Transactional semantics for a database or a journaled file system often require keeping track of changes made to the data and metadata contained in the files or entries. Typically, these changes are stored in data structures called log records through an operation called logging. These log records can then be used to undo (roll back), redo, or validate the changes at a later time, even across system reboots.
Windows provides this kind of logging service through the Common Log File System (CLFS) to support the transactional features built into Windows, including transactional NTFS (TxF) and transactional registry (TxR), and to enable third-party developers to take advantage of similar technology. CLFS provides user-mode and kernel-mode APIs for creating, reading, and writing CLFS log files. The APIs are flexible and extensible, which allows the implementation details and structure of the log records stored in a log file to be defined by a caller. CLFS can be used by a variety of applications, such as databases; for store and forward message queues and replication agents; and for operations such as event logging, compliance logging, or even maintaining undo/redo history in an editor. The CLFS APIs provide a consistent view of a log and allow the sharing of a log between user-mode and kernel-mode components.
Although CLFS calls itself a file system, it actually provides a virtual abstraction layer on top of NTFS by using streams and containers, described later. What CLFS exposes as a single virtual log file could actually be a single physical log file, a single log file divided into multiple physical files, or even different log files each divided into multiple physical files. Later, we’ll describe how NTFS interacts with CLFS to provide transactional support.
Internally, CLFS encapsulates the functionality of the Algorithm for Recovery and Isolation Exploiting Semantics (ARIES), which allows it to provide reliable recovery and replication of operations by using an industry-approved standard. However, CLFS is not limited to supporting ARIES; it is well suited to a variety of logging scenarios. You can find the full ARIES specification at www.sai.msu.su/~megera/postgres/gist/papers/concurrency/p94-mohan.pdf.
The primary job of any high-performance transactional log is to allow log clients to accurately repeat history. CLFS does this by marshalling client log records into memory buffers, forcing them to stable storage (a disk volume), and reading records back on request. After a record makes it to stable storage and the storage media is intact, CLFS is able to read the record across system failures.
Both user-mode and kernel-mode clients marshal data buffers into log records that are part of a marshalling area maintained in the client’s address space. When creating a marshalling area, a client must specify the number and size of the log I/O buffers it wants to maintain in its marshaling area. The marshalling runtime implements policy on allocating log I/O buffers, appending them to the log internal queue and flushing them to disk. Clients can override the default marshalling code policy by forcing queue appends and flushes to disk via API calls.
One of the design goals of the CLFS marshalling runtime is to minimize kernel transitions, which it achieves, among other things, through log-space reservation, a requirement for supporting scenarios such as transaction rollbacks. Every time the log marshalling area talks to the CLFS driver (which implies a kernel transition for user-mode clients), the marshalling area tries to negotiate a desired amount of reserved space, usually larger than what is currently required. This means that if the client requires more space in the future, the marshalling area can immediately satisfy the new request without issuing a new kernel transition. Note, however, that if the amount of the reservation cannot be satisfied, the marshalling area will try to get just enough of the reservation to satisfy the user’s request (without extra reserved space), which could potentially lead to additional kernel transitions.
CLFS supports two types of logs: dedicated logs and multiplexed logs (also called common logs). A dedicated log has a single stream of log records that is used by all the log’s clients. A multiplexed log has several streams: each stream has its own clients and its own memory buffers for marshalling log records, but the records from all those buffers are multiplexed into a single queue and written to a single log on stable storage. Multiplexing allows the I/O operations of several streams to be consolidated. When a log is created or opened, CLFS determines whether the log is dedicated or multiplexed depending on whether a dedicated log path or a multiplexed log path is specified.
If the request is for a client on a dedicated log (called a physical client), CLFS locates the physical file control block (FCB) object for the file proper and handles the request.
If the request is for a client on a multiplexed log (called a virtual client), CLFS locates the corresponding virtual FCB and context control block (CCB) objects to translate the request into an operation on the physical FCB object. CLFS then handles the operation on the CLFS physical FCB object as just described.
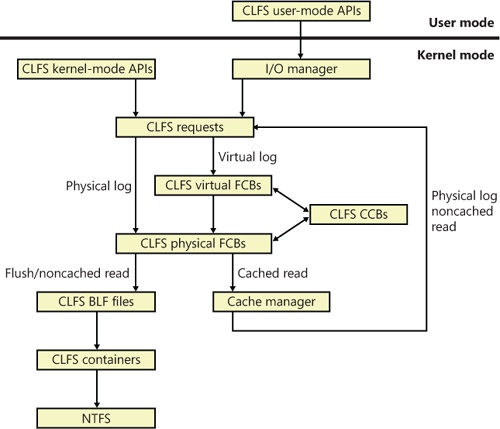
In either case, if the request is a cached read, CLFS uses the cache manager’s services for accessing cached data. (For more information on the cache manager, see Chapter 11.) Just as it does for requests from other file system drivers, the cache manager maps a view of the file and references the view, which might cause the memory manager to issue noncached reads to CLFS against the physical log. For flushes and noncached reads, CLFS finds the target container object through the log metadata and issues IRPs to NTFS directly. Figure 12-12 shows the possible CLFS paths for a request coming from user mode or kernel mode.
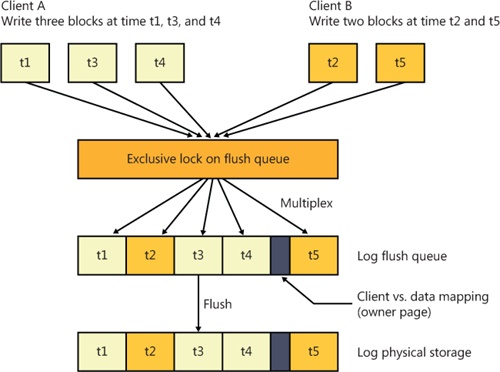
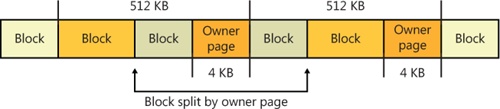
Because each stream of a multiplexed log provides its clients with the illusion that their stream is the entire log, CLFS must include metadata in the physical log that identifies which client each data block belongs to. This data is called the owner page and is always exactly one page (4 KB) in size. Each 512 KB of client data results in an owner page to describe it. Since dedicated logs require no tracking of client and data mapping, they don’t include owner pages. Figure 12-13 shows two clients writing log records to a multiplexed log and how the writes are kept together in a unified flush queue that can then be uniformly flushed to physical storage through a single I/O operation.
The flush queue will be emptied in the following conditions:
The amount of data in the flush queue exceeds a certain threshold. (The default is 40,000 bytes.)
The CLFS flush API is called.
A restart area is being written, and the log needs to be flushed beyond the restart area. (For more information on the restart area, see the section Log File Service later in this chapter.)
When flushing, CLFS scans the flush queue and determines how many entries need to be flushed. It then issues IRPs to NTFS for the corresponding log files of each of the entries and waits for all the IRPs to complete. If some IRPs fail, CLFS may re-issue IRPs (failures such as low memory condition, lack of quota, and so on are subject to retry) to redo the work and wait again.
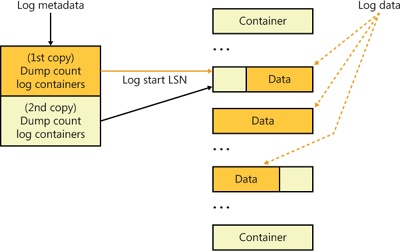
A log file is made up of a base log file (BLF) that contains metadata and up to 1,023 containers that hold the actual data. The base log file is initially 64 KB in size and grows as needed. The log metadata stores information about the log, including the beginning of the log, the container size, the container path, the location from which restart operations should be performed, the log state, the log name, and the log clients. For consistency in case a system failure occurs during a log update, the base log file stores two copies of the log metadata, and when it makes updates it overwrites the older copy. The BLF stores a value, the dump count, that indicates which copy is newer.
A container is the unit of allocation for an active physical log stream. All the containers in a log have the same size, which is a multiple of 512 KB with a 4-GB maximum size. A CLFS client grows or shrinks a log stream by adding or deleting containers from the log file. CLFS implements containers as contiguous files on the volume on which the BLF resides. Figure 12-14 shows the relationship between a base log file and the associated log data stored in containers.
Internally, the CLFS driver places the containers in a container queue to give clients a logical view of a single contiguous physical log stream; in doing so, the CLFS driver maps the physical container identifier to a logical container identifier. Containers are recycled when the tail of the active log migrates beyond the last sector of the container. Recycling a container involves moving it from the tail to the head of the container queue and appropriately updating its logical container identifier.
When a client writes a record to a stream, CLFS returns a log sequence number (LSN) that identifies the log record for future reference. The LSNs assigned to the records that are written to a particular stream form an increasing sequence. That is, the LSN assigned to a record that is written to a stream is always greater than the LSN assigned to the previous record written to that same stream. Two critical LSNs that the base log file keeps track of are the log start LSN and the restart LSN, which, as described earlier, are stored in the BLF metadata.
An LSN is 64 bits wide and consists of three parts, as shown in Figure 12-15:

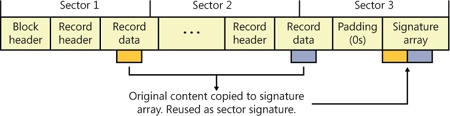
Because it is possible that a write to a log might fail, which is called a torn write, CLFS uses log blocks to track whether log records are fully committed to storage. CLFS stores log records within log blocks, which correspond to 512-byte sectors, and reads and writes data to a log using log blocks. Each log block includes a 2-byte sector signature at the end of each sector in the block that stores a sequence number and flags, as well as a copy of the most recently committed signatures in a signature array at the end of the block, as shown in Figure 12-16. Only if all the sector signatures in a log block are valid and match the signatures in the array, does CLFS consider the block valid. If a log block is partially written and a system failure occurs, for example, the signatures won’t match, and CLFS considers the log block invalid.
As mentioned previously, each 512-KB block of data in a multiplexed log (called a region) is correlated with its virtual log through an owner page. Each region consists of 4-KB pages, and each page contains one or more sectors, which contain log blocks. The owner page is the last page of a region, as shown in Figure 12-17. Because the owner page is itself a log block, CLFS can detect torn writes on the owner page, just as for a log record, by using the log block signature array.
An owner page contains two kinds of information:
For each sector in the region, the virtual log to which the sector belongs as well as the sector’s serial number (starting from 0). There can be at most 1,024 sectors in a region.
For each virtual log, the minimum and maximum virtual log LSN for the region. These values give the range of valid virtual LSNs for the region.
CLFS can tell by looking at the owner page of a virtual log LSN whether the record specified by the LSN resides in the current region or not. If the record does not reside in the current region, CLFS can decide whether it should search the previous region or the next region by comparing the virtual log LSN with the virtual log LSN range for the region.
When CLFS inserts log blocks into a multiplexed log’s physical FCB flush queue, if it finds that the current log block will overlap the owner page of the current region, it splits the current log block and inserts an owner page log block after the first half of the split log block (as shown in Figure 12-17). In other words, the owner page is written to disk only after the region that it describes becomes full. When a client reopens a multiplexed log file, CLFS scans the regions and rebuilds an in-memory owner page describing the latest region for which it hasn’t written an owner page log block.
Note that when reopening the log file, CLFS doesn’t know exactly where the log end LSN is, so it must find the LSN to avoid losing data or using corrupted data. For a dedicated log, CLFS reads the log blocks sequentially until an invalid log block is found and then sets the end of the log there. For a multiplexed log, CLFS reads the last owner page (the base log file saves a copy of the last flushed owner page’s LSN when the log metadata is last flushed) and verifies it is indeed valid. CLFS then reads the next region’s owner page repeatedly until an invalid owner page is found. After that, CLFS scans backward to find the first region with only valid log data blocks. CLFS then assumes the end of the log must fall within the next region. It will scan log block by log block until an invalid log block is found and then set the end of the log there.
CLFS relies on physical LSNs to identify log blocks within a physical log. However, CLFS combines several virtual logs in a physical log for multiplexed logs and uses virtual LSNs to locate log blocks in a virtual log. Therefore, for a virtual log client, a log block can be addressed both by a physical LSN and by a virtual LSN.
To translate a virtual log LSN to a physical log LSN, CLFS follows these steps:
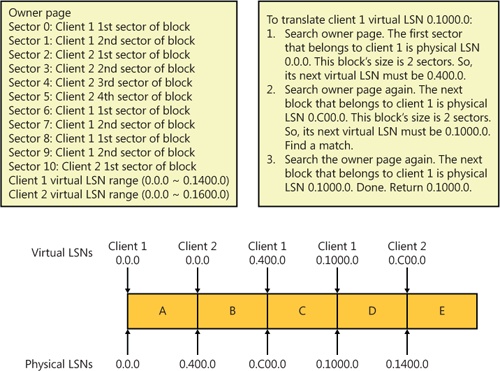
Reads the owner page for the region indicated by the virtual log LSN.
Checks the owner page’s virtual LSN region to see whether the virtual LSN is actually in the region or not. Most of the time the log block will be in the region.
If the virtual LSN is in the region, CLFS refers to the sector to client mapping in the owner page to find the physical LSN’s block offset. Given a client’s virtual LSN and its size, CLFS can calculate the virtual LSN of the next log block. Applying this rule, CLFS can deterministically calculate the physical LSN of every virtual log block in the region, as shown in Figure 12-18.
If the virtual LSN is not in the region, CLFS searches either the previous region or the next region depending on whether the virtual LSN is smaller or larger than the current region’s virtual LSN range.
Each CLFS log can be defined by a set of management policies that are configurable by the client. Table 12-5 lists these policies and their usage.
Table 12-5. CLFS Management Policies