

Cloud Overview
In this chapter, we introduce you to cloud concepts and explain how IBM Transparent Cloud Tiering (TCT) enables cloud integration with IBM DS8000 systems that run z/OS environments. You get a basic understanding of what a cloud is in the context of TCT, through a short description of Cloud Storage versus Cloud Computing. This chapter describes the following topics:
2.1 What defines cloud in the context of TCT?
The cloud is a combination of several different solutions, components and services. It consists of different layers.
Figure 2-1 provides a comprehensive diagram showing the different layers and where TCT integrates with the cloud:
•Application Layer: where applications can be hosted and run, and can also take advantage of pre-coded software APIs that you can integrate to create new applications.
•Infrastructure Layer: where entire systems can be hosted. An Infrastructure Layer can be composed of a mix of interconnected cloud and traditional infrastructures.
•The Cloud Layer is composed of three main classes of components:
– Storage Layer
– Network Layer
– Compute Layer
•Within the Storage Layer, we have three Storage types:
– Block Storage
– File Storage
– Object Storage
TCT uses Object Storage architecture for storing data sets. We will cover this in more detail in this chapter.
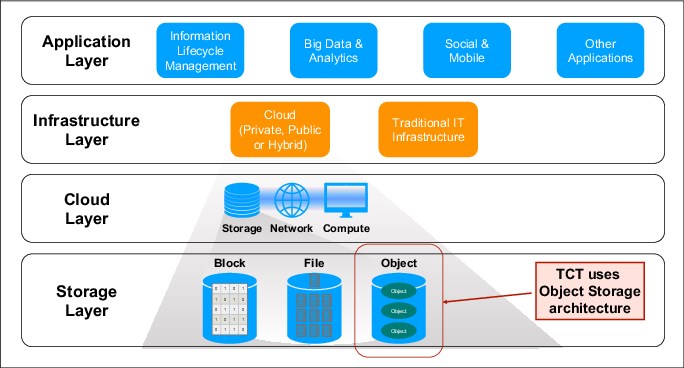
Figure 2-1 TCT in the context of the Cloud
2.2 Compute cloud versus storage cloud
In short, the compute cloud provides the necessary components to run the applications for processing resources, and is where you can deploy and run your chosen software, including operating systems and applications.
On the other hand, the storage cloud holds the data and caters for operations like backing up and archiving data. As mentioned earlier in this chapter, TCT uses Object Storage architecture to store the data it manages in the cloud.
2.3 Types of storage
Before you use storage clouds, you must understand what a gateway is, its function, and how the data is managed between the mainframe and the cloud.
The following types of architectures (see Figure 2-2) can be used for storing data, where each type has its advantages:
•Block and File: This architecture is used on mainframes and other operating systems to store data. It has the advantages of being faster, IOPS-centric, flash-optimized, and allows various approaches.
•Object Storage: This architecture provides larger storage environments, or cool/cold data, which can scale to petabytes of data while being cloud-compatible.
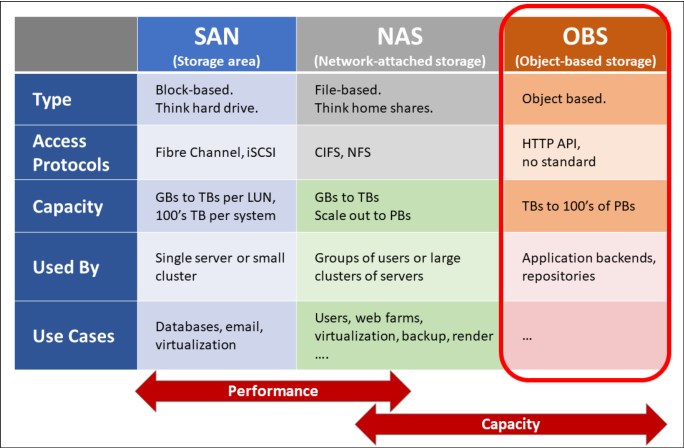
Figure 2-2 Types of storage
Having a storage cloud that uses object storage has several benefits. A storage cloud significantly reduces the complexity of storage systems by simplifying data scaling within a single namespace. Also, the REST protocol is used for communication between the server and the client. The use of high-density, low-cost commodity hardware turns storage clouds into a scalable, cost-efficient storage option.
The Transparent Cloud Tiering function of IBM DS8000 provides a method to convert the block to Object Storage without additional hardware on the LAN.
On storage clouds, the data is managed as objects, unlike other architectures that manage data as a block of storage, as is done on mainframes.
For this reason, the communication between mainframe systems and storage cloud is done by an application responsible for converting cloud storage APIs, such as SOAP or REST, to block-based protocols, such as iSCSI or Fibre Channel, when necessary.
Therefore, the storage cloud can be considered an auxiliary storage option for mainframe systems to be used by applications, such as these:
•DFSMShsm to migrate and recall data sets
•DFSMSdss to store data that is generated by using the DUMP command
2.4 Cloud Storage delivery models
Cloud delivery models refer to how a cloud solution is used by an organization, where the data is located, and who operates the cloud solution. There are multiple delivery models that can deliver the capabilities needed in a cloud solution.
The cloud delivery models are as follows:
•Public cloud
•Private cloud
•Hybrid cloud
These delivery models can be integrated with traditional IT systems and other clouds. They are divided into two categories:
•On premise: Consists of a private cloud infrastructure at your organization’s location.
•Off premise: Consists of a cloud infrastructure being hosted in a cloud service provider’s location.
Public Cloud
A public cloud is a solution in which the cloud infrastructure is available to the general public or a large industry group over the internet. The infrastructure is not owned by the user, but by an organization that provides cloud services. Services can be provided at no cost, as a subscription, or as a pay-as-you-go model.
There is another delivery model option known as community cloud, or multi-tenant cloud, which typically consists of a public cloud that is shared among multiple organizations, to lower costs. For ease of understanding, this book treats this delivery model as part of the public cloud category.
Private Cloud
A private cloud is a solution in which the infrastructure is provisioned for the exclusive use of a single organization. The organization often acts as a cloud service provider to internal business units that obtain all of the benefits of a cloud without having to provision their own infrastructure. By consolidating and centralizing services into a cloud, the organization benefits from centralized service management and economies of scale.
A private cloud provides an organization with some advantages over a public cloud. The organization gains greater control over the resources that make up the cloud. In addition, private clouds are ideal when the type of work that is being done is not practical for a public cloud because of network latency, security, or regulatory concerns.
A private cloud can be owned, managed, and operated by the organization, a third party, or a combination of the two. The private cloud infrastructure is provisioned on the organization’s premises, but it can also be hosted in a data center that is owned by a third party.
Hybrid Cloud
As the name implies, a hybrid cloud is a combination of various cloud types (public, private, and community). Each cloud in the hybrid mix remains a unique entity, but is bound to the mix by technology that enables data and application portability.
The hybrid approach allows a business to use the scalability and cost-effectiveness of a public cloud without making available applications and data beyond the corporate intranet. A well-constructed hybrid cloud can service secure, mission-critical processes, such as receiving customer payments (a private cloud service) and secondary processes, such as employee payroll processing (a public cloud service).
IBM Cloud Object Storage and TCT
IBM Cloud™ Object Storage (COS) offers all the delivery model options described previously. Figure 2-3 provides a summary of each option, with its capabilities:

Figure 2-3 IBM Cloud Object Storage capabilities
IBM Transparent Cloud Tiering solution provides an integration of the IBM DS8000 storage system, when running in z/OS environments, with a Cloud Object Storage infrastructure, that can be any of the options described above.
For detailed information about the IBM Cloud Object Storage service offering, see the Cloud Object Storage as a Service: IBM Cloud Object Storage from Theory to Practice - For developers, IT architects and IT specialists, SG24-8385 Redbooks publication or go to the IBM Cloud Object Storage website at this link:
For other IBM Cloud Storage solutions, refer to the IBM Private, Public, and Hybrid Cloud Storage Solutions, REDP-4873 Redbooks publication or go to the IBM Cloud website at the link:
2.5 Object Storage hierarchy
Data that is written to a cloud by using Transparent Cloud Tiering is stored as objects and organized into a hierarchy. The hierarchy consists of accounts, containers, and objects. An account can feature one or more containers and a container can include zero or more objects.
2.5.1 Storage cloud hierarchy
The storage cloud hierarchy consists of the following entities:
•Account
•Containers
•Objects
Each entity plays a specific role on data store, list, and retrieval by providing a namespace, the space for storage, or the objects. There also are different types of objects, data, and metadata.
A sample cloud hierarchy structure is shown in Figure 2-4. Each storage cloud component is described next.
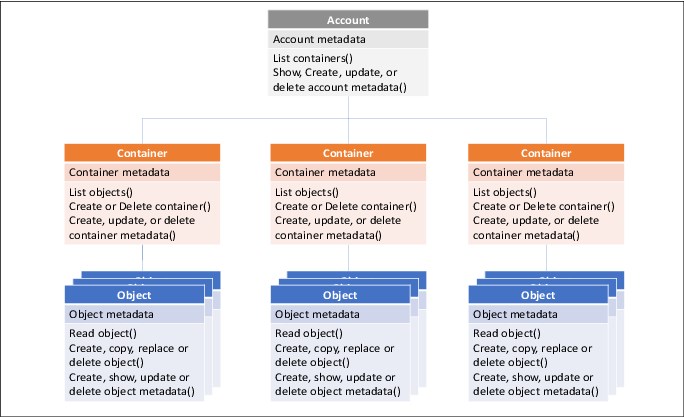
Figure 2-4 Cloud hierarchy
Account
An account is the top level of the hierarchy and is created by the service provider, but owned by the consumer. Accounts can also be referred to as projects or tenants and provide a namespace for the containers. An account has an owner that is associated with it, and the owner of the account has full access to all the containers and objects within the account.
The following operations can be done from an account:
•List containers
•Create, update, or delete account metadata
•Show account metadata
Containers
Containers (or buckets) are similar to folders in Windows or UNIX, and provide an area to organize and store objects, container-to-container synchronization, quotas, and object versioning. One main difference is that containers cannot be nested. That is, no support is available for creating a container within another container. Container names can be 256 bytes.
Access to objects within a container are protected by using read and write Access Control Lists (ACLs). There is no security mechanism to protect an individual object within a container. After a user is granted access to a container, that user can access all of the objects within that container.
The following operations are supported for containers:
•List objects
•Create container
•Delete container
•Create, update, or delete container metadata
•Show container metadata
Objects
As of this writing, there is a 5 GB limit to the size of an object due to an Openstack Swift restriction. Objects larger than 5 GB must be broken up and stored by using multiple segment objects. After all of the segment objects are stored, a manifest object is created to piece all of the segments together. When a large object is retrieved, the manifest object is supplied and the Object Storage service concatenates all of the segments and returns them to the requester. For most sizes greater than 100 MB, the system does multi-part uploads. By creating multiple parts, the system does parallel recall, and greater recall efficiency is achieved.
|
Note: The segmentation of objects into 5 GB chunks only applies to OpenStack Swift. For Clouds using the S3 API and for the TS7700, the restriction does not apply.
|
The following operations are supported for objects:
•Read object
•Create or replace object
•Copy object
•Delete object
•Show object metadata
•Create, update, or delete object metadata
The objects can also have a defined, individual expiration date. The expiration dates can be set when an object is stored and modified by updating the object metadata. When the expiration date is reached, the object and its metadata are automatically deleted.
However, the expiration does not update information about the z/OS host; therefore, DFSMShsm and DFSMSdss do not use this feature. Instead, DFSMShsm handles the expiration of objects.
User-created backups (backups that are created outside of DFSMShsm to the cloud) must be managed by the user. Therefore, a user must go out to a cloud and manually delete backups that are no longer valid. At present, this process is not recommended.
2.5.2 Metadata
In addition to the objects, metadata is recorded for account, container, and object information. Metadata consists of data that contains information about the stored data. Some metadata information might include data creation and expiration date, size, owner, last access, and other pertinent information.
The difference between data and metadata is shown in Figure 2-5.
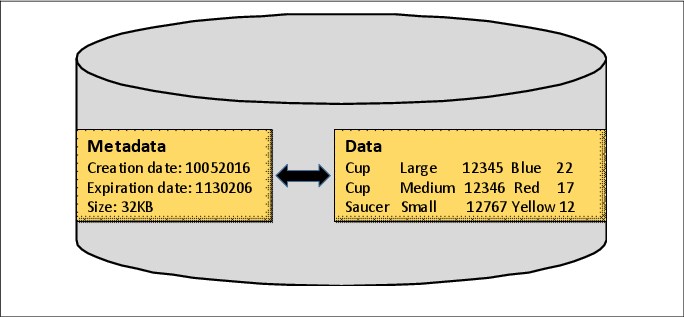
Figure 2-5 Data and metadata differences