There is a room in the Musée d’Orsay that I call the “room of possibilities.” The museum is roughly set up chronologically, happily wending its way through the nineteenth century, until you hit this one room with a group of painterly responses to the invention of the camera—about a half dozen proposals for the way painting could respond. One that sticks in my mind is a trompe l’oeil solution where a figure is painted literally reaching out of the frame into the “viewer’s space.” Another incorporates three-dimensional objects atop the canvas. Great attempts, but as we all know, impressionism—and hence modernism—won out. Writing is at such a juncture today.
With the rise of the Web, writing has met its photography. By that, I mean writing has encountered a situation similar to what happened to painting with the invention of photography, a technology so much better at replicating reality that, in order to survive, painting had to alter its course radically. If photography was striving for sharp focus, painting was forced to go soft, hence impressionism. It was a perfect analog to analog correspondence, for nowhere lurking beneath the surface of either painting, photography, or film was a speck of language. Instead, it was image to image, thus setting the stage for an imagistic revolution.
Today, digital media has set the stage for a literary revolution. In 1974 Peter Bürger was still able to make the claim that “because the advent of photography makes possible the precise mechanical reproduction of reality, the mimetic function of the fine arts withers. But the limits of this explanatory model become clear when one calls to mind that it cannot be transferred to literature. For in literature, there is no technical innovation that could have produced an effect comparable to that of photography in the fine arts.”1 Now there is.
If painting reacted to photography by going abstract, it seems unlikely that writing is doing the same in relation to the Internet. It appears that writing’s response—taking its cues more from photography than painting—could be mimetic and replicative, primarily involving methods of distribution, while proposing new platforms of receivership and readership. Words very well might not only be written to be read but rather to be shared, moved, and manipulated, sometimes by humans, more often by machines, providing us with an extraordinary opportunity to reconsider what writing is and to define new roles for the writer. While traditional notions of writing are primarily focused on “originality” and “creativity,” the digital environment fosters new skill sets that include “manipulation” and “management” of the heaps of already existent and ever-increasing language. While the writer today is challenged by having to “go up” against a proliferation of words and compete for attention, she can use this proliferation in unexpected ways to create works that are as expressive and meaningful as works constructed in more traditional ways.
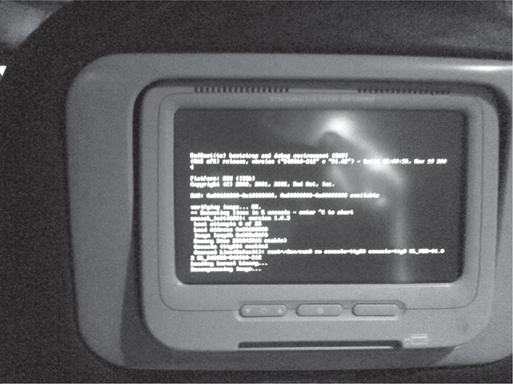
I’m on my way back to New York from Europe and am gazing wearily at the map charting our plodding progress on the screen sunk into the seatback in front of me. The slick topographic world map is rendered two dimensionally, showing the entire earth, half in darkness, half in light, with us—represented as a small white aircraft—making our way west. The screens change frequently, from graphical maps to a series of blue textual screens announcing our distance to destination—the time, the aircraft’s speed, the outside air temperature, and so forth—all rendered in elegant white sans serif type. Watching the plane chart its progress is ambient and relaxing as the beautiful renderings of oceanic plates and exotic names of small towns off the North Atlantic—Gander, Glace Bay, Carbonear—stream by.
Figure 1.1. DOS Startup screen on an airplane.
Suddenly, as we approach the Grand Banks off the coast of Newfoundland, my screen flickers and goes black. It stays that way for some time, until it illuminates again, this time displaying generic white type on a black screen: the computer is rebooting and all those gorgeous graphics have been replaced by lines of DOS startup text. For a full five minutes, I watch line command descriptions of systems unfurling, fonts loading, and graphic packages decompressing. Finally, the screen goes blue and a progress bar and hourglass appear as the GUI loads, returning me back to the live map just as we hit landfall.
What we take to be graphics, sounds, and motion in our screen world is merely a thin skin under which resides miles and miles of language. Occasionally, as on my flight, the skin is punctured and, like getting a glimpse under the hood, we see that our digital world—our images, our film and video, our sound, our words, our information—is powered by language. And all this binary information—music, video, photographs—is comprised of language, miles and miles of alphanumeric code. If you need evidence of this, think of when you’ve mistakenly received a .jpg attachment in an e-mail that has been rendered not as image but as code that seems to go on forever. It’s all words (though perhaps not in any order that we can understand): The basic material that has propelled writing since its stabilized form is now what all media is created from as well.
Besides functionality, code also possesses literary value. If we frame that code and read it through the lens of literary criticism, we will find that the past hundred years of modernist and postmodernist writing has demonstrated the artistic value of similar seemingly arbitrary arrangements of letters.
Here’s a three lines of a .jpg opened in a text editor:
^?Îj€≈ÔI∂fl¥d4˙‡À,†ΩÑÎóªjËqsõëY”Δ″/å)1Í.§ÏÄ@˙’∫JCGOnaå$ë¶æQÍ″5ô’5å
p#n›=ÃWmÃflÓàüú*Êœi”›_$îÛμ}Tß‹æ´’[“Ò*ä≠ˇ
Í=äÖΩ;Í”≠Õ¢ø¥}è&£S¨Æπ›ëÉk©ı=/Á″/”˙ûöÈ>∞ad_ïÉúö˙€Ì—éÆΔ’aø6ªÿ-
Of course a close reading of the text reveals very little, semantically or narratively. Instead, a conventional glance at the piece reveals a nonsensical collection of letters and symbols, literally a code that might be deciphered into something sensible.
Yet what happens when sense is not foregrounded as being of primary importance? Instead, we need to ask other questions of the text. Below are three lines from a poem by Charles Bernstein called “Lift Off,” written in 1979:
HH/ ie,s obVrsxr;atjrn dugh seineocpcy i iibalfmgmMw
er,,me”ius ieigorcy¢jeuvine+pee.)a/nat” ihl”n,s
ortnsihcldseløøpitemoBruce-oOiwvewaa39osoanfJ++,r”P2
Intentionally bereft of literary tropes and conveyances of human emotion, Bernstein chooses to emphasize the workings of a machine rather than the sentiments of a human. In fact, the piece is what its title says it is: a transcription of everything lifted off a page with a correction tape from a manual typewriter. Bernstein’s poem is, in some sense, code posing as a poem: careful reading will reveal bits of words and the occasional full word that was erased. For example, you can see the word “Bruce” on the last line, possibly referring to Bruce Andrews, Bernstein’s coeditor of the journal L=A=N=G=U=G=A=G=E. But such attempts at reassembling won’t get us too far: what we’re left with are shards of language comprised of errors from unknown documents. In this way Bernstein emphasizes the fragmentary nature of language, reminding us that, even in this shattered state, all morphemes are prescribed with any number of references and contexts; in this case the resultant text is a tissue of quotations drawn from a series of ghost writings.
Bernstein’s poem comes at the end of a long line of modernist poetry and prose that sought to foreground the materiality of language while allowing varying levels of emotion or sense to come through, throwing into question traditional notions of authorship. Stéphane Mallarmé’s Un coup de dés jamais n’abolira le hasard (A throw of the dice will never abolish chance; 1897) is a poem whose words—and their placement on the page—have been subjected to chance, scattering stability, controlled authorship, and prescribed ways of reading to the winds. Words are no longer primarily transparent content carriers; now their material quality must be considered as well. The page becomes a canvas, with the negative spaces between the words taking on as much import as the letters themselves. The text becomes active, begging us to perform it, employing the spaces as silences. Indeed, the author himself reiterates this by claiming that “the paper intervenes each time as an image.”3 Mallarmé asks us to consider the act of reading—whether silent or aloud—as an act of decoding by actualizing and materializing the symbols (in this case letters) on a page.
Mallarmé’s letteristic materiality inspires others to explore the same: whether it’s Gertrude Stein’s columns’ eye-tickling repetitions or Ezra Pound’s later Cantos, writers continued to treat words materially as the century progressed. Parts of Pound’s epic are filled with barely decipherable words comprised of dozens of languages jammed together with annotations and references to nonexistent footnotes:
It’s a sound poem, a concrete poem, and a lyrical poem all rolled into one. It’s both multilingual—bits of Chinese mingle with the “patter” of English—and nonlingual. Pound’s constellations hold the page like calligraphic strokes begging to be spoken aloud. This is active language, reminiscent of the sorts of tag clouds that you see today on Web pages, language that begs to be interacted with, to be clicked on, to be highlighted and copied.
James Joyce’s thunderclaps are the ten one-hundred-letter words scattered throughout Finnegans Wake, a six-hundred-page book of compound words and neologisms, all of which look to the uninitiated like reams of nonsensical code:
bababadalgharaghtakamminaronnonnbronntonnerronnuonnthunntrobarrhounawnskawntoohoohoordenenthurknuk
Spoken aloud, it’s the sound of thunder. This, of course, goes for the rest of Finnegans Wake, which, on first sight, is one of the most disorienting books ever written in English. But hearing Joyce read/decode a portion of FinnegansWake, most famously his own recording of the “Anna Livia Plurabelle” section, is a revelation: it all makes sense, coming close to standard English, yet on the page it remains “code.” Reading aloud is an act of decoding. Taken one step further, the act of reading itself is an act of decoding, deciphering, and decryption.
Computer code, made up of numbers—1s and 0s—can’t possibly have any literary or aesthetic value. Or can it? The twentieth century was brimming with number poems. Take this transcribed excerpt from a series called “Seven Numbers Poems” by British poet Neil Mills, published in 1971:
1,9
1,1,9
1,1,1,9
9
1,1,1,1,9
8,4
1,1,1,1,1,9
8,4
8,4
If you read it aloud, you’ll find it transform from a seemingly random bunch of numbers into a complex and beautiful rhythmic poem. Mills states, “I believed that the meaning which emerged in the reading of poetry lay primarily in intonation and rhythm, and only secondarily in semantic content i.e. that what was important was how something was read, rather than what was said—the human voice functioning as musical instrument.”5
The contemporary Japanese poet Shigeru Matsui writes what he calls “Pure Poems,” which come closest to the alphanumeric binaries we find in computer code. Begun in early 2001 and currently numbering in the hundreds, they are based on the 20 x 20 grid of standard Japanese writing paper. Every “Pure Poem” consists of four hundred characters, each a number from one to three. Originally written in Chinese script, which figures the numbers one, two, and three with a single, a double, and triple dash accordingly, later poems are written with roman numerals.
1007∼1103
III III I III I III I III III II II I II I I II II II I III
II II III II III II III II II I I III I III III I I I III II
III III II I I I II III I II I II I II II III I III II III
II II I III III III I II III I III I III I I II III II I II
I I III II II II III I II III II III II III III I II I III I
III I II I III III II II I II III II I I II I III III II I
II III I III II II I I III I II I III III I III II II I III
I II III II I I III III II III I III II II III II I I III II
I III II I I III II II III II I I I III II I II III II III
III II I III III II I I II I III III III II I III I II I II
II I III II II I III III I III II II II I III II III I III I
I I II I III I II II III II III III III I II I II III I II
III III I III II III I I II I II II II III I III I II III I
II II III II I II III III I III I I I II III II III I II III
I III II I I I II II I II II I III III I III II III III II
III II I III III III I I III I I III II II III II I II II I
II I III II II II III III II III III II I I II I III I I III
III II II I III I I II I II II III I I III III II III I II
II I I III II III III I III I I II III III II II I II III I
I III III II I II II III II III III I II II I I III I II III
When Matsui reads these poems aloud, they’re absolutely precise and hypnotic to listen to.
Read through the lens of these examples, a translation of a common computer icon graphic into its hex code has literary value. Here is the code that’s rendered into the W that you see in your Web browser’s address bar every time you load a Wikipedia page, called a favicon:

A close reading of the favicon reveals an enormous amount of literary and aesthetic value, rhythmically, visually, and structurally unfolding like a piece of minimalist music. The first column of numbers logically progresses in steps from 0000000 to 0000090, then takes a short derivation into 00000a0—00000f0 before picking back up to 0000100. Patterns occur in the horizontal lines as well, with minute variations on 1s, 0s, 2s, 8s, and 4s in the first four lines, before shifting over to combinations of numbers and letters in the middle section, only to be broken up by several 8888s in the mid to lower portion. Squint your eyes and you can almost discern the W embedded within the square of the code. Of course, this isn’t poetry, nor was it meant to be, rather it shows us that even seemingly meaningless and random sets of alphanumeric can be infused with poetic qualities. While this language is primarily concerned with transforming from one state to another (from code to icon), those same transformative qualities—language acting upon more language—is the foundation for much of the new writing.
There’s a Flickr pool called “The Public Computer Errors Pool” that documents what I experienced on my flight multiplied a hundred.6 It’s a fascinating set of photos. You see a digital elevator button displaying a question mark instead of a number, ATMs in reboot mode, subway advertisement signs with “out of memory” error messages, and flight arrival boards punctured by Windows desktops. My favorite is a larger-than-life size Mrs. Potato Head at an amusement park holding a display with a blue DOS screen filled with cold white letters where clearly something more child-friendly should have been. This photo pool documents the puncturing of the interface covering language.
But don’t take my word for it. You can easily create these textual ruptures on your computer. Take any MP3 file—we’ll use the prelude from Bach’s “Cello Suite No. 1”—and change the filename extension from .mp3 to .txt. Open the document in a text editor, you’ll see gobs of nonsensical alphanumeric code/language. Now, take any text—let’s say for the sake of consistency, we take Bach’s whole Wikipedia entry—and paste it into the middle of that code. Then save it and rename the file with the .mp3 extension. If you double click it and open it your MP3 player, it’ll play the file as usual, but when it hits the Wikipedia text, it coughs, glitches, and spits for the duration of time it takes for the player to decode that bit of language before going back to the prelude. With these sorts of manipulations, we find ourselves in new territory: While many types of analog mashups were created in the predigital age—such as the cutting up and gluing together of two separate LP halves or splicing magnetic tapes into collages—there was no language acting upon other language to form such ruptures. With digital media, we’re squarely in the world of textual manipulation, which not too long ago was almost the exclusive province of “writing” and “literature.”7
We can do the same thing with images. Let’s take a .jpg of the famous Droeshout engraving from the title page of the 1623 First Folio edition of Shakespeare’s plays and change the extension from .jpg to .txt. When we open it in a text editor, we’ll see garbled code. Now let’s insert his ninety-third sonnet into it, three times at somewhat equal intervals, and save the file and change the extension back to .jpg.

Figure 1.2. Inserting Shakespeare’s 93d sonnet three times into the source code of an image.
When we reopen it as an image, the effect that language had upon the image is clear:

Figure 1.3. The Droeshout Engraving before.
Figure 1.4. The Droeshout Engraving, after inserting text.
What we’re experiencing for the first time is the ability of language to alter all media, be it images, video, music, or text, something that represents a break with tradition and charts the path for new uses of language. Words are active and affective in concrete ways. You could say that this isn’t writing, and, in the traditional sense, you’d be right. But this is where things get interesting: we aren’t hammering away on typewriters; instead—focused all day on powerful machines with infinite possibilities, connected to networks with a number of equally infinite possibilities—the writer’s role is being significantly challenged, expanded, and updated.
Quantity Is the New Quality
In the face of unprecedented amount of digital text, writing needs to redefine itself in order to adapt to the new environment of textual abundance. What do I mean by textual abundance? A recent study showed that “in 2008, the average American consumed 100,000 words of information in a single day. (By comparison, Leo Tolstoy’s War and Peace is only about 460,000 words long.) This doesn’t mean we read 100,000 words a day—it means that 100,000 words cross our eyes and ears in a single 24-hour period.”8
I’m inspired by how these studies treat words materially. They’re not concerned with what words mean but with how much they weigh. In fact, when media studies wanted to first quantify language, they used words as their metric, a practice that continues to this day:
In 1960, digital sources of information were non-existent. Broadcast television was analog, electronic technology used vacuum tubes rather than microchips, computers barely existed and were mainly used by the government and a few very large companies … The concept that we now know as bytes barely existed. Early efforts to size up the information economy therefore used words as the best barometer for understanding consumption of information.
Using words as a metric … [it is] estimated that 4,500 trillion words were “consumed” in 1980. We calculate that words consumed grew to 10,845 trillion words in 2008, which works out to about 100,000 words per American per day.9
Of course, one can never know what all those words mean or if they have any use whatsoever, but for writers and artists—who often specialize in seeing value in things that most people overlook—this glut of language signifies a dramatic shift in their relationship to words. Since the dawn of media, we’ve had more on our plates than we could ever consume, but something has radically changed: never before has language had so much materiality —fluidity, plasticity, malleability—begging to be actively managed by the writer. Before digital language, words were almost always found imprisoned on a page. How different today when digitized language can be poured into any conceivable container: text typed into a Microsoft Word document can be parsed into a database, visually morphed in Photoshop, animated in Flash, pumped into online text-mangling engines, spammed to thousands of e-mail addresses, and imported into a sound editing program and spit out as music. The possibilities are endless.
In 1990 the Whitney Museum mounted a show called Image World, which speculated that as a result of television’s complete rule and saturation words would disappear from media, replaced by images. It seemed plausible at the time, with the rise of cable and satellite concurrent with the demise of print. The catalog decried the ubiquity and subsequent victory of images:
Every day … the average person is exposed to 1,600 ads…. the atmosphere is thick with messages. Every hour, every day, news, weather, traffc, business, consumer, cultural, and religious programming is broadcast on more than 1,200 network, cable, and public-access television channels. Television shows (60 Minutes) are constructed by like magazines, and newspapers (USA Today) emulate the structure of television. Successful magazine articles provide the plots for movies that manufacture related merchandise and then spin-off television series which, in turn, are novelized.10
Similarly, in 1998 Mitchell Stephens published a book called The Rise of the Image, the Fall of the Word, which charts the demise of the printed word, beginning with Plato’s distrust of writing. Stephens, a great lover of print, saw the future as video: “Moving images use our senses more effectively than do black lines of types stacked on white pages.”11 Stephens is right, but what he couldn’t see was that in the future video would be comprised entirely of black lines of type.
The curators of Image World and Mitchell Stephens were blind-sided by the Web, a then-emerging text-based technology that would soon grow to challenge—and overwhelm—their claims of imagistic dominance. Even as the digital revolution grows more imagistic and motion-based (propelled by language), there’s been a huge increase in text-based forms, from typing e-mails to writing blog posts, text messaging, social networking status updates, and Twitter blasts: we’re deeper in words than we’ve ever been.
Even Marshall McLuhan, who was so right about so many things predicting our digital world, got this one wrong. He, too, saw the coming of Image World and railed against the linearity of Gutenberg, predicting that we were headed to a return of an orally based, sensual, tactile, multimedia world that would eradicate the narrow centuries of the textual prison. And, in that, he was right: as the Web grows, it becomes richer, more tactile, more intermediary. But McLuhan would still have to reckon with the fact that these riches are ultimately driven by language in neat rows, programmed by even stricter bonds than any rhetorical form that preceded it.
But, far from McLuhan’s prison of words in straight lines, the flip side of digital language is its malleability, language as putty, language to wrap your hands around, to caress, mold, strangle. The result is that digital language foregrounds its material aspect in ways that were hidden before.
A Textual Ecosystem
If we think of words as both carriers of semantic meaning and as material objects, it becomes clear that we need a way to manage it all, an ecosystem that can encompass language in its myriad forms. I’d like to propose such a system, taking as inspiration James Joyce’s famous meditation on the universal properties of water in the Ithaca episode of Ulysses.
When Joyce writes about the different forms that water can take, it reminds me of different forms that digital language can take. Speaking of the way water puddles and collects in “its variety of forms in loughs and bays and gulfs,” I am reminded of the process whereby data rains down from the network in small pieces when I use a Bit-Torrent client, pooling in my download folder. When my download is complete, the data finds its “solidity in glaciers, icebergs, icefloes” as a movie or music file. When Joyce speaks of water’s mutability from its liquid state into “vapour, mist, cloud, rain, sleet, snow, hail,” I am reminded of what happens when I join a network of torrents and I begin “seeding” and uploading to the data cloud, the file simultaneously constructing and deconstructing itself at the same time. The utopian rhetoric surrounding data flows—“information wants to be free,” for example—is echoed by Joyce when he notes water’s democratic properties, how it is always “seeking its own level.” He acknowledges water’s double economic status in both “its climatic and commercial significance,” just as we know that data is bought and sold as well as given away. When Joyce speaks of water’s “weight and volume and density,” I’m thrown back to the way in which words are used as quantifiers of information and activity, entities to be weighed and sorted. When he writes about the potential for water’s drama and catastrophe “its violence in seaquakes, waterspouts, artesian wells, eruptions, torrents, eddies, freshets, spates, groundswells, watersheds, waterpartings, geysers, cataracts, whirlpools, maelstroms, inundations, deluges, cloudbursts,” I think of electrical spikes that wipe out hard drives, wildly spreading viruses, or what happens to my data when I bring a strong magnet too close to my laptop, disastrously scrambling my data in every direction. Joyce speaks of water the way data flows through our networks with “its vehicular ramifications in continental lakecontained streams and confluent ocean flowing rivers with their tributaries and transoceanic currents: gulf-stream, north and south equatorial courses,” while speaking of its upsides, “its properties for cleansing, quenching thirst and fire, nourishing vegetation: its infallibility as paradigm and paragon.”12
While writers have traditionally taken great pains to ensure that their texts “flow,” in the context of our Joyce-inspired language/data ecosystem, this takes on a whole new meaning, as writers are the custodians of this ecology. Having moved from the traditional position of being solely generative entities to information managers with organizational capacities, writers are potentially poised to assume the tasks once thought to belong only to programmers, database minders, and librarians, thus blurring the distinction between archivists, writers, producers, and consumers.
Using methods similar to Lethem, Joyce composed this passage by patchwriting an encyclopedia entry on water. By doing so, he actively demonstrates the fluidity of language, moving language from one place to another. Joyce presages uncreative writing by the act of sorting words, weighing which are “signal” and which are “noise,” what’s worth keeping and what’s worth leaving. Identifying—weighing—language in its various states of “data” and “information” is crucial to the health of the ecosystem:
Data in the 21st century is largely ephemeral, because it is so easily produced: a machine creates it, uses it for a few seconds and overwrites it as new data arrives. Some data is never examined at all, such as scientific experiments that collect so much raw data that scientists never look at most of it. Only a fraction ever gets stored on a medium such as a hard drive, tape or sheet of paper, yet even ephemeral data often has “descendents”—new data based on the old. Think of data as oil and information as gasoline: a tanker of crude oil is not useful until it arrives, its cargo unladed and refined into gasoline that is distributed to service stations. Data is not information until it becomes available to potential consumers of that information. On the other hand, data, like crude oil, contains potential value.13
How can we discard something that might in another configuration be extremely valuable? As a result, we’ve become hoarders of data, hoping that at some point we’ll have a “use” for it. Look at what’s on your hard drive in reserve (pooled, as Joyce would say) as compared to what you actually use. On my laptop, I have hundreds of fully indexable PDFs of e-books. Do I use them? Not in any regular way. I store them for future use. Like those PDFs, all the data that’s stored on my hard drive is part of my local textual ecosystem. My computer indexes what’s on my hard drive and makes it easier for me to search what I need by keyword. The local ecosystem is pretty stable; when new textual material is generated, my computer indexes it as data as soon as it’s created. On the other hand, my computer doesn’t index information: if I’m looking for a specific scene in a movie on my drive, my computer will not be able to find that unless I have, say, a script of the film on my system. Even though digitized films are made of language, my computer’s search function only, in Joycean terms, skims the surface of the water, recognizing only one state of language. What happens on my local ecosystem is prescribed, limited to its routine, striving to function harmoniously. I have software to protect against any viruses that might destabilize or contaminate it, allowing my computer to run as it’s supposed to.
Things get more complicated when I connect my computer to a network, suddenly transforming my local ecosystem into a node on a global one. All I need to do is to send and receive an e-mail to show the linguistic effects of the networked ecosystem. If I take a plain text version of the nursery rhyme Edison used to test the phonograph with, “Mary Had a Little Lamb”:
Mary had a little lamb,
little lamb, little lamb,
Mary had a little lamb,
whose fleece was white as snow.
And everywhere that Mary went,
Mary went, Mary went,
and everywhere that Mary went,
the lamb was sure to go.
and e-mail it to myself, it comes back:
Received: from [10.10.0.28] (unverified [212.17.152.146])
by zarcrom.net (SurgeMail 4.0j) with ESMTP id
58966155–1863875
for <xxx@ubu.com>; Sun, 26 Apr 2009 18:17:50 -0500
Return-Path: <xxx@ubu.com>
Mime-Version: 1.0
Message-Id: <p06210214c61a9c1ef20d@[10.10.0.28]>
Date: Mon, 27 Apr 2009 01:17:55 +0200
To: xxx@ubu.com
From: Kenneth Goldsmith <xxx@ubu.com>
Subject: Mary Had A Little Lamb
Content-Type: multipart/alternative; boundary=“============ _-971334617==_ma============“
X-Authenticated-User: xxx@ubu.com
X-Rcpt-To: <xxx@ubu.com>
X-IP-stats: Incoming Last 0, First 3, in=57, out=0, spam=0 ip=212.17.152.146
Status: RO
X-UIDL: 1685
<x-html><!x-stuff-for-pete base=““ src=““ id=“0” charset=““>
<!doctype html public “-//W3C//DTD W3 HTML//EN”>
<html><head><style type=“text/css”><!—
blockquote, dl, ul, ol, li { padding-top: 0 ; padding-bottom: 0 }
—></style><title>Mary Had A Little Lamb</title></head><body>
<div><font size=“+1” color=“#000000”>Mary had a little lamb,<br>
little lamb, little lamb,<br>
Mary had a little lamb,<br>
whose fleece was white as snow.<br>
And everywhere that Mary went,<br>
Mary went, Mary went,<br>
and everywhere that Mary went,<br>
the lamb was sure to go.</font></div>
</body>
</html>
</x-html>
While I haven’t written a word, my simple e-mail comes back to me a much more complex document than I sent out. The nursery rhyme, front and center when it left me, returns buried among reams of language, to the point where I almost can’t find it, padded out by many varieties of language. A remarkable amount of it is normal English words: Status, style, head, boundary; there’s also odd, poetic compounding of words: X-Authenticated-User, padding-bottom, SurgeMail; then there’s html tags: <br>, </font>, </div>; and strange stringings together of equal signs: ============; and finally, there’s lots of long numbers 58966155–1863875; and hybrid compounds: <p06210214c61a9c1ef20d@[10.10.0.28]>. What we’re seeing are the linguistic marks left by the network ecology on my text, all of which is a result of the journey the rhyme made by leaving my machine to interact with other machines. A paratextual reading of my e-mail would claim all the new texts as being of equal importance to the nursery rhyme. Identifying the sources of those texts and noting their subsequent impact is part of the reading and writing experience. The new text is a demonstration of local and networked ecologies acting together to create a new piece of writing.
We can create or enter into textual microclimates on a large scale—such as chat rooms or tweets—or more intimately with one-on-one instant messaging. Swarms of users on social networking sites around a keyword/trending topic can also create intensely focused microclimates of textuality.
I can take the transcript of an IM session, and, after stripping it of its networked context, it’s immediately indexed by my machine and entered back into the safe stasis of my local ecology. Now, let’s say I take that same transcript and upload a copy of it to a publicly accessible server where it can be downloaded, while keeping a copy on my PC. I have the identical text in two places, operating in two distinct ecosystems, like twins, one who spends his life close to home and the other who adventures out into the world: each textual life is marked accordingly. The text document on my PC sits untouched in a folder, remaining unchanged, while the text in play on the network is subject to untold changes: it can be cracked, password protected, stripped of its textual character, converted into plain text, remixed, written into, translated, deleted, eradicated, converted to sound, image, or video, and so forth. If a version of that text were somehow to find its way back to me, it might very well be more unrecognizable than my altered nursery rhyme.
The editing process that occurs between two people via e-mail of a word processing document is an example of a microclimate where the variables are extremely limited and controlled. The tracked editorial changes are extralinguistic and purposeful. Opening up the variables a little more, think of what happens when an MP3 is passed around from one user to another, each slightly remixing it, defying any definitive version. In these ecologies, final versions do not exist. Unlike the result of a printed book or pressed LP, there is no end-game, rather flux is inherent to the digital.
The text cycle is primarily additive, spawning new texts continuously. If a hosting directory is made public, language is siphoned off like water from a well, replicating it infinitely. There is no need to assume that—notwithstanding any of the aforementioned catastrophes—that a textual drought will occur. The morass of language does not deplete, rather it creates a wider, rhizomatic ecology, leading to a continuous and infinite variety of textual occurrences and interactions across both the network and the local environment.14
The uncreative writer constantly cruises the Web for new language, the cursor sucking up words from untold pages like a stealth encounter. Those words, sticky with residual junky code and formatting, are transferred back into the local environment and scrubbed with TextSoap, which restores them to their virginal states by removing extra spaces, repairing broken paragraphs, deleting e-mail forwarding marks, straightening curly quotation marks, even extracting text from the morass of HTML. With one click of a button, these soiled texts are cleaned and ready to be redeployed for future use.