9
Maximizing Predictability in the
Stock and Bond Markets
9.1 Introduction
THE SEARCH FOR PREDICTABILITY in asset returns has occupied the attention of investors and academics since the advent of organized financial markets. While investors have an obvious financial interest in predictability, its economic importance can be traced to at least three distinct sources: implications for how aggregate fluctuations in the economy are transmitted to and from financial markets, implications for optimal consumption and investment policies, and implications for market efficiency. For example, several recent papers claim that the apparent predictability in long-horizon stock return indexes is due to business cycle movements and changes in aggregate risk premia.1 Others claim that such predictability is symptomatic of inefficient markets, markets populated with overreacting and irrational investors.2 Following both explanations is a growing number of proponents of market timing or tactical asset allocation, in which predictability is exploited, ostensibly to improve investors' risk-return trade-offs.3 Indeed, Roll (1988, p. 541) has suggested that “The maturity of a science is often gauged by its success in predicting important phenomena.”
For these reasons, many economists have undertaken the search for predictability in earnest and with great vigor. Indeed, the very attempt to improve the goodness-of-fit of theories to observations—Learner's (1978) so-called specification searches—can be viewed as a search for predictability. But as important as it is, predictability is rarely maximized systematically in empirical investigations, even though it may dictate the course of the investigation at many critical junctures and, as a consequence, is maximized implicitly over time and over sequences of investigations.
In this chapter, we maximize the predictability in asset returns explicitly by constructing portfolios of assets that are the most predictable, in a sense to be made precise below. Such explicit maximization can add several new insights to findings based on less formal methods. Perhaps the most obvious is that it yields an upper bound to what even the most industrious investigator can achieve in his search for predictability among portfolios.4As such, it provides an informal yardstick against which other findings may be measured. For example, approximately 10% of the variation in the CRSP equal-weighted weekly return index from 1962 to 1992 can be explained by the previous week's returns—is this large or small? The answer will depend on whether the maximum predictability for weekly portfolio returns is 15 or 75%.
More importantly, the maximization of predictability can direct us toward more disaggregated sources of persistence and time variation in asset returns, in the form of portfolio weights of the most predictable portfolio, and sensitivities of those weights to specific predictors, e.g., industrial production, dividend yield. A primitive example of this kind of disaggregation is the lead/lag relation among size-sorted portfolios uncovered by Lo and MacKinlay (1990b), in which the predictability of weekly stock index returns is traced to the tendency for the returns of larger capitalization stocks to lead those of smaller stocks. The more general framework that we introduce below includes lead/lag effects as a special case, but captures predictability explicitly as a function of time-varying economic-risk premia rather than as a function of past returns only.
In fact, the evidence for time-varying expected returns in the stock and bond markets in the form of ex-ante economic variables that can forecast asset returns is now substantial.5 Our results add to those of the existing literature in three ways: (1) We estimate the maximally predictable portfolio (MPP), given a specific model of time-varying risk premia; (2) we compute the sensitivities of this MPP with respect to ex-ante economic variables; and (3) we trace the sources of predictability, via the portfolio weights of the MPP, to specific industry sectors, market-capitalization classes, and stock/bond/utilities classes, over various holding periods.
Of course, both implicit and explicit maximization of predictability are forms of data snooping or data mining and may bias classical statistical inferences. But the biases from an explicit maximization are far easier to quantify and correct for—which we do below—than those from a series of informal and haphazard searches.6 Moreover, we develop a procedure for maximizing predictability that does not impart any obvious data-snooping biases (although subtle biases may always arise), using an out-of-sample rolling estimation approach similar to that of Fama and MacBeth (1973). We use a subsample to estimate the optimal portfolio weights, form these portfolios with the returns from an adjacent subsample, and obtain estimates of predictability by rolling through the data.
When applied to monthly stock and bond returns from 1947 to 1993, we find that predictability can be increased considerably both by portfolio selection and by horizon selection. For example, if we consider as our universe of assets the 11 portfolios formed by industry or sector classification according to SIC codes, for an annual return horizon the MPP has an R2 of 53%, whereas the largest R2 of the 11 regressions of individual sector assets on the same predictors is 40 percent.
Moreover, the weights of the MPP change dramatically with the horizon, pointing to differences across market capitalization and sectors for forecasting purposes. For example, using the 11 sector assets as our universe and a monthly return horizon, the MPP has a long position in the trade sector (with a portfolio weight of 36%), and a substantial short position in the durables sector (with a portfolio weight of –138%). However, at an annual return horizon, the MPP is short in the trade sector (–70%), and long in durables (126%). Although the portfolio weights are much less volatile for the shortsales-constrained cases, they still vary considerably with the return horizon. Such findings suggest distinct forecasting horizons for the various sector assets, and may signal important differences in how such groups of securities respond to economic events.
In Section 9.2, we motivate our interest in the MPP by showing that the typical two-step approach of searching for predictability—fitting a contemporaneous linear multifactor model, and then predicting the factors—may significantly understate the true magnitude of predictability in asset returns and overstate the number of factors required to capture the predictability. In contrast, the MPP provides a more accurate assessment of the predictable variation. The MPP is developed more formally in Section 9.3 and an example of its economic relevance is provided. In Section 9.4, we apply these results to monthly stock and bond data from 1947 to 1993 and estimate the MPP for three distinct asset groups: a 5-asset group of stocks, bonds, and utilities; an 11-asset group of sector portfolios; and a 10-asset group of size- sorted portfolios. To correct for the obvious biases imparted by maximizing predictability, we report Monte Carlo results for the statistical inference of the maximal R2's in Section 9.5. To gauge the economic significance of the MPP, in Section 9.6 we present three out-of-sample measures of the portfolio's predictability, measures that are not subject to the most obvious kinds of data-snooping biases associated with maximizing predictability. We conclude in Section 9.7.
9.2 Motivation
An increasingly popular approach to investigating predictability in asset returns is to follow a two-step procedure: (1) Construct a linear factor model of returns based on cross-sectional explanatory power, e.g., factor analysis, principal components decomposition, and (2) analyze the predictability of these factors. Such an approach is motivated by the substantial and still-growing literature on linear pricing models such as the CAPM, the APT, and its many variants in which expected returns are linearly related to contemporaneous “systematic” risk factors. Because time variation in expected returns can be a source of return predictability, several recent studies have followed this two-step procedure, e.g., Chen (1991), Ferson and Harvey (1991a, 1991b, 1993), and Ferson and Korajcyzk (1995).
While the two-step approach can shed considerable light on the nature of asset return predictability—especially when the risk factors are known—it may not be as informative when the factors are unknown. For example, it is possible that the set of factors that best explains the cross-sectional variation in expected returns is relatively unpredictable, whereas other factors that can be used to predict expected returns are not nearly as useful contemporaneously in capturing the cross-sectional variation of expected returns. Therefore, focusing on the predictability of factors that are important contemporaneously may yield a very misleading picture of the true nature of predictability in asset returns.
9.2.1 Predicting Factors vs. Predicting Returns
To formalize this intuition, consider a simple example consisting of two assets, A and B, which satisfy a linear two-factor model. In particular, let Rt denote the (2 × 1) vector of de-meaned asset returns [Rat Rbt]' and suppose that:

where δ ≡ [δa1 δb1]', δa2 ≡ [δa2 δb2], εt = [εat εbt]' is vector white noise with covariance matrix σ2εI, and F1t and F2t are the two factors that drive the expected returns of A and B. Without loss of generality, we assume that the two factors are mutually uncorrelated at all leads and lags, and have zero mean and unit variance; hence,

Now suppose that F1t is unpredictable through time, while F2t is predictable. In particular, suppose that F1t is a white-noise process, and that F2t is an AR(1):

where {ηt} is a white-noise process with variance 1 – β2 and independent of {εt,} and {F1t,}. Under these assumptions, expected returns are explained by two contemporaneous factors, of which one is white noise and the other is predictable. For later reference, we observe that under this linear two-factor model the contemporaneous covariance matrix and the first-order autocovariance matrix of Rt are given by

For the remainder of this section, we shall assume that while (9.2.1) is the true data-generating process, it is unknown to investors.
When the true factors F1t and F2t are unobserved, the most common approach to estimating (9.2.1) is to perform some kind of factor analysis or principal-components decomposition (see, e.g., Roll and Ross, 1980; Brown and Weinstein, 1983; Chamberlain, 1983; Chamberlain and Rothschild, 1983; Lehmann and Modest, 1985; Connor and Korajczyk, 1986, 1988). For this reason, a natural focus for the sources of predictability are the extracted factors or principal components. In our simple two-asset example, the first principal component is a portfolio ωPC1 which corresponds to the normalized eigenvector of the largest eigenvalue of the contemporaneous covariance matrix 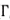 0 This yields the portfolio return
0 This yields the portfolio return

which may be interpreted as the linear combination of the two assets that “explains” as much of the cross-sectional variation in returns as possible. In this sense, RPC1,t may be viewed as the (cross-sectionally) “most important” factor. Therefore, this is a natural focus for the sources of predictability in expected returns.
How predictable is this most important factor? One measure is the theoretical or population R2 of a regression of RPCI,t on the lagged factors F1t–1 and F2t–1. This is given by

Observe that only the factor loading δ2 of factor 2 appears in the numerator of (9.2.8). Since factor 1 is white noise, it contributes nothing to the predictability of RPC1,t; hence δ1 plays no role in determining the R2. However, δ1 does appear implicitly in the denominator of (9.2.8) since it affects the variance of RPC1,t (see (9.2.5) ). Therefore, it is easy to see how an important cross-sectional factor may not have much predictability. By increasing the factor loading δ1, the first factor becomes increasingly more important in the cross section, but holding other parameters constant, this will decrease the predictability of RPC1,t
A second measure of predictability is the squared first-order autocorrelation coefficient of RPC1,t, which corresponds to the R2 of the regression of RPC1,t on RPC1,t–1. This is given by the expression

For similar reasons, it is apparent from (9.2.9) that an important cross-sectional factor need not reflect much predictability.
9.2.2 Numerical Illustration
For concreteness, consider the following numerical example:

Under these parameter values, the first principal-component portfolio RPC1,t accounts for 95.5% of the cross-sectional variation in returns, i.e., when the eigenvalues of 0 are normalized to sum to one, the largest eigenvalue is 0.955. However, the predictability of RPC1,t as measured by R2[RPC1,t] in (9.2.8) is a trivial 0.3%, and its squared own-autocorrelation is 0.0010%, despite the fact that factor 2 has an autocorrelation coefficient of 90%!
In Section 9.3, we shall propose an alternative to cross-sectional factors such as RPC1,t for measuring predictability: the MPP. In contrast to Rpc,t which is constructed by maximizing variance, the MPP is constructed by maximizing predictability or R2. For this reason, it provides a more direct measure of the magnitude and sources of predictability in asset returns data. Although we develop the MPP more formally in the next section, it is instructive to anticipate those results by comparing the predictability of the MPP to that of RPC1,t in this two-asset example.
As we shall see in Section 9.3, the MPP ωMPP is defined to be the nor malized eigenvector corresponding to the largest eigenvalue of the matrix  where
where  is the variance-covariance matrix of the one-step-ahead forecast of Rt using F1t–1 and F2t–1 (see Section 9.3 for further details and discussion). Substituting ωMPP for ωPC1 in (9.2.7) and (9.2.8) then yields a comparable measure of predictability for the MPP: R2 [RMPP,t]
is the variance-covariance matrix of the one-step-ahead forecast of Rt using F1t–1 and F2t–1 (see Section 9.3 for further details and discussion). Substituting ωMPP for ωPC1 in (9.2.7) and (9.2.8) then yields a comparable measure of predictability for the MPP: R2 [RMPP,t]
By calibrating the parameter values of (9.2.1) to monthly data (measured in percent per month), we can compare the predictability of the MPP to the PC1 portfolio directly. In particular, if we let

and let δa2 vary, we can see how well the two portfolios ωPC1 and ωPC1 reflect the predictability inherent in the two assets.
Table 9.1 reports the R2 measures for both portfolios under two different values for δa2. In panel (a), δa2 is set to 0.50, in which case the stocks A and B have R2's of 0.3 and 38.0%, respectively, and monthly standard deviations of 8.5 and 7.3%, respectively. In this case, observe that the PC1 portfolio has an R2 of only 9.6% and a squared own-autocorrelation ρ2(l) of only 1.1%, and this despite the fact that the squared own-autocorrelation of stock B is 17.9%. In contrast, the MPP has an R2 of 45.0% and a squared own-autocorrelation of 24.9%.
As δa2 is increased to 7.5, factor 2 becomes more important in determining the expected return of stock A, and its monthly variance also increases to 11.3%. In this case, the PC1 portfolio more accurately reflects the predictability in A and B, with an R2 and squared own-autocorrelation of 39.7 and 19.5%, respectively. Nevertheless, the MPP exhibits slightly more predictability, with an R2 and squared own-autocorrelation of 41.6 and 21.4%, respectively.
Table 9.1. Comparison of predictability of PC1 portfolio and MPP for a universe of two assets, A and Ba

aReturns satisfy a two-factor linear model where the first factor is white noise and the second factor is an AR(1) with autoregressive coefficient 0.90. Predictability is measured in two ways: the population R2 of the regression of each asset on the first lag of both factors, and the population squared own-autocorrelation ρ21 of each asset's returns. The return-generating processes for both assets are calibrated to correspond roughly to monthly returns (see the text for details).
9.2.3 Empirical Illustration
To illustrate the empirical relevance of the difference in the R2 of the PC1 portfolio and the MPP in this simple context, we anticipate the more detailed empirical analysis of Section 9.4 by performing the following simple calculation here. Using a sample of 11 sector portfolio returns and 6 predetermined factors, we calculate the sample R2 (see Section 9.4 for details about these portfolios and factors). Using monthly returns for the period 1947:1 to 1993:12, the sample R2 of the MPP is 12.0%, whereas the sample R2 of PC1 is only 7.2%. Similar results hold for annual returns. Using annual returns, the MPP R2 is 52.5% and the PC1 R2 is 35.5%. These results show that, empirically, the differences in the level of predictability of the returns on these two portfolios can be substantial.
This simple two-factor example illustrates the fact that while the PC1 portfolio may be interesting in studies of cross-sectional relations among asset returns, the MPP is more directly relevant when predictability is the object of interest. Furthermore, the sample R2 results suggest that the difference can be empirically important. In the following sections, we shall define the MPP more precisely and examine its statistical and empirical properties at length.
9.3 Maximizing Predictability
To define the predictability of a portfolio, we require some notation. Consider a collection of n assets with returns Rt ≡ [R1t R2t… Rnt]' and for convenience, assume the following throughout this section:7
(Al) Rt is a jointly stationary and ergodic stochastic process with finite expectation  and finite autocovariance matrices
and finite autocovariance matrices  where, with no loss of generality, we take k ≥ 0 since
where, with no loss of generality, we take k ≥ 0 since 
For convenience, we shall refer to these n assets as primary assets, assets to be used to construct the MPP, but they can be portfolios too.
Denote by Zt an (n x 1) vector of de-meaned primary asset returns, i.e., Zt ≡ Rt – µ, and let  t denote some forecast of Zt based on information available at time t – 1, which we denote by the information set Ωt–1. For simplicity, we assume that t is the conditional expectation of Zt with respect to Ωt–1 i.e.,
t denote some forecast of Zt based on information available at time t – 1, which we denote by the information set Ωt–1. For simplicity, we assume that t is the conditional expectation of Zt with respect to Ωt–1 i.e.,

which would be the optimal forecast under a quadratic loss function (although we are not assuming that such a loss function applies). We may then express Zt as

Included in the information set Ωt–1 are ex-ante observable economic variables such as dividend yield, various interest-rate spreads, earnings announcements, and other leading economic indicators. Therefore, with a suitably defined intercept term, (9.3.2) and (9.3.3) contain conditional versions of the CAPM (see Merton, 1973; Constantinides, 1980; and Bossaerts and Green, 1989), a dynamic multifactor APT (Ohlson and Garman, 1980, and Connor and Korajczyk, 1989), and virtually all other linear asset pricing models as special cases.
We also assume throughout that the εt's are conditionally homoskedastic and that the information structure {Ωt} is well behaved enough to ensure that t is also a stationary and ergodic stochastic process.8
9.3.1 Maximally Predictable Portfolio
Let γ denote a particular linear combination of the primary assets in Zt, and consider the predictability of this linear combination, as measured by the well-known coefficient of determination:

where

R2(γ) is simply the fraction of the variability in the portfolio return γ'Zt explained by its conditional expectation, y't. Maximizing the predictability of a portfolio of Zt then amounts to maximizing R2(γ) subject to the constraint that γ is a portfolio, i.e., γ'i = 1. But since R2(γ) = R2(cγ) for any constant c, the constrained maximization is formally equivalent to maximizing R2 over all γ, and then rescaling this globally optimal γ so that its components sum to unity.
Such a maximization is straightforward and yields an explicit expression for the maximum R2 and its maximizer, given by Gantmacher (1959) and Box and Tiao (1977).9 Specifically, the maximum of R2(γ) with respect to γ is given by the largest eigenvalue λ* of the matrix  and is attained by the eigenvector γ* associated with the largest eigenvalue of B. Therefore, when properly normalized, γ* is the MPP.10
and is attained by the eigenvector γ* associated with the largest eigenvalue of B. Therefore, when properly normalized, γ* is the MPP.10
Observe that the MPP has been derived from the unconditional co-variance matrices (9.3.5) and (9.3.6) and, as a result, it is constant over time. A time-varying version of the MPP also can be constructed, simply by replacing (9.3.5) and (9.3.6) with their conditional counterparts. In that case, the MPP must be recalculated in each period since the matrix Bt will then be a function of the conditioning variables and will vary through time.
However, to do this we require a fully articulated model of the conditional covariances of both Zt and ti which then must be estimated.11 Although this is beyond the scope of this chapter, recent empirical evidence suggests that the conditional moments of asset returns do vary through time (see Bollerslev, Chou, and Kroner, 1992, for a review), hence the conditional MPP may be an important extension from an empirical standpoint.
9.3.2 Example: One-Factor Model
To develop some intuition for the economic relevance of the MPP, consider the following example. Suppose we forecast excess returns Zt with only a single factor Xt–1, so that we hypothesize the relation

where β is an (n x 1) vector of factor loadings, and ∑ is any positive definite covariance matrix (not necessarily diagonal). Such a relation might arise from the CAPM, in which case Xt–1 is the period t–1 forecast of the market risk premium at time t.12 In this simple case, the relevant matrices may be calculated in closed form as

where σ2x ≡ Var[Xt–1]. The MPP γ* and its R2 are then given by

To develop further intuition for (9.3.11) and (9.3.12), suppose that ∑ = σ2ε I, so that the MPP and its R2 reduce to

Not surprisingly, with cross-sectionally uncorrelated errors, the MPP has weights directly proportional to the assets' betas. The larger the beta, the more predictable that asset's future return will be ceteris paribus; hence the MPP should place more weight on that asset. As expected, R2(γ*) is an increasing function of the signal-to-noise ratio σ2x/σε. But interestingly, the MPP weights γ* are not, and do not even depend on the σ2j's. This, of course, is an artifact of our extreme assumption that the assets' variances are identical. If, for example, we assumed that ∑ were a diagonal matrix with elements σ2j, j = 1, …, n, then the portfolio weights γ*j would be proportional to βj/σ2j. The larger the βj, the more weight asset j will have in the MPP, and the larger the σ2j, the less weight it will have.
Since the level of predictability of γ* does depend on how important Xt–1 is in determining the variability of Zt, in the case where ∑ = σ2εI as the signal-to-noise ratio increases the R2 of the MPP also increases, eventually approaching unity as σ2x /σ2ε increases without bound. Also, from (9.3.14) it is apparent that R2(γ*) increases with the number of assets ceteris paribus, since β'β is simply the sum of squared betas. Of course, even in the most general case, R2(γ*) must be a nondecreasing function of the number of assets because it is always possible to put zero weight on any newly introduced assets.
9.4 An Empirical Implementation
To implement the results of Section 9.3, we must first develop a suitable forecasting model for the vector of excess returns Zt. Using monthly data from 1947:1 to 1993:12, we consider three sets of primary assets for our vector Zt: (1) a five-asset group, consisting of the S&P 500, a small stock index, a government bond index, a corporate bond index, and a utilities index; (2) a 10-asset group consisting of deciles of size-sorted portfolios constructed from the CRSP monthly returns file; and (3) an 11-asset group of sector-sorted portfolios, also constructed from CRSP. The 11 sector portfolios are defined according to SIC code classifications: (1) wholesale and retail trade; (2) services; (3) nondurable goods; (4) construction; (5) capital goods; (6) durable goods; (7) finance, real estate, and insurance; (8) transportation; (9) basic industries; (10) utilities; and (11) coal and oil. Within each portfolio, the size-sorted portfolios and the sector-sorted portfolios are value weighted.
9.4.1 The Conditional Factors
In developing forecasting models for the three groups of assets, we draw on the substantial literature documenting the time variation in expected stock returns to select our conditional factors. From empirical studies by Rozeff (1984), Chen, Roll, and Ross (1986), Keim and Stambaugh (1986), Breen, Glosten, and Jagannathan (1989), Ferson (1990), Chen (1991), Estrella and Hardouvelis (1991), Ferson and Harvey (1991b), Kale, Hakansson, and Platt (1991), and many others, variables such as the growth in industrial production, dividend yield, and default and term spreads on fixed-income instruments have been shown to have forecast power. Also, the asymmetric lead/lag relations among size-sorted portfolios that Lo and MacKinlay (1990b) document suggest that lagged returns may have forecast power. Therefore, we were led to construct the following variables:
DYt Dividend yield, defined as the aggregated dividends for the CRSP value-weighted index for the 12-month period ending at the end of month t divided by the index value at the end of month t.
DEFt The default spread, defined as the average weekly yield for low-grade bonds in month t minus the average weekly yield for long-term government bonds (maturity greater than 10 years) in month t. The low grade bonds are rated Baa.
MATt, The maturity spread, defined as the average weekly yield on long-term government bonds in month t minus the average weekly yield from the auctions of three-month Treasury bills in month t.
SPRt The S&P 500 Index return, defined as the monthly return on a value-weighted portfolio of 500 common stocks.
IRTt, The interest-rate trend, defined as the monthly change of the average weekly yield on long-term government bonds.
SPDYt An interaction term to capture time variation in asset return betas, defined as the product DYtSPRt, of the dividend yield and the S&P 500 Index return variables.
Of course, there is a possible pre-test bias in our choosing these variables based on prior empirical studies. For example, Foster et al. (1995) show that choosing k out of m regressors (k < m) to maximize R2 can yield seemingly significant R2's even when no relation exists between the dependent variable and the regressors. They show that such a specification search may explain the findings of Keim and Stambaugh (1986), Campbell (1987), and Ferson and Harvey (1991a).13
Unfortunately, Foster et al.'s (1995) pre-test bias cannot be corrected easily in our application, for the simple reason that our selection procedure does not correspond precisely to choosing the “best” k regressors out of m. There is no doubt that prior empirical findings have influenced our choice of conditional factors, but in much subtler ways than this. In particular, theoretical considerations have also played a part in our choice, both in which variables to include and which to exclude. For example, even though a January indicator variable has been shown to have some predictive power, we have not included it as a conditional factor because we have no strong theoretical motivation for such a variable.
Because a combination of empirical and theoretical considerations has influenced our choice of conditional factors, Foster et al.'s (1995) corrections are not directly applicable. Moreover, if we apply their corrections without actually searching for the best k of m regressors, we will almost surely never find predictability even if it exists, i.e., tests for predictability will have no power against economically plausible alternative hypotheses of predictable returns. Therefore, other than alerting readers to the possibility of pre-test biases in our selection of conditional factors, there is little else that we can do to correct for this ubiquitous problem.
The final specification for the conditional factor model for Zt is then given by

The interaction term SPDYt–1 allows the factor loading of the S&P 500 to vary through time as a linear function of the dividend yield DYt–1.14
9.4.2 Estimating the Conditional-Factor Model
Table 9.2-9.4 report ordinary least squares estimates of the conditional-factor model (9.4.1) for the three groups of assets, respectively: the (5 × 1) vector of stocks, bonds, and utilities (SBU) ; the (10 × 1) vector of size deciles (SIZE); and the (l l × l) vector of sector portfolios (SECTOR). Panel (a) of
Table 9.2. Ordinary least squares regression results for individual asset returns in SBU asset group from 1947:1 to 1993:12

aDY = dividend yield; DEF = default premium; MAT = maturity premium; SPR = S&P 500 Index total return; SPDY = SPR x DY; IRT = interest-rate trend. The five assets in the SBU group are the S&P 500 Index, a small stock index, a government bond index, a corporate bond index, and a utilities index. Heteroskedasticity-consistent z-statistics are given in parentheses.
bDurbin-Watson test statistic for dependence in the regression residual.
Table 9.2 contains results for monthly SBU returns and Panel (b) contains annual results, and similarly for Tables 9.3 and 9.4.15 We perform all multi-horizon return calculations with nonoverlapping returns since Monte Carlo and asymptotic calculations in Lo and MacKinlay (1989a) and Richardson and Stock (1990) show that overlapping returns can bias inferences substantially.
The performance of the conditional factors in the regressions of Tables 9.2-9.4 are largely consistent with findings in the recent empirical literature. Among the equity assets, the dividend yield is positively related to future returns and generally significant at the 5% level. The default premium generally has little incremental explanatory power for future returns. Additional analysis indicates that its usual explanatory power is captured by the interest-rate trend variable. The maturity premium has predictive power mostly for the utilities asset at the annual horizon. In contrast, the S&P 500 Index return and the interest-rate trend variables are strongest at the monthly horizon, the former affecting expected returns positively, and the latter negatively. For the bond assets, most of the forecastability is from the positive relation with the maturity spread.
From Tables 9.2-9.4, it is also apparent that the market betas for monthly equity returns exhibit substantial time variation since the SPDY regressor is significant at the 5% level for the small stocks in Panel (a) of Table 9.2, and for most of the assets in Panel (a) of Tables 9.3 and 9.4. In these cases, the estimated coefficient of SPDY is consistently negative, indicating that the sensitivity of equity assets to the lagged aggregate market return declines as the dividend yield rises. Note that in each of these cases DY has additional explanatory power as a separate regressor, as its estimated coefficient is also significant at conventional levels.
At the annual return-horizon, the market beta and the time variation in market beta's remains significant for the equity assets. In Panel (b) of Tables 9.2, 9.3, and 9.4, the coefficients for SPR and SPDY are statistically significant in many of the regressions. Also, DY is still significant, and in all cases the R2 is larger for annual returns. In particular, whereas the R2's for monthly asset returns reported in Panel (a) of Tables 9.2, 9.3, and 9.4 range from 3 to 9%, the R2's for annual asset returns range from 16 to 44% in Panel (b) of Tables 9.2, 9.3, and 9.4.16
Of course, like any other statistic, the R2 is a point estimate subject to sampling variation. Since longer-horizon returns yield fewer nonoverlapping observations, we might expect the R2's from such regressions to exhibit larger fluctuations, with more extreme values than regressions for monthly data. We shall deal explicitly with the sampling theory of the R2 in Section 9.5.
Table 9.3. Ordinary least squares regression results for individual asset returns in the SIZE asset group from 1947:1 to 1993:12


aDY = dividend yield; DEF = default premium; MAT = maturity premium; SPR = S&P 500 Index total return; SPDY = SPR x DY; IRT = interest-rate trend. The 10 SIZE assets are portfolios of stocks grouped according to their market
value of equity. Heteroskedasticity-consistent z-statistics are given in parentheses.
bDurbin-Watson test statistic for dependence in the regression residual.
Table 9.4. Ordinary least squares regression results for individual asset returns in the SECTOR asset group from 1947:1 to 1993:12


aDY = dividend yield; DEF = default premium; MAT = maturity premium; SPR = S&P 500 Index total return; SPDY = SPR x DY; IRT = interest-rate trend. The eleven SECTOR assets are portfolios of stocks grouped according to their SIC codes. Heteroskedasticity-consistent z-statistics are given in parentheses.
bDurbin-Watson test statistic for dependence in the regression residual.
9.4.3 Maximizing Predictability
Given the estimated conditional-factor models in Tables 9.2-9.4, we can readily construct the (sample or estimated) MPP's. Given the estimate  ≡
≡  the estimated MPP
the estimated MPP  * is simply the eigenvector corresponding to the largest eigenvalue of .
* is simply the eigenvector corresponding to the largest eigenvalue of .
We will also have occasion to consider the constrained MPPγ*c, constrained to have nonnegative portfolio weights. It will become apparent below that an unconstrained maximization of predictability yields considerably more extreme and unstable portfolio weights than a constrained maximization. Moreover, for many investors, the constrained case may be of more practical relevance. Although we do not have a closed-form expression for γ*c, it is a simple matter to calculate it numerically. Again, given , we may obtain γ*c in a similar manner.
In Table 9.5, we report the conditional-factor model of the MPP for the SBU, SIZE, and SECTOR portfolios, constrained and unconstrained, for monthly and annual return-horizons using the factors of Section 9.4.1. In Panel (a) of Table 9.5, the patterns of the estimated coefficients are largely consistent with those of Table 9.2: The coefficient of the interaction variable SPDY is negative, though insignificant for monthly returns; the coefficient of dividend yield DY is positive and significant for all portfolios; and the maximal R2 increases with the horizon.
As expected, the maximal R2's are larger than the largest R2,s of the individual portfolio regressions. For example, the monthly constrained maximal R2 is 9%, and the S&P 500 regression in Panel (a) of Table 9.2 has an R2 of 7%. There is somewhat more improvement at an annual horizon. For example, the unconstrained maximal R2 is 50% at an annual horizon, whereas the R2's for the annual returns of the five individual assets in Panel (b) range from 34 to 43%.
Panels (a) and (b) of Table 9.5 exhibit similar findings for the SIZE and SECTOR assets. The R2's of monthly size portfolios range from 6 to 8% in Panel (a) of Table 9.3, whereas Panel (b) of Table 9.5 reports the unconstrained maximal R2 to be 12%, and the constrained to be 8%. But at an annual horizon, the R2's for individual size portfolios range from 23 to 44%, while the maximal constrained and unconstrained R2's from Table 9.5 are 45 and 61%, respectively.
Table 9.5. Conditional expected return of MPP for the three asset groups from 1947:1 to 1993:12

aDY = dividend yield; DEF = default premium; MAT = maturity premium; SPR = S&P 500 Index total return; SPDY = SPR x DY; IRT = interest-rate trend. The asset groups are SBU, SIZE, and SECTOR Heteroskedasticity-consistent statistics are given in parentheses.
bDurbin-Watson test statistic for dependence in the regression residual.
Table 9.5 also shows that the importance of the shortsales constraint for maximizing predictability depends critically on the particular set of assets over which predictability is being maximized. It is apparent that the shortsales constraint has little effect on the levels of the maximal R2 for the five SBU assets. Indeed, the constraint is not binding for annual returns. However, this is not the case for either the 10 SIZE assets or the 1 1 SECTOR assets. When the shortsales constraint is imposed, maximal R2's drop dramatically, from 62 to 45% for annual SIZE assets and from 53 to 46% for annual SECTOR assets.
9.4.4 The Maximally Predictable Portfolios
Whereas the coefficients of the regressions in Table 9.5 measure the sensitivity of the MPP to various factors, it is the portfolio weights of the MPPs that tell us which assets are the most important sources of predictability. Table 9.6 reports these portfolio weights for the three sets of assets, SBU, SIZE, and SECTOR.
Perhaps the most striking feature of Table 9.6 is how these portfolio weights change with the horizon. For example, the unconstrained maximally predictable SIZE portfolio has an extreme long position in decile 2 for monthly returns but an extreme short position for annual returns. The maximally predictable SECTOR and SBU portfolios exhibit similar patterns across the two horizons, but the weights are much less extreme. These changing weights are consistent with a changing covariance structure among the assets over horizons; as the structure changes, so must the portfolio weights to maximize predictability.
When the shortsales constraint is imposed, the portfolio weights vary less extremely—by construction, of course, since they are bounded between 0 and 1—but they still shift with the return horizon. For example, the constrained maximally predictable SBU portfolio is split between the S&P 500 and corporate bonds for monthly returns, but contains all assets for annual returns. More interestingly, the constrained maximally predictable SIZE portfolio is invested in decile 1 for monthly returns, but is concentrated in deciles 8, 9, and 10 for annual returns.
That the larger capitalization stocks should play so central a role in maximizing predictability among SIZE assets is quite unexpected, since it is the smaller stocks that are generally more highly autocorrelated. However, as the example in Section 9.3.2 illustrates, it is important to distinguish between the factors that predict returns and the assets that are most predictable. In the case of the SIZE assets, one explanation might be that over longer horizons, factors such as industrial production and dividend yield become more important for the larger companies since they track general business trends more closely than smaller companies (see Table 9.3).
Table 9.6. Portfolio weights of MPP for three asset groups from 1947:1 to 1993:12

Further insights concerning the sources of predictability are contained in the SECTOR portfolio weights. The constrained MPP for monthly SECTOR returns is invested in two assets: construction; and finance, real estate, and insurance. However, at an annual horizon, the composition of this portfolio changes dramatically, consisting mostly of two completely different assets: basic industries and utilities. This indicates that the sources of time variation in expected returns are sensitive to the return horizon. The sectors that are important for maximizing predictability for monthly returns may be quite different from those that maximize predictability for returns over longer horizons.
9.5 Statistical Inference for the Maximal R2
Although the magnitudes of the sample R2's of Section 9.4 suggest the presence of genuine predictability in stock returns, we must still consider data-snooping biases imparted by our in-sample maximization procedure. It is a well-known fact that the maximum of a collection of identically distributed random variables does not have the same distribution as the individual maximands. However, it is not always an easy task to deduce the distribution of the maximum, especially when the individual variables are not statistically independent as in our current application. Moreover, maximizing the R2 over a continuum of portfolio weights cannot be easily recast into the maximum of a discrete set of random variables. Therefore, much of our inferences must be guided by Monte Carlo simulation experiments in which the sampling distribution of R2 and related statistics are tabulated by generating pseudo-random data under the null hypothesis of no predictability.17
9.5.1 Monte Carlo Analysis
In particular, for the monthly return horizon, we simulate 564 observations of independently and identically distributed Gaussian stock returns, calculate the R2 corresponding to the MPP of q-period returns using the conditional factors of Section 9.4.2, record this R2, and repeat the same procedure 9,999 times, yielding 10,000 replications. For the annual horizon, we perform similar experiments: we simulate 10,000 independent samples at the annual horizon (a sample size of 47 observations), and record the maximum R2 for each sample.
The simulations yield the finite-sample distribution for the maximal R2 under the null hypothesis of no predictability. The features of that distribution are reported for various values of q in Panel (a) of Table 9.7 for the unconstrained MPP, and in Panel (b) for the constrained MPP. The rows with q = 1 correspond to a monthly return horizon and those with q = 12 correspond to an annual horizon. Within each panel, simulation results are reported for asset vectors with 5, 10, and 1 1 elements, corresponding to the number of SBU, SIZE, and SECTOR assets, respectively.
Table 9.7 shows that when predictability is maximized by combining assets into portfolios, spuriously large R2's may be obtained. With a monthly horizon and 564 observations, the problem is not severe. For example, when q = 1 and N = 11, the mean maximal R2 is 4.3%, a relatively small value. However, at an annual horizon, the problem becomes more serious. With 11 assets, the maximal R2 distribution for the unconstrained case has a mean of 50.0% and a 95% critical value of 62.9% for annual returns. Similar results hold for the constrained case—longer-horizon nonoverlapping returns can yield large R2's even when there is no predictability.
Table 9.7. Simulated finite-sample distribution of maximum R2 of MPP of N assets under null hypothesis of no predictability, using six variables as predictorsa

aFor each panel, the simulation consists of 10,000 independent replications of 564 independently and identically distributed Gaussian observations for the monthly horizon (q = 1) and 47 observations for the annual horizon (q = 12).
bShortsales constrained case with nonnegative weights.
Table 9.8. Finite-sample distribution of R2 of a given portfolio under null hypothesis of no predictability, using six variables as predictorsa

aDistribution is tabulated for 564 independently and identically distributed Gaussian observations for the monthly horizon (q = 1) and for 47 observations for the annual horizon (q = 12).
The effects of data snooping under the null hypothesis can be further quantified by comparing Table 9.7 with Table 9.8, in which the percentiles of the finite-sample distribution of the R2 for an arbitrary individual asset is reported, also under the null hypothesis of no predictability. For q = 1 the differences between the distributions in Table 9.7 and the distributions in Table 9.8 are small—for example, the 95% critical value of an individual asset's R2 is 2.2%, whereas the corresponding critical value for the unconstrained MPP's R2 are 3.8%, 5.5%, and 5.7% for 5,10, and 11 assets, respectively. But again, the effects of data snooping become more pronounced at longer horizons. Using annual returns with 10 assets, the distribution of the unconstrained maximal R2 has a 95% critical value of 60.6%, whereas Table 9.8 shows that without this maximization, the 95% critical value for the R2 is only 25.9%. These results emphasize the need to interpret portfolio R2'S with caution, particularly when the construction of the portfolios is determined by the data (see also Lo and MacKinlay, 1990a).
The statistical significance of the empirical results of Section 9.4 can now be assessed by relating the maximum sample R2's in Table 9.5 to the empirical null distributions in Table 9.7. The result of such an exercise is clear: The statistical significance of predictability decreases as the observation horizon increases. For the monthly horizon the sample R2's are substantially higher than the 95% critical values, whereas at the annual horizon they are not.
Of course, this finding need not imply the absence of predictability over longer horizons, but may simply be due to the lack of power in detecting predictability via the maximal R2 for long-horizon returns. After all, since we are using nonoverlapping returns, our sample size for the annual return horizon is only 47 observations, and given the variability of equity returns, it is not surprising that there is little evidence of predictability in annual data.
9.6 Three Out-of-Sample Measures of Predictability
Despite the statistical significance of predictability at monthly, semi-annual, and annual horizons, we are still left with the problem of estimating genuine predictability: that portion of the maximal R2 not due to deliberate data snooping. Although it is virtually impossible to provide such a decomposition without placing strong restrictions on the return- and data-generating processes (see, for example, Lo and MacKinlay, 1990a; Foster et al., 1995), an alternative is to measure the out-of-sample predictability of our MPP. Under the null hypothesis of no predictability, our maximization procedure should not impart any statistical biases out-of-sample, but if there is genuine predictability in the MPP, it should be apparent in out-of-sample forecasts.
We consider three out-of-sample measures of predictability. First, in a regression framework we examine the relation between the forecast error of a naive constant-expected-excess-return model—an unconditional forecast—and a conditional forecast minus the naive forecast, where the conditional forecast is conditioned on the factors of Section 9.4.1. If excess returns are unpredictable, these quantities should be uncorrelated. Second, we employ Merton's (1981) test of market timing to measure how predictable the MPP is in the context of a simple asset allocation rule. Third, we present an illustrative profitability calculation for this simple asset allocation rule to gauge the economic significance of the MPP's predictability.
These three measures yield the same conclusion: Recent U.S. stock returns contain genuine predictability that is both statistically and economically significant.
9.6.1 Naive vs. Conditional Forecasts
Denote by  the excess return for the MPP in month t (in excess of the one-month risk-free rate):
the excess return for the MPP in month t (in excess of the one-month risk-free rate):

where Rt is the vector of primary asset returns, * is the estimated MPP weights, and Rft is the one-month Treasury bill rate. A naive one-step-ahead forecast of  is the weighted average of the (time series) mean excess return for the past returns of each of the primary assets, an unconditional forecast of which we denote by
is the weighted average of the (time series) mean excess return for the past returns of each of the primary assets, an unconditional forecast of which we denote by  at. Now denote by bt the conditional one-step-ahead forecast of Z*t, conditioned on the economic variables of Section 9.4.1,
at. Now denote by bt the conditional one-step-ahead forecast of Z*t, conditioned on the economic variables of Section 9.4.1,

where we have added back the estimated mean vector  of the primary assets since t is the conditional forecast of de-meaned returns.
of the primary assets since t is the conditional forecast of de-meaned returns.
To compare the incremental value of the conditional forecast  beyond the naive forecast
beyond the naive forecast  , we estimate the following regression equation:
, we estimate the following regression equation:

If bt has no forecast power beyond the naive forecast at, then the estimated coefficient  1 should not be statistically different from zero.
1 should not be statistically different from zero.
To estimate (9.6.3) for each of our three groups of assets, we first estimate the parameters of the conditional factor model (9.4.1) and the MPP weights * for monthly SBU, SIZE, and SECTOR asset returns using the first 20 years of our sample, from 1947:1 to 1966:12. The one-month-ahead naive and conditional forecasts, at and bt are then generated month by month beginning in 1967:1 and ending in 1993:12, using a rolling procedure where the earliest observation is dropped as each new observation is added, keeping the rolling sample size fixed at 20 years of monthly observations. Therefore, the conditional-factor model's parameter estimates and the MPP's weights * are updated monthly.
For the 324-month out-of-sample period from 1967:1 to 1993:12, the ordinary least squares estimates of (9.6.3) for the three groups of assets are reported in Panel (a) of Table 9.9, labeled “monthly:monthly” to emphasize that monthly returns are used to construct the forecast and that monthly returns are being forecasted (see below). For the SBU asset group, the z-statistic of the slope coefficient is 1.47, implying that the power of the one-step-ahead conditional forecast of the MPP return is statistically indistinguishable from that of the naive forecast. However, for both the SIZE and SECTOR groups, the corresponding z-statistics are 3.20 and 3.30, respectively, which suggests that the conditional forecasts do add value in these cases.
To see how the return horizon affects forecast power, we perform a similar analysis for annual returns— we use annual returns to forecast one annual-step ahead. These results are reported in Panel (b) of Table 9.9, labeled “annual:annual.” At the annual frequency, conditional forecasts seem to add value for SBU and SIZE assets, but not for SECTOR assets.
Finally, in Panel (c) of Table 9.9, we consider the effect of using annual returns to forecast monthly returns. For example, annual returns are used to forecast one annual-step ahead, but this annual forecast is divided by 12 and is considered the one-month-ahead forecast. This procedure is then repeated in a rolling fashion for each month and the results are reported in Table 9.9's Panel (c) labeled “annual:monthly.”18
Interestingly, in the mixed return/forecast-horizon case, conditional forecasts add value for all three asset groups, with z-statistics ranging from 2.07 (SECTORassets) to 3.85 (SBU assets). This suggests the possibility that an optimal forecasting procedure may use returns of one frequency to forecast those of another. In particular, we shall see in Section 9.6.3 that within the SBU asset group, the economic significance of predictability is considerably greater when annual returns are used to forecast monthly returns than for the monthly-return-horizon/monthly-forecast-horizon combination.
Table 9.9. Out-of-sample evaluation of conditional one-step-ahead forecasts of MPP using a regression model with six predictorsa

aConditional forecasts are evaluated by regressing the deviation of the MPP excess return from its unconditional forecast on the deviation of the conditional MPP excess return forecast from the same unconditional forecast (denoted as b – a). Conditional forecasts for the time period 1967:1 to 1993:12 are constructed for three asset groups and for two time horizons. Heteroskedasticity-consistent z-statistics are given in parentheses.
bDurbin-Watson test stastic for dependence in the regression residual.
cforecasts are evaluated using a return horizon equal to the forecast horizon.
dAnnual returns are used to forecast monthly returns.
These out-of-sample forecast regressions suggest that statistically significant forecastability is present in the MPP, but the degree of predictability varies with the asset groups and with the return and forecast horizon.
9.6.2 Merton's Measure of Market Timing
As another measure of the out-of-sample predictability of the MPP, consider the following naive asset-allocation rule: If next month's MPP return is forecasted to exceed the risk-free rate, then invest the entire portfolio in it; otherwise, invest the entire portfolio in Treasury bills. More formally, let θt denote the fraction of the portfolio invested in the MPP in month t. Then our naive asset-allocation strategy is given by

where bt defined in (9.6.2), is the forecasted excess return on the MPP, in excess of the risk-free rate.
We can measure the out-of-sample predictability of the MPP by using Merton's (1981) framework for measuring market-timing skills. In particular, if the MPP return Z*t were considered the “market,” then one could ask whether the asset allocation rule θt exhibited positive market-timing performance. Merton (1981) shows that this depends on whether the sum of p1 and p2 exceeds unity, where

These two conditional probabilities are the probabilities that the forecast is correct in “up” and “down” markets, respectively. If p1 + p2 is greater than 1, then the forecast θt has value, i.e., Z*t is predictable; otherwise it does not.
To perform the Merton test, we use the same 20-year rolling estimation procedure as in Section 9.6.2 to generate our MPP returns and the one-month-ahead forecast θt. From these forecasts and the realized excess returns Z*t of the MPP, we construct the following (2 x 2) contingency table:

where n1 is the number of correct forecasts in “up” markets, n2 is the number of incorrect forecasts in “down” markets, and N1 and N2 are the number of up-market and down-market periods, respectively, in the sample. Henriksson and Merton (1981) show that n1 has a hypergeometric distribution under the null hypothesis of no market-timing ability, which may be
Table 9.10. Out-of-sample evaluation of conditional one-step-ahead forecasts of MPP using Merton's measure of market timinga

aMerton (1981). The number of outcomes are calculated for each of four possible excess return-forecast outcomes: a positive MPP excess return and a positive MPP conditional forecast, a positive excess return and a nonpositive conditional forecast, a nonpositive excess return and a positive conditional forecast, and a nonpositive excess return and a nonpositive conditional forecast. Z denotes the excess return and denotes the conditional forecast;  1 is the sample probability of a positive conditional forecast given a positive excess return and 2 is the sample probability of a nonpositive conditional forecast given a nonpositive excess return. The p value is the probability of obtaining at least the number of correct positive conditional forecasts under the null hypothesis of no forecastability. Conditional forecasts for the time period 1967:1 to 1993:12 are constructed for three asset groups and for two time horizons.
1 is the sample probability of a positive conditional forecast given a positive excess return and 2 is the sample probability of a nonpositive conditional forecast given a nonpositive excess return. The p value is the probability of obtaining at least the number of correct positive conditional forecasts under the null hypothesis of no forecastability. Conditional forecasts for the time period 1967:1 to 1993:12 are constructed for three asset groups and for two time horizons.
bForecasts are evaluated using a return horizon equal to the forecast horizon.
cAnnual returns are used to forecast monthly returns.
approximated by

where N ≡ N1 + N2 and n ≡ n1 + n2.
Using this sampling theory, we perform nonparametric tests for market-timing ability in our one-step-ahead conditional forecasts in Table 9.10 for the same return- and forecast-horizon combinations as in Table 9.9. Table 9.10 reports the number of forecasts in each category of (9.6.6), the estimated sum 1+2, and the p value based on (9.6.7).
The three panels of Table 9.10 show that predictability is statistically significant for the SBU asset group at both horizons. When annual returns are used to construct monthly forecasts, both SBU and SIZE asset groups have significant predictability. Merton's (1981) market-timing measure also confirms the presence of predictability in the MPP.
9.6.3 The Profitability of Predictability
As a final out-of-sample measure of predictability—one that addresses the economic significance of the MPP's predictability—we compare the total return of a passive or buy-and-hold investment in the MPP over the entire sample period with the total return of the active asset allocation strategy described in Section 9.6.2. In particular, for each of the three asset groups, and for the various return and forecast horizons, we calculate the following two quantities:

where θt is given in (9.6.4), R*t is the simple return of the MPP in month t, and WT is the end-of-period value of an investment of $1 over the entire investment period, which we take to be the 324-month period from 1967:1 to 1993:12 to match the empirical results from Sections 9.6.1 and 9.6.2.
Table 9.11 shows that the active asset-allocation strategy generally outperforms the passive for each of the three asset groups for all three return/forecast horizon pairs, yielding a higher mean return, a lower standard deviation of return, and a larger total return WT over the investment period. For example, the monthly passive strategy for the MPP in the SECTOR group of assets has a mean excess return of 0.82% per month and a standard deviation of 6.15% per month, whereas the active strategy has a mean excess return of 1.00% per month and a standard deviation of 5.26% per month. These values imply Sharpe ratios of  for the passive SECTOR strategy and
for the passive SECTOR strategy and  for the active SECTOR strategy.
for the active SECTOR strategy.
Table 9.11 also shows that the total returns of the active strategy dominate those of the passive for each of the three asset groups and for all return/forecast horizon pairs. A passive $1 monthly investment in the SECTOR asset group at the beginning of 1967:1 yields a total return of $46.73 at the end of 1993:12, whereas the corresponding active strategy yields a return of $99.38.
Of course, the total returns of the active strategy do not include transactions costs, which can be substantial. To determine the importance of such costs, Table 9.11 also reports break-even transactions costs, defined as that percentage cost 100 x s of buying or selling the MPP that would equate the active strategy's total return to the passive strategy's. More formally, if the active strategy requires k switches into or out of the MPP over the 324-month investment period, then the one-way break-even transactions cost 100 x s is defined by
Table 9.11. Out-of-sample evaluation of conditional one-step-ahead forecasts of MPP using a comparison of passive and active investment strategies in the portfolioa

aConditional forecasts for the time period 1967:l to 1993:12 are constructed for three asset groups and for two time
horizons. The forecasts are evaluated using a return horizon equal to the forecast horizon. For annual forecasts a monthly return horizon is also considered. The active strategies invest 100% in the MPP if the conditional excess return forecast is positive and invest 100% in Treasury bills otherwise.
bTerminal value of a $1 investment over entire sample.
cNumber of times the active strategy shifted into or out of the MPP.
dOne-way percentage transaction cost that equates the active and passive strategy's ending value.

For a monthly-return/monthly-forecast horizon, Table 9.11 shows that the number of switches into or out of the MPP ranges from 58 (SBU) to 80 (SIZE), implying two or three switches per year on average. This, in turn, implies that the one-way transactions cost would have to be somewhere between 0.77% (SBU asset group) and 1.19% (SIZE asset group) for the active strategy to yield the same total return as the passive.
At the annual-return/annual-forecast horizon, the number of switches declines by construction, dropping to approximately one switch every 4.5 years, hence the break-even transactions cost increases dramatically. In this case, the one-way transactions cost would have to be somewhere between 2.97% and 4.94% to equate the active and passive strategies' total returns.
Now we cannot conclude from Table 9.11 that the MPP is a market inefficiency that is exploitable by the average investor since we have not formally quantified the (dynamic) risks of the passive and active strategies. Although the active strategy's return has a lower standard deviation and a higher mean, this need not imply that every risk-averse investor would prefer it to the passive strategy. To address this more complex issue, we must specify the investor's preferences and derive his optimal consumption and portfolio rules dynamically, which lies beyond the scope of this chapter. Nevertheless, the three out-of-sample measures do indicate the presence of genuine predictability in the MPP, which is both statistically and economically significant.19
9.7 Conclusion
That stock-market prices contain predictable components is now a well-established fact. At issue are the economic sources of predictability in asset returns, since this lies at the heart of several current controversies involving the efficient-markets hypothesis, stock-market rationality, and the existence of “excessively” profitable trading strategies. Our results show that predictable components are indeed present in the stock market, and that sophisticated forecasting models based on measures of economic conditions do have predictive power. By studying the MPP, we see that the degree and sources of predictability also vary considerably among assets and over time. Some industries have better predictive power at shorter horizons, whereas others have more power at longer horizons. The changing composition of the MPP points to important differences among groups of securities that warrant further investigation. Nevertheless, predictability is both statistically and economically significant, both in sample and out of sample.
We hasten to emphasize that predictabilities need not be a symptom of market inefficiency. While dynamic investment strategies exploiting predictability have yielded higher returns historically, we have not attempted to adjust for risk or for subde selection biases that might explain such phenomena. But despite the ambiguity of the economic sources of predictability, our results suggest that ignoring predictability cannot be rational either.
1See Fama and French (1990) and Ferson and Harvey (1991b) for example.
2For example, see DeBondt and Thaler (1985), Lehmann (1990), and Chopra et al. (1992).
3 A few of the most recent examples include Clarke et al. (1989), Droms (1989), Vandell and Stevens (1989), Hardy (1990), kester (1990), Lee and Rahman (1990, 1991), Sy (1990), Weigel (1991), Shilling (1992), and Wagner et al. (1992). However, see Samuelson (1989, 1990) for a caution against such strategies.
4AS will become apparent below, we maximize predictability across portfolios, holding fixed the set of regressors used to forecast asset returns. In a related paper, Foster et al. (1995) maximize predictability across subsets of regressors, holding fixed the asset return to be predicted. Therefore, our upper bound obtains over a fixed set of regressors, while Foster et al.'s obtains over a fixed set of assets.
5See, for example, Gibbons and Ferson (1985), Chen et al. (1986), Keim and Stambaugh (1986), Engle et al. (1987), Ferson et al. (1987), Lo and MacKinlay (1988b), Ferson (1989, 1990), Ferson and Harvey (1991), Fama and French (1990), Jegadeesh (1990), and Chen (1991).
6For the biases of and possible corrections to such informal specification searches see Learner (1978), Ross (1987), Iyengar and Greenhouse (1988), Lo and MacKinlay (1990a), and Fosteretal. (1995).
7Assumption (Al ) is made for notational simplicity, since stationarity allows us to eliminate time indexes from population moments such as µ and k However, there are several alternatives to stationarity and ergodicity that permit time-varying unconditional moments and still satisfy a law of large numbers and central limit theorem, which is essentially all we require for our purposes. The qualitative features of our results will not change under such alternatives (e.g., weak dependence with moment conditions), but would merely require replacing expectations with corresponding probability limits of suitably defined time averages. See, for example, White (1984) and Lo and MacKinlay (1990b).
8Our analysis can easily be extended to conditionally heteroskedastic errors, but at the expense of notational and computational complexity. See Section 9.3.1 for further discussion.
9Two closely related techniques are the multivariate index model and the reduced rank regression model; see Reinsel (1983) and Velu, Reinsel, and Wichern (1986).
10Similarly, the minimum of R2(γ) with respect to γ is given by the smallest eigenvalue λ* of B and is attained by the eigenvector γ* associated with the smallest eigenvalue of B. Therefore, γ* is the minimally predictable portfolio, i.e., the portfolio that is closest to a random walk.
11 See, for example, Bollerslev, Engle, and Wooldridge (1988), Gallant and Tauchen (1989), and Hamilton (1994, Chapter 21).
12In particular, (9.3.8) may be viewed as a conditional version of a linear factor model where the factor Zt is a linear function of economic variables observable at t–1 (namely, Xt–1 ). Examples of such a specification in the recent literature include Chen, Roll, and Ross (1986), Engle, Lilien, and Robbins (1987), Ferson (1989, 1990), Ferson and Harvey (1991b), and Harvey (1989). To underscore this factor-pricing interpretation, we have referred to ß as the vector of factor loadings and will refer to the predictor Xt–1 as a conditional factor. However, it should be emphasized that a structural factor-model for our return-generating process, one that links expected returns to contemporaneous risk premia (such as the security market line of the CAPM), is not required by our framework. But even if such a structural factor-model exists, the contemporaneous factors or risk premia are almost always written as linear functions of ex-ante economic variables, especially when applying them to time-series data. Therefore, the simple specification (9.3.8) is considerably more general than it may appear to be.
13 However, using similar conditional factors, Bessembinder and Chan (1992) find similar levels of predictability for various commodity and currency futures which are nearly uncorrelated with equity returns. This is perhaps the most convincing empirical evidence to date for the genuine forecast power of dividend yields, short-term interest-rate yields, and the default premium.
14This interaction term is motivated by several recent empirical studies documenting time variation in asset-return betas, e.g., Ferson, Kandel, and Stambaugh (1987), Ferson (1989), Harvey (1989), and Ferson and Harvey (1991b). In principle, we can model all of the factor loadings as time-varying. However, the “curse of dimensionality” would arise, as well as the perils of overfitting. Moreover, the evidence in Ferson and Harvey (1991b, Table 8) suggests that the predictability in monthly size and sector portfolios is primarily due to changing risk premia, not changing betas. Therefore, our decision to leave β1 through β4 fixed through time is unlikely to be very restrictive.
15We have also analyzed quarterly and semi-annual returns, but do not report them here to conserve space. Although the variation in predictability across horizons exhibits some interesting features, the results generally fall in between the range of monthly and annual values.
16Note that the longer-horizon returns are nonoverlapping. In some unpublished Monte Carlo simulations, we have shown that overlapping returns can induce unusually high R2's even when the conditional factors are statistically independent of the long-horizon returns. See also Richardson and Stock (1990).
17We do have some analytical results for this problem, but they rely heavily on the assumption that returns are multivariate normal. Moreover, the exact sampling distribution of R2 is given by the sum of zonal polynomials which is computationally tractable only for very simple special cases. See Lo and MacKinlay (1992) for further details.
18We have investigated other mixed return/forecast-horizon regressions but, in the interest of brevity, do not report them here.
19See also Breen, Glosten, and Jagannathan (1989, Table IV), who find similar results for monthly equal- and value-weighted NYSE stock index returns.