
“You look at where you’re going and where you are and it never makes sense, but then you look back at where you’ve been and a pattern seems to emerge. And if you project forward from that pattern, then sometimes you can come up with something.”
Robert M. Pirsig
This chapter presents five patterns that address various types of concurrency architecture and design issues for components, subsystems, and applications: Active Object, Monitor Object, Half-Sync/Half-Async, Leader/Followers, and Thread-Specific Storage.
The choice of concurrency architecture has a significant impact on the design and performance of multi-threaded networking middleware and applications. No single concurrency architecture is suitable for all workload conditions and hardware and software platforms. The patterns in this chapter therefore collectively provide solutions to a variety of concurrency problems.
The first two patterns in this chapter specify designs for sharing resources among multiple threads or processes:
Both patterns can synchronize and schedule methods invoked concurrently on objects. The main difference is that an active object executes its methods in a different thread than its clients, whereas a monitor object executes its methods by borrowing the thread of its clients. As a result active objects can perform more sophisticated—albeit expensive—scheduling to determine the order in which their methods execute.
The next two patterns in this chapter define higher-level concurrency architectures:
Implementors of the Half-Sync/Half-Async and Leader/Followers patterns can use the Active Object and Monitor Object patterns to coordinate access to shared objects efficiently.
The final pattern in this chapter offers a different strategy for addressing certain inherent complexities of concurrency:
Implementations of all patterns in this chapter can use the patterns from Chapter 4, Synchronization Patterns, to protect critical regions from concurrent access.
Other patterns in the literature that address concurrency-related issues include Master-Slave [POSA1], Producer-Consumer [Grand98], Scheduler [Lea99a], and Two-phase Termination [Grand98].
The Active Object design pattern decouples method execution from method invocation to enhance concurrency and simplify synchronized access to objects that reside in their own threads of control.
Concurrent Object
Consider the design of a communication gateway,1 which decouples cooperating components and allows them to interact without having direct dependencies on each other. As shown below, the gateway may route messages from one or more supplier processes to one or more consumer processes in a distributed system.
The suppliers, consumers, and gateway communicate using TCP [Ste93], which is a connection-oriented protocol. The gateway may therefore encounter flow control from the TCP transport layer when it tries to send data to a remote consumer. TCP uses flow control to ensure that fast suppliers or gateways do not produce data more rapidly than slow consumers or congested networks can buffer and process the data. To improve end-to-end quality of service (QoS) for all suppliers and consumers, the entire gateway process must not block while waiting for flow control to abate over any one connection to a consumer. In addition the gateway must scale up efficiently as the number of suppliers and consumers increase.
An effective way to prevent blocking and improve performance is to introduce concurrency into the gateway design, for example by associating a different thread of control for each TCP connection. This design enables threads whose TCP connections are flow controlled to block without impeding the progress of threads whose connections are not flow controlled. We thus need to determine how to program the gateway threads and how these threads interact with supplier and consumer handlers.
Clients that access objects running in separate threads of control.
Many applications benefit from using concurrent objects to improve their quality of service, for example by allowing an application to handle multiple client requests simultaneously. Instead of using a single-threaded passive object, which executes its methods in the thread of control of the client that invoked the methods, a concurrent object resides in its own thread of control. If objects run concurrently, however, we must synchronize access to their methods and data if these objects are shared and modified by multiple client threads, in which case three forces arise:
 For example, if one outgoing TCP connection in our gateway example is blocked due to flow control, the gateway process still should be able to run other threads that can queue new messages while waiting for flow control to abate. Similarly, if other outgoing TCP connections are not flow controlled, it should be possible for other threads in the gateway to send messages to their consumers independently of any blocked connections.
For example, if one outgoing TCP connection in our gateway example is blocked due to flow control, the gateway process still should be able to run other threads that can queue new messages while waiting for flow control to abate. Similarly, if other outgoing TCP connections are not flow controlled, it should be possible for other threads in the gateway to send messages to their consumers independently of any blocked connections.
Applications like our gateway can be hard to program if developers use low-level synchronization mechanisms, such as acquiring and releasing mutual exclusion (mutex) locks explicitly. Methods that are subject to synchronization constraints, such as enqueueing and dequeueing messages from TCP connections, should be serialized transparently when objects are accessed by multiple threads.
In our gateway example, messages destined for different consumers should be sent concurrently by a gateway over different TCP connections. If the entire gateway is programmed to only run in a single thread of control, however, performance bottlenecks cannot be alleviated transparently by running the gateway on a multi-processor platform.
For each object exposed to the forces above, decouple method invocation on the object from method execution. Method invocation should occur in the client’s thread of control, whereas method execution should occur in a separate thread. Moreover, design the decoupling so the client thread appears to invoke an ordinary method.
In detail: A proxy [POSA1] [GoF95] represents the interface of an active object and a servant [OMG98a] provides the active object’s implementation. Both the proxy and the servant run in separate threads so that method invocations and method executions can run concurrently. The proxy runs in the client thread, while the servant runs in a different thread.
At run-time the proxy transforms the client’s method invocations into method requests, which are stored in an activation list by a scheduler. The scheduler’s event loop runs continuously in the same thread as the servant, dequeueing method requests from the activation list and dispatching them on the servant. Clients can obtain the result of a method’s execution via a future returned by the proxy.
An active object consists of six components:
A proxy [POSA1] [GoF95] provides an interface that allows clients to invoke publicly-accessible methods on an active object. The use of a proxy permits applications to program using standard strongly-typed language features, rather than passing loosely-typed messages between threads. The proxy resides in the client’s thread.
When a client invokes a method defined by the proxy it triggers the construction of a method request object. A method request contains the context information, such as a method’s parameters, necessary to execute a specific method invocation and return any result to the client. A method request class defines an interface for executing the methods of an active object. This interface also contains guard methods that can be used to determine when a method request can be executed. For every public method offered by a proxy that requires synchronized access in the active object, the method request class is subclassed to create a concrete method request class.

A proxy inserts the concrete method request it creates into an activation list. This list maintains a bounded buffer of pending method requests created by the proxy and keeps track of which method requests can execute. The activation list decouples the client thread where the proxy resides from the thread where the servant method is executed, so the two threads can run concurrently. The internal state of the activation list must therefore be serialized to protect it from concurrent access.
A scheduler runs in a different thread than its client proxies, namely in the active object’s thread. It decides which method request to execute next on an active object. This scheduling decision is based on various criteria, such as ordering—the order in which methods are called on the active object—or certain properties of an active object, such as its state. A scheduler can evaluate these properties using the method requests’ guards, which determine when it is possible to execute the method request [Lea99a]. A scheduler uses an activation list to manage method requests that are pending execution. Method requests are inserted in an activation list by a proxy when clients invoke one of its methods.

A servant defines the behavior and state that is modeled as an active object. The methods a servant implements correspond to the interface of the proxy and method requests the proxy creates. It may also contain other predicate methods that method requests can use to implement their guards. A servant method is invoked when its associated method request is executed by a scheduler. Thus, it executes in its scheduler’s thread.
When a client invokes a method on a proxy it receives a future [Hal85] [LS88]. This future allows the client to obtain the result of the method invocation after the servant finishes executing the method. Each future reserves space for the invoked method to store its result. When a client wants to obtain this result, it can rendezvous with the future, either blocking or polling until the result is computed and stored into the future.

The class diagram for the Active Object pattern is shown below:

The behavior of the Active Object pattern can be divided into three phases:

Five activities show how to implement the Active Object pattern.
For each remote consumer in our gateway example there is a consumer handler containing a TCP connection to a consumer process running on a remote machine. Each consumer handler contains a message queue modeled as an active object and implemented with an MQ_Servant. This active object stores messages passed from suppliers to the gateway while they are waiting to be sent to the remote consumer.2 The following C++ class illustrates the MQ_Servant class:
class MQ_Servant {
public:
// Constructor and destructor.
MQ_Servant (size_t mq_size);
~MQ_Servant ();
// Message queue implementation operations.
void put (const Message &msg);
Message get ();
// Predicates.
bool empty () const;
bool full () const;
private:
// Internal queue representation, e.g., a circular
// array or a linked list, that does not use any
// internal synchronization mechanism.
};
The put() and get() methods implement the message insertion and removal operations on the queue, respectively. The servant defines two predicates, empty() and full(), that distinguish three internal states: empty, full, and neither empty nor full. These predicates are used to determine when put() and get() methods can be called on the servant.
In general, the synchronization mechanisms that protect a servant’s critical sections from concurrent access should not be tightly coupled with the servant, which should just implement application functionality. Instead, the synchronization mechanisms should be associated with the method requests. This design avoids the inheritance anomaly problem [MWY91], which inhibits the reuse of servant implementations if subclasses require different synchronization policies than base classes. Thus, a change to the synchronization constraints of the active object need not affect its servant implementation.
The MQ_Servant class is designed to omit synchronization mechanisms from a servant. The method implementations in the MQ_Servant class, which are omitted for brevity, therefore need not contain any synchronization mechanisms.
In our gateway the MQ_Proxy provides the following interface to the MQ_Servant defined in implementation activity 1 (375):
class MQ_Proxy {
public:
// Bound the message queue size.
enum { MQ_MAX_SIZE = /* … */ };
MQ_Proxy (size_t size = MQ_MAX_SIZE):
scheduler_ (size), servant_ (size) { }
// Schedule <put> to execute on the active object.
void put (const Message &msg) {
Method_Request *mr = new Put (servant_, msg);
scheduler_.insert (mr);
}
// Return a <Message_Future> as the “future” result of
// an asynchronous <get> method on the active object.
Message_Future get () {
Message_Future result;
Method_Request *mr = new Get (servant_, result);
scheduler_.insert (mr);
return result;
}
// empty() and full() predicate implementations …
private:
// The servant that implements the active object
// methods and a scheduler for the message queue.
MQ_Servant servant_;
MQ_Scheduler scheduler_;
};
The MP_Proxy is a factory [GoF95] that constructs instances of method requests and passes them to a scheduler, which queues them for subsequent execution in a separate thread.
Multiple client threads in a process can share the same proxy. A proxy method need not be serialized because it does not change state after it is created. Its scheduler and activation list are responsible for any necessary internal serialization.
Our gateway example contains many supplier handlers that receive and route messages to peers via many consumer handlers. Several supplier handlers can invoke methods using the proxy that belongs to a single consumer handler without the need for any explicit synchronization.
The methods in a method request class must be defined by subclasses. There should be one concrete method request class for each method defined in the proxy. The can_run() method is often implemented with the help of the servant’s predicates.
In our gateway example a Method_Request base class defines two virtual hook methods, which we call can_run() and call():
class Method_Request {
public:
// Evaluate the synchronization constraint.
virtual bool can_run () const = 0
// Execute the method.
virtual void call () = 0;
};
We then define two subclasses of Method_Request: class Put corresponds to the put() method call on a proxy and class Get corresponds to the get() method call. Both classes contain a pointer to the MQ_Servant. The Get class can be implemented as follows:
class Get : public Method_Request {
public:
Get (MQ_Servant *rep, const Message_Future &f)
: servant_ (rep), result_ (f) { }
virtual bool can_run () const {
// Synchronization constraint: cannot call a
// <get> method until queue is not empty.
return !servant_->empty ();
}
virtual void call () {
// Bind dequeued message to the future result.
result_ = servant_->get ();
}
private:
MQ_Servant *servant_;
Message_Future result_;
};
Note how the can_run() method uses the MQ_Servant’s empty() predicate to allow a scheduler to determine when the Get method request can execute. When the method request does execute, the active object’s scheduler invokes its call() hook method. This call() hook uses the Get method request’s run-time binding to MQ_Servant to invoke the servant’s get() method, which is executed in the context of that servant. It does not require any explicit serialization mechanisms, however, because the active object’s scheduler enforces all the necessary synchronization constraints via the method request can_run() methods.
The proxy passes a future to the constructors of the corresponding method request classes for each of its public two-way methods in the proxy that returns a value, such as the get() method in our gateway example. This future is returned to the client thread that calls the method, as discussed in implementation activity 5 (384).
The activation list is often designed using concurrency control patterns, such as Monitor Object (399), that use common synchronization mechanisms like condition variables and mutexes [Ste98]. When these are used in conjunction with a timer mechanism, a scheduler thread can determine how long to wait for certain operations to complete. For example, timed waits can be used to bound the time spent trying to remove a method request from an empty activation list or to insert into a full activation list.3 If the timeout expires, control returns to the calling thread and the method request is not executed.
For our gateway example we specify a class Activation_List as follows:
class Activation_List {
public:
// Block for an “infinite” amount of time waiting
// for <insert> and <remove> methods to complete.
enum { INFINITE = -1 };
// Define a “trait”.
typedef Activation_List_Iterator iterator;
// Constructor creates the list with the specified
// high water mark that determines its capacity.
Activation_List (size_t high_water_mark);
// Insert <method_request> into the list, waiting up
// to <timeout> amount of time for space to become
// available in the queue. Throws the <System_Ex>
// exception if <timeout> expires.
void insert (Method_Request *method_request,
Time_Value *timeout = 0);
// Remove <method_request> from the list, waiting up
// to <timeout> amount of time for a <method_request>
// to be inserted into the list. Throws the
// <System_Ex> exception if <timeout> expires.
void remove (Method_Request *&method_request,
Time_Value *timeout = 0);
private:
// Synchronization mechanisms, e.g., condition
// variables and mutexes, and the queue implemen-
// tation, e.g., an array or a linked list, go here.
};
The insert() and remove() methods provide a ‘bounded-buffer’ producer/consumer [Grand98] synchronization model. This design allows a scheduler thread and multiple client threads to remove and insert Method_Requests simultaneously without corrupting the internal state of an Activation_List. Client threads play the role of producers and insert Method_Requests via a proxy. A scheduler thread plays the role of a consumer. It removes Method_Requests from the Activation_List when their guards evaluate to ‘true’. It then invokes their call() hooks to execute servant methods.
We define the following MQ_Scheduler class for our gateway:
class MQ_Scheduler {
public:
// Initialize the <Activation_List> to have
// the specified capacity and make <MQ_Scheduler>
// run in its own thread of control.
MQ_Scheduler (size_t high_water_mark);
// … Other constructors/destructors, etc.
// Put <Method_Request> into <Activation_List>. This
// method runs in the thread of its client, i.e.
// in the proxy’s thread.
void insert (Method_Request *mr) {
act_list_.insert (mr);
}
// Dispatch the method requests on their servant
// in its scheduler’s thread of control.
virtual void dispatch ();
private:
// List of pending Method_Requests.
Activation_List act_list_;
// Entry point into the new thread.
static void *svc_run (void *arg);
};
A scheduler executes its dispatch() method in a different thread of control than its client threads. Each client thread uses a proxy to insert method requests in an active object scheduler’s activation list. This scheduler monitors the activation list in its own thread, selecting a method request whose guard evaluates to ‘true,’ that is, whose synchronization constraints are met. This method request is then removed from the activation list and executed by invoking its call() hook method.
In our gateway example the constructor of MQ_Scheduler initializes the Activation_List and uses the Thread_Manager wrapper facade (47) to spawn a new thread of control:
MQ_Scheduler::MQ_Scheduler (size_t high_water_mark):
act_queue_ (high_water_mark) {
// Spawn separate thread to dispatch method requests.
Thread_Manager::instance ()->spawn (&svc_run, this);
}
The Thread_Manager::spawn() method is passed a pointer to a static MQ_Scheduler::svc_run() method and a pointer to the MQ_Scheduler object. The svc_run() static method is the entry point into a newly created thread of control, which runs the svc_run() method. This method is simply an adapter [GoF95] that calls the MQ_Scheduler::dispatch() method on the this parameter:
void *MQ_Scheduler::svc_run (void *args) {
MQ_Scheduler *this_obj =
static_cast<MQ_Scheduler *> (args);
this_obj->dispatch ();
}
The dispatch() method determines the order in which Put and Get method requests are processed based on the underlying MQ_Servant predicates empty() and full(). These predicates reflect the state of the servant, such as whether the message queue is empty, full, or neither.
By evaluating these predicate constraints via the method request can_run() methods, a scheduler can ensure fair access to the MQ_Servant:
virtual void MQ_Scheduler::dispatch () {
// Iterate continuously in a separate thread.
for (;;) {
Activation_List::iterator request;
// The iterator’s <begin> method blocks
// when the <Activation_List> is empty.
for (request = act_list_.begin ();
request != act_list_.end ();
++request) {
// Select a method request whose
// guard evaluates to true.
if ((*request).can_run ()) {
// Take <request> off the list.
act_list_.remove (*request);
(*request).call ();
delete *request;
}
// Other scheduling activities can go here,
// e.g., to handle when no <Method_Request>s
// in the <Activation_List> have <can_run>
// methods that evaluate to true.
}
}
}
In our example the MQ_Scheduler::dispatch() implementation iterates continuously, executing the next method request whose can_run() method evaluates to true. Scheduler implementations can be more sophisticated, however, and may contain variables that represent the servant’s synchronization state.
For example, to implement a multiple-readers/single-writer synchronization policy a prospective writer will call ‘write’ on the proxy, passing the data to write. Similarly, readers will call ‘read’ and obtain a future as their return value. The active object’s scheduler maintains several counter variables that keep track of the synchronization state, such as the number of read and write requests. The scheduler also maintains knowledge about the identity of the prospective writers.
The active object’s scheduler can use these synchronization state counters to determine when a single writer can proceed, that is, when the current number of readers is zero and no write request from a different writer is currently pending execution. When such a write request arrives, a scheduler may choose to dispatch the writer to ensure fairness. In contrast, when read requests arrive and the servant can satisfy them because it is not empty, its scheduler can block all writing activity and dispatch read requests first.
The synchronization state counter variable values described above are independent of the servant’s state because they are only used by its scheduler to enforce the correct synchronization policy on behalf of the servant. The servant focuses solely on its task to temporarily store client-specific application data. In contrast, its scheduler focuses on coordinating multiple readers and writers. This design enhances modularity and reusability.
A scheduler can support multiple synchronization policies by using the Strategy pattern [GoF95]. Each synchronization policy is encapsulated in a separate strategy class. The scheduler, which plays the context role in the Strategy pattern, is then configured with a particular synchronization strategy it uses to execute all subsequent scheduling decisions.
The future construct allows two-way asynchronous invocations [ARSK00] that return a value to the client. When a servant completes the method execution, it acquires a write lock on the future and updates the future with its result. Any client threads that are blocked waiting for the result are awakened and can access the result concurrently. A future can be garbage-collected after the writer and all readers threads no longer reference it. In languages like C++, which do not support garbage collection, futures can be reclaimed when they are no longer in use via idioms like Counted Pointer [POSA1].
In our gateway example the get() method invoked on the MQ_Proxy ultimately results in the Get::call() method being dispatched by the MQ_Scheduler, as shown in implementation activity 2 (378). The MQ_Proxy::get() method returns a value, therefore a Message_Future is returned to the client that calls it:
class Message_Future {
public:
// Binds <this> and <pre> to the same <Msg._Future_Imp.>
Message_Future (const Message_Future &f);
// Initializes <Message_Future_Implementation> to
// point to <message> m immediately.
Message_Future (const Message &message);
// Creates a <Msg._Future_Imp.>
Message_Future ();
// Binds <this> and <pre> to the same
// <Msg._Future_Imp.>, which is created if necessary.
void operator= (const Message_Future &f);
// Block upto <timeout> time waiting to obtain result
// of an asynchronous method invocation. Throws
// <System_Ex> exception if <timeout> expires.
Message result (Time_Value *timeout = 0) const;
private:
// <Message_Future_Implementation> uses the Counted
// Pointer idiom.
Message_Future_Implementation *future_impl_;
};
The Message_Future is implemented using the Counted Pointer idiom [POSA1]. This idiom simplifies memory management for dynamically allocated C++ objects by using a reference counted Message_Future_Implementation body that is accessed solely through the Message_Future handle.
In general a client may choose to evaluate the result value from a future immediately, in which case the client blocks until the scheduler executes the method request. Conversely, the evaluation of a return result from a method invocation on an active object can be deferred. In this case the client thread and the thread executing the method can both proceed asynchronously.
In our gateway example a consumer handler running in a separate thread may choose to block until new messages arrive from suppliers:
MQ_Proxy message_queue; // Obtain future and block thread until message arrives. Message_Future future = message_queue.get (); Message msg = future.result (); // Transmit message to the consumer. send (msg);
Conversely, if messages are not available immediately, a consumer handler can store the Message_Future return value from message_queue and perform other ‘book-keeping’ tasks, such as exchanging keep-alive messages to ensure its consumer is still active. When the consumer handler is finished with these tasks, it can block until a message arrives from suppliers:
// Obtain a future (does not block the client). Message_Future future = message_queue.get (); // Do something else here… // Evaluate future and block if result is not available. Message msg = future.result (); send (msg);
In our gateway example, the gateway’s supplier and consumer handlers are local proxies [POSA1] [GoF95] for remote suppliers and consumers, respectively. Supplier handlers receive messages from remote suppliers and inspect address fields in the messages. The address is used as a key into a routing table that identifies which remote consumer will receive the message.
The routing table maintains a map of consumer handlers, each of which is responsible for delivering messages to its remote consumer over a separate TCP connection. To handle flow control over various TCP connections, each consumer handler contains a message queue implemented using the Active Object pattern. This design decouples supplier and consumer handlers so that they can run concurrently and block independently.

The Consumer_Handler class is defined as follows:
class Consumer_Handler {
public:
// Constructor spawns the active object’s thread.
Consumer_Handler ();
// Put the message into the queue.
void put (const Message &msg) { msg_q_.put (msg); }
private:
MQ_Proxy msg_q_; // Proxy to the Active Object.
SOCK_Stream connection_; // Connection to consumer.
// Entry point into the new thread.
static void *svc_run (void *arg);
};
Supplier_Handlers running in their own threads can put messages in the appropriate Consumer_Handler’s message queue active object:
void Supplier_Handler::route_message (const Message &msg)
{
// Locate the appropriate consumer based on the
// address information in <Message>.
Consumer_Handler *consumer_handler =
routing_table_.find (msg.address ());
// Put the Message into the Consumer Handler’s queue.
consumer_handler->put (msg);
}
To process the messages inserted into its queue, each Consumer_Handler uses the Thread_Manager wrapper facade (47) to spawn a separate thread of control in its constructor:
Consumer_Handler::Consumer_Handler () {
// Spawn a separate thread to get messages from the
// message queue and send them to the consumer.
Thread_Manager::instance ()->spawn (&svc_run, this);
// …
}
This new thread executes the svc_run() method entry point, which gets the messages placed into the queue by supplier handler threads, and sends them to the consumer over the TCP connection:
void *Consumer_Handler::svc_run (void *args) {
Consumer_Handler *this_obj =
static_cast<Consumer_Handler *> (args);
for (;;) {
// Block thread until a <Message> is available.
Message msg = this_obj->msg_q_.get ().result ();
// Transmit <Message> to the consumer over the
// TCP connection.
this_obj->connection_.send (msg, msg.length ());
}
}
Every Consumer_Handler object uses the message queue that is implemented as an active object and runs in its own thread. Therefore its send() operation can block without affecting the quality of service of other Consumer_Handler objects.
Multiple Roles. If an active object implements multiple roles, each used by particular types of client, a separate proxy can be introduced for each role. By using the Extension Interface pattern (141), clients can obtain the proxies they need. This design helps separate concerns because a client only sees the particular methods of an active object it needs for its own operation, which further simplifies an active object’s evolution. For example, new services can be added to the active object by providing new extension interface proxies without changing existing ones. Clients that do not need access to the new services are unaffected by the extension and need not even be recompiled.
Integrated Scheduler. To reduce the number of components needed to implement the Active Object pattern, the roles of the proxy and servant can be integrated into its scheduler component. Likewise, the transformation of a method call on a proxy into a method request can also be integrated into the scheduler. However, servants still execute in a different thread than proxies.
Here is an implementation of the message queue using an integrated scheduler:
class MQ_Scheduler {
public:
MQ_Scheduler (size_t size)
: servant_ (size), act_list_ (size) { }
// … other constructors/destructors, etc.
void put (const Message m) {
Method_Request *mr = new Put (&servant_, m);
act_list_.insert (mr);
}
Message_Future get () {
Message_Future result;
Method_Request *mr = new Get (&servant_, result);
act_list_.insert (mr);
return result;
}
// Other methods …
private:
MQ_Servant servant_;
Activation_List act_list_;
// …
};
By centralizing the point at which method requests are generated, the Active Object pattern implementation can be simplified because it has fewer components. The drawback, of course, is that a scheduler must know the type of the servant and proxy, which makes it hard to reuse the same scheduler for different types of active objects.
Message Passing. A further refinement of the integrated scheduler variant is to remove the proxy and servant altogether and use direct message passing between the client thread and the active object’s scheduler thread.
For example, consider the following scheduler implementation:
class Scheduler {
public:
Scheduler (size_t size): act_list_ (size) { }
// … other constructors/destructors, etc.
void insert (Message_Request *message_request) {
act_list_.insert (message_request);
}
virtual void dispatch () {
for (;;) {
Message_Request *mr;
// Block waiting for next request to arrive.
act_list_.remove (mr);
// Process the message request <mr>…
}
}
// …
private:
Activation_List act_list_;
// …
};
In this variant, there is no proxy, so clients create an appropriate type of message request directly and call insert() themselves, which enqueues the request into the activation list. Likewise, there is no servant, so the dispatch() method running in a scheduler’s thread simply dequeues the next message request and processes the request according to its type.
In general it is easier to develop a message-passing mechanism than it is to develop an active object because there are fewer components. Message passing can be more tedious and error-prone, however, because application developers, not active object developers, must program the proxy and servant logic. As a result, message passing implementations are less type-safe than active object implementations because their interfaces are implicit rather than explicit. In addition, it is harder for application developers to distribute clients and servers via message passing because there is no proxy to encapsulate the marshaling and demarshaling of data.
Polymorphic Futures [LK95]. A polymorphic future allows parameterization of the eventual result type represented by the future and enforces the necessary synchronization. In particular, a polymorphic future describes a typed future that client threads can use to retrieve a method request’s result. Whether a client blocks on a future depends on whether or not a result has been computed.
The following class is a polymorphic future template for C++:
template <class TYPE>
class Future {
// This class can be used to return results from
// two-way asynchronous method invocations.
public:
// Constructor and copy constructor that binds <this>
// and <r> to the same <Future> representation.
Future ();
Future (const Future<TYPE> &r);
// Destructor.
~Future ();
// Assignment operator that binds <this> and <r> to
// the same <Future> representation.
void operator = (const Future<TYPE> &r);
// Cancel a <Future> and reinitialize it.
void cancel ();
// Block upto <timeout> time waiting to obtain result
// of an asynchronous method invocation. Throws
// <System_Ex> exception if <timeout> expires.
TYPE result (Time_Value *timeout = 0) const;
private:
// …
};
A client can use a polymorphic future as follows:
try {
// Obtain a future (does not block the client).
Future<Message> future = message_queue.get ();
// Do something else here…
// Evaluate future and block for up to 1 second
// waiting for the result to become available.
Time_Value timeout (1);
Message msg = future.result (&timeout);
// Do something with the result …
} catch (System_Ex &ex) {
if (ex.status () == ETIMEDOUT) /* handle timeout */
}
Timed method invocations. The activation list illustrated in implementation activity 3 (379) defines a mechanism that can bound the amount of time a scheduler waits to insert or remove a method request. Although the examples we showed earlier in the pattern do not use this feature, many applications can benefit from timed method invocations. To implement this feature we can simply export the timeout mechanism via schedulers and proxies.
In our gateway example, the MQ_Proxy can be modified so that its methods allow clients to bound the amount of time they are willing to wait to execute:
class MQ_Proxy {
public:
// Schedule <put> to execute, but do not block longer
// than <timeout> time. Throws <System_Ex>
// exception if <timeout> expires.
void put (const Message &msg,
Time_Value *timeout = 0);
// Return a <Message_Future> as the “future” result of
// an asynchronous <get> method on the active object,
// but do not block longer than <timeout> amount of
// time. Throws the <System_Ex> exception if
// <timeout> expires.
Message_Future get (Time_Value *timeout = 0);
};
If timeout is 0 both get() and put() will block indefinitely until Message is either removed from or inserted into the scheduler’s activation list, respectively. If timeout expires, the System_Ex exception defined in the Wrapper Facade pattern (47) is thrown with a status() value of ETIMEDOUT and the client must catch it.
To complete our support for timed method invocations, we also must add timeout support to the MQ_Scheduler:
class MQ_Scheduler {
public:
// Insert a method request into the <Activation_List>
// This method runs in the thread of its client, i.e.
// in the proxy’s thread, but does not block longer
// than <timeout> amount of time. Throws the
// <System_Ex> exception if the <timeout> expires.
void insert (Method_Request *method_request,
Time_Value *timeout) {
act_list_.insert (method_request, timeout);
}
}
Distributed Active Object. In this variant a distribution boundary exists between a proxy and a scheduler, rather than just a threading boundary. This pattern variant introduces two new participants:
The Distributed Active Object pattern variant is therefore similar to the Broker pattern [POSA1]. The primary difference is that a Broker usually coordinates the processing of many objects, whereas a distributed active object just handles a single object.
Thread Pool Active Object. This generalization of the Active Object pattern supports multiple servant threads per active object to increase throughput and responsiveness. When not processing requests, each servant thread in a thread pool active object blocks on a single activation list. The active object scheduler assigns a new method request to an available servant thread in the pool as soon as one is ready to be executed.
A single servant implementation is shared by all the servant threads in the pool. This design cannot therefore be used if the servant methods do not protect their internal state via some type of synchronization mechanism, such as a mutex.
Additional variants of active objects can be found in [Lea99a], Chapter 5: Concurrency Control and Chapter 6: Services in Threads.
ACE Framework [Sch97]. Reusable implementations of the method request, activation list, and future components in the Active Object pattern are provided in the ACE framework. The corresponding classes in ACE are called ACE_Method_Request, ACE_Activation_Queue, and ACE_Future. These components have been used to implement many production concurrent and networked systems [Sch96].
Siemens MedCom. The Active Object pattern is used in the Siemens MedCom framework, which provides a black-box component-based framework for electronic medical imaging systems. MedCom employs the Active Object pattern in conjunction with the Command Processor pattern [POSA1] to simplify client windowing applications that access patient information on various medical servers [JWS98].
Siemens FlexRouting - Automatic Call Distribution [Flex98]. This call center management system uses the Thread Pool variant of the Active Object pattern. Services that a call center offers are implemented as applications of their own. For example, there may be a hot-line application, an ordering application, and a product information application, depending on the types of service offered. These applications support operator personnel that serve various customer requests. Each instance of these applications is a separate servant component. A ‘FlexRouter’ component, which corresponds to the scheduler, dispatches incoming customer requests automatically to operator applications that can service these requests.
Java JDK 1.3 introduced a mechanism for executing timer-based tasks concurrently in the classes java.util.Timer and java.util.TimerTask. Whenever the scheduled execution time of a task occurs it is executed. Specifically, Timer offers different scheduling functions to clients that allow them to specify when and how often a task should be executed. One-shot tasks are straightforward and recurring tasks can be scheduled at periodic intervals. The scheduling calls are executed in the client’s thread, while the tasks themselves are executed in a thread owned by the Timer object. A Timer internal task queue is protected by locks because the two threads outlined above operate on it concurrently.
The task queue is implemented as a priority queue so that the next TimerTask to expire can be identified efficiently. The timer thread simply waits until this expiration. There are no explicit guard methods and predicates because determining when a task is ‘ready for execution’ simply depends on the arrival of the scheduled time.
Tasks are implemented as subclasses of TimerTask that override its run() hook method. The TimerTask subclasses unify the concepts behind method requests and servants by offering just one class and one interface method via TimerTask.run().
The scheme described above simplifies the Active Object machinery for the purpose of timed execution. There is no proxy and clients call the scheduler—the Timer object—directly. Clients do not invoke an ordinary method and therefore the concurrency is not transparent. Moreover, there are no return value or future objects linked to the run() method. An application can employ several active objects by constructing several Timer objects, each with its own thread and task queue.
Chef in a restaurant. A real-life example of the Active Object pattern is found in restaurants. Waiters and waitresses drop off customer food requests with the chef and continue to service requests from other customers asynchronously while the food is being prepared. The chef keeps track of the customer food requests via some type of worklist. However, the chef may cook the food requests in a different order than they arrived to use available resources, such as stove tops, pots, or pans, most efficiently. When the food is cooked, the chef places the results on top of a counter along with the original request so the waiters and waitresses can rendezvous to pick up the food and serve their customers.
The Active Object pattern provides the following benefits:
Enhances application concurrency and simplifies synchronization complexity. Concurrency is enhanced by allowing client threads and asynchronous method executions to run simultaneously. Synchronization complexity is simplified by using a scheduler that evaluates synchronization constraints to guarantee serialized access to servants, in accordance with their state.
Transparently leverages available parallelism. If the hardware and software platforms support multiple CPUs efficiently, this pattern can allow multiple active objects to execute in parallel, subject only to their synchronization constraints.
Method execution order can differ from method invocation order. Methods invoked asynchronously are executed according to the synchronization constraints defined by their guards and by scheduling policies. Thus, the order of method execution can differ from the order of method invocation order. This decoupling can help improve application performance and flexibility.
However, the Active Object pattern encounters several liabilities:
Performance overhead. Depending on how an active object’s scheduler is implemented—for example in user-space versus kernel-space [SchSu95]—context switching, synchronization, and data movement overhead may occur when scheduling and executing active object method invocations. In general the Active Object pattern is most applicable for relatively coarse-grained objects. In contrast, if the objects are fine-grained, the performance overhead of active objects can be excessive, compared with related concurrency patterns, such as Monitor Object (399).
Complicated debugging. It is hard to debug programs that use the Active Object pattern due to the concurrency and non-determinism of the various active object schedulers and the underlying operating system thread scheduler. In particular, method request guards determine the order of execution. However, the behavior of these guards may be hard to understand and debug. Improperly defined guards can cause starvation, which is a condition where certain method requests never execute. In addition, program debuggers may not support multi-threaded applications adequately.
The Monitor Object pattern (399) ensures that only one method at a time executes within a thread-safe passive object, regardless of the number of threads that invoke the object’s methods concurrently. In general, monitor objects are more efficient than active objects because they incur less context switching and data movement overhead. However, it is harder to add a distribution boundary between client and server threads using the Monitor Object pattern.
It is instructive to compare the Active Object pattern solution in the Example Resolved section with the solution presented in the Monitor Object pattern. Both solutions have similar overall application architectures. In particular, the Supplier_Handler and Consumer_Handler implementations are almost identical.
The primary difference is that the Message_Queue in the Active Object pattern supports sophisticated method request queueing and scheduling strategies. Similarly, because active objects execute in different threads than their clients, there are situations where active objects can improve overall application concurrency by executing multiple operations asynchronously. When these operations complete, clients can obtain their results via futures [Hal85] [LS88].
On the other hand, the Message_Queue itself is easier to program and often more efficient when implemented using the Monitor Object pattern than the Active Object pattern.
The Reactor pattern (179) is responsible for demultiplexing and dispatching multiple event handlers that are triggered when it is possible to initiate an operation without blocking. This pattern is often used in lieu of the Active Object pattern to schedule callback operations to passive objects. Active Object also can be used in conjunction with the Reactor pattern to form the Half-Sync/Half-Async pattern (423).
The Half-Sync/Half-Async pattern (423) decouples synchronous I/O from asynchronous I/O in a system to simplify concurrent programming effort without degrading execution efficiency. Variants of this pattern use the Active Object pattern to implement its synchronous task layer, the Reactor pattern (179) to implement the asynchronous task layer, and a Producer-Consumer pattern [Lea99a], such as a variant of the Pipes and Filters pattern [POSA1] or the Monitor Object pattern (399), to implement the queueing layer.
The Command Processor pattern [POSA1] separates issuing requests from their execution. A command processor, which corresponds to the Active Object pattern’s scheduler, maintains pending service requests that are implemented as commands [GoF95]. Commands are executed on suppliers, which correspond to servants. The Command Processor pattern does not focus on concurrency, however. In fact, clients, the command processor, and suppliers often reside in the same thread of control. Likewise, there are no proxies that represent the servants to clients. Clients create commands and pass them directly to the command processor.
The Broker pattern [POSA1] defines many of the same components as the Active Object pattern. In particular, clients access brokers via proxies and servers implement remote objects via servants. One difference between Broker and Active Object is that there is a distribution boundary between proxies and servants in the Broker pattern, as opposed to a threading boundary between proxies and servants in the Active Object pattern. Another difference is that active objects typically have just one servant, whereas a broker can have many servants.
The genesis for documenting Active Object as a pattern originated with Greg Lavender [PLoPD2]. Ward Cunningham helped shape this version of the Active Object pattern. Bob Laferriere and Rainer Blome provided useful suggestions that improved the clarity of the pattern’s Implementation section. Thanks to Doug Lea for providing many additional insights in [Lea99a].
The Monitor Object design pattern synchronizes concurrent method execution to ensure that only one method at a time runs within an object. It also allows an object’s methods to cooperatively schedule their execution sequences.
Thread-safe Passive Object
Let us reconsider the design of the communication gateway described in the Active Object pattern (369).4

The gateway process is a mediator [GoF95] that contains multiple supplier and consumer handler objects. These objects run in separate threads and route messages from one or more remote suppliers to one or more remote consumers. When a supplier handler thread receives a message from a remote supplier, it uses an address field in the message to determine the corresponding consumer handler. The handler’s thread then delivers the message to its remote consumer.
When suppliers and consumers reside on separate hosts, the gateway uses a connection-oriented protocol, such as TCP [Ste93], to provide reliable message delivery and end-to-end flow control. Flow control is a protocol mechanism that blocks senders when they produce messages more rapidly than receivers can process them. The entire gateway should not block while waiting for flow control to abate on outgoing TCP connections, however. In particular, incoming TCP connections should continue to be processed and messages should continue to be sent over any non-flow-controlled TCP connections.
To minimize blocking, each consumer handler can contain a thread-safe message queue. Each queue buffers new routing messages it receives from its supplier handler threads. This design decouples supplier handler threads in the gateway process from consumer handler threads, so that all threads can run concurrently and block independently when flow control occurs on various TCP connections.
One way to implement a thread-safe message queue is to apply the Active Object pattern (369) to decouple the thread used to invoke a method from the thread used to execute the method. Active Object may be inappropriate, however, if the entire infrastructure introduced by this pattern is unnecessary. For example, a message queue’s enqueue and dequeue methods may not require sophisticated scheduling strategies. In this case, implementing the Active Object pattern’s method request, scheduler and activation list participants incurs unnecessary performance overhead, and programming effort.
Instead, the implementation of the thread-safe message queue must be efficient to avoid degrading performance unnecessarily. To avoid tight coupling of supplier and consumer handler implementations, the mechanism should also be transparent to implementors of supplier handlers. Varying either implementation independently would otherwise become prohibitively complex.
Multiple threads of control accessing the same object concurrently.
Many applications contain objects whose methods are invoked concurrently by multiple client threads. These methods often modify the state of their objects. For such concurrent applications to execute correctly, therefore, it is necessary to synchronize and schedule access to the objects.
In the presence of this problem four forces must be addressed:
Synchronize the access to an object’s methods so that only one method can execute at any one time.
In detail: for each object accessed concurrently by multiple client threads, define it as a monitor object. Clients can access the functions defined by a monitor object only through its synchronized methods. To prevent race conditions on its internal state, only one synchronized method at a time can run within a monitor object. To serialize concurrent access to an object’s state, each monitor object contains a monitor lock. Synchronized methods can determine the circumstances under which they suspend and resume their execution, based on one or more monitor conditions associated with a monitor object.
There are four participants in the Monitor Object pattern:
A monitor object exports one or more methods. To protect the internal state of the monitor object from uncontrolled changes and race conditions, all clients must access the monitor object only through these methods. Each method executes in the thread of the client that invokes it, because a monitor object does not have its own thread of control.5
Synchronized methods implement the thread-safe functions exported by a monitor object. To prevent race conditions, only one synchronized method can execute within a monitor object at any one time. This rule applies regardless of the number of threads that invoke the object’s synchronized methods concurrently, or the number of synchronized methods in the object’s class.
A consumer handler’s message queue in the gateway application can be implemented as a monitor object by converting its put() and get() operations into synchronized methods. This design ensures that routing messages can be inserted and removed concurrently by multiple threads without corrupting the queue’s internal state.

Each monitor object contains its own monitor lock. Synchronized methods use this lock to serialize method invocations on a per-object basis. Each synchronized method must acquire and release an object’s monitor lock when entering or exiting the object. This protocol ensures the monitor lock is held whenever a synchronized method performs operations that access or modify the state of its object.
Monitor condition. Multiple synchronized methods running in separate threads can schedule their execution sequences cooperatively by waiting for and notifying each other via monitor conditions associated with their monitor object. Synchronized methods use their monitor lock in conjunction with their monitor condition(s) to determine the circumstances under which they should suspend or resume their processing.

In the gateway application a POSIX mutex [IEEE96] can be used to implement the message queue’s monitor lock. A pair of POSIX condition variables can be used to implement the message queue’s not-empty and not-full monitor conditions:
Note that the not-empty and not-full monitor conditions both share the same monitor lock.
The structure of the Monitor Object pattern is illustrated in the following class diagram:

The collaborations between participants in the Monitor Object pattern divide into four phases:

Four activities illustrate how to implement the Monitor Object pattern.
In our gateway example, each consumer handler contains a message queue and a TCP connection. The message queue can be implemented as a monitor object that buffers messages it receives from supplier handler threads. This buffering helps prevent the entire gateway process from blocking whenever consumer handler threads encounter flow control on TCP connections to their remote consumers. The following C++ class defines the interface for our message queue monitor object:
class Message_Queue {
public:
enum { MAX_MESSAGES = /* … */; };
// The constructor defines the maximum number
// of messages in the queue. This determines
// when the queue is ‘full.’
Message_Queue (size_t max_messages = MAX_MESSAGES);
// Put the <Message> at the tail of the queue.
// If the queue is full, block until the queue
// is not full.
/* synchronized */ void put (const Message &msg);
// Get the <Message> from the head of the queue
// and remove it. If the queue is empty,
// block until the queue is not empty.
/* synchronized */ Message get ();
// True if the queue is empty, else false.
/* synchronized */ bool empty () const;
// True if the queue is full, else false.
/* synchronized */ bool full () const;
private:
// … described later …
};
The Message_Queue monitor object interface exports four synchronized methods. The empty() and full() methods are predicates that clients can use to distinguish three internal queue states: empty, full, and neither empty nor full. The put() and get() methods enqueue and dequeue messages into and from the queue, respectively, and will block if the queue is full or empty.
Two conventions, based on the Thread-Safe Interface pattern (345), can be used to structure the separation of concerns between interface and implementation methods in a monitor object:
Similarly, in accordance with the Thread-Safe Interface pattern, implementation methods should not call any synchronized methods defined in the class interface. This restriction helps to avoid intra-object method deadlock or unnecessary synchronization overhead.
In our gateway, the Message_Queue class defines four implementation methods: put_i(), get_i(), empty_i(), and full_ i():
class Message_Queue {
public:
// … See above …
private:
// Put the <Message> at the tail of the queue, and
// get the <Message> at its head, respectively.
void put_i (const Message &msg);
Message get_i ();
// True if the queue is empty, else false.
bool empty_i () const;
// True if the queue is full, else false.
bool full_i () const;
};
Implementation methods are often non-synchronized. They must be careful when invoking blocking calls, because the interface method that called the implementation method may have acquired the monitor lock. A blocking thread that owned a lock could therefore delay overall program progress indefinitely.
A monitor object method implementation is responsible for ensuring that it is in a stable state before releasing its lock. Stable states can be described by invariants, such as the need for all elements in a message queue to be linked together via valid pointers. The invariant must hold whenever a monitor object method waits on the corresponding condition variable.
Similarly, when the monitor object is notified and the operating system thread scheduler decides to resume its thread, the monitor object method implementation is responsible for ensuring that the invariant is indeed satisfied before proceeding. This check is necessary because other threads may have changed the state of the object between the notification and the resumption. A a result, the monitor object must ensure that the invariant is satisfied before allowing a synchronized method to resume its execution.
A monitor lock can be implemented using a mutex. A mutex makes collaborating threads wait while the thread holding the mutex executes code in a critical section. Monitor conditions can be implemented using condition variables [IEEE96]. A condition variable can be used by a thread to make itself wait until a particular event occurs or an arbitrarily complex condition expression attains a particular stable state. Condition expressions typically access objects or state variables shared between threads. They can be used to implement the Guarded Suspension pattern [Lea99a].
In our gateway example, the Message_Queue defines its internal state, as illustrated below:
class Message_Queue {
// … See above ….
private:
// … See above …
// Internal Queue representation omitted, could be a
// circular array or a linked list, etc.. …
// Current number of <Message>s in the queue.
size_t message_count_;
// The maximum number <Message>s that can be
// in a queue before it’s considered ‘full.’
size_t max_messages_;
// Mutex wrapper facade that protects the queue’s
// internal state from race conditions during
// concurrent access.
mutable Thread_Mutex monitor_lock_;
// Condition variable wrapper facade used in
// conjunction with <monitor_lock_> to make
// synchronized method threads wait until the queue
// is no longer empty.
Thread_Condition not_empty_;
// Condition variable wrapper facade used in
// conjunction with <monitor_lock_> to make
// synchronized method threads wait until the queue
// is no longer full.
Thread_Condition not_full_;
};
A Message_Queue monitor object defines three types of internal state:
The constructor of Message_Queue creates an empty queue and initializes the monitor conditions not_empty_ and not_full_:
Message_Queue::Message_Queue (size_t max_messages)
: not_full_ (monitor_lock_),
not_empty_ (monitor_lock_),
max_messages_ (max_messages),
message_count_ (0) { /* … */ }
In this example, both monitor conditions share the same monitor_lock_. This design ensures that Message_Queue state, such as the message_count_, is serialized properly to prevent race conditions from violating invariants when multiple threads try to put() and get() messages on a queue simultaneously.
In our Message_Queue implementation two pairs of interface and implementation methods check if a queue is empty, which means it contains no messages, or full, which means it contains max_messages_. We show the interface methods first:
bool Message_Queue::empty () const {
Guard<Thread_Mutex> guard (monitor_lock_);
return empty_i ();
}
bool Message_Queue::full () const {
Guard<Thread_Mutex> guard (monitor_lock_);
return full_i ();
}
These methods illustrate a simple example of the Thread-Safe Interface pattern (345). They use the Scoped Locking idiom (325) to acquire and release the monitor lock, then forward immediately to their corresponding implementation methods:
bool Message_Queue::empty_i () const {
return message_count_ == 0;
}
bool Message_Queue::full_i () const {
return message_count_ == max_messages_;
}
In accordance with the Thread-Safe Interface pattern, these implementation methods assume the monitor_lock_ is held, so they just check for the boundary conditions in the queue.
The put() method inserts a new Message, which is a class defined in the Active Object pattern (369), at the tail of a queue. It is a synchronized method that illustrates a more sophisticated use of the Thread-Safe Interface pattern (345):
void Message_Queue::put (const Message &msg) {
// Use the Scoped Locking idiom to
// acquire/release the <monitor_lock_> upon
// entry/exit to the synchronized method.
Guard<Thread_Mutex> guard (monitor_lock_);
// Wait while the queue is full.
while (full_i ()) {
// Release <monitor_lock_> and suspend the
// calling thread waiting for space in the queue.
// The <monitor_lock_> is reacquired
// automatically when <wait> returns.
not_full_.wait ();
}
// Enqueue the <Message> at the tail.
put_i (msg);
// Notify any thread waiting in <get> that
// the queue has at least one <Message>.
not_empty_.notify ();
} // Destructor of <guard> releases <monitor_lock_>.
Note how this public synchronized put() method only performs the synchronization and scheduling logic needed to serialize access to the monitor object and wait while the queue is full. Once there is room in the queue, put() forwards to the put_i() implementation method. This inserts the message into the queue and updates its book-keeping information. Moreover, the put_i() is not synchronized because the put() method never calls it without first acquiring the monitor_lock_. Likewise, the put_i() method need not check to see if the queue is full because it is not called as long as full_i() returns true.
The get() method removes the message at the front of the queue and returns it to the caller:
Message Message_Queue::get () {
// Use the Scoped Locking idiom to
// acquire/release the <monitor_lock_> upon
// entry/exit to the synchronized method.
Guard<Thread_Mutex> guard (monitor_lock_);
// Wait while the queue is empty.
while (empty_i ()) {
// Release <monitor_lock_> and suspend the
// calling thread waiting for a new <Message> to
// be put into the queue. The <monitor_lock_> is
// reacquired automatically when <wait> returns.
not_empty_.wait ();
}
// Dequeue the first <Message> in the queue
// and update the <message_count_>.
Message m = get_i ();
// Notify any thread waiting in <put> that the
// queue has room for at least one <Message>.
not_full_.notify ();
return m;
// Destructor of <guard> releases <monitor_lock_>.
}
As before, note how the synchronized get() interface method performs the synchronization and scheduling logic, while forwarding the dequeueing functionality to the get_i() implementation method.
Internally, our gateway contains instances of two classes, Supplier_Handler and Consumer_Handler. These act as local proxies [GoF95] [POSA1] for remote suppliers and consumers, respectively. Each Consumer_Handler contains a thread-safe Message_Queue object implemented using the Monitor Object pattern. This design decouples supplier handler and consumer handler threads so that they run concurrently and block independently. Moreover, by embedding and automating synchronization inside message queue monitor objects, we can protect their internal state from corruption, maintain invariants, and shield clients from low-level synchronization concerns.
The Consumer_Handler is defined below:
class Consumer_Handler {
public:
// Constructor spawns a thread and calls <svc_run>.
Consumer_Handler ();
// Put <Message> into the queue monitor object,
// blocking until there’s room in the queue.
void put (const Message &msg) {
message_queue_.put (msg);
}
private:
// Message queue implemented as a monitor object.
Message_Queue message_queue_;
// Connection to the remote consumer.
SOCK_Stream connection_;
// Entry point to a distinct consumer handler thread.
static void *svc_run (void *arg);
};
Each Supplier_Handler runs in its own thread, receives messages from its remote supplier and routes the messages to the designated remote consumers. Routing is performed by inspecting an address field in each message, which is used as a key into a routing table that maps keys to Consumer_Handlers.

Each Consumer_Handler is responsible for receiving messages from suppliers via its put() method and storing each message in its Message_Queue monitor object:
void Supplier_Handler::route_message (const Message &msg)
{
// Locate the appropriate <Consumer_Handler> based
// on address information in the <Message>.
Consumer_Handler *consumer_handler =
routing_table_.find (msg.address ());
// Put <Message> into the <Consumer Handler>, which
// stores it in its <Message Queue> monitor object.
consumer_handler->put (msg);
}
To process the messages placed into its message queue by Supplier_Handlers, each Consumer_Handler spawns a separate thread of control in its constructor using the Thread_Manager class defined in the Wrapper Facade pattern (47), as follows:
Consumer_Handler::Consumer_Handler () {
// Spawn a separate thread to get messages from the
// message queue and send them to the remote consumer.
Thread_Manager::instance ()->spawn (&svc_run, this);
}
This new Consumer_Handler thread executes the svc_run() entry point. This is a static method that retrieves routing messages placed into its message queue by Supplier_Handler threads and sends them over its TCP connection to the remote consumer:
void *Consumer_Handler::svc_run (void *args) {
Consumer_Handler *this_obj =
static_cast<Consumer_Handler *> (args);
for (;;) {
// Blocks on <get> until next <Message> arrives.
Message msg = this_obj->message_queue_.get ();
// Transmit message to the consumer.
this_obj->connection_.send (msg, msg.length ());
}
}
The SOCK_Stream’s send() method can block in a Consumer_Handler thread. It will not affect the quality of service of other Consumer_Handler or Supplier_Handler threads, because it does not share any data with the other threads. Similarly, Message_Queue::get() can block without affecting the quality of service of other threads, because the Message_Queue is a monitor object.Supplier_Handlers can thus insert new messages into the Consumer_Handler’s Message_Queue via its put() method without blocking indefinitely.
Timed Synchronized Method Invocations. Certain applications require ‘timed’ synchronized method invocations. This feature allows them to set bounds on the time they are willing to wait for a synchronized method to enter its monitor object’s critical section. The Balking pattern described in [Lea99a] can be implemented using timed synchronized method invocations.
The Message_Queue monitor object interface defined earlier can be modified to support timed synchronized method invocations:
class Message_Queue {
public:
// Wait up to the <timeout> period to put <Message>
// at the tail of the queue.
void put
(const Message &msg, Time_Value *timeout = 0);
// Wait up to the <timeout> period to get <Message>
// from the head of the queue.
Message get (Time_Value *timeout = 0);
};
If timeout is 0 then both get() and put() will block indefinitely until a message is either inserted into or removed from a Message_Queue monitor object. If the time-out period is non-zero and it expires, the Timedout exception is thrown. The client must be prepared to handle this exception.
The following illustrates how the put() method can be implemented using the timed wait feature of the Thread_Condition condition variable wrapper outlined in implementation activity 3 (408):
void Message_Queue::put
(const Message &msg, Time_Value *timeout)
/* throw (Timedout) */ {
// … Same as before …
while (full_i ())
not_full_.wait (timeout);
// … Same as before …
}
While the queue is full this ‘timed’ put() method releases monitor_lock_ and suspends the calling thread, to wait for space to become available in the queue or for the timeout period to elapse. The monitor_lock_ will be re-acquired automatically when wait() returns, regardless of whether a time-out occurred or not.
Strategized Locking. The Strategized Locking pattern (333) can be applied to make a monitor object implementation more flexible, efficient, reusable, and robust. Strategized Locking can be used, for example, to configure a monitor object with various types of monitor locks and monitor conditions.
The following template class uses generic programming techniques [Aus98] to parameterize the synchronization aspects of a Message_Queue:
template <class SYNCH_STRATEGY> class Message_Queue {
private:
typename SYNCH_STRATEGY::Mutex monitor_lock_;
typename SYNCH_STRATEGY::Condition not_empty_;
typename SYNCH_STRATEGY::Condition not_full_;
// …
};
Each synchronized method is then modified as shown by the following empty() method:
template <class SYNCH_STRATEGY>
bool Message_Queue<SYNCH_STRATEGY>::empty () const {
Guard<SYNCH_STRATEGY::Mutex> guard (monitor_lock_);
return empty_i ();
}
To parameterize the synchronization aspects associated with a Message_Queue, we can define a pair of classes, MT_Synch and NULL_SYNCH that typedef the appropriate C++ traits:
class MT_Synch {
public:
// Synchronization traits.
typedef Thread_Mutex Mutex;
typedef Thread_Condition Condition;
};
class Null_Synch {
public:
// Synchronization traits.
typedef Null_Mutex Mutex;
typedef Null_Thread_Condition Condition;
};
To define a thread-safe Message_Queue, therefore, we simply parameterize it with the MT_Synch strategy:
Message_Queue<MT_Synch> message_queue;
Similarly, to create a non-thread-safe Message_Queue, we can parameterize it with the following Null_Synch strategy:
Message_Queue<Null_Synch> message_queue;
Note that when using the Strategized Locking pattern in C++ it may not be possible for a generic component class to know what type of synchronization strategy will be configured for a particular application. It is important therefore to apply the Thread-Safe Interface pattern (345) as described in implementation activity 4.2 (411), to ensure that intra-object method calls, such as put() calling full_i(), and put_i(), avoid self-deadlock and minimize locking overhead.
Multiple Roles. If a monitor object implements multiple roles, each of which is used by different types of clients, an interface can be introduced for each role. Applying the Extension Interface pattern (141) allows clients to obtain the interface they need. This design helps separate concerns, because a client only sees the particular methods of a monitor object it needs for its own operation. This design further simplifies a monitor object’s evolution. For example, new services can be added to the active object by providing new extension interface without changing existing ones. Clients that do not need access to the new services are thus unaffected by the extension.
Dijkstra and Hoare-style Monitors. Dijkstra [Dij68] and Hoare [Hoare74] defined programming language features called monitors that encapsulate functions and their internal variables into thread-safe modules. To prevent race conditions a monitor contains a lock that allows only one function at a time to be active within the monitor. Functions that want to leave the monitor temporarily can block on a condition variable. It is the responsibility of the programming language compiler to generate run-time code that implements and manages a monitor’s lock and its condition variables.
Java Objects. The main synchronization mechanism in Java is based on Dijkstra/Hoare-style monitors. Each Java object can be a monitor object containing a monitor lock and a single monitor condition. Java’s monitors are simple to use for common use cases, because they allow threads to serialize their execution implicitly via method-call interfaces and to coordinate their activities via calls to wait(), notify(), and notifyAll() methods defined on all objects.
For more complex use cases, however, the simplicity of the Java language constructs may mislead developers into thinking that concurrency is easier to program than it actually is in practice. In particular, heavy use of inter-dependent Java threads can yield complicated inter-relationships, starvation, deadlock, and overhead. [Lea99a] describes many patterns for handling simple and complex concurrency use cases in Java.
The Java language synchronization constructs outlined above can be implemented in several ways inside a compliant Java virtual machine (JVM). JVM implementors must choose between two implementation decisions:
The advantage of an internal threads implementation is its platform-independence. However, one of its disadvantages is its inability to take advantage of parallelism in the hardware. As a result, an increasing number of JVMs are implemented by mapping Java threads to native operating system threads.
ACE Gateway. The example from the Example Resolved section is based on a communication gateway application contained in the ACE framework [Sch96], which uses monitor objects to simplify concurrent programming and improve performance on multi-processors. Unlike the Dijkstra/Hoare and Java monitors, which are programming language features, the Message_Queues used by Consumer_Handlers in the gateway are reusable ACE C++ components implemented using the Monitor Object pattern. Although C++ does not support monitor objects directly as a language feature, ACE implements the Monitor Object pattern by applying other patterns and idioms, such as the Guarded Suspension pattern [Lea99a] and the Scoped Locking (325) idiom, as described in the Implementation section.
Fast food restaurant. A real-life example of the Monitor Object pattern occurs when ordering a meal at a busy fast food restaurant. Customers are the clients who wait to place their order with a cashier. Only one customer at a time interacts with a cashier. If the order cannot be serviced immediately, a customer temporarily steps aside so that other customers can place their orders. When the order is ready the customer re-enters at the front of the line and can pick up the meal from the cashier.
The Monitor Object pattern provides two benefits:
Simplification of concurrency control. The Monitor Object pattern presents a concise programming model for sharing an object among cooperating threads. For example, object synchronization corresponds to method invocations. Similarly clients need not be concerned with concurrency control when invoking methods on a monitor object. It is relatively straightforward to create a monitor object out of most so-called passive objects, which are objects that borrow the thread of control of its caller to execute its methods.
Simplification of scheduling method execution. Synchronized methods use their monitor conditions to determine the circumstances under which they should suspend or resume their execution and that of collaborating monitor objects. For example, methods can suspend themselves and wait to be notified when arbitrarily complex conditions occur, without using inefficient polling. This feature makes it possible for monitor objects to schedule their methods cooperatively in separate threads.
The Monitor Object pattern has the following four liabilities:
The use of a single monitor lock can limit scalability due to increased contention when multiple threads serialize on a monitor object.
Complicated extensibility semantics resulting from the coupling between a monitor object’s functionality and its synchronization mechanisms. It is relatively straightforward to decouple an active object’s (369) functionality from its synchronization policies via its separate scheduler participant. However, a monitor object’s synchronization and scheduling logic is often tightly coupled with its methods’ functionality. This coupling often makes monitor objects more efficient than active objects. Yet it also makes it hard to change their synchronization policies or mechanisms without modifying the monitor object’s method implementations.
It is also hard to inherit from a monitor object transparently, due to the inheritance anomaly problem [MWY91]. This problem inhibits reuse of synchronized method implementations when subclasses require different synchronization mechanisms. One way to reduce the coupling of synchronization and functionality in monitor objects is to use Aspect-Oriented Programming [KLM+97] or the Strategized Locking (333) and Thread-Safe Interface (345) patterns, as shown in the Implementation and Variants section.
Nested monitor lockout. This problem is similar to the preceding liability. It can occur when a monitor object is nested within another monitor object.
Consider the following two Java classes:
class Inner {
protected boolean cond_ = false;
public synchronized void awaitCondition () {
while (!cond)
try { wait (); }
catch (InterruptedException e) { }
// Any other code.
}
public synchronized void notifyCondition (boolean c){
cond_ = c;
notifyAll ();
}
class Outer {
protected Inner inner_ = new Inner ();
public synchronized void process () {
inner_.awaitCondition ();
}
public synchronized void set (boolean c) {
inner_.notifyCondition (c);
}
}
This code illustrates the canonical form of the nested monitor lockout problem in Java [JS97a]. When a Java thread blocks in the monitor’s wait queue, all its locks are held except the lock of the object placed in the queue.
Consider what would happen if thread T1 made a call to Outer.process() and as a result blocked in the wait() call in Inner.awaitCondition(). In Java, the Inner and Outer classes do not share their monitor locks. The wait() statement in waitCondition() call would therefore release the Inner monitor while retaining the Outer monitor. Another thread T2 cannot then acquire the Outer monitor, because it is locked by the synchronized process() method. As a result Outer.set cannot set Inner.cond_ to true and T1 will continue to block in wait() forever.
Nested monitor lockout can be avoided by sharing a monitor lock between multiple monitor conditions. This is straightforward in Monitor Object pattern implementations based on POSIX condition variables [IEEE96]. It is surprisingly hard in Java due to its simple concurrency and synchronization model, which tightly couples a monitor lock with each monitor object. Java idioms for avoiding nested monitor lockout in Java are described in [Lea99a] [JS97a].
The Monitor Object pattern is an object-oriented analog of the Code Locking pattern [McK95], which ensures that a region of code is serialized. In the Monitor Object pattern, the region of code is the synchronized method implementation.
The Monitor Object pattern has several properties in common with the Active Object pattern (369). Both patterns can synchronize and schedule methods invoked concurrently on objects, for example. There are two key differences, however:
It is instructive to compare the Monitor Object pattern solution in the Example Resolved section with the solution presented in the Active Object pattern. Both solutions have similar overall application architectures. In particular, the Supplier_Handler and Consumer_Handler implementations are almost identical. The primary difference is that the Message_Queue itself is easier to program and often more efficient when implemented using the Monitor Object pattern than the Active Object pattern.
If a more sophisticated queueing strategy is necessary, however, the Active Object pattern may be more appropriate. Similarly, because active objects execute in different threads than their clients, there are situations where active objects can improve overall application concurrency by executing multiple operations asynchronously. When these operations complete, clients can obtain their results via futures [Hal85] [LS88].
The Half-Sync/Half-Async architectural pattern decouples asynchronous and synchronous service processing in concurrent systems, to simplify programming without unduly reducing performance. The pattern introduces two intercommunicating layers, one for asynchronous and one for synchronous service processing.
Performance-sensitive concurrent applications, such as telecommunications switching systems and avionics mission computers, perform a mixture of synchronous and asynchronous processing to coordinate different types of applications, system services, and hardware. Similar characteristics hold for system-level software, such as operating systems.
The BSD UNIX operating system [MBKQ96] [Ste98] is an example of a concurrent system that coordinates the communication between standard Internet application services, such as FTP, INETD, DNS, TELNET, SMTP, and HTTPD, and hardware I/O devices, such as network interfaces, disk controllers, end-user terminals, and printers.

The BSD UNIX operating system processes certain services asynchronously to maximize performance. Protocol processing within the BSD UNIX kernel, for example, runs asynchronously, because I/O devices are driven by interrupts triggered by network interface hardware. If the kernel does not handle these asynchronous interrupts immediately, hardware devices may malfunction and drop packets or corrupt memory buffers.
Although the BSD operating system kernel is driven by asynchronous interrupts, it is hard to develop applications and higher-level system services using asynchrony mechanisms, such as interrupts or signals. In particular, the effort required to program, validate, debug, and maintain asynchronous programs can be prohibitive. For example, asynchrony can cause subtle timing problems and race conditions when an interrupt preempts a running computation unexpectedly.
To avoid the complexities of asynchronous programming, higher-level services in BSD UNIX run synchronously in multiple processes. For example, FTP or TELNET Internet services that use synchronous read() and write() system calls can block awaiting the completion of I/O operations. Blocking I/O, in turn, enables developers to maintain state information and execution history implicitly in the run-time stacks of their threads, rather than in separate data structures that must be managed explicitly by developers.
Within the context of an operating system, however, synchronous and asynchronous processing is not wholly independent. In particular, application-level Internet services that execute synchronously within BSD UNIX must cooperate with kernel-level protocol processing that runs asynchronously. For example, the synchronous read() system call invoked by an HTTP server cooperates indirectly with the asynchronous reception and protocol processing of data arriving on the Ethernet network interface.
A key challenge in the development of BSD UNIX was the structuring of asynchronous and synchronous processing, to enhance both programming simplicity and system performance. In particular, developers of synchronous application programs must be shielded from the complex details of asynchronous programming. Yet, the overall performance of the system must not be degraded by using inefficient synchronous processing mechanisms in the BSD UNIX kernel.
A concurrent system that performs both asynchronous and synchronous processing services that must intercommunicate.
Concurrent systems often contain a mixture of asynchronous and synchronous processing services. There is a strong incentive for system programmers to use asynchrony to improve performance. Asynchronous programs are generally more efficient, because services can be mapped directly onto asynchrony mechanisms, such as hardware interrupt handlers or software signal handlers.
Conversely, there is a strong incentive for application developers to use synchronous processing to simplify their programming effort. Synchronous programs are usually less complex, because certain services can be constrained to run at well-defined points in the processing sequence.
Two forces must therefore be resolved when specifying a software architecture that executes services both synchronously and asynchronously:
Although the need for both programming simplicity and high performance may seem contradictory, it is essential that both these forces be resolved in certain types of concurrent systems, particularly large-scale or complex ones.
Decompose the services in the system into two layers [POSA1], synchronous and asynchronous, and add a queueing layer between them to mediate the communication between services in the asynchronous and synchronous layers.
In detail: process higher-layer services, such as long-duration database queries or file transfers, synchronously in separate threads or processes, to simplify concurrent programming. Conversely, process lower-layer services, such as short-lived protocol handlers driven by interrupts from network interface hardware, asynchronously to enhance performance. If services residing in separate synchronous and asynchronous layers must communicate or synchronize their processing, allow them to pass messages to each other via a queueing layer.
The structure of the Half-Sync/Half-Async pattern follows the Layers pattern [POSA1] and includes four participants:
The synchronous service layer performs high-level processing services. Services in the synchronous layer run in separate threads or processes that can block while performing operations.
The Internet services in our operating system example run in separate application processes. These processes invoke read() and write() operations to perform I/O synchronously on behalf of their Internet services.
The asynchronous service layer performs lower-level processing services, which typically emanate from one or more external event sources. Services in the asynchronous layer cannot block while performing operations without unduly degrading the performance of other services.
The processing of I/O devices and protocols in the BSD UNIX operating system kernel is performed asynchronously in interrupt handlers. These handlers run to completion, that is, they do not block or synchronize their execution with other threads until they are finished.

The queueing layer provides the mechanism for communicating between services in the synchronous and asynchronous layers. For example, messages containing data and control information are produced by asynchronous services, then buffered at the queueing layer for subsequent retrieval by synchronous services, and vice versa. The queueing layer is responsible for notifying services in one layer when messages are passed to them from the other layer. The queueing layer therefore enables the asynchronous and synchronous layers to interact in a ‘producer/consumer’ manner, similar to the structure defined by the Pipes and Filters pattern [POSA1].
The BSD UNIX operating system provides a Socket layer [Ste98]. This layer serves as the buffering and notification point between the synchronous Internet service application processes and the asynchronous, interrupt-driven I/O hardware services in the BSD UNIX kernel.
External event sources generate events that are received and processed by the asynchronous service layer. Common sources of external events for operating systems include network interfaces, disk controllers, and end-user terminals.

The following class diagram illustrates the structure and relationships between these participants:

Asynchronous and synchronous layers in the Half-Sync/Half-Async pattern interact by passing messages via a queueing layer. We describe three phases of interactions that occur when input arrives ‘bottom-up’ from external event sources:

The interactions between layers and pattern participants is reversed to form a ‘top-down’ sequence when output arrives from services running in the synchronous layer.
This section describes the activities used to implement the Half-Sync/Half-Async pattern and apply it to structure the concurrency architecture of higher-level applications, such as Web servers [Sch97] and database servers, as well as to lower-level systems, such as the BSD UNIX operating system. We therefore present examples from several different domains.
Each Internet service shown in our BSD UNIX operating system example runs in a separate application process. Each application process communicates with its clients using the protocol associated with the Internet service it implements. I/O operations within these processes can be performed by blocking synchronously on TCP Sockets and waiting for the BSD UNIX kernel to complete the I/O operations asynchronously.
In our operating system example, processing of I/O device drivers and communication protocols in the BSD UNIX kernel occurs in response to asynchronous hardware interrupts. Each asynchronous operation in the kernel runs to completion, inserting messages containing data and/or control information into the Socket layer if it must communicate with an application process running an Internet service in the synchronous layer.
In our BSD UNIX operating system example, the Sockets mechanism [Ste98] defines the queueing layer between the synchronous Internet service application processes and the asynchronous operating system kernel. Each Internet service uses one or more Sockets, which are queues maintained by BSD UNIX to buffer messages exchanged between application processes, and the TCP/IP protocol stack and networking hardware devices in the kernel.
Multi-threading can reduce application robustness, however, because separate threads within a process are not protected from one another. For instance, one faulty thread can corrupt data shared with other threads in the process, which may produce incorrect results, crash the process, or cause the process to hang indefinitely. To increase robustness, therefore, application services can be implemented in separate processes.
The Internet services in our BSD UNIX example are implemented in separate processes. This design increases their robustness and prevents unauthorized access to certain resources, such as files owned by other users.
The following are two strategies that can be used to trigger the execution of asynchronous services:
In complex concurrent systems, it may be necessary to define a hierarchy of interrupts to allow less critical handlers to be preempted by higher-priority ones. To prevent interrupt handlers from corrupting shared state while they are being accessed, data structures used by the asynchronous layer must be protected, for example by raising the interrupt priority [WS95].
The BSD UNIX kernel uses a two-level interrupt scheme to handle network packet processing [MBKQ96]. Time-critical processing is done at a high priority and less critical software processing is done at a lower priority. This two-level interrupt scheme prevents the overhead of software protocol processing from delaying the servicing of high-priority hardware interrupts.
For example, the Web server in the Proactor pattern (215) illustrates an application that uses the proactive I/O mechanisms defined by the Windows NT system call API. This example underscores the fact that asynchronous processing and the Half-Sync/Half-Async pattern can be used for higher-level applications that do not access hardware devices directly.
Both of these asynchronous processing strategies share the constraint that a handler cannot block for a long period of time without disrupting the processing of events from other external event sources.
Services in the synchronous layer can block. A common flow control policy simply puts a synchronous service to sleep if it produces and queues more than a certain number of messages. After the asynchronous service layer empties the queue to below a certain level, the queueing layer can awaken the synchronous service to continue its processing.
In contrast, services in the asynchronous layer cannot block. If they can produce an excessive number of messages, a common flow-control policy allows the queueing layer to discard messages until the synchronous service layer finishes processing the messages in its queue. If the messages are associated with a reliable connection-oriented transport protocol, such as TCP [Ste93], senders will time-out eventually and retransmit discarded messages.
In more complex implementations of the Half-Sync/Half-Async pattern, services in one layer may need to send and receive certain messages to particular services in another layer. A queueing layer may therefore need multiple queues, for example one queue per service. With multiple queues, more sophisticated demultiplexing mechanism are needed to ensure messages exchanged between services in different layers are placed in the appropriate queue. A common implementation is to use some type of (de)multiplexing mechanism, such as a hash table [HMPT89] [MD91], to place messages into the appropriate queue(s).
The Message_Queue components defined in the Monitor Object (399) and Active Object (369) patterns illustrate various strategies for implementing a queueing layer:
The See Also sections of the Active Object (369) and Monitor Object (399) patterns discuss the pros and cons of using these patterns to implement a queueing layer.
Chapter 1, Concurrent and Networked Objects, and other patterns in this book, such as Proactor (215), Scoped Locking (325), Strategized Locking (333), and Thread-Safe Interface (345), illustrate various aspects of the design of a Web server application. In this section, we explore the broader system context in which Web servers execute, by outlining how the BSD UNIX operating system [MBKQ96] [Ste93] applies the Half-Sync/Half-Async pattern to receive an HTTP GET request via its TCP/IP protocol stack over Ethernet.
BSD UNIX is an example of an operating system that does not support asynchronous I/O efficiently. It is therefore not feasible to implement the Web server using the Proactor pattern (215). We instead outline how BSD UNIX coordinates the services and communication between synchronous application processes and the asynchronous operating system kernel.
In particular, we describe:6
These steps are shown in the following figure:
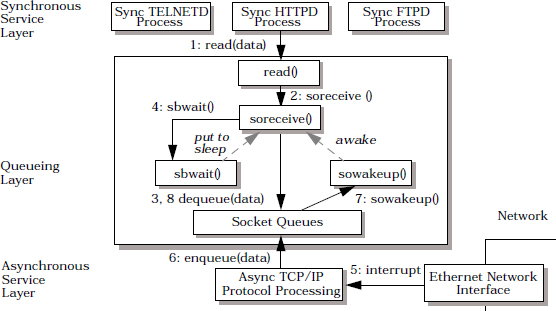
As shown in this figure, the HTTPD process invokes a read() system call on a connected socket handle to receive an HTTP GET request encapsulated in a TCP packet. From the perspective of the HTTPD process, the read() system call is synchronous, because the process invokes read() and blocks until the GET request data is returned. If data is not available immediately, however, the BSD UNIX kernel puts the HTTPD process to sleep until the data arrives from the network.
Many asynchronous steps occur to implement the synchronous read() system call, however. Although the HTTPD process can sleep while waiting for data, the BSD UNIX kernel cannot sleep, because other application processes, such as the FTP and TELNET services and I/O devices in the kernel, require its services to run concurrently and efficiently.
After the read() system call is issued the application process switches to ‘kernel mode’ and starts running privileged instructions, which direct it synchronously into the BSD UNIX networking subsystem. Ultimately, the thread of control from the application process ends in the kernel’s soreceive() function. This function processes input for various types of sockets, such as datagram sockets and stream sockets, by transferring data from the socket queue to the application process. The soreceive() function thus defines the boundary between the synchronous application process layer and the asynchronous kernel layer for outgoing packets.
There are two ways in which the HTTPD process’s read() system call can be handled by soreceive(), depending on the characteristics of the Socket and the amount of data in the socket queue:
After sbwait() puts the process to sleep, the BSD UNIX scheduler will switch to another process context that is ready to run. From the perspective of the HTTPD process, however, the read() system call appears to execute synchronously. When packet(s) containing the requested data arrive, the kernel will process them asynchronously, as described below. When enough data has been placed in the socket queue to satisfy the HTTPD process’ request, the kernel will wake this process and complete its read() system call. This call then returns synchronously so that the HTTPD process can parse and execute the GET request.
To maximize performance within the BSD UNIX kernel, all protocol processing is executed asynchronously, because I/O devices are driven by hardware interrupts. For example, packets arriving at the Ethernet network interface are delivered to the kernel via interrupt handlers initiated asynchronously by the Ethernet hardware. These handlers receive packets from devices and trigger subsequent asynchronous processing of higher-layer protocols, such as IP and TCP. Ultimately, valid packets containing application data are queued at the Socket layer, where the BSD UNIX kernel schedules and dispatches the waiting HTTPD process to consume this data synchronously.
For example, the ‘half-async’ processing associated with an HTTPD process’s read() system call starts when a packet arrives at an Ethernet network interface, which triggers an asynchronous hardware interrupt. All incoming packet processing is performed in the context of an interrupt handler. During an interrupt, the BSD UNIX kernel cannot sleep or block, because there is no application process context and no dedicated thread of control. The Ethernet interrupt handler therefore ‘borrows’ the kernel’s thread of control. Similarly, the BSD UNIX kernel borrows the threads of control of application processes when they invoke system calls.
If the packet is destined for an application process, it is passed up to the transport layer, which performs additional protocol processing, such as TCP segment reassembly and acknowledgments. Eventually, the transport layer appends the data to the receive socket queue and calls sbwakeup(), which represents the boundary between the asynchronous and synchronous layers for incoming packets. This call wakes up the HTTPD process that was sleeping in soreceive() waiting for data on that socket queue. If all the data requested by the HTTPD process has arrived, soreceive() will copy it to the buffer supplied by HTTPD, allowing the system call to return control to the Web server. The read() call thus appears to be synchronous from the perspective of the HTTPD process, even though asynchronous processing and context switching were performed while this process was asleep.
Asynchronous Control with Synchronous Data I/O. The HTTPD Web server described in the Implementation section ‘pulls’ messages synchronously from the queueing layer at its discretion, thereby combining control and data activities. On some operating system platforms, however, it is possible to decouple control and data so that services in the synchronous layer can be notified asynchronously when messages are inserted into the queueing layer. The primary benefit of this variant is that higher-level ‘synchronous’ services may be more responsive, because they can be notified asynchronously.
The UNIX signal-driven I/O mechanism [Ste98] implements this variant of the Half-Sync/Half-Async pattern. The UNIX kernel uses the SIGIO signal to ‘push’ control to a higher-level application process when data arrives on one of its Sockets. When a process receives this control notification asynchronously, it can then ‘pull’ the data synchronously from socket queueing layer via read().
The disadvantage of using asynchronous control, of course, is that developers of higher-level services must now face many of the asynchrony complexities outlined in the Problem section.
Half-Async/Half-Async. This variant extends the previous variant by propagating asynchronous control notifications and data operations all the way up to higher-level services in the ‘synchronous’ layer. These higher-level services may therefore be able to take advantage of the efficiency of the lower-level asynchrony mechanisms.
For example, the real-time signal interface defined in the POSIX real-time programming specification [POSIX95] supports this variant. In particular, a buffer pointer can be passed to the signal handler function dispatched by the operating system when a real-time signal occurs. Windows NT supports a similar mechanism using overlapped I/O and I/O completion ports [Sol98]. In this case, when an asynchronous operation completes, its associated overlapped I/O structure indicates which operation has completed and passes any data along. The Proactor pattern (215) and Asynchronous Completion Token pattern (261) describe how to structure applications to take advantage of asynchronous operations and overlapped I/O.
The disadvantage of this variant is similar to that of the previous variant. If most or all services can be driven by asynchronous operations, the design may be modeled better by applying the Proactor pattern (215) rather than the Half-Sync/Half-Async pattern.
Half-Sync/Half-Sync. This variant provides synchronous processing to lower-level services. If the asynchronous layer is multi-threaded, its services can run autonomously and use the queueing layer to pass messages to the synchronous service layer. The benefits of this variant are that services in the asynchronous layer may be simplified, because they can block without affecting other services in this layer.
Microkernel operating systems, such as Mach [Bl90] or Amoeba [Tan95], typically use this variant. The microkernel runs as a separate multi-threaded ‘process’ that exchanges messages with application processes. Similarly, multi-threaded operating system macrokernels, such as Solaris [EKBF+92], can support multiple synchronous I/O operations in the kernel.
Multi-threading the kernel can be used to implement polled interrupts, which reduce the amount of context switching for high-performance continuous media systems by dedicating a kernel thread to poll a field in shared memory at regular intervals [CP95]. In contrast, single-threaded operating system kernels, such as BSD UNIX, restrict lower-level kernel services to use asynchronous I/O and only support synchronous multi-programming for higher-level application processes.
The drawback to providing synchronous processing to lower-level services, of course, is that it may increase overhead, thereby degrading overall system performance significantly.
Half-Sync/Half-Reactive. In object-oriented applications, the Half-Sync/Half-Async pattern can be implemented as a composite architectural pattern that combines the Reactor pattern (179) with the Thread Pool variant of the Active Object pattern (369). In this common variant, the reactor’s event handlers constitute the services in the ‘asynchronous’ layer7 and the queueing layer can be implemented by an active object’s activation list. The servants dispatched by the scheduler in the active object’s thread pool constitute the services in the synchronous layer. The primary benefit of this variant is the simplification it affords. This simplicity is achieved by performing event demultiplexing and dispatching in a single-threaded reactor that is decoupled from the concurrent processing of events in the active object’s thread pool.
The OLTP servers described in the Example section of the Leader/Followers pattern (447) apply this variant. The ‘asynchronous’ service layer uses the Reactor pattern (179) to demultiplex transaction requests from multiple clients and dispatch event handlers. The handlers insert requests into the queueing layer, which is an activation list implemented using the Monitor Object pattern (399). Similarly, the synchronous service layer uses the thread pool variant of the Active Object pattern (369) to disseminate requests from the activation list to a pool of worker threads that service transaction requests from clients. Each thread in the active object’s thread pool can block synchronously because it has its own run-time stack.
The drawback with this variant is that the queueing layer incurs additional context switching, synchronization, data allocation, and data copying overhead that may be unnecessary for certain applications. In such cases the Leader/Followers pattern (447) may be a more efficient, predictable, and scalable way to structure a concurrent application than the Half-Sync/Half-Async pattern.
UNIX Networking Subsystems. The BSD UNIX networking subsystem [MBKQ96] and the UNIX STREAMS communication framework [Ris98] use the Half-Sync/Half-Async pattern to structure the concurrent I/O architecture of application processes and the operating system kernel. I/O in these kernels is asynchronous and triggered by interrupts. The queueing layer is implemented by the Socket layer in BSD UNIX [Ste98] and by Stream Heads in UNIX STREAMS [Rago93]. I/O for application processes is synchronous.
Most UNIX network daemons, such as TELNETD and FTPD, are developed as application processes that invoke read() and write() system calls synchronously [Ste98]. This design shields application developers from the complexity of asynchronous I/O processed by the kernel. However, there are hybrid mechanisms, such as the UNIX SIGIO signal, that can be used to trigger synchronous I/O processing via asynchronous control notifications.
CORBA ORBs. MT-Orbix [Bak97] uses a variation of the Half-Sync/Half-Async pattern to dispatch CORBA remote operations in a concurrent server. In MT-Orbix’s ORB Core a separate thread is associated with each socket handle that is connected to a client. Each thread blocks synchronously, reading CORBA requests from the client. When a request is received it is demultiplexed and inserted into the queueing layer. An active object thread in the synchronous layer then wakes up, dequeues the request, and processes it to completion by performing an upcall to the CORBA servant.
ACE. The ACE framework [Sch97] applies the ‘Half-Sync/Half-Reactive’ variant of the Half-Sync/Half-Async pattern in an application-level gateway that routes messages between peers in a distributed system [Sch96]. The ACE_Reactor is the ACE implementation of the Reactor pattern (179) that demultiplexes indication events to their associated event handlers in the ‘asynchronous’ layer. The ACE Message_Queue class implements the queueing layer, while the ACE Task class implements the thread pool variant of the Active Object pattern (369) in the synchronous service layer.
Conduit. The Conduit communication framework [Zweig90] from the Choices operating system project [CIRM93] implements an object-oriented version of the Half-Sync/Half-Async pattern. Application processes are synchronous active objects, an Adapter Conduit serves as the queueing layer, and the Conduit micro-kernel operates asynchronously, communicating with hardware devices via interrupts.
Restaurants. Many restaurants use a variant of the Half-Sync/Half-Async pattern. For example, restaurants often employ a host or hostess who is responsible for greeting patrons and keeping track of the order in which they will be seated if the restaurant is busy and it is necessary to queue them waiting for an available table. The host or hostess is ‘shared’ by all the patrons and thus cannot spend much time with any given party. After patrons are seated at a table, a waiter or waitress is dedicated to service that table.
The Half-Sync/Half-Async pattern has the following benefits:
Simplification and performance. The programming of higher-level synchronous processing services are simplified without degrading the performance of lower-level system services. Concurrent systems often have a greater number and variety of high-level processing services than lower-level services. Decoupling higher-level synchronous services from lower-level asynchronous processing services can simplify application programming, because complex concurrency control, interrupt handling, and timing services can be localized within the asynchronous service layer. The asynchronous layer can also handle low-level details that may be hard for application developers to program robustly, such as interrupt handling. In addition, the asynchronous layer can manage the interaction with hardware-specific components, such as DMA, memory management, and I/O device registers.
The use of synchronous I/O can also simplify programming, and may improve performance on multi-processor platforms. For example, long-duration data transfers, such as downloading a large medical image from a hierarchical storage management system [PHS96], can be simplified and performed efficiently using synchronous I/O. In particular, one processor can be dedicated to the thread that is transferring the data. This enables the instruction and data cache of that CPU to be associated with the entire image transfer operation.
Separation of concerns. Synchronization policies in each layer are decoupled. Each layer therefore need not use the same concurrency control strategies. In the single-threaded BSD UNIX kernel, for example, the asynchronous service layer implements synchronization via low-level mechanisms, such as raising and lowering CPU interrupt levels. In contrast, application processes in the synchronous service layer implement synchronization via higher-level mechanisms, such as monitor objects (399) and synchronized message queues.
Legacy libraries, such as X Windows and older RPC toolkits, are often not re-entrant. Multiple threads of control cannot therefore invoke these library functions concurrently within incurring race conditions. To improve performance or to take advantage of multiple CPUs, however, it may be necessary to perform bulk data transfers or database queries in separate threads. In this case, the Half-Sync/Half-Reactive variant of the Half-Sync/Half-Async pattern can be applied to decouple the single-threaded portions of an application from its multi-threaded portions.
For example, an application’s X Windows GUI processing could run under the control of a reactor. Similarly, long data transfers could run under the control of an active object thread pool. By decoupling the synchronization policies in each layer of the application via the Half-Sync/Half-Async pattern, non-re-entrant functions can continue to work correctly without requiring changes to existing code.
Centralization of inter-layer communication. Inter-layer communication is centralized at a single access point, because all interaction is mediated by the queueing layer. The queueing layer buffers messages passed between the other two layers. This eliminates the complexities of locking and serialization that would otherwise be necessary if the synchronous and asynchronous service layers accessed objects in each other’s memory directly.
The Half-Sync/Half-Async pattern also has the following liabilities:
A boundary-crossing penalty may be incurred from context switching, synchronization, and data copying overhead when data is transferred between the synchronous and asynchronous service layers via the queueing layer. For example, most operating systems implement the Half-Sync/Half-Async pattern by placing the queueing layer at the boundary between the user-level and kernel-level protection domains. A significant performance penalty can be incurred when crossing this boundary [HP91].
One way of reducing this overhead is to share a region of memory between the synchronous service layer and the asynchronous service layer [DP93]. This ‘zero-copy’ design allows the two layers to exchange data directly, without copying data into and out of the queueing layer.
[CP95] presents a set of extensions to the BSD UNIX I/O subsystem that minimizes boundary-crossing penalties by using polled interrupts to improve the handling of continuous media I/O streams. This approach defines a buffer management system that allows efficient page re-mapping and shared memory mechanisms to be used between application processes, the kernel, and its devices.
Higher-level application services may not benefit from the efficiency of asynchronous I/O. Depending on the design of operating system or application framework interfaces, it may not be possible for higher-level services to use low-level asynchronous I/O devices effectively. The BSD UNIX operating system, for example, prevents applications from using certain types of hardware efficiently, even if external sources of I/O support asynchronous overlapping of computation and communication.
Complexity of debugging and testing. Applications written using the Half-Sync/Half-Async pattern can incur the same debugging and testing challenges described in Consequences sections of the Proactor (215) and Reactor (179) patterns.
The Proactor pattern (215) can be viewed as an extension of the Half-Sync/Half-Async pattern that propagates asynchronous control and data operations all the way up to higher-level services. In general, the Proactor pattern should be applied if an operating system platform supports asynchronous I/O efficiently and application developers are comfortable with the asynchronous I/O programming model.
The Reactor pattern (179) can be used in conjunction with the Active Object pattern (369) to implement the Half-Sync/Half-Reactive variant of the Half-Sync/Half-Async pattern. Similarly, the Leader/Followers (447) pattern can be used in lieu of the Half-Sync/Half-Async pattern if there is no need for a queueing layer between the asynchronous and synchronous layers.
The Pipes and Filters pattern [POSA1] describes several general principles for implementing producer-consumer communication between components in a software system. Certain configurations of the Half-Sync/Half-Async pattern can therefore be viewed as instances of the Pipes and Filters pattern, where filters contain entire layers of many finer-grained services. Moreover, a filter could contain active objects, which could yield the Half-Sync/Half-Reactive or Half-Sync/Half-Sync variants.
The Layers [POSA1] pattern describes the general principle of separating services into separate layers. The Half-Sync/Half-Async pattern can thus be seen as a specialization of the Layers pattern whose purpose is to separate synchronous processing from asynchronous processing in a concurrent system by introducing two designated layers for each type of service.
Chuck Cranor was the co-author of the original version of this pattern [PLoPD2]. We would also like to thank Lorrie Cranor and Paul McKenney for comments and suggestions for improving the pattern.
The Leader/Followers architectural pattern provides an efficient concurrency model where multiple threads take turns sharing a set of event sources in order to detect, demultiplex, dispatch, and process service requests that occur on the event sources.
Consider the design of a multi-tier, high-volume, on-line transaction processing (OLTP) system [GR93]. In this design, front-end communication servers route transaction requests from remote clients, such as travel agents, claims processing centers, or point-of-sales terminals, to back-end database servers that process the requests transactionally. After a transaction commits, the database server returns its results to the associated communication server, which then forwards the results back to the originating remote client. This multi-tier architecture is used to improve overall system throughput and reliability via load balancing and redundancy, respectively. It also relieves back-end servers from the burden of managing different communication protocols with remote clients.

One way to implement OLTP servers is to use a single-threaded event processing model based on the Reactor pattern (179). However, this model serializes event processing, which degrades the overall server performance when handling long-running or blocking client request events. Likewise, single-threaded servers cannot benefit transparently from multi-processor platforms.
A common strategy for improving OLTP server performance is to use a multi-threaded concurrency model that processes requests from different clients and corresponding results simultaneously [HPS99]. For example, we could multi-thread an OLTP back-end server by creating a thread pool based on the Half-Sync/Half-Reactive variant of the Half-Sync/Half-Async pattern (423). In this design, the OLTP back-end server contains a dedicated network I/O thread that uses the select() [Ste98] event demultiplexer to wait for events to occur on a set of socket handles connected to front-end communication servers.
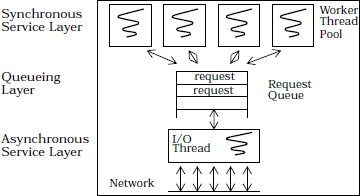
When activity occurs on handles in the set, select() returns control to the network I/O thread and indicates which socket handles in the set have events pending. The I/O thread then reads the transaction requests from the socket handles, stores them into dynamically allocated requests, and inserts these requests into a synchronized message queue implemented using the Monitor Object pattern (399). This message queue is serviced by a pool of worker threads. When a worker thread in the pool is available, it removes a request from the queue, performs the designated transaction, and then returns a response to the front-end communication server.
Although the threading model described above is used in many concurrent applications, it can incur excessive overhead when used for high-volume servers, such as those in our OLTP example. For instance, even with a light workload, the Half-Sync/Half-Reactive thread pool design will incur a dynamic memory allocation, multiple synchronization operations, and a context switch to pass a request message between the network I/O thread and a worker thread. These overheads make even the best-case latency unnecessarily high [PRS+99]. Moreover, if the OLTP back-end server is run on a multi-processor, significant overhead can occur from processor cache coherency protocols required to transfer requests between threads [SKT96].
If the OLTP back-end servers run on an operating system platform that supports asynchronous I/O efficiently, the Half-Sync/Half-Reactive thread pool can be replaced with a purely asynchronous thread pool based on the Proactor pattern (215). This alternative will reduce much of the synchronization, context switching, and cache coherency overhead outlined above by eliminating the network I/O thread. Unfortunately, many operating systems do not support asynchronous I/O and those that do often support it inefficiently.8 Yet, it is essential that high-volume OLTP servers demultiplex requests efficiently to threads that can process the results concurrently.
An event-driven application where multiple service requests arriving on a set of event sources must be processed efficiently by multiple threads that share the event sources.
Multi-threading is a common technique to implement applications that process multiple events concurrently. However, it is hard to implement high-performance multi-threaded server applications. These applications often process a high volume of multiple types of events, such as CONNECT, READ, and WRITE events in our OLTP example, that arrive simultaneously. To address this problem effectively, three forces must be resolved:
For our OLTP server applications, it may not be practical to associate a separate thread with each socket handle. In particular, as the number of connections increase significantly, this design may not scale efficiently on many operating system platforms.
Implementing our OLTP servers using the Half-Sync/Half-Reactive thread pool variant (423) outlined in the Example section requires memory to be allocated dynamically in the network I/O thread to store incoming transaction requests into the message queue. This design incurs numerous synchronizations and context switches to insert the request into, or remove the request from, the message queue, as illustrated in the Monitor Object pattern (399).
For instance, a pool of threads cannot use select() concurrently to demultiplex a set of socket handles because the operating system will erroneously notify more than one thread calling select() when I/O events are pending on the same set of socket handles [Ste98]. Moreover, for bytestream-oriented protocols, such as TCP, having multiple threads invoking read() or write() on the same socket handle will corrupt or lose data.
Structure a pool of threads to share a set of event sources efficiently by taking turns demultiplexing events that arrive on these event sources and synchronously dispatching the events to application services that process them.
In detail: design a thread pool mechanism that allows multiple threads to coordinate themselves and protect critical sections while detecting, demultiplexing, dispatching, and processing events. In this mechanism, allow one thread at a time—the leader—to wait for an event to occur on a set of event sources. Meanwhile, other threads—the followers—can queue up waiting their turn to become the leader. After the current leader thread detects an event from the event source set, it first promotes a follower thread to become the new leader. It then plays the role of a processing thread, which demultiplexes and dispatches the event to a designated event handler that performs application-specific event handling in the processing thread. Multiple processing threads can handle events concurrently while the current leader thread waits for new events on the set of event sources shared by the threads. After handling its event, a processing thread reverts to a follower role and waits to become the leader thread again.
There are four key participants in the Leader/Followers pattern:
Handles are provided by operating systems to identify event sources, such as network connections or open files, that can generate and queue events. Events can originate from external sources, such as CONNECT events or READ events sent to a service from clients, or internal sources, such as time-outs. A handle set is a collection of handles that can be used to wait for one or more events to occur on handles in the set. A handle set returns to its caller when it is possible to initiate an operation on a handle in the set without the operation blocking.
OLTP servers are interested in two types of events—CONNECT events and READ events—which represent incoming connections and transaction requests, respectively. Both front-end and back-end servers maintain a separate connection for each client, where clients of front-end servers are the so-called ‘remote’ clients and front-end servers themselves are clients of back-end servers. Each connection is a source of events that is represented in a server by a separate socket handle. Our OLTP servers use the select() event demultiplexer, which identifies handles whose event sources have pending events, so that applications can invoke I/O operations on these handles without blocking the calling threads.

An event handler specifies an interface consisting of one or more hook methods [Pree95] [GoF95]. These methods represent the set of operations available to process application-specific events that occur on handle(s) serviced by an event handler.
Concrete event handlers specialize the event handler and implement a specific service that the application offers. In particular, concrete event handlers implement the hook method(s) responsible for processing events received from a handle.

For example, concrete event handlers in OLTP front-end communication servers receive and validate remote client requests, and then forward requests to back-end database servers. Likewise, concrete event handlers in back-end database servers receive transaction requests from front-end servers, read/write the appropriate database records to perform the transactions, and return the results to the front-end servers. All network I/O operations are performed via socket handles, which identify various sources of events.
At the heart of the Leader/Followers pattern is a thread pool, which is a group of threads that share a synchronizer, such as a semaphore or condition variable, and implement a protocol for coordinating their transition between various roles. One or more threads play the follower role and queue up on the thread pool synchronizer waiting to play the leader role. One of these threads is selected to be the leader, which waits for an event to occur on any handle in its handle set. When an event occurs, the current leader thread promotes a follower thread to become the new leader. The original leader then concurrently plays the role of a processing thread, which demultiplexes that event from the handle set to an appropriate event handler and dispatches the handler’s hook method to handle the event. After a processing thread is finished handling an event, it returns to playing the role of a follower thread and waits on the thread pool synchronizer for its turn to become the leader thread again.

Each OLTP server designed using the Leader/Followers pattern can have a pool of threads waiting to process transaction requests that arrive on event sources identified by a handle set. At any point in time, multiple threads in the pool can be processing transaction requests and sending results back to their clients. One thread in the pool is the current leader, which waits for a new CONNECT or READ event to arrive on the handle set shared by the threads. When this occurs, the leader thread becomes a processing thread and handles the event, while one of the follower threads in the pool is promoted to become the new leader.
The following class diagram illustrates the structure of participants in the Leader/Followers pattern. In this structure, multiple threads share the same instances of thread pool, event handler, and handle set participants. The thread pool ensures the correct and efficient coordination of the threads:

The collaborations in the Leader/Followers pattern divide into four phases:
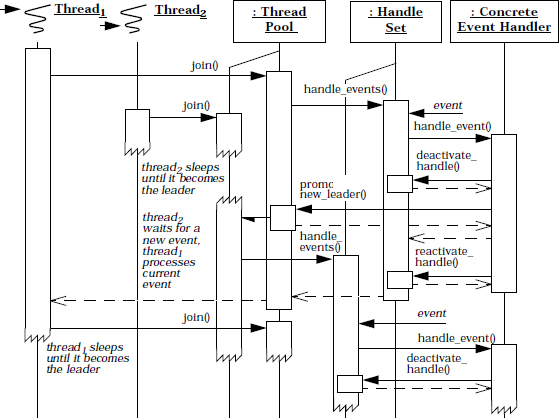
A thread’s transitions between states can be visualized in the following diagram:

Six activities can be used to implement the Leader/Followers pattern:
The following table summarizes representative examples for each combination of concurrent and iterative handles and handle sets:

As discussed in implementation activities 1.1 (456) and 1.2 (457), the semantics of certain combinations of protocols and network programming APIs support concurrent multiple I/O operations on a shared handle. For example, UDP support in the Socket API ensures a complete message is always read or written by one thread or another, without the risk of a partial read() or of data corruption from an interleaved write(). Likewise, certain handle set mechanisms, such as the Win32 WaitForMultipleObjects() function [Sol98], return a single handle per call, which allows them to be called concurrently by a pool of threads.9
In these situations, it may be possible to implement the Leader/Followers pattern by simply using the operating system’s thread scheduler to (de)multiplex threads, handle sets, and handles robustly, in which case, implementation activities 2 through 6 can be skipped.
Implementation activity 3.3 of the Reactor pattern (179) illustrates how to implement a demultiplexing table.
In our OLTP server example, an event must be demultiplexed to the concrete event handler associated with the socket handle that received the event. The Reactor pattern (179) supports this activity, therefore it can be applied to simplify the implementation of the Leader/Followers pattern. In the context of the Leader/Followers pattern, however, a reactor demultiplexes just one handle at a time to its associated concrete event handler, regardless of how many handles have events pending on them. Demultiplexing only one handle at a time can maximize the concurrency among a pool of threads and simplify a Leader/Followers pattern implementation by alleviating its need to manage a separate queue of pending events.
Deactivating the handle from the handle set avoids race conditions that could occur between the time when a new leader is selected and the event is processed. If the new leader waits on the same handle in the handle set during this interval, it could demultiplex the event a second time, which is erroneous because the dispatch is already in progress. After the event is processed, the handle is reactivated in the handle set, which allows the leader thread to wait for an event to occur on it or any other activated handles in the set.
In our OLTP example, a handle deactivation and reactivation protocol can be provided by extending the Reactor interface defined in implementation activity 2 of the Reactor pattern (179):
class Reactor {
public:
// Temporarily deactivate the <HANDLE>
// from the internal handle set.
void deactivate_handle (HANDLE, Event_Type);
// Reactivate a previously deactivated
// <Event_Handler> to the internal handle set.
void reactivate_handle (HANDLE, Event_Type);
// …
};
For example, the LF_Thread_Pool class shown below can be used for the back-end database servers in our OLTP example:
class LF_Thread_Pool {
public:
// Constructor.
LF_Thread_Pool (Reactor *r): reactor_ (r) { }
// Threads call <join> to wait on a handle set and
// demultiplex events to their event handlers.
void join (Time_Value *timeout = 0);
// Promote a follower thread to become the
// leader thread.
void promote_new_leader ();
// Support the <HANDLE> (de)activation protocol.
void deactivate_handle (HANDLE, Event_Type et);
void reactivate_handle (HANDLE, Event_Type et);
private:
// Pointer to the event demultiplexer/dispatcher.
Reactor *reactor_;
// The thread id of the leader thread, which is
// set to NO_CURRENT_LEADER if there is no leader.
Thread_Id leader_thread_;
// Follower threads wait on this condition
// variable until they are promoted to leader.
Thread_Condition followers_condition_;
// Serialize access to our internal state.
Thread_Mutex mutex_;
};
The constructor of LF_Thread_Pool caches the reactor passed to it. By default, this reactor implementation uses select(), which supports iterative handle sets. Therefore, LF_Thread_Pool is responsible for serializing multiple threads that take turns calling select() on the reactor’s handle set.
Application threads invoke join() to wait on a handle set and demultiplex new events to their associated event handlers. As shown in implementation activity 4 (462), this method does not return to its caller until the application terminates or join() times out. The promote_new_leader() method promotes one of the follower threads in the set to become the new leader, as shown in implementation activity 5.2 (464).
The deactivate_handle() method and the reactivate_handle() method deactivate and reactivate handles within a reactor’s handle set. The implementations of these methods simply forward to the same methods defined in the Reactor interface shown in implementation activity 2 (459).
Note that a single condition variable synchronizer followers_condition_ is shared by all threads in this thread pool. As shown in implementation activities 4 (462) and 5 (463), the implementation of LF_Thread_Pool uses the Monitor Object pattern (399).
This protocol is used in the following two cases:
If no leader thread is available, a processing thread can become the leader immediately. If a leader thread is already available, a thread can become a follower by waiting on the thread pool’s synchronizer.
Our back-end database servers can implement the following join() method of the LF_Thread_Pool to wait on a handle set and demultiplex new events to their associated event handlers:
void LF_Thread_Pool::join (Time_Value *timeout) {
// Use Scoped Locking idiom to acquire mutex
// automatically in the constructor.
Guard<Thread_Mutex> guard (mutex_);
for (;;) {
while (leader_thread_ != NO_CURRENT_LEADER)
// Sleep and release <mutex> atomically.
followers_condition_.wait (timeout);
// Assume the leader role.
leader_thread_ = Thread::self ();
// Leave monitor temporarily to allow other
// follower threads to join the pool.
guard.release ();
// After becoming the leader, the thread uses
// the reactor to wait for an event.
reactor_->handle_events ()’
// Reenter monitor to serialize the test
// for <leader_thread_> in the while loop.
guard.acquire ();
}
}
Within the for loop, the calling thread alternates between its role as a leader, processing, and follower thread. In the first part of this loop, the thread waits until it can be a leader, at which point it uses the reactor to wait for an event on the shared handle set. When the reactor detects an event on a handle, it will demultiplex the event to its associated event handler and dispatch its handle_event() method to promote a new leader and process the event. After the reactor demultiplexes one event, the thread re-assumes its follower role. These steps continue looping until the application terminates or a timeout occurs.
An application can implement concrete event handlers that subclass from the Event_Handler class defined in implementation activity 1.2 of the Reactor pattern (179). Likewise, the Leader/Followers implementation can use the Decorator pattern [GoF95] to create an LF_Event_Handler class that decorates Event_Handler. This decorator promotes a new leader thread and activates/deactivates the handler in the reactor’s handle set transparently to the concrete event handlers.
class LF_Event_Handler : public Event_Handler {
public:
LF_Event_Handler (Event_Handler *eh,
LF_Thread_Pool *tp)
: concrete_event_handler_ (eh),
thread_pool_ (tp) { }
virtual void handle_event (HANDLE h, Event_Type et) {
// Temporarily deactivate the handler in the
// reactor to prevent race conditions.
thread_pool_->deactivate_handle (h, et);
// Promote a follower thread to become leader.
thread_pool_->promote_new_leader ();
// Dispatch application-specific event
// processing code.
concrete_event_handler_->handle_event (h, et);
// Reactivate the handle in the reactor.
thread_pool_->reactivate_handle (h, et);
}
private:
// This use of <Event_Handler> plays the
// <ConcreteComponent> role in the Decorator
// pattern, which is used to implement
// the application-specific functionality.
Event_Handler *concrete_event_handler_;
// Instance of an <LF_Thread_Pool>.
LF_Thread_Pool *thread_pool_;
};
Cache affinity can improve system performance if the thread that blocked most recently executes essentially the same code and data when it is scheduled to run again. Implementing a LIFO promotion protocol requires an additional data structure, however, such as a stack of waiting threads, rather than just using a native operating system synchronization object, such as a semaphore.
Our OLTP back-end database servers could use the following simple protocol to promote follower thread in whatever order they are queued by a native operating system condition variable:
void LF_Thread_Pool::promote_new_leader () {
// Use Scoped Locking idiom to acquire mutex
// automatically in the constructor.
Guard<Thread_Mutex> guard (mutex_);
if (leader_thread_ != Thread::self ())
throw /* …only leader thread can promote… */;
// Indicate that we are no longer the leader
// and notify a <join> method to promote
// the next follower.
leader_thread_ = NO_CURRENT_LEADER;
followers_condition_.notify ();
// Release mutex automatically in destructor.
}
The OLTP back-end database servers described in the Example section can use the Leader/Followers pattern to implement a thread pool that demultiplexes I/O events from socket handles to their event handlers efficiently. In this design, there is no designated network I/O thread. Instead, a pool of threads is pre-allocated during database server initialization:
const int MAX_THREADS = /* … */;
// Forward declaration.
void *worker_thread (void *);
int main () {
LF_Thread_Pool thread_pool (Reactor::instance ());
// Code to set up a passive-mode Acceptor omitted.
for (int i = 0; i < MAX_THREADS - 1; ++i)
Thread_Manager::instance ()->spawn
(worker_thread, &thread_pool);
// The main thread participates in the thread pool.
thread_pool.join ();
};
These threads are not bound to any particular socket handle. Thus, all threads in this pool take turns playing the role of a network I/O thread by invoking the LF_Thread_Pool::join() method:
void *worker_thread (void *arg) {
LF_Thread_Pool *thread_pool =
static_cast <LF_Thread_Pool *> (arg);
// Each worker thread participates in the thread pool.
thread_pool->join ();
};
As shown in implementation activity 4 (462), the join() method allows only the leader thread to use the Reactor singleton to select() on a shared handle set of Sockets connected to OLTP front-end communication servers. If requests arrive when all threads are busy, they will be queued in socket handles until threads in the pool are available to execute the requests.
When a request event arrives, the leader thread deactivates the socket handle temporarily from consideration in select()’s handle set, promotes a follower thread to become the new leader, and continues to handle the request event as a processing thread. This processing thread then reads the request into a buffer that resides in the run-time stack or is allocated using the Thread-Specific Storage pattern (475).10 All OLTP activities occur in the processing thread. Thus, no further context switching, synchronization, or data movement is necessary until the processing completes. When it finishes handling a request, the processing thread returns to playing the role of a follower and waits on the synchronizer in the thread pool. Moreover, the socket handle it was processing is reactivated in the Reactor singleton’s handle set so that select() can wait for I/O events to occur on it, along with other Sockets in the handle set.
Bound Handle/Thread Associations. The earlier sections in this pattern describe unbound handle/thread associations, where there is no fixed association between threads and handles. Thus, any thread can process any event that occurs on any handle in a handle set. Unbound associations are often used when a pool of worker threads take turns demultiplexing a shared handle set.
A variant of the Leader/Followers pattern uses bound handle/thread associations. In this variant, each thread is bound to its own handle, which it uses to process particular events. Bound associations are often used in the client-side of an application when a thread waits on a socket handle for a response to a two-way request it sent to a server. In this case, the client application thread expects to process the response event on this handle in the same thread that sent the original request.
In the bound handle/thread association variant, therefore, the leader thread in the thread pool may need to hand-off an event to a follower thread if the leader does not have the necessary context to process the event. After the leader detects a new event, it checks the handle associated with the event to determine which thread is responsible for processing it. If the leader thread discovers that it is responsible for the event, it promotes a follower thread to become the new leader Conversely, if the event is intended for another thread, the leader must hand-off the event to the designated follower thread. This follower thread can then temporally disable the handle and process the event. Meanwhile, the current leader thread continues to wait for another event to occur on the handle set.
The following diagram illustrates the additional transition between the following state and the processing state:

The leader/follower thread pool can be maintained implicitly, for example, using a synchronizer, such as a semaphore or condition variable, or explicitly, using a container and the Manager pattern [Som97]. The choice depends largely on whether the leader thread must notify a specific follower thread explicitly to perform event hand-offs.
A detailed discussion of the bounded handle/thread association variant and its implementation appears in [SRPKB00].
Relaxing Serialization Constraints. There are operating systems where multiple leader threads can wait on a handle set simultaneously. For example, the Win32 function WaitForMultipleObjects() [Sol98] supports concurrent handle sets that allow a pool of threads to wait on the same set of handles concurrently. Thus, a thread pool designed using this function can take advantage of multi-processor hardware to handle multiple events concurrently while other threads wait for events.
Two variations of the Leader/Followers pattern can be applied to allow multiple leader threads to be active simultaneously:
Hybrid Thread Associations. Some applications use hybrid designs that implement both bound and unbound handle/thread associations simultaneously. Likewise, some handles in an application may have dedicated threads to handle certain events, whereas other handles can be processed by any thread. Thus, one variant of the Leader/Follower pattern uses its event hand-off mechanism to notify certain subsets of threads, according to the handle on which event activity occurs.
For example, the OLTP front-end communication server may have multiple threads using the Leader/Followers pattern to wait for new request events from clients. Likewise, it may also have threads waiting for responses to requests they invoked on back-end servers. In fact, threads play both roles over their lifetime, starting as threads that dispatch new incoming requests, then issuing requests to the back-end servers to satisfy the client application requirements, and finally waiting for responses to arrive from the back-end server.
Hybrid Client/Servers. In complex systems, where peer applications play both client and server roles, it is important that the communication infrastructure processes incoming requests while waiting for one or more replies. Otherwise, the system can deadlock because one client dedicates all its threads to block waiting for responses.
In this variant, the binding of threads and handles changes dynamically. For example, a thread may be unbound initially, yet while processing an incoming request the application discovers it requires a service provided by another peer in the distributed system. In this case, the unbound thread dispatches a new request while executing application code, effectively binding itself to the handle used to send the request. Later, when the response arrives and the thread completes the original request, it becomes unbound again.
Alternative Event Sources and Sinks. Consider a system where events are obtained not only through handles but also from other sources, such as shared memory or message queues. For example, in UNIX there are no event demultiplexing functions that can wait for I/O events, semaphore events, and/or message queue events simultaneously. However, a thread can either block waiting for one type of event at the same time. Thus, the Leader/Followers pattern can be extended to wait for more than one type of events simultaneously:
A drawback with this variant, however, is that the number of participating threads must always be greater than the number of event sources. Therefore, this approach may not scale well as the number of event sources grows.
ACE Thread Pool Reactor framework [Sch97]. The ACE framework provides an object-oriented framework implementation of the Leader/Followers pattern called the ‘thread pool reactor’ (ACE_TP_Reactor) that demultiplexes events to event handlers within a pool of threads. When using a thread pool reactor, an application pre-spawns a fixed number of threads. When these threads invoke the ACE_TP_Reactor’s handle_events() method, one thread will become the leader and wait for an event. Threads are considered unbound by the ACE thread pool reactor framework. Thus, after the leader thread detects the event, it promotes an arbitrary thread to become the next leader and then demultiplexes the event to its associated event handler.
CORBA ORBs and Web servers. Many CORBA implementations, including Chorus COOL ORB [SMFG00] and TAO [SC99], use the Leader/Followers pattern for both their client-side connection model and the server-side concurrency model. In addition, The JAWS Web server [HPS99] uses the Leader/Followers thread pool model for operating system platforms that do not allow multiple threads to simultaneously call accept() on a passive-mode socket handle.
Transaction monitors. Popular transaction monitors, such as Tuxedo, operate traditionally on a per-process basis, for example, transactions are always associated with a process. Contemporary OLTP systems demand high-performance and scalability, however, and performing transactions on a per-process basis may fail to meet these requirements. Therefore, next-generation transaction services, such as implementations of the CORBA Transaction Service [OMG97b], employ bound Leader/Followers associations between threads and transactions.
Taxi stands. The Leader/Followers pattern is used in everyday life to organize many airport taxi stands. In this use case, taxi cabs play the role of the ‘threads,’ with the first taxi cab in line being the leader and the remaining taxi cabs being the followers. Likewise, passengers arriving at the taxi stand constitute the events that must be demultiplexed to the cabs, typically in FIFO order. In general, if any taxi cab can service any passenger, this scenario is equivalent to the unbound handle/thread association described in the main Implementation section. However, if only certain cabs can service certain passengers, this scenario is equivalent to the bound handle/thread association described in the Variants section.
The Leader/Followers pattern provides several benefits:
Performance enhancements. Compared with the Half-Sync/Half-Reactive thread pool approach described in the Example section, the Leader/Followers pattern can improve performance as follows:
Programming simplicity. The Leader/Follower pattern simplifies the programming of concurrency models where multiple threads can receive requests, process responses, and demultiplex connections using a shared handle set.
However, the Leader/Followers pattern has the following liabilities:
Implementation complexity. The advanced variants of the Leader/Followers pattern are harder to implement than Half-Sync/Half-Reactive thread pools. In particular, when used as a multi-threaded connection multiplexer, the Leader/Followers pattern must maintain a pool of follower threads waiting to process requests. This set must be updated when a follower thread is promoted to a leader and when a thread rejoins the pool of follower threads. All these operations can happen concurrently, in an unpredictable order. Thus, the Leader/Follower pattern implementation must be efficient, while ensuring operation atomicity.
Lack of flexibility. Thread pool models based on the Half-Sync/Half-Reactive variant of the Half-Sync/Half-Async pattern (423) allow events in the queueing layer to be discarded or re-prioritized. Similarly, the system can maintain multiple separate queues serviced by threads at different priorities to reduce contention and priority inversion between events at different priorities. In the Leader/Followers model, however, it is harder to discard or reorder events because there is no explicit queue. One way to provide this functionality is to offer different levels of service by using multiple Leader/Followers groups in the application, each one serviced by threads at different priorities.
Network I/O bottlenecks. The Leader/Followers pattern, as described in the Implementation section, serializes processing by allowing only a single thread at a time to wait on the handle set. In some environments, this design could become a bottleneck because only one thread at a time can demultiplex I/O events. In practice, however, this may not be a problem because most of the I/O-intensive processing is performed by the operating system kernel. Thus, application-level I/O operations can be performed rapidly.
The Reactor pattern (179) often forms the core of Leader/Followers pattern implementations. However, the Reactor pattern can be used in lieu of the Leader/Followers pattern when each event only requires a short amount of time to process. In this case, the additional scheduling complexity of the Leader/Followers pattern is unnecessary.
The Proactor pattern (215) defines another model for demultiplexing asynchronous event completions concurrently. It can be used instead of the Leader/Followers pattern:
The Half-Sync/Half-Async (423) and Active Object (369) patterns are two other alternatives to the Leader/Followers pattern. These patterns may be a more appropriate choice than the Leader/Followers pattern:
The Controlled Reactor pattern [DeFe99] includes a performance manager that controls the use of threads for event handlers according to a user’s specification and may be an alternative when controlled performance is an important objective.
Michael Kircher, Carlos O’Ryan, and Irfan Pyarali are the co-authors of the original version of the Leader/Followers pattern. Thanks to Ed Fernandez for his comments that helped improve this version of the pattern.