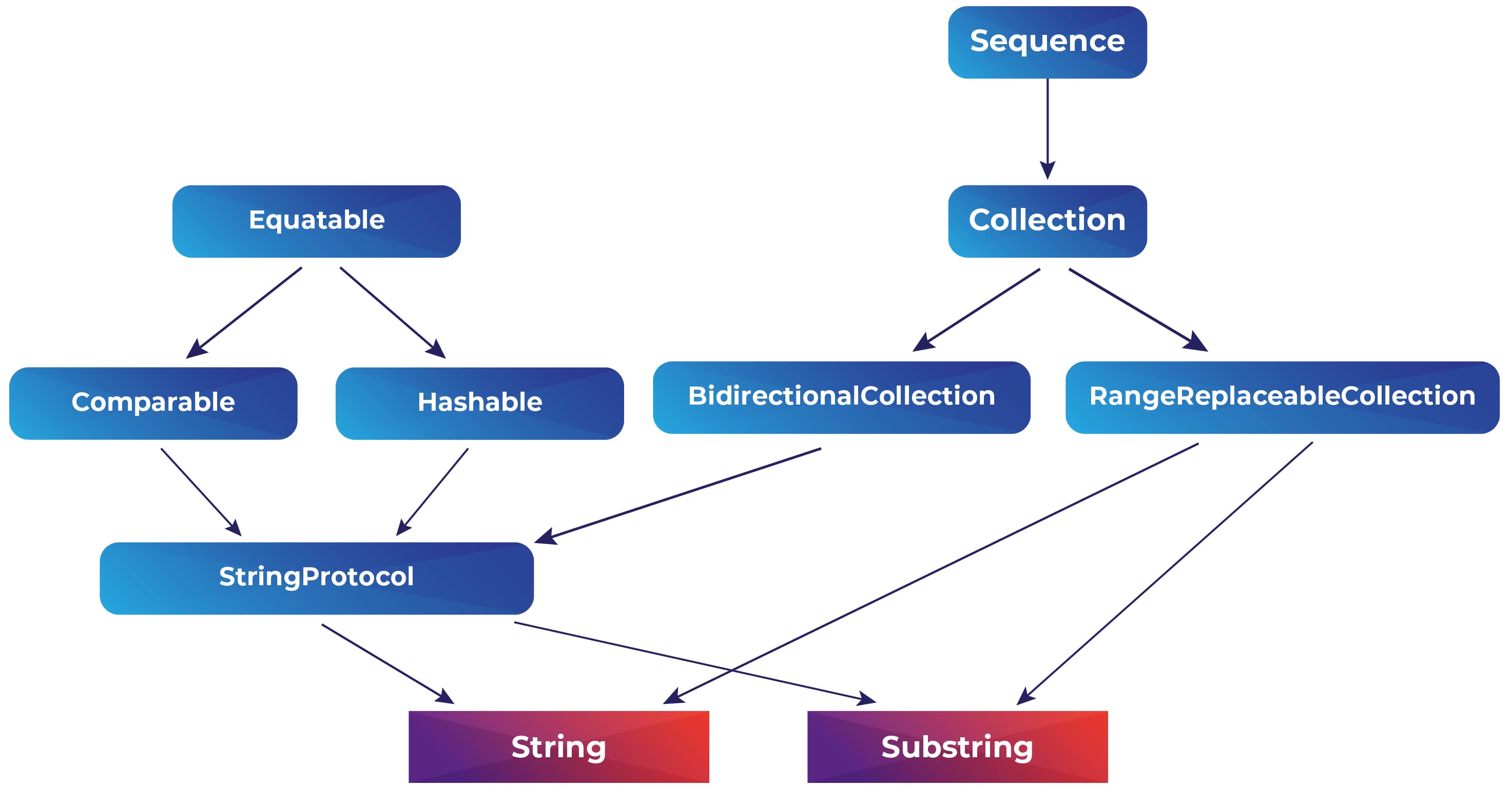
SubString is for strings like what ArraySlice is for arrays: a view of a part of a string, where its startIndex and endIndex are indices into the original string. It conforms to the same protocols as String:
StringProtocol contains many of the common text operations, so when you write functions that take a string parameter you can often use StringProtocol instead to also accept substrings. When you do, you have to use generics, as shown here:
func foo<S: StringProtocol>(s: S) {
// use 's' almost like a normal string.
}Just as with ArraySlice, substrings keep a reference to the entire string, so when you are done processing substrings you should turn them into normal strings and allow the original string to be released (if nothing else is using it):
String(substring)
Now it's time to create substrings. Follow these steps to do so:
- We can create substrings by passing a range of indices to a string subscript:
string[from..<upTo] string[from...upToAndIncluding]
- And we get a substring of the entire string with this little shortcut:
string[...]
- The following methods return a substring and leave the original string intact:
let string = "This is a pretty 👍 sentence" // a substring from the 2nd character and out string.dropFirst() // a substring from the 6th character and out string.dropFirst(5) // a substring from the first up to and including the second last string.dropLast() // a substring from the first up to the 9th last character string.dropLast(9) // a substring from the first space and out string.drop(while: {$0 != " "}) // the index of the first space, or the first character if there are no spaces let space_index = string.index(of: " ") ?? string.startIndex // a substring with the first 7 characters string.prefix(7) // a substring from the first up to space_index (excluding) string.prefix(upTo: space_index) // a substring from the first up to and including space_index string.prefix(through: space_index) // a substring of the consonants at the beginning of the string ("Th") string.prefix(while: {!["a", "e", "i", "o", "u"].contains($0)}) // a substring of the last 8 characters string.suffix(8) // a substring from space_index and out string.suffix(from: space_index) - The following methods return an array of substrings:
// the substrings between the spaces string.split(separator: " ") // split the string into 5 substrings (at the first 4 spaces), including the empty substring between the 2 adjacent spaces string.split(separator: " ", maxSplits: 4, omittingEmptySubsequences: false) // the substrings between the vowels string.split(whereSeparator: {["a", "e", "i", "o", "u"].contains($0)})
Follow these steps to parse strings:
- Go to the
Exercise - Parsepage of theStringsplayground. Enter the code to turn this:let info = """ title: Beginning Swift type: course year: 2018 publisher: Packt Publishing topic: programming """
Into this dictionary:
["year": "2018", "publisher": "Packt Publishing", "title": "Beginning Swift", "topic": "programming", "type": "course"]
- A possible solution is this:
for line in info.split(separator: "\n") { guard let colon = line.index(of: ":") else { continue } let key = line.prefix(upTo: colon) let value = line.suffix(from: line.index(colon, offsetBy: 2)) result[String(key)] = String(value) }
Earlier, we made the countLinguisticTokens method for counting the number of words, sentences, and paragraphs in a string. It would be nice if we could get hold of the actual words, sentences, and paragraphs, too:
func linguisticTokens(ofType unit: NSLinguisticTaggerUnit, options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace]) -> [String] {
let tagger = NSLinguisticTagger(tagSchemes: [.tokenType], options: 0)
tagger.string = self
let range = NSRange(startIndex..<endIndex, in: self)
var result = [String]()
tagger.enumerateTags(in: range, unit: unit, scheme: .tokenType, options: options, using: { _, tokenRange, _ in
let token = (self as NSString).substring(with: tokenRange)
result.append(token)
})
return result
}The only changes are the return type and these two lines:
let token = (self as NSString).substring(with: tokenRange)
result.append(token)tokenRange is of type NSRange, so we can't use it directly on String, but have to cast ourselves into NSString first.
This works fine, but it would be even nicer and more Swifty if we could get back ranges instead of strings, so we can decide for ourselves if we want to turn them into substrings or strings or do other operations with them. If we try to convert the NSRange to a Swift Range with Range(tokenRange, in: self), it returns an optional, and worse, in the third-last line of the example text, it returns nil. Twice. This is presumably because these characters do not fit in one UTF-16 code unit, and the conversion would create an index pointing to the middle of a Swift Character (see methods linguisticTokens2 and linguisticTokens3 for attempts at moving the index to the correct side of this character).
This highlights the usefulness of a string type which takes care of these things for us, and potential problems with converting between Foundation types and Swift types, not to mention the importance of testing with various languages.
Luckily, there is another Foundation method we can use that returns Swift ranges. We will use enumerateLinguisticTags in the next activity.
In this section, we have looked at substrings in detail: starting from its relation to strings to creating substrings.
Such a method can be used to automatically format code or create a text service on the Mac.
To use an Xcode playground to create a method on String, which turns it into one CamelCased word, optionally with the first letter lowercased.
- Open the
StringsExtraXcode project, and go to theStringsExtra.swiftfile. - Add this code to the bottom of the file:
extension String {- First, we create a method which returns an array of ranges of all the words in the string:
public func wordRanges() -> [Range<String.Index>] { let options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace] var words = [Range<String.Index>]() - This method on String gives us Swift ranges (as opposed to the NSRanges of the
linguisticTokensmethod we used previously). Unfortunately, it doesn't provide sentences or paragraphs, but in this case words are all we need:self.enumerateLinguisticTags( in: startIndex..<endIndex, scheme: NSLinguisticTagScheme.tokenType.rawValue, options: options) { (_, range, _, _) in words.append(range) } return words } - Now, for the
camelCasedmethod itself, which returns a capitalised CamelCase word by default:public func camelCased(capitalised: Bool = true) -> String { - First, we get all the ranges of the words in this string. We exit if there are no words in order to avoid a crash in the next line (
removeFirstremoves and returns the first element, and crashes if there isn't one):var wordRanges = self.wordRanges() guard !wordRanges.isEmpty else { return "" } let firstRange = wordRanges.removeFirst() - We initialize result to the first word, which is optionally capitalised. Note that both
capitalizedandlowercasedare methods on SubString which return strings:var result = capitalised ? self[firstRange].capitalized : self[firstRange].lowercased()
Then, it's a simple matter of going through the remaining words, capitalizing them, and adding them to
result:for range in wordRanges { result += self[range].capitalized } return result } }
- First, we create a method which returns an array of ranges of all the words in the string:
- Go to the unit tests in
StringsExtraTests.swift. - Uncomment the next comment block, so this becomes active:
func testCamelCased() { - Run all unit tests and verify that they pass.