CHAPTER 2
Demystifying Big Data
I know it when I see it.
—Supreme Court Justice Potter Stewart on his threshold test for possible obscenity. Concurring opinion, Jacobellis v. Ohio (1964)
The previous quote comes from perhaps the most famous of all U.S. Supreme Court cases. Stewart’s line “I know it when I see it” long ago entered the vernacular, at least in the United States. It’s been applied to myriad different scenarios. Those seven words illustrate a number of things, not the least of which is the difficulty that even really smart people have in defining ostensibly simple terms.
Fast forward nearly fifty years, and many learned folks are having the same issue with respect to Big Data. Just what the heck is it, anyway? Much like the term cloud computing, you can search in vain for weeks for the “perfect” definition of Big Data. Douglas Laney (then with the META group, now with Gartner) fired the first shot in late 2001. Laney wrote about the growth challenges and opportunities facing organizations with respect to increasing amounts of data.1 Years before the term Big Data was de rigueur, Laney defined three primary dimensions of the Data Deluge:
- Volume: the increasing amount of data
- Variety: the increasing range of data types and sources
- Velocity: the increasing speed of data
Laney’s three v’s stuck, and today most people familiar with Big Data have heard of them. That’s a far cry from saying, however, that everyone agrees on the proper definition of Big Data. Just about every major tech vendor and consulting firm has a vested interest in pushing its own agenda. To this end, many companies and thought leaders have developed their own definitions of Big Data. A few have even tried to introduce additional v’s like veracity (from IBM2) and variability (from Forrester Research3). Among the technorati, arguments abound, and it often gets pretty catty.
Let’s save some time: the perfect definition of Big Data doesn’t exist. Who can say with absolute certainty that one definition of the term is objectively better than all the others? Rather than searching for that phantom definition, this chapter describes the characteristics and demystifies the term.
CHARACTERISTICS OF BIG DATA
Providing a simple and concise definition of Big Data is a considerable challenge. After all, it’s a big topic. Less difficult, though, is describing the major characteristics of Big Data. Let’s go.
Big Data Is Already Here
Big Data is not some pie-in-the-sky, futuristic notion like flying cars. Nor is it a phenomenon largely in its infancy, such as the semantic web. Whether your particular organization currently does anything with Big Data is moot; it doesn’t change the fact that it has already arrived. Amazon, Apple, Facebook, Google, Yahoo!, Facebook, LinkedIn, American Airlines, IBM, Twitter, and scores of other companies currently use Big Data and related applications. While it’s not a perfect barometer or visualization, look at Figure 2.1 on news stories about Big Data captured by Google Trends.
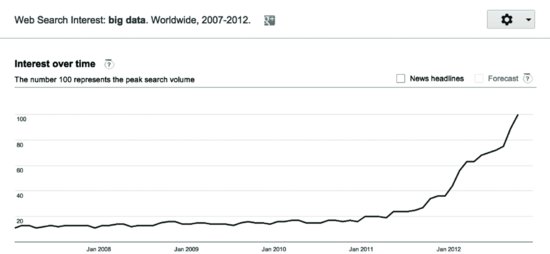
As Figure 2.1 shows, interest in Big Data has skyrocketed over the past few years, and Google only sees this trend continuing for the foreseeable future. And this is not just about Google searches or new buzzwords from consulting firms and software vendors. As I write these words, the United States has just reelected Barack Obama. Pundits called it the election of Big Data.5 “This election will be remembered for the role that Big Data played behind the scenes, at every step,” says Tarun Wadhwa, a research fellow at Singularity University studying digital identification systems and their impact on governance. “Obama won by identifying potential supporters and driving voter turnout in swing states.”6
Two days after the election, Time Magazine ran a fascinating account of how Obama’s team of sophisticated number crunchers identified key trends, performed extensive A/B testing, and made critical decisions. Ultimately, these actions helped the Obama campaign raise more than $1 billion and win the election.7 New political rock stars were anointed, like Jim Messina, Obama’s campaign manager. From the article, “The ‘scientists’ created regular briefings on their work for the President and top aides in the White House’s Roosevelt Room, but public details were in short supply as the campaign guarded what it believed to be its biggest institutional advantage over Mitt Romney’s campaign: its data.” [Emphasis mine.] In fact, the Democrats’ technology and data advantage may extend to 2016 and beyond. On the Business Insider site, Grace Wyler writes, “Nowhere were the GOP’s shortcomings more apparent than in the realm of data gathering and microtargeting, an increasingly important field of electioneering that provides campaigns with crucial insights into the nature of the electorate.”8
In a word, wow. I’ll be shocked if at least one book isn’t published soon about the role that Big Data played in the election—and the impact that it will have on future elections. I don’t see Big Data playing a smaller role in the 2014 and 2016 elections.
But Big Data goes way beyond politics and has for some time now. Few industries are more old school than wine, but Big Data is even making inroads there. Centuries-old winemakers like Gallo are launching new varietals based upon advanced analytics and data culled from social networks.9 Also on the wine front, data-driven companies like Fruition Sciences are using sensors to optimize grapevine quality and minimize wasted water.10 Laboratory and clinical scientists are collaborating and reaching conclusions from the same pool of (big) data—a process called translational research.11 The impact on medical research and drug discovery is potentially enormous. UPS regularly mines truck delivery data to optimize new routing methods and reduce expenses.12 Even pizza joints are getting in on the Big Data action.13 Each of these fields has been traditionally a “data-free zone.”
I could go on, but you get my drift: Big Data is already having an impact in many areas of business and society. Chapter 5 will provide three compelling case studies of organizations already on the Big Data train.
Big Data Is Extremely Fragmented
On February 28, 1983, M*A*S*H said good-bye. The series finale, titled “Goodbye, Farewell, and Amen,” became the most watched television broadcast in the history of television. An estimated 125 million viewers tuned in.14 While that number was unprecedented, back then consumer habits were fairly homogenous. That is, large numbers of us would buy the same records, read the same materials (books, magazines, and newspapers), go to the same movies, and watch the same shows. For instance, in the 1950s, a very large percentage of U.S. households routinely watched I Love Lucy. No, society wasn’t uniform, but the Long Tail hadn’t arrived yet. Relatively speaking, many of us consumed few different types of content.
That was then, and this is now. Compared to that era, today is Bizarro World. Hollywood hits still exist, and we still see best-selling books and albums. Relatively speaking, however, we consume many different types of content. Returning to TV, in 2011 the most popular show in the country (and, in fact, the world) was the forensic crime show CSI, but beneath its ratings something very different was going on. Sure, the show sports roughly 63 million viewers, but not among the 310 million citizens of the United States. Those 63 million come from more than three billion people across the globe.15 Authors like Seth Godin have written extensively about why the effectiveness of mass marketing has waned so precipitously. There is no mass market anymore. Today, there’s only one remaining commercial way to reach the masses every year: The Super Bowl.46 For that reason, the average price for a 30-second ad for the 2012 game was a record-breaking $3.5 million.16
Today, it’s a far cry from the 1980s, much less the 1950s. We long ago escaped the tyranny of a three-television-network world. People don’t confine their viewing to whatever shows are on ABC, CBS, and NBC. On the contrary, the Long Tail remains alive and well fifteen years after its arrival. We watch an ever-increasing number of niche shows and movies—and can even create our own programs via YouTube. Many of us haven’t listened to an FM or AM radio station in years. Today, we build our own customized radio stations on sites like Pandora. We read the blogs we like where we like. In mid-October 2012, Newsweek announced that it was discontinuing its print edition after 80 years. So how does all of this tie back to Big Data?
At a high level, we are no doubt generating and consuming more data—and different types of data—than ever. Not surprisingly, most of us only concern ourselves with the content relevant to us. (While I can talk your ear off about golf, tennis, the English progressive rock band Marillion, and technology, my knowledge of contemporary pop music and classic literature is laughable, and I know very little about reality TV.) Relative to the world’s entire body of content, very little actually matters to each of us individually. We don’t concern ourselves with the vast majority of books, movies, websites, etc., out there. For instance, more than seven in ten tweets are ignored—and that’s among the microscopic percentage of people we follow on Twitter.17 Someone with 3,000 “friends” on Facebook is still subject to Dunbar’s Number, meaning that each of us can really only keep track of 150 people in any meaningful way.18 (I laugh when I see individuals who follow 80,000 others on Twitter. Really?) For every YouTube video that goes viral, I suspect that tens of thousands only register a handful of views. (YouTube is a vintage Long Tail site.) After all, users upload more and more video content to the site every minute.19 Most blog posts aren’t read, and only a small percentage receives comments. Why? No one can possibly keep up with it all. Our ability to generate data far exceeds our ability to digest it. Data is just too big today.
In a sense, nothing has changed from the 1950s in that all of us still pick and choose what and how much we’ll consume. The difference today is that there’s much more choice by orders of magnitude. That is, relatively few of us watch a show “just because it’s on TV” or read the newspaper because there’s nothing else available.
None of the noisy statistics and facts just mentioned changes one simple truth: there’s still a signal in this noise, even if that signal is weak and difficult to find. As we’ll see in the next two chapters, Big Data tools allow that noise to be reduced; they strengthen that signal. Dismissing social media as junk specifically, and all forms of unstructured data generally, entirely misses the point. There’s gold in the streets, even if it’s surrounded by litter. With the right tools, organizations can find the gold in Big Data and do something with it.
Big Data Is Not an Elixir
For years, organizations have been searching in vain for that technology silver bullet, the one thing that would solve all their problems. Untold billions have been spent on new applications and related implementations, development efforts, consultants, systems, and methodologies. Let me be crystal clear here: Big Data is not an elixir in business, politics, government, or anything else. Think of Big Data as just one club in the bag, although an increasingly critical one. While potentially very powerful, it obviates neither the need for—nor the importance of—traditional data management. Don’t expect Big Data to resurrect a dying business, reverse the effects of incompetent management, or fix a broken corporate culture. A November 2011 Forbes article cited a recent survey of chief marketing executives. Among the survey’s key findings, “ . . . more than 60 percent of knowledge workers at large enterprises say their organizations lack the processes and the skills to use information effectively for decision making.”20
So Big Data has no magical powers. Recalcitrant employees unwilling to make decisions based upon data won’t suddenly do that because their employer got Big Data religion. What’s more, by itself, Big Data guarantees nothing; embracing it only increases the chances of success in any given area. Plenty of organizations have been extremely profitable without doing anything Big Data related, and it’s hard to imagine a day in which every company will get on board the Big Data train. Let’s say that two organizations (A and B) are identical save for one thing: A effectively uses Big Data, while B does not. All else being equal, I’ll bet on A over B any day of the week and twice on Sunday.
Small Data Extends Big Data
It’s critical for any enterprise to effectively manage its internal, structured data—aka, its Small Data. (Note, however, that Small Data is often quite big. It’s only “small” in comparison to Big Data. Many organizations store petabytes of structured, transactional data. Some database tables contain tens of billions of records.) Distinctions and definitions aside, the need to diligently manage Small Data is universal; it transcends organizational type, industry, and size.
Now, let’s not oversimplify matters here. Data management is a continuum, not a binary, and no group manages its own internal data without incident. However, I’m hard-pressed to think of any successful organization that routinely struggles with what is effectively basic blocking and tackling. I am sure that these companies exist—(i.e., those that are making a killing despite their truly messy enterprise data and related internal practices). I can’t help but wonder, though, how much better they would do if they took data management and governance seriously. In the end, these organizations succeed despite their internal data management practices, not because of them. And this success is usually ephemeral.
What’s the Big Data implication of all of this? All else being equal, parties that manage Small Data well will benefit more from Big Data than those that don’t. Well-managed organizations don’t waste time and resources manually cobbling together things like master customer, product, and employee lists. Employees at these companies merely click a mouse a few times or, better yet, receive these reports automatically. These organizations don’t need weeks to balance their books. As a result, they are often able to quickly understand their market share, sales, current liabilities, levels of risk, and the like. They can spot emerging trends. What’s more, they can more easily tie Small Data to Big Data, reaping greater rewards in the process.

At a high level, then, Small Data serves an important descriptive purpose: businesses can use it to determine what’s currently happening across a number of different areas—that is, they can understand the status quo. Still, this is just the tip of the iceberg. Data can do so much more, especially as a predictive tool. Data can help organizations spot nascent trends (both positive and negative), even if the precise reason driving a particular trend isn’t entirely clear.
The same can be said about metadata: it extends Big Data. Accurate metadata makes all types of data more meaningful—big and small, structured and unstructured, internal and external.
Big Data Is a Complement, Not a Substitute
While enormously powerful, Big Data can only do so much. At a high level, Big Data does not usurp the role of transactional and structured data and systems. Without question, Big Data can help organizations understand their customers better or make superior hiring decisions. However, Big Data cannot perform many essential organizational functions. For instance, Hadoop won’t generate an accurate P&L statement, trial balance, or aging receivables report. And hopefully, you’re not using Google’s Big Data tools to try to figure out how many employees work at your company. (Beyond its limitations, it’s also important to recognize the problems and issues associated with Big Data, topics covered more fully in Chapter 7.)
If I can use a golf analogy, think of Big Data as a driver. If swung right, one can hit a ball 300 yards with it, but you sure wouldn’t want to putt with it. No one hits a putter off the tee, and there’s a reason for that. If you want to shoot a low score, you’ll probably have to do well with both clubs. To finish off the golf analogy, organizations adroit with both Small and Big Data are more likely to find themselves wearing green jackets. Alternatively, think of Small Data as checkers and Big Data as chess. If you can’t grasp the former, it’s unlikely that you’ll be very good at the latter.
Big Data Can Yield Better Predictions
Generally speaking, it isn’t terribly difficult for employees to spot trends, especially when they possess the right tools. However, there’s an important caveat to this statement. For a bevy of reasons, most people still try to identify trends based largely upon historical Small Data. For instance, most companies can predict their sales and profits for the next quarter and year, at least within a reasonable range and barring some type of calamity. (Of course, even ostensibly small deviations from these estimates can result in substantial stock price fluctuations for publicly traded companies.) For their part, retailers know that each year they’ll have to augment their staff with temps during Thanksgiving and Christmas, a process known as holiday hire.
Now, better predictions and more accurate forecasts should not be confused with perfect predictions and forecasts. Those who expect Big Data to predict the future with certainty will ultimately be disappointed. Big Data isn’t chemistry or algebra. Certitude evades us; Big Data only serves to reduce it.
Big Data Giveth—and Big Data Taketh Away
Reed Hastings did much more than just make renting DVDs more convenient and put Blockbuster out of business. Hastings did something truly special and rare: he built a company that millions of people actually loved. Few people really care about the inner technical workings of Netflix, but behind the scenes it utilizes Big Data, collaborative filtering technology, and crowdsourcing to build a powerful entertainment recommendation engine.
For now, consider the following Netflix statistics as reported by GigaOM on June 14, 2012:
- More than 25 million users
- About 30 million plays per day (and Netflix tracks every time its customers rewind, fast-forward, and pause a movie streamed over its site)
- More than 2 billion hours of streaming video watched during the last three months of 2011 alone
- About 4 million ratings per day
- About 3 million searches per day
- 75 percent of current customers select movies based on recommendations, a number the company wants to make even higher21
The size of these numbers is impressive, but Netflix doesn’t just count how many times movies like Memento are watched, when online viewers stop watching them, and so on. Hastings understands the importance of metadata. The company tracks user geo-location and device information, purchases extensive external metadata from third parties such as Nielsen, and integrates as much user social media data from Facebook and Twitter.22 For videos streamed via its website, Netflix knows the time of the day and week that its customers watched different programs and movies. For instance, the company knows that its customers watch more TV shows during the week and more movies during the weekend.
One could make the argument that much of Netflix’s success emanated from its effective use of Big Data. As Hastings discovered in the summer of 2011, however, Big Data can be a sword as well as a shield. Over a public and painful two-month period, Netflix lost more than half of its market value. The company rebranded and repriced its DVD-by-mail service (Qwikster), an ill-conceived move that “alienated customers and drove away investors.”23 Many erstwhile Netflix customers and advocates quickly switched camps, becoming vociferous detractors and taking their frustration to Twitter, Facebook, and other social media channels. “Netflix sucks” videos appeared on YouTube.24 By the time the bleeding stopped, the company had lost more than 800,000 customers and enormous goodwill.25 According to some estimates, Twitter alone was responsible for more than 10 percent of the decline in the Netflix stock price. After a halfhearted Hastings’s apology,26 Netflix reversed course and nixed Qwikster. As of this writing, the stock has partially recovered, and many users have returned.27
From a Big Data standpoint, the Netflix fiasco is particularly instructive. Even in a Twitter-free world, it’s likely that Netflix still would have suffered from its gaffe. That is, Twitter didn’t “cause” Netflix to lose half of its value. If anything, Twitter and Facebook served as accelerants. Fundamentally, Qwikster was a bad business decision, and social media sites only intensified the anti-Netflix momentum. For our purposes, Big Data made a bad situation much worse for Netflix. The lesson here: those who only see the upsides of Big Data would do well to keep that in mind. Perhaps Big Data is the ultimate frenemy.
Big Data Is Neither Omniscient Nor Precise
In a sense, Big Data changes nothing. While it may increase our ability to spot trends, it certainly will not let us consistently and accurately predict the future. Even in a Big Data world, we will still have to live with varying degrees of uncertainty. This is true despite—or perhaps because of—the veritable sea of data out there.
The notion that we can only see some events hindsight is the premise behind Black Swan, the 2007 bestseller by Lebanese polymath Nassim Nicholas Taleb. In the book, Taleb explains why we often miss events that should have been completely obvious to us in hindsight. Examples of black swans include 9/11, bestselling books that hit upon a national nerve, and the valuation of individual and groups of stocks. For instance, not that long ago, online grocer WebVan was once famously “worth” $1.2 billion during the height of the dot-com bubble.28 In hindsight, that entire period was the acme of irrational exuberance.
Perhaps the most salient recent example of a black swan is the subprime housing meltdown and subsequent Great Recession. Here, Taleb’s background is particularly instructive. Taleb was no academic—at least, not entirely. For years before the market imploded, he put his Black Swan Theory into practice in the stock market. That is, he walked the talk. Taleb was so convinced that the mortgage bubble would explode that he based his entire investment strategy on it, ultimately making a fortune when most investment bankers were losing their shirts. While rare, Taleb’s contrarian beliefs weren’t completely flying under the radar ten years ago. Malcolm Gladwell wrote an article on Taleb and his investment philosophy in 2002 for The New Yorker,29 five years before Black Swan was published.
Nor was Taleb alone in raising a red flag about the housing market years ago. While comparatively few, others also predicted the financial turmoil that erupted in 2008. (Predicting that it would happen is hardly the same as predicting precisely when it would happen.) In The Big Short: Inside the Doomsday Machine, Michael Lewis introduces us to some of these colorful characters, including Dr. Michael Burry, a one-eyed neurologist with Asperger’s syndrome. Convinced of the irrationality of the stock market, Burry started a blog, more as a hobby than anything else. He quickly and unexpectedly gained a devoted following and received several offers to manage a good deal of others’ money. Eventually, Burry left neurology and started Scion Capital. He bet heavily against subprime mortgages. While Lehman Brothers and Bear Stearns were collapsing, Burry was on his way to earning a personal profit of $100 million and more than $700 million for Scion investors.30
Were there signals to the debacle? Of course, but the consequences were still nothing short of devastating. The larger point: even in a Big Data world, plenty of activity (both disturbing and surprisingly good) will continue to lie beneath the surface. Plenty of things will remain virtually undetected by people and parties that ought to know better.
Big Data Is Generally Wide, Not Long
Go into any table in a relational database management system (RDBMS), an application that stores structured enterprise data that techies like me often call the back end. You’ll almost always see structured data with many rows and relatively few columns. For instance, let’s consider a table with employee information. In the table, you’ll find key fields like employee number, first name, last name, social security number (hopefully not the same as the employee number), and tax information. Occasionally vendors will update their software to include new fields, like employee e-mail address. For the most part, though, new fields or columns are added infrequently. Contrast that with new rows. They are constantly added for one simple reason: companies hire employees on a regular basis. Each new employee represents a row in the employee table. For this reason, tables in ERP and CRM systems tend to be long, not wide. (I have worked with employee timekeeping tables in excess of 35 million records. Even those aren’t terribly big, especially by today’s standards.)
Big Data is very different for technical storage and retrieval reasons that are well beyond the scope of this book.47 Suffice it to say that Big Data has given rise to a new breed of databases that have very little to do with “rows” and Structured Query Language.
Columnar databases (discussed in more detail in Chapter 4) are the antitheses of their row-based counterparts. Because they are more wide than long, they are arguably better suited for Big Data. We’ll come back to that, though.
Big Data Is Dynamic and Largely Unpredictable
Why did Facebook agree to buy Instagram in April 2012 for more than $1 billion in cash and stock? The reason sure wasn’t accretive. Not only did Instagram lack profits; it lacked any proper revenue. Was Instagram “the best” or even the only photo-sharing app? Had it pioneered amazing technology that Facebook couldn’t replicate? Again, the answers are no. So what was Mark Zuckerberg thinking?
It was all about the app’s popularity and existing user base. Instagram had become the de facto standard for mobile photo sharing. Before the acquisition, Instagram “had reached nearly 30 million registered users before it launched an Android app, a turbo-charging event for the company.”31
And Instagram was not the only app to suddenly burst onto the scene. Even über-smart Steve Jobs could never have predicted that Angry Birds would have been downloaded more than one billion times.32 If venture capitalists (VCs) are so smart, why didn’t they make a deal with Pebble Watch CEO Eric Migicovsky before his product raised more than $10 million on Kickstarter?33 His company’s initial goal: a mere $100,000.
The main point is that today business is inherently unpredictable and, thanks to the rapid change engendered by technology, more unpredictable than ever. Much like YouTube videos or Internet memes, today apps can quickly go viral. New sites like Pinterest are taking off in very little time—and generating new data sources. Existing sites, companies, and web services suddenly spike, and generate even more data. Social commerce sites like The Fancy and Fab.com don’t even attempt to predict sales of any given product. There’s no central planner at Etsy. The CEOs of these companies don’t even know all the products they’ll be selling or featuring next month, never mind next year. There may be wisdom in crowds, but no one knows for certain what that wisdom will be.
Big Data Is Largely Consumer Driven
In my previous two books, I’ve written about the consumerization of IT. It’s nothing less than a game-changer and certainly warrants a mention here. In a nutshell, this isn’t 1995 anymore. Back then, the majority of people used technology exclusively at their desktops while working. Sure, there were tech aficionados like yours truly, but we were the exceptions to the rule.
Now that smartphones are becoming pervasive and e-readers and tablets are getting there, technology is everywhere—and not just for adults. Slate reports, “Two San Antonio, Texas schools have joined others in Houston and Austin in requiring students to wear cards with radio-frequency identification (RFID) chips embedded in them, allowing administrators to track their whereabouts on campus.”34 Pebble Watch (mentioned in the previous section) is yet another example of wearable technology.
Ubiquitous technology means that many IT departments are in effect throwing in the towel. They have given up trying to mandate the devices their own employees can and can’t use while on the clock, a movement termed bring your own device (BYOD). Think that this is just a private sector trend? Think again. Count federal agencies in the mix as well.35
One of the consequences of the consumerization of IT is that we are constantly generating, accessing, and consuming data. Big Data is a direct consequence of ubiquitous technology and near-constant connectivity. A company may block access to Facebook, Twitter, or other “unproductive” sites on its network via a service like Websense, but that means almost nothing anymore. Employees simply take out their smartphones and go to these forbidden sites. This is BYOD in action. I don’t know of any enterprise that can entirely prevent its employees from pinning photos on Pinterest, watching YouTube videos, updating Facebook, or tweeting. And venting over your boss during lunch is small potatoes compared to the increasing trend of employee data theft. “Personally owned mobile devices are increasingly being used to access employers’ systems and cloud-hosted data, both via browser-based and native mobile applications,” said John Yeoh, research analyst at Cloud Security Alliance. “This, without a doubt, is a tremendous concern for enterprises worldwide.”36
Enterprises still generate and consume quite a bit of data but, unlike twenty years ago, they are not the only game in town. Consumers are anything but passive bystanders these days; the term citizen journalist developed for a reason. I’d argue that consumers are driving Big Data more than traditional organizations, although the latter can stand to reap most Big Data benefits.
Big Data Is External and “Unmanageable” in the Traditional Sense
Data governance, master data management (MDM), quality, and stewardship all fall under the general umbrella of data management, an intentionally broad and fairly generic term. Data management implies that organizations actively manage their data (i.e., data that exists within their own internal systems, applications, and databases). What’s more, an organization’s employees for the most part generate, access, and ultimately control this data. This is true even if a company “rents” its applications. For example, perhaps it uses a SaaS customer relationship management (CRM) application such as Salesforce.com. For this reason, a company can go live with its new application in a relatively short period of time, especially compared with traditional on-premise applications requiring hardware purchases, configurations, and probably customizations. Note, however, that such an application will have limited use if it’s loaded with suspect, duplicate, or incomplete information.
Now, to be sure, an organization can manually import external data into its existing systems or automatically build a bridge. Companies like Twitter encourage the latter via making their application programming interfaces (APIs) open for others. However, it would be misleading to think about “managing” Big Data, at least as organizations have traditionally tried to manage Small Data. For instance, adding a duplicate employee, vendor, product, or customer into an enterprise system can cause some thorny problems. I can’t think of any enterprise system that doesn’t provide at least some safeguards against this type of thing. If Jeanette in HR somehow adds a duplicate record for Jordan, an existing employee, at some point the organization will have to purge one record and consolidate the information concurrently split between two different employee numbers. (In point of fact, the organization may use an MDM solution to further minimize the chance that this occurs in the first place.) The same thing can be said for a duplicate customer, vendor, or product code. (Duplicate paychecks, sales, and invoices often cause major data management headaches.) Small Data needs to be actively managed and kept as pure as possible.
Contrast the need for a master record—and, more generally, “data perfection”—with Big Data. I might tweet the same 140 characters five times about my dissatisfaction with my cable company, Cox Communications. Employees at Cox can ignore my tweets, but they can’t delete or manage them, at least in the traditional sense. (No one can delete my tweets but Twitter and me; and besides me, only Google can yank my videos from YouTube.) Rather, the fact that I’ve vented over Twitter about the same issue multiple times should signal to Cox’s customer service department that I’m not a happy camper—and someone should step in. In fact, I might be angrier than a customer who has tweeted only once or not at all.
Big Data Is Inherently Incomplete
Yes, Big Data is enormous, but don’t for a minute think that there’s such a thing as a “complete” set of data anywhere. Far from it. Even mighty Google cannot index the entire web—and not for want of trying. Although Google’s mission is “to organize the world’s information and make it universally accessible and useful,” it will never completely succeed. Standard search engines can only index the Surface Web, not the much larger Deep Web. The former is just the tip of the iceberg.
So we know that Google’s algorithm lacks many sources of information and content, but what percentage of data is Google missing? Phrased a bit differently, what percentage of all content on the Internet is on the Surface Web—and, by extension, not available to search engines? While impossible to precisely quantify, some estimates put that number at 96 percent.37 Figure 2.2 provides more estimates about what even the best search engines cannot index.

And it’s not as if search engines like Google can index even the entire Surface Web. An incredible amount of web traffic eludes even the world’s best search engines. Imagine how much more powerful Google would be if its software could crawl and index currently hidden content like
- Text and instant messages.
- Dynamic or scripted content.
- Unlinked content (i.e., pages to which other pages do not link). This omission can prevent web crawling programs from accessing the content.
- Password-protected websites.
- Videos specifically hidden from the search engines, a feature extremely easy to do on sites like Vimeo.
- Content in private e-mails. (While Google can mine text in Gmail, that information only serves to provide more relevant ads. You can’t Google “Who e-mailed Phil in Spanish today?”)
- Absent some type of hack, proprietary and private corporate information, networks, and intranets.
- Absent some type of hack, personal health and financial information.
- Physical documents not put online.
- Uncensored photos that StreetView could collect except for laws prohibiting the company from doing so (e.g., the European Union).38
- Content on closed, personal social networks managed through Yammer, Ning, and others.
- Content on private and membership-based sites such as LexisNexis.
- Content on sites behind pay walls like the Wall Street Journal and New York Times.
And let’s not forget another 800-pound gorilla. Much to Google’s chagrin, Facebook’s data lies behind a walled garden—and this is anything but an accident. (Of course, Facebook will open that garden to advertisers who are willing to pay for information, although COO Sheryl Sandberg insists that, like Google, her company does not sell or rent uniquely identifiable user information to anyone or any company.39) While it hasn’t always taken privacy seriously as a company, Facebook has always done one thing exceptionally well: kept its vast trove of user-provided information away from Google, something that annoys CEO Larry Page.
Bottom line: nothing even remotely close to a single repository or amalgamation of Big Data exists. I’m no sorcerer, but it’s hard to see such a data store coming in the foreseeable future. While an organization may—and should—manage customer master data in one central place, it cannot do the same with respect to Big Data. For potent Big Data solutions discussed in Chapter 4 to handle photos, analyze videos,40 and the like, one precondition must be met: the data must be accessible in the first place.
Big Overlap: Big Data, Business Intelligence, and Data Mining
Business intelligence (BI) has been with us for a while. By way of background, IBM researcher Hans Peter Luhn originally used the term business intelligence in a 1958 article, defining it as “the ability to apprehend the interrelationships of presented facts in such a way as to guide action towards a desired goal.”41
More than three decades later, BI applications finally rose to prominence. During the mid-1990s, many organizations finally implemented expensive CRM and ERP systems like Oracle, PeopleSoft, Siebel, and SAP. Post-implementation, a fundamental and important problem remained: while those vendors’ relational database applications excelled at getting data into systems, they weren’t designed to get that same data out. Many end users found that vendor-provided standard reports and ad hoc query tools just didn’t cut it. Organizations found that they needed separate, more powerful applications to interpret and analyze the massive amounts of data now available to them on customers, employees, financial transactions, and the like. Early BI vendors like Hyperion, MicroStrategy, and Canadian giant Cognos (acquired by IBM in January 200842) provided such functionality.
Some people view Big Data as merely another name for business intelligence. It’s not. To be sure, the two concepts are not completely different and even share the same ultimate business objective: to derive value from information. The key difference between Big Data and traditional BI applications boils down to the type of data that each is equipped to handle. Traditional BI tools cannot effectively handle largely unstructured and semi-structured information that comprises Big Data. That is, at a high level, most BI applications allow organizations to make sense out of their structured data. For their part, most prominent Big Data solutions are designed to handle all types of data, including unstructured and semi-structured data. This does not mean that one set of tools is inherently “better” than the other. To be sure, online analytical processing (OLAP) cubes loaded with sales data can provide extremely valuable insights into customer behavior. Just don’t try to load those same cubes with photos, videos, blog posts, call detail records (CDRs), and tweets and then expect them to spit out meaningful results. Conversely, Big Data solutions can handle structured data as well, as we’ll see in Chapter 4. Hybrid solutions are currently being developed and improved. The goal here: to allow organizations to theoretically manage every type and source of data in one place. Be that as it may, most organizations won’t be replacing their best-of-breed BI applications anytime soon.
At this point, it’s fair to ask about the relationship between Big Data and data mining, the latter of which many organizations have used for years. Perhaps the most famous data mining case study involves Harrah’s Entertainment and came from the Harvard Business Review.49 CEO Gary Loveman wrote about how, in the early 2000s, Harrah’s used sophisticated data mining techniques to target current and would-be customers very effectively.43 (Some would argue too effectively, like the folks at Gamblers Anonymous. Many gambling addicts were trying to quit, only to be lured back to the tables by remarkably enticing offers in the mail.)
For reasons that will become more apparent in Chapter 4, things are a little bit different now. That is, traditional data mining tools have largely attempted to harness value from large amounts of Small Data—and mostly the structured kind at that. They have largely ignored unstructured and semi-structured information, an increasing part of what we now call Big Data. (Big Data even 15 years ago just wasn’t as big, and it certainly wasn’t nearly as important as it is in 2013.) Put differently, historically people have used data mining software on much smaller, more orderly datasets than the unstructured ones of today. Now, at the time, those datasets were considered very large. (It’s all relative, right?) In a similar vein, the best computers of 2002 came with then-unprecedented power and speed. In each case, things have changed.
So what is the impact of Big Data on data mining? Data mining tools are expanding and evolving because, quite simply, data itself has expanded and evolved. Big Data is forcing many longstanding data mining solutions to either adapt or perish. For example, IBM’s Intelligent Miner, Microsoft’s Analysis Services, and SAS’s Enterprise Miner all become less and less relevant if they can only handle a decreasing percentage of available data (i.e., the structured kind). This goes double if other applications can effectively handle Big Data. As we’ll see in Chapter 4, newer solutions like Hadoop, columnar databases, and NoSQL can more quickly and efficiently handle all—or at least many more—types, sources, and amounts of data (especially compared to RDBMs). As Big Data moves to the right of the Technology Adoption Life Cycle, the popularity of these newer Big Data solutions will only increase—especially the less expensive open-source variety.
Perhaps we’ll begin hearing more about Data Mining 2.0 (yes, the term is already out there44). New data mining solutions must incorporate very different types of data—and lots of it. They will allow users to find more and different patterns in increasingly larger datasets. They will help people understand more about what’s actually going on and why. Ultimately, expect better predictions.
Big Data Is Democratic
There’s another big difference between Big Data and early BI efforts. Early BI efforts were almost exclusively the purview of fairly large enterprises. As any CIO will tell you, predecessors to cloud computing like application service providers (ASPs) in 2000 certainly weren’t cheap. Further, relatively few small companies purchased and implemented BI software. Financial firms were often notable exceptions to this rule in large part because the stakes were so high. A 30-employee hedge fund with $1 billion under management might decide that the benefits of BI more than covered its not inconsiderable costs.
Of course, current-day BI solutions are nothing like their expensive mid-1990s counterparts. (What technology has remained constant?) Today, the cloud has taken hold, and BI/Big Data start-ups like SiSense, Birst, iJento, and Pentaho are taking affordable BI to the masses. Each has raised millions of dollars in VC funding.
By contrast, Big Data finds itself born into a much more open, cost-effective era. The prevalence of free and open-source software like Hadoop and NoSQL (discussed extensively in Chapter 4), open APIs and datasets, and the like, only collectively underscore the fact that Big Data is inherently more democratic than many embryonic technologies over the past twenty years. It’s important to note, however, that one shouldn’t confuse free speech with free beer, as open-source folks like to say. (Showing off my Latin, gratis is not the same as libre.) Yes, open-source Big Data solutions like Hadoop may not require purchasing a formal license. However, this does not negate other related costs such as hardware (potentially), consulting, and employee training and salaries.
THE ANTI-DEFINITION: WHAT BIG DATA IS NOT
Having come full circle, now it’s time to return to the quote at the beginning of the chapter. If you think of Big Data as you would obscenity or pornography, the term may well be best defined against its inverse (i.e., that which it is not). In that vein, consider the following definition of Big Data from The Register:45
Big Data is any data that doesn’t fit well into tables and that generally responds poorly to manipulation by Structured Query Language (SQL).
[T]he most important feature of Big Data is its structure, with different classes of Big Data having very different structures.
With that definition, let’s consider some examples. Data from a Twitter feed is Big Data, but the census isn’t. Images, CDRs from telecoms companies, web logs, social data, and RFID output can all be Big Data. Lists of customers, employees, and products are not. At a high level, Big Data doesn’t fit well into traditional database tables.
Is this “no SQL” definition a bit too technical for most folks? It sure is, and, while instructive, even that one is hardly perfect. I’m not the most technical person in the world, but it doesn’t take a data scientist or rocket scientist to populate a spreadsheet, database table, or flat file with basic Twitter data and metadata. Such a table would include handle, time and date of tweet, tweet, and hashtags. As a general rule, though, traditional data management tools cannot truly harness the power of Big Data. Forget stalwarts like Microsoft Excel and Access; even expensive traditional relational databases just don’t cut it.
While we’re on the subject of tools, Big Data is about so much more than merely buying, downloading, and deploying a new application or program. Yes, Big Data requires new tools like Hadoop and sentiment analysis. But, more important, Big Data necessitates a new mind-set. Regardless of your own personal definition of the term, don’t make the mistake of assuming that heretofore methods and applications are sufficient.
SUMMARY
This chapter demystified the term Big Data and described many of its characteristics. Among other things, we learned that Big Data differs from Small Data in terms of the tools required to access it, not to mention the types, sources, and amounts of data associated with it. Now that we have garnered a much more complete understanding of Big Data, it’s time to go deeper. Chapters 3 and 4 examine the specific elements that comprise Big Data and look at some of the major solutions being used to operationalize it, respectively.
NOTES
1. Laney, Doug, “3D Data Management: Controlling Data Volume, Velocity, and Variety,” February 6, 2001, http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf, retrieved December 11, 2012.
2. “What Is Big Data?,” www.-01.ibm.com/software/data/bigdata, retrieved December 11, 2012.
3. Gogia, Sanchit, “The Big Deal About Big Data for Customer Engagement,” June 1, 2012, www.forrester.com/The+Big+Deal+About+Big+Data+For+Customer+Engagement/fulltext/-/E-RES72241, retrieved December 11, 2012.
4. www.google.com/trends/explore#q=big+data, retrieved December 11, 2012.
5. Talmadge, Candace, “Big Data May Transform Election Day Ground Game,” November 3, 2012, www.politicususa.com/big-data-transform-election-day-ground-game.html, retrieved December 11, 2012.
6. Farr, Christina, “Election 2012 Is Big-Data Nerds’ Gut Punch to Traditional Punditry,” November 7, 2012, http://venturebeat.com/2012/11/07/big-data-brigade/, retrieved December 11, 2012.
7. Scherer, Michael, “Inside the Secret World of the Data Crunchers Who Helped Obama Win,” November 7, 2012, http://swampland.time.com/2012/11/07/inside-the-secret-world-of-quants-and-data-crunchers-who-helped-obama-win/, retrieved December 11, 2012.
8. Wyler, Grace, “Republicans Have an Enormous Tech Problem, and It Could Kill Them in 2016,” November 26, 2012, www.businessinsider.com/republicans-tech-data-orca-obama-election-2012-11#ixzz2CmC8qVLE, retrieved December 11, 2012.
9. Henschen, Doug, “How Gallo Brings Analytics into the Winemaking Craft,” September 12, 2012, www.informationweek.com/global-cio/interviews/how-gallo-brings-analytics-into-the-wine/240006776, retrieved December 11, 2012.
10. O’Brien, Jeffrey M., “The Vine Nerds,” October 21, 2012, www.wired.com/wiredscience/2012/10/mf-fruition-sciences-winemakers/, retrieved December 11, 2012.
11. “Increasing Research Efficiency: Case Study for Big Data and Healthcare,” October 18, 2012, www.brightplanet.com/2012/10/increasing-research-efficiency-case-study-for-big-data-and-healthcare/, retrieved December 11, 2012.
12. Brynjolfsson, Erik; McAffe, Andrew, “The Big Data Boom Is the Innovation Story of Our Time,” November 21, 2011, www.theatlantic.com/business/archive/2011/11/the-big-data-boom-is-the-innovation-story-of-our-time/248215/, retrieved December 11, 2012.
13. Simon, Phil, “A Retail BI Case Study,” August 2, 2012, www.philsimon.com/blog/emerging-tech/bi/a-retail-bi-case-study/, retrieved December 11, 2012.
14. Hyatt, Wesley, Television’s Top 100 (Jefferson, NC, and London: McFarland, 2012).
15. Bibel, Sara, “‘CSI: Crime Scene Investigation’ Is the Most-Watched Show in the World,” June 14, 2012, http://tvbythenumbers.zap2it.com/2012/06/14/csi-crime-scene-investigation-is-the-most-watched-show-in-the-world-2/138212/, retrieved December 11, 2012.
16. Hipes, Patrick, “Top Super Bowl Ad Goes for $4 Million as NBC Inventory Sells Out,” January 3, 2012, www.deadline.com/2012/01/top-super-bowl-ad-goes-for-4m-as-inventory-sells-out/, retrieved December 11, 2012.
17. Geere, Duncan, “It’s Not Just You: 71 Percent of Tweets Are Ignored,” October 11, 2010, www.wired.com/business/2010/10/its-not-just-you-71-percent-of-tweets-are-ignored/, retrieved December 11, 2012.
18. Laden, Greg, “What Is Dunbar’s Number?,” June 10, 2012, http://scienceblogs.com/gregladen/2012/06/10/what-is-dunbars-number/, retrieved December 11, 2012.
19. Jarboe, Greg, “60 Hours of Video Is Now Uploaded to YouTube Every Minute,” February 2012, www.reelseo.com/60-hours-video-uploaded-to-youtube-minute/, retrieved December 11, 2012.
20. Spenner, Patrick, “Beware the Big Data Hype,” November 9, 2011, www.forbes.com/sites/patrickspenner/2011/11/09/beware-the-big-data-hype/, retrieved December 11, 2012.
21. Harris, Derrick, “Netflix Analyzes a Lot of Data About Your Viewing Habits,” June 14, 2012, http://gigaom.com/cloud/netflix-analyzes-a-lot-of-data-about-your-viewing-habits/, retrieved December 11, 2012.
22. Ibid.
23. Grover, Ronald; Nazareth, Rita; Edwards, Cliff, “Netflix Gets 57% Cheaper for Amazon-to-Google Acquirer: Real M&A,” September 26, 2011, www.bloomberg.com/news/2011-09-26/netflix-proves-57-less-expensive-for-amazon-to-google-acquirers-real-m-a.html, retrieved December 11, 2012.
24. YouTube user “yourwiseguy,” “Netflix Sucks!,” July 15, 2011, www.youtube.com/watch?v=Sa6Iod9pr-8, retrieved December 11, 2012.
25. Wingfield, Nick; Stelter, Brian, “How Netflix Lost 800,000 Members, and Good Will,” October 24, 2011, www.nytimes.com/2011/10/25/technology/netflix-lost-800000-members-with-price-rise-and-split-plan.html?pagewanted=all&_r=0, retrieved December 11, 2012.
26. Hastings, Reed, “An Explanation and Some Reflections,” September 18, 2011, http://blog.netflix.com/2011/09/explanation-and-some-reflections.html, retrieved December 11, 2012.
27. Gilbert, Jason, “Netflix Users Returning, Subscriptions Rebounding As Customers Forgive ‘Qwikster’ Debacle,” May 18, 2012, www.huffingtonpost.com/2012/05/18/netflix-users-subscriptions-rebound-qwikster_n_1527290.html, retrieved December 11, 2012.
28. Goldman, David, “10 Big Dot.Com Flops,” March 10, 2010, http://money.cnn.com/galleries/2010/technology/1003/gallery.dot_com_busts/2.html, retrieved December 11, 2012.
29. Gladwell, Malcom, “Blowing Up How Nassim Talep Turned the Inevitability of Disaster into an Investment Strategy.,” April 22 & 29, 2002, www.gladwell.com/2002/2002_04_29_a_blowingup.htm, retrieved December 11, 2012.
30. Lewis, Michael, “Betting on the Blind Side,” April 2010, www.vanityfair.com/business/features/2010/04/wall-street-excerpt-201004, retrieved December 11, 2012.
31. Malik, Om, “Here Is Why Facebook Bought Instagram,” April 9, 2012, http://gigaom.com/2012/04/09/here-is-why-did-facebook-bought-instagram/, retrieved December 11, 2012.
32. Kersey, Ben, “Angry Birds Reaches One Billion Downloads,” May 9, 2012, www.slashgear.com/angry-birds-reaches-one-billion-downloads-09227363/, retrieved December 11, 2012.
33. “Pebble: E-Paper Watch for iPhone and Android,” Launched April 11, 2012 Project fully funded May 18, 2012, www.kickstarter.com/projects/597507018/pebble-e-paper-watch-for-iphone-and-android, retrieved December 11, 2012.
34. Oremus, Will, “Texas Schools Are Forcing Kids to Wear RFID Chips. Is That a Privacy Invasion?,” October 11, 2012, www.slate.com/blogs/future_tense/2012/10/11/rfid_tracking_texas_schools_force_kids_to_wear_electronic_chips.html, retrieved December 11, 2012.
35. “Bring Your Own Device,” April 23, 2012, www.whitehouse.gov/digitalgov/bring-your-own-device, retrieved December 11, 2012.
36. Dale, Jonathan, “Data Loss, Insecure Networks Among Enterprises’ Biggest Mobile Concerns,” October 8, 2012, www.maas360.com/news/industry-news/2012/10/data-loss-insecure-networks-among-enterprises-biggest-mobile-concerns-800881059/, retrieved December 11, 2012.
37. Henry, Rebecca, “INFOGRAPHIC: Exploring the Deep Web with Semantic Search,” September 18, 2012, http://inventionmachine.com/the-Invention-Machine-Blog/bid/90626/INFOGRAPHIC-Exploring-the-Deep-Web-with-Semantic-Search, retrieved December 11, 2012.
38. Blake, Heidi, “Google’s EU Warning Over Street View Privacy,” February 26, 2010, www.telegraph.co.uk/news/worldnews/europe/7322309/Googles-EU-warning-over-Street-View-privacy.html, retrieved December 11, 2012.
39. Goodwin, Danny, “Google to Talk Privacy Policy in Private with Congress,” February 1, 2012, http://searchenginewatch.com/article/2143109/Google-to-Talk-Privacy-Policy-in-Private-with-Congress, retrieved December 11, 2012.
40. “Hadoop and Big Data,” copyright 2012 Cloudera, Inc, www.cloudera.com/what-is-hadoop/hadoop-overview/, retrieved December 11, 2012.
41. IBM Journal of Research and Development, www.research.ibm.com/journal/rd/024/ibmrd0204H.pdf, retrieved December 11, 2012.
42. “IBM Completes Acquisition of Cognos,” January 31, 2008, www.-03.ibm.com/press/us/en/pressrelease/23423.wss, retrieved December 11, 2012.
43. Loveman, Gary, “Diamonds in the Data Mine,” May 2003, http://faculty.unlv.edu/wrewar_emba/WebContent/Loveman_DataMining.pdf, retrieved December 11, 2012.
44. Lee, Thomas, “Data Mining 2.0,” October 11, 2009, www.startribune.com/business/63905422.html?refer=y, retrieved December 11, 2012.
45. Whitehorn, Mark, “Big Data Bites Back: How to Handle Those Unwieldy Digits When You Can’t Just Cram It into Tables,” August 27, 2012, www.theregister.co.uk/2012/08/27/how_did_big_data_get_so_big/, retrieved December 11, 2012.
46. The Olympics takes place every four years but, because of its duration, it cannot command the same number of eyeballs—at least in a concentrated period of time.
47. If you’re curious about the technical reasons, see www.tinyurl.com/mcknight-columnar.
48. Also called the Deepnet, the Invisible Web, the Undernet, or the hidden Web.
49. See http://hbr.org/product/gary-loveman-and-harrah-s-entertainment/an/OB45-PDF-ENG.