Technically, matrices are of fixed length and dimensions, so we cannot add or delete rows or columns. However, matrices can be reassigned, and thus we can achieve the same effect as if we had directly done additions or deletions.
Recall how we reassign vectors to change their size:
> x [1] 12 5 13 16 8 > x <- c(x,20) # append 20 > x [1] 12 5 13 16 8 20 > x <- c(x[1:3],20,x[4:6]) # insert 20 > x [1] 12 5 13 20 16 8 20 > x <- x[-2:-4] # delete elements 2 through 4 > x [1] 12 16 8 20
In the first case, x is originally of length 5, which we extend to 6 via concatenation and then reassignment. We didn’t literally change the length of x but instead created a new vector from x and then assigned x to that new vector.
Note
Reassignment occurs even when you don’t see it, as you’ll see in Chapter 14. For instance, even the innocuous-looking assignment x[2] <- 12 is actually a reassignment.
Analogous operations can be used to change the size of a matrix. For instance, the rbind() (row bind) and cbind() (column bind) functions let you add rows or columns to a matrix.
> one [1] 1 1 1 1 > z [,1] [,2] [,3] [1,] 1 1 1 [2,] 2 1 0 [3,] 3 0 1 [4,] 4 0 0 > cbind(one,z) [1,]1 1 1 1 [2,]1 2 1 0 [3,]1 3 0 1 [4,]1 4 0 0
Here, cbind() creates a new matrix by combining a column of 1s with the columns of z. We choose to get a quick printout, but we could have assigned the result to z (or another variable), as follows:
z <- cbind(one,z)
Note, too, that we could have relied on recycling:
> cbind(1,z)
[,1] [,2] [,3] [,4]
[1,] 1 1 1 1
[2,] 1 2 1 0
[3,] 1 3 0 1
[4,] 1 4 0 0Here, the 1 value was recycled into a vector of four 1 values.
You can also use the rbind() and cbind() functions as a quick way to create small matrices. Here’s an example:
> q <- cbind(c(1,2),c(3,4))
> q
[,1] [,2]
[1,] 1 3
[2,] 2 4Be careful with rbind and cbin(), though. Like creating a vector, creating a matrix is time consuming (matrices are vectors, after all). In the following code, cbind() creates a new matrix:
z <- cbind(one,z)
The new matrix happens to be reassigned to z; that is, we gave it the name z—the same name as the original matrix, which is now gone. But the point is that we did incur a time penalty in creating the matrix. If we did this repeatedly inside a loop, the cumulative penalty would be large.
So, if you are adding rows or columns one at a time within a loop, and the matrix will eventually become large, it’s better to allocate a large matrix in the first place. It will be empty at first, but you fill in the rows or columns one at a time, rather than doing a time-consuming matrix memory allocation each time.
You can delete rows or columns by reassignment, too:
> m <- matrix(1:6,nrow=3)
> m
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> m <- m[c(1,3),]
> m
[,1] [,2]
[1,] 1 4
[2,] 3 6Finding the distances between vertices on a graph is a common example used in computer science courses and is used in statistics/data sciences too. This kind of problem arises in some clustering algorithms, for instance, and in genomics applications.
Here, we’ll look at the common example of finding distances between cities, as it is easier to describe than, say, finding distances between DNA strands.
Suppose we need a function that inputs a distance matrix, where the element in row i, column j gives the distance between city i and city j and outputs the minimum one-hop distance between cities and the pair of cities that achieves that minimum. Here’s the code for the solution:
1 # returns the minimum value of d[i,j], i != j, and the row/col attainings
2 # that minimum, for square symmetric matrix d; no special policy on ties
3 mind <- function(d) {
4 n <- nrow(d)
5 # add a column to identify row number for apply()
6 dd <- cbind(d,1:n)
7 wmins <- apply(dd[-n,],1,imin)
8 # wmins will be 2xn, 1st row being indices and 2nd being values
9 i <- which.min(wmins[2,])
10 j <- wmins[1,i]
11 return(c(d[i,j],i,j))
12 }
13
14 # finds the location, value of the minimum in a row x
15 imin <- function(x) {
16 lx <- length(x)
17 i <- x[lx] # original row number
18 j <- which.min(x[(i+1):(lx-1)])
19 k <- i+j
20 return(c(k,x[k]))
21 }And here’s an example of putting our new function to use:
> q
[,1] [,2] [,3] [,4] [,5]
[1,] 0 12 13 8 20
[2,] 12 0 15 28 88
[3,] 13 15 0 6 9
[4,] 8 28 6 0 33
[5,] 20 88 9 33 0
> mind(q)
[1] 6 3 4The minimum value was 6, located in row 3, column 4. As you can see, a call to apply() plays a prominent role.
Our task is fairly simple: We need to find the minimum nonzero element in the matrix. We find the minimum in each row—a single call to apply() accomplishes this for all the rows—and then find the smallest value among those minima. But as you’ll see, the code logic becomes rather intricate.
One key point is that the matrix is symmetric, because the distance from city i to city j is the same as from j to i. So in finding the minimum value in the ith row, we need look at only elements i+1, i+2,..., n, where n is the number of rows and columns in the matrix. Note too that this means we can skip the last row of d in our call to apply() in line 7.
Since the matrix could be large—a thousand cities would mean a million entries in the matrix—we should exploit that symmetry and save work. That, however, presents a problem. In order to go through the basic computation, the function called by apply() needs to know the number of the row in the original matrix—knowledge that apply() does not provide to the function. So, in line 6, we augment the matrix with an extra column, consisting of the row numbers, so that the function called by apply() can take row numbers into account.
The function called by apply() is imin(), beginning in line 15, which finds the mininum in the row specified in the formal argument x. It returns not only the mininum in the given row but also the index at which that minimum occurs. When imin() is called on row 1 of our example matrix q above, the minimum value is 8, which occurs in index 4. For this latter purpose, the R function which.min(), used in line 18, is very handy.
Line 19 is noteworthy. Recall that due to the symmetry of the matrix, we skip the early part of each row, as is seen in the expression (i+1):(1x-1) in line 18. But that means that the call to which.min() in that line will return the minimum’s index relative to the range (i+1):(1x-1). In row 3 of our example matrix q, we would get an index of 1 instead of 4. Thus, we must adjust by adding i, which we do in line 19.
Finally, making proper use of the output of apply() here is a bit tricky. Think again of the example matrix q above. The call to apply() will return the matrix wmins:
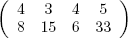
As noted in the comments, the second row of that matrix contains the upper-diagonal minima from the various rows of d, while the first row contains the indices of those values. For instance, the first column of wmins gives the information for the first row of q, reporting that the smallest value in that row is 8, occurring at index 4 of the row.
Thus line 9 will pick up the number i of the row containing the smallest value in the entire matrix, 6 in our q example. Line 10 will give us the position j in that row where the minimum occurs, 4 in the case of q. In other words, the overall minimum is in row i and column j, information that we then use in line 11.
Meanwhile, row 1 of apply()’s output shows the indices within those rows at which the row minima occur. That’s great, because we can now find which other city was in the best pair. We know that city 3 is one of them, so we go to entry 3 in row 1 of the output, finding 4. So, the pair of cities closest to each other is city 3 and city 4. Lines 9 and 10 then generalize this reasoning.
If the minimal element in our matrix is unique, there is an alternate approach that is far simpler:
minda <- function(d) {
smallest <- min(d)
ij <- which(d == smallest,arr.ind=TRUE)
return(c(smallest,ij))
}This works, but it does have some possible drawbacks. Here’s the key line in this new code:
ij <- which(d == smallest,arr.ind=TRUE)
It determines the index of the element of d that achieves the minimum. The argument arr.ind=TRUE specifies that the returned index will be a matrix index—that is, a row and a column, rather than a single vector subscript. Without this argument, d would be treated as a vector.
As noted, this new code works only if the minimum is unique. If that is not the case, which() will return multiple row/column number pairs, contrary to our basic goal. And if we used the original code and d had multiple minimal elements, just one of them would be returned.
Another problem is performance. This new code is essentially making two (behind-the-scenes) loops through our matrix: one to compute smallest and the other in the call to which(). This will likely be slower than our original code.
Of these two approaches, you might choose the original code if execution speed is an issue or if there may be multiple minima, but otherwise opt for the alternate code; the simplicity of the latter will make the code easier to read and maintain.