Back End Sheet
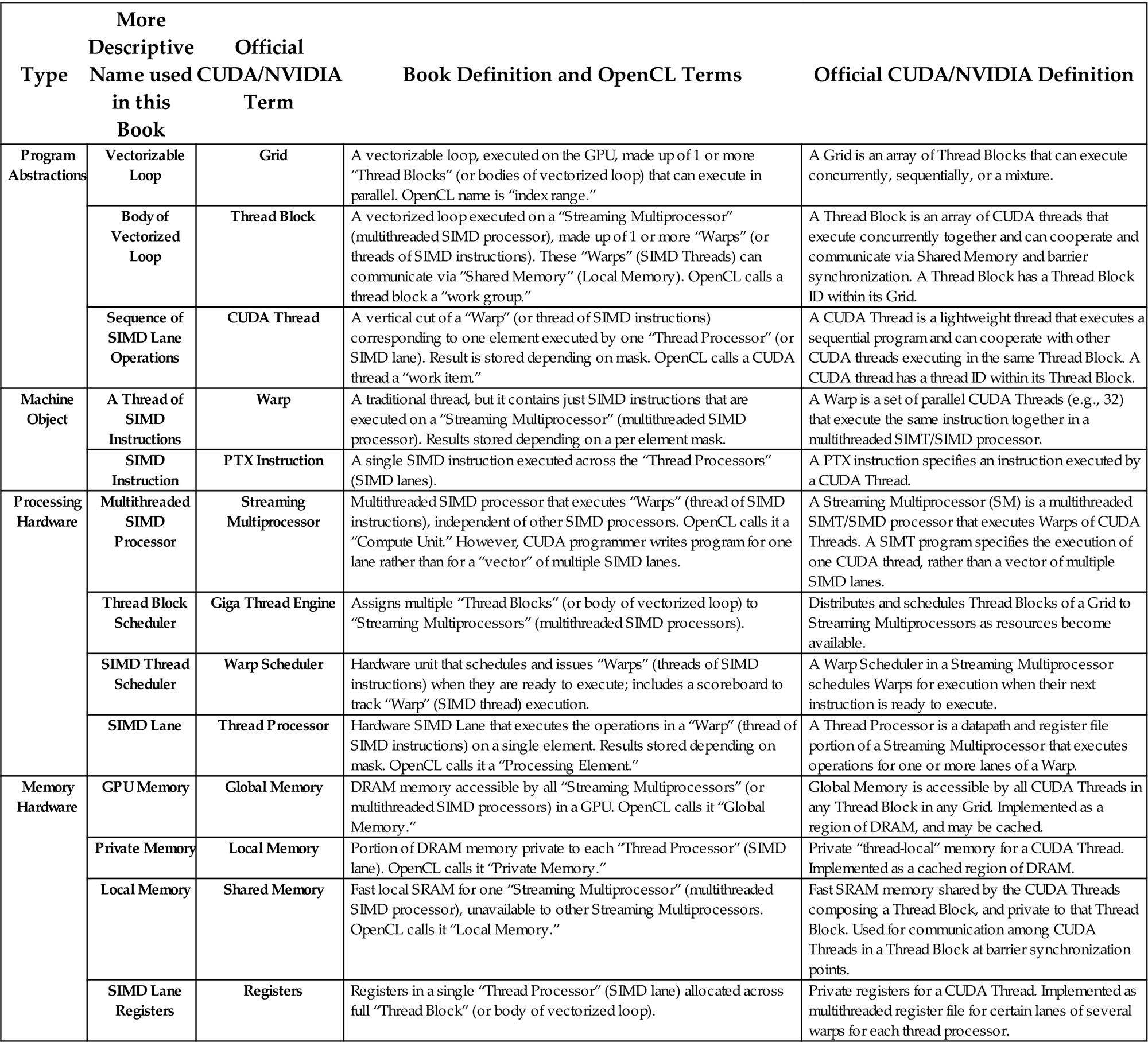
Translation between GPU terms in book and official NVIDIA and OpenCL terms.
| Type | More Descriptive Name used in this Book | Official CUDA/NVIDIA Term | Book Definition and OpenCL Terms | Official CUDA/NVIDIA Definition |
|---|---|---|---|---|
| Program Abstractions | Vectorizable Loop | Grid | A vectorizable loop, executed on the GPU, made up of 1 or more “Thread Blocks” (or bodies of vectorized loop) that can execute in parallel. OpenCL name is “index range.” | A Grid is an array of Thread Blocks that can execute concurrently, sequentially, or a mixture. |
| Body of Vectorized Loop | Thread Block | A vectorized loop executed on a “Streaming Multiprocessor” (multithreaded SIMD processor), made up of 1 or more “Warps” (or threads of SIMD instructions). These “Warps” (SIMD Threads) can communicate via “Shared Memory” (Local Memory). OpenCL calls a thread block a “work group.” | A Thread Block is an array of CUDA threads that execute concurrently together and can cooperate and communicate via Shared Memory and barrier synchronization. A Thread Block has a Thread Block ID within its Grid. | |
| Sequence of SIMD Lane Operations | CUDA Thread | A vertical cut of a “Warp” (or thread of SIMD instructions) corresponding to one element executed by one “Thread Processor” (or SIMD lane). Result is stored depending on mask. OpenCL calls a CUDA thread a “work item.” | A CUDA Thread is a lightweight thread that executes a sequential program and can cooperate with other CUDA threads executing in the same Thread Block. A CUDA thread has a thread ID within its Thread Block. | |
| Machine Object | A Thread of SIMD Instructions | Warp | A traditional thread, but it contains just SIMD instructions that are executed on a “Streaming Multiprocessor” (multithreaded SIMD processor). Results stored depending on a per element mask. | A Warp is a set of parallel CUDA Threads (e.g., 32) that execute the same instruction together in a multithreaded SIMT/SIMD processor. |
| SIMD Instruction | PTX Instruction | A single SIMD instruction executed across the “Thread Processors” (SIMD lanes). | A PTX instruction specifies an instruction executed by a CUDA Thread. | |
| Processing Hardware | Multithreaded SIMD Processor | Streaming Multiprocessor | Multithreaded SIMD processor that executes “Warps” (thread of SIMD instructions), independent of other SIMD processors. OpenCL calls it a “Compute Unit.” However, CUDA programmer writes program for one lane rather than for a “vector” of multiple SIMD lanes. | A Streaming Multiprocessor (SM) is a multithreaded SIMT/SIMD processor that executes Warps of CUDA Threads. A SIMT program specifies the execution of one CUDA thread, rather than a vector of multiple SIMD lanes. |
| Thread Block Scheduler | Giga Thread Engine | Assigns multiple “Thread Blocks” (or body of vectorized loop) to “Streaming Multiprocessors” (multithreaded SIMD processors). | Distributes and schedules Thread Blocks of a Grid to Streaming Multiprocessors as resources become available. | |
| SIMD Thread Scheduler | Warp Scheduler | Hardware unit that schedules and issues “Warps” (threads of SIMD instructions) when they are ready to execute; includes a scoreboard to track “Warp” (SIMD thread) execution. | A Warp Scheduler in a Streaming Multiprocessor schedules Warps for execution when their next instruction is ready to execute. | |
| SIMD Lane | Thread Processor | Hardware SIMD Lane that executes the operations in a “Warp” (thread of SIMD instructions) on a single element. Results stored depending on mask. OpenCL calls it a “Processing Element.” | A Thread Processor is a datapath and register file portion of a Streaming Multiprocessor that executes operations for one or more lanes of a Warp. | |
| Memory Hardware | GPU Memory | Global Memory | DRAM memory accessible by all “Streaming Multiprocessors” (or multithreaded SIMD processors) in a GPU. OpenCL calls it “Global Memory.” | Global Memory is accessible by all CUDA Threads in any Thread Block in any Grid. Implemented as a region of DRAM, and may be cached. |
| Private Memory | Local Memory | Portion of DRAM memory private to each “Thread Processor” (SIMD lane). OpenCL calls it “Private Memory.” | Private “thread-local” memory for a CUDA Thread. Implemented as a cached region of DRAM. | |
| Local Memory | Shared Memory | Fast local SRAM for one “Streaming Multiprocessor” (multithreaded SIMD processor), unavailable to other Streaming Multiprocessors. OpenCL calls it “Local Memory.” | Fast SRAM memory shared by the CUDA Threads composing a Thread Block, and private to that Thread Block. Used for communication among CUDA Threads in a Thread Block at barrier synchronization points. | |
| SIMD Lane Registers | Registers | Registers in a single “Thread Processor” (SIMD lane) allocated across full “Thread Block” (or body of vectorized loop). | Private registers for a CUDA Thread. Implemented as multithreaded register file for certain lanes of several warps for each thread processor. |