.9 All critical backup media should be stored offsite along with documentation and other IT resources necessary for recovery and business continuity plans. The scope of backups should be determined in collaboration between business process owners and IT personnel. Management of the offsite storage facility should adhere to the data classification policy and the enterprise’s media storage practices. IT management should ensure that offsite arrangements are periodically assessed for content, environmental protection, and security.
Compatibility of hardware and software should allow archived data to be restored, and backups should be periodically tested and refreshed.
• DS4.10 IT management should have established procedures for assessing the adequacy of the plan concerning the successful resumption of the IT function after a disaster, and the plan should be updated based on the results.
Summary
In this chapter, we covered the four related business resumption strategies that are all necessary for recovery from incidents, outages, and disasters that result in service or data loss: disaster recovery, business continuity planning, backups, and high-availability. Together, these form the core of a strategy to keep the organization’s information infrastructure operational.
Here in summary are the principal points, roles, and responsibilities of a good disaster recovery and business continuity program.
• Develop and maintain disaster recovery and business continuity plans for all your organization’s enterprise technologies.
• Schedule and oversee disaster recovery rehearsals for all enterprise systems.
• Ensure disaster awareness by planning and conducting awareness programs, Hazard Fairs, lunch-and-learn sessions, and other informative events and materials.
• Activate the plan.
• Ensure community involvement by participating in local community disaster mitigation and planning initiatives and professional groups.
The disaster recovery and business continuity process is cyclical and must be maintained in order for it to stay current with the needs of the organization and the technologies in the environment. Your plans must be updated and rehearsed regularly. Disaster recovery is vital to everyone—you, your family, and the workplace.
Backups can be an important part of a recovery strategy. They play a role in disaster recovery process, to move data from the primary site to the DR site, although real-time data replication approaches are replacing traditional tape shipments in modern DR plans. Backups are also necessary for recovering data in a traditional data center.
High availability architectures are the fourth leg of the table supporting service resiliency, to ensure that failure of one system or component of a service doesn’t cause that service to fail.
References
Blyth, Michael. Business Continuity Management: Building an Effective Incident Management Plan. Wiley, 2009.
Burtles, Jim. Principles and Practice of Business Continuity: Tools and Techniques. Rothstein Associates Inc., 2007.
Childs, Donna. Prepare for the Worst, Plan for the Best: Disaster Preparedness and Recovery for Small Businesses. Wiley, 2009.
Cimasi, John. Disaster Recovery & Continuity of Business: A Project Management Guide and Workbook for Network Computing Environments. CreateSpace, 2010.
Hiles, Andrew. The Definitive Handbook of Business Continuity Management. 3rd ed. Wiley, 2010.
Hotchkiss, Stuart. Business Continuity Management: In Practice. British Informatics Society Ltd, 2010.
Kildow, Betty. A Supply Chain Management Guide to Business Continuity. AMACOM, 2011.
McEntire, David. Disaster Response and Recovery. Wiley, 2006.
Phillips, Brenda. Disaster Recovery. Auerbach, 2009.
Snedaker, Susan. Business Continuity and Disaster Recovery Planning for IT Professionals. Syngress, 2007.
Wallace, Michael, and Lawrence Webber. The Disaster Recovery Handbook: A Step-by-Step Plan to Ensure Business Continuity. 2nd ed. AMACOM, 2010.