CHAPTER 5
Case Studies: The Big Rewards of Big Data
A problem well defined is a problem half-solved.
—John Dewey
Up to this point, we’ve defined Big Data and its elements. We then described many of the technologies that organizations are using to harness its value. Now it’s time to see some of these technologies in action. This chapter examines three organizations in depth, exploring how they have successfully deployed Big Data tools and seen amazing results. Let’s start with a company that makes handling Big Data its raison-d’etre.
QUANTCAST: A SMALL BIG DATA COMPANY
How do advertisers reach their target audiences online? It’s a simple question with anything but a simple answer. Traditionally, advertisers reached audiences via television based on demographic targeting. As discussed in Chapter 2, thanks to the web, consumers today spend less time watching TV broadcasts and more time in their own personalized media environments (i.e., their own individual blogs, news stories, songs, and videos picked). While good for consumers, this media fragmentation has scattered advertisers’ audiences. Relative to even twenty years ago, it is harder for them to reach large numbers of relevant consumers.
But just as the web lets consumers choose media more selectively, it lets advertisers choose their audiences more selectively. That is, advertisers need not try to re-create the effectiveness of TV advertising; they can surpass it. For example, an hour-long prime-time show on network TV contains nearly 22 minutes of marketing content.1 If advertisers could precisely target consumers, they could achieve the same economics with just a few minutes of commercials. As a result, TV shows could be nearly commercial free. Ads on the web are individually delivered, so decisions on which ad to show to whom can be made one consumer at a time.
Enter Quantcast.
Founded in 2006 by entrepreneurs Konrad Feldman and Paul Sutter, Quantcast is a web measurement and targeting company headquartered in San Francisco, California. Now with 250 employees, Quantcast models marketers’ best prospects and finds similar or lookalike audiences across the world. Connecting advertisers with their best customers certainly isn’t easy, never mind maximizing yield for publishers and delivering relevant experiences for consumers. To do this, Quantcast software must sift through a veritable mountain of data. Each month, it analyzes more than 300 billion observations of media consumption (as of this writing). Today the company’s web visibility is second only to Google. Ultimately, Quantcast attempts to answer some very difficult advertising-related questions—and none of this would be possible without Big Data.
I wanted to know more about how Quantcast specifically uses Big Data, so I asked Jim Kelly, the company’s VP of R&D, and Jag Duggal, its VP of Product Management. Over the course of a few weeks, I spoke with them.
Steps: A Big Evolution
It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is the most adaptable to change.
Charles Darwin
Quantcast understood the importance of Big Data from its inception. The company adopted Hadoop from the get-go but found that its data volumes exceeded Hadoop’s capabilities at the time. Rather than wait for the Hadoop world to catch up (and miss a potentially large business opportunity in the process), Quantcast took Hadoop to the next level. The company created a massive data processing infrastructure that could process more than 20 petabytes of data per day—a volume that is constantly increasing. Quantcast built its own distributed file system (a centerpiece of its current software stack) and made it freely available to the open source community. The Quantcast File System2 (QFS) is a cost-effective alternative to the Hadoop Distributed File System (HDFS) mentioned in Chapter 4. QFS delivers significantly improved performance while consuming 50 percent less disk space.3
In a Big Data world, complacency is a killer. New data sources mean that the days of “set it and forget it” are long gone, and Charles Darwin’s quote is as relevant now as it was 100 years ago. In 2006, like just about every company in the world, Quantcast practically ignored data generated from mobile devices. Most Internet-related data originated from desktops and laptops before iPhone and Droids arrived. Of course, that has certainly changed over the past five years, and Quantcast now incorporates these new and essential data sources into its solutions.4 This willingness and ability to innovate has resulted in some nice press for the company. In February 2010, Fast Company ranked Quantcast forty-sixth on its list of the World’s Most Innovative Companies.5 To this day, the company continues to expand and diversify its analytics products.
From its inception in 2006, Quantcast focused on providing online audience measurement services, a critical part of the advertising industry for both advertisers and publishers. TV and radio stations need to use a mutually agreeable source for determining how many people they are reaching. Companies like Arbitron and Nielsen had provided similar services for radio and TV for decades. These companies used panels of users to extrapolate media consumption across the entire population.
For the most part, these companies’ Small Data approaches consist of simply porting their panel-based approaches to the Internet. As discussed in earlier chapters, Small Data tools and methods typically don’t work well with Big Data, something that Quantcast understood early on. It built a Big Data–friendly system tailored to the web’s unique characteristics. Millions of popular sites, social networks, channels, blogs, and forums permeate the web. Consumption is fragmented, making extrapolating from a panel extremely difficult. Luckily, since each web page is delivered individually to a user panel, such extrapolation is unnecessary. On the web, Quantcast measures the “consumption” of each page directly.
Buy Your Audience
In 2009, Quantcast began development of an “audience-buying” engine. With it, the company could leverage its vast troves of consumer data on online user media consumption. As real-time ad exchanges such as the DoubleClick AdExchange arose, Quantcast quickly got on board. Today, Quantcast is a major player in a market that auctions off billions of ad impressions each day.
In November 2012, Quantcast released Quantcast Advertise. The self-service platform enables advertisers, agencies, and publishers to connect Big Data with discrete brand targets.6 With the right solutions, Big Data allows organizations to drill down and reach very specific audiences. “A flexible compute infrastructure was critical to our ability to produce more accurate audience measurement services. That same infrastructure produced more accurate ad targeting once ad inventory started to be auctioned in real-time,” Duggal told me.
We saw earlier in this book how Amazon, Apple, Facebook, Google, and other progressive companies eat their own dog food. Count Quantcast among the companies that use its own Big Data tools. What’s more, like Google, Quantcast makes some of its own internal Big Data solutions available for free to its customers.7 Quantcast audience segments allow users to understand and showcase any specific audience group for free. Once implemented, these segments appear in users’ full publisher profile on Quantcast.com. As a result, they can better represent their audiences. Figure 5.1 shows some sample data from its Quantified dashboard.
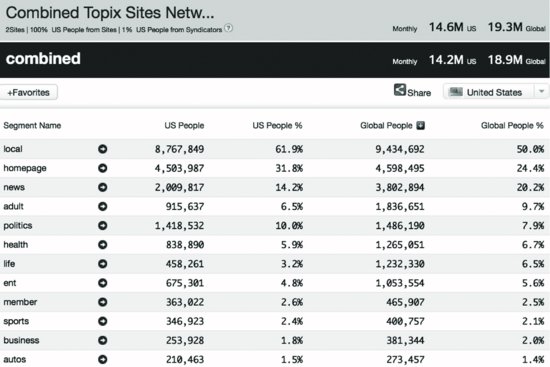
To be sure, “regular” web traffic, click-through, and purchase metrics might be sufficient for some business. However, Quantcast knows that it can’t serve myriad clients across the globe with a mind-set of one size fits all. No one company can possibly predict every Big Data need. Different businesses face vastly different data requirements, challenges, and goals. To that end, Quantcast provides integration between its products and third-party data and applications. What if customers could easily integrate their own data and applications with Quantcast-generated data? What if its clients wanted to conduct A/B testing, support out-of-browser and offline scenarios, and use multiple, concurrent analytic services—without impacting performance?
“Integration is central to everything we’re doing here,” says Kelly. “It’s the source of all the data we work with and the means by which it becomes relevant to the world.” And that advanced integration isn’t stopping anytime soon. Case in point: Quantcast created and offers an API built off the Microsoft Silverlight Analytics Framework.8
Results
Consider the following results from some of Quantcast’s recent customer campaigns:
- A national after-market auto parts retailer relied upon digital advertising to attract new customers and drive online sales. Quantcast built predictive models to convert customers who had actually completed an online purchase, distinguishing between passersby and converting customers. The campaign all but eliminated the majority of superfluous clicks, achieving a return on investment (ROI) greater than 200 percent.
- A major wireless phone company achieved a 76 percent increase in conversion rates above its optimized content-targeted campaign. Quantcast lookalike data allowed lead generation to garner significantly higher conversion rates over content-targeted inventory purchased from the same inventory sources.
- A leading hotelier gained deep insights into the demographic, interests, behaviors, and affinities of its customers. In the process, it ultimately doubled its bookings.
Lessons
Compared to many organizations, Quantcast is a relatively small company. This proves the point that an organization doesn’t need to be big to benefit from—and innovate with—Big Data. There’s no secret sauce, but embracing Big Data from its inception starts a company on the right path. Also, it’s critical to realize that Small Data tools just don’t play nice with Big Data. Understand this, and then spend the time, money, and resources to equip your employees and customers with powerful self-service tools.
EXPLORYS: THE HUMAN CASE FOR BIG DATA
In January 2011, U.S. health care spending reportedly topped $3 trillion.9 That is, more than one in every seven dollars in the U.S. economy is spent on health care. While figures vary, much of that astronomical number stems from behavioral, operational, and clinical waste. Factors here include dated technologies, risk-averse doctors, perverse incentives, administrative inefficiencies, and plain old bad data. A slightly dated PricewaterhouseCoopers report from 2008 titled “The Price of Excess” puts annual health care waste at $1.2 trillion.10 And it gets worse. By some estimates, health care expenditures will grow more than 7.5 percent in 2013,11 two to three times the rate of inflation. In a nutshell, health care in the United States is a complete and unsustainable mess with dire long-term economic implications. As the Chinese say, there is opportunity in chaos—and Big Data is a big part of that opportunity.
As discussed in Chapter 2, Big Data is not an elixir to any problem, much less one as complex and large as health care in the United States. There’s no doubt, though, that it represents a big part of the solution. At a bare minimum, Big Data has the opportunity to profoundly improve the delivery of health care and reduce superfluous expenses.
Having already led a Big Data transformation in other market sectors, in 2009, Stephen McHale, Charlie Lougheed, and Doug Meil recognized the tremendous opportunity in front of them. When they met up with Dr. Anil Jain, MD, cofounder and current Senior VP and Chief Medical Information Officer who had developed breakthrough approaches to traditional database search strategies in clinical informatics at Cleveland Clinic, the four realized that Big Data could have a big impact on health care. That year, in a spinoff deal with Cleveland Clinic, they founded Explorys. Based out of Cleveland, Ohio, today the company employs nearly 100 people.
Explorys’s DataGrid unlocks the power of Big Data by integrating clinical, financial, and operational data to provide superior delivery of care. According to Jain, health care is the perfect sector to leverage a Big Data platform given the volume, variety, and velocity of data that health care systems generate. Moreover, improving health care quality while reducing cost is a noble goal worth pursuing, and their customers are not seeing decreasing cost in traditional data technologies. Over the past three years, they developed a health care Big Data platform that combines real-time collection, secure transport, storage, processing, web services, and apps that are now used by some of the nation’s largest integrated health care delivery networks. Sounds promising, so I tracked down Lougheed (the company’s cofounder and president) and talked to him at length about how Explorys uses Big Data to provide better health outcomes at drastically lower costs.
Better Healthcare through Hadoop
It’s not much of an exaggeration to say that Hadoop accelerated the growth of Explorys. The company built DataGrid, a high-performance computing platform based on Cloudera Enterprise. DataGrid processes an enormous amount of data to provide real-time exploration, performance, and predictive analytics of clinical data. DataGrid users include several of the largest integrated delivery networks in the United States: Cleveland Clinic, MedStar, University Hospitals, St. Joseph Health System, Iowa Health System, Centura Health, Catholic Health Partners, and Summa Health System.
DataGrid provides subsecond ad hoc search across populations, providers, and care venues. Users can also build and view key performance metrics across providers, groups, care venues, and locations that identify ways to improve outcomes and reduce unnecessary costs. Explorys also offers EPM: Engage, an integrated application and framework for coordinating rules-driven registries, prioritized patient and provider outreach, and messaging.
Explorys uses MapReduce to process, organize, and curate large batches of incoming data very quickly into HDFS and HBase. Data sources include HL7,21 claims data, and third-party feeds from electronic health record (EHR) providers such as Epic, Eclipsys, Microsoft Amalga, McKesson, Meditech, and Cerner. Explorys developed proprietary engines that take that data and materialize it into structures that can be rapidly accessed and analyzed via off-the-shelf tools or custom-built applications. Those applications then send the data back into the Explorys platform for other processing needs. Analytics powered by Hadoop (among other technologies) facilitate clinical quality measure generation, measure calculations for registries, manage proactive care, and perform other critical tasks.
Explorys uses Hadoop-powered analytics for a variety of purposes. For example, to better serve its community, a county hospital might want to explore why people go to the emergency room (ER) rather than a primary physician for nonemergency care. This practice is hardly ideal. It is expensive for the hospital and the patient. What’s more, patients here are starting from scratch. They don’t receive the continuity of care that a primary physician would provide.
Twenty years ago, one would be limited to analyzing the hospital’s ER record system and manually attempting to cull data from disparate sources. Even then, the true answer would prove elusive. With the support of a Hadoop infrastructure, Explorys’s customers can easily analyze the demographics of a given population, their past medical history, their patient locations, and whether or not care is available in their neighborhoods. Rather than having to run reports, Explorys provides these analytics daily and automatically. In the end, decision-makers can take immediate action. Providers and care coordinators can reach out to patients over secure methods to guide them through their treatment processes. What happens when patients receive the right care at the right venues at the right time? The quality of patients’ overall care increases, while superfluous costs disappear.
This type of proactive health care just isn’t feasible when clinical information is stored among a bevy of relational databases or traditional data warehouses. Organizations that try to retrofit Big Data into old tools will quickly find themselves frustrated. For instance, let’s say that a hospital crams petabytes of unstructured clinical data into relational database management systems (RDBMSs). Health care practitioners who understand something specific about a population or segment of data will have to go to their IT departments and then wait days or weeks for that information. “We wanted to provide a platform that would give them an answer as fast as if they were searching on Google, but at the same time in a way that respects HIPAA and privacy concerns,” says McHale.
This is wise. Remember, we live in a self-service age. People are used to finding their own answers. We routinely use Google to answer questions for ourselves. We prefer to fish for ourselves, not wait for IT to return two weeks later with the fish they think we wanted.
Many organizations maintain data silos, and health care providers are some of the worst culprits. (I’ve worked in many a hospital in my consulting career.) Explorys took a vastly different, more integrated approach to data management. Rather than storing and managing clinical, financial, and operational data in three data silos, Explorys consolidated all that data. As Lougheed explained to me, “It’s about merging the three elements and telling a story about how an organization is doing, because ultimately what we want to do is improve health care and do it at a lower cost. With over 17 percent of the nation’s GDP being spent on health care services, we’ve got to find a better way to deliver health care for less.”
The variety of data would also present a challenge. As discussed in Chapter 3, EHRs are finally becoming more prevalent in the United States. “There are more and more devices that generate massive amounts of data. Patients are providing data and feedback on how they’re doing. They have devices in the home that provide data,” says Lougheed. “There’s a ton of data variety coming in, and it’s more than the health care space can really handle with traditional data warehousing.”
Explorys needed to find a cost-efficient technology that would help the company address these Big Data challenges. Hadoop met both of these criteria, and Cloudera stood out to Explorys as the most credible company delivering an enterprise-ready Hadoop solution. McHale, Lougheed, and Meil attended the first Hadoop World conference hosted by Cloudera in 2009. During the conference, the three were sold both on the value of Hadoop and on Cloudera’s ability to deliver. They also appreciated Cloudera’s contingent of on-staff Hadoop Committers. As an early Hadoop adopter, Explorys knew that it would need help in supporting production deployments that would ultimately drive the direction of the technology. “Our platform needed to support the ever-complex world of health care data, not to mention the evolving transformation of the health care delivery system,” says Jain. “It’s clear that we do not know what questions we may be asking of our health care data five years from now. We knew that we needed a solution that [would] grow with us.”
Steps
After deploying the DataGrid platform on CDH (Cloudera’s official distribution of Apache Hadoop), Explorys moved to the Cloudera Enterprise (CE) subscription. CE bundles CDH with Cloudera Support and Cloudera Manager, a software application that delivers visibility into and across Hadoop clusters for streamlined management, monitoring, and provisioning. CE allowed Explorys to continue operating its mission-critical Hadoop environment with a lean staff that could focus on the core competencies of its business. In other words, Explorys shows that Big Data need not require a big staff.
Explorys relies upon CDH to provide the flexibility, scalability, and speed necessary to answer complex questions on the fly. Lougheed believes that the window for analysis would have been 30 days using traditional technologies. With Explorys’s CDH-powered system, that number shrank to seconds or minutes.
Now also an HBase Committer at the Apache Software Foundation, Meil has his own take on things. “We didn’t invent clinical quality measures, but the ability to generate those measures on a rapid basis, support hundreds of them, implement complex attribution logic, and manifest that with a slick user interface on top—that’s revolutionary,” he explains. “Cloudera provides the technology that allows us to address traditional challenges in medicine and in operational reporting with a radical new approach.”
Results
Because Hadoop uses industry standard hardware, the cost-per-terabyte of storage is, on average, ten times cheaper than a traditional relational data warehouse system. “We’d be spending literally millions more dollars than we are today on relational database technologies and licensing,” says Lougheed. “Those technologies are important, but they’re important in their place. For Big Data, analytics, storage, and processing, Hadoop is a perfect solution for us. It has brought opportunities for us to rechannel those funds, that capital, in directions of being more innovative, bringing more products to bear, and ultimately hiring more people for the company as opposed to buying licenses.”
Lougheed summarized, “We were forced to think about a less expensive, more efficient technology from the beginning, and in hindsight, I’m glad that we were. For us—needing storage, high capacity index, and analytics—Hadoop really made a lot of sense. And from a partner perspective, Cloudera is one of the most influential that we’ve had throughout the years.”
Lessons
As discussed in Chapter 4, NoSQL means not only SQL. Explorys uses several open source technologies and has developed many proprietary engines to process data efficiently. Sometimes an organization can get a technology to do something it was not originally designed to do, but results are typically mixed. Sometimes that works well and produces breakthroughs. Other times, you hit the wall, especially given the scale of Big Data. As Explorys has shown, for an organization to successfully leverage Big Data, its engineering teams need to recognize this key tenet. It’s imperative to learn, adapt, and be creative.
NASA: HOW CONTESTS, GAMIFICATION, AND OPEN INNOVATION ENABLE BIG DATA
There’s no doubt that individual private companies like Quantcast and Explorys can devote significant internal resources to Big Data—and reap big rewards in the process. And if relatively small for-profit companies like these can harness the power of Big Data, then surely very large organizations can as well. But what about nonprofits and government agencies? And should an organization develop its own internal Big Data solutions just because it can? In other words, what’s the relationship among Big Data, collaboration, and open innovation? Before answering that question, let’s take a step back.
In 2006 Don Tapscott and Anthony D. Williams wrote Wikinomics: How Mass Collaboration Changes Everything. In the book, the authors discuss the dramatic effects of crowdsourcing on the economy and even the world. The effects of the Internet are impossible to overstate with respect to collaboration and innovation. For instance, Wikipedia isn’t the property of any one individual. It’s effectively run by and for the collective, and its results have been astounding. For instance, in 2005, a study found that Wikipedia is as accurate as Britannica12 despite the fact that, with some notable exceptions, anyone can edit anything at any time.
Fast-forward six years, and many new and mature organizations are realizing the benefits of open innovation, crowdsourcing, and gamification. (Case in point: private funding platforms like Kickstarter and IndieGoGo are redefining business, but that’s a book for another day.) Open innovation is allowing individuals, groups, and even large organizations to accomplish that which they otherwise could not. What’s more, individuals with unorthodox methods are finding unexpected solutions to vexing real-world problems at a fraction of the expected cost. If Wikipedia stems from the unpaid efforts of tens of thousands of unpaid volunteers, imagine what can be accomplished when organizations offer significant monetary prizes for solving big problems.
Open innovation, crowdsourcing, and gamification lend themselves to many areas of business—and Big Data is no exception. Remember from Chapter 2 that Big Data is less about following items on a checklist and more about embracing the unknown. When done right, Big Data is fundamentally exploratory in nature. Crackpot ideas from all corners of the globe may be crazy enough to work (i.e., to find a solution to a vexing problem or discover hidden value in massive datasets).
In Chapter 4, I briefly discussed how Kaggle is using these trends to democratize Big Data. It turns out that Kaggle is hardly alone in understanding how Big Data can benefit from the wisdom of crowds.22 Many people and organizations get it. Count among them the folks at NASA.
Background
NASA, Harvard Business School (HBS), and TopCoder collectively established the NASA Tournament Lab (NTL). Not unlike Kaggle (discussed in Chapter 3), TopCoder brings together a diverse community of software developers, data scientists, and statisticians. It runs contests that seek to produce innovative and efficient solutions for specific real-world challenges.13 For its part, NASA wants to do “space stuff” (i.e., deploy free-flying satellites, conduct planetary missions and laboratory experiments, and observe astronomical phenomena). Like any research institution, HBS is interested in the research potential and field experiment output of these data competitions.
Yes, institutions such as NASA and Harvard have at their disposal myriad human, physical, and financial resources. With a 2012 budget of more than $17 billion,14 organizations don’t get that much larger than NASA. However, with big budgets come big demands. To that end, even large, resource-laden organizations like these are starting to realize the vast benefits of looking outside of the organization to innovate. And this is certainly true with respect to Big Data. NTL is one of many organizations currently running data competitions through TopCoder. The site operationalizes NASA’s challenges, in effect satisfying the needs of both NASA and HBS. TopCoder helps marry problems with problem solvers, and not just for the public sector. “We have many times more nongovernment clients than government ones,” says McKeown. A look at existing TopCoder projects dazzles the mind. For instance, as I write this, the City of Boston is running a risk-prevention contest. Whoever writes the algorithm that best predicts the riskiest locations for major emergencies and crime will receive a share of the $10,000 prize purse.15
Examples
As the Director of Advanced Exploration Systems Division at NASA, Jason Crusan works closely with the TopCoder community to develop contests. In each data contest, smart cookies from across the globe compete with each other to develop innovative and efficient solutions to NASA’s specific real-world challenges—challenges as diverse as image processing solutions to help categorize data from missions to the moon on the types and numbers of craters to specific software required to handle the complex operations of a satellite. Submissions take place right on the TopCoder website. Real-time data tells potential contestants the number of submissions for each contest. Contestants can even comment on the contest via online forums.
Crusan serves as the Director of the Center of Excellence for Collaborative Innovation (CoECI). Established in 2011, CoECI advances the use of open innovation methods across the federal government. A major focus is the use of prizes and challenges. CoECI provides guidance to other federal agencies, and NASA centers on implementing open innovation initiatives, defining problems, designing appropriate incentives, and evaluating post-submission solutions.16 It’s interesting to note that the same TopCoder community conceived of and built both the CoECI and NTL platforms throughout the competition process. As we saw earlier in this chapter with Quantcast, Big Data companies practice what they preach—and TopCoder is no exception to this rule.23 “We eat our own dog food whenever we do anything, internally and for clients,” says Jim McKeown, TopCoder’s Director of Communications.
A Sample Challenge
Over the past thirty years, NASA has recorded more than 100 terabytes of space images, telemetry, models, and more from its planetary missions. NASA stores this data within its planetary data system (PDS) and makes it available to anyone with an Internet connection and sufficient interest.24 That’s all well and good, but what other research, commercial, and educational uses can come from that data? With that amount and variety of data, opinions run the gamut. Rather than put a bunch of employees on the project, NASA decided to run a data contest, presented next.

- A description of the overall idea.
- A description of the target audience (who might be interested in this application?)
- The benefits of the application for the target audience.
- The nature of the application (how should the application be implemented? As a web-based system, on a mobile device, a Facebook application, integrated into Eyes on the Solar System, etc.).
- Which existing PDS data sources are used, and which data sources will need to be created or modified in order for the application idea to function.
- Limitations.
- Any examples of the process flow or the interface behavior of the application. Mock-ups would be a bonus.
- A grand prize of $1,000 will be awarded to the highest-scoring submission as evaluated by the expert panel.
- Up to three $500 prizes will be awarded to additional submissions based on the discretion of the expert panel.
- A $750 community choice award will be awarded to the submission with the highest number of TopCoder community votes based on the voting procedure held at the conclusion of the submission phase.
- T-shirts and stickers to be given to the first 50 distinct submitters who submit ideas that pass basic screening criteria. To be considered for this prize, submissions must contain a valid idea and meet all other criteria outlined within the competition specifications.
In the two weeks that this first contest ran, 212 people registered, and 36 submitted proposals for the contest. The winning entry came from Elena Shutova, a twenty-something woman in Kiev, Ukraine.18 Shutova’s “White Spots Detection” proposal involved creating a database that would determine which areas, parameters, and objects of planetary systems are well researched and what objects are “white spots” (i.e., PDS has little knowledge on them). Shutova also developed a PDS document parser, processor, and validation tool that minimized the manual work required. In the end, NASA employees were able to easily see the data collected, fix it if necessary, and add supplemental record or metadata. Users could then query the database and immediately see the results in the system’s user interface (UI).
Shutova shows the type of innovation and problem solving that can emanate from anywhere on the planet. From NTL’s perspective, $1,000 is a minimal sum of money. At the same time, though, it provides sufficient incentive for creative and intelligent people just about anywhere, especially in developing countries. In the end, everybody wins. Other noteworthy NTL challenges have included vehicle recognition19 and crater detection.20
Lessons
To effectively harness Big Data, Crusan is quick to point out that an organization need not offer big rewards. What’s more, money is not always the biggest driver. In fact, offering too much money may signal the wrong thing (read: it’s too complicated). Crusan has learned that there is no one recipe to follow in pricing data contests. Pricing is more art than science, and many elements should be considered. It turns out that the hardest part of each challenge is not determining which parts of projects NTL should post on TopCoder. “Rather, the real trick is stating the problem in a way that allows a diverse set of potential solvers to apply their knowledge to the problem,” Crusan tells me. “The problem decomposition process by far takes the longest amount of time. However, it’s the critical piece. Without it, it’s impossible to create a compelling Big Data and open innovation challenge.”
SUMMARY
This chapter has demonstrated how three dynamic organizations are embracing Big Data. It has dispelled the myth that only big organizations can use—and benefit from—Big Data. On the contrary, size doesn’t matter. Progressive organizations of all sizes, types, and industries are reaping big rewards. They have realized that Big Data is just too big to ignore.
Chapter 6 will offer some advice for individuals, groups, and organizations thinking about getting on the Big Data train.
NOTES
1. “Average Hour-Long TV Show Is 36% Commercials,” May 7, 2009, www.marketingcharts.com/television/average-hour-long-show-is-36-commercials-9002, retrieved December 11, 2012.
2. “QFS: Quantcast File System,” September 27, 2012, http://quantcast.github.com/qfs/, retrieved December 11, 2012.
3. “Quantcast File System: Bigger Data, Smaller Bills,” 2012, www.quantcast.com/about/quantcast-file-system, retrieved December 11, 2012.
4. “Quantcast Measure: Mobile Web Traffic,” 2012, www.quantcast.com/measurement/mobile-web, retrieved December 11, 2012.
5. Ibid.
6. Mandese, Joe, “Quantcast Unveils Self-Serve Platform: Enables Brands, Publishers to Define Real-Time Audience Segments,” November 15, 2012, www.mediapost.com/publications/article/187358/quantcast-unveils-self-serve-platform-enables-bra.html#ixzz2CqhijD3L, retrieved December 11, 2012.
7. “Quantcast Measure,” 2012, www.quantcast.com/measurement, retrieved December 11, 2012.
8. “Learning Center: Quantcast Silverlight API Guide,” 2012, www.quantcast.com/learning-center/guides/quantcast-silverlight-api-guide/, retrieved December 11, 2012.
9. Munro, Dan, “U.S. Healthcare Hits $3 Trillion,” January 19, 2012, www.forbes.com/sites/danmunro/2012/01/19/u-s-healthcare-hits-3-trillion/, retrieved December 11, 2012.
10. “The Price of Excess: Identifying Waste in Healthcare Spending,” March 14, 2008, http://hc4.us/pwcchart, retrieved December 11, 2012.
11. Morgan, David, “Healthcare Costs to Rise 7.5 Percent in 2013: Report,” May 31, 2012, www.reuters.com/article/2012/05/31/us-usa-healthcare-costs-idUSBRE84U05620120531, retrieved December 11, 2012.
12. Terdiman, Daniel, “Study: Wikipedia as Accurate as Britannica,” December 15, 2005, http://news.cnet.com/2100-1038_3-5997332.html, retrieved December 11, 2012.
13. Keeler, Bill, “Human Exploration and Operations,” November 30, 2011, www.nasa.gov/directorates/heo/ntl/, retrieved December 11, 2012.
14. Berger, Brian, “NASA 2012 Budget Funds JWST, Halves Commercial Spaceflight,” November 18, 2011, www.spacenews.com/article/nasa-2012-budget-funds-jwst-halves-commercial-spaceflight#.ULkjX5IoeMI, retrieved December 11, 2012.
15. “Marathon Match, Contest: HMS Challenge #4,” 2010, http://community.topcoder.com/longcontest/?module=ViewProblemStatement&compid=29272&rd=15458, retrieved December 11, 2012.
16. Lewis, Robert E., “Center of Excellence for Collaborative Innovation,” December 7, 2012, www.nasa.gov/offices/COECI/index.html, retrieved December 11, 2012.
17. “Conceptualization: Planetary Data System Idea Challenge,” April 4, 2011, http://community.topcoder.com/tc?module=ProjectDetail&pj=30016974, retrieved December 11, 2012.
18. “Conceptualization: Planetary Data System Idea Challenge,” April 4, 2011, http://community.topcoder.com/tc?module=ProjectDetail&pj=30016974, retrieved December 11, 2012.
19. “Marathon Match, Contest: Marathon Match 4,” 2010, http://community.topcoder.com/longcontest/?module=ViewProblemStatement&compid=29272&rd=15458, retrieved December 11, 2012.
20. “Marathon Match, Contest: Marathon Match 2,” 2010, http://community.topcoder.com/longcontest/?module=ViewProblemStatement&compid=29272&rd=15459, retrieved November 11, 2012.
21. Health Level Seven International (HL7) is the global authority on standards for interoperability of health information technology, with members in over 55 countries.
22. In his 2004 book The Wisdom of Crowds: Why the Many Are Smarter Than the Few and How Collective Wisdom Shapes Business, Economies, Societies and Nations, James Surowiecki discusses how groups can use information to make decisions that are often better than could have been made by any one member of the group.
23. We’ll see in Chapter 6 how Sears does the same.
24. Anyone can access this data. Just go to http://pds.nasa.gov and knock yourself out.