Chapter 8: The Basics of File Input and File Output in C++
In the first few chapters of this book, we briefly discussed the iostream
library, also known as the library, to feature sequential file access stream classes. In this chapter, we will build our discussion on this fundamental concept and explore it in more detail and depth. Understanding file streams are very important in programming as they are a gateway for practicing portable file handling techniques. Moreover, file operations are one of the very foundational tasks on which C++ programs are built upon. Just as how functions, classes, objects, and variables all come together to make up the basic structure of a program, file streams provide a structural representation of storing data within a program to an external storage device. This is a very important process because a program primarily stores its data in the volatile system memory. Hence, when we close a program, the data in this volatile storage is immediately lost. That’s why we need certain techniques to not only output data from a program to permanent storage but also input data into the program as well.
The Basic Concept of Files
Before we discuss file streams, we must first understand the concepts of file operations and file positions.
File Operations
Just as how lone characters or an entire string of characters can be displayed on a screen as an output, such characters can also be written to a text file as well as representing this data. Now let’s talk a bit about records. Record is an umbrella term for referring to a file that houses data forming logical units. Generally, records are stored in files. This is achieved by the write operation,
which handles the process of virtually storing a specified record to a specified file. If the file already has an existing record, the write operation either updates the already present record or simply adds in a new record to the file alongside the pre-existing one. When we want to access the contents of the record stored in a file, we are issuing a read
command which takes the contents of the record and copies it to the program’s defined data structure.
Similarly, objects can also be stored in the permanent storage of the system instead of the volatile storage. However, the process isn’t entirely the same as storing and reading record files, as we need to do more than just store the internal data of the object itself. When storing objects, we need to make sure that the object, along with its data, is accurately reconstructed when we issue a read command. For this purpose, we not only need to store the object’s type information, but we also need to store the included references to other objects as well.
It is important to keep in mind that all of the external storage devices (for instance, a hard disk) have a block-oriented storage structure. This block-oriented nature of storage means that the data is stored into the device in blocks, and the sizes of these blocks are always multiples of 512 bytes.
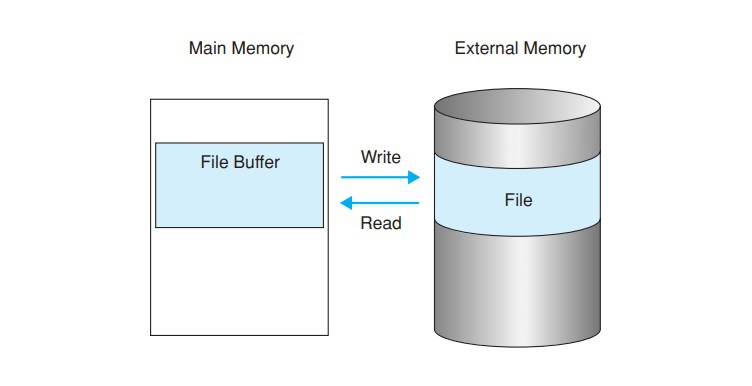
Efficient and simple file management simply refers to the concept of taking the data you need to store and transferring it to the temporary storage of the main memory, which is also known as ‘file buffer.’
Here’s a visual representation of this concept.
File Positions
In a C++ program, a file is interpreted as a large array of bytes. Keeping this in mind, the structural elements of this file is solely the responsibility of the programmer to handle. How much flexibility the file’s structure provides the programmer is dependent on how he structured the file itself.
In a file, there are many characters represented by bytes. Each byte in a file holds a specific position. For instance, the first byte of the file will be assigned the position 0, the next byte will be assigned the position 1 and this trend continues. As a consequence of this feature of files, a very important term arises, which is known as ‘current file position.’ This refers to the position that will be assigned to the upcoming byte, which is going to be written or read from the file. So, whenever a new byte is added to a file, the current file position is displaced positively (increased) by the value of 1.
In sequential access, things are a little different. As we know that the word ‘sequential’ means ‘in a sequence or following a sequence,’ the data that is being written or read to file is done in a fixed and defined order. In other words, there is a defined sequence in which the programmer can read or write data, and it is not possible to deviate from this sequence. So if you execute the very first read operation on a file, the program will begin reading the file from the very beginning. This means that if you want to access a specific piece of information located within the file, you will have to go through the entire sequence, i.e., start from the beginning and scrolling through the contents of the file until you find what you’re looking for. In terms of write operations, they have a little more freedom compared to read operations as they can easily create new files, overwrite existing files, or add new data to an existing file.
In contrast, random file access means that we can access or read any part of the file without having to follow through a sequence at any given time. This allows for instantaneous access to the contents of the file. The concept of providing easy access to files refers to this technique of random access, and programmers have the freedom of specifying current file positions per their needs.
File Stream Classes
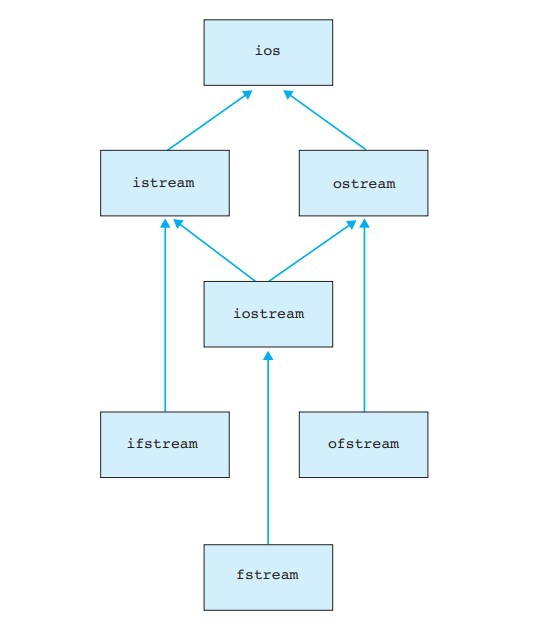
In C++, there are several classes standardized for file management purposes. These classes are commonly referred to as ‘file stream classes’ and offer easy file handling functionality for the program. Here’s a flow-chart highlighting some of the most commonly used file stream classes and their hierarchy relative to each other.
Although, as a programmer, you need to consider the file management classes and implement them properly, what you don’t need to worry about regarding file management during programming is buffer management or even the system specifics.
In C++, the major file stream classes have already been standardized, allowing programmers the freedom and capability of developing portable C++ programs. By portable, we do not mean easy to carry around like a laptop or a smartphone. Portable in programming means that this particular program can be easily ported over to other platforms such as Windows or Unix. Hence, standardized file stream classes make it easier for programmers to develop programs that can be easily ported to other platforms. All it takes is a simple recompilation of the program for each platform it’s being used on.
File Stream Classes Belonging to the iostream Library
If you refer to the flow-chart shown in the previous section highlighting the hierarchy of the file stream classes, we can see that this family of classes have something known as ‘base classes.’ A base class is a class from which other classes are derived. In other words, we can understand base classes by remembering them as ‘parent classes’ from which other classes can be created; however, ‘base class’ is the official programming term. We have already used some of these base classes in the programs demonstrated in this book as well. Here’s an explanation of what class has been derived from which parent class:
-
istream
is the parent class for the ifstream
class. In other words, the ifstream
class has been derived from the istream
class. The purpose of the ifstream
class is to allow the operations of file reading.
-
The ostream
class is the parent class for ofstream
. In other words, the ofstream
class is created from the ostream
class, and its purpose is to support writing operations for files.
-
The iostream
class is the parent class for fstream
. In other words, the fstream
class is created from the iostream
class, and its purpose is to support operations such as reading and writing for files.
So an object that is part of the file stream
class is referred to as a ‘file stream
.’ The standardized file stream classes are defined in a header file known as fstream,
and to use these classes in a program, we must add this header file into the program using the #include
directive.
Functionalities of the File Stream Classes
Whenever we create a file stream class from a base class, the newly derived class inherits all of the functionalities of its parent class as well. In this way, class functionalities such as methods, operators, and even manipulators for cin
and cout
are available to these classes as well. Hence, every file stream class comes with the following functional features:
-
Methods that have been defined for operations such as non-formatted reading or writing specifically for single characters and data blocks.
-
Operators (‘<<’ and ‘>>’) that are used for formatted read and write operations to or from files.
-
The methods and manipulators that have been defined for formatting character sequences.
-
The methods that have been defined for tasks such as state queries.
Creating Files through a C++ Program
Let’s see a program demonstrating the creation of file streams and then break it down and understand the fundamentals of this concept.
// showfile.cpp
// Reads a text file and outputs it in pages,
// i.e. 20 lines per page.
// Call: showfile filename
// ----------------------------------------------------
#include <iostream>
#include <fstream>
using namespace std;
int main( int argc, char *argv[])
{
if( argc != 2 ) // File declared?
{
cerr << "Use: showfile filename" << endl;
return 1;
}
ifstream file( argv[1]); // Create a file stream
// and open for reading.
if( !file ) // Get status.
{
cerr << "An error occurred when opening the file "
<< argv[1] << endl;
return 2;
}
char line[80];
int cnt = 0;
while( file.getline( line, 80)) // Copy the file
{ // to standard
cout << line << endl; // output.
if( ++cnt == 20)
{
cnt = 0;
cout << "\n\t ---- <return> to continue ---- "
<< endl;
cin.sync(); cin.get();
}
}
if( !file.eof() ) // End-of-file occurred?
{
cerr << "Error reading the file "
<< argv[1] << endl;
return 3;
}
return 0;
}
Opening a File
Before we can proceed to manipulate a file in a program, we first need to open and access it. To open a file, we need to perform two fundamental actions:
If the file we want to open does not have a directory or a path that is stated explicitly, it means that the file should be in the current directory of the program. The file access mode specifies the read and write permissions granted to the user for the file. This means that if the file access mode is defined as read-only, then we can only access the contents of the file but cannot modify it. When a program is terminated, all the open files that are associated with it are closed as well.
Defining the File Stream
When we create a file stream, we can also open the file at the same time as well. To do so, all we have to do is state the file’s designated name. The program demonstrated at the beginning of this section uses default values for defining the file access mode.
ifstream myfile("test.fle");
In this statement, since we have not specified any particular directory or path for the file ‘test.file,’ this tells the program that the file must be located in the same directory. The file is opened by the constructor of the ifstream
class to perform a read operation. Once a file has been opened in a program, the current file position is specified at the start of the file.
Also note that if you specify a write-only file mode access, then it’s no longer necessary for the actual file to even exist in the system. If there is no file corresponding to the file name for write-only access mode, then the program will create a new file with this specified name. However, if a file with the name specified actually exists, then the write-only access mode will delete this file.
In this line of code
ofstream yourfile("new.fle");
We are creating a new file with the name of ‘new.fle.’ Once this file has been created, the program opens the file to perform the write function. Just as we recently discussed, if the directory has an existing file with the same name, then it will be first deleted before the new file is created.
We can also create a file stream which does not necessarily refer to any particular file. This file can be opened later by using the open()
method. For example
ofstream yourfile;
yourfile.open("new.fle");
These two statements perform the same task as the “ofstream yourfile("new.fle");” line. To elaborate, the open() method opens the file by using the same set of values, which are also used by the default constructor for the file stream class.
Usually, fixed file names aren’t always used by experienced programmers in every instance. If we analyze the program shown at the beginning of this section, we will see that the name of the file we want to manipulate is stated in the command line instead. If we do not provide a suitable file name for the program to operate on, then it will simply generate an error message and close. Another alternative route of defining file names is to leverage the interactive user input feature in programs.
Modes when Opening Files
In this section, we will discuss open modes that can be used with constructors as well as the open()
method. But before we dive into this concept, let’s first understand the different flags for the open mode of a file. A table showing the open mode flags along with their corresponding functions have been displayed below:
|
Flag
|
Function
|
|
ios::in
|
Opens an existing file for input
|
|
ios::out
|
Opens a file for output. This flag implies
ios::trunc if it is not combined with one of the flags ios::in or ios::app or ios::ate
|
|
ios::app
|
Opens a file for output at the end-of-file
|
|
ios::trunc
|
An existing file is truncated to zero length
|
|
ios::ate
|
Open and seek to end immediately after opening. Without this flag, the starting position after opening is always at the beginning of the file
|
|
ios::binary
|
Perform input and output in binary mode.
|
(Explanation of the flags referenced from ‘A Complete Guide To Programming in C++ by Ulla Kirch-Prinz and Peter Prinz)
It is important to note that all of the flags mentioned above are already defined in the ios
base class (which is a parent class to all other file stream classes). Moreover, all of these file stream classes are of the ios::openmode
type.
The Default Settings of an Opened File
Whenever we open a file, the default values used by the constructor of the file stream class and the open()
method are:
|
Class
|
Flags
|
|
Ifstream
|
ios::in
|
|
Ofstream
|
ios::out | ios::trunc
|
|
Fstream
|
ios::in | ios::out
|
If you want to open a file without the default values assigned to its constructor and open() method, then we will need to supply the program with two things; the file name and the open mode. This is an absolute requirement to open a file that already exists in the directory in a write-only access mode without deleting the original file.
Understanding the Open Mode Flags
We can pass an additional argument to the open mode alongside the file name to both the constructor of the file stream class as well as the open() method. This is because the open mode of the file is dependent on flags.
In programming, a flag is represented by a single bit. If the flag is raised, then it will have a ‘1’ value, and if the flag is not raised, then it will have a ‘0’ value.
Another important element in flags is the bit operator “|.” This operator is commonly used to combine different flags. However, in all of the cases, one of the two flags, ‘ios::in’ or ‘ios::out,’ should be stated. This is because if the ios::in flag is raised when opening the program, it tells the system that the file already exists and vice versa. If we do not use the ios::in flag when opening a file, the program will create this file if it doesn’t exist in the directory.
In the following statement:
fstream addresses("Address.fle", ios::out | ios::app);
We are opening a file by the name of ‘Address.fle,’ and if it does not exist within the directory, then it will be created. According to the flags and file stream class being used in this statement, the file is being opened for a write operation at the end of the file. After the completion of each write operation, the file will grow automatically.
There’s also an update mode which allows us to open a file to append data into its existing contents or update the existing data and is often used in random file access mode. This is done by using the default mode for the fstream
class, which is (ios::in | ios::out), allowing the user to open a file that already exists for read and write operations.
Error Handling
Encountering errors when opening files is a common phenomenon. This can be due to various reasons, with the most common ones being that you either don’t have the required privileges to access the file or the file simply does not exist. To handle any error that may occur, we implement a flag failbit
that monitors the state of the operation. This flag is from the base class ios,
and if an error does occur, this flag is raised. Querying the flag is also very simple. We can either use the fail()
method to directly query the flag or check the status of the file stream by using the if
conditional to query the flag indirectly. For example
if( !myfile) // or: if( myfile.fail())
The failbit flag is also raised when an error occurs in the read or write operations. However, not every error indicates a critical malfunction or of some sort. For instance, if the program encounters a read error, then this may mean that the program has read through all the file’s contents, and there’s nothing left to read. In such cases, we identify the nature of the read error properly by using an end-of-file method, which is actually referred to as eof()
. We can separate such types of normal read errors from other types of hindering read errors by querying the eof
bit as shown below:
if( myfile.eof()) // At end-of-file?
Closing Files
It is recommended that whenever we are done working with files or completed the file manipulation tasks, we must always close the files. The effectiveness of this practice is widely supported due to two main reasons:
-
If a program is not properly terminated, then the file opened by the program may experience data loss.
-
A program is not capable of opening numerous files at the same time; there’s a limit to the files that can be opened simultaneously. As such, we should properly close the files we are not working with to avoid any errors in the program.
A program that is properly terminated will automatically close any open files that are associated with it. However, there are cases where a program is not properly terminated. To avoid those unforeseeable cases, it is important always to close the files directly once they are not being used.
Here’s a program that demonstrates the concepts discussed up till now.
// fcopy1.cpp : Copies files.
// Call: fcopy1 source [ destination ]
// ----------------------------------------------------
#include <iostream>
#include <fstream>
using namespace std;
inline void openerror( const char *file)
{
cerr << "Error on opening the file " << file << endl;
exit(1); // Ends program closing
} // all opened files.
void copy( istream& is, ostream& os); // Prototype
int main(int argc, char *argv[])
{
if( argc < 2 || argc > 3)
{ cerr << "Call: fcopy1 source [ destination ]"
<< endl;
return 1; // or: exit(1);
}
ifstream infile(argv[1]); // Open 1st file
if( !infile.is_open())
openerror( argv[1]);
if( argc == 2) // Just one sourcefile.
copy( infile, cout);
else // Source and destination
{
ofstream outfile(argv[2]); // Open 2nd file
if( !outfile.is_open() )
openerror( argv[2]);
copy( infile, outfile);
outfile.close(); // Unnecessary.
}
infile.close(); // Unnecessary.
return 0;
}
void copy( istream& is, ostream& os) // Copy it to os.
{
char c;
while( is.get(c) )
os.put(c); // or: os << c ;
}
The close() And is_open() Methods
Notice that each of the file stream classes used in the program demonstrated a method defined as a void
type. This is the close()
method, and as its name suggests, it’s purpose is to terminate the file which is occupied by the stream in which the method is used. For example:
Even though the file on the specified file stream is terminated, the file stream itself is left untouched. This means that by closing a file on a particular file stream, we can open another file immediately on the same stream. To check whether a file is currently occupying a file stream, we use the is_open()
method to do so. For instance,
if( myfile.is_open() )
{ /* . . . */ } // File is open
The exit() Function
When using the global exit()
function, files that are open and being accessed by the program are closed. The main reason for using this global terminating function as opposed to the close()
method is that we are not only closing the open files, but we are also terminating the program itself as well. In this way, the program is properly closed, and a status
error code is returned to the corresponding calling process. The prototype of the exit()
function is shown below:
The reason for returning a status
error code to the calling process is because the calling process evaluates the statu
s. Usually, the calling process in such cases is the command-line interpreter itself, for example, Unix shell. When a program is successfully terminated without any problems, it returns an error code ‘o’. Similarly, in the main()
function, the two statements return n
and exit(n)
are equivalent to each other.
In the program shown in the next section, you will see a program that is instructed to copy the contents of a file to and paste it to a destination file. The file is stated in the command line, and the program proceeds to copy it. If the user does not specify the destination file, then the original file is simply copied to the program’s standard output.
Read and Write Operation on Blocks
All of the file stream classes are capable of utilizing the public
operations that have been originally defined in their parent classes, otherwise known as base classes
. Hence, by using appropriate file stream classes for a program, we can easily perform write operations for transferring formatted or unformatted data to a specified file. Similarly, we can also perform a read operation to go through the data contents of the file in either entire blocks at a time or one character at a time.
Here’s a program demonstrating the use of read and write operations for blocks of data.
// Pizza_W.cpp
// Demonstrating output of records block by block.
// ---------------------------------------------------
#include <iostream>
#include <fstream>
using namespace std;
char header[] =
" * * * P I Z Z A P R O N T O * * *\n\n";
// Record structure:
struct Pizza { char name[32]; float price; };
const int MAXCNT = 10;
Pizza pizzaMenu[MAXCNT] =
{
{ "Pepperoni", 9.90F }, { "White Pizza", 15.90F },
{ "Ham Pizza", 12.50F }, { "Calzone", 14.90F } };
int cnt = 4;
char pizzaFile[256] = "pizza.fle";
int main() // To write records.
{
cout << header << endl;
// To write data into the file:
int exitCode = 0;
ofstream outFile( pizzaFile, ios::out|ios::binary );
if( !outFile)
{
cerr << "Error opening the file!" << endl;
exitCode = 1;
}
else
{
for( int i = 0; i < cnt; ++i)
if( !outFile.write( (char*)&pizzaMenu[i],
sizeof(Pizza)) )
{ cerr << "Error writing!" << endl;
exitCode = 2;
}
}
if( exitCode == 0)
cout << "\nData has been added to file "
<< pizzaFile << "\n" << endl;
return exitCode;
}
Formatted and Unformatted Input and Output
In the programs demonstrated up until now in this chapter, we have seen the use of some important methods get()
, getline()
and put()
to instruct the program to perform read or write operations to and from text files. Data that is formatted, such as numerical values, require the ‘<<’ and ‘>>’ operators for input and output. In addition, we also need specific formatting methods and proper manipulators to handle formatted data. For example:
double price = 12.34;
ofstream textFile("Test.txt");
textFile << "Price: " << price << "Dollar" << endl;
In these lines of code, we can understand that the actual test.txt
file itself will have a line that will correspond to “Price ..” and this line will match exactly with the output shown on the screen.
Transferring Blocks of Data
Transferring entire data blocks is mostly done by issuing a write operation through the write()
method. This method belongs to the ostream
class and transfers the number of bytes specified by the user from the system’s main memory to the destination file. The prototype of this method has been shown below:
ostream& write( const char *buf, int n);
Since the write()
method gives a reference value to the corresponding file stream, we can use this to check if the write operation completed successfully or if it wasn’t able to transfer the total bytes of data completely. The following statements show how this can be done:
if( ! fileStream.write("An example ", 2) )
cerr << "Error in writing!" << endl;
When the program tries to perform a write operation to transfer the first two characters, “An,” then it will issue a warning if the write operation encounters an error; otherwise, everything will go smoothly.
We can also perform a read operation by using the read()
method belonging to the istream
class to read the blocks of data within a specified file. When a read operation is performed, the read()
method takes a data block from the source file and transfers it to the buffer memory of the program to read it. Once the data block has been read, the buffer memory of the program is cleared, and the next data block is transferred until we reach the end-of-line of the file. The prototype method of the read operation is shown below:
istream& read( char *buf, int n);
It is important to note and remember that the read()
and write()
methods are primarily used with records that are of a fixed length. Moreover, the data block we want to transfer can have more than one record as well. Last but not least, the buffer in the system’s main memory can have two possible structures: a simple structure variable or an entire array whose elements are part of the structure type itself. When accessing the main memory for a data block, we must specify the address referring to the specific area of memory in which the data block is found to the argument (char *)
. The implementation of the read()
and write()
methods have been demonstrated in the following program:
Creating a Class Account
// Class Account with methods read() and write()
// ---------------------------------------------------
class Account
{
private:
string name; // Account holder
unsigned long nr; // Account number
double balance; // Balance of account
public:
. . . // Constructors, destructor,
// access methods, ...
ostream& Account::write(ostream& os) const;
istream& Account::read(istream& is)
};
Implementing the read() and write() methods.
// write() outputs an account into the given stream os.
// Returns: The given stream.
ostream& Account::write(ostream& os) const
{
os << name << '\0'; // To write a string
os.write((char*)&nr, sizeof(nr) );
os.write((char*)&balance, sizeof(balance) );
return os;
}
// read() is the opposite function of write().
// read() inputs an account from the stream is
// and writes it into the members of the current object
istream& Account::read(istream& is)
{
getline( is, name, '\0'); // Read a string
is.read( (char*)&nr, sizeof(nr) );
is.read( (char*)&balance, sizeof(balance));
return is;
}