Decision trees are extremely useful, but they are often not the best-performing classifiers. In this and the next section we present two techniques, boosting and random trees, that use trees in their inner loop and so inherit many of the useful properties of trees (e.g., being able to deal with mixed and unnormalized data types and missing features). These techniques typically perform at or near the state of the art; thus they are often the best "out of the box" supervised classification techniques[252] available in the library.
Within in the field of supervised learning there is a meta-learning algorithm (first described by Michael Kerns in 1988) called statistical boosting. Kerns wondered whether it is possible to learn a strong classifier out of many weak classifiers.[253] The first boosting algorithm, known as AdaBoost, was formulated shortly thereafter by Freund and Schapire.[254] OpenCV ships with four types of boosting:
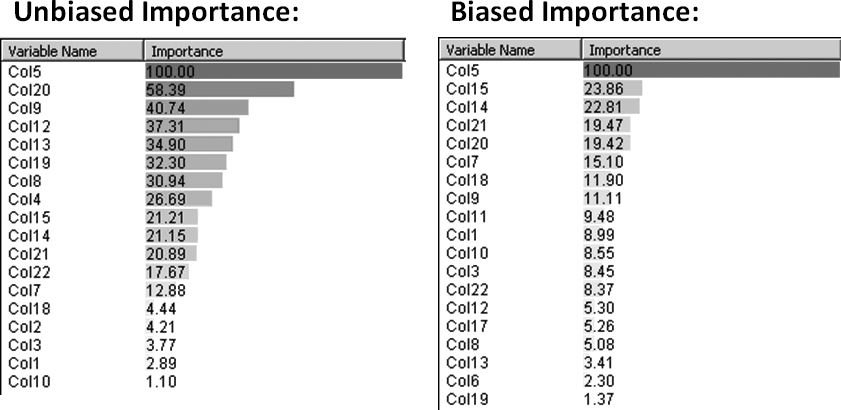
Figure 13-12. Variable importance for edible mushroom as measured by an unbiased tree (left panel) and a tree biased against poison (right panel)
Each of these are variants of the original AdaBoost, and often we find that the "real"
and "gentle" forms of AdaBoost work best. Real AdaBoost is a technique
that utilizes confidence-rated predictions and works well with categorical data.
Gentle AdaBoost puts less weight on outlier data points and for that
reason is often good with regression data. LogitBoost can also produce
good regression fits. Because you need only set a flag, there's no reason not to try all
types on a data set and then select the boosting method that works best.[255] Here we'll describe the original AdaBoost. For classification it should be noted
that, as implemented in OpenCV, boosting is a two-class (yes-or-no) classifier[256] (unlike the decision tree or random tree classifiers, which can handle multiple
classes at once). Of the different OpenCV boosting methods, LogitBoost and GentleBoost (referenced in
the "Boosting Code" subsection to follow) can be used to perform regression in addition to
binary classification.
Boosting algorithms are used to train T weak classifiers ht,
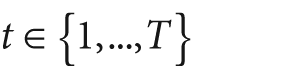
. These classifiers are generally very simple individually. In most cases these classifiers are decision trees with only one split (called decision stumps) or at most a few levels of splits (perhaps up to three). Each of the classifiers is assigned a weighted vote α t in the final decision-making process. We use a labeled data set of input feature vectors xi, each with scalar label yi (where i = 1,…,M data points). For AdaBoost the label is binary,
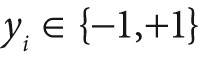
, though it can be any floating-point number in other algorithms. We initialize a data point weighting distribution Dt(i) that tells the algorithm how much misclassifying a data point will "cost". The key feature of boosting is that, as the algorithm progresses, this cost will evolve so that weak classifiers trained later will focus on the data points that the earlier trained weak classifiers tended to do poorly on. The algorithm is as follows.
D1(i) = 1/m, i = 1,…,m.
For t = 1,…,T:
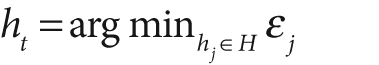
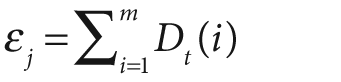
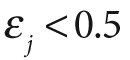
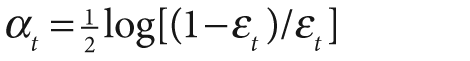
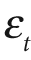
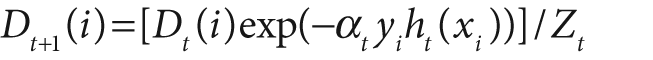
Note that, in step 2b, if we can't find a classifier with less than a 50% error rate then we quit; we probably need better features.
When the training algorithm just described is finished, the final strong classifier takes a new input vector x and classifies it using a weighted sum over the learned weak classifiers ht:
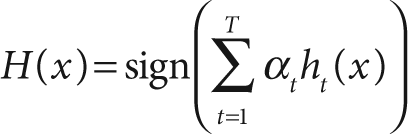
Here, the sign function converts anything positive
into a 1 and anything negative into a –1 (zero remains 0).
There is example code in …/opencv/samples/c/letter_recog.cpp that shows how to use boosting, random trees and back-propagation (aka multilayer perception, MLP). The code for boosting is similar to the code for decision trees but with its own control parameters:
struct CvBoostParams : public CvDTreeParams { int boost_type; // CvBoost:: DISCRETE, REAL, LOGIT, GENTLE int weak_count; // How many classifiers int split_criteria; // CvBoost:: DEFAULT, GINI, MISCLASS, SQERR double weight_trim_rate; CvBoostParams(); CvBoostParams( int boost_type, int weak_count, double weight_trim_rate, int max_depth, bool use_surrogates, const float* priors ); };
In CvDTreeParams, boost_type selects one of the
four boosting algorithms listed previously. The split_criteria is one of the following.
The last parameter, weight_trim_rate, is for
computational savings and is used as described next. As training goes on, many data points
become unimportant. That is, the weight Dt(i)
for the ith data point becomes very small. The weight_trim_rate is a threshold between 0 and 1 (inclusive)
that is implicitly used to throw away some training samples in a given boosting iteration.
For example, suppose weight_trim_rate is set to 0.95.
This means that samples with summary weight ≤ 1.0–0.95 = 0.05 (5%) do not participate in
the next iteration of training. Note the words "next iteration". The samples are not
discarded forever. When the next weak classifier is trained, the weights are computed for
all samples and so some previously insignificant samples may be returned back to the next
training set. To turn this functionality off, set the weight_trim_rate value to 0.
Observe that CvBoostParams{} inherits from CvDTreeParams{}, so we may set other parameters that are
related to decision trees. In particular, if we are dealing with features that may be
missing[257] then we can set use_surrogates to true, which will ensure that alternate features on which the
splitting is based are stored at each node. An important option is that of using priors to
set the "cost" of false positives. Again, if we are learning edible or poisonous mushrooms then we might set the priors to be float priors[] = {1.0, 10.0};
then each error of labeling a poisonous mushroom edible would cost ten times as much as
labeling an edible mushroom poisonous.
The CvBoost class contains the member weak, which is a CvSeq*
pointer to the weak classifiers that inherits from CvDTree
decision trees.[258] For LogitBoost and GentleBoost, the trees are regression trees (trees that predict
floating-point values); decision trees for the other methods return only votes for class 0
(if positive) or class 1 (if negative). This contained class sequence has the following
prototype:
class CvBoostTree: public CvDTree {
public:
CvBoostTree();
virtual ~CvBoostTree();
virtual bool train(
CvDTreeTrainData* _train_data,
const CvMat* subsample_idx,
CvBoost* ensemble
);
virtual void scale( double s );
virtual void read(
CvFileStorage* fs,
CvFileNode* node,
CvBoost* ensemble,
CvDTreeTrainData* _data
);
virtual void clear();
protected:
...
CvBoost* ensemble;
};Training is almost the same as for decision trees, but there is an extra parameter
called update that is set to false (0) by default. With
this setting, we train a whole new ensemble of weak classifiers from scratch. If update is set to true (1) then we just add new weak
classifiers onto the existing group. The function prototype for training a boosted
classifier is:
bool CvBoost::train( const CvMat* _train_data, int _tflag, const CvMat* _responses, const CvMat* _var_idx = 0, const CvMat* _sample_idx = 0, const CvMat* _var_type = 0, const CvMat* _missing_mask = 0, CvBoostParams params = CvBoostParams(), bool update = false );
An example of training a boosted classifier may be found in …/opencv/samples/c/letter_recog.cpp. The training code snippet is shown in Example 13-3.
Example 13-3. Training snippet for boosted classifiers
var_type = cvCreateMat( var_count + 2, 1, CV_8U ); cvSet( var_type, cvScalarAll(CV_VAR_ORDERED) ); // the last indicator variable, as well // as the new (binary) response are categorical // cvSetReal1D( var_type, var_count, CV_VAR_CATEGORICAL ); cvSetReal1D( var_type, var_count+1, CV_VAR_CATEGORICAL ); // Train the classifier // boost.train( new_data, CV_ROW_SAMPLE, responses, 0, 0, var_type, 0, CvBoostParams( CvBoost::REAL, 100, 0.95, 5, false, 0 ) ); cvReleaseMat( &new_data ); cvReleaseMat( &new_responses );
The prediction function for boosting is also similar to that for decision trees:
float CvBoost::predict( const CvMat* sample, const CvMat* missing = 0, CvMat* weak_responses = 0, CvSlice slice = CV_WHOLE_SEQ, bool raw_mode = false ) const;
To perform a simple prediction, we pass in the feature vector sample and then predict() returns the
predicted value. Of course, there are a variety of optional parameters. The first of these
is the missing feature mask, which is the same as it
was for decision trees; it consists of a byte vector of the same dimension as the sample vector, where nonzero values indicate a missing
feature. (Note that this mask cannot be used unless you have trained the classifier with
the use_surrogates parameter set to CvDTreeParams::use_surrogates.)
If we want to get back the responses of each of the weak classifiers, we can pass in a floating-point CvMat vector, weak_responses, with length
equal to the number of weak classifiers. If weak_responses is
passed, CvBoost::predict will fill the vector with the
response of each individual classifier:
CvMat* weak_responses = cvCreateMat( 1, boostedClassifier.get_weak_predictors()->total, CV_32F );
The next prediction parameter, slice, indicates
which contiguous subset of the weak classifiers to use; it can be set by
inline CvSlice cvSlice( int start, int end );
However, we usually just accept the default and leave slice set to "every weak classifier" (CvSlice
slice=CV_WHOLE_SEQ). Finally, we have the raw_mode, which is off by default but can be turned on by setting it to
true. This parameter is exactly the same as for
decision trees and indicates that the data is prenormalized to save computation time.
Normally you won't need to use this. An example call for boosted prediction is
boost.predict( temp_sample, 0, weak_responses );
Finally, some auxiliary functions may be of use from time to time. We can remove a weak classifier from the learned model via
void CvBoost::prune( CvSlice slice );
We can also return all the weak classifiers for examination:
CvSeq* CvBoost::get_weak_predictors();
This function returns a CvSeq of pointers to
CvBoostTree.
[252] Recall that the "no free lunch" theorem informs us that there is no a priori "best" classifier. But on many data sets of interest in vision, boosting and random trees perform quite well.
[253] The output of a "weak classifier" is only weakly correlated with the true classifications, whereas that of a "strong classifier" is strongly correlated with true classifications. Thus, weak and strong are defined in a statistical sense.
[254] Y. Freund and R. E. Schapire, "Experiments with a New Boosting Algorithm", in Machine Learning: Proceedings of the Thirteenth International Conference (Morgan Kauman, San Francisco, 1996), 148–156.
[255] This procedure is an example of the machine learning metatechnique known as voodoo learning or voodoo programming. Although unprincipled, it is often an effective method of achieving the best possible performance. Sometimes, after careful thought, one can figure out why the best-performing method was the best, and this can lead to a deeper understanding of the data. Sometimes not.
[256] There is a trick called unrolling that can be used to adapt any binary classifier (including boosting) for N-class classification problems, but this makes both training and prediction significantly more expensive. See …/opencv/samples/c/letter_recog.cpp.
[257] Note that, for computer vision, features are computed from an image and then fed to the classifier; hence they are almost never "missing". Missing features arise often in data collected by humans—for example, forgetting to take the patient's temperature one day.
[258] The naming of these objects is somewhat nonintuitive. The object of type CvBoost is the boosted tree classifier. The objects of
type CvBoostTree are the weak classifiers that constitute the overall boosted strong classifier. Presumably, the weak classifiers are typed as CvBoostTree because they derive from CvDTree (i.e., they are little trees in themselves, albeit
possibly so little that they are just stumps). The member variable weak of CvBoost points
to a sequence enumerating the weak classifiers of type CvBoostTree.