15
By drinking heavily during pregnancy, can an expectant mother have lifelong effects on her child’s behavior? Scientifically, the surest way to find out would be to conduct an experiment in which several hundred mothers would be randomly assigned to either an experimental group that drinks heavily during pregnancy or a nondrinking control group. The children of these two groups of mothers could be followed for the next few decades to determine if there were any average differences in their behavior. For ethical reasons, experiments of this type will never be conducted, at least not with human subjects. So, how can scientists answer such an obviously important question? In this chapter, some powerful ‘‘near experiments’’ will be examined that can sometimes provide reliable answers.
Thousands of experiments have never been conducted even though they would provide invaluable scientific information. For example, scientists have theories about the causes of child molestation, drug addition, religious conversions, violence, and schizophrenia that can best be tested using controlled experiments. So why not conduct the experiments? The main reason is that such experiments would be unethical. Many other experiments—such as ones for identifying the causes of war, of economic depression, and even of the collapse of civilizations—would provide fascinating data. However, these experiments would not only be unethical but would be virtually impossible from the standpoint of their financial costs and logistics.
What do researchers do if they want to answer questions of a causal nature but cannot conduct controlled experimentation to provide the answers? In many cases, they turn to the research designs that are the focus of this chapter: quasi-experiments.
QUASI-EXPERIMENTS COMPARED WITH CONTROLLED EXPERIMENTS
The prefix quasi means ‘‘sort of.’’ Accordingly, quasi-experimental research is similar to controlled experimentation, although it falls short in some significant way. The term quasi-experiment was first used in the 1960s to refer to studies that were not true experiments (Campbell & Stanley, 1966).
In the course of learning about quasi-experimentation, keep in mind that, from a methodological standpoint, the gold standard for answering all causal questions is experimentation. Therefore, if a controlled experiment is possible, there is no need for any alternative, but when ethics, time, or money make experimentation impossible, scientists often resort to quasi-experimentation.
As summarized in table 15.1, quasi-experiments resemble controlled experiments in that the main purpose of both is to answer questions about causation. For this reason, the terms independent variables and dependent variables are often used in discussing quasi-experiments just as they are in controlled experiments. However, the designation of these two types of variables is not always as emphatic in the case of quasi-experimentation because in quasi-experimentation a researcher only ‘‘pretends’’ to manipulate an independent variable. (‘‘Pretending’’ in the context of quasi-experimentation is made clearer shortly.)
Because there is no actual experimental control in quasi-experiments, some researchers use the term predictor variable instead of independent variable, and criterion variable rather than dependent variable (Carlo et al., 1998, 278). In this text, the terms independent variable and dependent variable are used.
Furthermore, in most quasi-experiments, there are no genuine experimental and control groups. Therefore, it is common to use the term exposure group rather than experimental group and comparison group instead of control group (Rossi & Freeman, 1989, 277). These latter terms are particularly helpful in maintaining the important distinction between quasi-experiments and controlled experiments, and are used throughout this chapter.
As the various types of quasi-experimental designs are examined, it will become apparent that all these designs circumvent the process of real experimentation in some significant way. For example, in nearly all quasi-experimental designs, researchers bypass the process of randomly assigning subjects to experimental and control groups. They instead contrive a ‘‘control group.’’ Despite such compromises, quasi-experimentation plays an important role in social science research, and can still be a powerful tool for identifying cause-effect relationships.
QUASI-EXPERIMENTAL DESIGNS IN THE NARROWER SENSE
There are both a narrow and a broad sense in which the term quasi-experiment is used (Rossi & Freeman, 1989, 312). In the broadest sense of the term, quasi-experiments are all studies other than controlled experiments designed to answer causal questions. In the narrower sense, quasi-experimentation does not include research designs based simply on multivariate statistics. This chapter uses the term in the broadest sense, although it gives separate consideration to quasi-experiments that are based solely on multivariate statistics.
The four types of quasi-experimental designs that fit the narrower sense are called ex post facto designs, prospective designs, linear time series designs, and event-specific alignment time series designs. Each type is defined and illustrated in the following sections.
Ex Post Facto (Retrospective) Designs
Ex post facto means ‘‘after the fact.’’ Studies that fall under the category of ex post facto (or retrospective) quasi-experiments simulate after-only experimental designs except for random assignment of subjects. A public health disaster in India provides a clear example of an ex post facto design.
The Union Carbide Disaster in Bhopal, India
On a dark night in 1984 at the Union Carbide plant in Bhopal, India, a large quantity of a very poisonous gas (methyl isocyanate [MIC]) was accidentally released into the air. The gas slowly spread downwind over several miles of the city, killing thousands of people within a few days, and causing tens of thousands to become ill.
Years later, a researcher wanted to determine if exposure to MIC caused an increase in miscarriages among women who were pregnant and in the affected area at the time of the MIC release (Kapoor, 1991). The women residing in areas downwind from the plant, of course, became the exposure group. For a comparison group, the researcher chose women living upwind from the plant in areas where no one had been killed by the gas. He made sure that these comparison women had also been pregnant when the disaster occurred and were roughly comparable in terms of average socioeconomic status and ethnic composition as the exposure group. The comparison revealed a miscarriage rate of 26.3 percent for the 136 women in the exposure area and 7.8 percent for the 139 women in the comparison area.
How persuasive is this study in showing that MIC causes miscarriages? While it is not an experiment, if the matching was done fairly, one is left with little option but to conclude that a causal connection exists. Of course, ex post facto quasi-experiments can always be criticized on grounds that the groups being compared may not be equivalent in all important ways other than their degree of exposure to the independent variable (Rossi & Freeman, 1989, 322).
Types of Matching Procedures
In ex post facto research, three different matching procedures for obtaining comparison groups have been developed. These are called group matching, individual matching, and sibling matching.
Group matching occurs when a researcher merely ensures that, on average, there are no significant differences between the exposure and the comparison groups regarding a variety of demographic characteristics. This was the matching procedure utilized in the Bhopal study. Recall that the comparison mothers were matched as a group with the exposure mothers in terms of socioeconomic status and ethnicity.
Another example of an ex post facto design using group matching was a study undertaken in Australia to evaluate the effectiveness of an Alcoholics Anonymous (AA) program for women (Smith, 1985). Treatment outcome for forty-three female AA participants was compared to thirty-five similarly diagnosed women. The two groups of women were found not to be significantly different on the basis of place of birth, years of residency in Australia, age of first intoxication, and age of first having sought treatment. There was, however, a significant difference between the two groups on age of first beginning to drink: 18.8 for the exposure group as opposed to 22.2 for the comparison group. The group receiving AA treatment fared significantly better than the comparison group on a number of outcome measures, particularly the length of abstinence from alcohol. Because this study was not a true experiment, conclusions must be extremely guarded, but evidence from the study supported the view that AA-type approaches to alcoholism can have beneficial effects, at least for women.
Individual matching is more difficult than group matching because it requires that the researcher locate individuals in the comparison group that essentially match individual members of an exposure group. For example, if one member of the exposure group was a middle-aged female Native American with a college degree, one should find a comparison group member with roughly identical characteristics. Obviously, individual matching ensures that the averages for the two groups will be the same, at least for all of the demographic characteristics used in carrying out the individual matching. However, individual matching is thought to give researchers greater confidence in the comparability of the two groups.
Sibling matching involves identifying individuals with some unusual trait that researchers would like to better understand from a causal standpoint and using same-sex siblings as comparison subjects. This type of matching procedure automatically controls for race and ethnicity, social status, and family background (Offord & Jones, 1976). Sibling matching has been most often used for identifying prenatal and early childhood factors potentially contributing to later problem behavior such as behavioral and psychiatric disorders (e.g., Mura, 1974; Ruff & Offord, 1971).
One study that used this type of matching procedure was undertaken in Canada to better identify childhood conditions preceding antisocial behavior (Reitsma-Street et al., 1985). Several significant differences were found between the affected subjects and their unaffected siblings in terms of early life experiences, including the affected subjects being less warmly treated by parents.
A study involving the same research team used a similar sibling matching procedure to assess the effects of pregnancy and birth complications on antisocial behavior among adolescents (Szatmari et al., 1986). Contrary to earlier studies (McNeil et al., 1970), this one did not find pregnancy or birth complications to be significantly more prevalent among the antisocial adolescents than among their same-sex siblings.
Extensiveness of Matching
Ideally, matching is performed with numerous characteristics, not just one or two. Among the most common traits used for matching are age, sex, race and ethnicity, and years of education. A point to bear in mind is that in actual experiments with control groups, researchers are able to use random assignment to control for every conceivable difference between an experimental group and a control group. Ex post facto designs are undertaken to achieve the same objective through matching.
Obviously, the more characteristics one uses in matching exposure and comparison groups, the more confidence one can have that the two groups are equivalent with the exception of the independent variable. Were it possible to match two groups of subjects on every characteristic imaginable, an ex post facto quasi-experiment would provide just as convincing a case for causal relationships as would actual controlled experiments (Rossi & Freeman, 1989, 322).
Prospective Quasi-Experimental Designs
A prospective quasi-experimental design involves observing variations in the independent variable as events are unfolding, rather than reconstructing the events after the fact (as in ex post facto designs). The main advantage of measuring the independent variable while it occurs is that such measurement eliminates the risk of biased recall (Bailey & Zucker, 1995, 44).
Otherwise, a prospective quasi-experimental design and an ex post facto design are similar. Both typically have a structure that resembles an after-only experimental design, and both use one of the three matching procedures already discussed.
An example of a prospective quasi-experiment was one undertaken to determine if consuming alcohol during pregnancy affects the intelligence of the off-spring. For ethical reasons, no researcher would consider conducting a controlled experiment with human subjects to find out. This is because since the late 1960s, studies have found consumption of substantial alcohol by expectant mothers associated with a condition known as fetal alcohol syndrome in the offspring (Lemoine et al., 1968). Nevertheless, the effects of consuming small amounts of alcohol during pregnancy have not been associated with any obvious physical deformities.
Rather than conducting experiments, a Seattle-based research team asked over a thousand mothers during their fifth month of pregnancy the amount and the frequency of alcohol consumed up to that point in their pregnancy. The researchers followed up the offspring of these mothers into the second grade (average age of 7.5 years) to see how well they preformed on a standardized IQ test (Streissguth et al., 1990). Among other things, the study revealed that offspring of mothers who consumed two or more drinks per day had children whose IQ scores averaged seven points lower than children whose mothers drank little or no alcohol during pregnancy. These results persisted even after the researchers used multivariate statistics to make the mothers statistically equivalent in terms of background variables such as years of education and family income.
This study is an example of a prospective quasi-experiment. Note that measurement of the independent variable occurred years before measurement of the dependent variable. Nevertheless, the study is methodologically weaker than a controlled experiment because the mothers were not randomly assigned to an experimental (two drinks or more per day) and a control (no drinking) group. This fact means that it is possible that one or more crucial factors not statistically controlled were actually responsible for the seven-point difference in offspring IQs.
With laboratory animals, it is possible to perform carefully controlled experiments to assess the effects of such drugs on offspring (Abel, 1989; McGivern et al., 1984; Shah & Weat, 1984). However, with humans this would obviously be unethical, because most of the effects would tend to be detrimental.
Prospective quasi-experimental designs for assessing the effects of prenatal drug exposure typically have the following basic structure: Substantial numbers of women who have recently confirmed their pregnancies at a health clinic are invited to participate in a study. Those who agree to take part are asked to keep a record of various activities, including their use of various drugs. Some time after their children are born, the mothers are asked to bring their children to the clinic for testing, and the results of these tests are then correlated with the mother’s drug-use history.
To give a specific example, one study was conducted in which 650 women were interviewed during each trimester of pregnancy regarding their alcohol consumption. The study found that women who gave birth to infants with the lowest birth weights and head circumferences reported drinking significantly more than mothers of normal- and high-birth-weight infants, particularly during the first two months of pregnancy (Day et al., 1989). This evidence was particularly disturbing to the researchers because during the earliest months of pregnancy, most women are not aware that they are pregnant.
Researchers must be cautious in interpreting both prospective and ex post facto quasi-experiments. In neither case are subjects randomly assigned to the exposure and comparison groups. In this example, because neither the drinking mothers nor the nondrinking mothers were randomly assigned, numerous non-drinking variables could actually be responsible for the difference in birth weight and head circumference of the infants.
Generally, prospective designs are considered more persuasive than retrospective designs, especially when the independent and dependent variables are separated by long periods of time. The main drawback to a prospective design, however, is that a researcher must wait until the dependent variable manifests itself. Since this sometimes takes several years, it may be difficult to track down all the subjects in order to measure the dependent variable.
Linear Time Series Designs
Most linear time series quasi-experiments (also simply called time series designs) have a structure that closely resembles before-after no control group experiments, although the most powerful time series designs resemble classical experiments. The typical time series design involves tracking a dependent variable over time and observing whether the values of the dependent variable seem to change in response to changes in an independent variable.
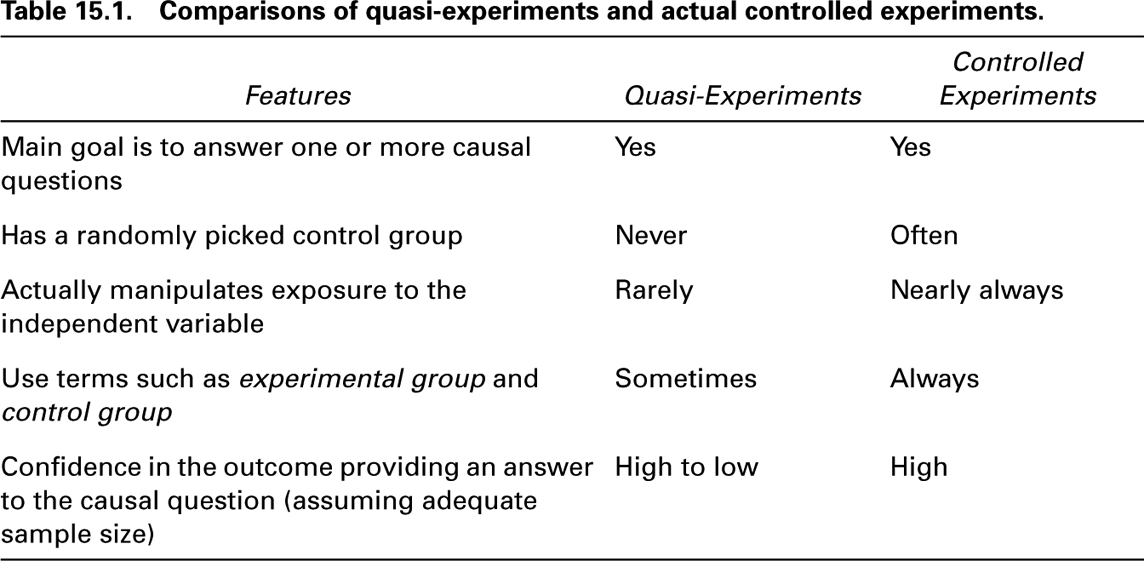
For a simple illustration of a time series quasi-experimental design, consider one undertaken with data in Wisconsin in order to assess the impact of raising cigarette taxes (Peterson & Remington, 1989). The annual per capita sale of cigarettes is shown in figure 15.1, along with the point at which two increases in tax were levied on each pack sold. In 1981, a 9¢ state tax was levied, which was followed two years later by an 8¢ federal tax increase.
As one can see, even though there was a general increase in per capita cigarette purchases from 1950 through 1980, purchases dropped rather dramatically following the two tax increases. The question that researchers must answer is whether the 1981–1984 decline in cigarette purchases (the dependent variable) can be attributed to the two tax increases (the independent variable). Obviously, no one can be certain, but it is reasonable to believe that the tax increases were at least the primary cause of the reduced cigarette sales.
There are two ways of strengthening a basic time series quasi-experimental design. One way is to include one or more reversals in imposition of the independent variable. In the case of the Wisconsin study, such a reversal could have been accomplished by repealing the taxes for a few years after their initial imposition. The design could then be strengthened even more by reimposing the taxes once again a few years later.
The second way to strengthen a basic time series quasi-experimental design involves adding a comparison group. This gives a time series quasi-experimental design a structure that closely resembles a classical experiment. In the Wisconsin study of cigarette smoking, such strengthening might have been accomplished by tracking cigarette sales in an adjacent state. Another comparison group might be the nearby Canadian province of Ontario. Assuming that Ontario did not increase taxes on cigarettes around the same time as the increases took place in Wisconsin, the drop in cigarette sales shown in figure 15.1 would not have occurred in Ontario.
Event-Specific Alignment Design
A type of time series design that deserves special attention is called an event-specific alignment study. As the name implies, this type of time series design obtains a series of average readings for some dependent variable in accordance with an independent variable that is occurring at irregular intervals over the course of time.
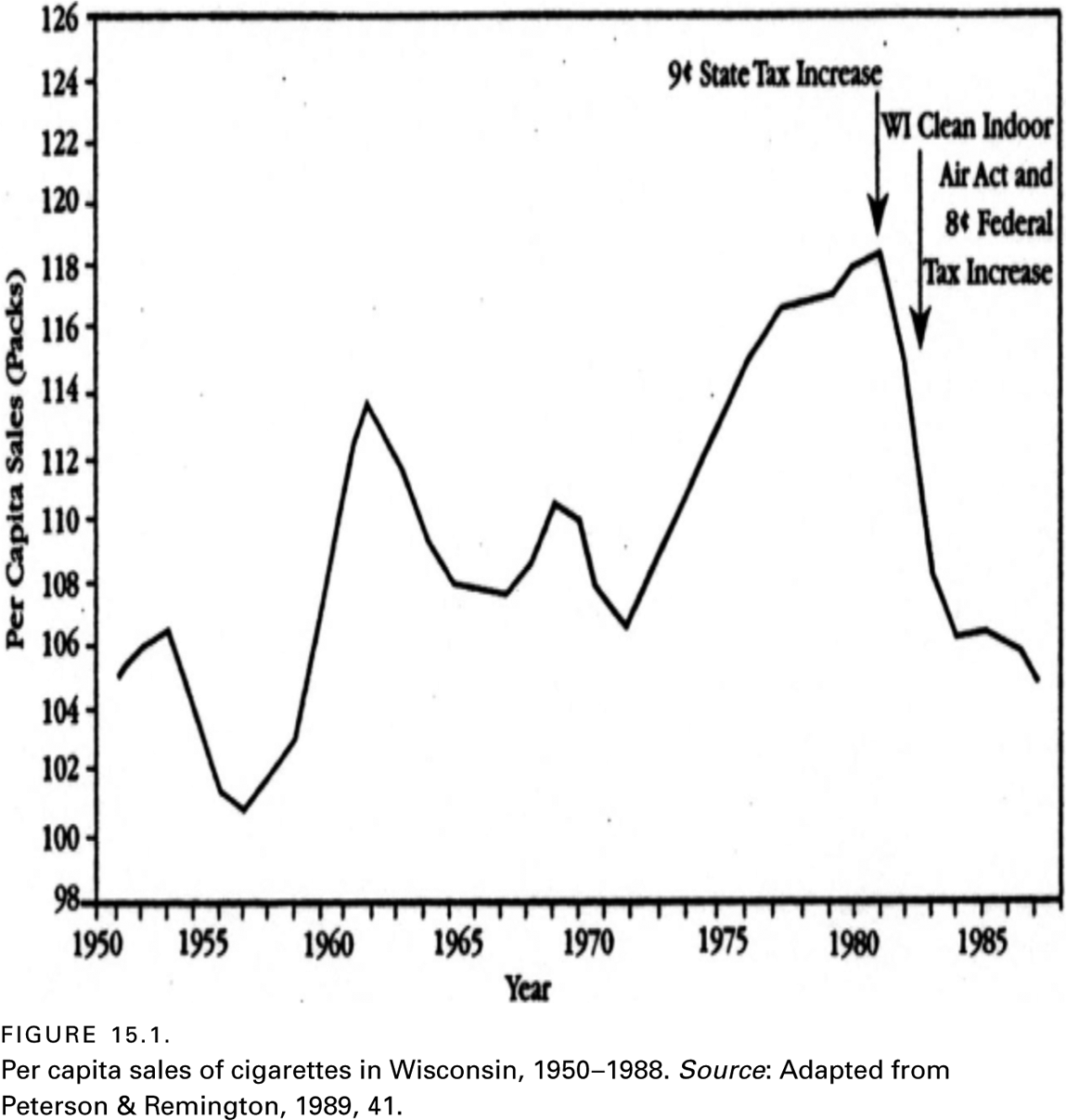
To see how such a design works, consider a study undertaken to discover whether people are often able to determine exactly when they die (Lee & Smith, 2000). The researchers who conducted this study reasoned that if individuals are often able to control when they die, people who were nearing the end of their lives would more likely die after rather than just before their birthday.
This study was based on the deaths of over five thousand elderly people living in San Francisco. Figure 15.2 shows the number of deaths spanning a period from twelve weeks prior to a decedent’s birthday through twelve weeks following. Throughout this time frame, an average of ninety-eight deaths occurred per week.
Figure 15.2 suggests a nonrandom pattern in the time of death relative to the decedents’ birthdays. However, the graph does not seem to support the idea that people delayed their deaths until after their birthday, since the two highest rates of death took place in the week prior to and the actual week of the decedent’s birthday. The authors of the report suggested that their findings imply that the stress associated with special occasions for people who are near death may sometimes be just enough to cause death. Such an explanation is often called a post hoc explanation, since the explanation was offered after obtaining an unanticipated finding.
The week of death–birthday study nicely illustrates an event-specific alignment time series design. The distinctive feature of such a design relative to a more common time series design is that all of the instances of some dependent variable (week of death in this instance) are aligned according to an independent variable (the birthday of the deceased). Then researchers calculate the average instance of the dependent variable for each time unit (each week) leading up to and extending through the occurrence of the independent variable.
For a second example of the event-specific alignment design, consider the long-standing controversy surrounding the death penalty as a deterrent for murder. Numerous nonexperimental studies have sought evidence to either refute or support the view that the death penalty has deterrent effects (e.g., Cochran, Chamlin & Seth, 1994; Decker & Kohfeld, 1990; Ehrlich, 1977; Forst, 1977). These studies have come to inconsistent conclusions, with most but not all suggesting that the deterrent effects are minimal (Layson, 1985; Peterson & Bailey, 1991).
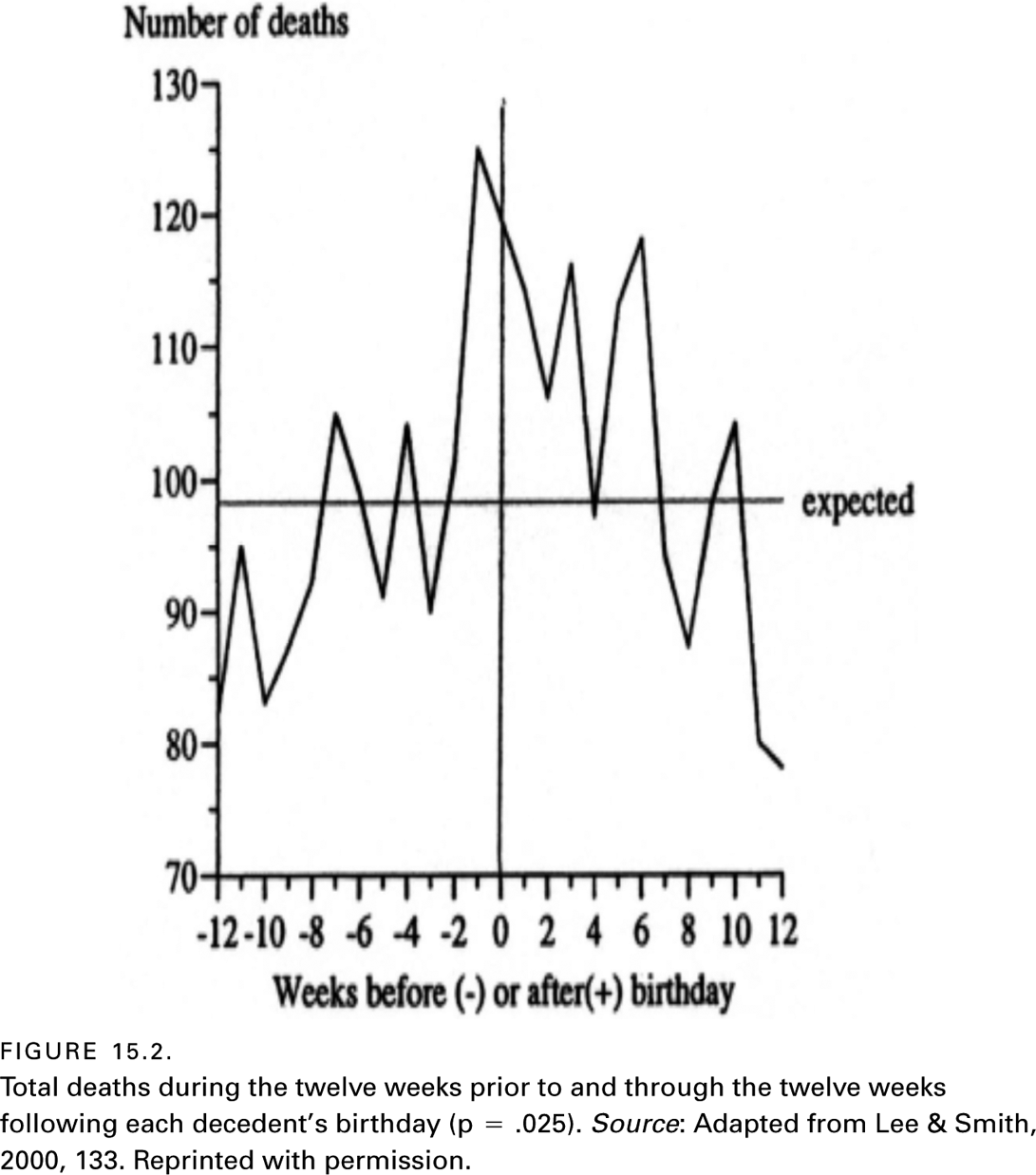
A sociologist took a particularly innovative approach to the question by utilizing an event-specific alignment design (Phillips, 1980). He obtained historical data on executions and murders in England between 1858 and 1921. During this period of time, twenty-two persons were publically executed for murder. The researcher aligned each murder in England during this time according to the week in which these twenty-two executions took place. His time frame was between the four weeks preceding and six weeks following the week of each execution.
The main findings are shown in figure 15.3. Notice that the number of murders was averaging just under thirty throughout the analysis period. In the week that the twenty-two executions took place, there was a substantial drop in the number of murders, and the number remained low for the following week. This suggests that the executions did have a deterrent effect. However, notice that by the third and fourth weeks following these twenty-two executions, the number of murders rose well above the average, almost completely canceling out the apparent earlier deterrent effects of the executions. A replication of this study based on contemporary U.S. data confirmed the essential findings from this rather intriguing study (Stack, 1987).
Basically, the event-specific alignment design is similar to other time series quasi-experimental designs except that all the instances in which the independent variable are imposed are aligned at a common point. Averages for the dependent variable are then calculated for specified time intervals leading up to and following the imposition of the independent variable. Despite the limited use of the event-specific alignment design compared with the more basic time series quasi-experimental design, it is a powerful design option for assessing cause-and-effect relationships.
QUASI-EXPERIMENTAL DESIGNS IN THE BROADER SENSE
In the narrow sense, quasi-experimental designs only include those just discussed, since all have design structures that resemble actual controlled experiments. In a broader sense, another type of design can also be considered a quasi-experiment. This is one in which multivariate statistics are used to ‘‘impose’’ comparability between two or more groups of subjects. To envision how multivariate statistics can be used to address causal hypotheses, consider a set of studies on a controversial topic: student learning in public verses private elementary schools.
An Example of Multivariate Statistics Used to Answer a Causal Question
Which type of school promotes greater academic achievement in grade school students: public schools or private schools? Research undertaken to address this question began to appear in the 1980s, led by a famous sociologist by the name of James Coleman, whose findings sparked controversy and has led to many subsequent studies. These studies have repeatedly demonstrated that, on average, students graduating from private (parochial) schools scored higher on a variety of standardized tests of academic performance than students graduating from public schools (Alexander & Pallas, 1983, 174; Coleman et al., 1981, 1982b, 1982c; Evans & Schwab, 1995; Heyne & Hilton, 1982; Sander, 1996; Young & Fraser, 1990, 18).
Although this evidence is consistent with the hypothesis that private schools better train students than public schools, there are certainly other possibilities. For example, private schools tend to be selective in the students they accept and retain, whereas public schools are legally required to take every child of an appropriate age. Therefore, differences between the achievement scores of children from private schools and those from public schools might not be the result of different teaching methods, school discipline, and the like. Instead, they reflect a selection bias by private schools (Murnane et al., 1995; Noell, 1982).
Why not conduct an experiment to sort out these possibilities? As one can imagine, few parents would be willing to allow their children to be randomly assigned to attend either private schools or public schools for the benefit of scientific knowledge. Consequently, Coleman and his associates sought to obtain an answer as to which type of school was doing the better job at teaching by statistically equalizing students attending both types of schools using multivariate statistics.
How can one statistically equalize students? The most widely used techniques involve determining how much of a difference exists in various demographic and family background variables (e.g., race and ethnicity, parental education, income) between students attending private school and those attending public school. Then, one makes statistical adjustments in the outcome variable (student achievement) on the basis of the average differences that exist in these background variables.
Most of the initial studies utilizing multivariate statistics indicated that the average difference in academic achievement between students attending public and private schools was almost an entire grade level, and that about half of this difference was eliminated by controlling for background variables (Coleman et al., 1981, 1982a, 1982b; Hoffer et al., 1985). Consequently, Coleman and his associates have suggested that private schools still seem to enhance the academic achievement of students over those of public schools by about a half a grade level, not a full grade level as the straightforward comparisons suggested.
To complicate the story, however, several researchers have reanalyzed the same data set that Coleman and his associates used in drawing their conclusions, and controlled for variables not included in Coleman’s analyses. These additional controls seem to almost completely eliminate the average differences in academic achievement between public and private school students (Alexander & Pallas, 1983; Goldberger & Cain, 1982; McPartland & McDill, 1982). A multivariate analysis of a completely different data set also suggested that combinations of control variables beyond those used by Coleman can explain nearly all the variation in academic performance (Morgan, 1983). If so, the inference is that when all other variables are taken into account, academic learning is virtually equal for the average private and public school. Coleman and his supporters have counterargued, however, that some of the statistical controls used by other investigators were inappropriate, and that some average differences in academic learning remains (Coleman & Hoffer, 1983).
So which conclusion is correct? Unfortunately, the answer still depends on whom you ask. Claims and counterclaims have frequently appeared in the social science literature. Basically, all the studies agree that standardized test scores of students attending parochial schools are higher than those of students attending public schools (Jencks, 1985). But why? Coleman and his associates have argued that significant performance differences remain in favor of private schools even after controlling for all reasonable differences between the types of students attending both types of schools (Evans & Schwab, 1995). They attribute most of these differences to the additional discipline and stricter enforcement of attendance policies by private schools (Coleman et al., 1982c). Others have attributed the supposed beneficial effects to the tendency of private schools to direct more students toward academic rather than vocational tracks, and to require more homework than occurs in most public schools (Hoffer et al., 1985). Critics have asserted that, once all the appropriate statistical controls are imposed, the difference in achievement of students attending public and private schools is too small to be of any practical significance (Alexander & Pallas, 1985; Willms, 1985).
Of course, this issue is of interest not only to social scientists. Studies like these have fueled considerable debate in the United States and other countries over governmental financing of private education (Allis, 1991; Edwards & Whitty, 1992; Morgan, 1983, 200).
QUASI-EXPERIMENTAL DESIGNS FOR ADDRESSING NATURE–NURTURE ISSUES
The most enduring issues in the social sciences center around the relative influence of learned sociocultural variables (nurture) and genetic and biological factors (nature) on human behavior (Ellis et al., 1988; Terwogt et al., 1993). With laboratory animals, controlled experiments have been conducted to assess the relative influence of nature and nurture on various types of behavior. Some of these experiments involve selectively inbreeding strains of rats or mice who exhibit some specific traits, such as unusual learning abilities, aggression, preferences for consumption of alcohol, and several other behavior traits (see table 13.1).
These studies suggest that genes account for substantial variation in many traits that appear to provide animal models for analogous human behavior. The way to be certain, however, is to conduct similar breeding experiments with humans, an approach that is obviously unethical and illegal. Fortunately, special quasi-experimental designs have been developed for addressing nature–nurture questions in humans (Pastore, 1949; Turkheimer, 1991, 392). The most common of these designs are called twin studies and adoption studies.
Twin Studies
Twin studies take advantage of the fact that there are two types of twins, both with a known degree of genetic relatedness to one another. Identical twins are, for all intents and purposes, genetic clones of one another. Except for rare mutations occurring after conception, they share 100 percent of their genes in common. Therefore, any differences between pairs of identical twins regarding either physical appearance or behavior can be attributed to environmental factors. Fraternal twins, on the other hand, are no more similar to one another than are ordinary siblings. Since all siblings receive half their genes from each parent, they share on average 50 percent of their genes in common, particularly if they are of the same sex.
The two-to-one ratio in the number of genes shared by identical and fraternal twins makes it possible to examine behavior traits for evidence of genetic and environmental influence. To the degree genetic factors influence a trait, identical twins will be twice as similar (concordant) for that trait as are fraternal twins. A variety of twin study designs have been developed over the years (Segal, 1990, 613), although they all rest on the fundamental logic just outlined. Behavior traits that twin studies suggest are significantly influenced (but not determined) by genetic factors include intelligence and educational achievement (Lykken et al., 1990; Tambs et al., 1989), occupational status (Fulker, 1978; Tambs & Sundet, 1985), criminality (Joseph, 2001), lifetime earnings (Taubman, 1976), homosexuality (Bailey & Pillard, 1991; Bailey et al., 1993), and criminality (Ellis et al., 2009, 77–78).
Some critics of the twin study method have argued that identical twins are found to be more concordant on many behavior traits not because of the influence of genetics, but because identical twins are treated more similarly by their parents and others than are fraternal twins. However, this may be because identical twins elicit more similar treatment due to appearance and behavioral similarities (Rowe, 1990, 608). Studies have generally failed to confirm that ‘‘similar treatment’’ is responsible for identical twins being roughly twice as concordant in numerous behavioral traits as are fraternal twins (reviewed by Segal, 1990, 614).
Adoption Studies
Most children have only one mother and one father. However, approximately 1 percent of infants born in Western countries every year are adopted at or near birth by persons unrelated to them (Cadoret, 1986, 45). Such children have two sets of parents: the parents who rear them (their rearing parents) and those who gave them their genes (their genetic parents). Social scientists have used adoptions to help determine how much influence genetic factors and family environment have over behavior.
Adoption studies, in fact, are very similar to a type of experimental design used with laboratory animals to address nature–nurture issues, a design referred to as cross-fostering experiments (Carter-Saltzman, 1980, 1263; Roubertoux & Carlier, 1988, 175). In these experiments, offspring are removed from their genetic mothers immediately after birth and given to foster mothers for rearing. To the degree that the offspring end up more closely resembling their genetic mothers than their rearing mothers for a given behavior pattern, genetic factors are deemed important for the expressions of the behavior (Huck & Banks, 1980; Roubertoux & Carlier, 1988).
Like twin studies, adoption studies have suggested that many human behavior traits are genetically influenced. For example, adoptees reared by nongenetic relatives have been found to more closely resemble one or both of their genetic parents than either of their rearing parents for each of the following traits: alcoholism, various forms of mental illness, and hyperactivity (Cadoret, 1986). Adoption studies also suggest that genes contribute significantly to variations in scholastic achievement (Teasdale & Sorensen, 1983; Thompson et al., 1991) and criminality (Ellis & Walsh, 2000, 445; Mednick et al., 1987; Raine & Dunkin, 1990; Tehrani & Mednick, 2000). One adoption study even suggested that handedness was influenced by genetic factors (Carter-Saltzman, 1980). Despite this evidence, the fact that the behavior patterns of adopted offspring are not fully explained by the influence of either set of parents makes it very likely that influences from environmental factors outside the family are important as well (Rowe, 1994).
Combined Twin and Adoption Studies and Other Designs
An especially innovative quasi-experimental design for addressing nature–nurture questions studies twins reared apart by different adoptive families (Holden, 1980; Lichtenstein et al., 1992; Waldman et al., 1992). While sample sizes tend to be small, twin/adoption designs have given researchers especially powerful avenues for separating the effects of genetic and environmental influences. Based on data from these combined twin/adoption studies, genetic factors have been detected for traits such as shyness and extraversion, dominance and submissiveness, intellectual ability (Bouchard et al., 1990; Holden, 1980; Waldman et al., 1992), and even occupational interests and status attainment (Lichtenstein et al., 1992; Moloney et al., 1991). Nevertheless, the effects of environmental factors, especially from outside the home, have also been quite evident (Lykken et al., 1990).
Other research designs that have been developed for sorting out the relative influence of genetic and environmental factors on behavior involve directly inspecting the deoxyribonucleic acid (DNA) and the chromosomes on which DNA codes appear (Ratcliffe, 1994; Schroder et al., 1981). However, these direct approaches to behavior genetics do not easily fit into the traditional trichotomy of nonexperimental, experimental, and quasi-experimental research designs.
While nature–nurture studies of human behavior have flourished in recent decades, they continue to be controversial. Some of the controversy has to do with details in methodology and interpretations of the findings (Fulker et al., 1972; Loehlin, 1992). Other areas of controversy surround the moral and legal implications of some of the findings from this research (Pastore, 1949; Montagu, 1980; Snyderman & Rothman, 1988).
SUMMARY
If a scientist is interested in whether Variable A causes Variable B, the surest way to a confident conclusion is by way of controlled experimentation. When experimental research is impractical or unethical, it is often possible to conduct quasi-experiments that simulate experiments. In the narrow sense of the word, quasi-experiments refer to studies that take advantage of manipulations of independent variables that occur outside of the direct control of the researcher. In the broader sense of the term, quasi-experimental studies include designs that rely primarily upon multivariate statistics to achieve ‘‘control’’ over variables that would normally be controlled through random assignment in an actual experiment.
Main Types of Quasi-Experimental Designs
There are three main types of quasi-experimental designs: ex post facto, prospective, and time series. Most ex post facto designs are conceptually structured like after-only experiments. However, instead of having any true experimental groups and control groups whose membership was randomly determined, ex post facto studies have comparison groups and exposure groups. A comparison group is ‘‘constructed’’ using some type of matching procedure. In ex post facto designs, the comparison group is chosen after the exposure group has received an unusual degree of exposure to an independent variable.
A prospective design is usually structured similarly to either an after-only or a classical experiment. Rather than being constructed after an unusual exposure to an independent variable has occurred, a prospective design is planned in advance of any exposure. Nevertheless, comparison subjects are again chosen through a matching process rather than by random selection.
Time series quasi-experimental designs have two distinct forms: the basic form and an event-specific alignment design. The basic time series design usually simulates a before-after no control group experiment, often with some type of reversal (e.g., ABAB) structure. Sometimes, a comparison group is used in a time series design, making it resemble a classical experimental design.
Regarding an event-specific alignment design, a researcher aligns numerous instances of a time-sequence for a dependent variable according to some specific independent variable. Then averages for the dependent variable are calculated for each time frame leading up to and following the independent variable. From this set of statistical adjustments, one is often able to detect changes in the dependent variable associated with imposition of the independent variable.
Multivariate Statistical Quasi-Experiments
In the broad sense of the term, some multivariate statistical studies can be classified as quasi-experiments. In a narrow sense, however, quasi-experiments based strictly on multivariate statistics simply control for ‘‘extraneous’’ variables statistically. Although control techniques made possible by multivariate statistics are fairly complex mathematically, the basic principles underlying them are fairly easy to understand and computer programs make them easy to perform. The key element of quasi-experiments based strictly on multivariate statistics is that the goal is to test causal hypotheses.
Quasi-Experimentation in Nature–Nurture Research
Special types of quasi-experimental designs have been developed for answering nature–nurture questions. The two most widely used designs are twin studies and adoption studies. Twin studies take advantage of the fact that humans have two types of twins, identical and fraternal, with known genetic relationships to one another. This makes it possible to estimate the relative influence of genetic and familial environmental factors on behavior patterns.
Adoption studies take advantage of the fact that many infants are adopted each year by nonrelatives, effectively giving them two sets of parents: their genetic parents and their rearing patents. This makes it possible to estimate the degree to which genetics and familiar environmental factors influence the behavior of adoptees.
There are, in fact, several types of twin study designs and adoption study designs, and recently a combined twin/adoption study design has been utilized. The latter involves studying twins reared apart in order to assess the influence of both genetic and environmental factors on behavior.
SUGGESTED READINGS
Coleman, J. S. (1990). Equality and achievement in education. Boulder, CO: Westview. (For those who would like to learn more about the debate surrounding private and public education, especially in the context of using multivariate statistics to help address hypotheses about cause-and-effect relationships, this book is well worth reading.)
Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentation: Design and analysis issues for field studies. Chicago: Rand McNally. (This is one of the very few books written specifically on quasi-experimental research.)
Among the social science journals that are most active in publishing research on the nature–nurture issue are:
Behavioral and Brain Sciences
Behavior Genetics
Personality and Individual Differences
No journals currently specialize in publishing quasi-experimental research.