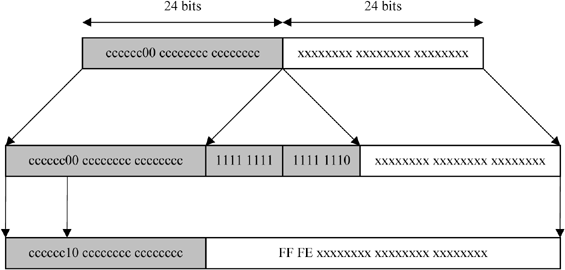
Figure 10.1. Two-level address structure

The Internet makes it possible to interconnect different heterogenous networks thanks to a common protocol: the IP protocol. The link layer frame is transmitted from point to point, whereas the IP packet it contains is sent on the network due to a routing technique. Thus, all the network machines are able to exchange data, without involving the link protocol. However, to be reachable, each machine must be identified with at least one address that must be unique on the IP network. The first addressing problem arises: how can IP addresses be efficiently allocated from the whole of the addressing space?
The value of the IP address is all the more important as it determines the routing of packets. An IP address contains location information with regards to the network to which it belongs. This information makes it possible for the router to determine the destination network among all the networks it knows. The addressing scheme of an IP network therefore affects routing and its performances. A second problem then emerges: how can addresses be allocated such that the routing technique is as efficient as possible?
At the beginning of the 1980s, a first IP protocol version was standardized to address these problems, but this standard has not stopped evolving. This chapter will endeavor to retrace the main evolutions in IPv4 network addressing and then those for IPv6, which is the new version of Internet Protocol.
RFC 791 definitively standardizes addressing rules for an IPv4 network interface. No matter what interface it is, it must have a unique 32-bit IP address. The network elements, whose tasks are, for example, to route IP packets have at least as many IP addresses as they have interfaces. This first RFC standardizes IP network addressing by defining several address classes, which are detailed later on.
This notion of class is designed to bring flexibility in IP address assignments. Each class has a different number of addresses and is composed of block addresses of different sizes assigned to an organization according to its needs.
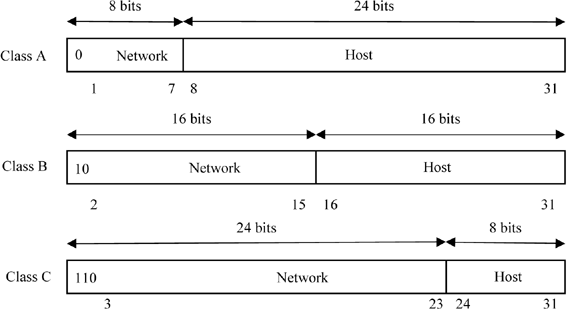
This first specification defines a logical splitting of IP addresses into two levels: the network and the host. These two parts are distinguishable due to the analysis of the first high bits of the IP address. The first part, called the network number or the network prefix, identifies the network on which the host resides. The second part, the host number, identifies the host on this network. We therefore have a two-level addressing illustrated by Figure 10.1.
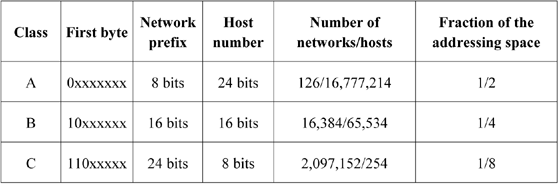
The number of possible networks in a class and the maximum number of network hosts are defined by the length of each part. Many classes were proposed in order to define different sized networks: classes A, B, C, D and E. The first three are destined to unicast addressing, in other words, addresses that are routable on the entire Internet. Class D is used for multicast addressing and class E is reserved for experimental uses. These last two classes are used only marginally and will not be addressed in this part.
In order to know to which class an address belongs, only the first high bits are needed. A router will therefore be able to determine where the network prefix ends, thus making it possible to search for a route in its routing table. Table 10.1 gives the number of networks and the number of hosts corresponding for each unicast addressing class. This table also gives the proportion of total space usage for each of them. The calculation takes into account the fixed part of the network prefix as well as the cutting off of certain special addresses, mentioned in the next section.
The dotted-decimal notation was specified to ease the reading of IP addresses. The series of bits is represented in the form of four integers, corresponding to the four bytes of the address, separated by dots.
Therefore, an address whose value is 10000100 11100011 01101110 11001111 is a class B address identified by its network prefix starting with the 10 bit string. This address can be written as 132.227.110.207 in decimal notation.
Precise uses have been specified for special addresses, among which the most common ones are cited here as examples:
– 127.0.0.0: this class A address is reserved for the local loop, in other words, the address of the machine itself;
– 0.0.0.0: is solely used as source address. This reserved class is used by a host when the network number is unknown and must be interpreted as “this host machine on this network”;
– 255.255.255.255: is solely used as destination address. This special address corresponds to a limited broadcast address and therefore makes it possible to reach all the machines in the local sub-network;
– 192.168.0.0: this class B address is reserved for addressing machines on a private network. Addresses of this class are not unique, and can be assigned without constraint if they are not used on the Internet;
– RFC 3330, the most recent update, entirely redefines these special addresses.
This first IP specification, defined in RFC 791, introduces the use of classes for the IP protocol. It has been really successful since this standard is used worldwide, tending to become the sole level 3 protocol. However, its success has also quickly shown the weaknesses in its addressing system: in fact, it obliges a network administrator to ask for a new addressing class for each new network installed, no matter its size. This being the case, a large number of addresses have been wasted due to biased distribution. In addition, the size of the mail routers’ routing tables has greatly increased.
A simple example shows the inadaptability of this addressing system. The distribution of class B to numerous companies that need just over 254 addresses has quickly shown that:
– each attribution of this type has caused a large waste of IP addresses;
– the number of available class B addresses has rapidly and worryingly decreased, and the size of Internet routing tables has proportionately increased.
In addition, companies legitimately requesting class B addresses have had to face a shortage and content themselves with many class C addresses. With the result of making the administration of such a network more complex, the size of routing tables has even more quickly increased and has reached an alarming level. In this context, a new specification has been made necessary in order to optimize the attribution and use of address classes.
The subnetting technique was specified in 1985 in RFC 950 to improve two-level addressing techniques in IP networks. This technique consists of adding a third hierarchical level and is destined to be used internally by an organization.
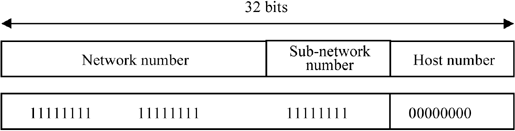
A third level of hierarchy divides the host number into two sub-parts: the sub-network number and the host number on this sub-network.
These three parts of the address are used in different ways according to whether they are used at the global Internet level or in an organization’s internal network. In the first case, the routing technique remains the same and each router identifies a network from the network number in the address. Within the organization, the extended prefix is used: the concatenation of the network number and the sub-network number. This extended prefix makes it possible to define many sub-networks based on the internal needs of the organization.
In order to know where the border between the sub-network number and the host number lays, an extra piece of information is necessary: the sub-network mask. A mask is constructed in the same 32-bit format. The bits set to 1 in the mask indicate the length of the extended prefix. It must be noted that in this technique, the sub-network mask is longer than the network number. This makes it possible to identify different sub-networks in the address class attributed to the organization.
The mask is written in dotted decimal notation. Thus, the mask 255.255.255.0 will have its first three bytes set to 1 and the last to 0. However, this notation is not ideal to determine the length of the extended prefix. A new notation is used: the notation based on the / (slash). This makes it possible to give an IP address followed by the size of its mask: an address 132.227.110.207 with a mask 255.255.255.0 will be written as 132.227.110.207/24, 24 being the number of 1 bits in the mask. Figure 8.3 illustrates this example.
The three-level addressing model guarantees the invisibility of the splitting into sub-networks with regards to the external world of the organization. Whichever the granularity of the split, each Internet router only has one route to the group of defined sub-networks: the one defined by the attributed class that aggregates all the internally created sub-networks. It is therefore possible to create new networks, in reality sub-networks, without adding any entry in the routing tables of the Internet routers.
A current use of subnetting consists of creating, from a class B address, a multitude of sub-networks differentiated by the third byte of the address.
In addition, when creating a sub-network, the administrator does not need to request new IP addresses. Subnetting makes it possible to reuse previously allocated addresses to create a new network.
Beyond the economy of addresses and the struggle against the growth of routing tables, subnetting also makes it possible to avoid the propagation of routing table modifications. This phenomenon called route flapping is encountered when an administrator modifies the structure of the network. In the traditional addressing scheme, each modification of the smallest network must be reflected in all of the Internet routers. Scaling this mechanism is worrying in a global network in permanent extension. Subnetting makes it possible to limit route flapping because the administrators can modify, add and remove sub-networks without affecting their global visibility.
This mechanism requires modifications in the internal infrastructure where it is implemented. In fact, not all routing protocols enable the transport of sub-network masks. Nonetheless, current routing protocol versions exchange the network number and corresponding mask with each other.
However, this subnetting technique quickly shows its limitations: all the created sub-networks must have the same size. In fact, in subnetting, a network’s addressing space is divided into a determined number of equally sized sub-networks. This leads to unoptimized addressing schemes where addresses are wasted. If an organization needs to divide its network into sub-networks of different sizes, the smaller sub-networks will have the same number of available addresses as the larger ones. A large number of addresses are therefore wasted.
In 1987, RFC 1009 defined the use of sub-network masks of varying lengths, in order to optimize the allocation of sub-networks. This technique is called variable length subnet mask (VLSM) as it is based on a variable length of the extended prefix.
This specification thus mitigates the problem of same-size sub-networks. It also introduces a new possibility in the allocation of the addressing plan of different sub-networks: the recursive splitting of addressing space makes it possible to aggregate routes. A network is split into many sub-networks of the same size, which are themselves split into other sub-networks, and so on. A single route announcing the network of a given level suffices to route toward all the lower-level sub-networks.
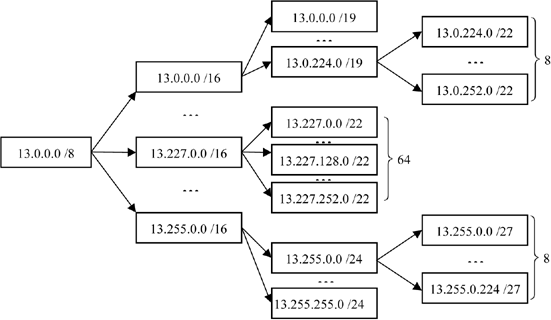
An organization with a class A written as 13.0.0.0 can therefore divide itself into sub-networks whose addresses are 13.X.0.0/16. Due to the specification proposed by VLSM, each of these sub-networks can be split into sub-networks of different sizes. Figure 10.4 illustrates the possible splitting of an addressing space.
In this example, the class A address is split into 256 sub-networks/16. Three of these are split into sub-networks of different sizes: 8 sub-networks/19, 64 sub-networks/22 and 256 sub-networks/24. Finally, two of these sub-networks are each split into two groups of 8 sub-networks.
From the point of view of the routers within the Internet, a single route is necessary to announce all the sub-networks created. Internally, the announcement of route 13.255.0.0/16 makes it possible, for example, to route 264 sub-networks. The aggregation of routes makes it possible to create a large quantity of sub-networks without increasing the size of the routing tables in higher levels.
So that this technique can be used in an organization’s internal network, it must respect certain constraints. Like subnetting, a routing protocol that transports sub-network masks, such as OSPF or RIPv2, is indispensable.
The routers must also implement an adapted routing algorithm. In fact, in the example illustrated in Figure 10.4, sub-networks can have the same address but different masks. A router looks for the most adequate route for a packet among a group of identical prefixes but of different masks. With a classic routing algorithm, the first route will be chosen, whereas the IP packet can be destined to a different sub-network.
A “longest prefix-matching” algorithm is therefore required to implement a correct routing strategy. This algorithm consists of applying the concerned sub-network masks by the packet in order to choose the sub-network with the longest extended prefix. By following the principle of aggregation, the route with the longest extended prefix is more specific than one with a shorter prefix. The router therefore selects the more specific route to forward a packet to its destination.
One last point remains to be respected in order to use VLSM while aggregating the optimal routes. The splitting of the addressing space must follow the network’s topology so that a route represents the maximum of sub-networks. If the network’s topology is totally respected by the hierarchical splitting of the addressing space, a single and unique route will suffice for routing toward all the lower level sub-networks.
A larger flexibility is therefore obtained due to VLSM, which makes it possible to recursively split the addressing space according to the organization’s needs. Moreover, by respecting the network’s topology, we get an optimal aggregation of routes. However, these advantages can only be applied within the organizations. The attribution of classes A, B or C remains the same and routing based on them does not profit from route aggregation introduced by VLSM.
In 1992, a lack of addresses was foreseen and B class addresses were almost all attributed. In addition, the size of routing tables within the Internet increased dramatically. A series of RFCs (RFC 1517, RFC 1518, RFC 1519, RFC 1520) was therefore defined in order to reclaim the advantages introduced by large-scale VLSM: this is the CIDR specification (classless inter-domain routing).
This specification proposes a radically different routing mechanism within the Internet. CIDR is called classless because the use of classes A, B and C is abandoned for an address attribution mode that better suits the needs. This new specification reclaims the functioning mode of VLSM by applying it to the entire Internet. We therefore benefit from the advantages of VLSM: the allocation of addresses is more efficient and the aggregation of routes makes it possible to relieve the core routers.
The use of network prefixes is now generalized throughout the Internet. All network addresses are therefore announced with their network prefix and it is possible to attribute blocks of addresses of arbitrary sizes. The first three bits of an address are no longer taken into account by the routers that are based on the announced network’s prefix.
The principle of varying size prefix is used to optimize the use of addresses. An Internet access provider is no longer constrained to waste a number of addresses by attributing the number of necessary classes to cover a company’s needs. In fact, it could not previously attribute anything but classes A, B or C, in other words blocks of addresses with /8, /16 or /24 prefixes. With CIDR, the access provider can split its addressing space as it wants and assigns, for example, an /11 or /19 address. The allocation is therefore more optimized and the size of routing tables is reduced: one route is enough to announce a network, whereas before it took as many routes as there were classes assigned to an organization (often more class Cs to meet the needs of an organization).
An organization that needs to attribute a certain address can also split it to give blocks of addresses of varying sizes, which can also be split. This results in a recursive splitting on the scale of the Internet.
As with VLSM, this recursive splitting makes it possible to aggregate routes. At each level, we only take into account the allocated blocks of addresses. Each route corresponds to a network and suffices to announce all the networks issued from it. Thus, an access provider only announces, on the Internet, one route per contiguous address space block that it administers, which suffices to announce all its networks. There again, the size of routing tables is reduced and makes it possible to have better performances and easier network administration.
The deployment of CIDR requires the same functionalities as VLSM: a routing protocol that transports network prefixes and implements a longest prefix matching algorithm. However, since CIDR no longer takes address classes into account, classless routers are indispensable. The first three bits no longer indicate the network prefix and must no longer be taken into account by the routers. Finally, the allocation of network addresses must follow the network’s topology so that route aggregation is as efficient as possible.
Due to CIDR deployment, addressing space is more efficiently used and the size of routing tables is reduced. But its efficiency is linked to the topology, which can become difficult in certain cases. When an organization wants to change its access provider, it does not necessarily want to change its entire addressing plan, since renumbering can be costly. In this case, a routing exception indicating the route to this company’s network is therefore necessary to indicate the path to follow. This exception makes it possible to reach this organization’s network and not the network of their former access provider. This type of exception is more and more prominent and increases the size of routing tables.
Nonetheless, a highly hierarchical organization of address space is the most adapted solution for a network as extended as the Internet. The routers that form the network route the packets at their hierarchical level. They mainly know the network addresses along the same hierarchical level due to route aggregation. This considerably reduces the size of routing tables and enables an acceptable performance.
The new IP protocol specification, IPv6, is also based on a hierarchical network organization and reuses the basic CIDR principles. The use of network prefixes of varying sizes and the aggregation of routes possible by a strong hierarchy have been retained for this new protocol. In the following section, we will detail this protocol’s principal innovations and notably the hierarchical structure imposed for the construction of an IPv6 address.
In order to adapt to the needs of new packet networks, a series of points has been modified in the IPv6 standard in relation to its IPv4 version. In this section, we will endeavor to describe the standard IPv6 addressing.
The IPv6 communication protocol defines and uses 128-bit (16 bytes) addresses. Although the size of the IPv6 packet’s address field enables 3.4 × 1038 combinations, the addressing space was defined in order to enable several network hierarchy levels. Thus, this network hierarchy makes it possible to define sub-networks, from the largest Internet backbones to any sub-network in an organization.
The IPv6 addressing structure includes the last improvements made to that of IPv4. IPv6 addressing is thus defined hierarchically with variable length masks. This makes it possible to optimize the size of routing tables within the routers.
In addition, IPv6 defines multi-level address organization in order to guarantee a total hierarchy. Due to the implementation of different levels of service providers within the addressing structure, the routing table structure corresponds to the real physical organization of different level ISPs.
In order to simplify host configuration, the IPv6 protocol supports both a stateful and a stateless configuration. Thus, the nodes that have an IPv6 stack will be able to receive an address from a stateful configuration through, for example, a DHCP server. The IPv6 nodes will also benefit from a stateless configuration by auto-configuring themselves.
In the case of stateless auto-configuration, the nodes are capable of defining their local address to communicate with their neighbors on the link and also their global address (routable over the Internet) derived from the sub-network prefix announced by the routers.
As was mentioned, the size of IPv6 addresses is 128 bits, which enables approximately 3.4 × 1038 combinations. With IPv6, it becomes truly difficult to imagine that a new lack of addresses could occur. In fact, to put these values into perspective, the number of possible combinations given by IPv6 makes it possible to allocate 6.5 × 1023 addresses for each square meter of the earth’s surface.
Of course, the choice of the value of 128 bits for the size of IPv6 addresses was not made according to the number of possible addresses per terrestrial square meter. This value was chosen in order to enable the organization of a better hierarchical sub-network structure. In addition this value of 128 bits enables a greater flexibility in the organization of different operator networks.
Similarly to IPv4, IPv6 address spacing is divided into different uses. This distinction between different address types is based on the high bits. Their value is fixed and is often referred to with the term format prefix (FP). This allocation of address types is detailed in Table 10.2.
Table 10.2. Distribution of addressing space
| Allocation | Format prefix (FP) | Fraction of addressing space |
|---|---|---|
Reserved |
0000 0000 |
1/256 |
Unassigned |
0000 0001 |
1/256 |
Reserved for NSAP allocation |
0000 001 |
1/128 |
Unassigned |
0000 010 |
1/128 |
Unassigned |
0000 011 |
1/128 |
Unassigned |
0000 1 |
1/32 |
Unassigned |
0001 |
1/16 |
Unicast and aggregatable addresses |
001 |
1/8 |
Unassigned |
010 |
1/8 |
Unassigned |
011 |
1/8 |
Unassigned |
100 |
1/8 |
Unassigned |
101 |
1/8 |
Unassigned |
110 |
1/8 |
Unassigned |
1110 |
1/16 |
Unassigned |
1111 0 |
1/32 |
Unassigned |
1111 10 |
1/64 |
Unassigned |
1111 110 |
1/128 |
Unassigned |
1111 1110 0 |
1/512 |
Local link unicast addresses |
1111 1110 10 |
1/1024 |
Local site unicast addresses |
1111 1110 11 |
1/1024 |
Multicast addresses |
1111 1111 |
1/256 |
All the unicast addresses can be used by IPv6 nodes that have a scope. This scope corresponds to the maximum range of the address within the network. The different defined scopes are the local link scope, local site scope and global scope. It should be noted that local site type addresses have just been abandoned by the various workgroups around IPv6 because their implementation complexity is too great.
In IPv6, the 128 bits of the address are divided into 16-bit blocks. Each of these blocks is converted into a 4-digit hexadecimal number. Each of the 16-bit blocks is separated by a colon (:).
Therefore, taking the following 128 bit address:
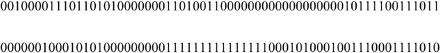
We divide the address into 16-bit blocks:
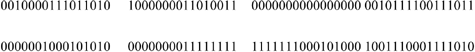
Each of the 16-bit blocks is then transcribed into hexadecimal notation separated by “:”:
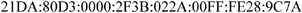
The representation of IPv6 addresses can be simplified by the elimination of the first zeros in each of the 16-bit blocks. Nonetheless, each block must have at least one digit. This leads to the following representation:
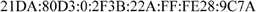
Certain types of IPv6 addresses carry a large number of zeros. In order to further simplify the representation of addresses, a sequence of 16-bit blocks whose value is zero can be compressed in the form “::”.
For example, the address FE80:0:0:0:25C3:FF:FE9A:BA13 can be compressed in the form FE80::25C3:FF:FE9A:BA13.
In the same manner, the multicast address FF02:0:0:0:0:0:0:2 can be compressed to FF02::2.
The compression of zeros can only be carried out in a single series of zeros within an IPv6 address. If ever we compressed two blocks of zeros in the same address, it would be impossible to know how many zeros are represented by the “::” symbol. Compressing zeros more than once would lead to address notation ambiguities.
As shown in Table 10.2, the format prefix defines the type of IPv6 address. This must not be mistaken for the IPv6 address prefix corresponding to the address’ high bits, serving to identify the network. The IPv6 prefixes are represented in the same way as the CIDR representation (classless inter-domain routing) of IPv4 addresses. Thus, an IPv6 prefix is referred to as network address/length of prefix. For example, 21DA:D3::/48 is an IPv6 prefix.
There are three types of IPv6 addresses: unicast, multicast and anycast.
A unicast address identifies a single and unique interface. Due to an appropriate unicast routing infrastructure, packets destined to a unicast address are delivered to a single interface.
A multicast address identifies many interfaces. With the appropriate routing structure, the packets addressed to a multicast address are sent to several interfaces.
An anycast address identifies several interfaces. Due to an appropriate routing infrastructure, packets destined to an anycast address are delivered to a single interface. This interface is the nearest having been identified by the anycast address in the direction of routing. The nearest interface is defined in terms of routing distance (number of skips, for example). An anycast address corresponds to a “one toward many” communication, thus delivering packets to a single interface.
Only unicast addresses can be used as source addresses identifying a node in the course of communication.
Unicast IPv6 addresses are divided into three categories: local link addresses, global addresses and special addresses. Local site addresses have been abandoned.
Global unicast addresses are identified by FP 001. They are equivalent to public IPv4 addresses. These addresses are globally routable and therefore reachable on the IPv6 part of the Internet. They are made to be aggregated, which will make it possible to have a greater efficiency in the routing infrastructure. IPv4 is actually a combination of flat and hierarchical routing due to the routing exceptions it contains. IPv6 was completely hierarchically conceived from the beginning. The scope, or the region, in which the global addresses are unique is the whole of the IPv6 Internet network.
As we have specified, IPv6 routing is based on the notion of prefix. Nonetheless, in order to guarantee the coherence and hierarchy of network addressing, address splitting was introduced. This splitting, described in Figure 10.5, only serves for the attribution of addresses to different ISPs and has no influence on routing.
TLA-ID: top level aggregation identifier. This 13-bit field identifies the highest level in the routing hierarchy. The TLA-IDs are administered by the IANA and attributed to local attribution organisms that attribute their TLA-IDs to high-level Internet access providers. The 13-bit field enables 8,192 combinations. The highest level routers in the Internet hierarchy therefore have no default route but have the whole of the entries corresponding to the TLA-IDs.
Res: these are bits used for future use in order to increase the size of the TLA-ID field or the NLA-ID field as needed. This field is 8 bits long.
NLA-ID: next level aggregator identifier. This field is used to identify a client site. This field is 24 bits long. The NLA-ID serves to create different addressing levels within a network in order to organize and route toward the lowest level access providers. The structure of these Internet access provider networks is not visible by the highest level routers. The combination of FP 001, of the TLA-ID and of the NLA-ID forms a 48-bit prefix attributed to an organization connected to the IPv6 portion of the Internet.
SLA-ID: site level aggregation identifier. The SLA-ID is used by an organization to identify its different sub-networks. This field is 16 bits long, which makes it possible for the organization to create 65,536 sub-networks or different hierarchical addressing levels. This makes it possible to implement an efficient routing infrastructure. Due to the 16-bit SLA-ID, assigning a prefix to an organization corresponds to attributing it a class A IPv4 address. The structure of the client’s network is not visible by the access provider.
Interface-ID: makes it possible to uniquely identify an interface on a network. This field is 64 bits long.
The fields we have just described make it possible to define a three-level structure as shown in Figure 10.6. The public topology corresponds to high and low level Internet access providers. The site topology corresponds to the group of sub-networks of the organization. The interface identifier enables the addressing of the interfaces within each of the organization sub-networks.
The local link addresses are identified by FP 1111 1110 10. These are used by the nodes that want to communicate with their neighbors on the same link. Thus, the hosts can simply communicate on an IPv6 link without a router. The scope of a local link address is the link on which the host resides.
A local link address is necessary for the communication between the nodes of a single link and is always automatically configured, even in the absence of all other unicast address types. Figure 10.7 describes the structure of a local link unicast address.
Local link addresses are implemented by using FP FE80. With a 64-bit interface identifier, the local link address prefix is always FE80::/64. An IPv6 router never relays packets whose source address field contains the local link addresses from the links to which it is connected.
The unspecified address (0:0:0:0:0:0:0:0 or::) is used to indicate the absence of an address. This address is typically used as source address during the configuration phase. This address is never attributed to an interface or used as a destination address.
The loopback address (0:0:0:0:0:0:0:1 or::1) is used to identify a loopback interface that makes it possible for a node to send packets to itself. This is equivalent to the IPv4 address 127.0.0.1. Packets addressed to a loopback address are never sent on the link or relayed by a router.
In IPv4, multicast is a notion that is difficult to implement. In the case of IPv6, the multicast traffic was originally defined at the local link. Multicast is essential for the communication and auto-configuration of nodes belonging to a single link.
IPv6 multicast addresses are defined by FP 1111 1111. In the case of IPv6, multicast addresses are easily recognizable by the fact that they all start by FP FF. Multicast addresses cannot be used as source address in an IP packet.
Putting aside the prefix used to identify them, multicast addresses have additional structures in order to identify their flag, their scope and their multicast group. Figure 10.8 describes the different fields used.
Flags: this field indicates the flag associated to the multicast address. This field is 4 bits long and makes it possible to differentiate addresses according to their life span. Currently, only two values have been defined. The T (transient) flag, when it is 0, indicates a permanently attributed address. On the contrary, when it is 1, it corresponds to a temporarily used address.
Scope: indicates the scope of the IPv6 address defining the corresponding multicast traffic. This field is 4 bits long. This field is notably used by multicast routers in order to know if they should relay packets or not. Table 10.3 defines the different scope values and their range within the Internet.
Table 10.3. Multicast scope values
| Value | Scope |
|---|---|
0 |
Reserved |
1 |
Local node scope |
2 |
Local link scope |
5 |
Local site scope |
8 |
Local organization scope |
E |
Global scope |
F |
Reserved |
Thus, the traffic corresponding to the multicast address FF02::2 has a local link scope. An IPv6 router will never relay this traffic any further than the local link.
Group ID: this field enables the identification of the multicast group within the whole defined by the scope. Addresses between FF01:: and FF0F:: are reserved and defined for a particular use:
– FF01::1 all the nodes according to the local node scope;
– FF02::1 all the nodes according to the local link scope;
– FF01::2 all the routers according to the local node scope;
– FF02::2 all the routers according to the local link scope;
– FF05::2 all the routers according to the local site scope.
Due to the 112 bits in the Group ID field, it is possible to obtain 212 different groups. Nonetheless, since the IPv6 multicast addresses are mapped on Ethernet addresses, it is recommended to only use the 32 low bits in the Group ID. Thus, each multicast group defined on the last 32 bits of the Group ID can be mapped on a unique Ethernet address. Figure 10.9 describes the fields of the modified multicast address.
An anycast address is assigned to several interfaces. Packets intended for an anycast address are relayed by the routing infrastructure to the nearest interface among the ones to which the anycast address has been attributed. An anycast address makes it possible to designate a service by a well-known address; in this way, it is not necessary to interrogate a server to know the location of an equipment.
In order to complete the relaying of the packets, the routing infrastructure must know the interfaces to which the anycast address has been attributed and their distances in terms of routing metrics.
If the anycast concept is simple in its principle, its implementation is otherwise delicate. Moreover, it should be known that at the time of drafting the IPv6 specifications, this concept was only a research topic. Finally, another argument explains the prudence that should be conserved regarding this concept: there has been no real-life experience making it possible to test the functionalities of anycast addresses.
Anycast and unicast type addresses are allocated in the same addressing space. Anycast addresses are created by attributing a single unicast address to distinct nodes. Then it is the routing infrastructure that routes the packets to the closest next hop, therefore completing the anycast service implementation.
Currently, anycast addresses can only be used as destination addresses and are solely attributed to routers. Anycast addresses attributed to routers are constructed on the network prefix base. This prefix is created from the network prefix for a given interface. To construct the anycast address attributed to a router, the network prefix bits are fixed to the appropriate value and the leftover bits are fixed to 0. Figure 10.10 shows the construction of the anycast address for a router.
The last 64 bits of an IPv6 address correspond to the interface identifier destined to be unique. There are different ways of determining the interface identifier:
– a 64-bit identifier derived from the extended unique identifier (EUI) of the MAC address;
– an interface identifier randomly and periodically generated to preserve anonymity;
– an identifier assigned during a stateful configuration (for example, by a DHCPv6 server).
Later on, we will only present the formation of IPv6 addresses due to the EUI-64 derived identifier. This can be derived from the interface’s MAC (medium access control) address defined by the IEEE (Institute of Electrical and Electronic Engineers). We will quickly present MAC addresses and EUI-64 and then the formation of the last 64 bits of an IPv6 address.
Network interface addresses use a 48-bit sequence called the IEEE 802 address. These 48 bits are composed of the identifier of the company that produces the network interfaces represented on 24 bits and of 24 bits representing the extension of the network card.
The combination of the unique company identifier with the extension of the card produces a unique 48-bit address called the MAC address. Figure 10.11 illustrates the characteristics of a MAC address.
The universal/local bit (U/L): the seventh bit of the high byte of the MAC address is used to indicate whether the address is locally or globally administered. If the U/L bit is 0, then the IEEE has administered the address. If the bit is 1, then the address is locally administered and there is no guarantee that the company identifier is unique.
The individual/group bit (I/G): the last bit of the high byte is used to determine whether the address is an individual address (unicast) or a group address (multicast). When this bit is 0, the address is a unicast address. When this bit is 1, the address designates a multicast address. A classic IEEE 802 address has U/L and I/G bits whose value is 0, which corresponds to a globally administered unique address.
The IEEE EUI-64 addresses represent a new standard for network interface addressing. The company identifier is still represented on 24 bits but the extension that represents the card is represented on 40 bits. This makes it possible to increase the network card addressing space for manufacturers. This standard uses U/L and I/G bits similarly to the IEEE 802 addresses. Figure 10.12 describes the format of IEEE EUI-64 addresses.
All unicast IPv6 addresses must use a unique 64-bit interface identifier. In order to obtain this identifier, the U/L bit in the EUI-64 address is complemented. Thus, to create the interface identifier for an IPv6 address, first the EUI-64 must be formed, which is derived from the MAC address. For this, the 16 bits 11111111 11111110 (0xFFFE) are inserted in the IEEE 802 address between the company identifier and the card extension. The U/L bit in the EUI-64 address must then be complemented. Figure 10.13 illustrates these different steps.
Throughout this chapter, the evolution of the IP network addressing technique is highlighted. The first specification of the IP protocol had not considered its scaling problem. Flexibility and performance problems have led to the specification of techniques more adapted to the general use of the Internet network. These successive modifications resulted in a radically different system. The use of fixed classes was finally abandoned for the use of network prefixes of varying sizes. Route aggregation benefiting from a multi-level hierarchy now makes it possible to generate performance problems due to a permanent extension of the network.
The new IP protocol specification reclaims these principles, while imposing a precise semantic for the attribution of IPv6 addresses. This organization makes it possible to obtain a completely hierarchical addressing and thus benefit from the previously cited advantages. In addition, IPv6 offers a much more vast addressing space, thus eliminating the problem of a lack of IP addresses. This point is not negligible in the face of the constant increase of IP terminals in the network. However, the migration toward IPv6 is not immediate and will surely be progressive, due notably to the coexistence within the network of the two versions of the IP protocol. In addition, the small quantity of addresses available for the number of countries that are still not well equipped will surely lead to a massive use of the IPv6 protocol in the near future.
Nonetheless, certain evolutions will carry unresolved problems, even in the framework of a fully operational IPv6 network. The major problem is induced by the dynamic topology of the network. To have optimal performances, the IP network hierarchy must reflect the physical topology of the network. When the topology changes, it is important to reflect these changes in the hierarchical splitting of the network, which can be very costly and therefore rarely possible. A simple change of access provider induces, for example, a complete renumbering. Another critical example concerns the ever-increasing mobility of terminals. This mobility provokes a changing network topology that can call into question the hierarchical organization of IP. This phenomenon introduces several problems, notably in terms of addressing and routing.
[RFC 791] “Internet Protocol, RFC 791”, IETF, September 1981.
[RFC 950] MOGUL J., POSTEL J., “Internet Standard Subnetting Procedure, RFC 950”, IETF, Standards Track, August 1985.
[RFC 1009] BRADEN R., POSTEL J., “Requirements for Internet Gateways, RFC 1009”, IETF, June 1987.
[RFC 1517] HINDEN R., “Applicability Statement for the Implementation of Classless Inter-Domain Routing (CIDR), RFC 1517”, IETF Standard Track, September 1993.
[RFC 1518] REKHTER Y., WATSON T.J., LI T., “An Architecture for IP Address Allocation with CIDR, RFC 1518”, IETF, Standards Track, September 1993.
[RFC 1519] FULLER V., LI T., YU J., VARADHAN K., “Classless Inter-Domain Routing (CIDR): an Address Assignment and Aggregation Strategy, RFC 1519”, IETF, Standards Track, September 1993.
[RFC 1520] REKHTER Y., WATSON T.J., TOPOLCIC C., “Exchanging Routing Information across Provider Boundaries in the CIDR Environment, RFC 1520”, IETF, Informational, September 1993.
[RFC 1918] REKHTER Y., MOSKOWITZ B., KARRENBERG D., DE GROOT G.J., LEAR E., “Address Allocation for Private Internets, RFC 1918”, IETF, Best Current Practice, February 1996.
[RFC 3330] IANA, “Special-Use IPv4 Addresses, RFC 3330”, IETF, Informational, September 2002.
[RFC 3513] HINDEN R., DEERING S., “Internet Protocol Version 6 (IPv6) Addressing Architecture, RFC 3513”, IETF, Standards Track, April 2003.
[RFC 3587] HINDEN R., DEERING S., NORDMARK E., “IPv6 Global unicast Address Format, RFC 3587”, IETF, Informational, August 2003.
1 Chapter written by Julien ROTROU and Julien RIDOUX.