Chapter 13
Device Programmability
A fully automated network is a lofty but challenging goal to realize with traditional interfaces and methods. Today the vast majority of network changes are performed manually. The mistakes and policy violations that are inherent to such manual processes are what lead to the majority of operational expenditures on network visibility and troubleshooting. Network engineers are simultaneously an organization’s greatest resource and its biggest source of risk. In contrast to the growth of rapid provisioning and configuration management in other areas of IT, the network has fallen behind. In an attempt to assist and accelerate adoption of network automation, attention must be given to not only the network controller but also the individual network element.
Device programmability describes the capability to extend configuration management, operational state, and traffic engineering through application programming interfaces (API) and open protocols. These APIs for the network element extend direct access to business support systems (BSS) and operational support systems (OSS). In addition, they can offload some level of effort from the network controller or configuration manager through model-based data abstractions to simplify configuration and provide consistency across platforms and new protocols, allowing a modern web-like interface to provide get and set transactions.
This chapter explains the following:
The current tools for network programmability, including their benefits and shortcomings
Model-based configuration and operational data in YANG
NETCONF, RESTCONF, and gRPC protocols
How telemetry leveraging YANG can expose normalized operational data
Tools to leverage programmability
New capabilities available via application hosting on IOS-XE platforms
Current State of Affairs
Traditional network engineers focused on learning command-line interfaces (CLI) across many platforms and vendors. It is a human skill that does not translate well to machines. However, engineers are by definition a resourceful bunch, and network engineers are no exception.
Many, if not most, engineers use Microsoft Notepad or spreadsheets leveraging Find/Replace as “configuration management” and then Copy/Paste the text into a console. This practice has been around for years and evolved using versioning tools to control release management of updating templates or adding new features or adding templates for different device types. In addition, the practice of documenting methods of procedure (MOP) as an ordered list of commands to enter and steps to verify is commonplace.
CLI Automation
Scripting configuration changes in Perl or Python is quite common; however, this is a very crude form of automation. While it solves some of the problems generated by “finger-defined networking” (i.e., manual typing of commands), it falls victim to an interface intended for human interaction, as CLI presents many syntax changes, modes, and prompts. Tools were painstakingly generated and shared by the open community in an attempt to mask some of the complexity.
The majority of CLI automation is based on Python Expect. A session is created to the network element and characters are interpreted by the script instead of passed to the screen. It is called Expect because the script waits for some expected characters to return before running the next line in the script. In the case of configuring a Cisco router, the script must be able to establish a connection over Secure Shell (SSL), handle encryption negotiation, determine whether the characters received are for a login prompt, a user mode prompt, an exec mode prompt, a configuration mode prompt, an interface configuration mode prompt, and the list goes on. The Expect script must know what characters it should receive from the remote device. This is usually a prompt, but all cases must be accounted for. If the session has a question or confirmation step before returning to the prompt, that must be accounted for as well. If a script receives something it did not expect, it continues waiting until it times out and ends in a failure with only the subset of intended commands prior to the unexpected result entered. If this sounds complex and painful, that’s because it is.
Fortunately, the open source community has created libraries and functions to assist in this effort. Paramiko is a Python (2.7+, 3.4+) implementation of the SSHv2 protocol, providing both client and server functionality. Netmiko took this a step further and is an implementation geared specifically for interacting with several network device types across vendors. These tools dramatically simplify configuration automation, but have some drawbacks. Because they are based on automating the interaction with the human interface, they are sensitive to the list of expected characters. Therefore, if there is a new configuration mode or some new command that requires a confirmation or additional response like yes/no before returning to the prompt, then those additional cases must be added by the user within their script or by the open source community in a newer version of the library. Additional shortcomings are that the errors or warnings sent by the network element are ignored or some logic must be added to interpret the text of the warning and react accordingly. Also, the error may be simply inadequate to respond to, such as
Invalid input detected at '^' marker.
There are even more advanced tools to help with CLI automation. These tools look to abstract the configuration as a description of the intended function, and include
Cisco Application Policy Infrastructure Controller Enterprise Module (APIC-EM), which leverages CLI automation for interacting with Cisco networking devices (while Cisco DNA Center is evolving to model-based programmability, as will be discussed later in this chapter).
Cisco Network Services Orchestrator (NSO), which utilizes the CLI in the Network Element Driver (NED) for communicating with devices that do not support modern programming interfaces.
NAPALM (Network Automation and Programmability Abstraction Layer with Multivendor support) is a Python library that implements a set of functions to interact with different network device operating systems using a unified API. Each device type has a driver to interpret the device specifics and convert to the unified API.
Ansible is an automation framework built in Python that uses data structures to represent the intended state of IT assets. It includes modules and plug-ins developed to abstract the communication with networking devices over SSH and present the user with a simple interface.
Although APIC-EM, NSO, NAPALM, and Ansible have masked considerable complexity of CLI automation (through considerable effort by their engineering staffs and the open source community), they still are built upon a brittle foundation of interpreting and sending text over a session to the network element. Therefore, each has, or is building, capabilities upon modern APIs and model-driven data, as discussed shortly.
Configuration is only a small part of managing a network. The vast majority of interactions with the network element are for gathering operational data. This can be accomplished via regular queries such as show processes cpu to monitor CPU utilization, show ip route to validate the current best path(s) to a destination, show inventory to conduct asset management, or show interface to troubleshoot individual network interfaces. Each of these commands has one thing in common—the output is intended to be viewed on a screen. The spacing is designed to present data visually in the most efficient and easy-to-consume manner for humans. How, then, can a script return data from a show command? By default, the response is returned as a single string, where all the whitespacing turns it into a mess. Regular expressions (regex) must be leveraged to pull out the interesting information from the response. This can be taken a few steps further by converting the text into a programming object such as a list or a set of key-value pairs as in a Python dictionary. For the regex savvy, this is not a problem, but those individuals are in short supply. Again, the open source community has come to the rescue with libraries of regex templates to use in conjunction with textfsm, an open source Python text parsing engine. However, these libraries are incomplete, subject to requiring update if a show command changes its output (this happens more often than you think) and require programming expertise to properly utilize.
SNMP
Simple Network Management Protocol (SNMP) is leveraged widely today for gathering data from the network elements and is generally regarded as reasonably suitable for device monitoring. However, SNMP is not without issues. Although it can be used for configuring devices, it is rarely used in this capacity by network administrators. This is at least in part due to the lack of writeable Management Information Base (MIB) elements, which makes it incomplete, and the fact that there is no concept of rollback or replay for SNMP writeable objects. A MIB Object Identifier (OID) is a string of numbers that uniquely identifies the specific item for which some data is retrieved, but it is hardly self-describing, nor is it obvious which OID relates to which item in the device configuration. In addition, SNMPv3 is the only version that includes security features such as authentication and encryption, but many devices are not SNMPv3 capable and, as such, it has not been widely adopted among network engineers. MIBs are nontrivial to develop and are relatively inflexible. SNMP also requires the running of an application on a server. RFC 35351 breaks down the shortcomings of SNMP for configuration and highlights the need for new methods for network management.
1 “Overview of the 2002 IAB Network Management Workshop”; https://tools.ietf.org/html/rfc3535
CLI automation is the symptom, not the disease. The issue lies with dependence upon configuration and operational data in unstructured text format. The modern tools do a lot to enable automation and, considering the CLI is the only method to reach the majority of devices in production networks, it isn’t going away anytime soon. Likewise, SNMP was initially developed back in 1988 and still is an invaluable tool for network monitoring.
Model-Based Data
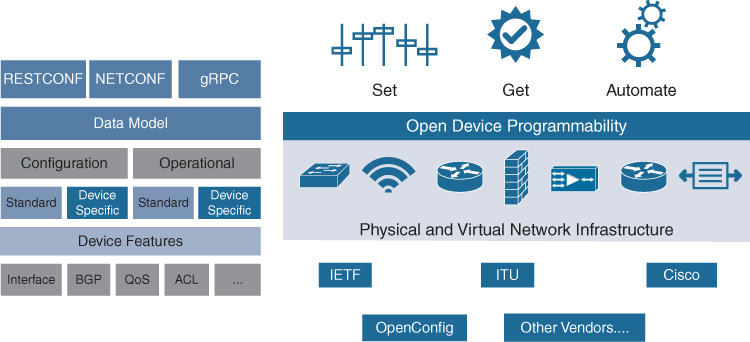
Given the lessons learned from CLI automation and SNMP, and borrowing concepts from other segments of IT led to a new method for representing data in a structured way. Instead of textual representation of information, the information is stored and transmitted in a machine-friendly format. Automation is run by machines and therefore the data that is sent or collected should be in a proper format. For example, consider how humans determined location and directions before smartphones. Maps were an excellent visual representation of geography for thousands of years. However, a map is a terrible input format for a machine. A machine cannot simply look around at landmarks or street signs and determine location. A program to convert a map to a digital format is a massive undertaking. Therefore, a new model was created with the machine perspective in mind. It represented the same location information, but instead in global positioning coordinates, a simple set of numbers to represent location exactly. From that simple concept, there now is Global Positioning System (GPS) capability on most mobile phones, leading to on-demand location awareness and all kinds of integration opportunities. Following this analogy, model-based data represents the networking device configuration in computer programming data structures that are easy for a machine to consume and share with other machines or applications. Figure 13-1 demonstrates this in a layered approach of model-based data as an abstraction of device configuration and operational data. These models are the basis of the payload that protocols transmit.
YANG
In the case of representing configuration of a network device, models are more flexible and abstract, which makes these better suited to the needs of the evolving and innovating field of networking. In addition, there must be strict rules to follow to allow the industry to collaborate and interoperate. Models explicitly and precisely define data structure, syntax, and semantics. Yet Another Next Generation (YANG) models look to create a mold for which the relevant network element data is stored in programming data structures. YANG was built with the following requirements:
Human readable
Hierarchical configuration
Extensible through augmentation
Formal constraints for configuration validation
Reusable types and groupings
Modularity through modules and submodules
Defined versioning rules
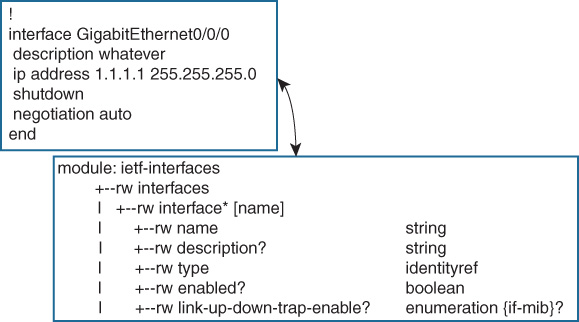
YANG is a programming language to model data. Its hierarchical tree structure is intended to organize the functionality of the device or service as nodes. Each node has a name and either child nodes or a value if it is a leaf in the tree. As seen in Figure 13-2, although it is built with programming data structures, it is still human readable and, in many cases, is recognizable compared to CLI configuration. YANG is structured in modules and submodules. Data is imported from external modules and is organized into model libraries to enable extensibility by augmentation by another module. YANG expresses constraints around data to match the constraints of the platform. For example, on Cisco switches, a user can configure a virtual local area network (VLAN) identifier (ID) between 1 and 4094, with the exception of 1002–1005 (which are reserved for token ring and Fiber Distributed Data Interface [FDDI]). This is represented as
type uint16 {
range "1..1001 | 1006..4094";
}
Concepts such as typedef and groupings allow for reuse of code. For example, a percent type can be limited to just reasonable values (0–100) and that type reused throughout the model. Groupings such as the common portion of an interface—name, description, and whether enabled—can be coded once and reused for interface definitions, as shown in Example 13-1.
Example 13-1 Programming Common Portions of Interface Configurations
grouping interface-common-config {
description
“Configuration data nodes common to physical interfaces and subinterfaces”;
leaf name {
type string;
}
leaf description {
type string;
}
leaf enabled {
type boolean;
default “true”;
}
}
YANG was created with flexibility in mind to allow models to be augmented or extended to add new features or functionality easily. YANG models are commonly used to configure devices or to deploy services. Also, YANG is not limited to networking devices or functions; the same concepts apply to representing the configuration of a hypervisor or server or even multiple systems all working together to deploy a service.
There are two sets of relevant data for network devices: configuration data (what the device is told to do) and operational data (what the device is doing and the state of its components). SNMP had both types together in MIBs and there was no way to easily separate them. With these states clearly distinguished, it is easier to set finer controls on what data is sent where or who is permitted access. It is also clearer to the consumer (of the data) what can be manipulated and what is simply feedback from the device. As shown in Example 13-2, the read/write (rw) components are configuration data, while the read-only (ro) components are operational data.
Example 13-2 YANG-Modeled Configuration (rw) and Operational (ro) Interface Data
(linuxhost)$ pYANG -f tree -p ietf-interfaces.YANG
module: ietf-interfaces
+--rw interfaces
| +--rw interface* [name]
| +--rw name string
| +--rw description? string
| +--rw type identityref
| +--rw enabled? boolean
| +--rw link-up-down-trap-enable? enumeration {if-mib}?
+--ro interfaces-state
+--ro interface* [name]
+--ro name string
+--ro type identityref
+--ro admin-status enumeration {if-mib}?
+--ro oper-status enumeration
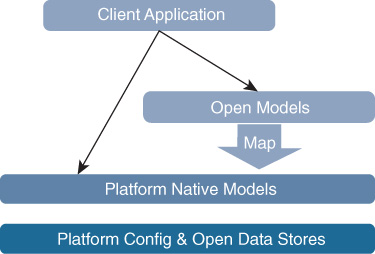
There are also two classes of YANG models, Open and Native, as illustrated in Figure 13-3. Native is specific to the vendor implementation; Open is created by the standards body (Internet Engineering Task Force [IETF]) or community (OpenConfig) to represent vendor-agnostic abstractions. Thus far, it seems the IETF models have wide coverage from a vendor perspective but minimal functional coverage of configurable items, whereas OpenConfig models have higher feature velocity as they are driven by the people who want to use them. Native models are generated directly by the vendor and cover all configuration and operational data available on the platform. Thanks to the modular and flexible nature of YANG, vendors can map the Open models to their Native model as opposed to directly coding the Open model into its operating system or configuration database.
Models are commonly written for a specific technology or service, which means there are models for interfaces, quality of service (QoS), routing protocols, MIB implementations, etc. With all the Open models and Native models, a device could support hundreds of models. Therefore, the versioning and maintenance of models is paramount to their usefulness. YANG models have strict rules for versioning to protect backward compatibility. Also, YANG model mapping and importing promote inclusion of new modules.
Protocols
With just the data model, there is no real improvement other than on the device itself. Protocols are introduced to take action and “do stuff” with the data. Using protocols and API applications together presents solutions that are more than the sum of their parts. To borrow from the map versus GPS analogy presented earlier, being aware of location is only minimally interesting. But with applications working together, the calendar app communicates with the mapping app and consumes input from the traffic feed app to warn the user when it’s time to leave for an important meeting, or even deviate a trip home based on a message requesting a stop by the grocery store. In the networking world, more data is available than ever before. But it’s the sharing of this data between applications (via open APIs) that allows for entirely new communication possibilities. Some examples are devices reporting new equipment directly to the asset management system; IT service management (ITSM) applications requesting relevant information from devices as a ticket is routed through queues; and adding information such as Border Gateway Protocol (BGP) peering states and interface statistics directly into the ticket automatically for better situational awareness and decision making. The protocols provide the transport to exchange the model-based data in an efficient, reliable, and globally consistent manner.
Encoding
YANG is just a representation of what can be configured on the device. Therefore, there must be a way to fill in the blanks with the intended configuration or operational data in the payload of the protocol’s transport. That is where the encoding comes into play. In this context, “encoding” describes the format to convert structured data to a serialized format for transmission. Because YANG is a tree structure, the encoding must provide a representation of data in a tree structure as well.
The following are the three most common encoding types in network programmability, as shown in Figure 13-4:

Extensible Markup Language (XML)
JavaScript Object Notation (JSON)
Yet Another Markup Language (YAML)
XML is the oldest encoding method and looks familiar to Hypertext Markup Language (HTML) coders and is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. XML represents key-value pairs where the value is surrounded by <key> and </key> tags to organize the data.
JSON is the current de facto standard encoding for web applications. It represents data objects as key-value pairs and common programming special characters such as [] to represent a list or array and {} to represent a dictionary object.
YAML is a favorite in situations in which humans must interact with the encoded data. It is the simplest, usually requires the least typing, and has multiple options to represent data. It leverages Python-style indentation to indicate nesting or leverages [] and {} characters like JSON. All three encoding types are supported by several programming languages and have conversion libraries to and from each format.
Google Protocol Buffers (protobufs or GPB) is a relatively new entry to the encoding landscape. A protobuf is a binary encoding of the data to transmit. Just like XML, JSON, and YAML, the objective is to represent structured data to be transmitted serially. However, protobufs offer two options, self-describing or compact. Self-describing is similar to the other encodings as the key-value pairs are maintained. However, with compact mode, only a key index and value are encoded. It achieves this by separating the data definition from the data itself by uniquely numbering the fields like an index. When compiling a protobuf, the generated .proto file represents the structure of the data, and from then on only the data is transmitted. Because only the data is transported with indexed fields and values versus the key-value pairs, a protobuf doesn’t lend itself to human readability. For example, if the field number 1 represents the device hostname, then only 1:RouterA is sent. However, the goal of using protobufs is speed, which is easily achieved because it is roughly 20 to 100 times faster than XML and 3 to 10 times smaller. Given its size and speed, it fits perfectly for use cases of streaming data. As such, protobufs is examined again later in the “Telemetry” section.
Network Protocols
Now that you are familiar with the model and encoding, next to consider is the transport. How does the data get from client to the server (i.e., the network device)? And vice-versa? That is the role of the protocols. Protocols such as Network Configuration Protocol (NETCONF), Representational State Transfer Configuration Protocol (RESTCONF), and Google Remote Procedure Call (gRPC) are built leveraging many years of lessons learned in IT and networking. The goal of exposing all configuration and operational data to nearly any application is now within grasp.
NETCONF
NETCONF, Network Configuration Protocol, was born from the networking community to specifically address shortcomings in available mechanisms for network management. The 2002 IAB Network Management Workshop outlined in RFC 3535 (previously cited) several requirements for a design for the next-generation network management protocol, including the following:
Distinction between configuration and state data
Multiple configuration datastores (candidate, running, and startup)
Configuration change transactions
Configuration testing and validation support
Selective data retrieval with filtering
Streaming and playback of event notifications
Extensible procedure call mechanism
NETCONF was built to support these requirements in RFC 47412 (which in turn was updated and obsoleted by RFC 62413), as illustrated in Figure 13-5. In addition, wherever possible, it leveraged common and best practices instead of creating new capabilities.
2 “NETCONF Configuration Protocol”; https://tools.ietf.org/html/rfc4741
3 “Network Configuration Protocol (NETCONF)”; https://tools.ietf.org/html/rfc6241
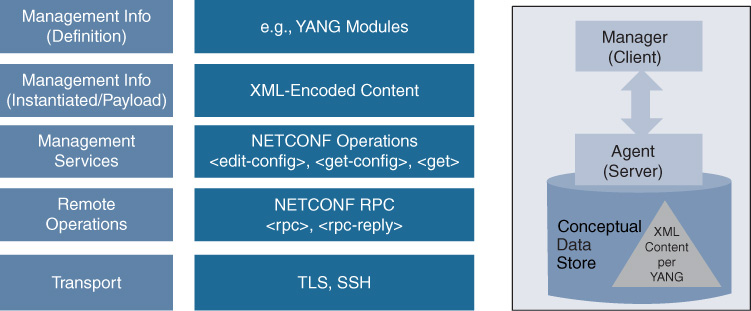
As with many protocols, it is easiest to start at the bottom. NETCONF Transport relies on SSH or Transport Layer Security (TLS). SSH is the most common implementation and is in use on Cisco devices supporting NETCONF. NETCONF is a session-oriented protocol and allows for multiple messages and responses. As SSH is very common and understood, it makes validating service availability a single step of ssh to port 830 with the netconf flag:
ssh –p 830 cisco@172.20.20.20 -s netconf
NETCONF uses Remote Procedure Call (RPC) for the Messages layer encoded as RPC messages and ensures responses to RPC as rpc-reply. The entire message, including the RPC message, is encoded in XML. The Operations layer describes the operations to edit or retrieve data as follows. The get operation retrieves both operational and configuration data, where the get-config is exclusive to configuration data. Similarly, edit-config only manipulates configuration data; operational data cannot be edited because it represents the state of the network device and its components. All RPC messages receive a response to indicate success or failure of the call. NETCONF operations are summarized in Table 13-1.
Table 13-1 NETCONF Operations Summary
Main Operations |
Description |
<get> |
Retrieves running configuration and device state information |
<get-config> |
Retrieves all or part of specified configuration datastore |
<edit-config> (close to configure terminal) |
Loads all or part of a configuration to the specified configuration datastore |
Other Operations |
Description |
<copy-config> |
Replaces an entire configuration datastore with another |
<delete-config> |
Deletes a configuration datastore |
<commit> |
Copies candidate datastore to running datastore |
<lock> / <unlock> |
Locks or unlocks the entire configuration datastore system |
<close-session> |
Gracefully terminates NETCONF session |
<kill-session> |
Forces termination of NETCONF session |
The concept of a datastore is also critical to understanding NETCONF. There are three possible configuration datastores:
Running
Startup
Candidate
The running configuration datastore is the configuration currently applied, similar to running-config on Cisco devices, and is the only one required.
The startup configuration datastore, as the name implies, is the configuration to be applied at the next boot, similar to startup-config in Cisco devices.
The candidate configuration datastore may be a new concept for individuals who have been exposed only to Cisco IOS or IOS-XE platforms. It is a temporary “scratchpad” for configuration. It allows for configuration to be entered to the device and committed to the running configuration completely, not line by line. NETCONF capability of a network device does not imply candidate store availability, because in some cases only the running store is available and saving configuration is via save-config RPC. In addition, not all datastores are writeable. In some cases, the running datastore is not writable. In these cases, the candidate datastore is the writeable datastore and the commit or copy RPC takes the action to move configuration to the running datastore.
The Content layer of the message holds the configuration to be edited in the case of an edit-config RPC or the operational or configuration data in a get or get-config RPC respectively. The scope of an RPC is filtered to limit the data returned in the rpc-reply or to describe where the edit-config data is applied.
The NETCONF stack, including the Messages (RPC), Operations, and Content layers, is illustrated in Figure 13-6.

Thus far there has been no mention of content conforming to a YANG model, and that is because NETCONF does not require YANG; in fact, NETCONF was created years before YANG was developed. Some devices are NETCONF 1.0 capable, which means conformance with RFC 4741, but RFC 6241 describes NETCONF 1.1, which leverages YANG for the data model.
One major advantage to NETCONF for configuration of network devices is transactionality. As per the RFC 3535 design requirements, transactions are paramount for configuration management. This allows all or none of a configuration to be applied; no in between. Therefore, if there is a syntax error or invalid entry in the edit-config, an error rpc-reply is returned describing the issue and no change is made. This differs dramatically from CLI automation. If a syntax error or some invalid entry is sent, all of the commands before the error are accepted, the invalid line is likely skipped, and some or all of the commands after the error may be applied. This creates an unknown and possible failed configuration.
With all the different NETCONF capabilities, supported RPCs, datastores, XML filtering options, and YANG models, there must be a way for a client to quickly determine the device capability. NETCONF includes a capability exchange included in the initial session handshake to share capabilities and supported YANG modules. In addition, a get-schema RPC is used to download the specified YANG module for the client to inspect the module directly.
NETCONF also supports subscribing and receiving asynchronous event notifications. This is discussed in the upcoming “Telemetry” section.
RESTCONF
RESTCONF, Representational State Transfer Configuration Protocol, is a method for interacting with YANG data as defined in NETCONF, but over the most common transport in the world: Hypertext Transfer Protocol (HTTP). RESTCONF was recently ratified in RFC 8040.4 RESTCONF is not a replacement for NETCONF, but rather a supplement to provide an alternative web-like interface to the underlying YANG data.
4 “RESTCONF Protocol”; https://tools.ietf.org/html/rfc8040
REST is a framework for stateless client-server communications that is the de facto standard among web services. It is an architectural style that specifies constraints to support consistent performance, scalability, and modifiability. For example, web browsers are able to explore complex server content with no prior knowledge of the remote resources. It is the server’s responsibility to supply locations of resources and required data. One key tenant is that the client and server must agree on media used. In the case of the Internet that content is HTML. REST content types range from JSON, XML, and HTML. Because REST most commonly is implemented in HTTP, it supports a set of operations or verbs: GET to retrieve data, POST to create an object, PUT to change content, POST to merge a change, and DELETE to remove an object. Another fundamental tenet of REST is the use of return codes. Each message receives an HTTP return code to provide information, success, redirection, or error information. Table 13-2 presents a comparison between RESTCONF and NETCONF.
Table 13-2 Comparison of RESTCONF and NETCONF
RESTCONF |
NETCONF |
GET |
<get-config>, <get> |
POST |
<edit-config> (operation="create") |
PUT |
<edit-config> (operation="create/replace") |
PATCH |
<edit-config> (operation="merge") |
DELETE |
<edit-config> (operation="delete") |
RESTCONF is described as REST-like, as it does not conform strictly to REST; this is because the media type is not application/json, but instead is a JSON or XML representation of the YANG model. This means the RESTCONF Uniform Resource Identifier (URI) and JSON or XML payload is based on the YANG model. The RESTCONF URI is illustrated in Figure 13-7.
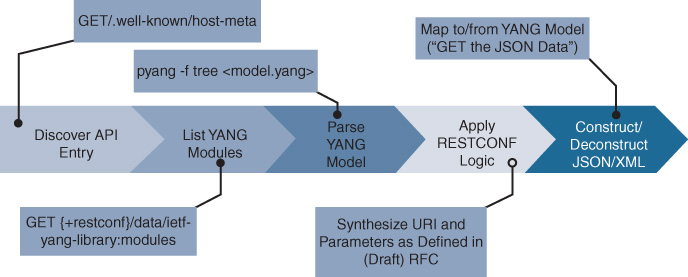
Not every client application supports NETCONF, but nearly any web-based service can leverage a REST-like interface. RESTCONF is a clientless, stateless, uniform protocol. Each communication is a single transaction to gather information or modify the state of the server. Similar to NETCONF, RESTCONF validates the entire message before editing any configuration data. RESTCONF supports familiar web operations such as these:
GET operations retrieve configuration data and state data; for example, getting current interface counters.
POST operations create new configuration data; for example, adding a loopback interface.
PUT operations perform a destructive replacement of configuration data (like a configuration replace); for example, changing the IP address of a given interface.
PATCH operations perform a configuration merge, similar to traditional copy and paste configuration changes; for example, adding interface descriptions to multiple interfaces.
DELETE operations remove an object; for example, removing a loopback interface.
gRPC
Remote Procedure Call (RPC) provides services that can be remotely called by clients. RPC specifies methods or functions with defined parameters and return types. Essentially RPC is running commands on a remote server without the hassle of automating SSH, Virtual Network Computing (VNC), or Remote Desktop Protocol (RDP) to run commands and return data. gRPC (Google Remote Procedure Call) is a flavor of RPC client-server application, where the remote services appear as a local object. gRPC creates objects on the client like classes and methods in C, Go, Java, Python, or Ruby that include “getters” (functions to return data) and “setters” (functions to set variables) that are remotely executed on the server.
There are four types of RPC:
Unary: A single request and response
Client streaming: A set of requests with a single response
Server steaming: A set of requests with several responses
Bidirectional streaming: A combination of client and server streaming, suited for multiple requests with multiple responses, where each stream is independent
Deadlines and timeouts are leveraged to terminate sessions. The server may wait to respond with its stream or the client can build the next request on the previous server response. A concept of channels is leveraged to modify the default client-server session by client specifying channel arguments.
The gRPC server listens on a port in either HTTP/2 or a raw Transmission Control Protocol (TCP) socket. HTTP/2 has slight overhead but offers built-in encryption and authentication of TLS. A raw TCP socket allows for flexibility and simplicity. gRPC authentication is quite flexible. It allows simple credentials, Secure Sockets Layer (SSL) with or without Google token-based authentication (used when communicating with Google services), or an external authentication system via code extension.
By default, gRPC leverages protobufs as the interface definition language (IDL) to describe the format of the messages and payload to properly interact with the services and data available on the remote server. These protobufs, as described earlier in the “Encoding” section, can be self-describing or compact. The efficiency, flexibility, and language bindings of protobufs make gRPC an attractive choice for interacting with a wide range of devices and services. gRPC is commonly used by large cloud computing environments and provides high-performant, scalable methods. The popularity of protobufs compute and container environments continues to pour over into networking use cases, and thus the list of networking devices that support gRPC continues to grow.
Telemetry
Today’s network devices create a wealth of state information, and analytics platforms perform impressive reporting, visibility, root cause analysis, and anomaly detection in our networks. Telemetry is the practice of gathering and storing that operational data and presenting it to the analytic platforms. In most networks today, that is commonly achieved by gathering system logs, SNMP polling and traps, and flow data (usually in the form of NetFlow). Unfortunately, these data-gathering methods are incomplete, inefficient, or have inconsistent formatting. SNMP MIBs may be structured independently and thus interpreted differently across vendors or even business units within vendors. Syslogs, while consistent in eight severity levels (from debug to emergency), are inconsistent in the formatting and content of messages across products as well. Efforts are underway to deliver products and services to normalize this data and present the analytics platforms with a consistent format, such as the Common Information Model (CIM). While CIM is a laudable initiative, it serves to solve only part of the problem, and requires constant updating (as new MIBs are created or as Syslog messages change from device version to version, etc.). At best CIM server to mask the inadequacies of these legacy mechanisms, and as such, only goes so far toward addressing messaging inconsistency.
Consider though: What if there was no need for normalization? Why not instead leverage model-based definitions in YANG? That way the data is self-describing, complete, extensible, and standardized. In addition, it makes sense to provide additional transport features such as low-latency, high-speed throughput, nonrepudiation, and a multi-destination subscription model. That’s exactly what NETCONF and gRPC telemetry streaming have set out to do, so as to meet the needs of network telemetry requirements.
There are several options and details to describe a specific telemetry stream, also known as a sensor group. Network devices support multiple streams, each with its own parameters such as direction, destinations, encoding, sample-interval, and paths. There are two types of transmission directions, dial-in and dial-out. These refer to who is the initiator of the conversation, the server or the client. This does not mean dial-in is polling of data. Once the initial session is established, the network device transmits telemetry data for the desired path at the designated interval. The set of stream destinations is configured statically by some means such as CLI or NETCONF for dial-out, but the subscription details are dynamic for dial-in mode, allowing clients to subscribe without configuration change. Encoding is also statically configured on the network device for the sensor group. Encoding for telemetry streaming options are JSON, self-describing gRPC, or compact gRPC. The sample interval is how often to gather statistics and transmit. Paths describe the YANG model path of interest that the particular sensor group transmits telemetry data per sample interval.
Collecting data—by itself—is not the end goal for telemetry, as the client needs to forward the data via telemetry to a data analytics stack, either directly or by leveraging a data bus to distribute the data. Projects such as Pipeline receive raw telemetry and transform it for data analysis before forwarding to a data bus, such as Kafka, to publish relevant streams to data analytics engines or big data platforms. In addition, there are collection stacks capable of directly consuming telemetry, such as ELK Stack (Elasticsearch, Logstash, and Kibana) or Splunk, to receive, store, and display data in a massively scalable and rich GUI to provide near-real-time situational awareness, historical trending, auditing, and powerful queries to correlate and search operational data.
gRPC Telemetry
As previously mentioned, using protobufs is dramatically more efficient in serializing data for transport. gRPC, by default, leverages those protobufs. There are two methods to represent YANG in protobufs. A .proto can be created to describe each model or a single .proto can describe all models. The single .proto cannot adequately index all models and therefore is self-describing (include key with value, not just index), and therefore is less efficient. Conversely, the unique .proto per model leverages compact mode. There are trade-offs to be made. There are operational advantages to a single .proto to maintain on the client, and human-readable key-value pairs of data in transit assist in troubleshooting and are easier to integrate. However, the compact protobuf encoding is about three times faster than self-describing.
gRPC’s HTTP/2 transport supports both dial-in and dial-out, while TCP supports only dial out.
Tools
While NETCONF, RESTCONF, gRPC, and YANG are quite interesting, they are limited in functionality without tools to harness their power. Fortunately, vendors and the open source community have created several projects and products to leverage the power of model-driven configuration, data, and telemetry.
Pyang is an open source project to validate a YANG module for correctness, convert it to additional formats, and even generate code in relation to the module. Pyang ensures syntax, module references, and conformance with standards. Common uses are to create a skeleton XML instance, convert to JSON, or display the graphical representations of the module as a simple tree or even a Unified Modeling Language (UML) diagram. Pyang also creates code in several languages, such as Python and Java, to build classes with similar structure to the module. Its ability to integrate plug-ins allow for the majority of features.
Ncclient is an open source Python NETCONF client. It is a Python library with an intuitive API to simplify interaction with XML whose goal is to make scripting NETCONF easier. It is an exhaustive client capable of all capabilities included in the NETCONF RFC (RFC 6241): edit-config, get-config, copy-config, delete-config, validate, get, discard-changes, commit, lock, unlock, confirmed-commit, rollback-on-error, datastore capabilities, url, xpath, etc. NCCLIENT is a commonly used NETCONF client and is leveraged in many open source tools and custom scripts and is integrated into some other NETCONF tools.
ConfD is a Cisco-developed tool (via its Tail-f acquisition) that models management interfaces in YANG. The underlying mechanism to communicate with devices can be NETCONF, RESTCONF, CLI, REST, web, or SNMP. Abstracting a non-model-driven configuration device in YANG provides significant advantages to integration with automation systems, as demonstrated in the “NETCONF” and “YANG” sections. While ConfD is not open source, it does offer a basic distribution at no cost. ConfD includes netconf-console, a command-line NETCONF client to communicate with devices.
NCC is a Python-based NETCONF client to facilitate communicating with devices. It includes edit-config and get-config and is an open project to allow extension. The same project includes Python scripts to poll, perform filtered get, and even download all schemas (YANG modules) to determine missing sources for import or include statements.
YANG-explorer is an open source project to visualize YANG modules and communicate with network elements. It loads in a web browser to give a simple interface to interact and explore YANG modules. It is an extensive multiuser client to build device profiles for multiple network elements, browse a YANG tree and drill down to properties, upload YANG modules from files or devices, build and execute RPCs against devices, save RPCs for later use, and even generate Python.
YANG Catalog is a recent addition to open source YANG tools thanks to the efforts of contributors and IETF Hackathons. There have been many YANG modules developed in recent years and YANG Catalog seeks to be a reference of the modules for developers to validate and add modules to the community, and a searchable library for operators to find the correct module to use. For example, it assists in finding the right module for the specific use case based on module type (service model or not), maturity level, if the module is implemented, vendor or equipment type, the contact, and if there is open source code available. It also validates YANG modules and visualizes dependencies or bottlenecks. It also integrates with YANG-explorer to test the YANG module against a device.
There are many common REST clients with similar features and capabilities, including Postman, PAW, Cocoa, Insomnia, and many more. Some clients are open source, some are free, and some require purchase. For example, Postman was created to help build, test, and document APIs faster. It has a simple and intuitive GUI to interact with a REST API. It includes a history of prior requests to make it easy to resend or modify a previously sent request. In addition, it includes collections as a feature to organize a set of REST calls for reuse or sharing. In addition, it supports variables for the same calls against different devices or environments. It also includes scripting capability to react based on responses, such as to save data in variables.
Ansible, an open source community project sponsored by Red Hat, is an automation platform for configuration management, software provisioning, and task automation. It uses data structure abstractions to represent the intended state of IT assets. It has broad acceptance among system administrators, where it is a mainstay in DevOps and hybrid IT environments. In the past few years Ansible has grown to include powerful network automation capabilities. Ansible represents a configured state in an easy-to-read YAML format as a set of tasks called a playbook. It provides looping and acts as a script manager across several devices. It is idempotent, which is to say if the element is found in the intended state already, such as a loopback exists and is configured with a given IP address, then nothing is done. However, if the element is in another state, the task leverages the code in the module to bring the element to the desired state, Ansible is commonly leveraged for networking to create configurations based on a template, deploy initial configurations to devices, deploy service-based configurations to devices individually or in a list, or gather facts about devices as a seed for later tasks or to return data to the user. As previously mentioned, Ansible leverages SSH, but it also has plug-ins and modules to utilize NETCONF as a method to interact with devices. In addition, Ansible is developing more functions and tools to abstract and simplify network configuration through its development team and the open source community. Ansible also includes a product called Ansible Tower to extend Ansible’s capability with a centralized point of job execution, GUI, dashboard, log aggregation, and workflow management for multiple playbooks. Ansible use has grown significantly due in part to the low barrier of entry from a skill and system requirements perspective and from an active community delivering rapid features.
Puppet is an open source software configuration management tool that inspects and operates IT infrastructure. Puppet leverages a declarative manifest to describe the intended state of a device or system of devices. Puppet clients regularly check in with the master to monitor devices to determine if they are in the desired state or take action upon the device. Puppet uses a resource abstraction of types and providers. A type is a human-readable model of a resource that includes a set of attributes as parameters or variables. A provider is a method with which to manipulate the resource described by the type. For example, a type may be an interface with several attributes such as name, encapsulation, IP address, etc., while the provider may be code with methods such as SSH to manipulate the endpoint. Puppet follows a pull model from the agent. The agent regularly checks in with the Puppet master to share relevant data. The Puppet server maintains a database of resources and interdependencies and displays them graphically. This presents a transactional behavior where the result of any requested configuration change is reported back to the server. Traditionally, Puppet requires an agent installed on the devices under management. Puppet developed agents for Nexus devices and types/providers to configure many tasks and provides a unique capability to Puppet users. However, most Cisco devices do not support agents and therefore require a different approach. YANG modules describe the configuration and operational data in a similar fashion to Puppet types. Leveraging the similarity, the Puppet engineering team and user community developed types based on the YANG module and providers via NETCONF transport. These efforts are underway and will provide a capability to manage IT infrastructure to include NETCONF 1.1-capable network devices all from a single platform.
YANG Development Kit (YDK) is an open source project created to ease and encourage network programmability using data models.
YDK has two components:
YDK-gen, which creates APIs in a variety of programming languages (including Python, Ruby, Go, C++, and C#)
The APIs that are generated from YDK-gen (such as YDK-Py or YDKcpp)
For the majority of relevant modules, such as IETF, OpenConfig, and native Cisco modules, the APIs are already created and available via the Python Package Index (PyPI). Additional APIs for modules not present, such as service models or other vendor models, are also created via YDK-gen.
Within the APIs there are three elements: models, services, and providers.
Models are a mirror of the YANG module. They take advantage of the similar structures and capabilities to create data structures within them. For example, YANG containers, lists, and leafs (of various types, such as integer, string, Boolean, enumeration, etc.) are analogous to Python classes, lists, and variables of various types (that can be extended to similar constructs as YANG).
Services are classes to perform the actions, including implementing the RPCs themselves—i.e., representing create, read, update, and delete (CRUD) actions, management protocols, direct access to the protocols, and a service to encode and decode data transmitted to/from the device.
Providers are classes to implement a service; for example, creating the NETCONF session or encoding in XML.
Depending on the situation, a single provider could implement multiple services or multiple providers may be required to implement a service. YDK was created for the programmer looking to control a network device. It creates a set of libraries to import into scripts or programs to abstract YANG directly to the programming language of choice with no need for XML or JSON payload, as in the case with ncclient or similar tools. YDK is open source and is an active project with regularly updated functionality and models. In addition, efforts are underway to integrate or leverage YDK within network automation platforms to accelerate their feature delivery.
Cisco Network Services Orchestrator (NSO) is a flexible and extensible network orchestration platform. It was designed for the entire service automation lifecycle from deploy, validate, and update/redeploy through decommission. It is another product developed by the Tail-f team within Cisco and is a superset of ConfD capability. Not only does NSO present a YANG abstraction to nearly any networking service or downstream device or system API (NETCONF, RESTCONF, CLI, REST, web, or SNMP) via Network Element Driver (NED), but it includes a GUI and comprehensive northbound API for system integration. In addition, the network service models integrate data from outside systems such as Internet Protocol Address Management (IPAM), operational support systems (OSS), or service provisioning systems like business support systems (BSS) to allow business data integrated to the service deployment automation. Also, the services may include advanced logic and programming in Java or Python to provision flexible services templates. NSO maintains a Configuration Database (CDB) that represents the state of the entire network. As such, configuration changes are committed in a “dry run” to determine the impact to the configuration without sending a single command to a device. Service instantiation is deployed as a single atomic transaction across the entire network or system. Therefore, if a single managed endpoint fails to accept the change, the entire system returns to the prior state. NSO provides an incredibly powerful and flexible automation framework, but such power leads to a higher learning curve or Advanced Services driven deployment. Common use cases are service providers deploying services across multiple devices within their network and network function virtualization (NFV) service provisioning.
Application Hosting
With the advancements in multiple cores and hypervisor support in modern processors and the industry shift toward microservices and containerization, opportunities now exist to extend compute resources throughout the enterprise leveraging the network infrastructure, as shown in Figure 13-8. Cisco traditionally has offered container or agent support on Nexus and service provider platforms and this capability is now available on enterprise networking devices as well via IOS XE. Primary concerns of application hosting and service containers are the impact to the network devices’ performance and security considerations. It is paramount that the container environment not negatively impact the management, control, and data planes of the network element. Therefore, performance and security is controlled via Linux container (LXC) technologies to isolate guest applications such as unprivileged containers or Linux kernel control groups (cgroups) for namespace isolation and resource limitation.
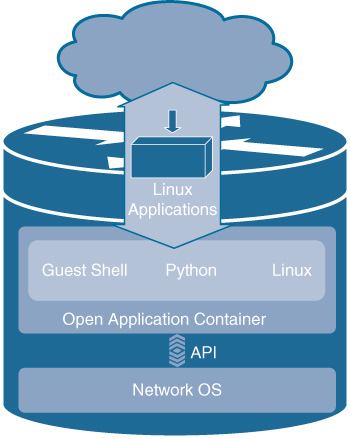
There are several use cases for application hosting on the network devices. Built into the IOS-XE software release is a Guest Shell to present a Linux environment to the user based on CentOS or Montavista Linux (depending on platform). This Guest Shell enables a Linux shell for scripting and Python environment with libraries for communication with network devices via traditional IP-based or backend CLI APIs. This environment allows for installing Linux applications and tools to extend scripting capability to the device. For example, a log parser could filter messages in search of prospective issues or Embedded Event Manager (EEM) tracking resource threshold transitions may call Python scripts to react or remediate problems locally. In addition to Guest Shell, application containers could be installed to support a myriad of use cases from network probes, distributed telemetry processing, data collection for bulk transport for devices with limited upstream connectivity, configuration management agents, asset management applications, or a customer-built application container. The options are nearly limitless as more and more services and applications provide container support.
Summary
This chapter discussed the many aspects of network device programmability and how the network element exposes additional functionality and abstract functions from the network controller. This chapter introduced the following:
Model-driven architecture: A structure of configuration and operational data built for machines avoids conversion of text or CLI input to data structures and presents an opportunity for integration with external applications and services.
Device APIs: These are the vehicles to transmit the model-based data. Leveraging industry-standard encoding and protocols, nearly any application can get or set data on the network element via RESTCONF. NETCONF was built by network management experts to address the needs of a network management protocol.
Telemetry: Device telemetry solves the problem of exporting data to analytics platforms by providing multi-destination, low-latency, model-based data transport.
Tools: A wide range of tools is available to leverage both legacy CLI methods and modern model-based APIs from both vendors and the open source community.
Application hosting: Multicore processors and Linux kernel features, container-based applications, and Linux guestshell can reside directly on the network device to extend capability and distribute workloads.
Leveraging these features extends networking capabilities to DevOps environments, rapid, reliable configuration deployment, and ubiquitous availability of operational data to OSSs and BSSs. Network device programmability facilitates machine-to-machine communications, adding value, capability, and scalability to the network operator. Network programmability is not a threat to network engineers, but rather is an enabler, as it minimizes mundane and repetitive tasks and lets the engineer work “up the stack” to more complex, interesting, and challenging projects like new technology adoption and building capabilities on top of programmability. Programmability reallocates network engineering efforts from operations and troubleshooting to engineering, testing, and development.
Further Reading
Tischer, R., and J. Gooley. Programming and Automating Cisco Networks: A Guide to Network Programmability and Automation in the Data Center, Campus, and WAN. Indianapolis: Cisco Press; 2016.