Chapter 12. Coping with Complexity
Simplicity is a great virtue but it requires hard work to achieve it and education to appreciate it. And to make matters worse: complexity sells better.Edsger Dijkstra
Code is complex. Complexity is a battle that we all have to fight daily.
Of course, your code is great, isn’t it? It’s other people’s code that is complex.
Well, no. Not always. Admit it. It’s all too easy to write something complicated. It happens when you’re not paying attention. It happens when you don’t plan ahead sufficiently. It happens when you start working on a “simple” problem, but soon you’ve discovered so many corner cases that your simple algorithm has grown to reflect a labyrinth, ready to entrap an unwary programmer.
My observation is that software complexity stems from three main sources. Blobs. And lines.
And what you get when you combine them: people.

In this chapter, we’ll take a look at each of these and see what we can learn about writing better software.
Blobs
The first part of software complexity we should consider relates to blobs: that is, the components we write. The size and number of those blobs determine complexity.
Some software complexity is a natural consequence of size; the larger a project becomes, the more blobs we need, the harder it is to comprehend, and the harder it is to work with. This is necessary complexity.
But there is plenty of unnecessary complexity that causes hassle. I’ve lost count of the times I have opened a C++ header file, and balked at thousands of lines in a single class declaration. How is a mere mortal supposed to be able to understand what such a beast does? This is surely unnecessary complexity.
Sometimes these large monsters are autogenerated by code “wizards” (notable examples are GUI construction tools). However, it’s not just tools that are to blame. Serious code hooligans can produce these code monsters without a second thought. (In fact, the lack of thought is often the cause of such abominations.)
So we need to manage our necessary complexity. And educate—or shoot—our unnecessary programmers.
It’s important to realise that size itself is not the enemy. If you have a software system that has to do three things, then you need to put code in there to do those three things. If you remove some of that code in order to reduce complexity, then you’ll have different problems. (That’s being simplistic rather than simple, and it’s not a good thing.)
No, size itself is not the problem. We need enough code to meet requirements. The problem is how we structure that code. It’s how that size is distributed.
Imagine you start working on a vast system. And you discover that the class structure of the beast is like the image shown here:

Three whole classes! Now, is that a complex system or not?
On one level, it doesn’t seem complicated at all. There are only three parts! How could that be hard to understand? And the software design has the added benefit of looking like Mickey Mouse, so it must be good.
In fact, this appears to be a beautifully simple design. You could describe it to someone in seconds.
But, of course, each of those parts will be so large and dense, presumably with so much interconnection and spaghetti logic that they are likely to be practically impossible to work with. So this is almost certainly a very complex system, hidden behind a simplistic design.
Clearly, a better structure—one that is simpler to understand, and simpler to maintain—would consider those three sections as “modules” and further subdivide them into other parts: packages, components, classes, or whatever abstraction makes sense. Something more like the following image:
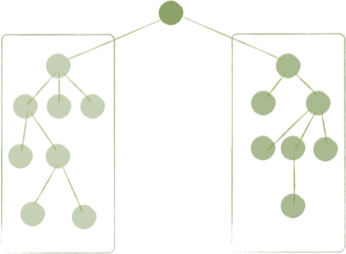
Immediately, this feels better. It looks like a lot of small (so understandable, and likely simpler) components connected into a larger whole. Our brains are suited to dividing problems into hierarchies like this and reasoning about the problems when thus abstracted.
The consequences of such a design are increased comprehension and greater modifiability (you can work on a part of the system’s functionality by identifying the smaller part that relates to it, rather than having to roll your sleeves up and dive into a single behemoth class). We prefer classes with better cohesion that do a small number of things well—preferably just one thing.
Of course, the trick to making this work—the trick that enables a design like this to actually be simple rather than just look simple—is to ensure that each of the blobs has the correct roles and responsibilities. That is, a single responsibility resides in a single part of the system rather than smeared across it.
Case Study: Reducing Blob Complexity
One of my favourite recent reductions in software complexity was a section of code with two very large objects that were so interrelated they were practically one and the same class.

I started chipping away at one of the objects, realising that it contained hundreds of unused “helper” methods. I mercilessly removed them; an enjoyable experience not unlike deflating a helium balloon. And so for effect, I started speaking in an excitable high voice. This was code becoming simpler.
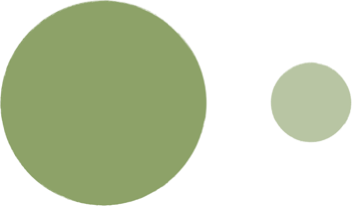
Now that I could see the remainder of the object, it was clear that the majority of its methods simply forwarded to the partner. So I removed those methods and made all calling code just use the other object. There were just two remaining methods, one of which belonged on the partner anyway, and one which should have been a simple non-member function.
The result?

A far simpler class design, I think you’ll agree.
Of course, the next step was to decompose the remaining blob. But that’s another story. (And nowhere near as interesting.)
Lines
We’ve considered blobs: the components and objects that we create. To paraphrase John Donne: No code is an island. Complexity is not borne solely from the blobs, but from the way they connect.
In general, software designs are simpler when there are fewer lines. The more connections between blobs (this is known as greater coupling if you’re talking like a proper grown-up), the more rigid a design is, and the more interoperation you have to comprehend (and fight) as you work on a system.
At the most basic level, a system comprised of many objects, none of which are connected at all, would appear the simplest. But it is not a single system at all. It’s a number of separate systems.
As we add connections, we create actual software systems. As we add more blobs and, crucially, lines between them, the more complex our systems become.
The structure of our software interconnections dramatically affects our ease of working with it. Consider the following structures, which are based on real examples I have been working on.
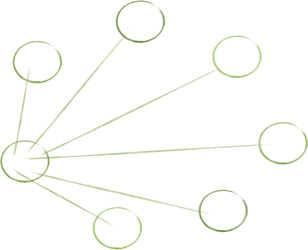
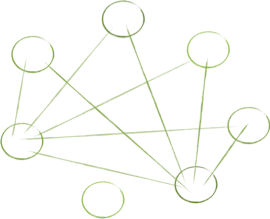
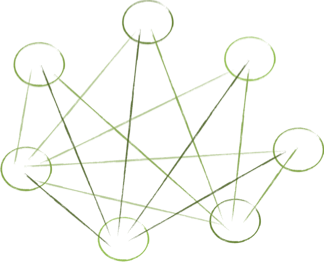
What’s your reaction to them? Which looks simpler? I’ll admit that working on the last one almost caused my head to explode.
When we map out connections, we see that complexity often springs from cycles in our graph. Cyclical dependencies are generally the most complex relationships to consider. When objects are codependent, their structure is rigid, not easy to change, and often very hard to work with. A change to one object usually requires a change to the other. The objects effectively become one entity; one that’s harder to maintain.
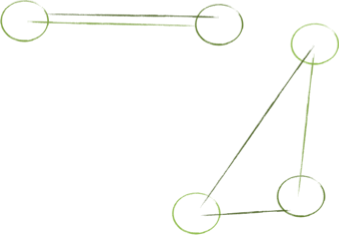
These kinds of relationships can be simplified by breaking one of the links. Perhaps by introducing new abstract interfaces to reduce the coupling between objects.

This kind of structure enhances composability, introduces flexibility, and fosters testability (you can write testing versions of components behind those abstract interfaces). We can use well-named interfaces to make those relationships descriptive.
One of the nastiest systems I’ve had to work with in a long time looked like this:
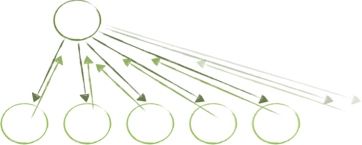
It seems a superficially simple model: one parent object represents “the system” and creates all of the child objects. However, each of those objects was given a back-reference to the parent, so they could access each other. This design effectively allowed every child-object to rely on (and become closely coupled with) every sibling, locking the entire system down into one rigid shape.
Michael Feathers described this to me as the known anti-pattern distributed self. I had another name for it, but it’s not polite enough to print.
And Finally: People
So software complexity depends on the structure of our blobs and lines.
But it’s important to observe that blobs and lines don’t create themselves. Those structures are not intrinsically to blame. It is the people writing the code who are responsible (yes, that’s you, gentle reader). It is the programmer who has the power to introduce incredible complexity, or to reduce a nasty problem down to an elegant and simple solution.
How often do people set out to write nasty, complex code? You may think that your corrupt coworkers are planning to introduce more stress in your life with their Machiavellian code. But complexity is generally accidental, rarely something someone adds wilfully.
It’s often the product of history: programmers extend and extend and extend the system, with no time allowed for refactoring. Or the “prototype to throw away” turns into a production system. By the time it’s being used, there’s no chance to take it apart and start again.
Software complexity is caused by humans working in real-world situations. The only way we can reduce complexity is by taking charge of it, and trying to prevent work pressures from forcing our code into unworkable structures.
Conclusion
In this little saunter through software complexity territory, we’ve seen that complexity arises from blobs (our software components), lines (the connections between those components), but mostly from the people who construct these software monstrosities.
Oh, and of course, it comes from the Singleton design pattern. But no one uses that anymore, do they?
Questions . Why is simplicity in code design better? Is there a difference between simplicity in design and in code implementation? . How do you strive for simplicity in your code? How do you know you’ve achieved it? . Does the nature of connections matter as much as the number of connections? What connections are “better” than others? . If software complexity stems from social problems, how can we address it? . How can you tell the difference between necessary and unnecessary complexity? . If it’s true that many programmers do know that their software designs should be simpler, how can we encourage them to craft simpler code?
See also
-
Keep It Simple The flip side of complexity: simplicity. This chapter covers some ideas for constructing simple designs.
-
People Power It’s people who create complexity. Aim to work with the kind of people who reduce, not promote, disorder.
-
Wallowing in Filth Unnecessary complexity leads to messy code that is hard to understand.
-
A Case for Code Reuse Employing the right code reuse strategy can help reduce complexity. The wrong strategy makes a complex ball of mud.
-
A Tale of Two Systems An example of a complex design contrasted with a simpler one, showing the consequences of each design.
Example 12-1.
Identify the ways that you have introduced unnecessary complexity into your recent code. How can you address this?

