9
New directions
Thus far we have covered the traditional ground of pragmatics and pragmatic theory. In a ‘slim guide’ such as this one, this is the most important thing: to ensure that the reader will emerge with a solid understanding of the basics of the field, specifically the areas that have emerged over the decades as fundamental and agreed upon as the most important topics and theories. In this chapter, I will very briefly touch on more current issues and research methods in the field of pragmatics. The chapter will begin by comparing traditional research methods with newer ones and will move on to new directions in pragmatic theory.
Research methods
Although linguistics is defined as the scientific study of human language, the field itself has not always been as empirically based as this ‘scientific’ label would suggest. Much early research in linguistics has been based on introspection, with a researcher simply deciding whether a given sentence strikes them as acceptable or not, and basing their theories on that intuition. There are several problems with this method: First, native speakers are notoriously bad at reporting their own linguistic behavior. It’s very common to have a person report that they ‘never use’ a certain expression, and then use it the very next minute, and linguistics researchers are not immune to this problem. I have heard anecdotally of a linguistics researcher using a postverbal definite in an existential while vehemently arguing that that precise use was impossible—unwittingly providing a naturally occurring counterexample to his own claim. In short, just like other language users, linguists themselves are not good judges of their own linguistic behavior, which makes so-called armchair linguistics—in which the researcher bases theoretical claims on nothing more than their own linguistic judgments—a terrible idea. Another reason it’s a terrible idea is that if it’s their own theory that’s at stake (as it usually is in research), a researcher can’t help but be biased in favor of judgments that support the theory. Linguistic judgments can be very subtle, and every linguist knows the phenomenon of being presented with a sentence, thinking hard, and saying, ‘yeah, I can get that as okay’. When the intuitions are subtle, the last thing you want is to have only one person deciding whether to count the sentence as ‘good’ or ‘bad’ and to have that person be the one individual with something to gain or lose by the decision.
So what are the alternatives? One option is to elicit naturally occurring data. William Labov (1972) famously pioneered a naturalistic approach that involved eliciting certain forms from unwitting members of the public. In his landmark study (Labov 1966, 1972), he spoke with workers at three different New York department stores serving three different socioeconomic groups—Saks Fifth Avenue (upper class), Macy’s (middle class), and S. Klein (lower class)—and made a point of speaking with three different relative socioeconomic classes of worker as well—floor walker (upper), cashier (middle), and stock person (lower). He asked each worker about the location of various items, in order to get them to say fourth floor in a natural context so that he could study their enunciation (or lack thereof) of the /r/ in these two words, among other things. He found a pattern of ‘social stratification’ of the pronunciation of these workers—in particular, a significantly higher rate of ‘[r]-drop’ in the lower socioeconomic classes of store and worker. By allowing him to study language as it is actually used, as opposed to the reports of participants on their own language use, Labov was able to show a correlation between phonetic features and socioeconomic status that might not have shown up had he merely asked people how they pronounced certain words. When queried, people are likely to give what they believe to be the ‘right’ (i.e., prescriptively ‘correct’) answers rather than to report accurately on how they actually speak; in fact, they may not even be aware of how they actually speak. The naturalistic approach circumvents both of these problems.
The study of naturally occurring language has become increasingly important in linguistics, especially in pragmatics, where the emphasis on contextually embedded discourse makes it all the more important to have naturally produced examples. It’s one thing to make up a sentence and consider its grammaticality; it’s quite another to invent a longer discourse in order to examine the felicity of an utterance embedded in that discourse, especially given that there are so many variables one could tweak in the surrounding discourse to improve or degrade that felicity. At some point it becomes absolutely necessary to look at real-life language rather than depending on researcher judgments, and in the case of pragmatics, that point tends to come early in the process.
Fortunately, the advent of the digital age has (mostly) spared linguists the need to run from department store to department store eliciting tokens of specific constructions. The field of corpus linguistics looks at large digital compilations of naturally occurring data in order to develop generalizations about language use. There are two great advantages to corpus work: First, and most obviously, the data are produced by nonlinguists, usually with no knowledge that their words will ever be used for a linguistics study, so they are speaking or writing naturally and with no theory at stake. And second, it allows the researcher to look at an enormous number of examples, rather than thinking up a small number of examples on which to base their claims. So even if there happens to be some unrecognized conflating factor that affects the felicity of an utterance in one context, that will be swamped by the other examples in which that factor does not appear. The more examples you’ve got, the less you can be misled by an outlier.
One of the earliest and most widely used corpora was the groundbreaking, million-word Brown Corpus (Kučera and Francis 1967). The Brown Corpus was made up of written data—and by ‘data’ here I mean naturally produced samples of language in use—in fifteen categories (such as various subcategories of fiction, journalism, etc.). Soon thereafter, part-of-speech tags were added to the corpus, to identify the lexical category of each word (noun, verb, etc.). Many other corpora have followed; they have grown enormously in size, and are very frequently tagged for parts of speech. Some corpora include only written data, some only oral data, and some a mix of the two. The Switchboard Corpus (Godfrey et al. 1992), for example, consists of recorded telephone conversations between randomly paired subjects who have been given a topic to talk about. The result is a large corpus of natural conversational data for researchers who want to investigate recorded speech.
Because corpora are stored on computers, they are a common source of data both in the general field of computational linguistics, which uses computational tools to study human language, and in more specific areas like artificial intelligence, natural language processing, speech recognition, and machine translation. Pragmatics research is particularly important in the development of spoken dialog systems, in which users communicate with computer systems using spoken language. (You’ve probably encountered these when calling companies or medical organizations whose phone systems ask you to describe your problem so that their system can route you to the right person.) Spoken dialog systems need to be able to recognize human speech, determine what’s been said, react appropriately, and use synthesized speech to give an appropriate verbal response. Interpretation of spoken language and the development of verbal responses, as well as other appropriate reactions, depend on contextual factors and domain-specific knowledge, and thus on pragmatics.
Computational research into pragmatics frequently uses natural-language corpora, which are particularly valuable for providing the context of an utterance (which is not always available when tokens are caught ‘on the fly’). And because the corpora are searchable, a researcher looking into the use of a particular word, phrase, or construction can often find a large number of tokens with relatively little effort. The Linguistic Data Consortium (https://www.ldc.upenn.edu/) collects corpora in an enormous range of languages and genres, with various types and degrees of syntactic and other tagging. Mark Davies of Brigham Young University has created a group of ten corpora constituting many billions of words (https://corpus.byu.edu/overview.asp) that are freely available for use by linguistics scholars and can be searched for word and phrase frequency and collocations, as well as for collecting tokens for use in studies of specific words, expressions, and constructions. Several of the examples in this book come from the Corpus of Contemporary American English (COCA), one of Davies’ corpora.
Although corpus research is sometimes criticized on the grounds that naturally occurring language includes performance errors—that is, accidental errors in production that do not reflect the speakers’ actual linguistic competence—the use of a large enough corpus can, again, make it possible to distinguish the actual regularities in linguistic usage from occasional ‘noise’ in the data produced by performance errors. Nonetheless, it is wise to use corpus data in combination with native-speaker intuitions in order to reach reliable conclusions about what is and is not acceptable in language use.
One of the most important areas of current pragmatics research is experimental pragmatics, which applies empirical methods to the investigation of pragmatic claims. Early influential research in experimental pragmatics includes, for example, Clark and Lucy’s (1975) reaction-time studies, Gibbs’ work on idioms (e.g., Gibbs 1980), and Clark and Wilkes-Gibbs’ work on common ground and collaboration in discourse (e.g., Clark 1985, Clark and Wilkes-Gibbs 1986). Experimental pragmatics provides a means for empirically addressing the field’s theoretical claims, as with, e.g., Noveck’s (2001) and Chierchia et al.’s (2001) studies of scalar implicature in children, Bezuidenhout and Morris’s (2004) study of the processing of generalized conversational implicatures, and Kaiser and Trueswell’s work on sentence processing and its interactions with word order (2004) and reference resolution (2008), inter alia.
Researchers in experimental pragmatics conduct empirical studies of language production and processing by studying research subjects, often with the use of sophisticated equipment. Studies range in technological sophistication from simple pencil-and-paper questionnaires to fMRI studies measuring brain activity during language production and comprehension; and with increasing technological sophistication come increasingly subtle measurements of linguistic behavior. With an ‘eye-tracker’, for example, researchers can measure extremely small shifts in visual focus to determine how quickly a subject is reading a text or precisely where they are focusing in a visual display while listening to a verbal description of that display. Many of the techniques in experimental pragmatics come from the field of psycholinguistics, and most of them focus on issues of comprehension, such as what a hearer understands an utterance to mean, how easy or difficult it is for them to comprehend, or by what processes they come to understand it.
At one end of the technological spectrum, one way to find out what hearers take an utterance to mean is simply to ask them, via a paper-and-pencil questionnaire; but as we have seen, there are pitfalls to simply asking a person about their language use and comprehension. A more indirect but potentially more reliable questionnaire-based method is to leave the subject in the dark as to what you’re studying, and to ask questions that will get at their comprehension indirectly—for example, by giving them an ambiguous sentence to read and then asking a question whose answer will tell you which of the two readings the subject gave the sentence. In a pragmatics study, you might present a scenario in which a particular inference might or might not be drawn, and then ask questions designed to determine whether that inference was in fact drawn.
One interesting experimental approach is Doran et al.’s (2012) ‘Literal Lucy’ paradigm, which introduces a character (Literal Lucy) who takes everything literally, and asks subjects to make judgments based on Lucy’s world view. This unique paradigm provides a way to get at participants’ intuitive distinctions between literal (truth-conditional) and contextual meaning when those participants are unfamiliar with the theoretical distinction between semantics and pragmatics.
Other studies rely heavily on computers and (often) additional sophisticated equipment, as we’ve seen with, e.g., eye-trackers. Consider studies based on priming—that is, the propensity for evocation of one concept to make related concepts more readily accessible. For example, mention of the word doctor makes words like nurse, stethoscope, and other medical terms more accessible to a hearer, and so they’ll comprehend them more quickly than they do unrelated words. This increased accessibility can be measured by means of a lexical decision task: The researcher asks the subject to read a passage, immediately after which a word or a nonword (like glarb) is flashed on the screen. The subject’s task is to press a ‘yes’ or ‘no’ key indicating whether what flashed is or is not a word of English. What you find is that words that have been primed—that is, words related to concepts that have been evoked and are therefore salient—will be recognized more quickly than words that have not been primed, so the subject’s reaction time is quicker for those words. Although the difference is measured in mere milliseconds, computer programs measuring the speed with which subjects hit the ‘yes’ key can distinguish between the times for primed and unprimed words, which in turn can indicate what concepts have been evoked by the passage that was read. Thus, suppose a researcher flashes the word nurse on the screen after each of the following sentences:
(1) 
If (1a) leads to an inference that the speaker saw the doctor in a medical context, whereas (1b) does not, we might expect subjects to recognize the word nurse more quickly after reading or hearing (1a) than (1b). In this way, a researcher could find evidence to help determine when subjects draw certain pragmatic inferences in discourse, and what factors affect the drawing of these inferences.
Lexical decision tasks are one type of reaction-time study, in which relative reaction times are used as an indirect measure of processing time, reading time, and the like. One early reaction-time study was done by Clark and Lucy (1975), comparing processing time for direct requests vs. indirect requests inferred via conversational implicatures (like Can you color the circle blue?). Such studies can also measure reading speed, for example to examine whether a noncanonical-word-order sentence takes longer to read when it’s presented without a supporting context (see, e.g., Kaiser and Trueswell 2004)—e.g., a preposing presented in isolation, as in (2a), vs. one with a prior evocation of the preposed constituent, as in (2b):
(2) 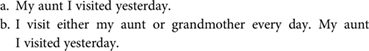
An even more sophisticated way of studying subjects’ language processing or reading speed—or at least one involving even more sophisticated machinery—requires the use of an eye-tracker, as previously mentioned. In eye-tracking studies, the subject’s slightest eye movements are tracked in order to see what they are focusing on at any particular moment. (See, e.g., Bezuidenhout and Morris 2004, Kaiser and Trueswell 2004, 2008, Papafragou et al. 2008, Kaiser et al. 2009, inter alia.) This can give a much more fine-grained measurement of reading speed, enabling researchers to see how long a reader lingers on any particular word. So it is possible, for example, to see whether a reader slows down at the point when an inference must be made in order to relate a definite NP to a previously evoked referent, or when a conversational implicature requires the reader to make an inference in order to understand the text.
An eye-tracker can also be used in connection with scenes that correspond in various ways to what a subject is hearing. So again, by careful placement of items in scenes, you can check for priming, inference, or givenness/newness: For example, if you know that a postposing requires new information in postverbal position, you can present a scene with three evoked entities and one new one, and upon hearing the beginning of the postposing, the subject’s eyes will move to the new entity, in anticipation of a postverbal reference to it. Elsi Kaiser and others have done studies in this vein investigating the comprehension of NWO constructions in a wide variety of languages (see Ward, Birner, and Kaiser 2017 for a summary). For example, Kaiser and Trueswell 2004 reports on an eye-tracking study in which Finnish speakers showed anticipatory eye movements toward a discourse-new entity when hearing the beginning of a construction whose postverbal constituent was constrained to be discourse-new.
Another method of studying pragmatic interpretation uses electroencephalograms (EEGs) to measure event-related potentials (ERPs) in the brain (so called because they are related to the processing of particular events). For these studies, electrodes are placed on the subject’s scalp to measure brain activity, allowing the researcher to measure the brain’s response to specific linguistic stimuli. ERP studies can show the time-course of processing, which in turn can indicate, for example, which inferences are more or less difficult (hence more or less time-consuming) for the hearer to make. Such studies can examine the difference in difficulty between different categories of inference, or between novel and more established metaphors, between literal and figurative readings of an expression, or between deductive inferences and pragmatic inferences, to name just a few possibilities.
Perhaps the most sophisticated machinery of all in linguistics research is functional magnetic resonance imaging (fMRI), which again shows what brain areas are active during processing, but at a greater level of detail than ERPs. Unlike the more familiar MRIs used in various medical procedures, which take a series of static images, fMRI is dynamic, which means that it records brain activity through time; fMRI is to MRI as a movie is to a photograph. Use of an fMRI machine is, however, extremely expensive, so studies of this sort are relatively rare compared to other experimental methods.
There is vastly more that could be discussed in the realm of experimental pragmatics, which is one of the most important and fastest-growing areas of pragmatics research today. For more information on research in experimental pragmatics, see Noveck and Sperber 2004, Noveck and Reboul 2008, Meibauer and Steinbach 2011, Noveck 2018, and Cummins and Katsos 2019.
In summary, as we look through the pragmatics studies of the past and present and on into the future, we see a shift from studies based solely on the researcher’s own intuitions to a greater emphasis on empirical studies using ever more sophisticated techniques and technologies to investigate the production and comprehension of language in context.
New directions in theory
Early pragmatic theory generally (either explicitly or implicitly) treated pragmatic meaning as meaning that lay ‘beyond’ semantics—as though a hearer first interpreted the semantic meaning of an utterance, and then fed that into the context, which exerted some additional influence, resulting in a final interpretation of the meaning in context. As we’ve already seen, that view of the relationship between semantics and pragmatics doesn’t work, because semantic interpretation doesn’t take place independently of, or prior to, the influence of contextual factors. Consider the examples in (3):
(3) 
The truth of (3a) doesn’t depend on whether John has ever had breakfast, but whether he’s had breakfast on the day of utterance; this is information that isn’t explicitly included, but which the hearer understands to be part of the communicated content (what Bach (1994) calls an impliciture), and it figures into the truth-conditions of the utterance: The hearer would take (3a) to be true if John hasn’t had breakfast on the day of utterance, even if he had breakfast the previous day. (It would be bizarre for John’s sister to pipe up and assert that (3a) is false on the grounds that she regularly had breakfast with him thirty years earlier.) Given a truth-conditional semantics, then, in order to work out the truth-conditions of (3a) not only do we need to supplement the speaker’s statement with the contextual matter of what day it was uttered on, but we also need to be able to infer that this information is what is at issue—that is, we need to infer that the speaker is saying something about John’s not having had breakfast today, not about his never having had breakfast. In (3b), the truth-conditional meaning depends on (and needs to include) the referents of both he and my; the proposition enriched sufficiently to render it truth-evaluable is called an explicature (Sperber and Wilson 1986). In (3c), the context must supply an implicit argument—too dark for what? And once that argument has been supplied (say, ‘too dark for reading’), we’re still left with the fact that what counts as ‘dark’—and certainly what counts as ‘too dark’—is a vague and subjective thing. ‘Too dark for reading’ might well be significantly lighter than ‘too light for sleeping’. Likewise, in a context in which (3c) and (3d) involve judgments of paint colors, what’s too dark for the kitchen might well be judged too light for the exterior of the house, and so on. Worse yet is the fact that, in traditional semantic and pragmatic theories, each sentence’s truth-conditional meaning is worked out independently of each other’s, so that even if the sentence prior to (3b) provided the referent for he, the semantics of (3b) wouldn’t have access to that information.
In short, a theory in which truth-conditions are first worked out and then fed into the context is too simplistic; we need a theory in which the semantics and the pragmatics work together. A number of semantic theories have been developed over the years to take into account the need for contextual information to carry over from one sentence to another, including File Change Semantics (Heim 1982, 1983, 1988), Discourse Representation Theory (Kamp 1981), and Dynamic Montague Grammar (Groenendijk and Stokhof 1990, 1991), all of which can be considered to be types of Dynamic Semantics—that is, semantic theories that account for the development of semantic meaning over the course of a text or discourse rather than simply as applied to a ‘static’ sentence. In this sense, such theories are really at the semantics/pragmatics boundary, in that they use the tools and concepts of traditional semantic theory but apply them to an extended discourse, taking the prior linguistic context into account. So they are to some extent both semantic and pragmatic. Most crucially, all of these approaches allow discourse entities to persist from one sentence to another, which in turn allows them to account for pronominal reference and similar features that require pragmatic information to be filled in before semantic meaning (such as truth-conditions) can be fully worked out.
To see how this might work, consider (4):
(4) 
At the point when the second sentence is encountered, the pronoun they is ambiguous; it could be coreferential with either student debt collectors or student borrowers or even attorneys general or a handful of states. If our semantic theory allows us only to look at sentences in isolation, of course, we don’t even know that much; they could have as its referent any plural entity at all, making it impossible to work out the truth-conditions of the sentence Now, they may be getting some relief. Dynamic theories create a discourse referent for each of the entities mentioned in the first sentence and indicate their relationships to each other and any properties the sentence attributes to them; and these entities, relations, and properties persist by default into the representation of the discourse that is inherited by the second sentence. Because these entities and their attributes and relations are available to the new sentence, its pronouns have access to those entities for potential referents. Notice that this doesn’t always resolve the ambiguity—but that is as it should be if the same ambiguity exists for interlocutors in the real-world discourse. In fact, the discourse in (4) plays on this very possibility: Because student borrowers might be more likely to be expected to get relief, particularly as an outcome of the mentioned lawsuits, the reader is led to assume that the referent of they is the borrowers, leading to a (fully intended) shock when it turns out that it’s the debt collectors who may be getting relief. To the extent that dynamic theories retain this ambiguity, it’s a feature, not a bug.
A newer theory that addresses the relationship between pragmatics and semantics is Optimality Theory (e.g., Blutner and Zeevat 2004). OT itself does not have its roots in pragmatics; far from it. It has been applied within a number of subfields of linguistics, originally and most prominently in phonology (Prince and Smolensky 1993, 2004), with pragmatics being a relative latecomer to the approach. The fundamental insight of OT is that linguistic phenomena are generally influenced by a range of constraints whose relative importance can be ranked. So to take a greatly simplified example, suppose you are deciding whether to stop reading this and eat dinner. There are various factors that will influence your decision:
Factor (b) argues in favor of eating; factors (a), (c), and (d) argue against it. Do you decide that since there are three arguments against eating and only one in favor of it, the higher number of arguments wins? No, of course not—because some considerations are more important than others. Perhaps being hungry is a highly ranked factor in this decision, whereas your being tired and having a lot of reading to do, and the fact that eating takes time and energy, are more minor considerations. In fact, perhaps being hungry trumps all of the other factors combined. In that case, despite good reasons to not want to eat, the fact that you’re hungry is in itself a strongly persuasive argument for eating, regardless of the list of (minor) arguments against it.
Without taking the details of this toy example too seriously, you see the point that a wide range of factors might figure into any given choice, and that the ultimate ‘winner’ is determined by a set of constraints, some of which outrank others in determining the outcome. If you recall the constraints on preposing and postposing discussed in the last chapter, they were presented as absolute: Preposing, for example, requires the preposed constituent to be discourse-old, period. OT, on the other hand, analyzes every linguistic constraint as violable in principle, just so long as there is a higher-ranked countervailing constraint. Blutner (1998) offers an OT-based analysis to account for Horn’s (1984) division of pragmatic labor, discussed in Chapter 3; many other examples can be found in Blutner and Zeevat 2004.
Related to OT is Game Theory, which applies mathematical models to decision-making and has been adopted by some as a way of explaining linguistic behavior. The general idea is that interlocutors are rational decision-makers, and linguistic behavior—and specifically for our purposes, pragmatic behavior—involves rational decision-making, including decisions about interpretation of utterances. Blutner (2017) and Benz and Stevens (2018) offer useful overviews of game-theoretic approaches to pragmatics, and van Rooij (2004, 2008) gives a game-theoretical account of Horn’s division of pragmatic labor.
A related area of pragmatics that is receiving increased attention, both in general and among OT theorists in particular, is lexical pragmatics. While much of pragmatic theory focuses on the utterance or discourse—which makes sense, since pragmatics is all about interpretation in context—there is renewed interest in the effects of pragmatic factors on the understanding of individual words. This isn’t an entirely new phenomenon; recall that the original motivation for Grice 1975 was the natural-language interpretation of the logical connectives. And just three years later came McCawley 1978, ‘Conversational implicature and the lexicon’. The field of lexical pragmatics investigates issues such as the interpretation of semantically underspecified lexical items; lexical relationships that are regular, yet not predictable from the lexical entries of the words in question; inferences based on the logical operators; and regularities in what concepts are and are not lexicalized (that is, expressed by a single word): For example, there’s a word for ‘not none’—some—but there isn’t one for ‘not all’ such as *nall; for an account of why this is so, see Horn 2017, which offers a wide-ranging overview of phenomena in lexical pragmatics. Blutner (2006) similarly presents a synopsis of issues and approaches in lexical pragmatics, and argues for an approach based on semantic underspecificity, which he demonstrates via an application of Optimality Theory to some of the relevant issues.
There is, of course, much more happening in pragmatics research than a book of this size can cover. Examples include research in pragmatics and intonation, historical pragmatics, intercultural pragmatics, coherence relations, the use and interpretation of discourse markers, pragmatics in language-impaired individuals, the acquisition of pragmatics by children, crosslinguistic pragmatics, and much more. One area that will certainly continue to grow is the study of pragmatics in computational linguistics, including research into speech recognition, machine translation, machine learning, and artificial intelligence. This chapter has barely scratched the surface of current pragmatics research, but hopefully it gives you a sense of where the field of pragmatics is heading and where it may find itself in the future.