
Figure 9.1 TORCS, 2014. (Image courtesy of the Libre Game Wiki.)
Let us return to the question of what intelligence actually is, the one I discussed in chapter 3 without coming to any satisfying conclusion. Since you are reading this, you clearly haven’t given up on reading this book, but you may be a bit disappointed with me because I apparently can’t give you a straight answer. Well, I was just being honest. It is still very much up for debate to what extent there exists such a thing as general intelligence. I won’t try to force a particular view on you because I think there’s plenty of work, both philosophical and empirical, left to do to understand this question better. What it seems we can all agree on, however, is that some artificial intelligence systems have broader applicability than others in the sense that they can perform a wider range of tasks and that it is a desirable quality of an AI system to be generic rather than specific. There is nothing wrong with AI systems that can do only one thing if we are simply trying to engineer a solution to a specific problem. If we are trying to make scientific progress on creating artificial intelligence, however, then it is important that we build systems that can do a range of different things—for example, play different games.
Around the time that I was finishing my PhD, I thought that the little car racing game I had constructed for my experiments with evolving neural networks was pretty nifty and that other people might want to use it for their own experiments, so I decided to make the code available. As I was doing that, I decided to start a competition. Researchers, students, and anyone else could submit their best agents, and they would compete against each other. Just like in real-world car racing, the car that finished the course fastest would win. Also just like in real-world car racing, the collisions were the most fun part to watch. I quickly got a few dozen competitors from all over the world, submitting controllers based on some pretty different AI techniques. The winner used a technique called fuzzy logic to reason about how to drive best, but there were several good agents based on reinforcement learning and evolutionary algorithms. Seeing how well the competition went, I decided to run it again, but this time I teamed up with some Italian researchers, Pier Luca Lanzi and Daniele Loiacono at the Politecnico di Milano, to move it over to a more capable 3D racing game called TORCS. The competition ran for seven years, with continued participation from universities, and in some cases hobbyists and private companies, around the world (figure 9.1).1
Figure 9.1 TORCS, 2014. (Image courtesy of the Libre Game Wiki.)
A few years later I started another AI competition based on Infinite Mario, the open-source clone of Super Mario Bros. I mentioned earlier. My student Sergey Karakovskiy and I rebuilt Infinite Mario into an AI benchmark and had people submit their best Mario-playing AI agents. With a few weeks to go before the end of the competition, a young PhD student by the name of Robin Baumgarten submitted an agent based on the A* algorithm discussed in chapter 4. The agent was stupendously effective. It completed all the levels our level generators could generate seemingly faultlessly and went on to win the competition. This was a bit of a letdown for us, as we had imagined that we had constructed a hard AI problem, only for an agent based on such a simple and well-known algorithm to walk all over it. In an attempt to salvage the competition for the next round, we went to work on making the level generator meaner. Next time we ran the competition, the level generator created levels with frequent dead ends, which Mario would need to backtrack to get out of. This was a challenge that Baumgarten’s A* agent could not overcome; instead, the next competition was won by a complex agent called REALM, which combined evolutionary algorithms with a rule-based system and, as one subservient part of the mix, an A* algorithm similar to Baumgarten’s.2
Of course, I was not the first to run game-based AI competitions. Competitions for AI players of Chess, Checkers, and Go have been running for decades. Within the video game space, there have been long-running AI competitions based on classic arcade games such Ms. Pac-Man, first-person shooters such as DOOM, and physics puzzle games such as Angry Birds. One of the most active competitions right now is the StarCraft competition, which revolves around a game in which the best submitted agents still stand no chance against a good human player.
In most of these competitions, as least those that continue for a few years, there is clear progress. Racing agents submitted to the 2012 Simulated Car Racing Competition literally run laps around those submitted to the 2008 competition, and agents submitted to the 2011 Mario AI Competition finish levels that agents submitted to the 2009 competition would not. This is all good and would seem to suggest that these competitions spur advancements in game-playing AI. Looking at the submissions from each year, however, you can see a worrying trend: there are, in general, fewer and fewer general AI algorithms in the later submissions. The submissions to the first edition of Simulated Car Racing Competition consisted of agents using relatively general-purpose algorithms that could have been used to play other games with minor changes. In later years of the competition, agents were being tailored more and more to the task of playing this particular racing game, including painstakingly handcrafted mechanisms for changing gears, learning the shape of the track, blocking overtaking cars, and so on. In fact, machine learning algorithms in general were used in fewer and lesser roles in later years’ submissions compared to those at the beginning of the competitions. Advanced AI algorithms were demoted to supporting roles. The improvement in the agents’ performance is not really due to any improvements in the underlying algorithms but to better game-specific engineering. A similar development could be observed in the Mario AI competition. As for the StarCraft competitions, the agents that win tend to be intricately handcrafted strategies with little in the way of what we would normally call AI, such as search or machine learning algorithms.
Above all, these agents are very specific. The agents submitted to the Mario AI Competition cannot control the cars in the Simulated Car Racing Competition or build bases and command armies in StarCraft. The StarCraft agents cannot drive cars or play Super Mario Bros., and so on. It’s not just that the agent would play these games badly; it’s that it cannot play them at all: the game state is represented very differently for each of the game. The StarCraft game state makes no sense to the Mario-playing agent, and the outputs of that agent (such as running and jumping) make no sense to the StarCraft game.
This is not a problem unique to these competitions. I mentioned back in chapter 5 that DeepMind trained neural networks to play a few dozen classic Atari games. This might seem like an example of more general game-playing AI, were it not for the fact that each neural network is trained to play one game only. The neural network trained to play Space Invaders cannot play Pac-Man, Montezuma’s Revenge, or any of the other Atari games—at least not play them any better than the proverbial monkey in front of a typewriter, but with a joystick instead of a typewriter. There have been several attempts to train neural networks to be able to play more than one game, so far with limited success.3 The same thing is true for the other famous game-playing agent from DeepMind, AlphaGo. It is very good at playing Go, but it can only play Go. It can’t play anything else, not even Chess.4
Let’s return to the question of developing general artificial intelligence, or at least somewhat general artificial intelligence. It seems all this work on developing AI agents that can play individual games may not be moving us that much closer to this goal after all. In the worst case, it may even be a case of two steps forward and one step backward: we keep spending resources on understanding and exploiting the dynamics of individual games rather than trying to create agents that can demonstrate more general intelligence. The best way to demonstrate more general intelligence would be for the same agent, with no or little retraining, to solve multiple different tasks, such as playing multiple different games.
How would you ensure that researchers work on creating agents that have some more general game-playing capacity? You create a competition! That’s what a group of us were thinking back in 2013 as we started working on the General Video Game AI (GVG-AI) Competition (figure 9.2) The idea was to have a competition where you cannot tailor your agent to a particular game, so you have to make it at least somewhat general. We figured that we needed to design the competition so you did not know what games your agent was going to play. Every time we ran the competition, we needed new games that no one had seen before (even though they could be similar to or versions of well-known games). For this, we needed a way to easily create these games, so we started by designing a new language specifically for creating games in the style of classic arcade games. Tom Schaul took the lead in creating this language, which we call the Video Game Description Language (VGDL). Diego Perez-Liebana then took the lead in creating the competition software.
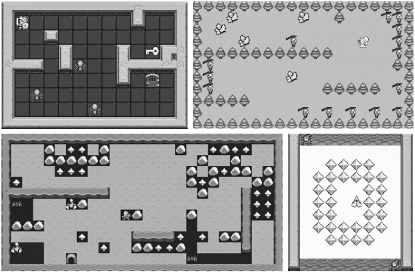
Figure 9.2 Four different games in the GVG-AI framework: Zelda, Butterflies, Boulder Dash, and Solar Fox. The common interface means that the same agent can play all games in the framework, but with varying skill.
So far, we’ve run the GVG-AI competition a few times per year since 2014. Every competition event tests all the submitted agents on a set of ten new games, which must be handmade for each competition. To date, more than a hundred games have been created, many of them versions of or inspired by arcade games from the 1980s. Competitors don’t know which games their agents will be tested on until after they have submitted their agents, making sure that they spend their energy on improving the agents’ general game-playing capacities rather than their fit with a particular game. Currently, the best agents can reliably win at fewer than half of the existing games, showing that there is ample room for improvement.5
If someone constructed an agent that could win at all of the existing games in the GVG-AI competition, would we call that agent “generally intelligent”? Well, not quite yet. The GVG-AI software gives the AI agents access to a forward model, or a simulator of the games, which makes it easy to plan your actions by simulating what would happen if you executed your plan. For example, the version of the A* agent that won the Mario AI competition crucially depends on having a forward model. You would generally not have access to that as a human playing classic arcade games, and the “real world” notoriously lacks a forward model. We are working on a new version of the competition, which does not provide agents with this possibility but instead gives them a short amount of time to adapt to each game. Also, the games that can be expressed in the current version of VGDL are limited to the kinds of games you would find in an early 1980s home computer or arcade hall, and even then some types of games are missing (e.g., there are no text-based games). In some unspecified future, we hope that VGDL or some successor language will be able to express a much wider range of games. We also hope that at some point in the future, it will be possible to generate these games automatically, making it much easier to create new games to test AI agents on.
While the GVG-AI project is only a small step toward solving, or even properly formulating, the problem of general game playing, I do believe that it is extremely relevant for understanding intelligence in general. As we have seen in the book, games are incredibly diverse, and they challenge our cognitive capacities in ways we are barely beginning to understand. If at some point in the future we create an agent that can learn quickly to play all video games or even just the most well-designed ones (let’s say the top 100 popular games on each of the major distribution platforms, such as Steam or the iOS App Store) with a skill similar to that of a game-playing human, then I think we will have achieved artificial general intelligence. At the very least, we will have enormously advanced our understanding of what intelligence is and is not.