Chapter 1
Working with Arrays, Pointers, and References
IN THIS CHAPTER
 Working with arrays and multidimensional arrays
Working with arrays and multidimensional arrays
Understanding the connection between arrays and pointers
Dealing with pointers in all their forms
Using reference variables
When the C programming language, predecessor to C++, came out in the early 1970s, it was a breakthrough because it was small. C had only a few keywords. Tasks like printing to the console were handled not by built-in keywords but by functions. Technically, C++ still has few keywords, so it’s still small. So what makes C++ big?
- Its libraries are huge.
- It’s extremely sophisticated, resulting in millions of things you can do with the language.
In this chapter, you encounter the full rundown of topics that lay the foundation for C++: arrays, pointers, and references. In C++, these items come up again and again.
This chapter assumes that you have a basic understanding of C++ — that you understand the material in Books 1 and 2. You know the basics of pointers and arrays (and maybe just a teeny bit about references) and you’re ready to grasp them thoroughly. When you finish this chapter, you’ll have expanded on your knowledge enough to perform some intermediate and advanced tasks with relative ease.
 You don’t have to type the source code for this chapter manually. In fact, using the downloadable source is a lot easier. You can find the source for this chapter in the
You don’t have to type the source code for this chapter manually. In fact, using the downloadable source is a lot easier. You can find the source for this chapter in the \CPP_AIO4\BookV\Chapter01 folder of the downloadable source. See the Introduction for details on how to find these source files.
Building Up Arrays
As you work with C++ arrays, it seems like you can do a million things with them. This section provides the complete details on arrays. The more you know about arrays, the less likely you are to use them incorrectly, which would result in a bug. (The following sections don’t tell you about the std::array class described at https://en.cppreference.com/w/cpp/container/array. Instead, they discuss basic C++ arrays. Book 3, Chapter 1 provides a simple std::array example in the “Creating a declarative C++ example” section, and you get a more detailed look in the “Working with std::array” section in Chapter 6 of this minibook.)
Know how to get the most out of arrays when necessary — not just because they’re there. Avoid using arrays in the most complex way imaginable.
Declaring arrays
The usual way of declaring an array is to line up the type name, followed by a variable name, followed by a size in brackets, as in this line of code:
int Numbers[10];
This code declares an array of 10 integers. The first element gets index 0, and the final element gets index 9. Always remember that in C++, arrays start at 0, and the highest index is one less than the size. (Remember, index refers to the position within the array, and size refers to the number of elements in the array.) To declare an array of indeterminate size, leave out the size value, like this:
int Numbers[];
In certain situations, you can declare an array without putting a number in the brackets. For example, you can initialize an array without specifying the number of elements:
int MyNumbers[] = {1,2,3,4,5,6,7,8,9,10};
The compiler is smart enough to count how many elements you put inside the braces, and then the compiler makes that count the array size.
Specifying the array size helps decrease your chances of having bugs. Plus, it has the added benefit that, in the actual declaration, if the number in brackets does not match the number of elements inside braces, the compiler issues an error. The following
int MyNumbers[5] = {1,2,3,4,5,6,7,8,9,10};
yields this compiler error:
error: too many initializers for 'int [5]'
But if the number in brackets is greater than the number of elements, as in the following code, you won’t get an error. Instead, the remaining array elements aren’t defined, so you can’t access them. So be careful!
int MyNumbers[15] = {1,2,3,4,5,6,7,8,9,10};
You also can skip specifying the array size when you pass an array into a function, like this:
int AddUp(int Numbers[], int Count) {
int loop;
int sum = 0;
for (loop = 0; loop < Count; loop++) {
sum += Numbers[loop];
}
return sum;
}
This technique is particularly powerful because the AddUp() function can work for any size array. You can call the function like this:
cout << AddUp(MyNumbers, 10) << endl;
But this way to do it is kind of annoying because you have to specify the size each time you call in to the function. However, you can get around this problem. Look at this line of code:
cout << AddUp(MyNumbers, sizeof(MyNumbers) / 4) << endl;
With the array, the sizeof operator tells you how many bytes it uses. But the size of the array is usually the number of elements, not the number of bytes. So you divide the result of sizeof by 4 (the size of each int element).
But now you have that magic number, 4, sitting there. (By magic number, we mean a seemingly arbitrary number that’s stuffed somewhere into your code.) So a slightly better approach would be to enter this line:
cout << AddUp(MyNumbers, sizeof(MyNumbers) / sizeof(int))
<< endl;
Now this line of code works, and here’s why: The sizeof the array divided by the sizeof each element in the array gives the number of elements in the array. (You also see this technique demonstrated in the “Declaring and accessing an array” section of Book 2, Chapter 2.)
Arrays and pointers
The name of the array is a pointer to the array itself. The array is a sequence of variables stored in memory. The array name points to the first item. The following sections discuss arrays and pointers.
Seeing arrays as arrays and pointers
An interesting question about arrays and pointers is whether it’s possible to use a function header, such as the following line, and rely on sizeof to determine how many elements are in the array. If so, this function wouldn’t need to have the caller specify the size of the array.
int AddUp(int Numbers[]) {
Consider this function found in the Array01 example and a main() that calls it:
#include <iostream>
using namespace std;
void ProcessArray(int Numbers[]) {
cout << "Inside function: Size in bytes is "
<< sizeof(Numbers) << endl;
}
int main(int argc, char *argv[]) {
int MyNumbers[] = {1,2,3,4,5,6,7,8,9,10};
cout << "Outside function: Size in bytes is ";
cout << sizeof(MyNumbers) << endl;
ProcessArray(MyNumbers);
return 0;
}
When you run this application, here’s what you see:
Outside function: Size in bytes is 40
Inside function: Size in bytes is 4
Outside the function, the code knows that the size of the array is 40 bytes. However, inside the function the size reported is 4 bytes. The reason is that even though it appears that you’re passing an array, you’re really passing a pointer to an array. The size of the pointer is just 4, and so that’s what the final cout line prints.
Understanding external declarations
Declaring arrays has a slight idiosyncrasy. When you declare an array by giving a definite number of elements, such as
int MyNumbers[5];
the compiler knows that you have an array, and the sizeof operator gives you the size of the entire array. The array name, then, is both a pointer and an array! But if you declare a function header without an array size, such as
void ProcessArray(int Numbers[]) {
the compiler treats this as simply a pointer and nothing more. This last line is, in fact, equivalent to the following line:
void ProcessArray(int *Numbers) {
Thus, inside the functions that either line declares, the following two lines of code are equivalent:
Numbers[3] = 10;
*(Numbers + 3) = 10;
This equivalence means that if you use an extern declaration on an array, such as
extern int MyNumbers[];
and then take the size of this array, the compiler will get confused. Here’s an example: If you have two files, numbers.cpp and main.cpp, where numbers.cpp declares an array and main.cpp externally declares it (as shown in the Array02 example), you will get a compiler error if you call sizeof:
#include <iostream>
using namespace std;
extern int MyNumbers[];
int main(int argc, char *argv[]) {
cout << sizeof(MyNumbers) << endl;
return 0;
}
In Code::Blocks, the gcc compiler gives this error:
error: invalid application of 'sizeof' to incomplete type 'int []'
The solution is to put the size of the array inside brackets, such as extern int MyNumbers[10];. Just make sure that the size is the same as in the other source code file! You can fake out the compiler by changing the number, and you won’t get an error. But that’s bad programming style and just asking for errors.
Although an array is simply a sequence of variables all adjacent to each other in memory, the name of an array is really just a pointer to the first element in the array. You can use the name as a pointer. However, do that only when you really need to work with a pointer. After all, you really have no reason to write code that is cryptic, such as *(Numbers + 3) = 10;.
The converse is also true. Look at this function:
void ProcessArray(int *Numbers) {
cout << Numbers[1] << endl;
}
This function takes a pointer as a parameter, yet you access it as an array. Again, don’t write code like this; instead, you should try to understand why code like this works. That way, you gain a deeper knowledge of arrays and how they live inside the computer, and this knowledge, in turn, can help you write code that works properly.
Differentiating between pointer types
Even though this chapter tells you that the array name is just a pointer, the name of an array of integers isn’t the exact same thing as a pointer to an integer. Check out these lines of code (found in the Array03 example):
#include <iostream>
using namespace std;
int main() {
int LotsONumbers[50];
int x;
LotsONumbers = &x;
}
The code tries to point the LotsONumbers pointer to something different: something declared as an integer. The compiler doesn’t let you do this; you get an error. That wouldn’t be the case if LotsONumbers were declared as int *LotsONumbers; then this code would work. But as written, this code gives you a compiler error like this one:
error: incompatible types in assignment of 'int*' to 'int [50]'
This error implies the compiler does see a definite distinction between the two types, int* and int[50]. Nevertheless, the array name is indeed a pointer, and you can use it as one; you just can’t do everything with it that you can with a normal pointer, such as reassign it. These tips will help you keep your arrays bug-free:
- Keep your code consistent. If you declare, for example, a pointer to an integer, do not treat it as an array.
- Keep your code clear and understandable. If you pass pointers, it’s okay to take the address of the first element, as in
&(MyNumbers[0])if this makes the code clearer — though it’s equivalent to justMyNumbers. - When you declare an array, always try to put a number inside the brackets, unless you are writing a function that takes an array.
- When you use the
externkeyword to declare an array, also put the array size inside brackets. But be consistent! Don’t use one number one time and a different number another time. The easiest way to be consistent is to use a constant, such asconst int ArraySize = 10;in a common header file and then use that in your array declaration:int MyArray[ArraySize];.
Using multidimensional arrays
Arrays do not have to be just one-dimensional. Dimensions make it possible to model data more realistically. For example, a three-dimensional array would allow you to better model a specific place in 3-D space. The following sections discuss using multidimensional arrays.
Declaring a multidimensional array
You can declare a multidimensional array using a technique similar to a single-dimensional array, as shown in the Array04 example in Listing 1-1. The difference is that you must declare each dimension separately.
LISTING 1-1: Using a Multidimensional Array
#include <iostream>
using namespace std;
int MemorizeThis[10][20];
int main() {
for (int x = 0; x < 10; x++) {
for (int y = 0; y < 20; y++ ) {
MemorizeThis[x][y] = x * y;
}
}
cout << MemorizeThis[9][13] << endl;
cout << sizeof(MemorizeThis) / sizeof(int) << endl;
return 0;
}
When you run this, MemorizeThis gets filled with the multiplication tables. Here’s the output for the application, which is the contents of MemorizeThis[9][13], and then the size of the entire two-dimensional array:
117
200
And indeed, 9 times 13 is 117. The size of the array is 200 elements. Because each element, being an integer, is 4 bytes, the size of the array in bytes is 800.
 You can have many, many dimensions, but be careful. Every time you add a dimension, the size multiplies by the size of that dimension. Thus an array declared like the following line has 48,600 elements, for a total of 194,400 bytes:
You can have many, many dimensions, but be careful. Every time you add a dimension, the size multiplies by the size of that dimension. Thus an array declared like the following line has 48,600 elements, for a total of 194,400 bytes:
int BigStuff[4][3][5][3][5][6][9];
And the following array has 4,838,400 elements, for a total of 19,353,600 bytes. That’s about 19 megabytes!
int ReallyBigStuff[8][6][10][6][5][7][12][4];
 If you really have this kind of a data structure, consider redesigning it. Any data stored like this would be downright confusing. And fortunately, the compiler will stop you from going totally overboard. Just for fun, try this giant monster:
If you really have this kind of a data structure, consider redesigning it. Any data stored like this would be downright confusing. And fortunately, the compiler will stop you from going totally overboard. Just for fun, try this giant monster:
int GiantMonster[18][16][10][16][15][17][12][14];
You’ll get an error of:
error: size of array 'GiantMonster' is too large
Considering data type
The data type of your array also makes a difference. Here are some byte values for arrays of the same size, but using different types:
char CharArray[20][20]; // 400 bytes
short ShortArray[20][20]; // 800 bytes
long LongArray[20][20]; // 1,600 bytes
float FloatArray[20][20]; // 1,600 bytes
double DoubleArray[20][20]; // 3,200 bytes
Initializing multidimensional arrays
Just as you can initialize a single-dimensional array by using braces and separating the elements by commas, you can initialize a multidimensional array with braces and commas and all that jazz, too. But to do this, you combine arrays inside arrays, as in this code:
int Numbers[5][6] = {
{1,2,3,4,5,6},
{7,8,9,10,12},
{13,14,15,16,17,18},
{19,20,21,22,23,24},
{25,26,27,28,29,30}
};
The hard part is remembering whether you put in five arrays containing six subarrays or six arrays containing five subarrays. Think of it like this: Each time you add another dimension, it goes inside the previous dimension. That is, you can write a single-dimensional array like this:
int MoreNumbers[5] = {
100,
200,
300,
400,
500,
};
Then, if you add a dimension to this array, each number in the initialization is replaced by an array initializer of the form {1,2,3,4,5,6}. Then you end up with a properly formatted multidimensional array.
Passing multidimensional arrays
If you have to pass a multidimensional array to a function, things can get just a bit hairy. That’s because you don’t have as much freedom in leaving off the array sizes as you do with single-dimensional arrays. Suppose you have this function:
int AddAll(int MyGrid[5][6]) {
int x,y;
int sum = 0;
for (x = 0; x < 5; x++) {
for (y = 0; y < 6; y++) {
sum += MyGrid[x][y];
}
}
return sum;
}
So far, the function header is fine because it explicitly states the size of each dimension. But you may want to do this:
int AddAll(int MyGrid[][]) {
or maybe pass the sizes as well:
int AddAll(int MyGrid[][], int rows, int columns) {
But unfortunately, the compiler displays this error for both lines:
declaration of 'MyGrid' as multidimensional array
must have bounds for all dimensions except the first
The compiler is telling you that you must explicitly list all the dimensions, but it’s okay if you leave the first one blank, as with one-dimensional arrays.
So this crazy code will compile:
int AddAll(int MyGrid[][6]) {
The reason is that the compiler treats multidimensional arrays in a special way. A multidimensional array is not really a two-dimensional array, for example; rather, it’s an array of an array. Thus, deep down inside C++, the compiler treats the statement MyGrid[5][6] as if it were MyGrid[5] where each item in the array is itself an array of size 6. And you’re free not to specify the size of a one-dimensional array. Well, the first brackets represent the one-dimensional portion of the array. So you can leave that space blank, as you can with other one-dimensional arrays. But then, after that, you have to give the subarrays bounds, a specific number of entries.
When using multidimensional arrays, it’s often easier to think of them as an array of arrays. Either of the following function headers, for example, is confusing:
int AddAll(int MyGrid[][6]) {
int AddAll(int MyGrid[][6], int count) {
Here’s a way around this problem: Use a typedef, which is cleaner:
typedef int GridRow[6];
int AddAll(GridRow MyGrid[], int Size) {
int x,y;
int sum = 0;
for (x = 0; x < Size; x++) {
for (y = 0; y < 6; y++) {
sum += MyGrid[x][y];
}
}
return sum;
}
The typedef line defines a new type called GridRow. This type is an array of six integers. Then, in the function, you’re passing an array of GridRows.
Using this typedef is the same as simply using two brackets, except it emphasizes that you’re passing an array of an array — that is, an array in which each member is itself an array of type GridRow.
Arrays and command-line parameters
In a typical C++ application, the main() function receives an array and a count as command-line parameters — parameters provided as part of the command to execute that application at the command line. However, to beginning programmers, the parameters can look intimidating. But they’re not: Think of the two parameters as an array of strings and a size of the array. However, each string in this array of strings is actually a character array. In the old days of C, and earlier breeds of C++, no string class was available. Thus strings were always character arrays, usually denoted as char *MyString. (Remember, an array and a pointer can be used interchangeably for the most part). Thus you could take this thing and turn it into an array — either by throwing brackets at the end, as in char *MyString[], or by making use of the fact that an array is a pointer and adding a second pointer symbol, as in char **MyString. The following code from the CommandLineParams example shows how you can get the command-line parameters:
#include <iostream>
using namespace std;
int main(int argc, char *argv[]) {
int loop;
for (loop = 0; loop < argc; loop++) {
cout << argv[loop] << endl;
}
return 0;
}
Before you build your application, add some command-line arguments to it by choosing Project ⇒ Set Program’s Arguments to display the Select Target dialog box, shown in Figure 1-1. Type these arguments (one on each line) in the Program Arguments field and then click OK.
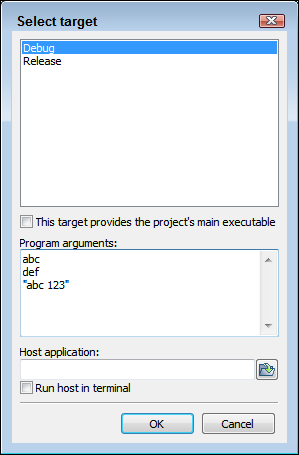
FIGURE 1-1: Use the Select Target dialog box to add program arguments.
You see the following output when you run the application. (Note that the application name comes in as the first parameter and the quoted items come in as a single parameter.)
C:\CPP_AIO4\BookV\Chapter01\CommandLineParams\bin\Debug\CommandLineParams.exe
abc
def
abc 123
The first argument is always the name of the executable. The executable name can be accompanied by the .exe extension, the executable path, and the drive on which the executable resides. What you see depends on your IDE and compiler.
Allocating an array on the heap
Arrays are useful, but it would be a bummer if the only way you could use them were as stack variables. This section shows an exception to not treating arrays as pointers by telling how you can allocate an array on the heap by using the new keyword. (If you can’t quite remember the difference between the stack and the heap, check out the “Heaping and Stacking the Variables” section in Book 1, Chapter 8.) But first you need to know about a couple of little tricks to make it work.
You can easily declare an array on the heap by using new int[50], for example. But think about what this is doing: It declares 50 integers on the heap, and the new word returns a pointer to the allocated array. But, unfortunately, the makers of C++ didn’t see it that way. For some reason, they based the array pointer type on the first element of the array (which is, of course, the same as all the elements in the array). Thus the call:
new int[50]
returns a pointer of type int *, not something that explicitly points to an array, just as this call does:
new int;
If you want to save the results of new int [50] in a variable, you have to have a variable of type int *, as in the following:
int *MyArray = new int[50];
In this case, an array name is a pointer and vice versa. So now that you have a pointer to an integer, you can treat it like an array:
MyArray[0] = 25;
Deleting an array from the heap
When you finish using the array, you can call delete. But you can’t just call delete MyArray;. The reason is that the compiler knows only that MyArray is a pointer to an integer; it doesn’t know that it’s an array! Thus delete MyArray will only delete the first item in the array, leaving the rest of the elements sitting around on the heap, wondering when their time will come. So the makers of C++ gave us a special form of delete to handle this situation. It looks like this:
delete[] MyArray;
If you’re really curious about the need for delete[] and delete, consider that there’s a distinction between allocating an array and allocating a single element on the stack. Look closely at these two lines:
int *MyArray = new int[50];
int *somenumber = new int;
The first allocates an array of 50 integers, while the second allocates a single array. But look at the types of the pointer variables: They’re both the same! They’re both pointers; each one points to an integer. And so the statement
delete something;
is ambiguous if something is a pointer to an integer: Is it an array, or is it a single number? The designers of C++ knew this was a problem, so they unambiguated it. They declared and proclaimed that delete shall delete only a single member. Then they invented a little extra that must have given the compiler writers a headache: They said that if you want to delete an array instead, just throw on an opening and closing bracket after the word delete. And all will be good.
Storing arrays of pointers and arrays of arrays
Because of the similarities between arrays and pointers, you are likely to encounter some strange notation. For example, in main() itself, you have seen both of these at different times:
char **argc
char *argc[]
If you work with arrays of arrays and arrays of pointers, the best bet is to make sure that you completely understand what these kinds of statements mean. Remember that although you can treat an array name as a pointer, you’re in for some technical differences. The following lines of code show these differences. First, think about what happens if you initialize a two-dimensional array of characters like this:
char NameArray[][6] = {
{'T', 'o', 'm', '\0', '\0', '\0'},
{'S', 'u', 'z', 'y' , '\0', '\0'},
{'H', 'a', 'r', 'r' , 'y', '\0'}
};
This is an array of an array. Each inner array is an array of six characters. The outer array stores the three inner arrays. (The individual content of an array is sometimes called a member — the inner array has six members and the outer array has three members.) Inside memory, the 18 characters are stored in one consecutive row, starting with T, then o, and ending with m and finally three copies of \0, which is the null character. But now take a look at this:
char* NamePointers[] = {
"Tom",
"Suzy",
"Harry"
};
This is an array of character arrays as well, except that it’s not the same as the code that came just before it. This is actually an array holding three pointers: The first points to a character string in memory containing Tom (which is followed by a null-terminator, \0); the second points to a string in memory containing Suzy ending with a null-terminator; and so on. Thus, if you look at the memory in the array, you won’t see a bunch of characters; instead, you see three numbers, each being a pointer.
It’s often helpful to see the content of memory as you work with arrays. To see memory in Code::Blocks, choose Debug ⇒ Debugging Windows ⇒ Memory Dump. You see the Memory window. Type & (ampersand) plus the name of the variable you want to view in the Address field and click Go. (You can also see the content of a specific memory address by typing its address, such as 0x28ff08, or the memory pointed to by a register by typing $ plus the register name, such as $sp.)
 So where on earth (or in the memory, anyway) are the three strings,
So where on earth (or in the memory, anyway) are the three strings, Tom, Suzy, and Harry when you have an array of three pointers to these strings? When the compiler sees string constants such as these, it puts them in a special area where it stores all the constants. These constants then get added to the executable file at link time, along with the compiled code for the source module. And that’s where they reside in memory. The array, therefore, contains pointers to these three constant strings in memory. Now, if you try to do the following (notice the type of PointerToPointer)
char **PointerToPointer = {
"Tom",
"Suzy",
"Harry"
};
you will get an error:
error: initializer for scalar variable requires one element
A scalar is just another name for a regular variable that is not an array. In other words, the PointerToPointer variable is a regular variable (that is, a scalar), not an array.
Yet, inside the function header for main(), you can use char **, and you can access this as an array. As usual, there’s a slight but definite difference between an array and a pointer. You can’t always treat a pointer as an array; for example, you can’t initialize a pointer as an array. But you can go the other way: You can take an array and treat it as a pointer most of the time. Thus you can do this:
char* NamePointers[] = {
"Tom",
"Harry",
"Suzy"
};
char **AnotherArray = NamePointers;
This code compiles, and you can access the strings through AnotherArray[0], for example. Yet you’re not allowed to skip a step and just start out initializing the AnotherArray variable like so:
char** AnotherArray = {
"Tom",
"Harry",
"Suzy"
};
If you write the code that way, it’s the same as the code shown just before this example — and it yields a compiler error! This is one (perhaps obscure) example in which the slight differences between arrays and pointers become obvious, but it does help explain why you can see something like this:
int main(int argc, char **argv)
and you are free to use the argv variable to access an array of pointers — specifically, in this case, an array of character pointers, also called strings.
Building constant arrays
If you have an array and you don’t want its contents to change, you can make it a constant array. The following lines of code, found in the Array05 example, demonstrate this approach:
const int Permanent[5] = { 1, 2, 3, 4, 5 };
cout << Permanent[1] << endl;
This array works like any other array, except you cannot change the numbers inside it. If you add a line like the following line, you get a compiler error, because the compiler is aware of constants:
Permanent[2] = 5;
Here’s the error you get when working in Code::Blocks:
error: assignment of read-only location 'Permanent[2]'
Arrays have a certain constancy built in. For example, you can’t assign one array to another. If you make the attempt (as shown in the Array06 example), the Code::Blocks compiler presents you with an error: invalid array assignment error message.)
int NonConstant[5] = { 1, 2, 3, 4, 5 };
int OtherList[5] = { 10, 11, 12, 13, 14 };
OtherList = NonConstant;
In other words, that third line is saying, “Forget what OtherList points to; instead, make it point to the NonConstant array, {1,2,3,4,5}!” The point is that arrays are always constant. If you want to make the array elements constant, you can precede its type with the word const. When you do so, the array name is constant, and the elements inside the array are also constant.
Pointing with Pointers
To fully understand C++ and all its strangeness and wonders, you need to become an expert in pointers. (Fortunately, many modern innovations in C++ are making the need to know pointers less of an issue — you have other means at your disposal, as discussed in Book 1, Chapter 8.) One of the biggest sources of bugs is when programmers who have a so-so understanding of C++ work with pointers and mess them up. But what’s bad in such cases is that the application may run properly for a while and then suddenly not work. Those bugs are the hardest bugs to catch, because the user may see the problem occur and then report it, but programmers can’t reproduce the problem. In this section, you see how you can get the most out of pointers and use them correctly in your applications so that you won’t have these strange problems.
Becoming horribly complex
You could see a function header like this:
void MyFunction(char ***a) {
Yikes! What are all those asterisks for? Looks like a pointer to a pointer to a pointer to … something! How confusing. Some humans have brains that are more like computers, and they can look at that code and understand it just fine, but most people can’t. The following sections help you understand how passing pointers to functions works.
Using a typedef
To understand the code, think about this: Suppose you have a pointer variable, and you want a function to change what the pointer variable points to. What this is saying is that the function wants to make the pointer point to something else, rather than change the contents of the thing that it points to. There’s a big difference between the two. Any time you want a function to change a variable, you have to either pass it by reference or pass its address. This process can get confusing with a pointer. One way to reduce the confusion is to define a new type — using the typedef word. It goes like this (as shown in the Pointer01 example):
typedef char *PChar;
This is a new type called PChar that is equivalent to char *. That is, PChar is a pointer to a character.
Now look at this function:
void MyFunction(PChar &x) {
x = new char('B');
}
This function takes a pointer variable and points it to the result of new char(’B’). That is, it points it to a newly allocated character variable containing the letter B. Now, think this through carefully: A PChar simply contains a memory address — really. You pass it by reference into the function, and the function modifies the PChar so that the PChar contains a different address. That is, the PChar now points to something different from what it previously did.
To try this function, here’s some code you can put in main() that tests MyFunction():
PChar ptr = new char('A');
PChar copy = ptr;
MyFunction(ptr);
cout << "ptr points to " << *ptr << endl;
cout << "copy points to " << *copy << endl;
The code creates two variables of type PChar: ptr and copy. It assigns a new char, ’A’, to ptr and then copies the address of ptr to copy so that they both point to the same location in memory. At this point, then, ptr and copy both have the same memory address in them.
Next, the code calls MyFunction(), which changes where ptr points in memory. On return from the function, the code prints two characters: the character that ptr points to and the character that copy points to. Here’s what you see when you run it:
ptr points to B
copy points to A
This means that MyFunction() worked! The ptr variable now points to the character allocated in MyFunction (a B), while the copy variable still points to the original A. In other words, they no longer point to the same thing: MyFunction() managed to change what the variable points to.
Using pointers to pointers
Now consider the same function, but instead of using references, try it with pointers. Here’s a modified form (as found in the Pointer02 example):
typedef char *PChar;
void AnotherFunction(PChar *x) {
*x = new char('C');
}
The parameter is really a char ** in this case. You could create another typedef to handle it, as in typedef char **PPChar;. Because the parameter is a pointer, you have to dereference it to modify its value. Thus you see an asterisk, *, at the beginning of the middle line. Here’s a modified main() that calls this function:
PChar ptr = new char('A');
PChar copy = ptr;
AnotherFunction(&ptr);
cout << "ptr points to " << *ptr << endl;
cout << "copy points to " << *copy << endl;
Because the function uses a pointer rather than a reference, you have to pass the address of the ptr variable, not the ptr variable directly. So notice that the call to AnotherFunction() has an ampersand, &, in front of the ptr. This code works as expected. When you run it, you see this output:
ptr points to C
copy points to A
This version of the function, called AnotherFunction(), made a new character called C. Indeed, it’s working correctly: ptr now points to a C character, and copy hasn’t changed. Again, the function pointed ptr to something else.
Avoiding typedefs
The previous examples created a typedef to make it much easier to understand what the functions are doing. However, not everybody does it that way; therefore you have to understand what other people are doing when you attempt to fix their code. So here are the same two functions found in the previous sections, MyFunction() and AnotherFunction(), but without typedef. Instead of using the new PChar type, they directly use the equivalent char * type:
void MyFunction(char *&x) {
x = new char('B');
}
void AnotherFunction(char **x) {
*x = new char('C');
}
To remove the use of the typedefs, all you do is replace the PChar in the two function headers and the variable declarations with its equivalent char *. You can see that the headers now look goofier. But they mean exactly the same as before: The first is a reference to a pointer, and the second is a pointer to a pointer.
But think about char **x for a moment. Because char * is also the same as a character array in many regards, char **x is a pointer to a character array. In fact, sometimes you may see the header for main() written like this
int main(int argc, char **argv)
instead of
int main(int argc, char *argv[])
Notice the argv parameter in the first of these two is the same type as we’ve been talking about: a pointer to a pointer (or, in a more easily understood manner, the address of a PChar). But you know that the argument for main() is an array of strings.
Using multiple typedefs
Now it’s time to consider what happens when you have a pointer that points to an array of strings and a function that is going to make it point to a different array of strings. The Pointer03 example begins by creating the required typedefs:
typedef char **StringArray;
typedef char *PChar;
StringArray is a type equivalent to an array of strings. In fact, if you put these two lines of code before your main(), you can actually change your main() header into the following and it will compile:
int main(int argc, StringArray argv)
Now here’s a function that will take as a parameter an array of strings, create a new array of strings, and set the original array of strings to point to this new array of strings:
void ChangeAsReference(StringArray &array) {
StringArray NameArray = new PChar[3];
NameArray[0] = "Tom";
NameArray[1] = "Suzy";
NameArray[2] = "Harry";
array = NameArray;
}
Just to make sure that it works, here’s something you can put in main():
StringArray OrigList = new PChar[3];
OrigList[0] = "John";
OrigList[1] = "Paul";
OrigList[2] = "George";
StringArray CopyList = OrigList;
ChangeAsReference(OrigList);
cout << OrigList[0] << endl;
cout << OrigList[1] << endl;
cout << OrigList[2] << endl << endl;
cout << CopyList[0] << endl;
cout << CopyList[1] << endl;
cout << CopyList[2] << endl;
The code creates a pointer to an array of three strings. It then stores three strings in the array. Next, the code saves a copy of the pointer in the variable called CopyList, changes the OrigList pointer by calling ChangeAsReference(), and prints all the values. Here’s the output:
Tom
Suzy
Harry
John
Paul
George
The first three outputs are the elements in OrigList, which were passed into ChangeAsReference(). They no longer have the values John,Paul, and George. The three original Beatles names have been replaced by three new names: Tom, Harry, and Suzy. However, the Copy variable still points to the original string list. Thus, once again, changing the pointer reference worked.
Working with string arrays using pointers
The previous section uses typedefs to work with string arrays, but you can also do it with pointers. Here’s the modified version of the function, this time using said pointers (as shown in the Pointer04 example):
void ChangeAsPointer(StringArray *array) {
StringArray NameArray = new PChar[3];
NameArray[0] = "Tom";
NameArray[1] = "Harry";
NameArray[2] = "Suzy";
*array = NameArray;
}
As before, here’s the slightly modified sample code that tests the function:
StringArray OrigList = new PChar[3];
OrigList[0] = "John";
OrigList[1] = "Paul";
OrigList[2] = "George";
StringArray CopyList = OrigList;
ChangeAsPointer(&OrigList);
cout << OrigList[0] << endl;
cout << OrigList[1] << endl;
cout << OrigList[2] << endl << endl;
cout << CopyList[0] << endl;
cout << CopyList[1] << endl;
cout << CopyList[2] << endl;
You can see that when the code calls ChangeAsPointer(), it passes the address of OrigList. The output of this version is the same as that of the previous version.
Here are the two function headers without using the typedefs:
int ChangeAsReference(char **&array) {
and
int ChangeAsPointer(char ***array) {
You may see code like these two lines from time to time. Such code isn’t the easiest to understand, but after you know what these lines mean, you can interpret them.
Most developers use a typedef, even if it’s just before the function in question. That way, it’s clearer to other people what the function does. You are welcome to follow suit. But if you do, make sure that you’re familiar with the non-typedef version so that you understand that version when somebody else writes it without using typedef.
Pointers to functions
When an application is running, the functions in the application exist in the memory; so just like anything else in memory, they have an address.
You can access the address of a function by taking the name of it and putting the address-of operator (&) in front of the function name, like this:
address = &MyFunction;
But to make this work, you need to know what type to declare address. The address variable is a pointer to a function, and the cleanest way to assign a type is to use auto, like this:
auto address = &MyFunction;
The traditional method is to use a typedef (as shown in the FunctionPointer01 example). Here’s the typedef you need:
typedef int(*FunctionPtr)(int);
It’s hard to follow, which is why using auto is better, but the name of the new type is FunctionPtr. This defines a type called FunctionPtr that returns an integer (the leftmost int) and takes an integer as a parameter (the rightmost int, which must be in parentheses). The middle part of this statement is the name of the new type, and you must precede it by an asterisk, which means that it’s a pointer to all the rest of the expression. Also, you must put the type name and its preceding asterisk inside parentheses. Now you’re ready to declare some variables! Here goes:
FunctionPtr address = &MyFunction;
This line declares address as a pointer to a function and initializes it to MyFunction(). For this to work, the code for MyFunction() must have the same prototype declared in the typedef: In this case, it must take an integer as a parameter and return an integer. So, for example, you may have a function like this:
int TheSecretNumber(int x) {
return x + 1;
}
Then you could have a main() that stores the address of this function in a variable — and then calls the function by using the variable:
int main() {
typedef int (*FunctionPtr)(int);
int MyPasscode = 20;
FunctionPtr address = &TheSecretNumber;
cout << address(MyPasscode) << endl;
}
Using the typedef approach has the advantage of specifying precisely what you want in the way of inputs, but the auto form is shorter and easier to understand. Here’s main() using the auto form (you must be using C++ 11 or above to use this form):
int main() {
int MyPasscode = 20;
auto address = &TheSecretNumber;
cout << address(MyPasscode) << endl;
}
Just so you can say that you’ve seen it, here’s what the address declaration would look like without using a typedef:
int (*address)(int) = &TheSecretNumber;
The giveaway should be that you have two things in parentheses side by side, and the set on the right has only types inside it. The one on the left has a variable name. So this line is not declaring a type; rather, it’s declaring a variable.
Pointing a variable to a method
When working with object-oriented programming (OOP), you need a way to access the methods within the object. Within an object’s code, you use the this pointer to obtain the address of an object’s method so that you can access the method instance data directly.
Remember that each instance of a class gets its own copy of the properties unless the properties are static. But methods are shared throughout the class. Yes, you can distinguish static methods from nonstatic methods. But doing so just refers to the types of variables they access: Static methods can access only static properties, and you don’t need to refer to them with an instance. Nonstatic (that is, normal, regular) methods work with a particular instance. However, inside the memory, really only one copy of the method exists.
So how does the method know which instance to work with? The this parameter gets passed into the method to differentiate between instances. Suppose you have a class called Gobstopper that has a method called Chew(). Next, you have an instance called MyGum, and you call the Chew() method, like so:
MyGum.Chew();
When the compiler generates assembly code for this, it actually passes a parameter into the function — the address of the MyGum instance, also known as the this pointer. Therefore only one Chew() function is in the code, but to call it, you must use a particular instance of the class.
Because only one copy of the Chew() method is in memory, you can take its address. But to do so requires some sort of cryptic-looking code. Here it is, quick and to the point. Suppose your class looks like this:
class Gobstopper {
public:
int WhichGobstopper;
int Chew(string name) {
cout << WhichGobstopper << endl;
cout << name << endl;
return WhichGobstopper;
}
};
The Chew() method takes a string and returns an integer. Here’s a typedef for a pointer to the Chew() function:
typedef int (Gobstopper::*GobMember)(string);
And here’s a variable of the type GobMember:
GobMember func = &Gobstopper::Chew;
As with other functions, you can use auto to make things simple when you work with C++ 11 or above. Here’s the auto form of a variable that points to the Chew() method:
auto func = &Gobstopper::Chew;
If you look closely at the typedef, it looks similar to a regular function pointer. The only difference is that the class name and two colons precede the asterisk. Other than that, it’s a regular old function pointer.
But whereas a regular function pointer is limited to pointing to functions of a particular set of parameter types and a return type, this function pointer shares those restrictions but has a further limitation: It can point only to methods within the class Gobstopper.
To call the function stored in the pointer, you need to have a particular instance. Notice that in the assignment of func in the earlier code, there was no instance, just the class name and function, &Gobstopper::Chew. So to call the function, grab an instance, add func, and go! The FunctionPointer02 example, shown in Listing 1-2, contains a complete example with the class, the method address, and two separate instances.
LISTING 1-2: Taking the Address of a Method
#include <iostream>
using namespace std;
class Gobstopper {
public:
int WhichGobstopper;
int Chew(string name) {
cout << WhichGobstopper << endl;
cout << name << endl;
return WhichGobstopper;
}
};
int main() {
typedef int (Gobstopper::*GobMember)(string);
GobMember func = &Gobstopper::Chew;
Gobstopper inst;
inst.WhichGobstopper = 10;
Gobstopper another;
another.WhichGobstopper = 20;
(inst.*func)("Greg W.");
(another.*func)("Jennifer W.");
return 0;
}
The code begins by creating a typedef called GobMember, as discussed earlier in this section. It then creates a method pointer, func, to access the method. When using C++ 11 or above, you can replace these two lines with the much easier-to-understand single line:
auto func = &Gobstopper::Chew;
Of course, when you use this alternative, the compiler must deduce the correct types, which it may not always do correctly. Using the typedef gives you additional control at the cost of complexity.
The code then creates two instances of Gobstopper, inst and another. In both cases, it directly assigns a value to WhichGobstopper, which will vary depending on instance and accessed through this. The final section calls the Chew() method indirectly using func in each instance and assigns a name as the input string.
When you run the code, you can see from the output that it is indeed calling the correct method for each instance:
10
Greg W.
20
Jennifer W.
Now, when you hear “the correct method for each instance,” what the statement really means is that the code is calling the same method each time but using a different instance. If you’re thinking in object-oriented terms, consider each instance as having its own copy of the method. Therefore it’s okay to say “the correct method for each instance.”
Pointing to static methods
A static method is, in many senses, just a plain old function. The difference is that you have to use a class name to call a static function. But remember that a static method does not go with any particular instance of a class; therefore you don’t need to specify an instance when you call the static function.
Here’s an example class (as shown in the FunctionPointer03 example) with a static function:
class Gobstopper {
public:
static string MyClassName() {
return "Gobstopper!";
}
int WhichGobstopper;
int Chew(string name) {
cout << WhichGobstopper << endl;
cout << name << endl;
return WhichGobstopper;
}
};
And here’s some code that takes the address of the static function and calls it by using the address:
int main() {
typedef string (*StaticMember)();
StaticMember staticfunc = &Gobstopper::MyClassName;
cout << staticfunc() << endl;
return 0;
}
Note that the call staticfunc() doesn’t refer to a specific instance and it doesn’t refer to the class, either. The application just called it. Because the truth is that deep down inside, the static function is just a plain old function.
Referring to References
This section discusses how to use references and assumes that you already know how to pass a parameter by reference when you’re writing a function. (For more information about passing parameters by reference, see Book 1, Chapter 8.) But you can use references for more than just parameter lists. You can declare a variable as a reference type. And just like job references, this use of references can be both good and devastating. So be careful when you use them.
Reference variables
Declaring a variable that is a reference is easy. Whereas the pointer uses an asterisk, *, the reference uses an ampersand, &. But it has a twist. You can’t just declare it, like this:
int &BestReference; // Nope! This won't work!
If you try this, you see an error that says BestReference declared as reference but not initialized. That sounds like a hint: Looks like you need to initialize it.
Yes, references need to be initialized. As the name implies, reference refers to another variable. Therefore, you need to initialize the reference so that it refers to some other variable, like so (as shown in the Reference01 example):
int ImSomebody;
int &BestReference = ImSomebody;
From this point on, the variable BestReference refers to — that is, is an alias for — ImSomebody. So, if you change the value of BestReference, as shown here:
BestReference = 10;
you’ll really be setting ImSomebody to 10. Look at this code that could go inside main():
int ImSomebody;
int &BestReference = ImSomebody;
BestReference = 10;
cout << ImSomebody << endl;
When you run this code, you see the output
10
That is, setting BestReference to 10 caused ImSomebody to change to 10, which you can see when you print the value of ImSomebody. That’s what a reference does: It refers to another variable.
Because a reference refers to another variable, that implies that you can’t have a reference to just a number, as in int &x=10. In fact, the offending line has been implicated: You are not allowed to do that. You can have only a reference that refers to another variable.
Returning a reference from a function
It’s possible to return a reference from a function. But be careful if you try to do this: You don’t want to return a reference to a local variable within a function, because when the function ends, the storage space for the local variables goes away.
But you can return a reference to a global variable. Or, if the function is a method, you can return a reference to a property.
For example, here’s a class found in the Reference02 example that has a function that returns a reference to one of its variables:
class DigInto {
private:
int secret;
public:
DigInto() { secret = 150; }
int &GetSecretVariable() { return secret; }
void Write() { cout << secret << endl; }
};
Notice that the constructor stores 150 in the secret variable, which is private. The GetSecretVariable() function returns a reference to the private variable called secret. The Write() function writes out the value of the secret variable. Lots of secrets here! And some surprises, too, which you discover shortly. You can use this class like so:
int main()
{
DigInto inst;
inst.Write();
int &pry = inst.GetSecretVariable();
pry = 30;
inst.Write();
auto &pry2 = inst.GetSecretVariable();
pry2 = 40;
inst.Write();
return 0;
}
The example uses two kinds of references, one int and one auto (you must have C++ 11 or above installed to use the second type). Notice that using auto doesn’t eliminate the need for the & to create a reference. If you were to write auto pry2 = inst.GetSecretVariable(); instead, you’d receive a warning message stating warning: variable ’pry2’ set but not used. However, the code would still compile, and if you use the Build ⇒ Build and Run option, you might not even notice the warning.
When you run this example, you see the following output:
150
30
40
Here’s a look at the code in a little more detail. The first output line is the value in the secret variable right after the application creates the instance. But look at the code carefully: The variable called pry is a reference to an integer, and it gets the results of GetSecretVariable().What is that result? It’s a reference to the private variable called secret — which means that pry itself is now a reference to that variable. Yes, a variable outside the class now refers directly to a private member in the instance! After that, the code sets pry to 30. When the code calls Write() again, the private variable will indeed change. (The same sequence occurs when you use the auto variable pry2.)
Creating code like this is a bad idea because it provides access to a private variable. The GetSecretVariable() function pretty much wipes out any sense of the variable’s actually remaining private. The main() function is able to grab a reference to it and poke around and change it however it wanted, as if it were not private!
That’s a problem with references: They can potentially leave your code wide open. Therefore, think twice before returning a reference to a variable. Here’s one of the biggest risks: Somebody else may be using this code, may not understand references, and may not realize that the variables called pry and pry2 have a direct link to the private secret variable. Such an inexperienced programmer might then write code that uses and changes pry or pry2 — without realizing that the property is changing along with it. Later on, then, a bug results — a pretty nasty one at that!
Because functions returning references can leave unsuspecting and less-experienced C++ programmers with just a wee bit too much power on their hands, it’s a best practice to use caution with references. No, you don’t have to avoid them altogether; it’s simply a good idea to be careful. Use them only if you really feel you must. But remember also that a better approach in classes is to have member access functions that can guard the private variables.
However, now that you’ve received the usual warnings, know that references can be very powerful, provided that you understand what they do. When you use a reference, you can easily modify another variable without having to go through pointers — which can make life much easier sometimes. So, please: Use your newfound powers carefully.