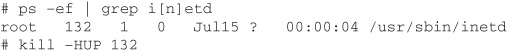
Securing Linux can seem to be a daunting task at first, especially if you have no one to show you the tricks of the trade. Security, in essence, consists of verifying that your server is clean, checking to ensure that it stays clean, and deactivating elements of the system that you do not need.
Since Linux has so much in common with other Unix-based operating systems, it follows that maintaining its security is also similar. While there are a few differences, keeping a Linux server secure is not much different than keeping any other Unix-based server secure.
We will assume in this chapter that you are familiar with basic concepts of Linux administration such as inserting/mounting CD-ROMs. If you need some more in-depth discussions of these concepts, an excellent reference is Linux: The Complete Reference by Richard Petersen (McGraw-Hill/Osborne, 2002).
In this chapter, we will refer to several tools, listed in the following table. Download them now and write them to a CD-ROM that you can insert into your new server. This will save you time as you go through the chapter, and will allow you to install some basic security tools before connecting your server to a network. These are the tools:
After you implement the suggestions in this chapter, your system will be more secure than it is right “out of the box.” Do not confuse that with being 100 percent secure. The only machine that is 100 percent secure has no keyboard, mouse, console, or network connection. On top of all the other suggestions here, do not forget the value in a good firewall. All your servers, unless you have a good reason to the contrary, should always be behind a firewall.
TIP Many security tools are provided with a checksum number that you can use to verify that no one has tampered with the tool before you install it. Usually, these are computed with the md5sum command or the sum command. It is a good habit to check the checksums of your tools before deployment. Use the man command to learn more about these commands.
Although it may seem obvious, unless you have a clean installation of Linux on a freshly formatted hard drive, there is no guarantee that someone has not already hacked into your system, making all future security work moot.
Insert the Install/Boot CD from your distribution. Disconnect the server from your network or verify that the network it is connected to is isolated. Boot your server from the CD and follow your distribution’s installer scripts, making sure to format all hard drive partitions before installing. Do not connect your server back to the network until you have done your system hardening.
When selecting which packages you will install, ensure that you install the gcc compiler, and its related packages. You will need this to build the system hardening tools discussed later in the chapter. Remove all compilers from your system before taking it live!
NOTE The preceding advice should be followed for all operating system installs, not just Linux.
Unless you know what is installed on your system, and all of the metadata associated with each file (for example, file size, modification date, owner, permissions), it can be tricky to spot when something has been altered, deleted, or otherwise modified. For this reason, it is a wise precaution to install a system file scanning tool.
Unless you install the tool on a system that you know is clean, you might merely be verifying that your hacked system is still hacked. Install this tool on your freshly installed system, before you attach the server back to your network.
There are several different scanning tools available, but we are going to focus on Tripwire. Tripwire comes in two different versions: a commercially distributed version that can be purchased from www.tripwire.com/, and an open source version. More information on the open source version can be found at www.tripwire.org/, and the latest version can be downloaded from http://sourceforge.net/projects/tripwire/. The differences between the versions are discussed at www.tripwire.com/products/.
Since we’re concentrating on Linux security, we will focus on the open source version. The latest version as of this writing is 2.3.1-2. On a different system than the one you’re going to secure, download the latest version of Tripwire and copy it onto a CD. Insert this CD into your new server, and copy the tar file to /tmp.

Now that you have the source code, you need to compile and install it. Edit the Makefile in the src directory and verify that the variables SYSPRE, MAKEFILE, and GMAKE are set correctly for your system. When you are finished, cd into the src directory and make tripwire:
![]()
When the compile completes successfully, cd back to the base tripwire directory and copy both files from install to the base directory:
![]()
Now you need to edit the file install.cfg and verify that the settings are acceptable for your environment. In particular, pay attention to the MAIL section. If your machine is not running sendmail (and it should not be if you do not accept incoming e-mail), then comment out the lines:
![]()
Uncomment the lines:
![]()
Set the values to what is appropriate for you. When you are finished, save the file and run the install:
![]()
This will ask you a series of questions. Along the way you will be asked for a site key and a local key. When you create these, keep them different, i.e., do not use the same key for both site and local. Additionally, create a key that will be hard to guess by including both upper-and lowercase letters, punctuation, and numbers. Have a minimum of six characters in each key. By keeping the keys different, you assure that, if a hacker gets into one system and cracks the key, the other systems will remain unaffected.
Congratulations! You have now installed Tripwire on your system. Now you need to configure it and run it for the first time to create a baseline for future comparisons.
First, you must initialize the Tripwire database so that it has a baseline to compare against. Do this with the following command:
![]()
Now that you have a working implementation of Tripwire, download the documentation from http://sourceforge.net/project/showfiles.php?group_id=3130 and read them thoroughly. Configuring Tripwire is a nontrivial task, but the time spent setting it up will be well worth it the first time your system gets “rooted” and you know what has changed.
NOTE According to Tripwire’s best-practices policy, you should move your original scan of your server to a read-only medium such as a CD-ROM disc. That way, you’re guaranteed your original database cannot be modified to cover up any system changes.
Before you deploy your server, you should sit down and decide exactly what role that server will perform. With few exceptions, for every additional service you run on your server, you will have at least one open network port, and at least one daemon or process to service that port. The more ports and services you are running, the more chances a malicious person has to try to crack into your system. Therefore, it is in your best interest to open only the ports you will need for your server to function, and lock down any others as much as possible.
Here is an incomplete listing of TCP/IP ports, and their associated services. For an up-to-date and much more complete list, go to www.iana.org/assignments/port-numbers/.
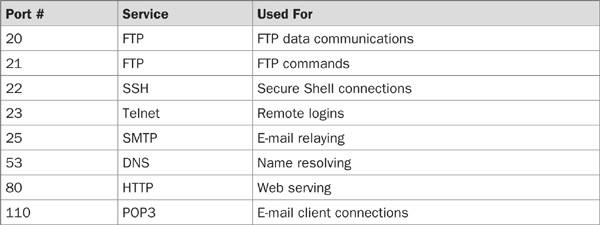
A huge number of ports have been defined, and many more are used without official sanction. The file /etc/services on your server will list all of the ports that your server knows about, and /etc/inetd.conf is a listing of services that handle the ports defined in /etc/services. Look through those files, but do not change anything yet.
Certain services are interrelated. For example, if you wish to run a mail server, unless you have a dedicated DNS server that can handle sporadically high volumes of traffic and a solid network between the servers, you might want to enable the DNS service for caching on your mail server.
Once you have determined what role your server will have in your network scheme, you need to edit your configuration files and remove and/or comment out the lines for services that you do not wish to support.
If your machine is going to be publicly visible on the Internet, you should disable Telnet, FTP, and the r* commands (rsh, rlogin, rexec, etc.) to shut down a large security risk. Most of the functionality of those services can be implemented in SSH much more securely. Visit www.openssh.org/ for more information on SSH. Most recent Linux distributions include SSH in the installation.
You could also use the configuration utility that came with your distribution to deactivate the startup scripts for unneeded services. For example, SuSE Linux uses YaST, and Red Hat uses Control Center. The option you want will be named something like “Run Level Editor” and will allow you to toggle services on and off via a clean GUI. Additionally, most recent Linux distributions come with a utility called chkconfig that is very versatile and useful. Use chkconfig if your Linux system has it.
Using any one of the preceding methods will produce the desired result, i.e., stopping unwanted services and daemons from starting up at system boot time. Pick the one that you are most comfortable with and stick to it.
Once you have locked down your server and have only those ports open that are needed for operation, you can add a port watching application to monitor attempts to access ports that you have deactivated. Sometimes these accesses will be unintentional and benign, but often you can shut down a cracker before they get started by watching for network activity.
There are many different applications available to perform this task, but among the simpler and easier to set up is PortSentry, available at http://sourceforge.net/projects/sentrytools/. PortSentry allows you to set up a simple list of which ports to monitor, and allows you to define actions when they are triggered. One of the most useful features of PortSentry is the use of ipchains/iptables to block all traffic from an offending IP.
As an example, suppose that PortSentry detects an attempt to connect to your server via port 139, a NetBIOS port (MS Windows filesharing). Unless your server is running Samba and sharing files to an MS Windows client, nobody should be attempting to connect to your server on that port. Therefore, you can configure PortSentry to perform several steps when it encounters this traffic:
• Add the connecting IP to TCP Wrappers (discussed in the next section).
• Add the connecting IP to ipchains to block further attempts at connecting.
• Add an entry into your syslog file (and to a remote syslog server if you have one defined).
• Send you an e-mail informing you of the attempt.
To install PortSentry, copy it from the CD you created on a networked system to your /tmp filesystem, then uncompress it. The latest version available as of this writing is 1.2; it creates a directory named portsentry_beta.

This will compile PortSentry and install the application and all configuration files in /usr/local/psionic/portsentry. After you have installed the application, read the file README.install to get an idea of what PortSentry can do, and what the different options mean. When you’re ready to implement the service, change to the /usr/local/psionic/ portsentry directory and edit portsentry.conf to have the options you wish. Then start PortSentry using the commands described in the README.install file, for example:
![]()
These two commands will start PortSentry in its basic mode—without stealth detection—and monitor both TCP and UDP ports. To make sure that PortSentry will be started each time your server boots, add the startup commands to your startup scripts.
Stealth detection, in a nutshell, activates PortSentry to watch the ports you have listed, but to not advertise the port as being open and accessible. For example, you could have PortSentry watching port 515 in stealth mode. This way, if someone does a port scan of your server, they will not see port 515 as being active, but if they try to connect to it anyway, PortSentry will catch the attempt.
You cannot run PortSentry in basic and stealth modes simultaneously but must choose which mode best fits your security model. Run PortSentry in one of its modes on your server, especially if you have some of the more abused protocols such as SMTP or lpr deactivated on your server. Having a process watch for exploit attacks on those fragile systems can stop a cracker before they start hitting some of the protocols that your server really is running.
Another way to lock down your server is by restricting what IPs are allowed to access it. The most highly regarded system for doing this is TCP Wrappers by Wietse Venema, who also is responsible for Postfix (a sendmail replacement) and SATAN (a network scanner), among others. TCP Wrappers can be downloaded from ftp://ftp.porcupine.org/pub/ security/index.html.
Since TCP Wrappers has been so widely adopted, it may be supplied and installed by default on your Linux distribution. If so, you can skip the following discussion on how to install it, and go straight to the section detailing how to configure it.
First check to determine if your Linux system came with TCP Wrappers preinstalled; the majority of them do. If it is already installed, skip to the next section to configure your setup. Otherwise, change to your /tmp directory and unpack TCP Wrappers from your CD.

Please take the time to read the README file if you are unfamiliar with what this program does. We will be using the “advanced” install of TCP Wrappers. When you are ready, edit the Makefile and verify that the REAL_DAEMON_DIR variable is pointed to the correct directory (which is /usr/sbin on most Linux installations). Save the Makefile and exit your editor, then compile TCP Wrappers.
![]()
When the compilation finishes, you will be left with five programs. The most important is tcpd, which is the main TCP Wrappers handler. Copy this file into /sbin. TCP Wrappers is now installed.
TIP On all of the recent distributions that I tested this with, when compiling I would receive the following error: “percent_m.c:17 conflicting types for ‘sys_errlist’.” If this happens to you, simply edit the file percent_m.c and change line 17 to read “ /* extern char *sys_errlist[]; */,” then save the file and run make linux again.
TCP Wrappers is controlled by two configuration files, /etc/hosts.allow and /etc/ hosts.deny, and invoked through /etc/inetd.conf. Before we tell inetd to start using TCP Wrappers, we need to set up a few simple rules for it to follow. The rules in /etc/ hosts.allow and /etc/hosts.deny can grow large and complex, but the basic format of the rules is “SERVICE: ACTION.” Make sure you thoroughly read and understand the README file supplied with the source code; it provides a wealth of information and examples of how to construct more complicated rule sets.
The logic that TCP Wrappers follows is fairly straightforward and can be simply described:
1. Any host listed in /etc/hosts.allow for the requested service will be allowed access.
2. Any host listed in /etc/hosts.deny for the requested service will be denied access, unless granted access in /etc/hosts.allow.
3. Any host not listed in either file will be allowed access.
So, let us set up an initial /etc/hosts.deny file to block all access to all services. By doing this, only machines explicitly granted access to services in /etc/hosts.allow will be allowed to connect to your server, and all other attempts will be blocked. Edit /etc/hosts.deny and add the single line
![]()
This will block all attempts except from the server itself. Now you need to determine which machines need access to your server, and what services they need access to.
NOTE Services supplied from applications or daemons that are not controlled by /etc/inetd.conf (such as a WWW server) will not be affected by TCP Wrappers. For example, if your server will be running Apache, you should not need to add a line to /etc/hosts.allow in the form “httpd: ALL,” as TCP Wrappers will never see that connection. This can be beneficial, but it can leave doors open that you didn’t intend to leave open.
If the service that you are looking at is not listed in /etc/inetd.conf, then it is probably running as a background daemon. TCP Wrappers can be of little help in this situation, unless the author of the daemon has added support for TCP Wrappers to the source code. Read the README and INSTALL files carefully for any service that you are installing to see if TCP Wrappers is supported, and if so, what steps you need to take to activate it.
Now that we’ve blocked access to all of the services to everyone, we need to allow back in the machines that have a legitimate need to connect. Make a list of what services in /etc/ inetd.conf you will leave activated, and add to that list what machines can connect to each service. The rules allow for pattern matching, so if you wish everyone in a specific subnet to have access, or everyone with a specific domain name, you can do this.
As an example, let us consider a WWW server. To the outside world, this system should have only port 80 and perhaps port 443 (for secured https) available, but to your internal staff they need to be able to FTP files onto the server, and they do not want to use SFTP. Everyone who needs access has an IP in the range 192.168.34.0–192.168.34.255. They are also in the domain mycompany.com. Now, you could open up FTP by putting the line
![]()
into /etc/hosts.allow, but that can be risky. Should everyone who works at your company be allowed to connect to that server? Remember, in security, the more you can lock something down, the better off you will be. Since you know that everyone who needs access is in one subnet, the line
![]()
would be preferable to the entire domain. If you can narrow it down to a single IP, that’s even better. You can add multiple conditions to the allowed rules by separating them with a comma (,). In the following example, we’re allowing everyone in our company to FTP into the system, as well as everyone from our sister company, and everyone with an IP in the range of 10.0.1.0–10.0.1.255.
![]()
The last thing we need to do is to edit /etc/inetd.conf to enable out rule sets. Open up this file in your editor and modify all of the lines describing the services you wish to monitor to use your new tcpd program. For example, the line describing in.ftpd would change from
![]()
and become
![]()
Make sure to leave any command-line arguments at the end of the line alone; they will be passed on to the service if authorization is granted. After all of these changes have been put into place, it is time to activate TCP Wrappers. To do that, send a HUP signal to your inetd daemon. In the following example, the inetd daemon has a PID of 132.
Systems that use xinetd instead of inetd use TCP Wrappers in a different way. Because of the configuration differences between inetd and xinetd, xinetd daemons are linked with the libwrap library provided with TCP Wrappers. For this reason, all of the daemons are already aware of TCP Wrappers and no further configuration changes are needed to the xinetd.conf file to enable TCP Wrappers.
To use TCP Wrappers on these servers, simply edit the /etc/hosts.allow and /etc/ hosts.deny files as described in the preceding section. To determine if a daemon has been linked with the libwrap library, use the command
![]()
Replace the word “daemon” with the file you are checking against, for example, in.telnetd to check the telnet service.
For further information on xinetd, use the man command. This daemon is a very powerful replacement for inetd.
TCP Wrappers is now installed and helping block unwanted system access.
Once you have implemented the preceding suggestions, you can connect and activate the network on your server, as you must do for the next section.
One of the main rules in system security is this: knowledge is power. If you do not know that something happened, you are powerless against it. For that reason, systems keep copious logs of important events that you should be aware of.
Having spent many evenings combing through logs trying to piece together events, I can tell you that not much is more boring than reading system logs. Nevertheless, it needs to be done. Fortunately, other administrators felt the same way, and they wrote automated log scanning applications to help relieve the tedium. By setting up an automated system to scan your logs for you, you can dramatically cut down on the amount of reading you need to do to stay on top of your systems. We will discuss some of these applications in the next few sections.
Another rule that applies to system logs is to keep multiple copies. Set up a centralized log server to capture system logs from all of your machines. The main reason for this is to archive your logs for reconstruction later if needed, but it serves a good security purpose as well. Let us look at a real-life scenario.
Your server web box has been hacked into. The person who cracked your box edited the log files on that machine and erased his tracks. If that machine was replicating its logs in real time to a log server, however, then the cracker must attempt to hack into this second box to remove tracks from there as well. This will take some time to do, but since you were running a log scanning program on the centralized server, you’ve already been alerted to the hacker’s presence and have started taking the necessary steps to terminate their entry.
This happens around the world every day. If you’re at all serious about security, you need to have at least one centralized log server. When creating the server, deactivate almost all of the services (with the notable exception of syslogd—make sure that port is open and available). The two things the log server will need above all else are hard drive space and CPU power. When gathering the logs from several servers, the combined files can grow quite huge, and a slow CPU will be hard-pressed to keep up in real time with the data coming in.
TIP While on the surface, it might make sense for you to combine your Windows and Unix logs onto the same log servers, in reality it does not. Both systems use very different log file formats, and the only systems that can gather both are not able to accept large amounts of data graciously. Keep the Unix servers and the Windows servers logging to different machines.
Once you have a centralized server up and accepting logs, you need to configure your servers to use it. Log in to your server and edit /etc/syslog.conf. Decide what messages you are interested in replicating, and add the appropriate lines. For instance, if you were interested in all emerg, alert, crit, err, warning, and notice messages and your log server had an IP of 192.168.5.43, you would add the line
![]()
to /etc/syslog.conf. You can add multiple lines; you do not have to cram all of your setup onto a single line. Once you have made your changes, send a HUP signal to syslogd to have it reread the configuration file. Then watch on your log server to verify that system logs are coming over.
Scanning your logs will help alert you to potential trouble, often before it progresses too far. Scanning all of your logs in real time on all your servers can be a tremendous drain on your available CPU power. That is why there are two main types of log scanning applications, those that scan periodically and those that scan continuously. My recommendation is to put a periodic scanner on each server, and a real-time scanner on your centralized log servers.
There are several different applications that do log scanning, but we’re going to look at only two of the more prevalent applications. For real-time scanning, we will look at Swatch, available from swatch.sourceforge.net/, and for periodic scanning, we will use Logcheck, available from sourceforge.net/projects/sentrytools/.
The most recent version of Swatch available as of this writing is 3.0.8. Download the source and unpack it. Read the README and INSTALL files to ensure that you meet all of the prerequisites for installing Swatch. Once you’re ready to install Swatch, perform the following steps:

Swatch does not come with separate documentation; all of the docs are contained in pod format. If you are more comfortable reading man pages, cd to a man5 directory and run pod2man.
![]()
Swatch derives all of its power from a set of configuration files. One of the trade-offs to making an application very powerful is that it is often very difficult to configure, and Swatch proves itself to be no exception. It’s easy to write a Swatch configuration that works, but it’s very difficult to write one that works well.
Once you have created the man page for Swatch, read it by typing man swatch at the command line. Pay particular attention to the section labeled “THE CONFIGURATION FILE,” as this will tell you all of the rules to writing your own configuration. The rules follow the pattern of KEYWORD VALUE followed by one or more indented lines containing commands to execute when that rule is triggered. As an example, the following rule set will watch for the word ALERT, then ring the system bell three times and send an e-mail when it sees that word.
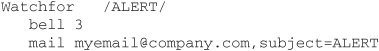
A lot of the power of Swatch comes from its ability to run other commands on matched output. For example, if you got a message that your /tmp file system is full, you could execute a command to delete all files older than seven days. This ability really opens up the door to unlimited possibilities of actions that can be performed, and this is what makes Swatch a powerful tool when well configured.
Once you have your configuration file written, launch Swatch with the command
![]()
Swatch is capable of scanning in real time any file you specify; it is not limited to system log files. Additionally, Swatch is capable of reading data command output. Each file or command that you wish to monitor with Swatch has its own configuration file, thereby allowing you to take different actions for different files. Just start Swatch once for each file or command you want to monitor, as in the preceding example.
By having Swatch monitor all your system logs in real time on your log server and e-mail or page you on suspicious events, you can keep up with your servers without having to spend a lot of time reading logs on your own.
Logcheck takes a different tack from Swatch, in that it’s not expecting to run all the time. Logcheck uses a customized tail program that keeps a record of the last line of each file that was scanned, and then picks up from that point when invoked again. The most common scenario with Logcheck is to have it called via cron repeatedly, for example, every 30 minutes. One of the advantages of Logcheck is that it can e-mail (or otherwise alert) you when it encounters a message that it does not have any information about. This can be useful to let you know when something out of the ordinary is happening.
Logcheck follows two simple rules when it scans:
1. It reports everything you told it to watch for.
2. It reports everything you didn’t tell it to ignore.
To install Logcheck, download the source from http://sourceforge.net/projects/sentrytools/ and unpack it.

Once there, read the README file for good background and the philosophy of Logcheck. After that, carefully read the INSTALL file, and follow the directions. Once you have edited the logcheck.sh file, run make linux and Logcheck will be installed. After that step, edit your crontab file to call logcheck.sh on a regular basis. For example, to call logcheck.sh every 15 minutes, you would add the line
![]()
to the root crontab by using the command crontab –e as root. Ignore the line in the INSTALL file telling you to send crond a HUP signal; using the command crontab –e takes care of that for you.
Configuring Logcheck is a fairly straightforward endeavor. Simply go to the directory /usr/local/etc and edit the files; logcheck.ignore specifies what patterns to disregard, logcheck.violations specifies what patterns to raise an alert to, and logcheck.hacking specifies what patterns to raise an obnoxious, attention-getting alert to.
The patterns are specified one per line, and Logcheck comes with a list of patterns specific to your operating system (Linux in this example) to use as a boilerplate for your own alerts.
Run Logcheck as configured for a while to determine what is logged to your system. After a few days of running, you should have enough alerts to allow you to start editing the configuration files to more closely match your environment.
When you start setting up security for the first time, your tendency is to set up as much alerting as possible, and be hyper-informed on the state of your systems. While this is a worthy ambition, the sad reality is that you will quickly become overwhelmed with too much information, most of it not very useful. At that point, you will start to disregard the alerting system you worked so hard to implement, and when a real emergency comes along, you will miss it in the sea of information you are swimming in.
Spend a little time when you first implement a warning system like these to tune it for your environment. The more you can filter out routine alerts and nice-to-know but not very relevant informational logs, the better able you will be to recognize a real alert when it comes along. Sometimes, having too much information is just as bad as having too little.
Examples of alerts that can fall into the “not very relevant” category could be named (DNS) alerts of a lame server for resolving MX records or that an e-mail was not delivered yet because the remote server is inaccessible. Events that you will probably want to know about quickly could be someone trying to connect to port 515 (lpr) when they’re not even in your geographic location and you don’t have lpr running, very large sendmail commands being sent, or a file system filling up.
The world is a constantly changing place, and the world of Linux is no exception. New exploits to services are found, buggy code is discovered in daemons, and other problems are found. Sometimes these discoveries are made by people who want to find them so that they can be fixed, but many times they are discovered by people actively looking to exploit your servers. While there is no surefire way of guaranteeing that you can plug all of the holes before you’re hit, there are things you can do to plug them in a timely fashion.
Most commercial Linux distributions available today have a system updating tool. In SuSE Linux, it is called “yast2,” and in Red Hat, it is called the Red Hat Network Agent. Load the administration tool for your distribution and familiarize yourself with it. Get into the habit of running the tool on a regular basis and determining what new updates have been released.
When you see an update available, don’t blindly update your system with the patch. Think about it first and ask yourself, is this an application or service that you are using? If the answer is no and you have already deactivated this service, there is really no reason to perform the update. In addition, if you do perform the update, there is a very good chance that the installer script will reactivate the service upon termination. This behavior is not desired.
If the update is for something you are using, read the release notes before installing the update. Try to determine what impact installing the update will have on your system, and look at the changes it will make. Will it open up something that you already closed, or otherwise tamper with the security you’ve worked hard to implement? Only after determining exactly what the update will do and deciding that it is beneficial should you install the update.
Many software projects for Linux run mailing lists to inform people of new releases or other pertinent information. If you’re running software that has such a list, consider joining it. Most modern e-mail clients allow you to separate each list into its own folder to keep them neat, so you don’t clutter your inbox with too much information. These lists are a great source of information when an exploit has been discovered in the software. Usually, they will give you quick fixes or temporary workarounds for the problem, and then when the fixed release is available, they will alert you to get it. This information can be exceedingly valuable for publicly available services such as Apache.
There are a number of security-focused web sites and mailing lists that you can join to keep up with the ever-changing world of systems security. Some of the better ones are SecurityFocus at www.securityfocus.com/, CERT at www.cert.org/, and SANS at www.sans.org/. Make it a habit to go to their sites on a regular basis to see if any new threats have been discovered, and subscribe to one or more of their alert newsletters to keep informed on the latest happenings.
As stated previously, there is no such thing as bulletproof security. If you have a publicly available server and someone is determined enough, they will crack into it. The trick is to make your server hard enough to crack that someone who is not determined will give it up as a bad job, and move on to a less secured server.
There is a lot more that you can do to secure your server than what has been presented in this chapter. There are many whole books devoted to nothing else but hardening your system. However, if you follow the advice given here and stay on top of your servers, they will probably be “hard enough” to crack that most people will give up and move on, and that’s all you can really hope for.