The code developed in this book up to this point has been restricted to code that may be placed inside curly brackets after the initial line of code “int main(int argc, char* argv[]);”. Readers with previous programming experience will be aware of the limitations this places when writing code. For example, if we were to apply the same operations in different places in the code we would have to repeat the lines of code that performed these operations everywhere in the code where they were required. It would be much more convenient if we could write a function that we could call whenever we wanted to perform these operations. This chapter introduces the C++ machinery for writing functions.
5.1 Blocks
A block is any piece of code between curly brackets. A variable, when declared inside a block, may be used throughout that block, but only within that block. This is demonstrated in the code below. In line 9, we attempt to use the variable j when it is only declared—and therefore available—in the block enclosed within the curly brackets in lines 4 and 8. In the language of programmers, “the scope of j is the block between lines 4 and 8”. If we attempted to use the code fragment below, the compiler would report this attempted use of j as an error: j is said to be out of scope at line 9.
The same variable name may be used for a variable declared both inside a block—termed the local variable—and outside the scope of any function (including the main function)—termed the global variable. Both of these variables may be accessed inside the block as shown in the code below, using the example of both a global and a local variable called i. Furthermore, we may define a variable j in both the outer block and the inner block: inside the inner block the value of j stored by the variable declared in the outer block is not accessible. The multiple declaration of both i and j in the code below is bad programming practice, as it can clearly lead to confusion. In fact, since the scope of variables is so important, we suggest that variables are declared only within the block where they are needed, close to their first use. This multiple declaration of variables is known as variable shadowing and you can avoid it happening by turning on “shadow warnings” in your compiler. With the GNU g++ compiler this is achieved by adding the -Wshadow flag to the compilation command.
5.2 Functions
Now that we have defined what we mean by a block of code we may demonstrate how to write functions.
5.2.1 Simple Functions
A simple program that writes and uses a function to determine the minimum value of two double precision floating point variables x and y, and stores it in the double precision variable minimum_value is shown below. Note the function prototypethat is line 3 in the listing below. The function prototype tells the compiler what input variables are required, and what variable, if any, is returned. In the example below, the function prototype explains that later in the code there will be a function called CalculateMinimum that requires two double precision floating point variables as input, and returns one double precision floating point variable. The function prototype can be thought of as being similar to declaring a variable. The variable names a and b in the prototype are ignored by the compiler and don’t have to be included, but their inclusion can clarify the program. Note that the function prototype ends with a semi-colon.
Lines 15–29 of the code contain the statements that perform the tasks required by the function. This code begins with a line of code that is identical to the function prototype (including the variable names) without the semi-colon. After this there is a block of code that ends with a return statement that returns the value required to the point in the code where this function was called from. Note that there is no need to declare the variables a and b inside the function—the declaration in line 15 has done this already. Variables such as minimum that are used inside the function but are not part of the function prototype must be declared within the function block. Line 8 demonstrates how to call a function: the variables in brackets (x and y in this case) are sent to the function, and are known as the arguments of the function. The variable returned from the function is stored as minimum_value.
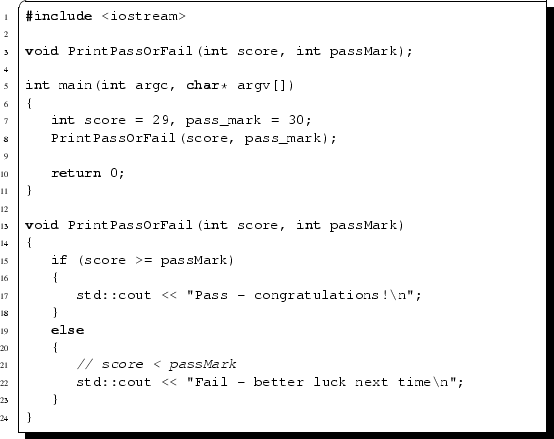
Note that only one variable may be returned from a function. Although sufficient for some purposes, we may sometimes want to return more variables. We will see how this may be done later in this chapter. Of course, there are some circumstances where we do not want a function to return any variable: such functions may be prototyped as a void function. The code below contains an example of a function that prints out a message informing a candidate whether or not they have passed an exam. This function requires two integer variables as input: the first of these contains the mark that a candidate has scored; the second contains the pass mark for the exam.
A function can only change the value of a variable sent to a function inside that function: changes made within the function will have no effect on this variable after the function has been executed and the code continues to execute statements in the block where the function has been called from. This is because a copy is made of any variable that is sent to a function, and it is this copy of the variable, and not the original variable, that is modified inside the function. For example, the following function has no effect on the variable x outside the function, even though the value of xis changed inside the function.
5.2.2 Returning Pointer Variables from a Function
In Sect. 5.2.1, we demonstrated how to write functions that returned either a variable that wasn’t a pointer, or had no return type. Functions can be used to return pointer variables as well, as shown in the code below. In this case, we have written a function that allocates memory for a matrix dynamically, and returns the pointer to the memory allocated. The array can then be used as if the memory were allocated in the main function, as demonstrated in lines 8 and 9. Because every new requires a matching delete we have avoided leaking memory by also providing a function called FreeMatrixMemory to free up the memory created in AllocateMatrixMemory. Both AllocateMatrixMemory and its partner function FreeMatrixMemory operate in the manner described in Sect. 4.2.2.
5.2.3 Use of Pointers as Function Arguments
We concluded Sect. 5.2.1 by explaining that any changes to a variable made inside a function would have no effect outside that function. This has the advantage that if a variable is altered unintentionally then the impact of this is localised to the function where this unintentional alteration was made. However, there are occasions where we do wish changes to a variable inside a function to have an effect outside a function. For example, if we are given a complex number in polar form, zre, we may wish to write a function that returns the real part, denoted by the variable x, and imaginary part, denoted by the variable y, of this number. We have noted earlier that a function can only return one variable, and so we may not return both the variable x and the variable y. It would therefore be useful to include the variables x and y in the function call. However, this would not work either, as the values assigned to these variables would not have any effect outside the function. Fortunately pointers provide us with one way around this problem. Instead of sending the variables x and y to the function, we send the addresses of these variables to the function. When the function is called, copies are made of the addresses of these variables, and it is these copies that are sent to the function. Changes to these addresses will not have any effect outside the function as we are working with a copy of these addresses. However, we can change the contents of the variable without changing the address through de-referencing the pointer, and this will have an effect outside of the function. This is demonstrated in the code below.
Note that lines 4–6 of the code are really meant to be one long line, giving the function prototype of CalculateRealAndImaginary. Since the line is long, we have split it across several lines and indented the continuation lines for clarity (see Sect. 6.6 for a discussion of stylistic conventions when writing code). The prototype lists the arguments for the function. The first two arguments are double precision floating point variables representing the magnitude (denoted by r) and argument (denoted by theta) of the specified complex number. The third and fourth arguments are pointers to—that is, the addresses of—the real part and imaginary part of the complex number. In line 12, we declare integers x and y that represent the real and imaginary parts of the complex number. To use the function CalculateRealAndImaginary, we send the addresses of these variables to the function. Behind the scenes a copy of these addresses is made, and it is these copies that are used in the function in lines 20–26. However, these copies refer to the same memory as the original variables x and y, and so it is this memory that the results of the calculations in lines 24 and 25 are stored in.
5.2.4 Sending Arrays to Functions
When sending arrays to functions—whether or not the memory has been allocated dynamically—it should be noted that it is the address of the first element of the array that is being sent to the function. In common with sending the pointer to a variable to a function, changes to this address will not have an effect in the code from which this function is called: however, the contents of this address—that is, the contents of the array—may be changed. As such, any changes made to an array inside a function will have an effect when that variable is used subsequently outside the function.
We begin by showing how to send arrays whose size is known at compile time to a function. This is shown in the listing below. Note that we do not have to specify the size of the first index of an array in the function prototype. This size is computed by the compiler. It may be included if desired, but this will be ignored when the code is compiled.
Arrays whose size has been dynamically allocated can also be sent to a function. Example code for this is shown below.
5.2.5 Example: A Function to Calculate the Scalar Product of Two Vectors
Suppose we want to calculate the scalar product of two vectors of double precision floating point numbers of length n. Calculating the scalar product could be embedded within a function that inputs the two arrays, and the length n of both vectors, and returns a double precision floating point variable that represents the scalar product of the two vectors: see Sect. A.1.2 for a discussion of how to calculate the scalar product of two vectors. We would first need to allocate memory for the two vectors. We could then call the function that calculates the scalar product, before finally deleting the memory allocated to the two vectors. Code for this is shown below.
5.3 Reference Variables
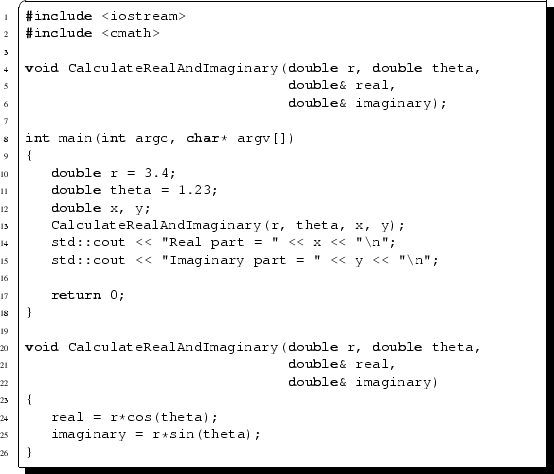
In Sect. 5.2.3, we demonstrated the use of pointers to allow changes made to a variable within a function to have an effect outside the function, and showed how this could be used to allow a function to, in effect, return more than one variable. An alternative to using pointers is to use reference variables: these are variables that are used inside a function that are a different name for the same variable as that sent to a function. When using reference variables any changes inside the function will have an effect outside the function. These are much easier to use than pointers: all that has to be done is the inclusion of the symbol & before the variable name in the declaration of the function and the prototype—this indicates that the variable is a reference variable. It is actually the case that references behave like pointers behind the scenes, but without the programmer having to convert to an address with & on the function call (as in Listing 5.1) and without having to de-reference inside the function—they provide a layer of syntactic sugar to ease the programmer’s burden. We now modify the example code in Listing 5.1 that wrote a function that calculated the real and imaginary parts of a complex number given in polar form to use references instead of pointers.
5.4 Default Values for Function Arguments
If we are writing a function to implement an iterative technique, such as the Newton–Raphson technique for finding a root of a nonlinear equation, we will usually be content if the solution is accurate to within a tolerance of, say, 10. Only on very rare occasions would we want to change this tolerance. We might also want to restrict the number of function evaluations: the Newton–Raphson iteration will probably be implemented using a while loop, and numerical rounding errors may prevent the error being sufficiently small for the iteration to terminate. Under these conditions, we would never exit the while loop, and the program that called this function would never terminate. It would therefore be prudent to write a function for implementing the Newton–Raphson technique that sets a default tolerance for the solution, and a default maximum number of iterations. We would then be able to call this function without specifying these default values. However, if we did want to call this function with different values then we would like to be able to do this. This is easily achieved by setting default values in the function prototype. This is demonstrated below in a program that uses the Newton–Raphson technique for calculating the cube root of a given number K through solving the nonlinear equation . Using a given initial guess x, the Newton–Raphson method results in the iteration
By setting default values for the tolerance and maximum number of function iterations we may call the function using one of: (i) the default values of these parameters; (ii) specifying the tolerance (the first optional parameter in the function prototype) and using the default maximum number of function iterations; and (iii) specifying both of these parameters. All three of these cases are shown below.
5.5 Function Overloading
Suppose we want to write one function to multiply a vector by a scalar, and another function to multiply a matrix by a scalar. It would seem natural to call both these functions Multiply. This is allowed in C++: we write different function prototypes and functions for both of these operations: the compiler then chooses the correct function based on the input arguments. This is demonstrated in the code below, and is known as function overloading.
Note that we can overload functions based only on the number and type of the arguments and not on the return type. This means that we could not have vector multiply function bool Multiply(double scalar, double* u, double* v, int n) alongside the version which has a void return type. This is because the compiler can infer the correct version of an overloaded function from the types of its arguments from the context in which it is used. This is not the case with the return type, where you may want to call a function which returns something, but then to cast its output to another return type, or ignore its output completely.
5.6 Declaring Functions Without Prototypes
It is good practice to give the function signature prototypes before you write the implementation. This is so that the function main, or any other function will recognise the name and argument types of the new function. However, it is possible to skip the writing of the function prototype by writing the function implementation before its first use, as is shown in the code below.
If prototypes are not given, then the function implementations must be ordered in such a way that each implementation is seen by the compiler before its first use. Note that if two functions are mutually recursive, that is, both functions call the other function, then it will not be possible to order the functions in this way—and so prototypes must be declared in this case.
5.7 Function Pointers
Suppose we want to write a function to implement the solution of the nonlinear equation f(x) 0 using the Newton–Raphson technique, where f is a user-specified function. We may want to call this function for solving nonlinear equations more than once during the execution of a given program, and for different user-specified nonlinear functions. To achieve this, we need to specify the appropriate nonlinear function each time the function is called. This may be done, as demonstrated in the code below, using function pointers.
In the code below, we specify two functions myFunction and myOtherFunction. In line 8, we declare a function pointer*p_function. This declaration specifies that the function that this pointer refers to must: (i) accept one (and only one) input argument which is a double precision floating point variable; and (ii) return one double precision floating point variable. In line 10, we specify that p_function points at the function myFunction: calling the function p_function in line 11 then has an identical effect to calling myFunction. In lines 13 and 14, we demonstrate how to use p_function to subsequently call the function myOtherFunction.
The Newton–Raphson method for solving nonlinear equations is defined in Exercise 2.6 in the Exercises at the end of Chap. 2. This is implemented below for two different user-specified functions through the use of function pointers. In lines 5–16, we write a function to implement this algorithm. This function requires specification of: (i) a function pointer to the nonlinear function; (ii) a function pointer to the derivative of the nonlinear function; and (iii) an initial guess to the solution. Note that the function as it stands does not check for divergence, so is unsafe to use in some cases.
In lines 46 and 47, we call the Newton–Raphson solver to solve the equation with initial guess x 1: the nonlinear function Sqrt10, and the derivative of the nonlinear function Sqrt10Prime are given in lines 19–22 and 26–29 of the code. Similarly, in lines 48 and 49 we call the Newton–Raphson solver to solve the equation with initial guess x 1: the nonlinear function Cube10, and the derivative of the nonlinear function Cube10Prime are given in lines 32–35 and 39–42 of the code.
5.8 Recursive Functions
In some applications, we may wish to call a function from within the same function: this is known as recursion, and is possible in C++. A simple application of this is the calculation of the factorial of a positive integer n, denoted by fact(n), and written mathematically as n!, which is defined by
Code to implement this recursive definition of the factorial function is given below: we simply call the function CalculateFactorial from within the same function as many times as required.
5.9 Modules
Suppose we want to write a code to allow us to solve linear systems of the form Axb, where A is a square, invertible matrix of size n, b is a specified vector of size n, and x is a vector to be calculated of size n. It would be useful if we could write all the functions required to solve this linear system and then allow these functions to be called through an appropriate function—that is, we want to write a function called SolveLinearSys with the prototype shown below.
The function SolveLinearSys, and all other functions associated with this linear solver, are known as a module. In more concrete terms, a module is a collection of functions that performs a given task. Every module has an interface. In the example above, this was defined by the prototype of the function SolveLinearSys, and may be thought of as a list of variables that contains: (i) those that must be input to the module; and (ii) those that are output by the module.
Modules are very useful when sharing code. For example, if a colleague has written code for solving linear systems as described above then it would be a very simple task for another colleague to utilise this code. All that is required is an understanding of the interface and what the purpose of the code is: there is no need to understand the mathematical algorithm that determines how the linear system has been solved, and the module may be thought of as a “black box”.
5.10 Tips: Code Documentation
As you begin to write more programs, there is often a temptation to “just get on with the coding” without paying specific attention to quality. After all “you generally know where you are going and understand the program which you are writing”. It is important to bear in mind, though, that your code will not always be as well understood as it is now. You might come back to a given file in three years’ time, because you need to correct it or to add some new functionality to it. Alternatively, you may at some stage hand your programs over to someone else who has the job of working out what you were doing.
Our tip in this chapter is that computer programs should be human-readable, as well as machine-readable. Even the smallest portion of code may prove to be opaque unless we include enough commentary to aid the human reader. Take for example the function given below, which calculates the p-norm of a vector. Without comments in the code, it would not be obvious what was happening, even though there are only a few lines of code. A hint is given in the name of the function, CalculateNorm, but what is it meant to do? What is the significance of the arguments s and p?
In the code segment below, we give a description of the function immediately before its definition. This description gives, in line 3, a means of mapping the mathematics of the function to its implementation. The rest of the description gives an alternate place to find more information about the p-norm (lines 4–6) and an explanation of some of the arguments as necessary. In the body of the function, the loop has been commented to describe what its functional purpose is: it is about computing a sum over the elements of the vector. Finally, the return value is commented with a few words of explanation.
Note that documenting code is sometimes more of an art than a science. There is a balance to be struck concerning the right level of documentation. Too many comments can make the program less readable rather than more readable. Our tip here is that you should describe what part of the problem the code is solving and, perhaps, how it is solving that problem. Do not be tempted to describe the code in overmuch detail. For example, the comment on the loop in line 12 of code above could have read
While this comment is accurate (describing the range of the loop variable vecSize), it does nothing to aid a programmer in their understanding of the code.
The formatting of the code documentation can also help readability. A simple tip is that using empty lines to break code and comments into sections can make the code look more readable. If you want to emphasise something you can simulate underlining with hyphens or underscores, for example,
Alternatively, you can emphasise something by putting it in a box:
5.11 Exercises
In all exercises, we suggest that you use dynamic allocation of memory for vectors and matrices as described in Sect. 4.2. Be sure that you are correctly de-allocating memory when using dynamic allocation of memory, as explained in the exercises at the end of Chap. 4.
5.1
Write code that sends the address of an integer to a function that prints out the value of the integer.
5.2
Write code that sends the address of an integer to a function that changes the value of the integer.
5.3
Write a function that swaps the values of two double precision floating point numbers, so that these changes are visible in the code that has called this function.
1.
Write this function using pointers.
2.
Write this function using references.
5.4
Write a function that can be used to calculate the mean and standard deviation of an array of double precision floating point numbers. Note that the standard deviation of a collection of numbers is given by
where is the mean of the numbers.
5.5
Write a function Multiply that may be used to multiply two matrices given the matrices and the size of both matrices. Use assertions to verify that the matrices are of suitable sizes to be multiplied.
5.6
Overload the function Multiply written in the previous exercise so that it may be used to multiply:
1.
a vector and a matrix of given sizes;
2.
a matrix and a vector of given sizes;
3.
a scalar and a matrix of a given size; and
4.
a matrix of a given size and a scalar.
5.7
The p-norm of a vector v of length n is given by
where p is a positive integer. Extend the code in Sect. 5.10 to calculate the p-norm of a given vector, where p takes the default value 2.
5.8
The determinant of a square matrix may be defined recursively: see Sect. A.1.3. Write a recursive function that may be used to calculate the determinant of a square matrix of a given size. Check the accuracy of your code by comparison with the known formulae for square matrices of size 2 and 3:
5.9
Write a module for solving the 3 3 linear system Aub where A is nonsingular.
5.10
Write a module for solving the nn linear system Aub using Gaussian elimination with pivoting, where A is nonsingular. See Sect. A.2.1.3 for details of this algorithm.





 re
re , we may wish to write a function that returns the real part, denoted by the variable x, and imaginary part, denoted by the variable y, of this number. We have noted earlier that a function can only return one variable, and so we may not return both the variable x and the variable y. It would therefore be useful to include the variables x and y in the function call. However, this would not work either, as the values assigned to these variables would not have any effect outside the function. Fortunately pointers provide us with one way around this problem. Instead of sending the variables x and y to the function, we send the addresses of these variables to the function. When the function is called, copies are made of the addresses of these variables, and it is these copies that are sent to the function. Changes to these addresses will not have any effect outside the function as we are working with a copy of these addresses. However, we can change the contents of the variable without changing the address through de-referencing the pointer, and this will have an effect outside of the function. This is demonstrated in the code below.
, we may wish to write a function that returns the real part, denoted by the variable x, and imaginary part, denoted by the variable y, of this number. We have noted earlier that a function can only return one variable, and so we may not return both the variable x and the variable y. It would therefore be useful to include the variables x and y in the function call. However, this would not work either, as the values assigned to these variables would not have any effect outside the function. Fortunately pointers provide us with one way around this problem. Instead of sending the variables x and y to the function, we send the addresses of these variables to the function. When the function is called, copies are made of the addresses of these variables, and it is these copies that are sent to the function. Changes to these addresses will not have any effect outside the function as we are working with a copy of these addresses. However, we can change the contents of the variable without changing the address through de-referencing the pointer, and this will have an effect outside of the function. This is demonstrated in the code below.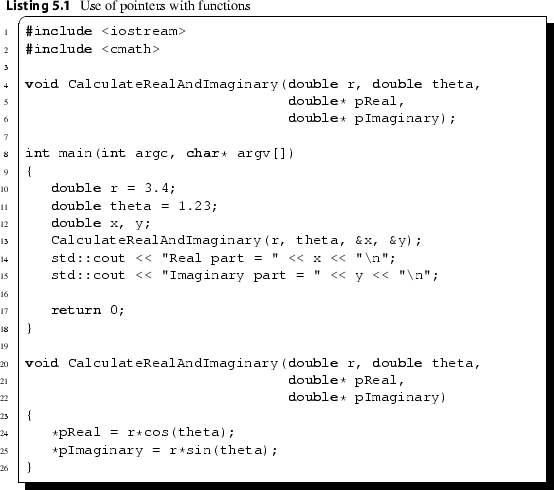



 . Only on very rare occasions would we want to change this tolerance. We might also want to restrict the number of function evaluations: the Newton–Raphson iteration will probably be implemented using a while loop, and numerical rounding errors may prevent the error being sufficiently small for the iteration to terminate. Under these conditions, we would never exit the while loop, and the program that called this function would never terminate. It would therefore be prudent to write a function for implementing the Newton–Raphson technique that sets a default tolerance for the solution, and a default maximum number of iterations. We would then be able to call this function without specifying these default values. However, if we did want to call this function with different values then we would like to be able to do this. This is easily achieved by setting default values in the function prototype. This is demonstrated below in a program that uses the Newton–Raphson technique for calculating the cube root of a given number K through solving the nonlinear equation
. Only on very rare occasions would we want to change this tolerance. We might also want to restrict the number of function evaluations: the Newton–Raphson iteration will probably be implemented using a while loop, and numerical rounding errors may prevent the error being sufficiently small for the iteration to terminate. Under these conditions, we would never exit the while loop, and the program that called this function would never terminate. It would therefore be prudent to write a function for implementing the Newton–Raphson technique that sets a default tolerance for the solution, and a default maximum number of iterations. We would then be able to call this function without specifying these default values. However, if we did want to call this function with different values then we would like to be able to do this. This is easily achieved by setting default values in the function prototype. This is demonstrated below in a program that uses the Newton–Raphson technique for calculating the cube root of a given number K through solving the nonlinear equation  . Using a given initial guess x
. Using a given initial guess x , the Newton–Raphson method results in the iteration
, the Newton–Raphson method results in the iteration




 0 using the Newton–Raphson technique, where f is a user-specified function. We may want to call this function for solving nonlinear equations more than once during the execution of a given program, and for different user-specified nonlinear functions. To achieve this, we need to specify the appropriate nonlinear function each time the function is called. This may be done, as demonstrated in the code below, using function pointers.
0 using the Newton–Raphson technique, where f is a user-specified function. We may want to call this function for solving nonlinear equations more than once during the execution of a given program, and for different user-specified nonlinear functions. To achieve this, we need to specify the appropriate nonlinear function each time the function is called. This may be done, as demonstrated in the code below, using function pointers.
 with initial guess x
with initial guess x  1: the nonlinear function Sqrt10, and the derivative of the nonlinear function Sqrt10Prime are given in lines 19–22 and 26–29 of the code. Similarly, in lines 48 and 49 we call the Newton–Raphson solver to solve the equation
1: the nonlinear function Sqrt10, and the derivative of the nonlinear function Sqrt10Prime are given in lines 19–22 and 26–29 of the code. Similarly, in lines 48 and 49 we call the Newton–Raphson solver to solve the equation  with initial guess x
with initial guess x  1: the nonlinear function Cube10, and the derivative of the nonlinear function Cube10Prime are given in lines 32–35 and 39–42 of the code.
1: the nonlinear function Cube10, and the derivative of the nonlinear function Cube10Prime are given in lines 32–35 and 39–42 of the code. 
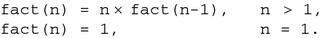

 b, where A is a square, invertible matrix of size n, b is a specified vector of size n, and x is a vector to be calculated of size n. It would be useful if we could write all the functions required to solve this linear system and then allow these functions to be called through an appropriate function—that is, we want to write a function called SolveLinearSys with the prototype shown below.
b, where A is a square, invertible matrix of size n, b is a specified vector of size n, and x is a vector to be calculated of size n. It would be useful if we could write all the functions required to solve this linear system and then allow these functions to be called through an appropriate function—that is, we want to write a function called SolveLinearSys with the prototype shown below. 


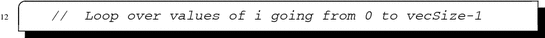


 of a collection of numbers
of a collection of numbers  is given by
is given by
 is the mean of the numbers.
is the mean of the numbers.

 3 linear system Au
3 linear system Au  b where A is nonsingular.
b where A is nonsingular. n linear system Au
n linear system Au  b using Gaussian elimination with pivoting, where A is nonsingular. See Sect. A.2.1.3 for details of this algorithm.
b using Gaussian elimination with pivoting, where A is nonsingular. See Sect. A.2.1.3 for details of this algorithm.