Figure 2.1. Vertical integration
Quality of Service (QoS) is a widely used term. Hardware vendors sell equipment supplying “QoS solutions”, operators offer “QoS guaranteed” services; QoS has been the subject of countless works, articles and journals over the years. It is not a new trend; on the contrary, QoS is a growing phenomenon. It is not the goal of this chapter to revisit QoS (there are books dedicated to the subject); we aim to present some useful concepts to understand the QoS problems in networks, and especially IP networks. We will present the currently used QoS parameters, as well as the basic mechanisms implemented at the heart of the hardware. Complete architectures and protocols using these mechanisms will be presented in the next chapter.
Before we go on to discuss technicalities, we should ask ourselves basic questions. Why are we talking about QoS? Why do we even need QoS? How do we define it? And what are the major concerns?
The answer to this question could be as simple as: because there are services, but even more precisely, because there are users who pay for these services. Each time a new service is defined, it implies (or should imply) a definition of the expected result. And on the other side, each new user of a service implies a perception (more or less subjective) of this result, of the QoS received.
QoS is often dealt with by itself, separately from services, because certain issues are common to all services. It is therefore important to have a global recognition, regardless of domains and applications, in order to find the most generally sound solutions.
It can also be said that QoS has become fashionable in the last few years. This is due to the Internet explosion, its uses and the rapid evolution of resulting demands.
The needs are generated by the ever-growing number of users and of the applications they use.
Within IP networks, we first find new applications, which are very sensitive to network dysfunctions. Among them are the following:
– telephony over IP and videoconferences: companies are moving toward internal IP solutions and it is not uncommon today for connected users to communicate via webcams;
– ASPs (Application Service Providers): with actual distributed infrastructures, the network is becoming more and more a critical resource for the accurate behavior of a lot of applications;
– network gaming: they have been there since the beginning of networks, but today’s computing power enables the design of an ever-growing number of memory-intensive games. Furthermore, the ease of accessing the Internet now enables the use of this network to play. The main console makers even supply online gaming over the Internet.
On top of these new applications, some of the older critical applications are slowly transferred over to IP. For example:
– administrative functions (remote control);
– online banking, stock exchange;
– medical applications.
Speaking of medical applications, apart from information and management access, we can name a new application that could become global and which obviously needs a perfect communication quality: telesurgery. We may remember the first procedure on a human being in September 2001 during which Dr Marescaux from New York performed an operation on a patient in a hospital in Strasbourg, France.
There is a diversity of applications, and it is not easy to give a global definition of QoS. In fact, it all depends on the point of view.
A user, for example, will want the system to work correctly. This term groups different criteria depending on the services used and may be subjective at times. For example, in the case of file transfers, the main judging criteria will be speed. On the other hand, for a videoconference, the user must be audible and recognizable. For movie viewing, there needs to be a good image definition and a good refresh speed (especially for an action movie). In the case of online banking, we will be mostly concerned with reliability and security for our transactions. Finally, if we go back to our network games example, there must be a good synchronization between gamers’ machines. We could probably come up with still more criteria if we brought up other applications.
On the contrary, an operator will have a much more technical view, which enables more objectivity. We will then talk about bandwidth, error ratio, etc. Detailed examples of these parameters are presented later on.
Once the service quality criteria are well defined, the means to guarantee them has to be implemented. In order to do that, we must proceed to an integration of several elements within a general end-to-end model. There are providers for turnkey solutions, but these are mainly responsible at the network level and are only concerned with the interconnection between two sites or the connection to another network. One of the major concerns is a successful integration at two levels: vertical and horizontal.
Vertical integration consists of traveling from user needs to the physical resources. Each layer has its own control mechanisms and it is important to ensure the correct transfer between them. The translation of needs must be completed and interoperability of mechanisms must be ensured.
Horizontal integration is basically the hardware connecting two communicating extremities. We might have a combination of multiple operators, which can lead to negotiation problems, and we probably also have a variety of implemented QoS technologies. The crossing of the network requires interoperability.
The problems will also vary according to the context. In the case of closed environments, or proprietary, the operator has total control over his environment. Moreover, the environment is usually homogenous. It is then easier to put dedicated solutions in place (leased lines, ATM, MPLS, etc.).
On the other hand, an open environment will be harder to manage. It is probably heterogenous (horizontal view) and the more popular technologies (IP, Ethernet) are not adapted to QoS (IP best effort mode).
In order to overcome these problems it is necessary to:
– define the mechanisms (basic layer) to manage QoS within different layers;
– define the integration architectures/models of these mechanisms to supply requested services;
– define the interaction (vertical and horizontal) of these models for an end-to-end QoS.
This chapter will mostly deal with network considerations, staying within the basic layer, but we must remember that a viable solution requires a global model that goes back to the user of the service (be it an application or a human being).
In order to be able to discuss the requirements in terms of QoS and to be able to establish contracts and verify afterward that the clauses are respected, we need a clear set of criteria.
When we get into technical considerations, it is much easier to define the parameters and to be objective in their evaluation (which does not mean that the measurement is easy).
The relevant parameters can vary according to the environments and there is not really a universal criterion (except maybe for bandwidth). However, we can name five parameters that are traditionally found associated with networks and that have a direct impact on applications: availability, bandwidth, latency, jitter and loss ratio.
These parameters are not completely decorrelated, but allow for different needs.
In this section, we will try to give a precise definition, to show the impacts on applications and to identify the multiple elements responsible for their degradation.
Network availability can be defined as the ratio between the time when the connection to the network was available and the total time that the system should have been open. We then get a percentage that gives us a first glance at the offered service. For example, if there were three failures last week lasting a total of 5 hours, we could say that the network was available 97% of the time during the week.
We must be careful here because this parameter only takes into consideration the network connection, with no other measurement of quality. There is nothing to tell us that during the network availability periods, the global QoS was sufficient to execute the user’s applications properly.
That is why we will also find another notion, which is availability of service. This more general notion is defined as the ratio between the time during which the network offered the expected QoS and the total time the service was available. This indicator will obviously be inferior to the previous one.
It is important here to clarify subjective perceptions, which we mentioned earlier. If a user uses the network twice during the week and he encounters an interruption of service his second connection, he will feel like he had a 50% availability rate, even if objectively the availability was 97%. It is therefore important to clearly define the criteria, the measuring tools and to clarify the reports.
In order to avoid redundancy with the other parameters, we generally take into account the availability of the network connection, which is defined separately from the other parameters.
Several factors will come into play to determine the impact on applications. The main factor will be the length of time during which the connection is unavailable. However, this time will be more or less critical depending on the application used.
Simply put, we can say that if the disconnection time is long enough, the application will be alerted and the associated service will be interrupted. On the other side, if the disconnection time is short enough, mechanisms of the transport layer will mask this interruption and ensure continuity of service. An example of this continuity can be seen during a TCP session. If we unplug and replug the network cable, the session does not go down.
However, even if the connection with the application is held, thus masking the network outage, it will still have an incidence on QoS. In reality, all the parameters will be affected. The resent packets will have a more important routing delay, risking jitter. Furthermore, the available bandwidth is reduced to zero during the break, and possible congestion control mechanisms can be activated and reduce the throughput, even when the connection is back (slowstart TCP). This can be translated into degradations at the application level, without incurring loss of service. For example, telephony over IP session can be maintained, even though the user has experienced the break-up in the middle of a word.
The causes for network connection loss vary and are mostly due to some kind of outage. There is another cause that is not so rare: maintenance operations.
It is indeed frequent to have intentional interruptions of service on certain networks. This can happen with operators during important migrations (at the time of a changeover). Certain suppliers of mass ADSL access, for example, disconnect their service every 24 hours. These interruptions are very short and are mentioned in their contract clauses. They are, as much as possible, planned for times when the least number of users will be affected, but some people take advantage of the night times to download and may have noticed a network outage (that might have lead to a change in their dynamic IP address).
Bandwidth is probably the most widely known parameter. Most of the operator offers mention throughputs, commercially at least. We often illustrate bandwidth as the width of a pipe. We also show the image of a highway and imagine the bandwidth as the number of available lanes.
More precisely, the bandwidth is defined as the number of bits that can be transmitted per second, or today as the number of kilobits (Kbit) or megabits (Mbit) per second. When we speak of a 512 Kbit/s connection, we mean a bandwidth of 512 kilobits per second.
When we speak of bandwidth, we sometimes make a distinction between gross bandwidth and useful bandwidth. In WiFi networks, for example, we can say that 802.11b can supply a bandwidth of 11 Mbit/s, but a useful load of only about 6 Mbit/s. The difference is caused by the fact that control and signaling traffic does not represent the communication data. In the QoS network parameters, we refer to gross bandwidth because it is not always possible to calculate the precise useful load (which depends on the applications used).
Another fact to consider is the application domain of the bandwidth which looks at the possible throughput between two points. In the case of an operator that supplies an Internet access, we generally refer to the bandwidth between the customer’s hardware and the operator’s network. There is no guarantee concerning zones out of the operator’s network. We could then have a 2 Mbit/s leased line and do a file download on another network that is limited to 10 KB/s. In the case where it would be important to guarantee bandwidth through multiple networks, we must have reservation mechanisms (whether they are static or dynamic like RSVP). We are now talking about end-to-end bandwidth.
In conclusion, we should mention that the bandwidth concerns one given direction, for example, in sending. It is entirely possible to have different values in both directions, whether the connection is symmetrical or asymmetrical.
The impact will vary according to the nature of the applications, since some of them will be able to adapt to a smaller throughput, whereas others will not be able to function.
Among the applications that can adapt, we have file transfer. Even though the speed of transfer is the main QoS parameter for this application, it is still possible to continue to transfer data with a lower throughput. This is especially true if the transfer does not contain much data, as is the case with sending emails or during Web browsing (if we put aside slow loading graphics). The impact will then not be as much at the application level but more for the user who might find it slower (if he is waiting for the end of a file transfer, for example).
It is important not to minimize the impact of the bandwidth for transfers because it may be vital sometimes. Many corporations start backups and programmed synchronizations during the night or over the weekend, and start other automatic operations later. A long delay in the backup process can cancel the procedure and even, in the worst-case scenario, compromise the integrity of the data if another operation starts before the end of a synchronization.
Examples of applications that adapt poorly are those that require a constant or minimal throughput. Some of those include telephony over IP, streaming content (audio and video), etc. With telephony or videoconference, under a certain throughput threshold, correct encoding becomes impossible and communication may be interrupted. In the case of streaming content there are buffer mechanisms that absorb the temporary bandwidth decrease and synchronizing mechanisms in case data gets lost. But then again, after a certain threshold, the application cannot continue. At best, it can put the transmission on hold (if it is not live).
The bandwidth depends on the physical supports used, but also on the processing capacity of the feedthrough network equipment.
In general, it decreases when congestion is detected (by the TCP flow control, for example). When no measure is taken to guarantee QoS, the network functions in best effort mode. If more than one application is using the resources, these are allocated more or less evenly, thus reducing available bandwidth for each application.
Congestion should not logically happen if the bandwidth is guaranteed and therefore reserved. There are always breakdown or deterioration risks of the supports and equipment. Material problems (cables, network cards) can generate important error rates and increase the resending of packets. Hardware breakdowns can force a changeover to emergency hardware, which makes it possible to maintain the network connection, though in low quality mode, their capacity being sometimes inferior.
It is also possible that an operator incurs a peak of significant traffic, which has not been anticipated and is then found at fault if he practices overbooking, offering more resources than he actually has (somewhat the same as what we see with airline reservations). This behavior is not aberrant as long as it is possible to perform statistical estimations and it is rare that all customers will use the complete bandwidth dedicated to them all of the time. We do not see this behavior much anymore, however, since the operators today apply an oversizing policy, which is easier to maintain and less expensive, due in particular to optical technologies. An interesting consequence is that we sometimes see today the extreme case reversed, where the available bandwidth is superior to the one negotiated (the bandwidth negotiated is then considered minimum).
The delay corresponds to the time a packet takes to cross the network, from sending the first bit to receiving the last bit. It depends on:
– the support: the propagation time varies according to the technologies used. Fiber optic communication, for example, is much faster than a twisted pair or satellite communication;
– the number of hardware crossed: each piece of equipment will add processing time to the packet. This delay depends on the equipment. Therefore, a switch will process faster than a router translating addresses;
– the size of the packets: serialization time is also taken into account, i.e. the time required to send the packet on the network link bit by bit (same thing for the reception).
This definition helps to understand that it is not enough to increase the bandwidth in order to ensure better delays, contrary to what we may sometimes think. We can recall here the analogy with highways. The bandwidth corresponds to the number of vehicles passing through a fixed mark per second. The speed being limited at 130 km/h and security distances respected, we must increase the number of lanes on the highway in order to increase throughput, going from 2 to 4 lanes, for example. We can then double the bandwidth. However, with the speed still limited at 130 km/h, a vehicle will still take the same amount of time to reach his destination and therefore the delay as not changed.
In the case of bandwidth decrease, particularly because of congestions, there can be a notable increase in the delay of certain packets that end up in queues or are simply deleted (or resent later).
Some applications, by nature, require very short delays and therefore very low network latency. It is the case with interactive applications, but also with applications requiring a strong synchronization between equipment and networks.
Telephony is an example of an interactive application where delays must be low in order for the utilization to be comfortable (we estimate that 100 ms is the maximum). A delay that is too long disrupts communication and causes repetitions and interruptions. This problem can easily be seen when you look at TV news channels during conversations with correspondents on foreign soil. Communication often goes through satellite, where delays are very long (they may reach 500 ms). In almost every case, we see the announcer ask a question and when he does not get an answer within his comfort interval, he asks the question again. Immediately after, the correspondent starts to answer and stops (he is receiving the question the second time it was asked), apologizes and continues his response. The problem happens the same way if one of the speakers tries to talk over the other. Put in network terms, the delay surpasses the time-out for the receipt of the message and therefore it is resent.
The problem with strong synchronization is a little different since it is not possible to compensate by resending if the message takes too long to arrive at destination. Contemporary applications that illustrate this problem are network games, in particular real-time combat games. Most of the time, movements are extremely fast and a very short delay is imperative in order to synchronize the position of the adversaries.
In order to give a professional example of such an application, we should consider online banking, especially market operators. There are networks offering real-time information flow (Reuters, etc.) and there is also a network where orders are placed. These two networks are critical. If he does not have accurate on-time information, the operator can miss an important deal and if his transactions are not registered fast enough, he can easily lose enormous amounts of money. This is true for manually entered orders, but is even more critical in the context where we find multiple reactive automatons that can rapidly place orders.
Globally, we can say that any application with real-time constraints (or close to real time) is impacted by problems with delays.
The different elements that can affect the value of latency have been described in the previous definition.
Except in very special cases, serialization and propagation times are not deteriorating factors because their variance is limited and is pretty well controlled. If we want to see the impact of serialization, we can play around by testing the UNIX ping command. By choosing a machine on the local network and by varying the size of the test packets (between 50 and 1,024, for example), we will often see a 2 factor in the result.
The most critical point is the network crossing equipment. Each component produces minimum processing, which is necessary in order to function properly. This defines its minimal delay, which is not only linked to the reception and sending of packets, but also to processes. In the case of a router, there needs to be an analysis of the destination and of the routing table. If this router integrates QoS control mechanisms, this complicates somewhat the processes (we will show some examples later on). In the case of a bridge, if we must fragment packets, encapsulate them into another technology, translate addresses, filter them, etc., latency will be increased.
As we can see, the more active and intelligent the network components, then the more the delay increases. Technologies and components have to be very powerful, but as simple as possible, in order to reduce the delay. This explains the importance of evolved switching techniques (MPLS and others) to lighten processes in the heart of networks.
Jitter is the variance in the latency. It measures the distance between the transmission delays of the different packets in the same flow.
It is possible to have a clear idea of the minimum time that a packet will need to go through the network, but it is harder to know the exact time because of the multiple flows that are present on the network as well as all the components that come into play. Even in the absence of congestion, we see variations of latency. We can again use the ping command and see that on many occurrences we do not find the exact same value, whether it is on the local network or, more logically over the Internet.
Jitter is therefore non-zero, but this does not cause problems unless the gaps become important.
We can again identify different consequences, depending on the applications. However, the ones more sensitive to jitter are those evolving in the multimedia world and that need synchronization.
We have seen that latency is critical and could compromise the operation of connections if it is too high, whether it is caused by time-outs or insufficient quality. There are, however, applications that can adapt to network constraints such as high latency (without exaggerating) and low bandwidth. Streaming applications, whether we are talking about listening to an audio flow (radio on the Web, for example) or watching a video (rebroadcast of a remote event), can in general offer multiple coding quality values, according to the available bandwidth. Since the communication is not interactive, the delay problem does not have the same impact, for it is possible to receive the flow with a delay of a few hundreds of ms, maybe even a few seconds. The constraint here is essentially having a constant flow and relatively stable inter-packet delays. In reality, even if the video is completely rebroadcast, it is not advisable to have pauses in the middle or even to slow down the action! An image arriving later than expected would be pointless, deleted and would include a blank space in the video rendering, generally visible (in the case of relative coding, where the transmission is not of an entire image but of the differences, the loss of only one packet can disrupt the display during many seconds if the action is slow). Thankfully, there are mechanisms within the applications (memory-buffers, for example) that can compensate for the inevitable jitter. However, these mechanisms have their limit; they can only handle a set maximum variation. If there is a serious congestion, they can be insufficient. In certain instances, as we can see here, a lower latency may not necessarily be a good thing. Packets arriving too early will be memorized in the buffer, but will be deleted if the buffer is full (although we can always ask for a rebroadcast).
We have recalled above a latency adaptation mechanism, especially to jitter. For other applications, one way to control jitter will be to size time-out values somewhat wider than necessary. However, we cannot exaggerate the values, as this would diminish its responsiveness in the case of a real problem (packet lost and not delayed, for example).
The elements that will contribute to jitter are obviously linked to elements that initially define latency. Therefore, a piece of network hardware, during congestion, will take more time to treat packets, to control its queues and thus will increase its routing delay. One thing to consider is that the higher the number of feedthrough equipment, the greater the minimal feedthrough delay, but also the risk of jitter will increase. That is why, we prefer the shorter roads that enable a better latency control (minimum value and jitter).
Another factor to take into account is the dynamic changes of the elements involved in the calculation. During routing change, for example, the number of equipment, their nature and associated processing times can vary greatly.
For all these reasons, jitter is probably the hardest parameter to manage, especially on large networks and particularly when they are open (as with Internet).
The loss ratio is defined as the ratio between the number of bytes transmitted and the number of bytes actually received. This calculation integrates the undetected losses (for example, UDP), as well as the retransmitted data.
This makes it possible to have an overview of the useful capacity of the transmission and to identify the percentage of traffic output due, not to the client activity, but to network failures (useful data for invoicing).
There are mechanisms in place to detect and correct losses. TCP is an example of a transport layer enabling a connected mode and the retransmission management of lost packets.
Applications using this type of service are not generally concerned with loss ratio. The effects are usually due to the impact of these losses over other parameters. Thus, a very high ratio will result in a high bandwidth decrease, all the way to a network outage. In general, losses will mean retransmission of packets and therefore a consequent extension of their effective transmission delay. These are then the consequences linked to the parameters previously discussed. Such applications as file transfer or a Website inquiry will not be seriously impacted by a low loss ratio.
Applications that are more sensitive are those not using these guarantees and that rely on offline modes; multimedia applications are a good example. They can be using, for example, the RTP protocol (in order to sequence packets) which is then encapsulated into UDP. The network will not detect lost packets, as this protocol offers no guarantees. It is therefore important to keep this aspect in mind during application design in order to be able to function even with the absence of lost packets. In spite of these drawbacks, UDP is often preferred here because of its simplicity and speed, and especially because it does not implement TCP flow control, thus enabling a constant flow (amid lost packets), decreasing jitter.
One possible cause for packet loss is an equipment or transmission support problem. However, the latter is getting more and more reliable and with today’s optical fiber, the error margin reaches the 10–12 level. The level of trust for transmission support explains the fact that most new technologies execute less checks in the lower layers of the OSI model.
In practice, the major cause for loss of packets is network congestion. When a piece of equipment is saturated with respect to the processes that it can manage and its queuing capacity, it deletes the new packets.
As we have seen, QoS essentially depends on processes executed on network equipments. Whether static or dynamic architectures are put in place, or whether the solutions are based on resource reservation or flow clustering and differentiation of services, it will be imperative to be able to use a certain number of mechanisms or building bricks in order to manipulate packets at equipment level.
After analyzing the simplified case of a standard router, later on in this section, we will discuss the operating principles of a QoS router and we will detail the different mechanisms involved in order to understand their operation.
This section examines the case of an IP router, but the principles may apply to other network layers, as well as to some switching equipment.
Most of today’s available routers already integrate the mechanisms that will be discussed here, but in order to understand its usefulness, it may be interesting to go back to the basic router operation.
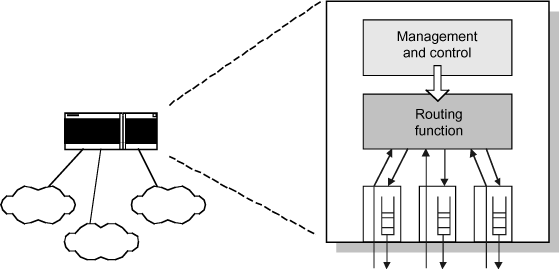
The architecture of a standard router is described in the figure below. Common components are:
– input/output interfaces, used to receive and transmit packets;
– the routing function, which is responsible for finding the destination interface of a packet from a routing table;
– management functions, which integrate equipment control functions as well as the management of routing protocols (to update its table).
The principles of operation are pretty simple:
– receiving of a packet on the router interface;
– consultation of routing table to determine the output interface to use;
– adding to the queue (FIFO – First In First Out) of the output interface. If the queue is full, the packet is deleted.
This operation can be very fast. Congestion is in the routing function, which is used by all interfaces, but the newer equipment eliminates this problem by using multiple dedicated processors and internal buses at very high throughput.
The main problem here is in the output queue, which is often FIFO.
When there is congestion, the queue fills rapidly. Once full, there is no way to process new packets and they are deleted without distinction between those that are critical and those that are not. This illustrates what we call the best effort mode, meaning that the packets will go through the equipment as long as there is no problem, but when there is congestion, the operation cannot be foreseen. Some jokingly call this mode the non-effort mode.
In order to discuss QoS, we must be able to differentiate the flows and apply processes accordingly. This means taking into account the specific needs for this or that application, as well as the requirements of the users with valid contracts.
For this, we integrate a number of mechanisms within the router:
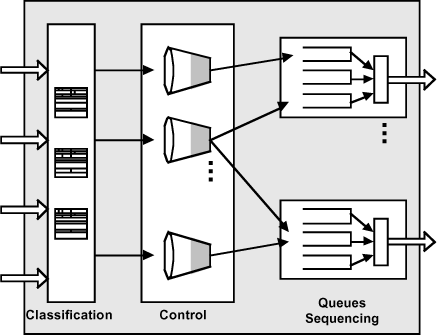
– classification: packets are analyzed at input level in order to determine the process to apply;
– policing and marking: policing enables the verification of traffic according to predictions. If this is not the case, it is possible to mark packets as out of profile for further processing (they will, for example, be deleted first);
– queuing: a more detailed control than the simple FIFO mechanisms enables the optimization of packet processes and a better congestion management;
– scheduling: packets must be transmitted for output, according to the pre-executed classification.
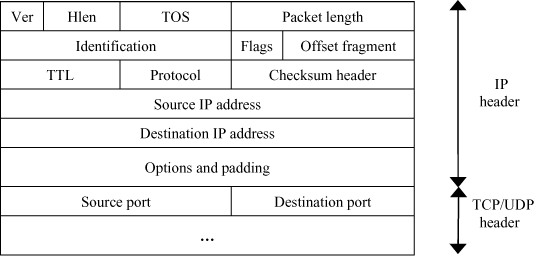
The objective of classification is to determine what process to apply for a received packet and to associate it with an anticipated traffic profile. This will be based on information within the packet, particularly its header.
The information that is used will depend on the classification type we determine, knowing that we can rely on one or more fields.
In its simplest form, we use only one byte, initially designed to differentiate IP services, called the TOS (Type Of Service) field. Practically, this field has been diverted from its initial definition and is today called the DSCP (Differentiated Service Code Point) in reference to the QoS DiffServ model that redefines it (RFC2474).
There are many advantages to using a unique field to control classification. Filtering will be faster and, in the case of the DSCP field, it stays accessible even during secure transfers (IPSec, for example). However, it is then presumed that the packets have been adequately marked previously and this limits the number of possible cases to process (in the case of bytes, theoretically 256).
We will discuss in more detail the DSCP field and the flow process in the following chapter (which describes different protocols of QoS management).
A more precise way to classify packets is to look in more detail at IP headers as well as transport (TCP and UDP). The goal being to identify a particular flow, we will obviously analyze the origin and destination of packets.
The fields more frequently used are TOS, IP source and destination addresses, as well as source and destination ports, which allow the identification of the appropriate applications in more detail. It is important to note that using the fields in the transport layer can cause problems if there is IP fragmentation. Complementary mechanisms must then be put in place in order to associate fragments in the same session.
The choices of implementation will depend on the global model that we will want to use. There are, however, certain constraints to take into account. It is especially important to determine the classification for the speed of packet arrival. In particular, it is important to execute classification at the speed of packet arrival.
There are other issues to consider. Multifield classification is not adapted to secure networks. The useful load being encrypted, the router has no access to the transport header, for example. Within the global model, we must ensure the reliability of information used for classification. Without control mechanisms, a user could send all his packets with a DSCP field corresponding to the best service, even if he does not have that right.
The objective of policing is to verify that the traffic flows according to predictions and, if it is not the case, to make sure it does not affect other flows.
Compliance is based on a flow definition previously done at the equipment level. This means making sure that the contract is respected by the transmitter. Avoiding that exceeding traffic disturbs other flows constitutes the equipment’s respect of the contract.
This is done on two levels: traffic measuring tools and management techniques for non-compliant traffic.
As mentioned previously, it is important that traffic does not affect the other flows. A simple way to solve this problem is to delete exceeding packets, but that is not the only solution.
For example, it is possible to smooth traffic within the same flow. We memorize the exceeding packets in order to transmit them later, when the volume of traffic is back below allowed resources. Of course, we cannot memorize packets indefinitely and we thus increase latency. However, if we consider that the traffic exceeds the limits of the contract, it is not critical.
We could, on the contrary, let the traffic pass by marking non-compliant packets. This marking will consider these packets as non-priority and delete them directly if congestion happens.
The advantage of this solution is that it does not introduce an additional delay and it will use the available general resources in the best possible way.
In the case of smoothing, we would take advantage of a decrease in traffic from the same flow later on.
In the case of marking, we take immediate advantage of the possible decrease of the other flows.
Marking is used during queue management within the same equipment. If we want it to spread to other equipment (not always desirable), it is necessary to use a specific field to transport the information (modification of TOS for IP or the CLP byte in ATM, for example).
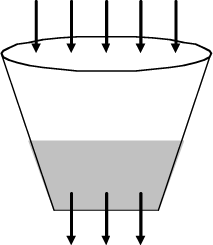
This model is defined as a mechanism based on the operation of a leaky bucket. We can fill it all we can, until it is full, but its output will be limited by the size of the hole. An example of a leaky bucket is illustrated in Figure 2.6.
The parameter that defines the hole makes it possible to control precisely and limit the output bandwidth. If the input traffic varies, this mechanism enables a more regular output.
The bucket’s capacity, although limited, will accept specific traffic and will smooth it. Once the limit is reached, exceeding packets are then considered non-compliant.
The major drawback for this mechanism is its output limit. We cannot take advantage of the fact that our network is not full, at some point, to empty the bucket and thus avoid possible saturation while decreasing latency for the queuing packets.
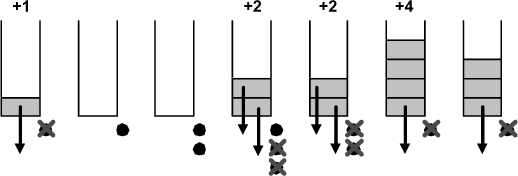
This model is based on a token mechanism. These tokens are allocated regularly and indicate how many packets can be output.
In the figure above, we see the evolution, over time, of the content of the bucket. Each moment, an additional token is allocated (black spot). The number on top (+ n) indicates packets arriving. The arrows show which packets are transmitted, with the crossed out tokens (consumed).
As you can see in this example, we minimize the leaky bucket model problem. Even though we only allocate one token at a time, we can recognize the output of two packets. Furthermore, if we look closer, without the management by token mechanism, a packet would have been deemed non-compliant at the sixth interval (4 packets arriving). Therefore, we can better control the output bandwidth and we avoid packet deletions.
This mechanism offers more flexibility than the previous mechanism but it must stay compliant with the initial output contract. Instead of being limited to a specific level, the output bandwidth is averaged. The peaks should not get too big and therefore we must limit the number of memorized tokens (this number defines the bucket’s peak output).
We must note that this mechanism, even though it corresponds to a way of implementing flow control, is also used to specify the traffic models for negotiations (RSVP, for example), and this should be done independently from the actual coding of equipment control mechanisms.
The objective for the queue management mechanism is to optimize traffic processing by taking into account peaks, for example, and it is also responsible for the minimization of the size and placement of queues. This last point is important in order to reduce delays and processing time adding to global latency. It is a matter of finding the correct compromises and having mechanisms in place to control congestion and avoid queue overflow.
In order to do this, we must ensure an active flow control, anticipate congestion and attempt to regulate faulty transmitters. This regulation has to go through TCP flow control, since UDP does not supply an appropriate mechanism. We normally presume that the IP traffic is essentially composed of TCP packets.
The goal of flow control is to decrease the transmitter’s throughput in order to resolve or anticipate congestion problems on the network.
This should be done in an explicit manner. The transmitter must be advised to decrease his transmission window. This makes it possible to target the guilty party but, at the moment, there is no standard defined for IP (there are, however, some propositions such as RFC2481).
Then, the following must be done in an implicit manner, i.e. ensuring that the remote TCP layer detects a problem and acts accordingly. To do this, it must delete exceeding packets. The TCP layer then automatically reduces its window. This solution, however, creates new problems. On the one hand, it is difficult to target the guilty source, but more importantly we risk affecting all sources and so have a quick return of congestion (all flows coming back at the same time to their maximum throughput, when bandwidth becomes available again).
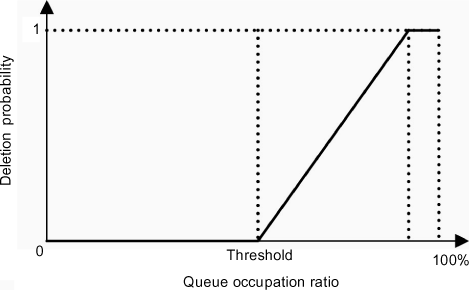
To improve this mechanism, we use more complex packet deletion methods. The most commonly used method is RED (Random Early Detection).
In order to avoid congestion, we will start by deleting packets randomly before queue saturation. As we can see in the figure above, we first define a queue usage threshold. Once this threshold has been reached, each new packet arriving has an increased chance of being deleted, reaching up to 100% just before full queue saturation. The advantage to this is that not all transmitters are affected at the same time and we reduce the total number of deleted packets. Evidently, traffic must be TCP and the source must be affected by the deletions in order for this to be an efficient solution, but this technique is statistically valid.
We can name a few other techniques extended from RED:
– WRED (Weighted RED): multiple thresholds within the same queue, that can receive different types of traffic with different priorities, are defined. The lowest threshold is associated with the packets with the lowest priority;
– RIO (RED with In/Out): is a variation of WRED which defines two thresholds, the lowest being associated with the packets previously marked out of profile;
– ARED (Adaptive), FRED (Flow), etc.
Each technique addresses a particular problem and more than one can be used on the same equipment, depending on the context and the global QoS model.
In conclusion, we can point out that these mechanisms all work under the presumption that the TCP congestion control is correctly programmed, i.e. that the transmitter actually reduces its throughput window when packet loss is detected. There are implementations that work quite differently. This matter is discussed in RFC2309 (Recommendations on Queue Management and Congestion Avoidance in the Internet).
The last mechanism to be discussed here, sequencing, transmits in the correct order the outgoing packets through the equipment.
In the case of a unique FIFO queue, as seen previously, control is managed completely upstream. Packets are transmitted in the order in which they arrive. On the other hand, when many queues are associated with a single interface, it is important to have rules to sequence the packets and empty the queues. We will present two mechanisms that will show the issue. Many others exist and are either variations or combinations of these. You could actually find different mechanisms within the same equipment.
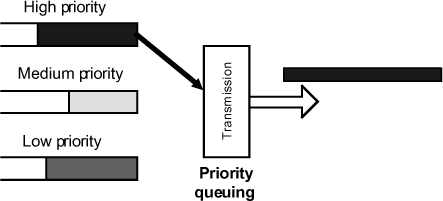
In this case, there are multiple queues that correspond to different priorities. The object is to manage the transmission of the packets respecting these priorities precisely.
The transmission will start with all packets in the high priority queue. Once that queue is empty, it goes to medium priority queue. It is easy to understand the problem that this mechanism brings: the priority queue can monopolize bandwidth. This mechanism makes sense if there is only one category of traffic that must take priority over everything else, for example, critical control flows.
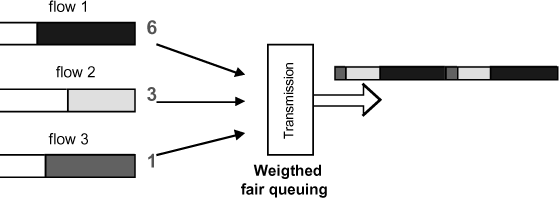
The goal of weighted fair queuing is to share network usage between multiple applications, each having its own minimum bandwidth specifications. Each queue has a weight factor, according to its desired bandwidth.
In simple terms, the example in Figure 2.10 shows that when all queues are used, the sequencer transmits 6 packets from flow 1, then 3 packets from flow 2, 1 packet from the last flow and then starts again. If a queue does not have as many packets as the weight indicates, we move on to the next queue, which enables free bandwidth to be used.
In reality, this mechanism is less simple than it seems. Actually, the used bandwidth does not depend strictly on the number of transmitted packets, but also on their size. It is therefore important to consider this during weighing calculations (we will not go into further detail at this point). The theory remains the same, however, and helps to ensure a minimum bandwidth at every queue and to allocate the unused bandwidth fairly.
An overview of a QoS router is presented in Figure 2.11. On the inbound side, note the classification mechanisms, which will lead the identified flows toward the control tools. Once over this filter, and eventually marked, the packets will be associated with an outbound queue, according to the interface that will be used, as well as to the QoS associated to the flow. The queue control mechanisms will then be responsible for managing congestion, while the sequencers will be responsible for transmitting the packets on the router’s outbound interfaces.
These are all mechanisms that will help control and guarantee the network parameters presented earlier (availability, bandwidth, latency, jitter, loss ratio). They constitute the basic layer that must be configured and used in the framework of a global model in order to provide end-to-end QoS between the transmitter and the receiver. Architectural and integration (vertical and horizontal) problems between the different technologies need to be addressed. The next chapter describes the main models and protocols in use today.
1 Chapter written by Benoît CAMPEDEL.