Cross Entropy
So far, we used the log loss formula for our binary classifiers. We even used the log loss when we bundled ten binary classifiers in a multiclass classifier (in Chapter 7, The Final Challenge). In that case, we added together the losses of the ten classifiers to get a total loss.
While the log loss served us well so far, it’s time to switch to a simpler formula—one that’s specific to multiclass classifiers. It’s called the cross-entropy loss, and it looks like this:
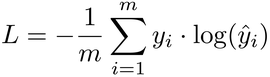
Here’s the cross-entropy loss in code form:
| | def loss(Y, y_hat): |
| | return -np.sum(Y * np.log(y_hat)) / Y.shape[0] |
If you’re curious, you can read how the cross-entropy loss works on the ProgML[15] site. However, you don’t need to understand how it works, as long as you remember what it does: like other loss formulae, it measures the distance between the classifier’s predictions and the labels. The lower the loss, the better the classifier.
Besides its cool name, there is a pragmatic reason to use the cross-entropy loss in our neural network: it’s a perfect match for the softmax. More specifically, a softmax followed by a cross-entropy loss makes it easier to code gradient descent. But I’m getting ahead of myself here—that’s a topic for the next chapter. For now, just know that the softmax and the cross-entropy loss jive well together, and they’ll cap off our neural networks for the rest of this book.
Finally, let me clear one potential source of confusion. If you look at the code, you might wonder why we bother with the loss in the first place. In fact, we don’t even seem to ever use the loss function, apart from printing its value on the screen.
Indeed, we don’t care about the loss as much as the gradient of the loss, that we’re going to use later during gradient descent. While the loss function is not really necessary, however, it’s still nice to have. We can look at that number to gauge how well the classifier is doing, both during training and during classification. That’s the reason why we bothered to code loss and call it from the report function.
With the loss function, our neural network’s classification code is done. Let’s wrap it up.