

Transparent cloud tiering
In this chapter, we describe how Transparent Cloud Tiering extends the tiering process a step further, by adding cloud object storage as another tier.
This chapter includes the following topics:
3.1 Transparent Cloud Tiering overview
DS8000 Transparent Cloud Tiering (TCT) provides the framework that enables z/OS applications to move data to cloud object storage with minimum host I/O workload. The host application initiates the data movement, but the actual data transfer is performed by the DS8000. In this section, we provide a high-level overview of how TCT works.
|
Note: Currently, the only host application that can use TCT is the Hierarchical Storage Manager component of z/OS DFSMS (DFSMShsm or HSM).
|
HSM can migrate data to cloud object storage instead of its traditional Maintenance Levels 1 or 2. You can call HSM manually, or define rules for automatic migration. When it migrates a data set to cloud storage, HSM creates a dump job for the DFSMS data mover service (DFSMSdss). DFSMSdss then initiates the move of the data:
•It creates metadata objects that describe the data set and are needed to rebuild it in case of recall.
•It sends these metadata objects to the cloud storage.
•It sends instructions to the DS8000 to compose and send the extent objects that contain the actual customer data to cloud storage. The DS8000 creates one extent object for each volume the data set is stored on.
HSM maintains a record in its Control Data Set (CDS), describing if a data set is migrated to cloud storage. When recalling a data set, it uses this record to compose a restore job definition for DFSMSdss which in turn initiates the data movement back from cloud storage to active DS8000 volumes:
1. It reads the metadata objects that describe the data set.
2. It prepares the restoration of the data by selecting a volume and allocating space.
3. It sends instructions to the DS8000 to retrieve and store the extent objects that contain the actual customer data.
See “Storing and retrieving data using DFSMS” on page 23 for more detail about the DFSMSdss operations and metadata objects.
DS8000 Transparent Cloud Tiering supports several cloud storage target types:
•Swift: the Open Stack cloud object storage implementation, public or on-premise.
•IBM Cloud Object Storage (IBM COS) in the public IBM cloud or as on-premise cloud object storage solution.
•Amazon Web Services Simple Storage Service (AWS S3) in the Amazon public cloud.
•Generic S3 compatible object storage: any S3 compatible cloud object storage solution in a public or on-premise cloud implementation.
•IBM Virtual Tape Server TS7700 as cloud object storage.
To create metadata objects, DFSMS must communicate with the cloud object storage solution. Depending on the target type, this happens in one of two ways:
•For the Swift target type, DFSMS communicates directly to the cloud storage
•For all other target types, the DS8000 HMC acts as a cloud proxy. DFSMS sends commands and objects to the HMC, using the Swift protocol. The HMC passes them on to the cloud storage, using the appropriate protocol for the target type.
3.2 Transparent Cloud Tiering data flow
Traditional HSM data movement during availability and space management operations is performed over the FICON infrastructure. The data is transferred between the DASD controller, the host, and a tape controller. With TCT there are several data flows and connections between the host (z/OS DFSMS), the storage controller (DS8000) and the cloud target.
3.2.1 DS8000 cloud connection
The DS8000 connects to the cloud object storage via TCP/IP, using Ethernet ports in each of the two internal servers. You can either use free ports that are available onboard in each server, or purchase and connect a separate pair of more powerful Ethernet controllers. Connect the ports you intend to use for TCT to a network that extends to the cloud target. The DS8000 uses this connection to send and retrieve the extent objects that contain the actual customer data. In cloud proxy mode (see “Other cloud target types” on page 22), it also transfers cloud requests and objects on behalf of DFSMS and HSM.
When storing or retrieving data from the cloud, the system uses the ethernet ports of the server that owns the Logical Subsystem (LSS) associated with the request. This might lead to unbalanced migrations and recalls if the majority of the data is on a specific LSS.
Defining your storage groups with volumes from LSS that belong to both storage facility images can reduce the chances of having an unbalanced link usage.
The instructions that cause the DS8000 to initiate the transfer of an object to or from cloud storage come from DFSMS and are transmitted over the FICON connection between z/OS and the DS8000.
3.2.2 DFSMS cloud connection
DFSMS must be able to communicate with the cloud object storage to store and retrieve the metadata objects that it needs to identify, describe and reconstruct the migrated data sets. HSM also uses this connection for maintenance purposes, such as removing objects that are not used anymore, or for reporting and auditing.
The communication between the mainframe and the cloud uses a Representational State Transfer (REST) interface. REST is a lightweight, scalable protocol that uses the HTTP standard. The z/OS Web Enablement Toolkit (WETK) provides the necessary support for secure HTTPS communication between endpoints by using the Secure Sockets Layer (SSL) protocol or the Transport Layer Security (TLS) protocol.
To access the cloud object storage, cloud credentials like a user ID and password are required. Although the password is not included in DFSMS Cloud constructs, it is used by DFSMShsm and DFSMSdss to do store and recovery tasks from the cloud.
DFSMShsm stores an encrypted version of the password in its control data sets (CDSs) for use when migrating and recalling data. For manual DUMP and RESTORE operations, DFSMSdss requires the user ID and password to be included in the job definition.
|
Note: Any users with access to the user ID and password to the cloud have full access to the data from z/OS or other systems perspective. Ensure that only authorized and required personnel can access this information.
|
For more information about security and user ID and password administration for DFSMShsm, see Chapter 8, “Using automatic migration” on page 81.
Swift cloud type
For Swift cloud object storage targets, DFSMS sends and receives metadata directly to and from the cloud storage, using the z/OS Web Enablement Toolkit (WETK). It uses FICON in-band communication to instruct the DS8000 to move the actual extent objects with the customer data to and from cloud storage. The DS8000 sends and receives these objects through a TCP/IP connection to the cloud storage solution. The communication flow for Swift type cloud object storage is illustrated in Figure 3-1.

Figure 3-1 Cloud communication with Swift API
For the DFSMS cloud connection definition, you need information about your cloud storage environment, including the endpoint URL and credentials, such as user name and password.
Other cloud target types
The integration between z/OS DFSMS and the other cloud target types (S3, IBM COS, and TS7700) is different from the one used for Swift. DFSMS does not communicate with the cloud storage directly.
DFSMS uses the DS8000 as cloud proxy instead, as shown in Figure 3-2. The DFSMS cloud connection definition points to the DS8000 HMC, and uses DS8000 credentials (user name and password). It sends cloud commands and metadata objects to the HMC. The HMC passes them on to the DS8000 itself, which is connected to the cloud storage.

Figure 3-2 Cloud communication with S3 and IBM COS APIs
3.3 Storing and retrieving data using DFSMS
From a z/OS perspective, the storage cloud is an auxiliary storage option, but unlike tapes, it does not provide a block-level I/O interface. Instead, it provides only a simple HTTP get-and-put interface that works at the object level.
HSM uses DFSMSdss as the data mover when data is migrated to or recalled from cloud object storage. The number of objects for each data set can vary, based on the following factors:
•The number of volumes the data set is on. For each volume that the data set is stored on, an extent object and an extent metadata object are created.
•When VSAM data sets are migrated to cloud, each component has its own object, meaning a key-sequenced data set (KSDS) has at least one object for the data component and another for the Index. The same concept is applied to alternative indexes.
Also, several metadata objects are created to store information about the data set and the application.
Table 3-1 lists some objects that are created as part of the DFSMSdss dump process.
Table 3-1 Created objects
|
Object name
|
Description
|
|
objectprefix/HDR
|
Metadata object that contains ADRTAPB
prefix.
|
|
objectprefix/DTPDSNLnnnnnnn
|
n = list sequence in hexadecimal. Metadata object that contains a list of data set names successfully dumped.
Note: This object differs from dump processing that uses OUTDD where the list consists of possibly dumped data sets. For Cloud processing, this list includes data sets that were successfully dumped.
|
|
objectprefix/dsname/DTPDSHDR
|
Metadata object that contains data set dumped. If necessary, this object also contains DTCDFATT and DTDSAIR.
|
|
objectprefix/dsname/DTPVOLDnn/desc/META
|
Metadata object that contains attributes of the data set dumped:
•desc = descriptor
•NVSM = NONVSAM
•DATA = VSAM Data Component
•INDX = VSAM Index Component
•nn = volume sequence in decimal, 'nn' is determined from DTDNVOL field inDTDSHDR
|
|
objectprefix/dsname/DTPSPHDR
|
Metadata object that contains Sphere information. If necessary, this object also contains DTSAIXS, DTSINFO, and DTSPATHD.
Present if DTDSPER area in DTDSHDR is ON.
|
|
objectprefix/dsname/DTPVOLDnn/desc/EXTENTS
|
Data object. This object contains the data that is found within the extents for the source data set on a per volume basis:
•desc = descriptor
•NVSM = NONVSAM
•DATA = VSAM Data Component
•INDX = VSAM Index Component
|
|
objectprefix/dsname/APPMETA
|
Application metadata object that is provided by application in EIOPTION31 and provided to application in EIOPTION32.
|
After the DSS metadata objects are stored, the extent (data) objects are stored by DS8000 transparent cloud tiering. The data object consists of the extents of the data set that are on the source volume. This process is repeated for every source volume where parts of the data set are stored.
After all volumes for a data set are processed (where DSS successfully stored all the necessary metadata and data objects), DSS creates an additional application metadata object. DFSMSdss supports one application metadata object for each data set that is backed up.
Because data movement is offloaded to the DS8000, a data set cannot be manipulated as it is dumped or restored. For example, DFSMSdss cannot do validation processing for indexed VSAM data sets, compress a PDS on RESTORE, nor reblock data sets while it is being dumped.
At the time of this writing, no compression is performed by the DS8000 during data migration. Your data might be compressed or encrypted when it is allocated on the DS8000. Such data is offloaded to cloud in its original condition: compressed or encrypted. (Compression or encryption is typically done by zEDC or pervasive encryption.)
To maintain some structure in the potentially very large number of objects, HSM uses cloud object storage containers. By default, a new container is created every 7 days. The container name reflects the creation date and the HSM plex name. See 7.2, “Cloud container management” on page 70 for details.
If you attempt to create an object prefix that exists within a container, DFSMSdss fails the DUMP to prevent the data from being overwritten.
The following migration considerations can guide clients who are looking towards implementing Transparent Cloud Tiering and configuring the DFSMShsm to use it:
•Already migrated data
After you configure the DFSMShsm, you might want to move some of your data from other migration tiers, such as disk ML1, or tapes ML2. You need to keep in mind that currently there is no command or automated process to move migrated data directly to the cloud.
If you want to move data already migrated to the cloud, you need to first recall your data, and then migrate it to the cloud, again.
•Recalling data from the cloud
As you expand your environment to use cloud services, it is likely that more data will be migrated and recalled from the cloud. When you request a recall for a data set, the ACS routines are called, and the volume selection is done. Only cloud-capable volumes can be selected as target volumes. If no volumes in such condition exist, the recall fails.
|
Note: If you have more than one DS8000 attached to your system, make sure that all of them have access to migrate and recall data from the cloud.
|
3.4 Transparent cloud tiering and disaster recovery
Having a working disaster recovery solution is vital to maintaining the highest levels of system availability. These solutions can range from the simplest volume dump to tape and tape movement management, to high availability multi-target PPRC and IBM HyperSwap® solutions. The use of transparent cloud tiering, and storing data in cloud storage might affect your disaster recovery plan, and needs to be carried out during implementation.
Some of the steps required to recover your migrated data after a disaster include, but are not limited to:
•Network connectivity
Make sure that your disaster recovery has network access to the cloud environment. This might include configuring proxy, firewall, and other network settings to secure your connection.
•Cloud configuration
Your disaster recovery DS8000 must be configured with the information necessary to access the cloud storage, including certificates to allow SSL connections. You might also have to set up your z/OS to connect to the cloud environment, depending on your configuration.
•User ID administration
You might also need to create the userid and password on your disaster recovery DS8000 if you use S3 or IBM COS clouds. Update your z/OS to connect to the new DS8000, and have the userid defined in your storage.
•Bandwidth
Keep in mind that during a disaster, a large amount of data set recalls might be requested, such as migrated image copies, and other data sets used only for disaster recovery (DR) purposes. If these data sets are stored in the cloud, make sure to have enough bandwidth available in your recovery site to avoid recovery delays related to network issues.
|
Note: Theoretically it is also possible to create DFSMS dump and restore jobs manually that move data to and from cloud object storage. This is complex and poor practice because it requires clear text cloud credentials in the job definition
|
3.5 Transparent cloud tiering and DS8000 Copy Services
Many disaster recovery solutions are based on DS8000 Copy Services for data replication. TCT supports all DS8000 data replication technologies (Copy Services), except z/OS Global Mirror, also know as Extended Remote Copy (XRC). In the following sections we describe the way TCT and the various Copy Services Solution interact.
3.5.1 IBM FlashCopy
As shown in Figure 3-3, you can use TCT to migrate data from IBM FlashCopy® source and target volumes. It does not matter whether a FlashCopy has been issued with or without background copy or whether the background copy is still ongoing.
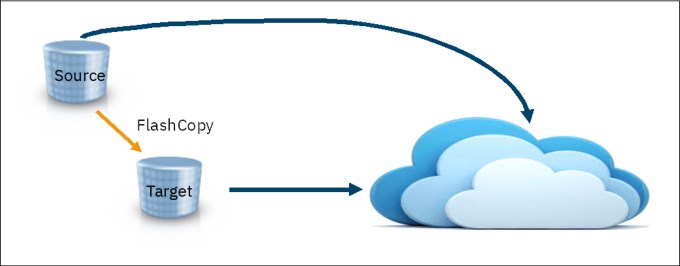
Figure 3-3 TCT migration with FlashCopy
A potential use case for TCT migration from a FlashCopy target volume is the migration of an IBM DB2® image copy that was created with FlashCopy.
Recalling data with TCT currently works only from FlashCopy source volumes, as shown in Figure 3-4. A TCT recall is treated like regular host write I/O, and any data that is overwritten by the recall operation is backed up to the FlashCopy target to preserve the point in time data of the FlashCopy.

Figure 3-4 TCT recall with FlashCopy
3.5.2 Metro Mirror
With TCT, you can migrate and recall data from volumes that are in Metro Mirror primaries, as shown in Figure 3-5.
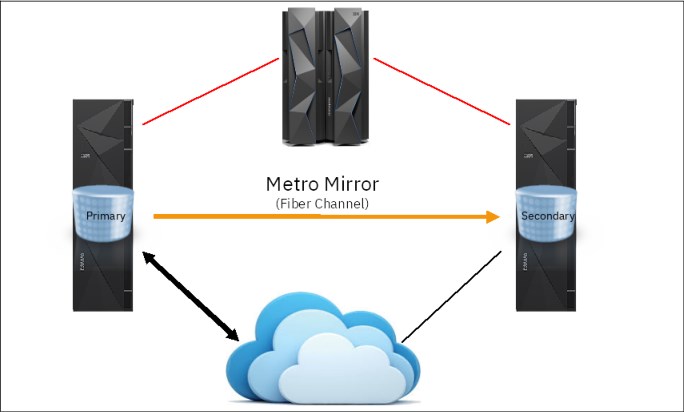
Figure 3-5 TCT with Metro Mirror
As with FlashCopy, TCT recalls are treated the same way as regular host I/O operations, and Metro Mirror replicates recalled data to the secondary volumes. Make sure that your secondary DS8000 is connected to the same cloud object storage as the primary. This way you can continue to migrate and recall after a recovery to the secondary.
|
Note: If you use TCT with S3, IBM COS, or TS7700 as cloud target type, you might need to change the DFSMS cloud definition after a recovery to the secondary DS8000. You can define only one DS8000 HMC as the cloud proxy, and the one you use may be unavailable after a failure in the primary site.
|
3.5.3 Metro Mirror with HyperSwap
DS8000 TCT is aware if your environment is enabled for HyperSwap (either using CSM or IBM GDPS®). A collision of a HyperSwap event and a TCT migrate or recall operation is treated according to Figure 3-6.

Figure 3-6 TCT operations and HyperSwap
3.5.4 Global Mirror
Just as with Metro Mirror, TCT also supports migrate and recall operations to and from Global Mirror primary volumes, as illustrated in Figure 3-7.

Figure 3-7 TCT and Global Mirror
TCT recalls are treated the same way as regular host I/O operations, and Global Mirror replicates recalled data to the remote site. If you have a requirement to continue TCT migrate and recall operations after a recovery to the remote site, your remote DS8000 and host systems must be connected to the same cloud storage as the primary site.
|
Note: z/OS Global Mirror, also known as XRC is not supported with TCT.
|
3.5.5 Multisite data replication
TCT allows migrate and recall operations in all supported combinations of DS8000 Copy Services:
•Cascaded Metro Global Mirror
•Multi Target Metro Mirror - Metro Mirror
•Multi Target Metro Mirror - Global Mirror
•4-site Metro Mirror - Global Mirror combinations with remote Global Copy
All implication regarding TCT operations after recovery described for the 2-site configurations are valid for multi-site, too.
3.6 Transparent Clout Tiering encryption
Your Transparent Cloud Tiering object storage can be located outside of your own data center, maybe even in a public cloud outside of your country or on another continent. To protect the migrated data from unauthorized access even in potentially insecure storage locations, TCT provides encryption capability.
Data is encrypted in the DS8000 and therefore already protected while it is transferred over the network. TCT uses IBM POWER® Systems hardware accelerated 256-bit AES encryption at full line speed, without impact on I/O performance. The data remains encrypted in the cloud storage. When recalled, it is decrypted when it is received back in the DS8000.
If the data set is already encrypted by data set level encryption, DFSMS informs the DS8000 and Transparent Cloud Tiering Encryption will not encrypt again.
|
Restriction: TCT encryption, as of DS8000 R9.0, is not supported with TS7700.
|
TCT encryption relies on external key servers for key management: It uses the industry standard Key Management Interoperability Protocol (KMIP). At the time of this writing, IBM SKLM is the only supported key management solution. TCT requires at least two SKLM servers at a minimum version of 3.0.0.2, configured in multi-master mode.
In high availability and disaster recovery scenarios using Metro Mirror or Global Mirror, all DS8000 systems must be connected to the same cloud, and all must be configured for Transparent Cloud Tiering encryption. Every DS8000 must be added to the TCT encryption group in SKLM during setup. This way any DS8000 in the DR configuration can decrypt the data in the cloud, even if it was encrypted by another one.
TCT encryption does not require a specific license and can be used in conjunction or independently from data at rest encryption.
See IBM DS8000 Encryption for data at rest, Transparent Cloud Tiering, and Endpoint Security (DS8000 Release 9.0), REDP-4500 for more details about TCT encryption and implementation instructions.
3.7 Selecting data to store in a cloud
When you decide to implement Transparent Cloud Tiering, you also must plan for who can use this cloud and the type of data that you want to store. Defining correct data to be offloaded to cloud gives you more on-premises storage to allocate to other critical data.
As described in this chapter, the cloud should be considered an auxiliary storage option within a z/OS system, meaning that no data that requires online or immediate access should be moved to the cloud. Also, only Simplex volumes are eligible to have their data sets moved to the cloud.
Because no Object Storage data is cataloged or automatically deleted (except for DFSMShsm-owned objects), it is suggested that you proceed with caution when deciding which users can dump and restore their data sets from cloud. If any users decide to use the cloud, they must manually do housekeeping and delete the storage objects and containers that are created by them.
The area of DFSMShsm operations is a principal use case for storage cloud, for these reasons:
•DFSMShsm maintains information on containers and objects in its control data sets.
•It can retrieve or expire in its control data sets.
•It can automatically retrieve and expire the objects that are associated with data sets that are migrated to cloud storage.
The latest APARs for auto-migration allow for deleting empty containers.