4
Discoverability
The IoT is envisioned to bring together billions of devices, or “smart objects”, by connecting them in an Internet‐like structure, allowing them to communicate and exchange information and to enable new forms of interaction among things and people. Smart objects are typically equipped with a microcontroller, a radio interface for communication, sensors and/or actuators. Smart objects are constrained devices, with limited capabilities in terms of computational power and memory. They are typically battery‐powered, thus introducing even more constraints on energy consumption: this motivates the quest for energy‐efficient technologies, communication/networking protocols, and mechanisms. Internet Protocol (IP) has been widely envisaged as the true IoT enabler, as it allows full interoperability among heterogeneous objects. As part of the standardization process that is taking place, new low‐power protocols are being defined in international organizations, such as the IETF and the IEEE.
4.1 Service and Resource Discovery
Together with application‐layer protocols, suitable mechanisms for service and resource discovery should be defined. In particular, CoAP defines the term service discovery as the procedure used by a client to learn about the endpoints exposed by a server. A service is discovered by a client by learning the Uniform Resource Identifier (URI) [28] that references a resource in the server namespace. Resource discovery is related to the discovery of the resources offered by a CoAP endpoint. In particular, M2M applications rely on this feature to keep applications resilient to change, and therefore not requiring human intervention. A resource directory (RD) [14] is a network element hosting the description of resources held on other servers, allowing lookups to be performed for those resources.
A crucial issue for the robust applications, in terms of resilience to changes that might occur over time (e.g., availability, mobility, or resource description), and the feasible deployment of (billions of) smart objects is the availability of mechanisms that minimize, if not remove, the need for human intervention for the configuration of newly deployed objects. The RESTful paradigm is intended to promote software longevity and independent evolution [29], both of which are extremely important for IoT and M2M applications deployed on smart objects that are expected to stay operational for long periods; say, years. Self‐configuring service and resource discovery mechanisms should take into account the different scopes that these operations might have:
- in a local scope, they should enable communication between geographically concentrated smart objects; that is, residing in the same network;
- in a global (large‐scale) scope, they should enable communication between smart objects residing in different (and perhaps geographically distant) networks.
These approaches should also be scalable, since the expected number of deployed objects is going to be of the order of billions.
Self‐configuration is another crucial feature for the diffusion of IoT systems, where all the objects equipped with a radio interface are potential sources of information to be interconnected. An external operator managing a network first needs to configure the system. Clearly, if this operation is carried out manually, there may be misconfigurations. This is far more likely when thousands of devices are involved. In addition, an occasional manual network reconfiguration may cause a significant system outage, just as, in an industrial plant, machines may need to be stopped for normal maintenance. For this reason, a self‐configurable IoT system is a good way to prevent long outages and configuration errors.
4.2 Local and Large‐scale Service Discovery
In the literature, there are already mechanisms for implementing service discovery. Most of these, however, were originally conceived for LANs and were then extended for constrained IPv6 over low‐power wireless personal area networks (6LoWPANs). One of these mechanisms is Universal Plug and Play (UPnP) [57], a protocol that allows for automatic creation of a device‐to‐device network. However, as UPnP uses TCP as the transport protocol and XML as the message exchange format, it is not suited to constrained devices.
Another proposed mechanism is based on the Service Location Protocol (SLP) [58], [59] through which computers and devices can find services in LANs without prior configuration. Devices use SLP to announce the services they provide in the local network; these are grouped into scopes: simple strings that classify the services. The use of SLP may be important in large‐scale IoT scenarios, in order to make service discovery automatic. However, SLP does not target constrained devices like those used in the IoT. In addition, it relies on centralized approaches, which may be prone to failure. Finally, up to now, no SLP implementation has been available for Contiki‐based devices.
Another alternative to UPnP is the Zero‐configuration (Zeroconf) [60] networking protocol, which allows for automatic creation of computer networks based on the TCP/IP Internet stack and does not require any external configuration. Zeroconf implements three main functionalities:
- automatic network address assignment;
- automatic distribution and resolution of host names;
- automatic location of network services.
Automatic network assignment intervenes when a node first connects to the network. The host name distribution and resolution is implemented using multicast DNS (mDNS) [61], a service that has the same interfaces, packet formats, and semantics as standard DNS messages to resolve host names in networks that do not include a local name server. In the service discovery phase, Zeroconf implements DNS‐based Service Discovery (DNS‐SD) [62]. Using standard DNS queries, a client can discover, for a given domain, the named instances of the service of interest.
In the field of ubiquitous computing, PIAX, a P2P platform for geographic service location, has been proposed [63], [64]. In PIAX, every node is a peer of the overlay. This approach is not suitable for the IoT, since many nodes are constrained in terms of processing capabilities. In addition, PIAX does not provide a URI resolution service, so that it can only try to route the query to the correct area of the network but cannot resolve the endpoint to be contacted.
Efforts have been made to adapt these solutions to the world of constrained devices. Busnel et al. introduced a P2P overlay to perform broadcast or anycast in wireless sensor networks (WSNs) without any centralized element [65]. Sensors were clustered according to their types into specific layers. However, they took into account neither local service discovery nor computational complexity due to the existence of nodes belonging to different layers.
Gutierrez et al. instead introduced a separation between WSNs and P2P networks [66]. Their focus was on exploiting these two types of network to develop a feedback loop to allow developers to define self‐managing behaviors. However, they did not take into account aspects like energy efficiency, self‐discovery of resources, or large‐scale deployments.
Leguay et al. implemented an automatic discovery mechanism [67]. In their approach each node is responsible for announcing itself to the main gateway through HELLO messages. These messages are sent either in response to a discovery request or proactively sent in an automatic way. The gateway is then be in charge of addressing the requests coming from external networks to the correct nodes.
Kovacevic et al. have proposed NanoSD, a lightweight service discovery protocol designed for highly dynamic, mobile, and heterogeneous sensor networks [68]. Their solution requires extensive multicast and broadcast messages to keep track of service information of the neighboring nodes.
Another solution was presented by Mayer and Guinard [69]. They developed a RESTFul web service using HTTP‐based service discovery. However, their approach does not provide management and status maintenance of existing services.
Finally, Butt et al. divided the network into groups, assigning different roles to the nodes in each group [70]. Embedding a directory agent into the border router makes scalability easier. However, this architecture tends to be too fragile in the presence of failures of the central border router. In addition, the protocol focuses on in‐network service location, but it lacks coordination with other similar entities, thus preventing large‐scale discovery.
A few papers related to service discovery in IoT systems have appeared. Jara et al. sketched an architecture for large‐scale service discovery and location [71]. However, theirs was a centralized solution, exposing a search engine to make the integration of distributed service directories feasible.
Paganelli and Parlanti exploited an underlying distributed P2P overlay to support more complex queries, such as multi‐attribute and range queries [72]. This approach is more focused on service resolution rather than on the creation of the overlay by automatically discovering existing services. Unlike our approach, which aims at being transparent and agnostic of the underlying technology, several P2P overlays presented in the literature focus on RFID for supply chains [73], [74], [75].
CoAP natively provides a mechanism for service discovery and location [7]. Each CoAP server must expose an interface /.well‐known/core, to which the RD or, more generally, a generic node can send requests for discovering available resources. The CoAP server will reply with the list of resources and, for each resource, an attribute that specifies the format of the data associated with that resource. CoAP, however, does not specify how a node joining the network for the first time must behave in order to announce itself to the resource directory node.
In the IETF's latest draft for CoAP [76], this functionality is extended to multicast communications. In particular, multicast resource discovery can be useful when a client needs to locate a resource within a limited scope, and that scope supports IP multicast. A GET request to the appropriate multicast address is made for /.well‐known/core. Of course, multicast resource Discovery works only within an IP multicast domain and does not scale to larger networks that do not support end‐to‐end multicast. However, in CoAP there is no specification on how a remote client can lookup the RD and query for the resource of interest.
Peer‐to‐peer (P2P) networks have been designed to provide some desirable features for large‐scale systems, such as scalability, fault‐tolerance, and self‐configuration. The main feature that makes P2P networks appealing is the fact that as the number of participating nodes increases, the overall system capacity (in terms of processing and storage capabilities) increases as well. This challenges classical client/server architectures, where an increase in the number of clients may bring the system to saturation and/or failure. P2P networks arrange participating nodes in an overlay network, built on top of an existing network, such as the Internet. The algorithm through which the overlay is created can be used to make a distinction between structured and unstructured P2P networks. Structured P2P networks, such as distributed hash tables (DHTs), are built using consistent hashing algorithms, which guarantee that the routing of requests takes a deterministic and upper‐bounded number of hops for completion, at the cost of having network traffic for managing and maintaining the overlay. Historically, P2P networks have been associated with file sharing applications, such as eMule1 and BitTorrent2. The decrease in the popularity of file sharing applications has cooled interest in P2P, even though notable applications, such as Skype, have historically used a P2P overlay as backbone to provide a scalable and efficient service. However, the features that P2P networks have been designed for are very appealing for IoT scenarios, where large‐scale and robust applications need to be supported. IoT thus represents an opportunity of a renaissance for P2P.
Centralized approaches for service discovery, such as the RD of the CoAP protocol, suffer from scalability and availability limitations and are prone to attacks, such as denial of service (DoS). Possible alternatives to this problem may consist of the use of DHTs. Key/value pairs are stored in a DHT and any participating node can efficiently retrieve the value associated with a given key. Responsibility for maintaining the mapping from keys to values is distributed among the nodes in such a way that a change in the set of participants causes a minimal amount of disruption (consistent hashing). This allows a DHT to scale to extremely large numbers of nodes and to handle continuous node arrivals, departures, and failures.
Several different algorithms and protocols have already been proposed for DHTs; the most significant are Chord [77] (for its simplicity) and Kademlia [78] (for its efficiency). Some papers have also been published on the use of P2P for service discovery. Yulin et al. combine P2P technology and the centralized Universal Description Discovery and Integration (UDDI) technology to provide a flexible and reliable service discovery approach [79]. Kaffille et al. apply the concepts of DHTs to the service discovery, creating an overlay P2P to exchange information about available services without flooding the entire network [80]. However, these approaches do not take into account the constraints and requirements of IoT. In Section 4.3, we will detail our P2P implementation for large‐scale service/resource discovery in IoT networks, extending the P2P DHT solution by taking into account the requirements of scalability and self‐configuration typical of constrained networks.
4.2.1 ZeroConf
ZeroConf is an open standard originally designed by Apple. It allows services to be setup automatically within a network, without requiring manual configuration. The IETF Zeroconf Working Group was formed in 1999 and has worked on the definitions and the standardization mechanisms required to achieve zero configuration of services.
ZeroConf is based on the combination of three functionalities: address selection, service name resolution, and service discovery. These functions are provided by the following suite of standards, respectively:
- IPv4 link‐local addressing [81]: this standard allows hosts to self‐assign IP addresses in a network without relying on a DHCP server;
- Multicast DNS [82]: this standard provides a way to resolve names to IP addresses without relying on a DNS server;
- DNS service discovery (DNS‐SD) [83]: this standard allows discovery of services within a network using the semantics of DNS messages.
The ZeroConf suite allows services to be configured and discovered without requiring DHCP and DNS servers. It does this by making all hosts collectively responsible for publishing/discovering services and resolving names to addresses, simply by using the semantics of the DNS protocol and multicast communication.
ZeroConf supports both IPv4 and IPv6, using multicast IP addresses 224.0.0.251 and ff02::fb and UDP ports 53 and 5353, respectively.
Service discovery typically occurs by searching for services of a given type in a particular domain; that is, matching the service type string of the form _ServiceName._ServiceType._TransportProtocolName.Domain. (for example, _http._tcp.local. or _coap._udp.local.) The service discovery process returns a list of services that comply with the searched type. Subsequently, a service with a given name can be resolved to an IP address and port number at which it can be accessed. In the case of a CoAP server, once discovered, a request can be issued to the server for its /.well‐known/core in order to perform resource discovery.
Several implementations of ZeroConf are available, in essence for all platforms. Due to this widespread support, ZeroConf is a very good option for IoT smart objects that want to advertise their presence and allow other applications to discover them automatically with no manual configuration.
The limitation of ZeroConf is its reliance on multicast communication, which is rarely propagated beyond the scope of the local network, making ZeroConf typically suitable only for local environments. However, locally, ZeroConf provides an extremely convenient and elegant way to perform service discovery and can thus be adopted to deploy self‐configuring IoT applications.
4.2.2 UPnP
With a similar intent to ZeroConf, the Universal Plug and Play (UPnP) protocol suite provides a way to perform dynamic and seamless discovery of devices in a network, without relying on DHCP and DNS servers. UPnP has been defined by the UPnP Forum and uses HTTPU/HTTPMU (HTTP over UDP and HTTP over multicast UDP) and SOAP to perform service description, discovery, and data transfer. UPnP suits home appliances rather than enterprise‐level deployments due to its security and efficiency issues. Many consumer‐oriented smart objects, such as Philips Hue light bulbs, use UPnP as a zero‐configuration service discovery mechanism for bridges.
4.2.3 URI Beacons and the Physical Web
The Physical Web, a concept promoted by Google, is a different approach to provide seamless discovery and interaction with smart objects. The assumption behind the Physical Web is that the web itself provides all the necessary means for a fruitful interaction with any endpoint, be that a website or an object. As a consequence, the only operation that is needed in order to merge the physical world and the web is to discover the URL related to a web resource linked to a smart object. After that, a web browser is capable of delivering a user interface to the end user, which they can use to interact with the object (mediated by a backend that is actually connected to the object itself).
The discovery mechanism defined by the Physical Web (and illustrated in Figure 4.1 ) is based on the use of URI beacons; that is, Bluetooth Low Energy (BLE) devices broadcasting URLs. The use of BLE is particularly convenient because it is supported on the vast majority of user devices as well as having low energy consumption, which is important in order to ensure that battery‐powered beacons can last as long as possible. The standard for data broadcasting over BLE is the Eddystone protocol, designed by Google. The Eddystone protocol defines four packet types:
- Eddystone‐UID, used to contain a beacon identifier;
- Eddystone‐URL, used to broadcast a URL;
- Eddystone‐TLM, used for sending telemetry information
- Eddystone‐EID, used for carrying ephemeral IDs, in order to protect against replay attacks or spoofing.
Although BLE is currently the only communication protocol that can be used to broadcast a URL, other options, such as mDNS or UPnP, can still be applied and might be supported in the future.

Figure 4.1 Physical Web discovery mechanism.
The advantage in using URI beacons is the possibility to discover and interact with objects even if the user device is not connected to the same network. However, this benefit may also become a downside, because the interaction with the object might not take into account context information related to the association of the user device with the network. Moreover, it may be unsafe in some scenarios to openly broadcast object URLs: it might raise security issues and it could be impossible to restrict discovery to only authorized devices. The Physical Web is therefore particularly suited to public spaces, where no restricted access to objects should occur.
4.3 Scalable and Self‐configuring Architecture for Service Discovery in the IoT
In this section, we present a scalable and self‐configuring architecture for service and resource discovery in the IoT. aiming at providing mechanisms requiring no human intervention for configuration, thus simplifying the deployment of IoT applications. Our approach is based on:
- at a large scale, P2P technologies, to provide a distributed large‐scale service discovery infrastructure;
- at a local scale, zero‐configuration mechanisms.
Information on resources provided by smart objects attached to a local wireless network are gathered by a special boundary node, referred to as the “IoT gateway”. This is also part of a P2P overlay used to store and retrieve such information, resulting into a distributed and scalable RD. As will be shown, the global service discovery performance depends only on the number of peers in the P2P overlay; this makes the proposed approach directly scalable when the size of the IoT network increases. Local service discovery at the IoT gateway makes the process of discovery of new resources automatic. In particular, in our experimental tests we use CoAP for the description of the available endpoints.
To the best of our knowledge, this is the first research to provide an architecture and mechanisms that allow for service discovery at both global and local scales into a unique self‐configuring system. We also provide some preliminary results obtained by an implementation and a real‐world deployment of our architecture, thus demonstrating its feasibility.
We note that the proposed architecture is built upon components designed to be absolutely agnostic regarding the format of service and resource descriptors, in order to avoid the introduction of application‐specific constraints. In fact, the architecture provides mechanisms for publishing and retrieving information, mapped to service or RD URIs, which can be represented in any suitable content format for service/resource description, either already available, such as the CoRE Link Format [13], or foreseeable. The adoption of standard description formats is mandatory to guarantee maximum interoperability, but it is a service's responsibility to enforce this practice. It is also important to note that IoT applications should be implemented according to the REST paradigm; the definition of CoAP is intended to accomplish precisely this. Client applications, in order to comply with the RESTful paradigm, must follow the HATEOAS (Hypermedia as the Engine of Application State) principle [2], which forbids applications from driving interactions that are based on out‐of‐band information rather than on hypermedia. The existence of prerequisites, in terms of resource representations, is a violation of the REST paradigm. The service discovery architecture itself does not do this: it is extremely flexible, able to handle any resource description format. The absence of content‐related dependencies leads to more robust implementations, in terms of longevity and adaptability to changes that resource descriptions might undergo.
4.3.1 IoT Gateway
The service discovery architecture proposed in this work relies on the presence of an IoT gateway. By combining different functions, the IoT gateway provides both IoT nodes and standard (non‐constrained) nodes with service and resource discovery, proxying, and (optionally) caching and access‐control functionalities. In this section, the internal architecture of the IoT gateway and its associated functions will be detailed.
4.3.1.1 Proxy Functionality
The IoT gateway interacts, at the application level, with other IoT nodes through CoAP and may act as both CoAP client and CoAP server. More precisely, in the terms of the CoAP specifications, it may act as CoAP origin server and/or proxy. The CoAP specification defines an origin server as a CoAP server on which a given resource resides or has to be created, while a proxy is a CoAP endpoint which, by implementing both the server and client sides of CoAP, forwards requests to an origin server and relays back the received responses. The proxy may also (optionally) perform caching and protocol translation (in which case it is termed a “cross‐proxy”).
The presence of a proxy at the border of an IoT network can be very useful for a number of reasons:
- to protect the constrained network from the outside: for security reasons such as DoS attacks;
- to integrate with the existing web through legacy HTTP clients;
- to ensure high availability of resources through caching;
- to reduce network load of constrained devices;
- to support data formats that might not be suitable for constrained applications, such as XML.
In Figure 4.2, a layered view of the IoT gateway node is presented.
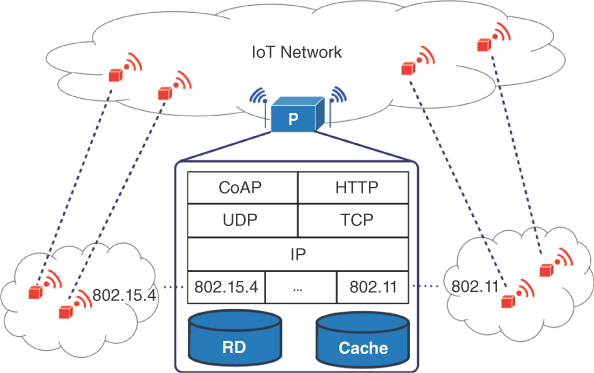
Figure 4.2 Architecture of IoT gateway with internal layers and caching/resource directory capabilities.
In addition to standard CoAP proxying behavior, the IoT gateway may also act as an HTTP‐to‐CoAP proxy by translating HTTP requests to CoAP requests (and vice‐versa). Just like standard CoAP proxying, an HTTP‐to‐CoAP proxy can integrate two different operational modes:
- reverse proxy: by translating incoming HTTP requests to CoAP requests, it provides access to resources that are created and stored by CoAP nodes within the IoT network (acting as CoAP servers);
- origin server: acting as both HTTP and CoAP server, by letting CoAP nodes residing in the IoT network (and acting as clients) create resources through CoAP POST/PUT requests, and by making such resources available to other nodes through HTTP and CoAP.
The latter operational mode is particularly suited for duty‐cycled IoT nodes, which may post resources only during short wake‐up intervals. Figure 4.3 shows the difference between a reverse proxy and an origin server.
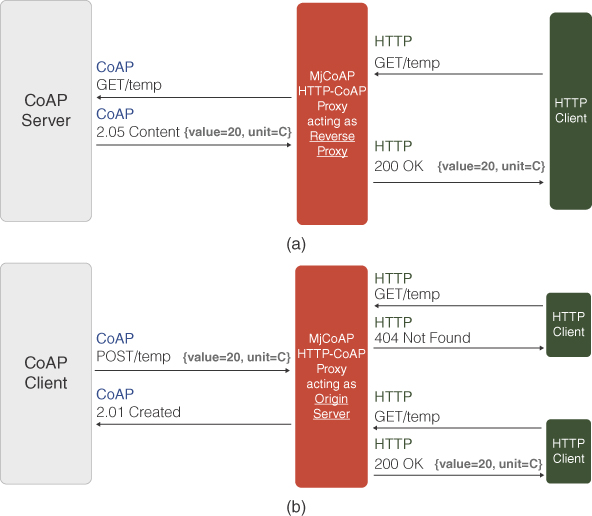
Figure 4.3 HTTP‐to‐CoAP proxy acting as: (a) reverse proxy and (b) origin server.
From an architectural point of view, the IoT gateway comprises the following elements:
- an IP gateway, managing IPv4/IPv6 connectivity among smart objects in heterogeneous networks (i.e., IEEE 802.15.4, IEEE 802.11.x, and IEEE 802.3) so as to allow for interconnection of devices operating in different networks by providing an IP layer to let nodes communicate seamlessly;
- a CoAP origin server, which can be used by CoAP clients within the network to post resources that will be maintained by the server on their behalf;
- a HTTP‐to‐CoAP reverse proxy, optionally equipped with caching capabilities, which can be used for accessing services and resources that are available in an internal constrained network.
The IoT gateway is therefore a network element that coordinates and enables full and seamless interoperability among highly heterogeneous devices, which:
- may operate different protocols at the link and/or application layers;
- may not be aware of the true nature of the nodes providing services and resources;
- may be geographically distant.
4.3.1.2 Service and Resource Discovery
Service discovery aims at obtaining the hostport of the CoAP servers in the network, while resource discovery is discovery of the resources that a CoAP server manages. Because of its role in managing the life‐cycle of nodes residing in its network, the IoT gateway is naturally aware of the presence of the nodes and the available services and resources. When the IoT gateway detects that a CoAP node has joined its IP network, it can query the CoAP node, asking for the list of provided services; in CoAP this is done by sending a GET request to the /.well‐known/core URI. Such information (the resource directory) is then locally maintained by the IoT gateway and successively used to route incoming requests to the proper resource node. According to this mechanism, the IoT gateway may act as an RD for the CoAP nodes within the network.
In Section 4.3.2, we detail how IoT gateways can be federated in a P2P overlay in order to provide a distributed and global service and resource directory that can be used to discover services at a global scale. In Section 4.3.3, we then provide a zero‐configuration solution for discovery of resources and services within a local scope, with no prior knowledge or intervention required on any node of the network. This allows the IoT gateways to populate and update their resource and service directories.
4.3.2 A P2P‐based Large‐scale Service Discovery Architecture
As stated in Section 4.3.1, IoT gateways can be federated in a P2P overlay in order to provide a large‐scale service discovery mechanism. The use of a P2P overlay can provide several desirable features:
- scalability: P2P systems are typically designed to scale and increase their capacity as the number of participants increases;
- high‐availability: P2P systems are inherently robust because they have no single point of failure and the failure of a node does not compromise the overall availability of the services and resources provided;
- self‐configuration: P2P systems provide mechanisms to let the overlay re‐organize itself automatically when nodes join and leave, requiring no direct intervention for configuration.
These features fit perfectly in IoT scenarios, where billions of objects are expected to be deployed. Among several approaches to implementing P2P overlays, structured overlays, such as DHTs, have some interesting features, including efficient storage and lookup procedures, resulting in deterministic behavior. On the contrary, with unstructured overlays, flooding techniques are used for message routing. In the remainder of this section, we propose a P2P‐based approach that provides a scalable and self‐configuring architecture for service discovery at a global scale.
IoT gateways are organized as peers of a structured P2P overlay, which provides for efficient name resolution for CoAP services. The large‐scale service discovery architecture presented in this work relies on two P2P overlays:
The DLS provides a name resolution service to retrieve all the information needed to access a resource (of any kind) identified by a URI. The DGT builds up a distributed geographical knowledge, based on the location of nodes, which can be used to retrieve a list of resources matching geographic criteria. The combination of these two P2P overlay systems allows for the building of a distributed architecture for large‐scale service discovery, with the typical features of P2P networks (scalability, robustness, and self‐configuration), yet enabling the unique feature of service and resource discovery on a geographical basis. In the following, we first detail the DLS and DGT and then we describe the overall envisioned system architecture.
4.3.2.1 Distributed Location Service
The DLS is a DHT‐based architecture that provides a name resolution service based on storage and retrieval of bindings between a URI, identifying resources (e.g., web services) and the information that indicates how they can be accessed [84]. In essence, the DLS implements a location service that can be used to store and retrieve information for accessing services and resources. Together with each contact URI, other information can be stored, such as the expiration time, an access priority value, and, optionally, a human‐readable text (e.g., a contact description or a name).
The service provided by DLS can be considered as similar to that of the DNS, since it can be used to resolve a name to retrieve the information needed to access the content related to that name. However, the DNS has many limitations that the DLS overcomes, such as:
- the DNS applies only to the fully qualified domain names (FQDN) and not to the entire URI;
- the DNS typically has long propagation times (further increased by the use of caching), which are not suited to highly dynamic scenarios, such as those encompassing node mobility;
- the DNS essentially provides the resolution of a name, which results in an IP address, but it does not allow for storage and retrieval of additional useful information related to the resolved URI, such as the description and the parameters of the hosted service.
Another important feature that makes the use of the DLS preferable to the DNS is its robustness. If a DNS server is unreachable, then resolution cannot be performed. In contrast, P2P overlays do not have single point of failure that might cause service disruption, resulting in a more robust, dynamic, and scalable solution.
A DLS can be logically accessed through two simple methods:
- put(key,value);
- get(key);
where key is a resource URI (actually its hash), while value is structured information that may include location information (e.g. a contact URI) together with a display name, expiration time, priority value, etc. The get(key) method should return the set of the corresponding values (actually the contact information) associated with the targeted resource. The removal of a resource is performed by updating an existing resource through a put operation with expiration time set to zero. This mapping allows the approach to support:
- mobility: it is sufficient to put and replace an old resource with an updated one that considers the new position of the resource;
- replication: it is sufficient to execute several put operations for the same resource in order to have multiple replicas diffused in the DHT.
The DLS interface can be easily integrated with existing networked applications, such as a middleware layer offering services to applications and working on top of standard transport protocols. Different RPC protocols, such as dSIP [87] and RELOAD [88], may be used for messaging, regardless of the actual selected DHT algorithm (e.g., Chord or Kademlia).
4.3.2.2 Distributed Geographic Table
The DGT [85], [86] is a structured overlay scheme, built directly using the geographical location of the nodes. Unlike DHTs, with a DGT each participant can efficiently retrieve node or resource information (data or services) located near any chosen geographic position. In such a system, the responsibility for maintaining information about the position of active peers is distributed among nodes, so that a change in the set of participants causes a minimal amount of disruption.
The DGT is different from other P2P‐based localization systems, where geographic information is routed, stored, and retrieved among nodes organized according to a structured overlay scheme. The DGT principle is to build the overlay by directly taking into account the geographic positions of nodes. This allows for building of a network in which overlay neighbors are also geographic neighbors; no additional messages are needed to identify the closest neighbors of a peer. The main difference between the DGT and the DHT‐based P2P overlays is the fact that the DGT overlay is structured in such a way that the messages are routed exclusively according to the geographic locations of the nodes, rather than on keys that have been assigned to the nodes. Typically, DHTs arrange hosts at unpredictable and unrelated points in the overlay, deriving keys through hashing functions. In contrast, the DGT ensures that hosts that are geographically close are also neighbors in the overlay.
The DGT provides a primitive get(lat, lon, rad), which returns a list of nodes that fall inside the circular region centered at (lat, lon) with radius rad. Each node that provides a service can be looked up. The get primitive is used to localize the list of nodes in a certain geographic region. It might be possible to extend the get primitive by introducing query filters, making it possible to return only matching services. The DGT does not provide a generic put primitive that can be invoked on the overlay as a whole. However, it is possible to extend the classical DGT behavior with a generic put primitive, consisting of the detection of a list of peers in a given area (through the native DGT get primitive) and, subsequently, to invoke a put method directly on each of the detected peers.
4.3.2.3 An Architecture for Large‐scale Service Discovery based on Peer‐to‐peer Technologies
The mechanisms presented in the previous subsections are the key ingredients of a large‐scale service discovery architecture. In Figure 4.4, an illustrative representation of the system architecture is shown. Several IoT gateways managing their respective networks are interconnected through the two P2P overlays. Each IoT gateway is, at the same time, a DLS peer and a DGT peer. The data structures of the overlays are separated, since they pertain to different operations of the overall architecture. The DLS and DGT overlays are loosely coupled. The IoT gateway uses the DLS to publish/lookup the details of resources and services, and the DGT to publish its presence or discover existing IoT gateways in a given geographic area. This separation allows the IoT gateway to access the services provided by each overlay as a “black‐box”, without any risk of direct interference between the overlays. The IoT gateway is responsible for implementing the behavior required by the service discovery architecture.
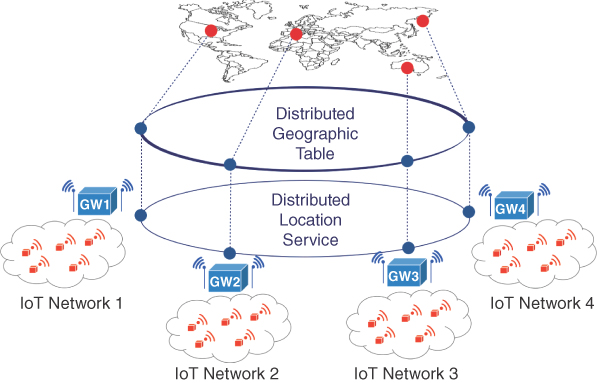
Figure 4.4 Large‐scale service‐discovery architecture. IoT gateway nodes act as peers of two different P2P overlays. The DLS overlay is used for discovering resources and services: a “white‐pages” service that provides a name resolution service to be used to retrieve the information needed to access a resource. The DGT is used as a “yellow‐pages” service, for learning about the existence of IoT gateway nodes in a certain geographical neighborhood.
The lifecycle of an IoT gateway is shown in Figure 4.5 and can be described as follows:
- Upon start up, the IoT gateway joins the DLS and DGT overlays.
- The IoT gateway publishes its presence in the DGT by issuing a DGT.put (lat, lon,
 ) request.
) request. - When the IoT gateway detects a new CoAP node in the network, through any suitable means (e.g., Zeroconf), it fetches the node's local resource directory (LRD) through a CoAP GET request targeting the /.well‐known/core URI. The LRD is filled with documents in JSON‐WSP3 or similar formats (such as CoRE Link Format) containing the description of all the resources that are hosted by the CoAP node and the information to be used to access them. At this point, the resources included in the fetched node's LRD are added to the IoT gateway's LRD.
- If the IoT gateway is willing to let the resources be reachable through it, it will modify its LRD to include the references of the URLs to be used to reach the resources through the IoT gateway, obtaining a new LRD, denoted as LRD*; the IoT gateway could also delete from the LRD all the references directly related to this resource, in order to avoid having a resource that could be accessed without the IoT gateway relaying messages.
- The IoT gateway publishes the LRD* in the DLS through a DLS.put(
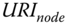 /.well‐known/core,LRD*) request.
/.well‐known/core,LRD*) request. - The IoT gateway keeps track of the list of nodes that are in its managed network, by adding the node to a local node directory (LND).
- The IoT gateway publishes the LND pair in the DLS through a DLS.put(
 /.well‐known/nodes,LND) request.
/.well‐known/nodes,LND) request. - If, in addition, the IoT gateway acts as origin server, it stores its own resources, which will then be published as soon as it receives CoAP POST requests from CoAP clients residing in the inner network.
Steps 3 to 7 are repeated for each CoAP node detected in the network. By publishing all the LRDs in the DLS, a distributed resource directory (DRD) is obtained. The DRD provides global knowledge of all the available resources. The use of LNDs provides a census of all the nodes that are within a certain network. Location information is managed with JSON‐WSP or CoRE Link Format documents, which provide all the details related to parameters and return values. This is similar to WSDL documents, but in a more compact, yet just as descriptive, format than XML. As soon as a node joins a local network and discovers the presence of an IoT gateway (it can be assumed that either the IoT gateway address is hard‐coded or the node joins the RPL tree, finding the IoT gateway – other mechanisms may also be possible), the node announces its presence. We note that this phase is optional, in the sense that other discovery mechanisms can be adopted. When the IoT gateway detects this advertisement, it issues a GET /.well‐known/core to the node, in order to discover its available resources. The node, in return, replies by sending a JSON‐WSP or CoRE Link Format document describing its exposed resources, the URI to access them, and their data format. Finally, the IoT gateway will parse this response and will populate the DLS and DGT accordingly. If other IoT gateways are present within a certain network, they can act as additional access points for a resource: this can be achieved by publishing a LRD* containing the URLs related to them. This will lead to highly available and robust routing in very dynamic scenarios where IoT gateways join and leave the network. Should one want to provide fault‐tolerance, information replication mechanisms can be also introduced [89].
containing the URLs related to them. This will lead to highly available and robust routing in very dynamic scenarios where IoT gateways join and leave the network. Should one want to provide fault‐tolerance, information replication mechanisms can be also introduced [89].

Figure 4.5 Messages exchanged when a new node joins the network. First, the IoT gateway discovers the resources of a new CoAP server or stores them on behalf of a CoAP client. Finally, DGT and DLS are updated with information about the new node.
In the proposed architecture, the DLS can be interpreted as a “white‐pages” service to resolve the name of a service, in the form of a URI, to get all the information needed to access it. Similarly, the DGT can be interpreted as a “yellow‐pages” service, used to retrieve a list of available services matching geographic location criteria; that is, in the proximity of a geographic position. Note that the DGT is just one possible solution to get matching services; other mechanisms might be adopted. These might not be related to geographic locations, but instead on different matching criteria, such as taxonomies/semantics. This is the case if the search is by type of service rather than by geographical location.
The distinction between the lookup services provided by DLS and DGT avoids the inclusion, in the URI, of service or resource information that can dynamically change (such as the location), thus making it possible to support mobility of services and resources. The DGT and the DLS run in parallel, and the IoT gateways of a IoT sub‐network act as peers of both the DLS and the DGT. The resulting architecture is very flexible and scalable: nodes that may join and leave the network at any time. In fact, as explained in the previous subsections, the nature of DLS and DGT P2P overlay networks allows new IoT gateways to be added without requiring the re‐computation of the entire hash table. Vice versa, only the nodes responsible for maintaining the resources close to the joining node must update their hash tables in order to include the resources of the new node.
A client needing to retrieve data from a resource and with no information about the URI to contact, must perform the operations shown in Figure 4.6. It can perform service discovery through the mediation of a known IoT gateway that is part of the DLS and DGT overlays. The procedure can be detailed as follows (the first five steps are explicitly shown in Figure 4.6):
- 1) The client contacts a known IoT gateway in order to access the DLS and DGT overlays for service discovery.
- 2) The client uses the DGT to retrieve a list of IoT gateways that are in the surroundings of a certain geographical location through a DGT.get(lat, lon, rad) request.
- 3a) The IoT gateway selects one of the IoT gateways returned by the DGT and discovers the list of its managed nodes, through a DLS.get(
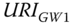 /.well‐known/nodes) request.
/.well‐known/nodes) request. - 3b)
The IoT gateway discovers the resources that are reachable:
- by executing a DLS.get(
 /.well‐known/core) procedure or
/.well‐known/core) procedure or - by issuing a CoAP GET request for
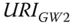 /.well‐known/core.
/.well‐known/core.
- by executing a DLS.get(
- 4) The IoT gateway interacts with the resource by issuing CoAP or HTTP requests targeting the selected resource through the appropriate IoT gateway. The client can then contact the URI of the resource, either directly through CoAP (if supported by the IoT gateway) or by HTTP (by delegating to the IoT gateway the HTTP‐CoAP request translation).
- 5) Once the command has been transmitted to the CoAP server, the latter will reply with the requested data.
- 6) If supported, the response will be through CoAP to the client. Otherwise, the IoT gateway will be in charge of response translation.

Figure 4.6 Data retrieval operations: 1) the client C contacts a known IoT gateway GW1; 2) GW1 accesses the DGT to retrieve the list of IoT gateways available in a given area; 3a) GW1 selects one of these IoT gateways, namely GW2; 3b) GW1 discovers the nodes managed by the GW2 through the DLS or directly by contacting GW2; 4) finally, GW1 queries the node, associated with the resource of interest, managed by GW2.
4.3.3 Zeroconf‐based Local Service Discovery for Constrained Environments
Service discovery within a local network can be performed using several mechanisms. In scenarios where a huge number of devices are involved or external human intervention is complicated, it is desirable that all devices can automatically adapt to the surrounding environment. The same considerations apply to devices that do not reside in a particular environment but are characterized by mobility, for example smartphones. In both cases, a service discovery mechanism, which requires no prior knowledge of the environment, is preferable. In this section, we propose a novel lightweight Zeroconf‐based mechanism for service and resource discovery within local networks.
4.3.3.1 Architecture
Our local service discovery mechanism is based on the Zeroconf protocol suite. It involves the following elements:
- IoT nodes (smart objects) belonging to an IoT network;
- an IoT gateway, which manages the IoT network and acts as the RD;
- client nodes, which are interested in consuming the services offered by the IoT nodes.
We assume that IP multicast is supported within the local network and that DHCP [90] provides the dynamic configuration for the IP layer.
4.3.3.2 Service Discovery Protocol
There are essentially two relevant scenarios for the application of the proposed service discovery protocol:

Figure 4.7 Service advertisement by CoAP server detected by HTTP‐to‐CoAP proxy.
- a new device offering some service is added to the network and starts participating actively;
- a client, which is interested in consuming the services offered by the nodes already present in the network, discovers the available services.
In the former scenario, the procedure for adding a new service to the network can be performed in two different ways, depending whether:
- the smart object can be queried for its services (using the /.well‐known/core URI); or
- it posts the information related to the services it is offering on the IoT gateway, which acts as a resource directory.
The difference between the two scenarios also involves the characterization of the smart object as a CoAP server or as a CoAP client, respectively. If the device acts as a CoAP (origin) server, the service discovery procedure, as shown in Figure 4.7, is the following:
- The IoT node joins the network and announces its presence by disseminating a mDNS message for a new service type _coap._udp.local.
- The IoT gateway, listening for events related to service type _coap._udp.local., detects that a new node has joined the network.
- The IoT gateway queries the new node for its provided services by sending a CoAP GET request targeting the URI /.well‐known/core.
- The IoT node replies with a JSON‐WSP or CoRE Link Format document describing the offered services.
- The IoT gateway updates the list of services that it manages on behalf of the constrained nodes residing in the network, thus making these services consumable by clients residing outside of the IoT network (e.g., remote Internet hosts, which may be unaware of the constrained nature of the network where the service of interest is located).
If the device acts as a CoAP client, on the other hand, the service discovery procedure, as shown in Figure 4.8 , is the following:
- The proxy, which is a module of the IoT gateway, announces its presence periodically, by disseminating a mDNS message for a new service type _httpcoap._udp.local.
- The joining smart object, which is listening for events related to the service type advertised by the IoT gateway (_httpcoap._udp.local.), detects that an IoT gateway is available in the network.
- The smart object sends a CoAP GET request to the URI /.well‐known/core to get a description of the services that the IoT gateway provides and other information that might be used to detect the most suitable proxy for the client.
- The IoT gateway replies with a JSON‐WSP or CoRE Link Format document describing the services it provides.
- The smart object processes the payload and then sends a CoAP POST/PUT request to the IoT gateway to store resources to be made available to external clients.
In this scenario, the IoT gateway does not simply forward incoming requests and relay responses, but it acts as a server both towards
- the generator of the resource (CoAP client) from which it receives CoAP POST requests;
- external clients, to which it appears as the legitimate origin server, since the generator of the data is not a CoAP server.
When a client needs to discover the available services, the procedure comprises the following steps:
- The client sends a CoAP or HTTP request to the proxy targeting the URI /.well‐known/core.
- The proxy replies with a JSON‐WSP or CoRE Link Format document describing all the services managed on behalf of the nodes;
- The client then uses the received information to perform subsequent CoAP or HTTP requests in order to consume the required services.
The use of IP multicast (i.e., mDNS) has the chief advantage of avoiding having to set a priori the actual network address of any device present, thus eliminating the need for any configuration.
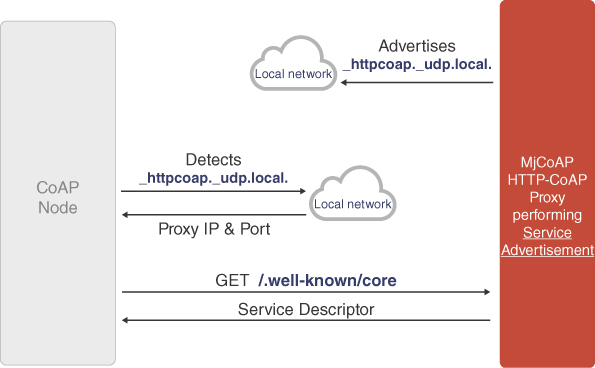
Figure 4.8 Service advertisement by HTTP‐to‐CoAP proxy detected by CoAP client.
4.3.4 Implementation Results
The solutions presented Sections 4.3.1–4.3.3 may be used for many large IoT scenarios in which scalable and reliable service and resource discovery is required. In particular, we focus on a smart‐infrastructure surveillance scenario, where given areas of interest can be monitored by means of wireless devices. Each device (smart object) is characterized by the type of the collected data and by its position. A system user may then be interested either in directly contacting a given resource (e.g., a sensor) or having the list of all available resources in a given area. Such wireless sensors are grouped in low‐power wireless networks with one or more gateways acting as interfaces between the resulting constrained wireless network and the rest of the network (namely, in the considered scenario, the Internet).
In order to validate the feasibility of the proposed solution and to evaluate its performance, extensive experimentation has been carried out in the reference smart‐infrastructure surveillance scenario. The performance evaluation focuses on both local and large‐scale service discovery mechanisms, as described in Sections 4.3.2 and 4.3.3, respectively.
4.3.4.1 Local Service Discovery
The first phase of the experimental performance analysis focuses on the discovery of new CoAP services (associated with constrained devices) available in the local network.
The performance evaluation of our Zeroconf‐based local service discovery strategy was conducted using Zolertia Z1 Contiki nodes, simulated in the Cooja simulator. The Contiki software stack running on each node was configured so as to fit in the Z1's limited available memory, in terms of both RAM and ROM – Z1 nodes feature a nominal 92 kB ROM (when compiling with 20‐bit architecture support) and an 8 kB RAM. In practice, the compilation with the Z1 nodes was performed with a 16‐bit target architecture, which lowers the amount of available ROM to roughly 52 kB. The simulated smart objects run Contiki OS, uIPv6, RPL, NullMAC, and NullRDC. The software stack deployed on the smart objects includes our lightweight implementation of the mDNS [82] and DNS‐SD [83] protocols, developed in order to minimize memory footprint and to include all the needed modules in the smart objects. The implementations comply with the IETF standards defined in the RFCs and can be replaced by any other compatible implementation, should no particular constraint on the code size be present. The local service discovery mechanism was tested on IEEE 802.15.4 networks formed by Contiki nodes arranged in linear and grid topologies. The performance indicators were:
- the time needed to perform a DNS‐SD query – from the DNS‐SD client perspective;
- the time needed to process an incoming DNS‐SD query and respond – from the DNS‐SD server perspective.
The impact of the number of constrained nodes (and, therefore, the number of hops needed) in the network was analyzed. All the results were obtained by performing 100 service discovery runs on each configuration. The specific performance metrics are detailed in Table 4.1.
Table 4.1 Local service discovery metrics.
| Metric | Description | Dimension |
| QC | Query client time: the time needed by a node acting as client to send a DNS‐SD query and receive a response | ms |
| QS | Query server time: the time needed by a node acting as server to construct and send a response back to a DNS‐SD client | ms |
In Figure 4.9a, the considered linear topology, with a maximum of 20 nodes deployed in Cooja, is shown. In particular:
- node 1 is the 6LoWPAN border router (6LBR), which is the root of the RPL tree;
- node 2 is the node acting as DNS‐SD server;
- node 3 is the node acting as DNS‐SD client.
The distance between nodes was set so that the query had to follow a multi‐hop path consisting of as many hops as the number of nodes in the network. In Figure 4.9b, the corresponding performance, in terms of QC/QS times, as functions of the number of smart objects, is shown. The QS time has a nearly constant value of around 65 ms, since the processing time is independent of the number of nodes in the network. The QC time is a linear function of the number of hops (which, in our scenario, coincides with the number of nodes), since the query packet has to be relayed by each intermediate node to reach the DNS‐SD server node.
![Illustration of linear topology considered for multihop Zeroconf-based service discovery (top). Average time (dimension: [ms]) of Zeroconf-based service discovery on Contiki nodes with linear topology (bottom).](images/c04f009.jpg)
Figure 4.9 (a) Linear topology considered for multi‐hop Zeroconf‐based service discovery; (b) average time of Zeroconf‐based service discovery on Contiki nodes with linear topology.
More complex bi‐dimensional topologies were also tested in order to evaluate grid‐like deployments. Different sizes and arrangements for grids were considered, as shown in Figure 4.10 . In all cases:
- node 1 is the 6LBR;
- node 2 is the node acting as DNS‐SD server;
- node 3 is the node acting as DNS‐SD client.
The topologies in Figure 4.10 are: (a) Grid‐A (3 hops); (b) Grid‐B (4 hops); (c) Grid‐C (6 hops); (d) Grid‐D (5 hops). The corresponding performance of service resolution, in terms of QC/QS times, is shown in Figure 4.11. Just like in the linear case, the QS time is independent of the network size (around 65 ms were still needed by the DNS‐SD server‐side processing). As the number of nodes participating in the network increases, the QC time increases as well, because of the need for multi‐hop communications from client to server. It can be seen that, in the case of Grid‐D, even though the number of nodes is larger than in the case of Grid‐C, the QC time is shorter. This is because the distance between the nodes has decreased from 40 m to 30 m (to minimize collisions due to the use of NullMAC) and, therefore, the total number of hops from the client to the server decreases. In general, it can be concluded that, at a fixed node density, the QC time is a linear function of the number of hops.
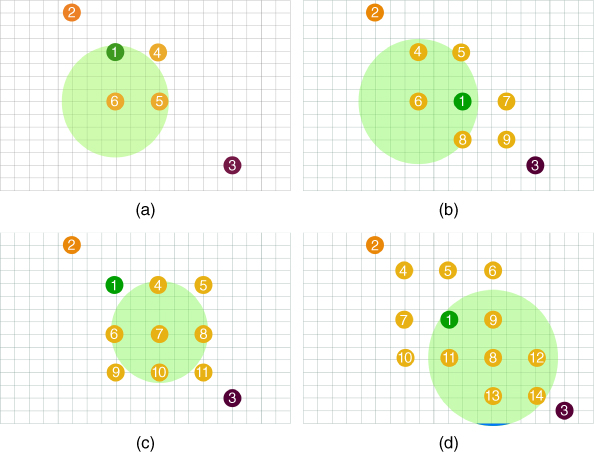
Figure 4.10 Grid topologies considered for bi‐dimensional deployments of smart objects: (a) Grid‐A (3 hops); (b) Grid‐B (4 hops); (c) Grid‐C (6 hops); (d) Grid‐D (5 hops).

Figure 4.11 Average QC/QS times of the Zeroconf‐based service discovery in the grid topologies shown in Figure 4.10.
4.3.4.2 Large‐scale Service Discovery
The second performance evaluation phase focuses on a P2P overlay in which multiple IoT gateways join the network in order to store new resouces in the DLS overlay and retrieve references to existing ones. The aim of this evaluation was to test the validity of the proposed approach with different configurations and, in particular, to measure the average time required by an IoT gateway to complete the three main actions in the network (JOIN, PUT and GET) for different sizes of the P2P overlay. We focus only on the evaluation of the DLS overlay since the published content pertains to IoT services and resources and, therefore, it represents the component of the proposed service discovery architecture that is directly related to IoT services and resources. The DGT allows for a structured geographical network that can be used to efficiently discover available nodes based on location criteria in a content‐agnostic way; this is what the DGT was designed and thoroughly evaluated for, both in simulative environments and real‐world deployments [91], [92].
The performance evaluation was carried out for several configurations, with different numbers of IoT gateways (which are also the peers of the overlay). Each IoT gateway acts as boundary node of a wireless network with CoAP‐aware sensor nodes. The DLS overlay uses a Kademlia DHT and the dSIP protocol for P2P signalling [87], [93], both implemented in Java. The P2P overlay contains up to 1000 nodes deployed over an evaluation platform comprising four cluster hosts, each an 8‐CPU Intel®Xeon®E5504 running at 2.00 GHz, with 16∼GB RAM and running the Ubuntu 12.04 operating system. The number of nodes in the P2P network was split evenly among all cluster hosts (up to 250 peers per cluster host), which were connected using a traditional switched Ethernet LAN. The HTTP‐to‐CoAP proxy functionality relies on two different implementations:
- one based on the mjCoAP library [23], an open‐source Java‐based RFC‐compliant implementation of the CoAP protocol;
- the other based on the Californium platform [94].
Both HTTP‐to‐CoAP proxies were written in Java and provide their own local service discovery mechanisms. The use of two different types of HTTP‐to‐CoAP proxy shows clearly how the overlay can be easily developed and integrated with currently available technologies. The sensor nodes are either Arduino boards or Java‐based emulated CoAP nodes (just for emulating large network scenarios).
Each performance result is obtained by averaging over 40 executions of PUT and GET procedures for each size of the overlay.
As anticipated, the following performance metrics are of interest:
- elapsed time for a JOIN operation (dimension: [ms]);
- number of rounds for PUT operations (adimensional);
- number of rounds for GET operations (adimensional).
The selection of the number of rounds for PUT and GET operations, rather than their times, is expedient to present performance results that are independent of the actual deployment environment. For the JOIN operation, the average total time required to completion is shown in order to provide a practical measurement of the complexity of this operation. However, the very nature of all operations relies on a common iterative procedure [78], thus making it possible to intuitively derive the behavior of all operations in terms of time and rounds.
The performance results are shown in Figure 4.12. As expected, the complexity, in terms of JOIN time and numbers of rounds for PUT/GET operations, is a logarithmically increasing function of the number of peers. In Figure 4.12, the experimental data are directly compared with the following logarithmic fitting curves [95]:
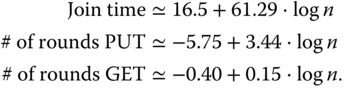

Figure 4.12 Experimental results collected to evaluate the performance of the DLS overlay: (a) average elapsed time for JOIN operations, (b) the average number of rounds (adimensional) for PUT operations, and (c) the average number of rounds (adimensional) for GET operations on the DLS towards the number of active IoT gateways in the P2P network. Plotted data have also been used to construct fitted curves (in red); the formulae of which are reported in the top‐right hand corners.
This clearly proves the scalability brought by the use of a P2P approach, confirming the formal analysis and results of Maymounkov and Mazières [ 78 .
To summarize, we have presented a novel architecture for self‐configurable, scalable, and reliable large‐scale service discovery. The proposed approach provides efficient mechanisms for both local and global service discovery. First, we have described the IoT gateway and the functionalities that this element must implement to perform resource and service discovery. Then, we have focused on large‐scale distributed resource discovery, exploiting a proper P2P overlays, namely DLS and DGT, which implement, respectively, “white‐pages” and “yellow‐pages” services. Finally, we have shown a solution for automated local service discovery that allows for discovery of resources available in constrained WSNs and their publication into the P2P overlay with no need for any prior configuration (Zeroconf).
Extensive experimental performance evaluation of the proposed local and large‐scale service discovery mechanisms was performed. For the local service discovery mechanism, experiments were conducted on Contiki‐based nodes operating in constrained (IEEE 802.15.4) networks with RPL in the Cooja simulator. The large‐scale service discovery mechanism was deployed and tested on P2P overlays of different sizes, spanning from a few to 1000 peers, in order to evaluate the performance in terms of scalability and self‐configuration. The results show that the time required for service resolution in the Zeroconf‐based approach for local service discovery is linearly dependent on the number of hops in the path between the client and server node. For large‐scale service discovery, the adoption of a P2P overlay provides scalability in terms of the time required to perform the basic publish/lookup operations.
In conclusion, the easy and transparent integration of two different types of overlays shows the feasibility and reliability of a large‐scale architecture for efficient and self‐configurable service and resource discovery in IoT networks.
4.4 Lightweight Service Discovery in Low‐power IoT Networks
Zeroconf [60] is a protocol suite which reuses the semantics of DNS messages over IP multicast to provide name resolution and service discovery/advertisement over local networks. In order to support Zeroconf service discovery mechanisms, it is very important that the network supports IP multicasting and implements proper forwarding techniques to guarantee that packets are delivered to all group nodes and avoids the establishment of loops. Using efficient packet forwarding mechanisms can bring benefits in multi‐hop communications among smart objects, in terms of delay and energy consumption. Moreover, it is also important to note that the limited amount of memory available on smart objects requires the adoption of small‐footprint mechanisms, in order to allow developers to integrate a complete software stack, without having to sacrifice some modules in order to meet the memory constraints. Although the IETF ROLL working group is defining a Multicast Protocol for Low power and Lossy Networks (MPL) [96], based on the Trickle algorithm [97], some applications might have different requirements and could benefit from the adoption of other multicast techniques.
In the following sections we present a lightweight and low‐power multicast forwarding protocol for service discovery in smart objects operating in IEEE 802.15.4 multi‐hop networks. The proposed solution features a smaller memory footprint than in other state‐of‐the‐art solutions. The proposed mechanism has been implemented on Contiki OS‐enabled smart objects. Extensive testing is carried out in the Cooja simulator to evaluate the feasibility and efficiency, in terms of delay and energy consumption, of the proposed mechanism.
Local service discovery mechanisms in LANs have been proposed in the literature. Protocols like UPnP [57] and SLP [58], [59] focus on automatic announcement and discovery of in‐network existing services. However, their porting to IoT devices is not straightforward because of the severe computation and energy constraints of the nodes. An alternative to these protocols relies on multicast forwarding. For instance, Jung and Kastner proposed an efficient group communication strategy for the CoAP and the Efficient XML Interchange protocols [98]. To achieve group communication, they rely on the Open Building Information eXchange standard. However, this implementation runs on Raspberry PI nodes, so it is not suitable for constrained devices.
Concerning 6LoWPAN and IPv6, the only active IETF draft on efficient multicast forwarding is MPL [96], that relies on the Trickle algorithm to manage transmissions for both control and data plane. The different multicast interfaces, identified by an unicast address and associated with one or more multicast domains, are handled separately, so as to maintain an independent seed set to decide whether to accept a packet or not. The MPL forwarder, which is in charge of sending data messages, has two different possible strategies: proactive or reactive. In the former case, the MPL forwarder schedules the transmission of MPL data messages using the Trickle algorithm, without any prior indication that neighbor nodes are yet to receive the message. After transmitting a limited number of MPL data messages, the MPL forwarder may terminate proactive forwarding for the MPL data message. In the latter, the MPL forwarder sends link‐local multicast MPL control messages using the Trickle algorithm. MPL forwarders use MPL control messages to discover new MPL data messages that have not yet been received. When an MPL forwarder discovers that a neighbor MPL forwarder has not yet received an MPL data message, it schedules the transmission of those MPL data messages using the Trickle algorithm. The two approaches can coexist at the same time.
Oikonomou and Phillips proposed Stateless Multicast RPL Forwarding (SMRF [99]), which relies on the presence of the RPL routing protocol and requires group management information to be carried inside RPL destination advertisement object (DAO) messages. However, since, for our goal, a less complicated multicast strategy (no group management is required) is needed, we prefer to rely on a more lightweight flooding technique, which adapts well to duty‐cycled devices operating in RPL networks implementing the Zeroconf protocol suite.
4.4.1 Efficient Forwarding Protocol for Service Discovery
Zeroconf is a protocol that allows for automatic creation of computer networks based on the TCP/IP Internet stack. It does not require any external configuration [60]. Zeroconf provides three main functionalities:
- automatic network address assignment;
- automatic distribution and resolution of host names;
- automatic location of network services.
Automatic network assignment comes into the picture when a node first connects to the network. The host name distribution and resolution is implemented using multicast DNS (mDNS) [61], a service that has the same interfaces, packet formats, and semantics as standard DNS, so as to resolve host names in networks that do not include a local name server. Zeroconf also allows to for publication of services (DNS‐SD) in a local network. Both mDNS and DNS‐SD do not require the presence of any server (and, therefore, its knowledge) to perform publish, lookup, and name resolution operations, but rely on the use of IP multicast communications in order to address all the nodes in the local network. Zeroconf specifies that mDNS and DNS‐SD messages (for both requests and responses) must be sent to the mDNS IPv4/IPv6 link‐local multicast address (i.e., 224.0.0.251 and ff02::fb, respectively). However, Zeroconf does not require per‐group multicast routing: according to the protocol specifications, messages should simply reach all nodes in the local network.
6LoWPAN defines methods
- to transmit IPv6 packets and
- to form IPv6 link‐local addresses and statelessly autoconfigure addresses on IEEE 802.15.4 networks.
The RPL protocol defines a routing protocol for IP communications in LLNs. The IETF ROLL Working Group is working on the definition of MPL, a multicast protocol providing IPv6 multicast forwarding in constrained networks. This could become a general multicast technique able to manage multicast groups of any size. However, in some scenarios, such as Zeroconf service discovery, there is no need to actually adopt such a full‐feature multicast protocol. For the sake of Zeroconf service discovery, it is sufficient to provide a multicast forwarding mechanism that guarantees that messages can be delivered to all nodes in the local network. In this section, we detail a simple and efficient forwarding algorithm that can be adopted by constrained devices operating in RPL networks with ContikiMAC radio duty‐cycling protocol, in order to enable IP multicast communications with a small footprint, targeting Zeroconf service discovery.
4.4.1.1 Multicast through Local Filtered Flooding
Flooding is the simplest routing protocol for broadcasting a packet to all nodes in the network. From a practical implementation point of view, each node forwards a received packet to all its neighbors. This technique is effective only for cycle‐free topologies (i.e., trees). In the presence of graphs with cycles, it is necessary to implement duplicate detection techniques to avoid forward loops. An illustration is shown in Figure 4.13.

Figure 4.13 Flooding of a DNS‐SD query in generic topology with cycles.
In order to implement an efficient mechanism to detect already‐processed packets (and, thus, avoid redundant forwarding), we propose the adoption of Bloom filters [100]. Bloom filters are probabilistic data structures that can be used to add elements to a set and to efficiently check whether an element belongs to the set or not. Bloom filters provide two primitives:
- add(x): add element x to the set;
- query(x): test to check whether element x is in the set.
The filter does not provide a remove(x) primitive, so it is not possible to undo an insertion. Bloom filters are slower when performing check operations than equivalent probabilistic data structures (in terms of provided functionalities), such as quotient filters [101], but occupy less memory. As available memory on smart objects is extremely limited, one of the design goals of the proposed forwarding algorithm is to keep the memory footprint (both in terms of RAM and ROM) as low as possible. Therefore, Bloom filters have been selected as the most appropriate data structure to keep track of already‐processed packets.
A Bloom filter is initially an array of 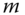 bits, all set to zero. The add(x) operation passes the input argument
bits, all set to zero. The add(x) operation passes the input argument  through
through  different hashing functions and obtains
different hashing functions and obtains 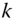 indexes in the bit array of the Bloom filter that will be set to one. The query(x) operation verifies whether the indexes corresponding to
indexes in the bit array of the Bloom filter that will be set to one. The query(x) operation verifies whether the indexes corresponding to  are all set to one. The Bloom filter is probabilistic in the sense that a query(x) operation can return false positives: there can exist two values
are all set to one. The Bloom filter is probabilistic in the sense that a query(x) operation can return false positives: there can exist two values  and
and  , such that query(
, such that query( ) = query(
) = query( ) = true. False negatives, on the other hand, are not possible: this means that if a query(x) returns false, then
) = true. False negatives, on the other hand, are not possible: this means that if a query(x) returns false, then  is not in filter. The query(x) operation can thus return either “probably in the set” or “not in the set”.
is not in filter. The query(x) operation can thus return either “probably in the set” or “not in the set”.
Bloom filters can be instantiated to meet specific application requirements by selecting the parameters  (number of bits in the array) and
(number of bits in the array) and  (number of hashing functions). For instance, the choice of
(number of hashing functions). For instance, the choice of  and
and  has an impact on the probability of getting false positives for query(x) operations and on memory occupation. In any case, the impossibility of removing an element from the filter leads to an increase in the probability of false positives as more and more elements are added to the filter. Since the purpose of using a Bloom filter in the forwarding algorithm is to detect duplicate elements, in order to cope with the problem of false positives, the Bloom filter is periodically reset. Resetting the filter might introduce some unnecessary retransmissions if the filter is emptied before receiving a duplicate packet. However, retransmissions are preferable to packet drops in order to guarantee that a multicast packet reaches all hosts. Moreover, such unnecessary retransmissions might occur no more than once, as the packet would then be added to the filter and not processed upon future receptions. To summarize, upon receiving a packet, a node will perform the following steps:
has an impact on the probability of getting false positives for query(x) operations and on memory occupation. In any case, the impossibility of removing an element from the filter leads to an increase in the probability of false positives as more and more elements are added to the filter. Since the purpose of using a Bloom filter in the forwarding algorithm is to detect duplicate elements, in order to cope with the problem of false positives, the Bloom filter is periodically reset. Resetting the filter might introduce some unnecessary retransmissions if the filter is emptied before receiving a duplicate packet. However, retransmissions are preferable to packet drops in order to guarantee that a multicast packet reaches all hosts. Moreover, such unnecessary retransmissions might occur no more than once, as the packet would then be added to the filter and not processed upon future receptions. To summarize, upon receiving a packet, a node will perform the following steps:
- Check if the incoming IP packet has already been processed, by performing a query operation in the Bloom filter.
- If the Bloom filter contains the packet, discard it; otherwise, the packet is added to the Bloom filter through an add operation.
- If needed, forward the received IP packet to all neighbors by means of local IEEE 802.15.4 broadcast.
4.4.2 Efficient Multiple Unicast Forwarding
While the described algorithm implements an optimized flooding mechanism by avoiding loops through the introduction of Bloom filters, broadcasting with the ContikiMAC radio duty‐cycling protocol results in inefficient transmissions, leading to higher energy consumption and end‐to‐end delays. In fact, in ContikiMAC, a broadcasting node must repeatedly transmit a packet for the full wake‐up interval [49], in order to ensure that it can be received by all neighbor nodes, regardless of their wake‐up time. This conservative approach has the following drawbacks:
- the number of transmitted packets is larger than necessary, and therefore energy consumption is higher;
- when a node is broadcasting a packet, other nodes are not allowed to transmit, and this delays the transmission until the channel is clear;
- since ContikiMAC broadcasting does not make provision to acknowledge received packets, it might be that not all neighbors have successfully received the packet, thus leading to unreliable transmission.
These inefficiencies are magnified when the channel check rate (CCR) decreases, since the full wake‐up interval is longer and therefore the channel is busy for longer, thus leading to even more repeated transmissions and delays. This contrasts with the assumption that lower CCR leads to lower energy consumption. In order to tackle these issues, we replace local broadcast with multiple unicast transmission. The forwarding algorithm can therefore be optimized by selecting the receiving nodes from the list of next hops, which is retrieved from the RPL routing table. In fact, ContikiMAC provides per‐node‐pair synchronization, which ensures that packets are sent only when the receiver is supposed to be active. The receiver is required to send an acknowledgement for the received packet, thus transmitting packets only for as long as necessary, thus leading to more reliable transmissions.
The enhanced version of the proposed multicast protocol can therefore be detailed as follows:
- Check if the incoming IP packet has been processed already by performing a query operation in the Bloom filter.
- If the Bloom filter contains the packet, discard it; otherwise, add the packet to the Bloom filter through an add operation.
- Retrieve the list of next hops from the routing table.
- If needed, forward the received IP packet to each next hop using IEEE 802.15.4 unicast communication.
An excerpt of a sequence of transmitted frames, using broadcast for a DNS‐SD query, is shown in Figure 4.14.
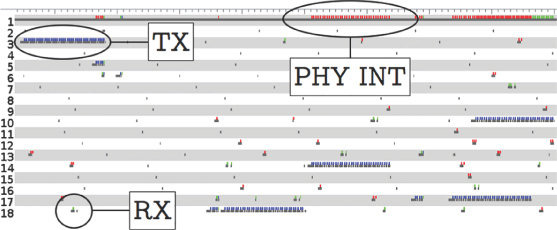
Figure 4.14 DNS‐SD query propagation DNS‐SD query propagation with ContikiMAC broadcast. Time is on the  ‐axis while node identifiers are on the
‐axis while node identifiers are on the  ‐axis.
‐axis.
The equivalent packet flooding with multiple unicast transmissions is shown in Figure 4.15. Transmitted packets (TX), received packets (RX), and PHY interference (PHY INT) are highlighted. The root of the RPL tree (node 1) is always active, while all other nodes have CCR = 8 Hz. The timelines clearly show that multiple unicast transmissions optimize the number of transmitted packets and the packet propagation delay in the network, while guaranteeing more reliable transmissions. However, this comes at the cost of a slightly increased ROM/RAM footprint.
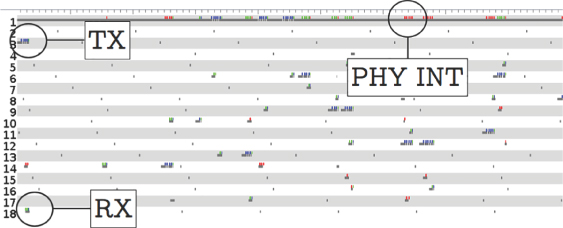
Figure 4.15 DNS‐SD query propagation with multi‐unicast. Time is on the  ‐axis while node identifiers are on the
‐axis while node identifiers are on the  ‐axis.
‐axis.
4.5 Implementation Results
In order to evaluate the performance of the proposed multicast packet forwarding mechanism, a Contiki‐based implementation has been developed. Besides the proposed multicast forwarding algorithm, the mDNS and DNS‐SD protocols have been re‐implemented, in order to have a smaller memory footprint than in other, already available implementations. The performance evaluation of the Zeroconf‐based local service discovery strategy was conducted using WiSMote4 Contiki nodes, simulated in the Cooja simulator. The Contiki software stack running on each node was configured in order to fit in the WiSMote's available memory, in terms of both RAM and ROM – WiSMote nodes feature a nominal 128 kB, 192 kB or 256 kB ROM and 16 kB RAM. The simulated smart objects run Contiki OS, uIPv6, RPL, and ContikiMAC.
The local service discovery mechanism was tested on Contiki nodes arranged in linear and grid topologies, as shown in Figure 4.16, in IEEE 802.15.4 networks, with RPL as routing protocol and ContikiMAC as radio duty‐cycling protocol. In particular:
- node 1 is the 6LoWPAN border router (6LBR), which is the root of the RPL tree;
- node 2 is the node acting as DNS‐SD server;
- node 3 is the node acting as DNS‐SD client.
The first performance indicator is memory occupation in terms of ROM. The proposed multicast protocol – both with broadcast and multiple unicast transmission – is compared to the MPL (with Trickle algorithm) implementation available in the Contiki 3.x fork. The results are shown in Table 4.2.
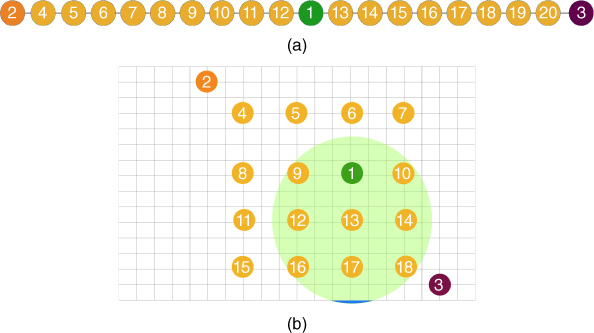
Figure 4.16 Topologies considered for Zeroconf service discovery experimentation with the proposed multicast protocol: (a) linear and (b) grid.
Table 4.2 ROM usage for the proposed multicast protocol and an MPL implementation: total ROM occupation and as a percentage of available memory on 128‐kB WiSMote.
| Library | ROM occupation [B] | Occupation of overall available ROM |
| This work (broadcast) | 842 | 0.64% |
| This work (multiple unicast) | 1454 | 1.11% |
| MPL with Trickle | 3804 | 2.90% |
As expected, the footprint of the proposed solution is significantly smaller than that of the MPL implementation: approximately 78% for broadcast and 62% for multiple unicast.
The next phase of experimentation aims at evaluating the time and the overall network energy consumption needed to perform advertisement and resolution of services using Zeroconf in the topologies shown in Figure 4.16 and the proposed broadcast‐based and multiple unicast‐based approaches. All the results were obtained by performing 100 service discovery runs on each configuration. The specific performance metrics are:
- query client time (QC), which is the time needed by a node acting as client to send a DNS‐SD query and receive a response (dimension: [ms]);
- energy consumption (E), which is the overall network energy consumption for a DNS‐SD query operation (dimension: [mJ]).
The impact of the CCR (varying from 8 Hz to 128 Hz) of the nodes participating in the constrained network is analyzed. The results for QC and E are shown in Figures 4.17 and 4.18, respectively. As expected, QC is inversely proportional to the CCR. The benefit of using multiple unicast transmissions, instead of broadcast, is higher when the CCR is low, while the two approaches tend to overlap for higher values of the CCR. At typical CCR values, multiple unicast performs better than broadcast because, with lower CCR, the wake‐up interval is longer and ContikiMAC broadcast transmissions occupy the channel for the whole interval. Higher CCR values mean shorter wake‐up intervals and therefore other nodes in the network are likely to be blocked.
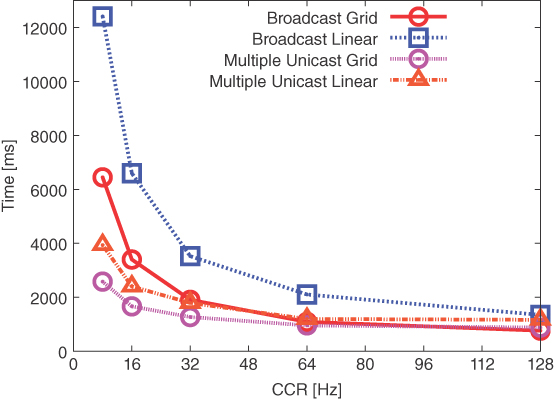
Figure 4.17 Time required to perform a DNS‐SD query by a client in linear and grid topologies with broadcast and multiple unicast.
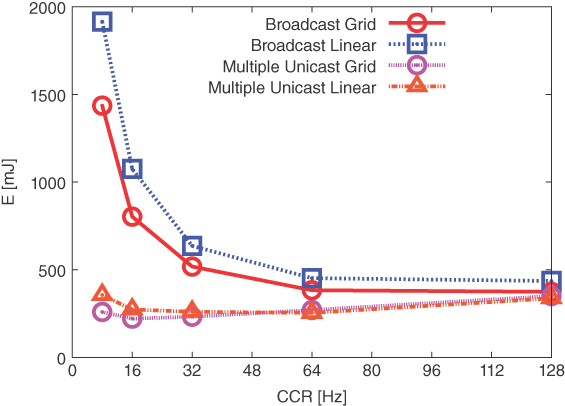
Figure 4.18 Overall network energy consumption when a client performs a DNS‐SD query in linear and grid topologies with broadcast and multiple unicast.
In the case of the grid topology, with a CCR of 128 Hz, broadcast is actually slightly faster than unicast. In fact, at this high rate, the smart objects are almost behaving as with null duty‐cycling, which is the best‐case scenario for broadcast transmission. As for energy consumption, the results clearly show that broadcast is much more inefficient than multiple unicast transmissions. It is important to point out that a significant contribution (more than 60% with multiple unicast and 30% with broadcast, at CCR = 8 Hz) to the energy consumption of the overall network comes from the border router, which does not perform duty‐cycling. Again, this is motivated by the ContikiMAC broadcast strategy, which requires nodes to transmit for the whole wake‐up interval. As for QC, the two approaches tend to overlap at high CCR. However, these results should not be interpreted as a suggestion to use higher CCR, as this would invalidate all the advantages of duty‐cycling, which is particularly beneficial in other scenarios.
We introduced a novel multicast forwarding mechanism targeting service discovery in IoT scenarios. The proposed solution is suited to bringing efficient IP‐multicast support to low‐power IoT networks with duty‐cycled devices. The rationale behind the presented forwarding mechanism is to have a lightweight and low‐memory‐footprint implementation for specific Zeroconf service discovery operations. In such scenarios, the adoption of a full‐featured multicast implementation, such as MPL, might be overkill, since there is no need to provide multicast group support. Instead, an efficient flooding mechanism is used in the local network. The proposed multicast protocol relies on filtered local flooding, which adapts well to duty‐cycled devices operating in LLNs with RPL. In order to avoid forward loops, we introduce Bloom filters, an efficient probabilistic data structure, to detect duplicate packets and prevent forward loops. The experimental results demonstrate that the proposed multicast protocol features a much smaller footprint, in terms of ROM occupation, than the MPL implementation available in the official Contiki fork. Finally, delay and network energy consumption have been evaluated.