

Open Access This book is licensed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (http://creativecommons.org/licenses/by-nc-nd/4.0/), which permits any noncommercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if you modified the licensed material. You do not have permission under this license to share adapted material derived from this book or parts of it.
The images or other third party material in this book are included in the book's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the book's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Think Parallel
We have aimed to make this book useful for those who are new to parallel programming as well as those who are expert in parallel programming. We have also made this book approachable for those who are comfortable only with C programming, as well as those who are fluent in C++.
In order to address this diverse audience without “dumbing down” the book, we have written this Preface to level the playing field.
What Is TBB
TBB is a solution for writing parallel programs in C++ which has become the most popular, and extensive, support for parallel programming in C++. It is widely used and very popular for a good reason. More than 10 years old, TBB has stood the test of time and has been influential in the inclusion of parallel programming support in the C++ standard. While C++11 made major additions for parallel programming, and C++17 and C++2x take that ever further, most of what TBB offers is much more than what belongs in a language standard. TBB was introduced in 2006, so it contains support for pre-C++11 compilers. We have simplified matters by taking a modern look at TBB and assuming C++11. Common advice today is “if you don’t have a C++11 compiler, get one.” Compared with the 2007 book on TBB, we think C++11, with lambda support in particular, makes TBB both richer and easier to understand and use.
TBB is simply the best way to write a parallel program in C++, and we hope to help you be very productive in using TBB.
Organization of the Book and Preface
- I.
Preface: Background and fundamentals useful for understanding the remainder of the book. Includes motivations for the TBB parallel programming model, an introduction to parallel programming, an introduction to locality and caches, an introduction to vectorization (SIMD), and an introduction to the features of C++ (beyond those in the C language) which are supported or used by TBB.
- II.
Chapters 1 – 8 : A book on TBB in its own right. Includes an introduction to TBB sufficient to do a great deal of effective parallel programming.
- III.
Chapters 9 – 20 : Include special topics that give a deeper understanding of TBB and parallel programming and deal with nuances in both.
- IV.
Appendices A and B and Glossary: A collection of useful information about TBB that you may find interesting, including history (Appendix A) and a complete reference guide (Appendix B).
Think Parallel
For those new to parallel programming, we offer this Preface to provide a foundation that will make the remainder of the book more useful, approachable, and self-contained. We have attempted to assume only a basic understanding of C programming and introduce the key elements of C++ that TBB relies upon and supports. We introduce parallel programming from a practical standpoint that emphasizes what makes parallel programs most effective. For experienced parallel programmers, we hope this Preface will be a quick read that provides a useful refresher on the key vocabulary and thinking that allow us to make the most of parallel computer hardware.
After reading this Preface, you should be able to explain what it means to “Think Parallel” in terms of decomposition, scaling, correctness, abstraction, and patterns. You will appreciate that locality is a key concern for all parallel programming. You will understand the philosophy of supporting task programming instead of thread programming – a revolutionary development in parallel programming supported by TBB . You will also understand the elements of C++ programming that are needed above and beyond a knowledge of C in order to use TBB well.
- (1)
An explanation of the motivations behind TBB (begins on page xxi)
- (2)
An introduction to parallel programming (begins on page xxvi)
- (3)
An introduction to locality and caches – we call “Locality and the Revenge of the Caches” – the one aspect of hardware that we feel essential to comprehend for top performance with parallel programming (begins on page lii)
- (4)
An introduction to vectorization (SIMD) (begins on page lx)
- (5)
An introduction to the features of C++ (beyond those in the C language) which are supported or used by TBB (begins on page lxii)
Motivations Behind Threading Building Blocks (TBB)
TBB first appeared in 2006. It was the product of experts in parallel programming at Intel, many of whom had decades of experience in parallel programming models, including OpenMP. Many members of the TBB team had previously spent years helping drive OpenMP to the great success it enjoys by developing and supporting OpenMP implementations. Appendix A is dedicated to a deeper dive on the history of TBB and the core concepts that go into it, including the breakthrough concept of task-stealing schedulers.
Born in the early days of multicore processors, TBB quickly emerged as the most popular parallel programming model for C++ programmers. TBB has evolved over its first decade to incorporate a rich set of additions that have made it an obvious choice for parallel programming for novices and experts alike. As an open source project, TBB has enjoyed feedback and contributions from around the world.
TBB promotes a revolutionary idea: parallel programming should enable the programmer to expose opportunities for parallelism without hesitation, and the underlying programming model implementation (TBB) should map that to the hardware at runtime.
Understanding the importance and value of TBB rests on understanding three things: (1) program using tasks, not threads; (2) parallel programming models do not need to be messy; and (3) how to obtain scaling, performance, and performance portability with portable low overhead parallel programming models such as TBB. We will dive into each of these three next because they are so important! It is safe to say that the importance of these were underestimated for a long time before emerging as cornerstones in our understanding of how to achieve effective, and structured, parallel programming.
Program Using Tasks Not Threads
Parallel programming should always be done in terms of tasks , not threads . We cite an authoritative and in-depth examination of this by Edward Lee at the end of this Preface. In 2006, he observed that “For concurrent programming to become mainstream, we must discard threads as a programming model.”
Parallel programming expressed with threads is an exercise in mapping an application to the specific number of parallel execution threads on the machine we happen to run upon. Parallel programming expressed with tasks is an exercise in exposing opportunities for parallelism and allowing a runtime (e.g., TBB runtime) to map tasks onto the hardware at runtime without complicating the logic of our application.
Threads represent an execution stream that executes on a hardware thread for a time slice and may be assigned other hardware threads for a future time slice. Parallel programming in terms of threads fail because they are too often used as a one-to-one correspondence between threads (as in execution threads) and threads (as in hardware threads, e.g., processor cores). A hardware thread is a physical capability, and the number of hardware threads available varies from machine to machine, as do some subtle characteristics of various thread implementations.
In contrast, tasks represent opportunities for parallelism. The ability to subdivide tasks can be exploited, as needed, to fill available threads when needed.
With these definitions in mind, a program written in terms of threads would have to map each algorithm onto specific systems of hardware and software. This is not only a distraction, it causes a whole host of issues that make parallel programming more difficult, less effective, and far less portable.
Whereas, a program written in terms of tasks allows a runtime mechanism, for example, the TBB runtime, to map tasks onto the hardware which is actually present at runtime. This removes the distraction of worrying about the number of actual hardware threads available on a system. More importantly, in practice this is the only method which opens up nested parallelism effectively. This is such an important capability, that we will revisit and emphasize the importance of nested parallelism in several chapters.
Composability: Parallel Programming Does Not Have to Be Messy
TBB offers composability for parallel programming, and that changes everything. Composability means we can mix and match features of TBB without restriction. Most notably, this includes nesting. Therefore, it makes perfect sense to have a parallel_for inside a parallel_for loop. It is also okay for a parallel_for to call a subroutine, which then has a parallel_for within it.
Supporting composable nested parallelism turns out to be highly desirable because it exposes more opportunities for parallelism, and that results in more scalable applications. OpenMP, for instance, is not composable with respect to nesting because each level of nesting can easily cause significant overhead and consumption of resources leading to exhaustion and program termination. This is a huge problem when you consider that a library routine may contain parallel code, so we may experience issues using a non-composable technique if we call the library while already doing parallelism. No such problem exists with TBB, because it is composable. TBB solves this, in part, by letting use expose opportunities for parallelism (tasks) while TBB decides at runtime how to map them to hardware (threads).
This is the key benefit to coding in terms of tasks (available but nonmandatory parallelism (see “relaxed sequential semantics” in Chapter 2 )) instead of threads (mandatory parallelism). If a parallel_for was considered mandatory, nesting would cause an explosion of threads which causes a whole host of resource issues which can easily (and often do) crash programs when not controlled. When parallel_for exposes available nonmandatory parallelism, the runtime is free to use that information to match the capabilities of the machine in the most effective manner.
We have come to expect composability in our programming languages, but most parallel programming models have failed to preserve it (fortunately, TBB does preserve composability!). Consider “ if ” and “ while ” statements. The C and C++ languages allow them to freely mix and nest as we desire. Imagine this was not so, and we lived in a world where a function called from within an if statement was forbidden to contain a while statement! Hopefully, any suggestion of such a restriction seems almost silly. TBB brings this type of composability to parallel programming by allowing parallel constructs to be freely mixed and nested without restrictions, and without causing issues.
Scaling, Performance, and Quest for Performance Portability
Perhaps the most important benefit of programming with TBB is that it helps create a performance portable application. We define performance portability as the characteristic that allows a program to maintain a similar “percentage of peak performance” across a variety of machines (different hardware, different operating systems, or both). We would like to achieve a high percentage of peak performance on many different machines without the need to change our code.
We would also like to see a 16× gain in performance on a 64-core machine vs. a quad-core machine. For a variety of reasons, we will almost never see ideal speedup (never say never: sometimes, due to an increase in aggregate cache size we can see more than ideal speedup – a condition we call superlinear speedup).
What Is Speedup?
Speedup is formerly defined to be the time to run sequentially (not in parallel) divided by the time to run in parallel. If my program runs in 3 seconds normally, but in only 1 second on a quad-core processor, we would say it has a speedup of 3×. Sometimes, we might speak of efficiency which is speedup divided by the number of processing cores. Our 3× would be 75% efficient at using the parallelism.
The ideal goal of a 16× gain in performance when moving from a quad-core machine to one with 64 cores is called linear scaling or perfect scaling .
To accomplish this, we need to keep all the cores busy as we grow their numbers – something that requires considerable available parallelism. We will dive more into this concept of “available parallelism” starting on page xxxvii when we discuss Amdahl’s Law and its implications.
For now, it is important to know that TBB supports high-performance programming and helps significantly with performance portability. The high-performance support comes because TBB introduces essentially no overhead which allows scaling to proceed without issue. Performance portability lets our application harness available parallelism as new machines offer more.
In our confident claims here, we are assuming a world where the slight additional overhead of dynamic task scheduling is the most effective at exposing the parallelism and exploiting it. This assumption has one fault: if we can program an application to perfectly match the hardware, without any dynamic adjustments, we may find a few percentage points gain in performance. Traditional High-Performance Computing (HPC) programming, the name given to programming the world’s largest computers for intense computations, has long had this characteristic in highly parallel scientific computations. HPC developer who utilize OpenMP with static scheduling, and find it does well with their performance, may find the dynamic nature of TBB to be a slight reduction in performance. Any advantage previously seen from such static scheduling is becoming rarer for a variety of reasons. All programming including HPC programming, is increasing in complexity in a way that demands support for nested and dynamic parallelism support. We see this in all aspects of HPC programming as well, including growth to multiphysics models, introduction of AI (artificial intelligence), and use of ML (machine learning) methods. One key driver of additional complexity is the increasing diversity of hardware, leading to heterogeneous compute capabilities within a single machine. TBB gives us powerful options for dealing with these complexities, including its flow graph features which we will dive into in Chapter 3 .
It is clear that effective parallel programming requires a separation between exposing parallelism in the form of tasks (programmer’s responsibility) and mapping tasks to hardware threads (programming model implementation’s responsibility).
Introduction to Parallel Programming
Before we dive into demystifying the terminology and key concepts behind parallel programming, we will make a bold claim: parallel is more intuitive than sequential. Parallelism is around us every day in our lives, and being able to do a single thing step by step is a luxury we seldom enjoy or expect. Parallelism is not unknown to us and should not be unknown in our programming.
Parallelism Is All Around Us
Long lines: When you have to wait in a long line, you have undoubtedly wished there were multiple shorter (faster) lines, or multiple people at the front of the line helping serve customers more quickly. Grocery store check-out lines, lines to get train tickets, and lines to buy coffee are all examples.
Lots of repetitive work: When you have a big task to do, which many people could help with at the same time, you have undoubtedly wished for more people to help you. Moving all your possessions from an old dwelling to a new one, stuffing letters in envelopes for a mass mailing, and installing the same software on each new computer in your lab are examples. The proverb “ Many hands make light work ” holds true for computers too.
Once you dig in and start using parallelism, you will Think Parallel. You will learn to think first about the parallelism in your project, and only then think about coding it.
Yale Pat, famous computer architect, observed:
A Conventional Wisdom Problem is the belief that
Thinking in Parallel is Hard
Perhaps (All) Thinking is Hard!
How do we get people to believe that:
Thinking in parallel is natural
(we could not agree more!)
Concurrent vs. Parallel
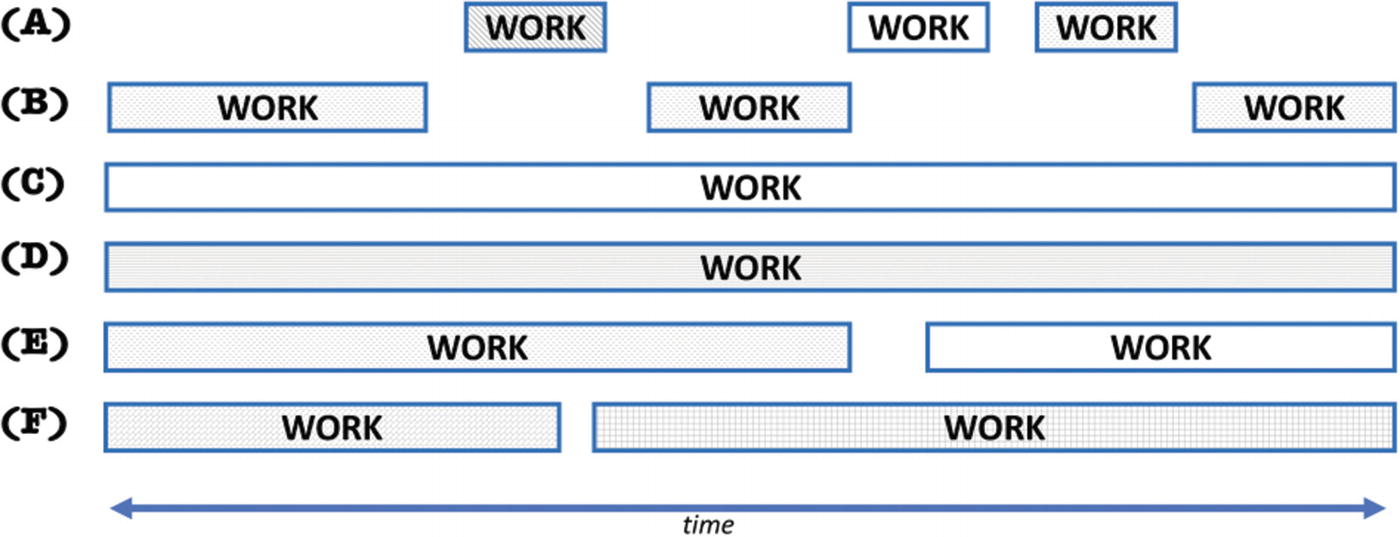
Parallel vs. Concurrent: Tasks (A) and (B) are concurrent relative to each other but not parallel relative to each other; all other combinations are both concurrent and parallel
Enemies of parallelism: locks, shared mutable state, synchronization, not “Thinking Parallel,” and forgetting that algorithms win.
Enemies of Parallelism
Locks: In parallel programming, locks or mutual exclusion objects (mutexes) are used to provide a thread with exclusive access to a resource – blocking other threads from simultaneously accessing the same resource. Locks are the most common explicit way to ensure parallel tasks update shared data in a coordinated fashion (as opposed to allowing pure chaos). We hate locks because they serialize part of our programs, limiting scaling. The sentiment “we hate locks” is on our minds throughout the book. We hope to instill this mantra in you as well, without losing sight of when we must synchronize properly. Hence, a word of caution: we actually do love locks when they are needed, because without them disaster will strike. This love/hate relationship with locks needs to be understood.
Shared mutable state: Mutable is another word for “can be changed.” Shared mutable state happens any time we share data among multiple threads, and we allow it to change while being shared. Such sharing either reduces scaling when synchronization is needed and used correctly, or it leads to correctness issues (race conditions or deadlocks) when synchronization (e.g., a lock) is incorrectly applied. Realistically, we need shared mutable state when we write interesting applications. Thinking about careful handling of shared mutable state may be an easier way to understand the basis of our love/hate relationship with locks. In the end, we all end up “managing” shared mutable state and the mutual exclusion (including locks) to make it work as we wish.
Not “Thinking Parallel”: Use of clever bandages and patches will not make up for a poorly thought out strategy for scalable algorithms. Knowing where the parallelism is available, and how it can be exploited, should be considered before implementation. Trying to add parallelism to an application, after it is written, is fraught with peril. Some preexisting code may shift to use parallelism relatively well, but most code will benefit from considerable rethinking of algorithms.
Forgetting that algorithms win: This may just be another way to say “Think Parallel.” The choice of algorithms has a profound effect on the scalability of applications. Our choice of algorithms determine how tasks can divide, data structures are accessed, and results are coalesced. The optimal algorithm is really the one which serves as the basis for optimal solution. An optimal solution is a combination of the appropriate algorithm, with the best matching parallel data structure, and the best way to schedule the computation over the data. The search for, and discovery of, algorithms which are better is seemingly unending for all of us as programmers. Now, as parallel programmers, we must add scalable to the definition of better for an algorithm.
Locks, can’t live with them, can’t live without them.
Terminology of Parallelism
The vocabulary of parallel programming is something we need to learn in order to converse with other parallel programmers. None of the concepts are particularly hard, but they are very important to internalize. A parallel programmer, like any programmer, spends years gaining a deep intuitive feel for their craft, despite the fundamentals being simple enough to explain.
We will discuss decomposition of work into parallel tasks, scaling terminology, correctness considerations, and the importance of locality due primarily to cache effects.
When we think about our application, how do we find the parallelism?
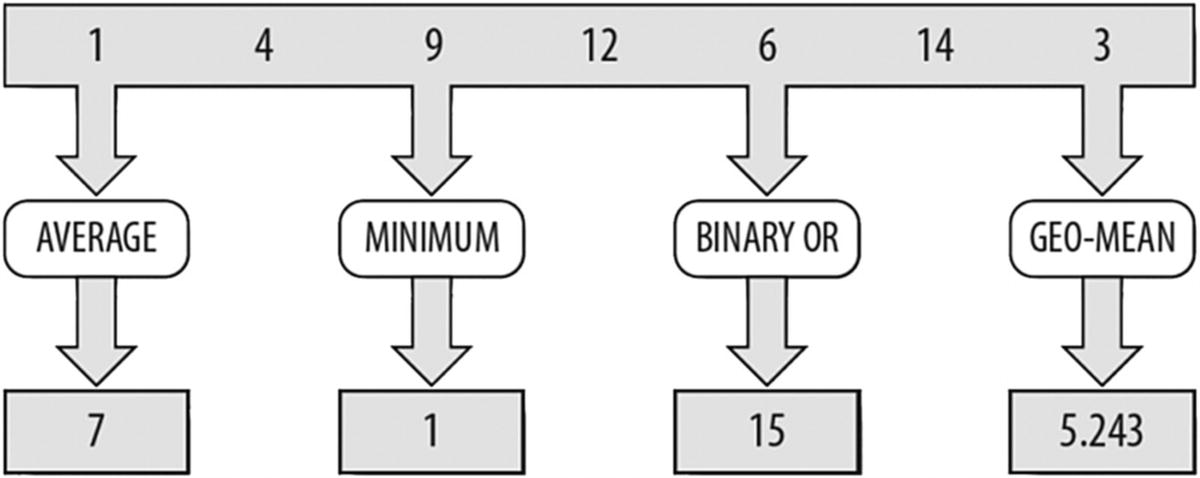
Task parallelism
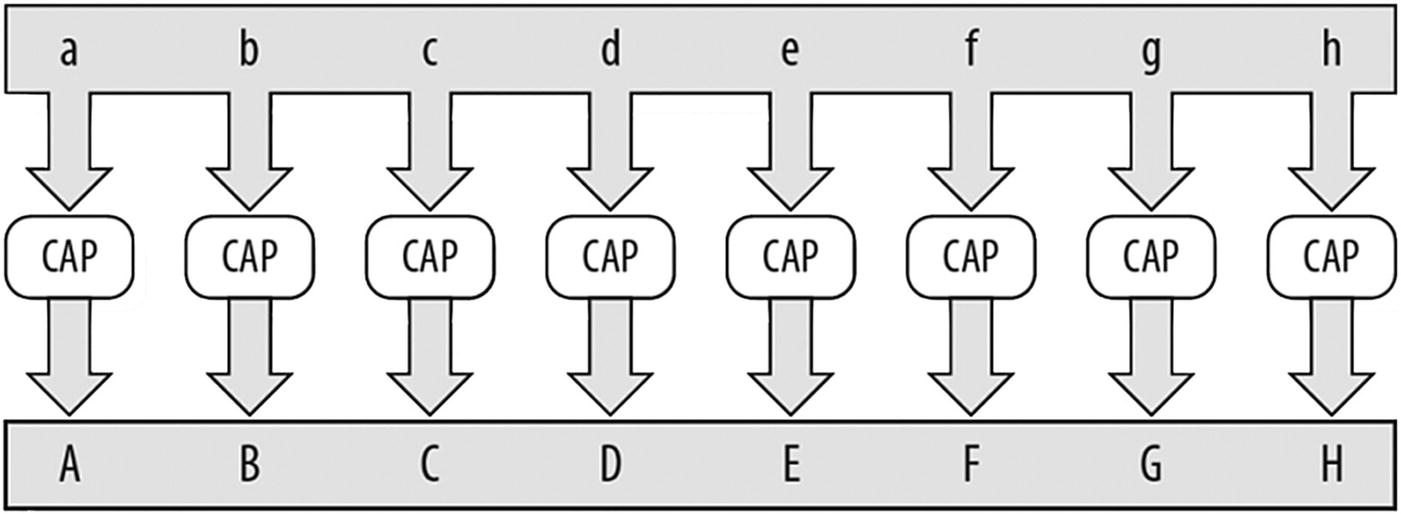
Data parallelism
Terminology: Task Parallelism
Task parallelism refers to different, independent tasks. Figure P-2 illustrates this, showing an example of mathematical operations that can each be applied to the same data set to compute values that are independent. In this case, the average value, the minimum value, the binary OR function, and the geometric mean of the data set are computed. Finding work to do in parallel in terms of task parallelism becomes limited by the number of independent operations we can envision.
Earlier in this Preface, we have been advocating using tasks instead of threads. As we now discuss data vs. task parallelism, it may seem a bit confusing because we use the word task again in a different context when we compare task parallelism vs. data parallelism . For either type of parallelism, we will program for either in terms of tasks and not threads . This is the vocabulary used by parallel programmers.
Terminology: Data Parallelism
Data parallelism (Figure P-3 ) is easy to picture: take lots of data and apply the same transformation to each piece of the data. In Figure P-3 , each letter in the data set is capitalized and becomes the corresponding uppercase letter. This simple example shows that given a data set and an operation that can be applied element by element, we can apply the same task in parallel to each element. Programmers writing code for supercomputers love this sort of problem and consider it so easy to do in parallel that it has been called embarrassingly parallel . A word of advice: if you have lots of data parallelism, do not be embarrassed – take advantage of it and be very happy. Consider it happy parallelism .

Pipeline

Imagine that each position is a different car in different stages of assembly, this is a pipeline in action with data flowing through it
Terminology: Pipelining
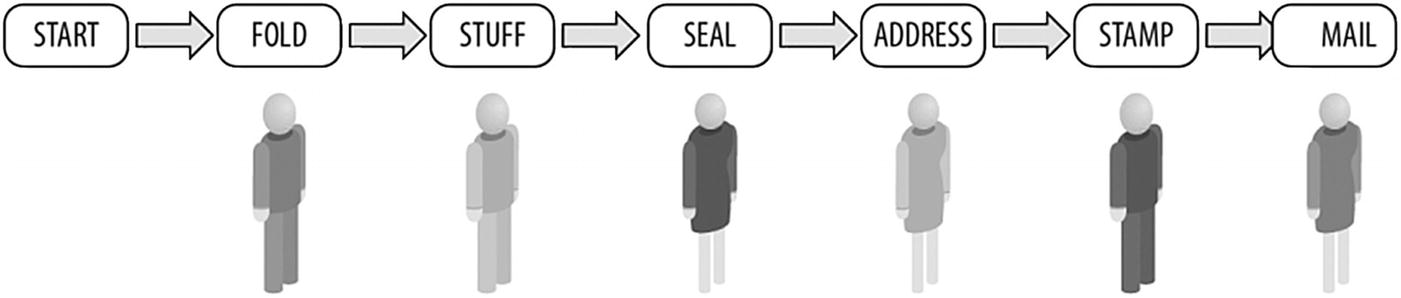
Pipelining – each person has a different job
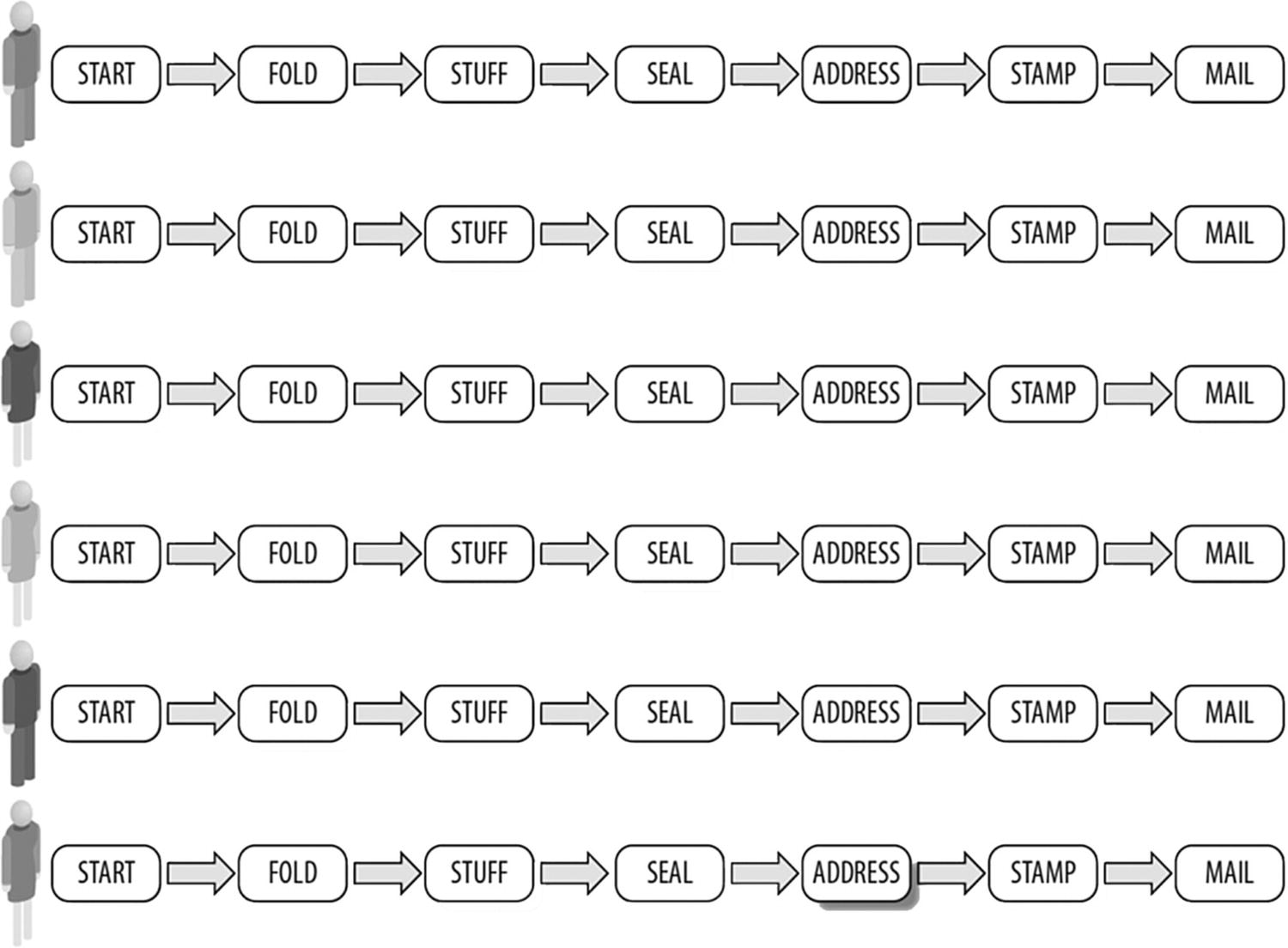
Data Parallelism – each person has the same job
Example of Exploiting Mixed Parallelism
Consider the task of folding, stuffing, sealing, addressing, stamping, and mailing letters. If we assemble a group of six people for the task of stuffing many envelopes, we can arrange each person to specialize in and perform their assigned task in a pipeline fashion (Figure P-6 ). This contrasts with data parallelism, where we divide up the supplies and give a batch of everything to each person (Figure P-7 ). Each person then does all the steps on their collection of materials.
Figure P-7 is clearly the right choice if every person has to work in a different location far from each other. That is called coarse-grained parallelism because the interactions between the tasks are infrequent (they only come together to collect envelopes, then leave and do their task, including mailing). The other choice shown in Figure P-6 approximates what we call fine-grained parallelism because of the frequent interactions (every envelope is passed along to every worker in various steps of the operation).
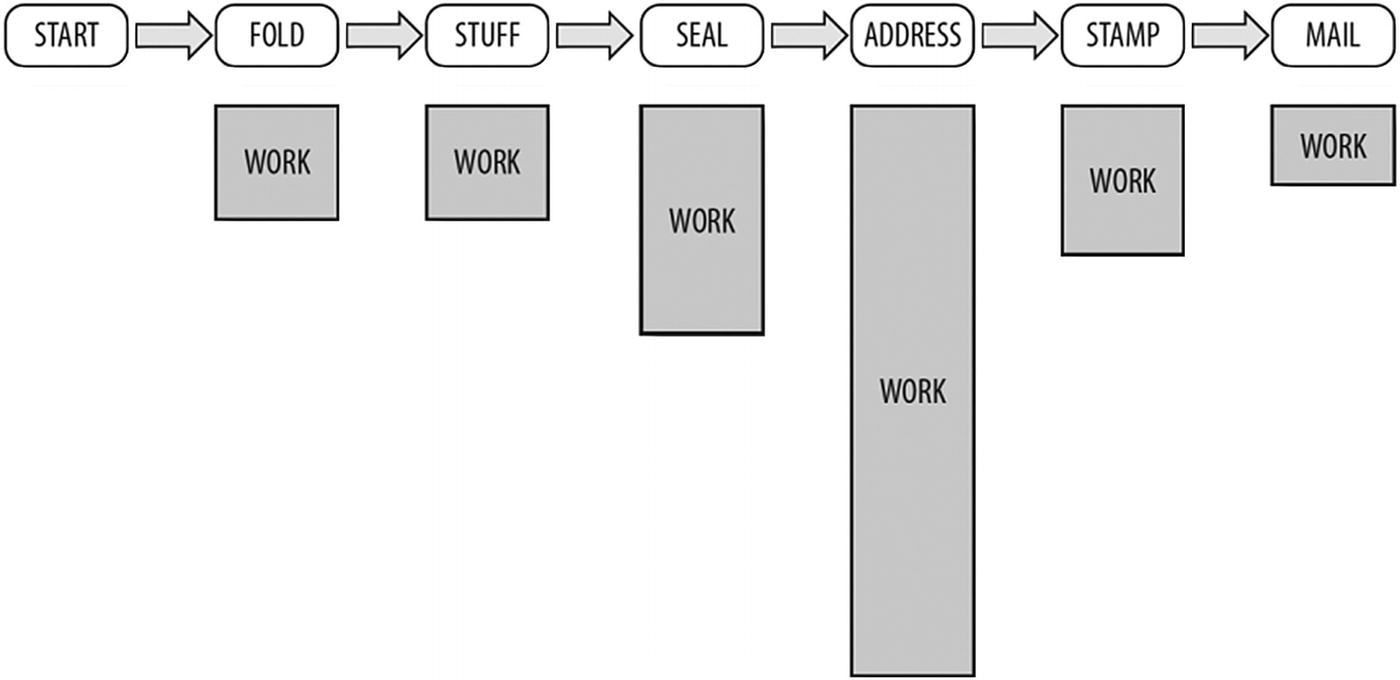
Unequal tasks are best combined or split to match people
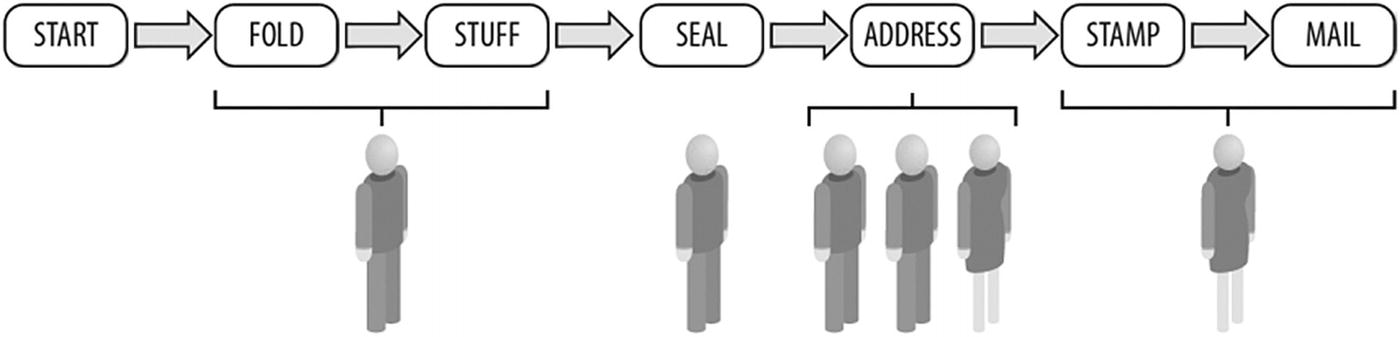
Because tasks are not equal, assign more people to addressing letters
Achieving Parallelism
- 1.
Assign people to tasks (and feel free to move them around to balance the workload).
- 2.
Start with one person on each of the six tasks but be willing to split up a given task so that two or more people can work on it together.
The six tasks are folding, stuffing, sealing, addressing, stamping, and mailing. We also have six people (resources) to help with the work. That is exactly how TBB works best: we define tasks and data at a level we can explain and then split or combine data to match up with resources available to do the work.
The first step in writing a parallel program is to consider where the parallelism is. Many textbooks wrestle with task and data parallelism as though there were a clear choice. TBB allows any combination of the two that we express.
Far from decrying chaos – we love the chaos of lots of uncoordinated tasks running around getting work done without having to check-in with each other (synchronization). This so-called “loosely coupled” parallel programming is great! More than locks, we hate synchronization because it makes tasks wait for other tasks. Tasks exist to work – not sit around waiting!
If we are lucky, our program will have an abundant amount of data parallelism available for us to exploit. To simplify this work, TBB requires only that we specify tasks and how to split them. For a completely data-parallel task, in TBB we will define one task to which we give all the data. That task will then be split up automatically to use the available hardware parallelism. The implicit synchronization (as opposed to synchronization we directly ask for with coding) will often eliminate the need for using locks to achieve synchronization. Referring back to our enemies list, and the fact that we hate locks, the implicit synchronization is a good thing. What do we mean by “implicit” synchronization? Usually, all we are saying is that synchronization occurred but we did not explicitly code a synchronization. At first, this should seem like a “cheat.” After all, synchronization still happened – and someone had to ask for it! In a sense, we are counting on these implicit synchronizations being more carefully planned and implemented. The more we can use the standard methods of TBB, and the less we explicitly write our own locking code, the better off we will be – in general.
By letting TBB manage the work, we hand over the responsibility for splitting up the work and synchronizing when needed. The synchronization done by the library for us, which we call implicit synchronization, in turn often eliminates the need for an explicit coding for synchronization (see Chapter 5 ).
We strongly suggest starting there, and only venturing into explicit synchronization (Chapter 5 ) when absolutely necessary or beneficial. We can say, from experience, even when such things seem to be necessary – they are not. You’ve been warned. If you are like us, you’ll ignore the warning occasionally and get burned. We have.
People have been exploring decomposition for decades, and some patterns have emerged. We’ll cover this more later when we discuss design patterns for parallel programming.
Effective parallel programming is really about keeping all our tasks busy getting useful work done all the time – and hunting down and eliminating idle time is a key to our goal: scaling to achieve great speedups.
Terminology: Scaling and Speedup
The scalability of a program is a measure of how much speedup the program gets as we add more computing capabilities. Speedup is the ratio of the time it takes to run a program without parallelism vs. the time it takes to run in parallel. A speedup of 4× indicates that the parallel program runs in a quarter of the time of the serial program. An example would be a serial program that takes 100 seconds to run on a one-processor machine and 25 seconds to run on a quad-core machine.
As a goal, we would expect that our program running on two processor cores should run faster than our program running on one processor core. Likewise, running on four processor cores should be faster than running on two cores.
Any program will have a point of diminishing returns for adding parallelism. It is not uncommon for performance to even drop, instead of simply leveling off, if we force the use of too many compute resources. The granularity at which we should stop subdividing a problem can be expressed as a grain size . TBB uses a notion of grain size to help limit the splitting of data to a reasonable level to avoid this problem of dropping in performance. Grain size is generally determined automatically, by an automatic partitioner within TBB, using a combination of heuristics for an initial guess and dynamic refinements as execution progresses. However, it is possible to explicitly manipulate the grain size settings if we want to do so. We will not encourage this in this book, because we seldom will do better in performance with explicit specifications than the automatic partitioner in TBB, it tends to be somewhat machine specific, and therefore explicitly setting grain size reduces performance portability.
As Thinking Parallel becomes intuitive, structuring problems to scale will become second nature.
How Much Parallelism Is There in an Application?
The topic of how much parallelism there is in an application has gotten considerable debate, and the answer is “it depends.”
Original program without parallelism
Progress on adding parallelism
Amdahl’s Law
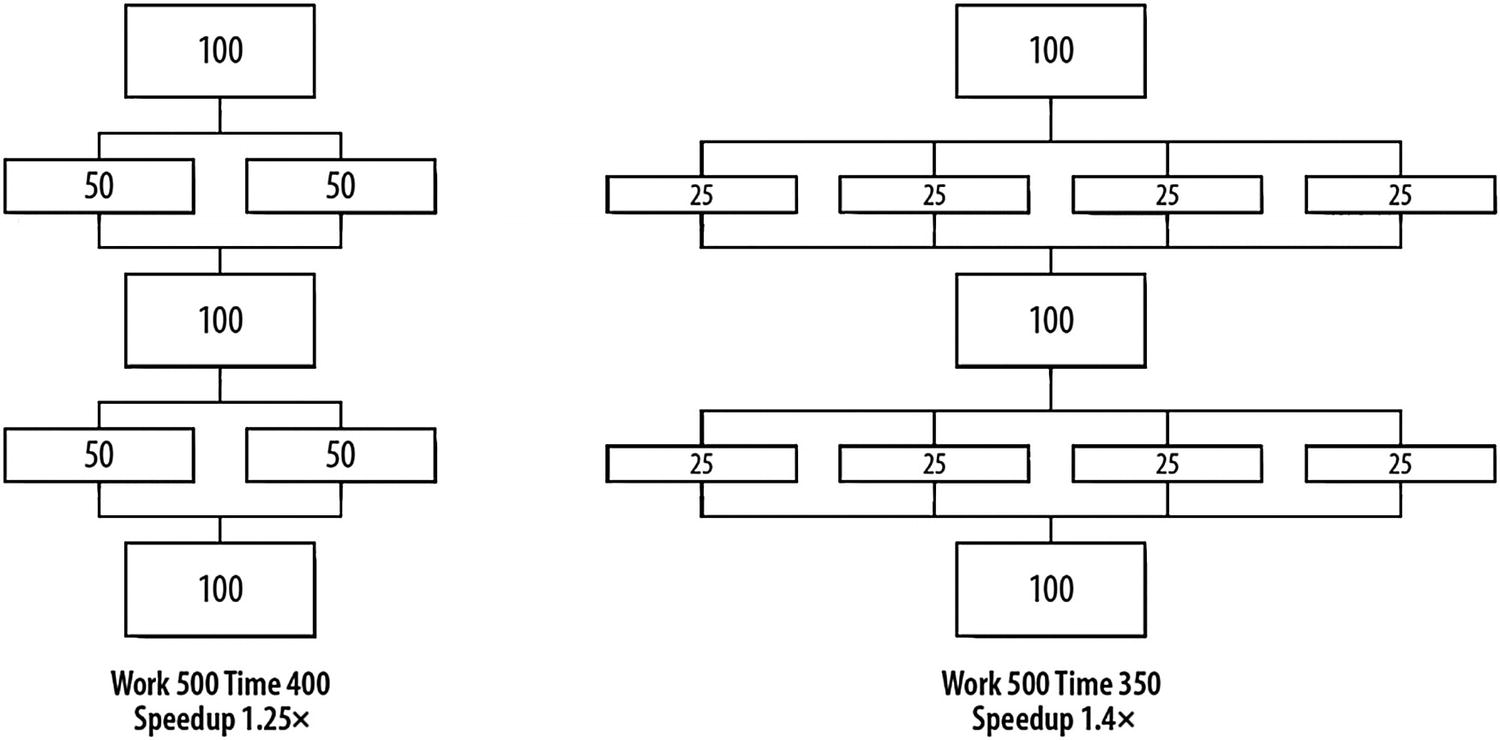
Renowned computer architect, Gene Amdahl, made observations regarding the maximum improvement to a computer system that can be expected when only a portion of the system is improved. His observations in 1967 have come to be known as Amdahl’s Law. It tells us that if we speed up everything in a program by 2×, we can expect the resulting program to run 2× faster. However, if we improve the performance of only 2/5th of the program by 2×, the overall system improves only by 1.25×.
Limits according to Amdahl’s Law
Parallel programmers have long used Amdahl’s Law to predict the maximum speedup that can be expected using multiple processors. This interpretation ultimately tells us that a computer program will never go faster than the sum of the parts that do not run in parallel (the serial portions), no matter how many processors we have.
Scale the workload with the capabilities
Gustafson’s Observations Regarding Amdahl’s Law
Amdahl’s Law views programs as fixed, while we make changes to the computer. But experience seems to indicate that as computers get new capabilities, applications change to take advantage of these features. Most of today’s applications would not run on computers from 10 years ago, and many would run poorly on machines that are just 5 years old. This observation is not limited to obvious applications such as video games; it applies also to office applications, web browsers, photography, and video editing software.
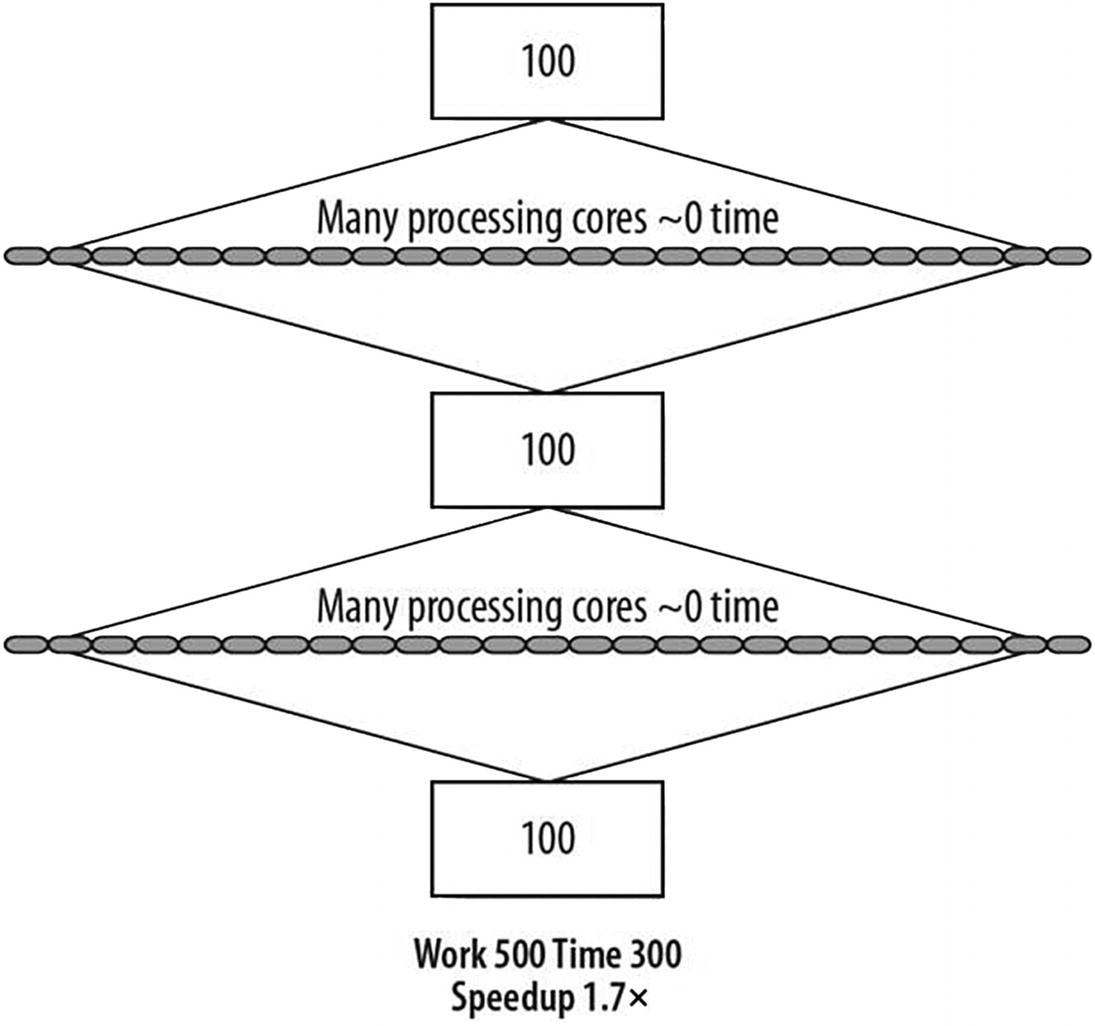
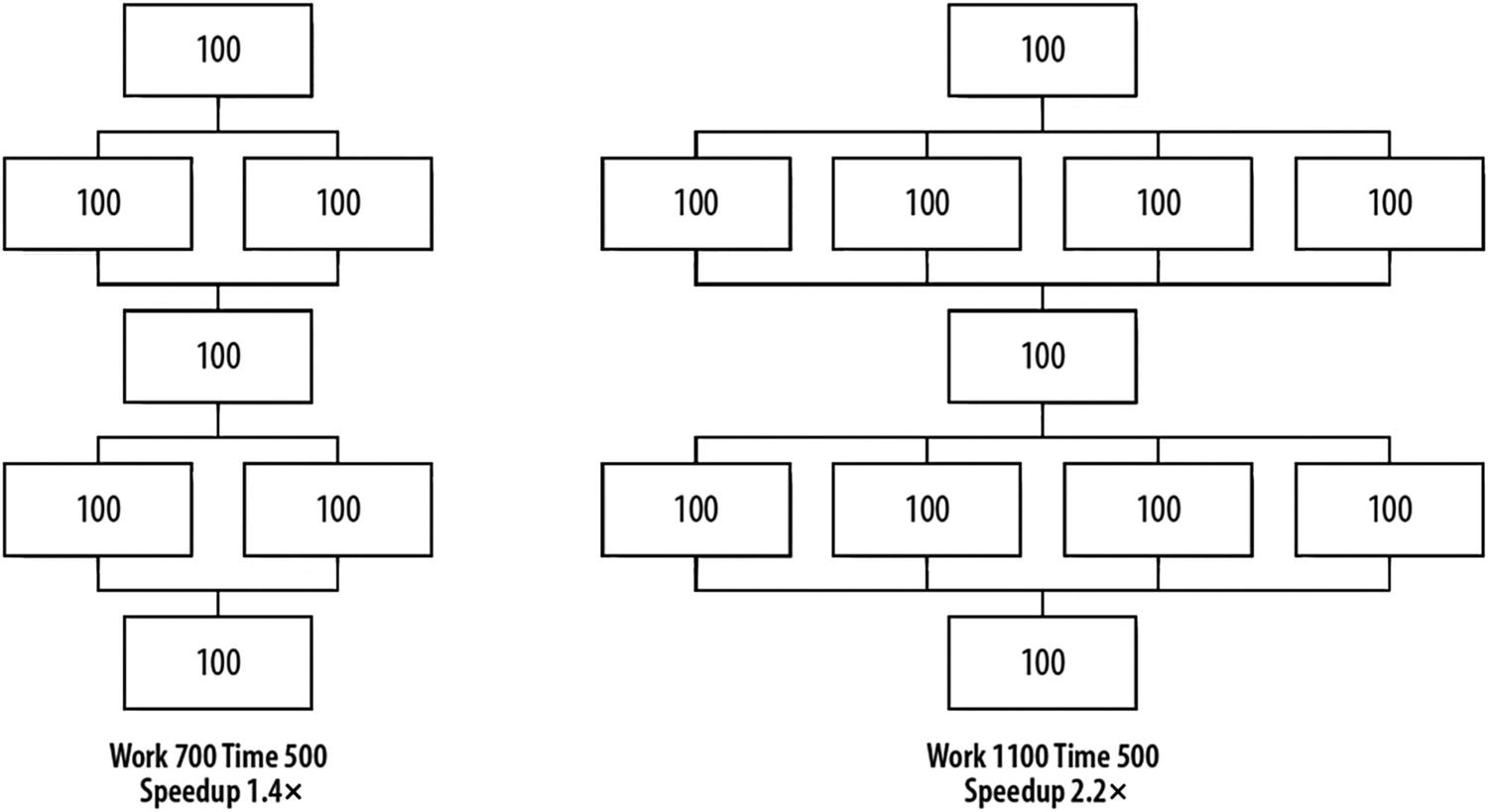
More than two decades after the appearance of Amdahl’s Law, John Gustafson, while at Sandia National Labs, took a different approach and suggested a reevaluation of Amdahl’s Law. Gustafson noted that parallelism is more useful when we observe that workloads grow over time. This means that as computers have become more powerful, we have asked them to do more work, rather than staying focused on an unchanging workload. For many problems, as the problem size grows, the work required for the parallel part of the problem grows faster than the part that cannot be parallelized (the serial part). Hence, as the problem size grows, the serial fraction decreases, and, according to Amdahl’s Law, the scalability improves. We can start with an application that looks like Figure P-10 , but if the problem scales with the available parallelism, we are likely to see the advancements illustrated in Figure P-13 . If the sequential parts still take the same amount of time to perform, they become less and less important as a percentage of the whole. The algorithm eventually reaches the conclusion shown in Figure P-14 . Performance grows at the same rate as the number of processors, which is called linear or order of n scaling, denoted as O(n).
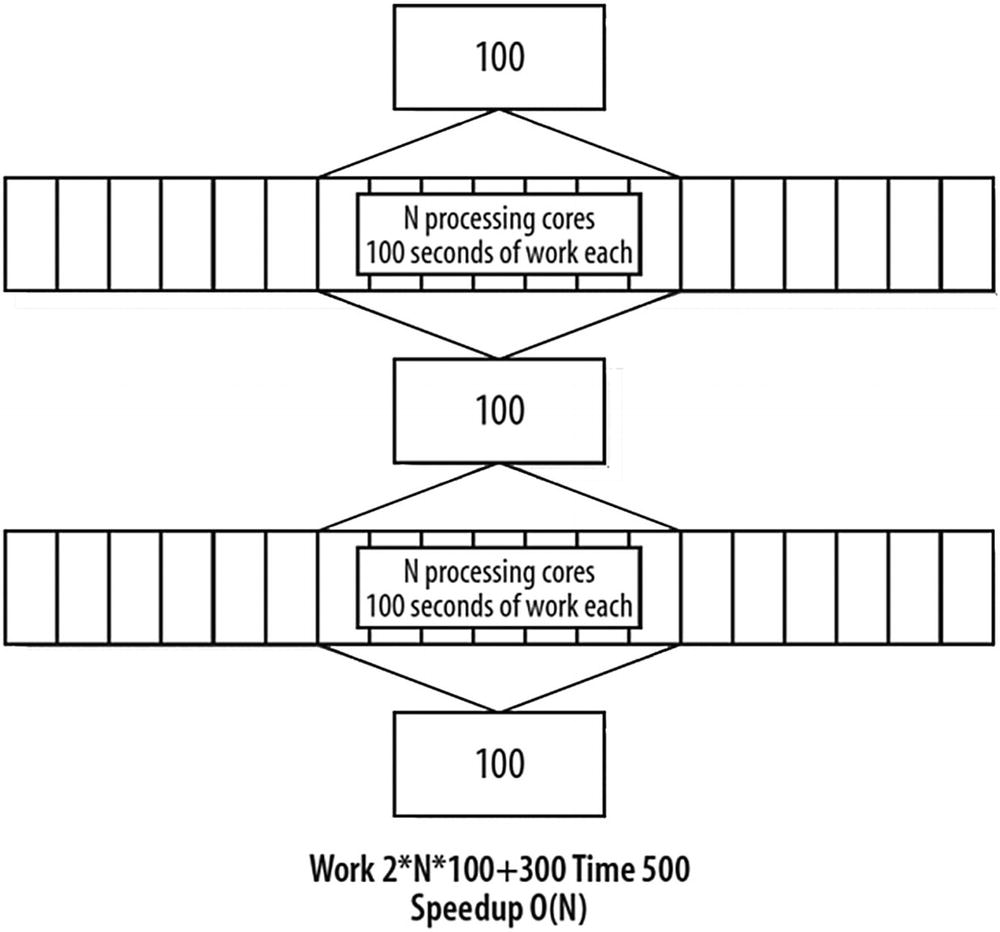
Gustafson saw a path to scaling
Both Amdahl’s Law and Gustafson’s observations are correct, and they are not at odds. They highlight a different way to look at the same phenomenon. Amdahl’s Law cautions us that if we simply want an existing program to run faster with the same workload, we will be severely limited by our serial code. When we envision working on a larger workload, Gustafson has pointed out we have hope. History clearly favors programs getting more complex and solving larger problems, and this is when parallel programming pays off.
The value of parallelism is easier to prove if we are looking forward than if we assume the world is not changing.
Making today’s application run faster by switching to a parallel algorithm without expanding the problem is harder than making it run faster on a larger problem. The value of parallelism is easier to prove when we are not constrained to speeding up an application that already works well on today’s machines.
Some have defined scaling that requires the problem size to grow as weak scaling . It is ironic that the term embarrassingly parallel is commonly applied to other types of scaling, or strong scaling . Because almost all true scaling happens only when the problem size scales with the parallelism available, we should just call that scaling . Nevertheless, it is common to apply the term embarrassing scaling or strong scaling to scaling that occurs without growth in the problem size and refer to scaling that depends on expanding data sizes as weak scaling . As with embarrassing parallelism, when we have embarrassing scaling, we gladly take advantage of it and we are not embarrassed. We generally expect scaling to be the so-called weak scaling , and we are happy to know that any scaling is good and we will simply say that our algorithms scale in such cases.
The scalability of an application comes down to increasing the work done in parallel and minimizing the work done serially. Amdahl motivates us to reduce the serial portion, whereas Gustafson tells us to consider larger problems.
What Did They Really Say?
…the effort expended on achieving high parallel processing rates is wasted unless it is accompanied by achievements in sequential processing rates of very nearly the same magnitude.
—Amdahl, 1967
…speedup should be measured by scaling the problem to the number of processors, not by fixing the problem size.
—Gustafson, 1988
Serial vs. Parallel Algorithms
One of the truths in programming is this: the best serial algorithm is seldom the best parallel algorithm, and the best parallel algorithm is seldom the best serial algorithm.
This means that trying to write a program that runs well on a system with one processor core, and also runs well on a system with a dual-core processor or quad-core processor, is harder than just writing a good serial program or a good parallel program.
Supercomputer programmers know from practice that the work required grows quickly as a function of the problem size. If the work grows faster than the sequential overhead (e.g., communication, synchronization), we can fix a program that scales poorly just by increasing the problem size. It’s not uncommon at all to take a program that won’t scale much beyond 100 processors and scale it nicely to 300 or more processors just by doubling the size of the problem.
Strong scaling means we can solve the same problem faster on a parallel system. Weak scaling means we can solve more interesting problems using multiple cores in the same amount of time that we solved the less interesting problems using a single core.
To be ready for the future, write parallel programs and abandon the past. That’s the simplest and best advice to offer. Writing code with one foot in the world of efficient single-threaded performance and the other foot in the world of parallelism is the hardest job of all.
One of the truths in programming is this: the best serial algorithm is seldom the best parallel algorithm, and the best parallel algorithm is seldom the best serial algorithm.
What Is a Thread?
If you know what a thread is, feel free to skip ahead to the section “Safety in the Presence of Concurrency.” It’s important to be comfortable with the concept of a thread, even though the goal of TBB is to abstract away thread management. Fundamentally, we will still be constructing a threaded program, and we will need to understand the implications of this underlying implementation.
All modern operating systems are multitasking operating systems that typically use a preemptive scheduler. Multitasking means that more than one program can be active at a time. We may take it for granted that we can have an e-mail program and a web browser program running at the same time. Yet, not that long ago, this was not the case.
A preemptive scheduler means the operating system puts a limit on how long one program can use a processor core before it is forced to let another program use it. This is how the operating system makes it appear that our e-mail program and our web browser are running at the same time when only one processor core is actually doing the work.
Generally, each program runs relatively independent of other programs. In particular, the memory where our program variables will reside is completely separate from the memory used by other processes. Our e-mail program cannot directly assign a new value to a variable in the web browser program. If our e-mail program can communicate with our web browser – for instance, to have it open a web page from a link we received in e-mail – it does so with some form of communication that takes much more time than a memory access.
This isolation of programs from each other has value and is a mainstay of computing today. Within a program, we can allow multiple threads of execution to exist in a single program. An operating system will refer to the program as a process , and the threads of execution as (operating system) threads .
All modern operating systems support the subdivision of processes into multiple threads of execution. Threads run independently, like processes, and no thread knows what other threads are running or where they are in the program unless they synchronize explicitly. The key difference between threads and processes is that the threads within a process share all the data of the process. Thus, a simple memory access can set a variable in another thread. We will refer to this as “shared mutable state” (changeable memory locations that are shared) – and we will decry the pain that sharing can cause in this book. Managing the sharing of data, is a multifaceted problem that we included in our list of enemies of parallel programming. We will revisit this challenge, and solutions, repeatedly in this book.
We will note, that it is common to have shared mutable state between processes. It could be memory that each thread maps into their memory space explicitly, or it could be data in an external store such as a database. A common example would be airline reservation systems, which can independently work with different customers to book their reservations – but ultimately, they share a database of flights and available seats. Therefore, you should know that many of the concepts we discuss for a single process can easily come up in more complex situations. Learning to think parallel has benefits beyond TBB! Nevertheless, TBB is almost always used within a single process with multiple threads, with only some flow graphs (Chapter 3 ) having some implications beyond a single process.
Each thread has its own instruction pointer (a register pointing to the place in the program where it is running) and stack (a region of memory that holds subroutine return addresses and local variables for subroutines), but otherwise a thread shares its memory with all of the other threads in the same process. Even the stack memory of each thread is accessible to the other threads, though when they are programmed properly, they don’t step on each other’s stacks.
Threads within a process that run independently but share memory have the obvious benefit of being able to share work quickly, because each thread has access to the same memory as the other threads in the same process. The operating system can view multiple threads as multiple processes that have essentially the same permissions to regions of memory. As we mentioned, this is both a blessing and a curse – this “shared mutable state.”
Programming Threads
A process usually starts with a single thread of execution and is allowed to request that more threads be started. Threads can be used to logically decompose a program into multiple tasks, such as a user interface and a main program. Threads are also useful for programming for parallelism, such as with multicore processors.
Many questions arise when we start programming to use threads. How should we divide and assign tasks to keep each available processor core busy? Should we create a thread each time we have a new task, or should we create and manage a pool of threads? Should the number of threads depend on the number of cores? What should we do with a thread running out of tasks?
These are important questions for the implementation of multitasking, but that doesn’t mean we should answer them. They detract from the objective of expressing the goals of our program. Likewise, assembly language programmers once had to worry about memory alignment, memory layout, stack pointers, and register assignments. Languages such as Fortran and C were created to abstract away those important details and leave them to be solved by compilers and libraries. Similarly, today we seek to abstract away thread management so that programmers can express parallelism directly.
TBB allows programmers to express parallelism at a higher level of abstraction. When used properly, TBB code is implicitly parallel.
A key notion of TBB is that we should break up the program into many more tasks than there are processors. We should specify as much parallelism as practical and let TBB runtime choose how much of that parallelism is actually exploited.
What Is SIMD?
Threading is not the only way for a processor to do more than one thing at a time! A single instruction can do the same operation on multiple data items. Such instructions are often called vector instructions, and their use is called vectorization of code (or vectorization for short). The technique is often referred to as Single Instruction Multiple Data (SIMD). The use of vector instructions to do multiple things at once is an important topic which we will discuss later in this Preface (starting on page lxi).
Safety in the Presence of Concurrency
When code is written in such a way that runs may have problems due to the concurrency, it is said not to be thread-safe. Even with the abstraction that TBB offers, the concept of thread safety is essential. Thread-safe code is code that is written in a manner to ensures it will function as desired even when multiple threads use the same code. Common mistakes that make code not thread-safe include lack of synchronization to control access to shared data during updates (this can lead to corruption) and improper use of synchronization (can lead to deadlock, which we discuss in a few pages).
Any function that maintains a persistent state between invocations requires careful writing to ensure it is thread-safe. We need only to do this to functions that might be used concurrently. In general, functions we may use concurrently should be written to have no side effects so that concurrent use is not an issue. In cases where global side effects are truly needed, such as setting a single variable or creating a file, we must be careful to call for mutual exclusion to ensure only one thread at a time can execute the code that has the side effect.
We need to be sure to use thread-safe libraries for any code using concurrency or parallelism. All the libraries we use should be reviewed to make sure they are thread-safe. The C++ library has some functions inherited from C that are particular problems because they hold internal state between calls, specifically asctime , ctime , gmtime , localtime , rand , and strtok . We need to check the documentation when using these functions to see whether thread-safe versions are available. The C++ Standard Template Library (STL) container classes are, in general, not thread-safe (see Chapter 6 for some current container solutions from TBB for this problem, or Chapter 5 for synchronization to use in conjunction with items that are otherwise not thread-safe).
Mutual Exclusion and Locks
We need to think about whether concurrent accesses to the same resources will occur in our program. The resource we will most often be concerned with is data held in memory, but we also need to think about files and I/O of all kinds.
If the precise order that updates of shared data matters, then we need some form of synchronization. The best policy is to decompose our problem in such a way that synchronization is infrequent. We can achieve this by breaking up the tasks so that they can work independently, and the only synchronization that occurs is waiting for all the tasks to be completed at the end. This synchronization “when all tasks are complete” is commonly called a barrier synchronization. Barriers work when we have very coarse-grained parallelism because barriers cause all parallel work to stop (go serial) for a moment. If we do that too often, we lose scalability very quickly per Amdahl’s Law.
For finer-grained parallelism, we need to use synchronization around data structures, to restrict both reading and writing by others, while we are writing. If we are updating memory based on a prior value from memory, such as incrementing a counter by ten, we would restrict reading and writing from the time that we start reading the initial value until we have finished writing the newly computed value. We illustrate a simple way to do this in Figure P-15 . If we are only reading, but we read multiple related data, we would use synchronization around data structures to restrict writing while we read. These restrictions apply to other tasks and are known as mutual exclusion . The purpose of mutual exclusion is to make a set of operations appear atomic (indivisible).
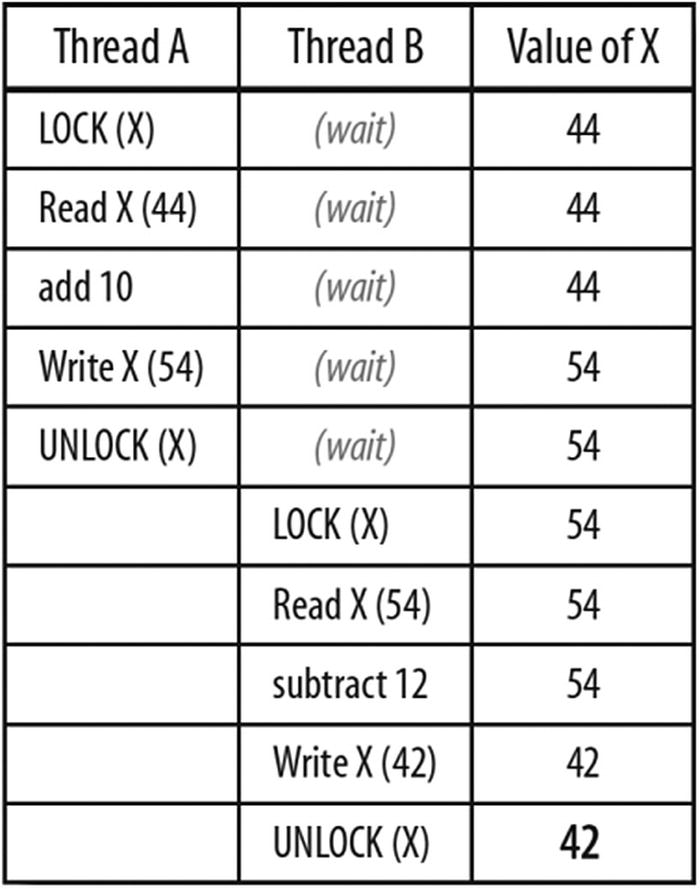
Serialization that can occur when using mutual exclusion
Consider a program with two threads that starts with X = 44 . Thread A executes X = X + 10 . Thread B executes X = X – 12 . If we add locking (Figure P-15 ) so that only Thread A or Thread B can execute its statement at a time, we always end up with X = 42 . If both threads try to obtain a lock at the same time, one will be excluded and will have to wait before the lock is granted. Figure P-15 shows how long Thread B might have to wait if it requested the lock at the same time as Thread A but did not get the lock because Thread A held it first.

Race conditions can lead to problems when we have no mutual exclusion. A simple fix here would be to replace each Read-operation-Write with the appropriate atomic operation (atomic increment or atomic decrement).
As much as we hate locks, we need to concede that without them, things are even worse. Consider our example without the locks, a race condition exists and at least two more results are possible: X=32 or X=54 (Figure P-16 ). We will define this very important concept of race condition very soon starting on page l. The additional incorrect results are now possible because each statement reads X , does a computation, and writes to X . Without locking, there is no guarantee that a thread reads the value of X before or after the other thread writes a value.
Correctness
The biggest challenge of learning to Think Parallel is understanding correctness as it relates to concurrency. Concurrency means we have multiple threads of control that may be active at one time. The operating system is free to schedule those threads in different ways. Each time the program runs, the precise order of operations will potentially be different. Our challenge as a programmer is to make sure that every legitimate way the operations in our concurrent program can be ordered will still lead to the correct result. A high-level abstraction such as TBB helps a great deal, but there are a few issues we have to grapple with on our own: potential variations in results when programs compute results in parallel, and new types of programming bugs when locks are used incorrectly.
Computations done in parallel often get different results than the original sequential program. Round-off errors are the most common surprise for many programmers when a program is modified to run in parallel. We should expect numeric results, when using floating-point values, to vary when computations are changed to run in parallel because floating-point values have limited precision. For example, computing (A+B+C+D) as ((A+B)+(C+D)) enables A+B and C+D to be computed in parallel, but the final sum may be different from other evaluations such as (((A+B)+C)+D) . Even the parallel results can differ from run to run, depending on the order of the operations actually taken during program execution. Such nondeterministic behavior can often be controlled by reducing runtime flexibility. We will mention such options in this book, in particular the options for deterministic reduction operations (Chapter 16 ). Nondeterminism can make debugging and testing much more difficult, so it is often desirable to force deterministic behavior. Depending on the circumstances, this can reduce performance because it effectively forces more synchronization.
A few types of program failures can happen only in a program using concurrency because they involve the coordination of tasks. These failures are known as deadlocks and race conditions . Determinism is also a challenge since a concurrent program has many possible paths of execution because there can be so many tasks operating independently.
Although TBB simplifies programming so as to reduce the chance for such failures, they are still possible even with TBB. Multithreaded programs can be nondeterministic as a result of race conditions, which means the same program with the same input can follow different execution paths each time it is invoked. When this occurs, failures do not repeat consistently, and debugger intrusions can easily change the failure, thereby making debugging frustrating, to say the least.
Tracking down and eliminating the source of unwanted nondeterminism is not easy. Specialized tools such as Intel Advisor can help, but the first step is to understand these issues and try to avoid them.
There is also another very common problem, which is also an implication of nondeterminism, when moving from sequential code to parallel code: instability in results. Instability in results means that we get different results because of subtle changes in the order in which work is done. Some algorithms may be unstable, whereas others simply exercise the opportunity to reorder operations that are considered to have multiple correct orderings.
Next, we explain three key errors in parallel programming and solutions for each.
Deadlock
Deadlock occurs when at least two tasks wait for each other and each will not resume until the other task proceeds. This happens easily when code requires the acquisition of multiple locks. If Task A needs Lock R and Lock X , it might get Lock R and then try to get Lock X . Meanwhile, if Task B needs the same two locks but grabs Lock X first, we can easily end up with Task A wanting Lock X while holding Lock R , and Task B waiting for Lock R while it holds only Lock X . The resulting impasse can be resolved only if one task releases the lock it is holding. If neither task yields, deadlock occurs and the tasks are stuck forever.
Solution for Deadlock
Use implicit synchronization to avoid the need for locks. In general, avoid using locks, especially multiple locks at one time. Acquiring a lock and then invoking a function or subroutine that happens to use locks is often the source of multiple lock issues. Because access to shared resources must sometimes occur, the two most common solutions are to acquire locks in a certain order (always A and then B , for instance) or to release all locks whenever any lock cannot be acquired and begin again (after a random length delay).
Race Conditions
A race condition occurs when multiple tasks read from and write to the same memory without proper synchronization. The “race” may finish correctly sometimes and therefore complete without errors, and at other times it may finish incorrectly. Figure P-16 illustrates a simple example with three different possible outcomes due to a race condition.
Race conditions are less catastrophic than deadlocks, but more pernicious because they do not necessarily produce obvious failures and yet can lead to corrupted data (an incorrect value being read or written). The result of some race conditions can be a state unexpected (and undesirable) because more than one thread may succeed in updating only part of their state (multiple data elements).
Solution for Race Conditions
Manage shared data in a disciplined manner using the synchronization mechanisms described in Chapter 5 to ensure a correct program. Avoid low-level methods based on locks because it is so easy to get things wrong. Explicit locks should be used only as a last resort. In general, we are better off using the synchronization implied by the algorithm templates and task scheduler when possible. For instance, use parallel_reduce (Chapter 2 ) instead of creating our own with shared variables. The join operation in parallel_reduce is guaranteed not to run until the subproblems it is joining are completed.
Instability of Results (Lack of Deterministic Results)
A parallel program will generally compute answers differently each time because it the many concurrent tasks operate with slight variations between different invocations, and especially on systems with differing number of processors. We explained this in our discussion of correctness starting on page xlviii.
Solution for Instability of Results
TBB offers ways to ensure more deterministic behavior by reducing runtime flexibility. While this can reduce performance somewhat, the benefits of determinism are often worth it. Determinism is discussed in Chapter 16 .
Abstraction
When writing a program, choosing an appropriate level of abstraction is important. Few programmers use assembly language anymore. Programming languages such as C and C++ have abstracted away the low-level details. Hardly anyone misses the old programming method.
Parallelism is no different. We can easily get caught up in writing code that is too low level. Raw thread programming requires us to manage threads, which is time-consuming and error-prone.
Programming with TBB offers an opportunity to avoid thread management. This will result in code that is easier to create, easier to maintain, and more elegant. In practice, we find that this code is also more portable and performance portable. However, it does require thinking of algorithms in terms of what work can be divided and how data can be divided.
Patterns
Experienced parallel programmers know that there are common problems for which there are known solutions. All types of programming are like this – we have concepts such as stacks, queues, and linked lists in our vocabulary as a result. Parallel programming brings forward concepts such as map, reduce, and pipeline.
We call these patterns , and they can be adapted to our particular needs. Learning common patterns is a perfect way to learn from those who have gone before us. TBB implements solutions for key patterns, so we can implicitly learn them simply by learning TBB. We think patterns are an important enough concept, that we will discuss them in more depth in Chapter 8 .
Locality and the Revenge of the Caches
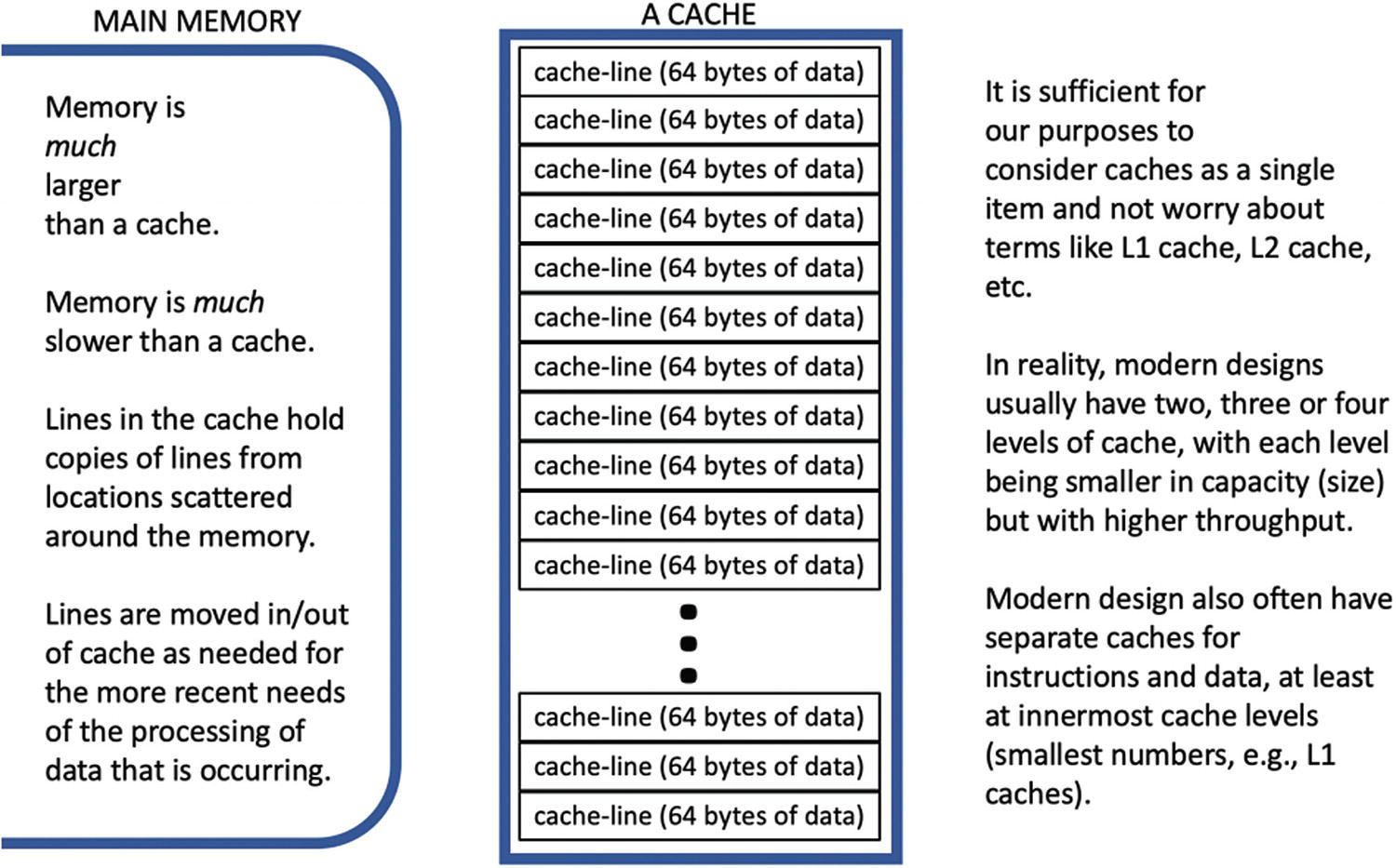
Effective parallel programming requires that we have a sense of the importance of locality . The motivation for this requires that we speak briefly about the hardware, in particular memory caches . A “cache” is simply a hardware buffer of sorts that retains data we have recently seen or modified, closer to us so it can be accessed faster than if it was in the larger memory. The purpose of a cache is to make things faster, and therefore if our program makes better usage of caches our application may run faster.
We say “caches” instead of “cache” because modern computer design generally consists of multiple levels of caching hardware, each level of which is a cache. For our purposes, thinking of cache as a single collection of data is generally sufficient.
We do not need to understand caches deeply, but a high-level understanding of them helps us understand locality, the related issues with sharing of mutable state , and the particularly insidious phenomenon known as false sharing .
Main memory and a cache
Hardware Motivation
We would like to ignore the details of hardware implementation as much as possible, because generally the more we cater to a particular system the more we lose portability, and performance portability. There is a notable and important exception: caches (Figure P-17 ).
A memory cache will be found in all modern computer designs. In fact, most systems will have multiple levels of caches. It was not always this way; originally computers fetched data and instructions from memory only when needed and immediately wrote results into memory. Those were simpler times!
The speed of processors has grown to be much faster than main memory. Making all of memory as fast as a processor would simply prove too expensive for most computers. Instead, designers make small amounts of memory, known as caches , that operate as fast as the processor. The main memory can remain slower and therefore more affordable. The hardware knows how to move information in and out of caches as needed, thereby adding to the number of places where data is shuffled on its journey between memory and the processor cores. Caches are critical in helping overcome the mismatch between memory speed and processor speed.
Virtually all computers use caches only for a temporary copy of data that should eventually reside in memory. Therefore, the function of a memory subsystem is to move data needed as input to caches near the requesting processor core, and to move data produced by processing cores out to main memory. As data is read from memory into the caches, some data may need to be evicted from the cache to make room for the newly requested data. Cache designers work to make the data evicted be approximately the least recently used data. The hope is that data which has not been used recently is not likely to be needed in the near future. That way, caches keep in their precious space the data we are most likely to use again.
Once a processor accesses data, it is best to exhaust the program’s use of it while it is still in the cache. Continued usage will hold it in the cache, while prolonged inactivity will likely lead to its eviction and future usage will need to do a more expensive (slow) access to get the data back into the cache. Furthermore, every time a new thread runs on a processor, data is likely to be discarded from the cache to make room for the data needed by the particular thread.
Locality of Reference
Consider it to be expensive to fetch data from memory the first time, but it is much cheaper to use the data for a period of time after it is fetched. This is because caches hold onto the information much like our own short-term memories allow us to remember things during a day that will be harder to recall months later.
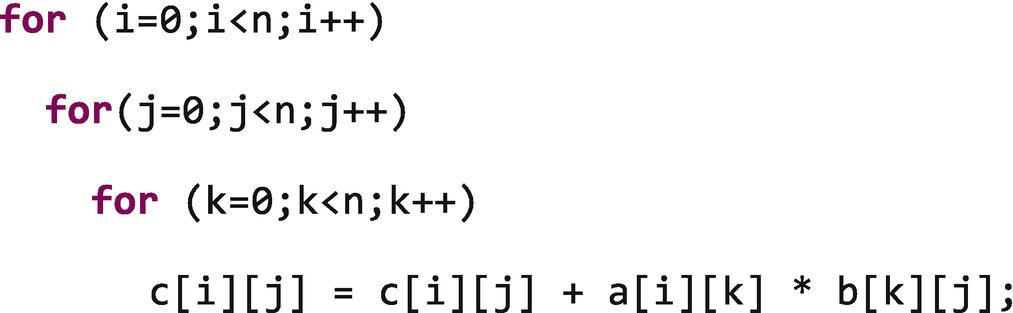
Matrix multiplication with poor locality of reference
C and C++ store arrays in row-major order. Which means that the contiguous array elements are in the last array dimension. This means that c[i][2] and c[i][3] are next to each other in memory, while c[2][j] and c[3][j] will be far apart ( n elements apart in our example).
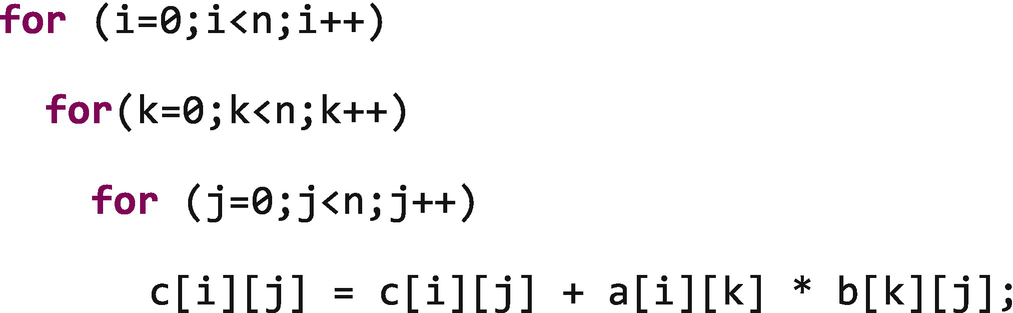
Matrix multiplication with improved locality of reference
Cache Lines, Alignment, Sharing, Mutual Exclusion, and False Sharing
Caches are organized in lines. And processors transfer data between main memory and the cache at the granularity of cache lines. This causes three considerations which we will explain: data alignment, data sharing, and false sharing.
The length of a cache line is somewhat arbitrary, but 512 bits is by far the most common today – that is, 64 bytes in size, or the size of eight double precision floating-point numbers or sixteen 32-bit integers.
Alignment
It is far better for any given data item (e.g., int , long , double , or short ) to fit within a single cache line. Looking at Figure P-17 or Figure P-20 , and consider if it were a single data item (e.g., double ) stretching across two cache lines. If so, we would need to access (read or write) two caches lines instead of one. In general, this will take twice as much time. Aligning single data items to not span cache lines can be very important for performance. To be fair to hardware designers, some hardware has significant capabilities to lessen the penalty for data that is not aligned (often called misaligned data). Since we cannot count on such support, we strongly advise that data be aligned on its natural boundaries. Arrays will generally span cache lines unless they are very short; normally, we advise that an array is aligned to the alignment size for a single array element so that a single element never sits in two cache lines even though the array may span multiple cache lines. The same general advice holds for structures as well, although there may be some benefit to aligning small structures to fit entirely in a cache line.
A disadvantage of alignment is wasted space. Every time we align data, we are potentially skipping some memory. In general, this is simply disregarded because memory is cheap. If alignment occurs frequently, and can be avoided or rearranged to save memory, that can occasionally still be important. Therefore, we needed to mention the disadvantage of alignment. In general, alignment is critical for performance, so we should just do it. Compilers will automatically align variables, including array and structures to the element sizes. We need to explicitly align when using memory allocations (e.g., malloc ) so we recommend how to do that in Chapter 7 .
The real reason we explain alignment is so we can discuss sharing and the evils of false sharing.
Sharing
Sharing copies of immutable (unchangeable) data from memory is easy, because every copy is always a valid copy. Sharing immutable data does not create any special problems when doing parallel processing.
It is mutable (changeable) data that creates substantial challenges when doing parallel processing of the data. We did name shared mutable state as an enemy of parallelism! In general, we should minimize sharing of mutable (changeable) data between tasks. The less sharing, the less there is to debug and the less there is to go wrong. We know the reality is that sharing data allows parallel tasks to work on the same problem to achieve scaling, so we have to dive into a discussion about how to share data correctly.
Shared mutable (changeable) state creates two challenges: (1) ordering, and (2) false sharing. The first is intrinsic to parallel programming and is not caused by the hardware. We discussed mutual exclusion starting on page xlv and illustrated a key concern over correctness with Figure P-16 . It is a critical topic that must be understood by every parallel programmer.
False Sharing
Because data is moved around in cache lines, it is possible for multiple ,completely independent variables or memory allocations to be all or partially within the same cache line (Figure P-20 ). This sharing of a cache line will not cause a program to fail. However, it can greatly reduce performance. A complete explanation of the issues that arise when sharing a cache line, for mutable data being used in multiple tasks, would take many pages. A simple explanation is updating data anywhere in a cache line can create slowdowns for all accesses in the cache line from other tasks.
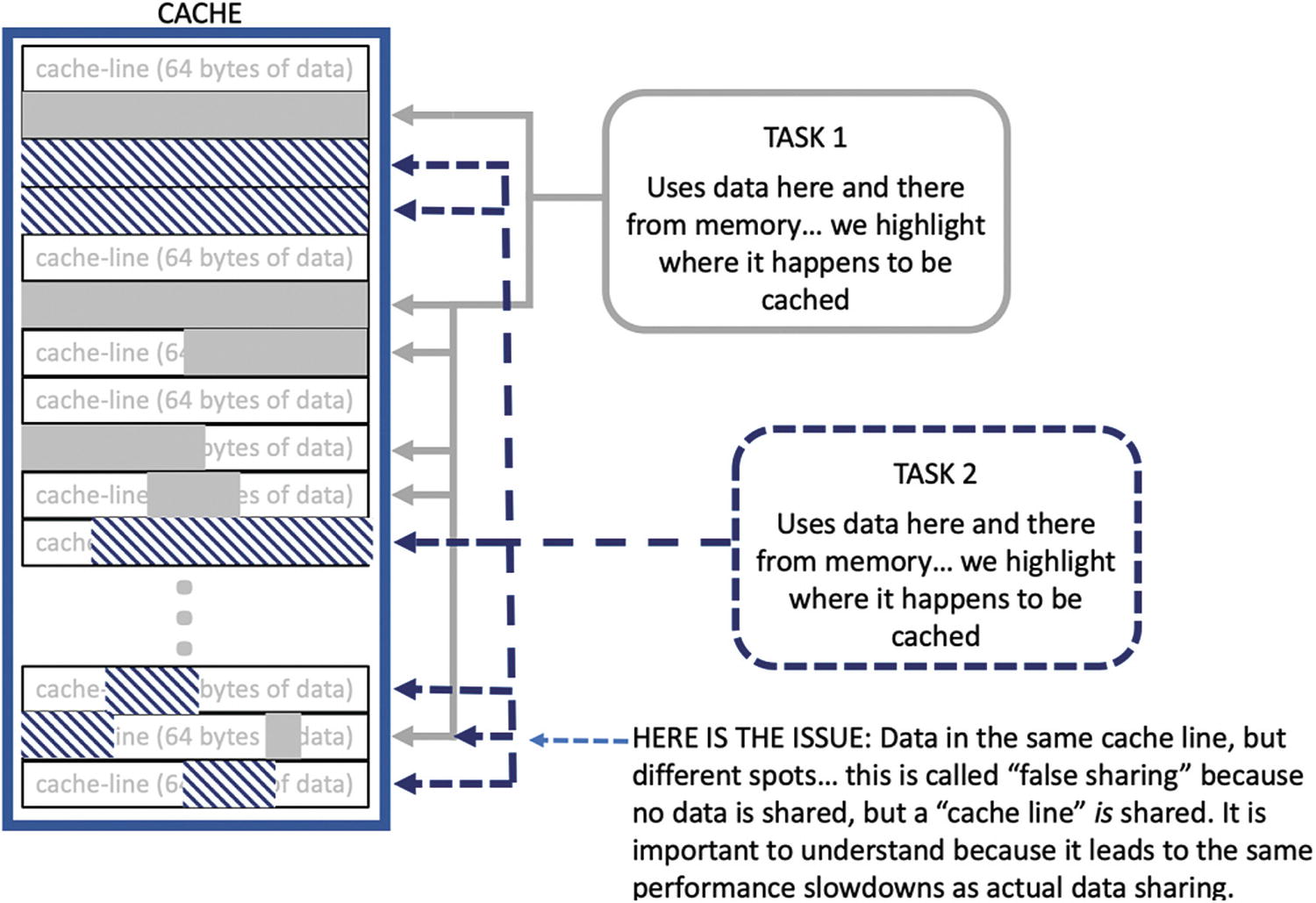
False sharing happens when data from two different tasks end up in the same cache line

Two consecutive entries in my_private_counter are likely to be in the same cache line. Therefore, our example program can experience extra overhead due specifically to the false sharing caused by having data used by separate threads land in the same cache line. Consider two threads 0 and 1 running on core0 and core1 respectively, and the following sequence of events:
Thread 0 increments my_private_counter[0] which translates into reading the value in the core 0 private cache, incrementing the counter, and writing the result. More precisely, core 0 reads the whole line (say 64 bytes) including this counter into the cache and then updates the counter with the new value (usually only in the cache line).
Next, if thread 1 also increments my_private_counter[1] , extra overhead due to false sharing is paid. It is highly likely that positions 0 and 1 of my_private_counter fall into the same cache line. If this is the case, when thread 1 in core1 tries to read their counter, the cache coherence protocol comes into play. This protocol works at the cache line level, and it will conservatively assume that thread 1 is reading the value written by thread 0 (as if thread 0 and thread 1 where truly sharing a single counter). Therefore, core 1 must read the cache line from core 0 (the slowest alternative would be to flush core 0 cache line to memory, from where core1 can read it). This is already expensive, but it is even worse when thread 1 increments this counter, invalidating the copy of the cache line in core0.
Now if thread 0 increments again my_private_counter[0] , it does not find his counter in core 0’s local cache because it was invalidated. It is necessary to pay the extra time to access core 1’s version of the line that was updated most recently. Once again, if thread 0 then increments this counter, it invalidates the copy in core 1. If this behavior continues, the speed at which thread 0 and thread 1 will access their respective counters is significantly slower than in the case in which each counter lands in a different cache line.
This issue is called “false sharing” because actually each thread has a private (not shared) counter, but due to the cache coherence protocol working at cache line level, and both counters “sharing” the same cache line, the two counters seem to be shared from a hardware point of view.
Now you are probably thinking that a straightforward solution would be to fix the hardware implementation of the cache coherence protocol so that it works at word level instead of a line level. However, this hardware alternative is prohibitive, so hardware vendors ask us to solve the problem by software: Do your best to get each private counter falling in a different cache line so that it is clear to the hardware that the expensive cache coherence mechanism does not have to be dispatched.
We can see how a tremendous overhead can easily be imposed from false sharing of data. In our simple example, the right solution is to use copies of each element. This can be done in a number of ways, one of which would be to use the cache aligned allocator for the data needed for a given thread instead allocating them all together with the risk of false sharing.
Avoiding False Sharing with Alignment
In order to avoid false sharing (Figure P-20 ), we need to make sure that distinctly different pieces of mutable data that may be updated in parallel do not land in the same cache line. We do that with a combination of alignment and padding.
Alignment of data structures, such as arrays or structures, to a cache line boundary will prevent placement of the start of the data structure in a cache line used by something else. Usually, this means using a version of malloc that aligns to a cache line. We discuss memory allocation, including cache aligned memory allocators (e.g., tbb::cache_aligned_allocator ), in Chapter 7 . We can also explicitly align static and local variables with compiler directives (pragmas), but the need for that is far less common. We should note that performance slowdowns from false sharing from memory allocation are often somewhat nondeterministic, meaning that it may affect some runs of an application and not others. This can be truly maddening because debugging a nondeterministic issue is very challenging since we cannot count on any particular run of an application to have the issue!
TBB Has Caches in Mind
TBB is designed with caches in mind and works to limit the unnecessary movement of tasks and data. When a task has to be moved to a different processor, TBB moves the task with the lowest likelihood of having data in the cache of the old processor. These considerations are built into the work (task) stealing schedulers and therefore are part of the algorithm templates discussed in Chapters 1 – 3 .
For best performance, we need to keep data locality in mind when considering how to structure our programs. We should avoid using data regions sporadically when we can design the application to use a single set of data in focused chunks of time.
Introduction to Vectorization (SIMD)
Parallel programming is ultimately about harnessing the parallel computational capabilities of the hardware. Throughout this book, we focus on parallelism that exploits having multiple processor cores. Such hardware parallelism is exploited by thread-level (or abstractly task-level) parallelism, which is what TBB solves for us.
There is another class of very important hardware parallelism known as vector instructions, which are instructions that can do more computation (in parallel) than a regular instruction. For instance, a regular add instruction takes two numbers, adds them, and returns a single result. An eight-way vector add would be able to handle eight pairs of inputs, add each pair, and produce eight outputs. Instead of C=A+B in a regular add instruction, we get C 0 =A 0 +B 0 and C 1 =A 1 +B 1 and C 2 =A 2 +B 2 … and C 7 =A 7 +B 7 from a single vector add instruction. This can offer 8× in performance. These instructions do require that we have eight of the same operations to do at once, which does tend to be true of numerically intensive code.
This ability to do multiple operations in a single instruction is known as Single Instruction Multiple Data (SIMD), one of four classification of computer architecture known by computer scientists as Flynn’s taxonomy. The concept that a single instruction can operate on multiple data (e.g., the inputs to eight different additions) gives us parallelism that we will want to exploit.
Vectorization is the technology that exploits SIMD parallelism, and it is a technology which relies on compilers because compilers specialize in hardware instruction selection.
We could largely ignore vector parallelism in this book and say “it’s a different subject with a different set of things to study” – but we won’t! A good parallel program generally uses both task parallelism (with TBB) and SIMD parallelism (with a vectorizing compiler).
Our advice is this: Read Chapter 4 of this book! Learn about vectorizing capabilities of your favorite compiler and use them. #pragma SIMD is one such popular capability in compilers these days. Understand Parallel STL (Chapter 4 and Appendix B), including why it is generally not the best solution for effective parallel programming (Amdahl’s Law favors parallelism being put at a higher level in the program than in STL calls).
While vectorization is important, using TBB offers superior speedup for most applications (if you consider choosing one or the other). This is because systems usually have more parallelism from cores than from SIMD lanes (how wide the vector instructions are), plus tasks are a lot more general than the limited number of operations that are available in SIMD instructions.
Good advice: Multitask your code first (use TBB); vectorize second (use vectorization).
Best advice: Do both.
Doing both is generally useful when programs have computations that can benefit from vectorization. Consider a 32-core processor with AVX vector instructions. A multitasking program could hope to get a significant share of the theoretical maximum 32× in performance from using TBB. A vectorized program could hope to get a significant share of the theoretical maximum 4× in performance from using vectorization on double precision mathematical code. However, together the theoretical maximum jump in performance is 256× – this multiplicative effect is why many developers of numerically intensive programs always do both.
Introduction to the Features of C++ (As Needed for TBB)
Since the goal of parallel programming is to have an application scale in performance on machines with more cores, C and C++ both offer an ideal combination of abstraction with a focus on efficiency. TBB makes effective use of C++ but in a manner that is approachable to C programmers.
Every field has its own terminology, and C++ is no exception. We have included a glossary at the end of this book to assist with the vocabulary of C++, parallel programming, TBB, and more. There are several terms we will review here that are fundamental to C++ programmers: lambda functions, generic programming, containers, templates, Standard Template Library (STL), overloading, ranges, and iterators.
Lambda Functions
We are excited by the inclusion of lambda functions in the C++11 standard, which allow code to be expressed inline as an anonymous function. We will wait to explain them in Chapter 1 when we need them and will illustrate their usage.
Generic Programming
Generic programming is where algorithms are written to generically operate on any data type. We can think of them as using parameters which are “to-be-specified-later.” C++ implements generic programming in a way that favors compile time optimization and avoids the necessity of runtime selection based on types. This has allowed modern C++ compilers to be highly tuned to minimize abstraction penalties arising from heavy use of generic programming, and consequently templates and STL. A simple example of generic programming is a sort algorithm which can sort any list of items, provided we supply a way to access an item, swap two items, and compare two items. Once we have put together such an algorithm, we can instantiate it to sort a list of integers, or floats, or complex numbers, or strings, provided that we define how the swap and the comparison is done for each data type.

These are actually supported in the C++ Standard Template Library (STL – definition coming up on the next page) for C++ when we include the appropriate header file.
Containers
“Container” is C++ for “a struct” that organizes and manages a collection of data items. A C++ container combines both object-oriented capabilities (isolates the code that can manipulate the “struct”) and generic programming qualities (the container is abstract, so it can operate on different data types). We will discuss containers supplied by TBB in Chapter 6 . Understanding containers is not critical for using TBB, they are primarily supported by TBB for C++ users who already understand and use containers.
Templates
Templates are patterns for creating functions or classes (such as containers) in an efficient generic programming fashion, meaning their specification is flexible with types, but the actual compiled instance is specific and therefore free of overhead from this flexibility. Creating an effective template library can be a very involved task, but using one is not. TBB is a template library.
To use TBB, and other template libraries, we can really treat them as a collection of function calls. The fact that they are templates really only affects us in that we need to use a C++ compiler to compile them since templates are not part of the C language. Modern C++ compilers are tuned to minimize abstraction penalties arising from heavy use of templates.
STL
The C++ Standard Template Library (STL) is a software library for the C++ programming language which is part of the C++ programming standard. Every C++ compiler needs to support STL. STL provides four components called algorithms, containers, functions, and iterators.
The concept of “generic programming” runs deep in STL which relies heavily on templates. STL algorithms, such as sort , are independent of data types (containers). STL supports more complex data types including containers and associative arrays, which can be based upon any built-in type or user-defined type provided they support some elementary operations (such as copying and assignment).
Overloading
Operator overloading is an object-oriented concept which allows new data types (e.g., complex ) to be used in contexts where built-in types (e.g., int ) are accepted. This can be as arguments to functions, or operators such as = and + . C++ templates given us a generalized overloading which can be thought of extending overloading to function names with various parameters and or return value combinations. The goals of generic programming with templates, and object-oriented programming with overloading, are ultimately polymorphism – the ability to process data differently based on the type of the data, but reuse the code processing. TBB does this well – so we can just enjoy it as users of the TBB template library.
Ranges and Iterators
If you want to start a bar fight with C++ language gurus, pick either “ iterators ” or “ ranges ” and declare that one is vastly superior to the other. The C++ language committee is generally favoring to ranges as a higher-level interface and iterators for future standard revisions. However, that simple claim might start a bar fight too. C++ experts tell us that ranges are an approach to generic programming that uses the sequence abstraction as opposed to the iterator abstraction. Head spinning yet?
As users, the key concept behind an iterator or a range is much the same: a shorthand to denote a set (and some hints on how to traverse it). If we want to denote the numbers 0 to 999999 we can mathematically write this as [0,999999] or [0,1000000) . Note the use of mathematical notation where [ or ] are inclusive and ( or ) note noninclusion of the number closest to the parenthesis. Using TBB syntax, we write blocked_range<size_t>(0,1000000) .
We love ranges, because they match perfectly with our desire to specify “possible parallelism” instead of mandatory parallelism. Consider a “parallel for” that planned to iterate a million times. We could immediately create a million threads to do the work in parallel, or we could create one thread with a range of [0,1000000) . Such a range can be subdivided as needed to fill the available parallelism, and this is why we love ranges.
TBB supports and makes use of iterators and ranges , and we will mention that periodically in this book. There are plenty of examples of these starting in Chapter 2 . We will show examples of how to use them, and we think those examples are easy to imitate. We will simply show which one to use where, and how, and not debate why C++ has them both. Understanding the deep C++ meanings of iterators vs. ranges will not improve our ability to use TBB. A simple explanation for now would be that iterators are less abstract that ranges, and at a minimum that leads to a lot of code using iterators which passes two parameters: something.begin() and something.end() when all we wanted to say was “use this range – begin to end.”
Summary
We have reviewed how to “Think Parallel” in terms of decomposition, scaling, correctness, abstraction, and patterns. We have introduced locality as a key concern for all parallel programming. We have explained how using tasks instead of threads is a key revolutionary development in parallel programming supported by TBB. We have introduced the elements of C++ programming that are needed above and beyond a knowledge of C in order to use TBB well.
With these key concepts bouncing around in your head, you have begun to Think Parallel . You are developing an intuition about parallelism that will serve you well.
This Preface, the Index, and Glossary are key resources as you venture forth in the rest of this book to explore and learn parallel programming with TBB.
For More Information
The C++ standard(s), https://isocpp.org/std/the-standard .
“The Problem with Threads” by Edward Lee, 2006. IEEE Computer Magazine, May 2006, http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.306.9963&rep=rep1&type=pdf , or U. C. Berkley Technical Report: www2.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-1.pdf .
All of the code examples used in this book are available at https://github.com/Apress/pro-TBB .
Two people offered their early and continuing support for this project – Sanjiv Shah and Herb Hinstorff. We are grateful for their encouragement, support, and occasional gentle pushes.
The real heroes are reviewers who invested heavily in providing thoughtful and detailed feedback on draft copies of the chapters within this book. The high quality of their input helped drive us to allow more time for review and adjustment than we initially planned. The book is far better as a result.
The reviewers are a stellar collection of users of TBB and key developers of TBB. It is rare for a book project to have such an energized and supportive base of help in refining a book. Anyone reading this book can know it is better because of these kind souls: Eduard Ayguade, Cristina Beldica, Konstantin Boyarinov, José Carlos Cabaleiro Domínguez, Brad Chamberlain, James Jen-Chang Chen, Jim Cownie, Sergey Didenko, Alejandro (Alex) Duran, Mikhail Dvorskiy, Rudolf (Rudi) Eigenmann, George Elkoura, Andrey Fedorov, Aleksei Fedotov, Tomás Fernández Pena, Elvis Fefey, Evgeny Fiksman, Basilio Fraguela, Henry Gabb, José Daniel García Sánchez, Maria Jesus Garzaran, Alexander Gerveshi, Darío Suárez Gracia, Kristina Kermanshahche, Yaniv Klein, Mark Lubin, Anton Malakhov, Mark McLaughlin, Susan Meredith, Yeser Meziani, David Padua, Nikita Ponomarev, Anoop Madhusoodhanan Prabha, Pablo Reble, Arch Robison, Timmie Smith, Rubén Gran Tejero, Vasanth Tovinkere, Sergey Vinogradov, Kyle Wheeler, and Florian Zitzelsberger.
We sincerely thank all those who helped, and we apologize for any who helped us and we failed to mention!
Mike (along with Rafa and James!) thanks all of the people who have been involved in TBB over the years: the many developers at Intel who have left their mark on the library, Alexey Kukanov for sharing insights as we developed this book, the open-source contributors, the technical writers and marketing professionals that have worked on documentation and getting the word out about TBB, the technical consulting engineers and application engineers that have helped people best apply TBB to their problems, the managers who have kept us all on track, and especially the users of TBB that have always provided the feedback on the library and its features that we needed to figure out where to go next. And most of all, Mike thanks his wife Natalie and their kids, Nick, Ali, and Luke, for their support and patience during the nights and weekends spent on this book.
Rafa thanks his PhD students and colleagues for providing feedback regarding making TBB concepts more gentle and approachable: José Carlos Romero, Francisco Corbera, Alejandro Villegas, Denisa Andreea Constantinescu, Angeles Navarro; particularly to José Daniel García for his engrossing and informative conversations about C++11, 14, 17, and 20, to Aleksei Fedotov and Pablo Reble for helping with the OpenCL_node examples, and especially his wife Angeles Navarro for her support and for taking over some of his duties when he was mainly focused on the book.
James thanks his wife Susan Meredith – her patient and continuous support was essential to making this book a possibility. Additionally, her detailed editing, which often added so much red ink on a page that the original text was hard to find, made her one of our valued reviewers.
As coauthors, we cannot adequately thank each other enough. Mike and James have known each other for years at Intel and feel fortunate to have come together on this book project. It is difficult to adequately say how much Mike and James appreciate Rafa! How lucky his students are to have such an energetic and knowledgeable professor! Without Rafa, this book would have been much less lively and fun to read. Rafa’s command of TBB made this book much better, and his command of the English language helped correct the native English speakers (Mike and James) more than a few times. The three of us enjoyed working on this book together, and we definitely spurred each other on to great heights. It has been an excellent collaboration.
We thank Todd Green who initially brought us to Apress. We thank Natalie Pao, of Apress, and John Somoza, of Intel, who cemented the terms between Intel and Apress on this project. We appreciate the hard work by the entire Apress team through contract, editing, and production.
Thank you all,
Mike Voss, Rafael Asenjo, and James Reinders
Table of Contents
About the Authors
is a Principal Engineer in the Intel Architecture, Graphics and Software Group at Intel. He has been a member of the TBB development team since before the 1.0 release in 2006 and was the initial architect of the TBB flow graph API. He is also one of the lead developers of Flow Graph Analyzer, a graphical tool for analyzing data flow applications targeted at both homogeneous and heterogeneous platforms. He has co-authored over 40 published papers and articles on topics related to parallel programming and frequently consults with customers across a wide range of domains to help them effectively use the threading libraries provided by Intel. Prior to joining Intel in 2006, he was an Assistant Professor in the Edward S. Rogers Department of Electrical and Computer Engineering at the University of Toronto. He received his Ph.D. from the School of Electrical and Computer Engineering at Purdue University in 2001.
, Professor of Computer Architecture at the University of Malaga, Spain, obtained a PhD in Telecommunication Engineering in 1997 and was an Associate Professor at the Computer Architecture Department from 2001 to 2017. He was a Visiting Scholar at the University of Illinois in Urbana-Champaign (UIUC) in 1996 and 1997 and Visiting Research Associate in the same University in 1998. He was also a Research Visitor at IBM T.J. Watson in 2008 and at Cray Inc. in 2011. He has been using TBB since 2008 and over the last five years, he has focused on productively exploiting heterogeneous chips leveraging TBB as the orchestrating framework. In 2013 and 2014 he visited UIUC to work on CPU+GPU chips. In 2015 and 2016 he also started to research into CPU+FPGA chips while visiting U. of Bristol. He served as General Chair for ACM PPoPP’16 and as an Organization Committee member as well as a Program Committee member for several HPC related conferences (PPoPP, SC, PACT, IPDPS, HPCA, EuroPar, and SBAC-PAD). His research interests include heterogeneous programming models and architectures, parallelization of irregular codes and energy consumption.
is a consultant with more than three decades experience in Parallel Computing, and is an author/co-author/editor of nine technical books related to parallel programming. He has had the great fortune to help make key contributions to two of the world’s fastest computers (#1 on Top500 list) as well as many other supercomputers, and software developer tools. James finished 10,001 days (over 27 years) at Intel in mid-2016, and now continues to write, teach, program, and do consulting in areas related to parallel computing (HPC and AI).