CHAPTER 2
Health Care Data Quality
Chapter One provided an overview of the various types of health care data and information that are generated and used by health care organizations. We established the importance of understanding health care data and information in order to reach the goal of having effective health care information systems. There is another fundamental aspect of health care data and information that is central to developing effective health care information systems—data quality. Consider for a moment an organization with sophisticated health care information systems that affect every type of health care information, from patient specific to knowledge based. What if the quality of the documentation going into the systems is poor? What if there is no assurance that the reports generated from the systems are accurate or timely? How would the users of the systems react? Are those information systems beneficial or detrimental to the organization in achieving its goals?
According to the International Standards Organisation (ISO) definition, quality is “the totality of features and characteristics of an entity that bears on its ability to satisfy stated and implied needs” (ISO 8402–1986, Quality-Vocabulary). In this chapter we will examine several aspects of data quality. We begin by distinguishing between health care data and health care information. We then look at some problems associated with poor-quality health care data, both at an organizational level and across organizations. The discussion continues with a presentation of two sets of guidelines that can be used in evaluating data quality and ends with an examination of the major types of health care data errors.
DATA VERSUS INFORMATION
What is the difference between data and information? The simple answer is that information is processed data. Therefore, we can say that health care information is processed health care data. (We interpret processing broadly to cover everything from formal analysis to explanations supplied by the individual decision maker’s brain.) Health care data are raw health care facts, generally stored as characters, words, symbols, measurements, or statistics. One thing apparent about health care data is that they are generally not very useful for decision making. Health care data may describe a particular event, but alone and unprocessed they are not particularly helpful. Take, for example, this figure: 79 percent. By itself, what does it mean? If we process this datum further by indicating that it represents the average bed occupancy for a hospital for the month of January, it takes on more meaning. With the additional facts attached, is this figure now information? That depends. If all a health care executive wants or needs to know is the bed occupancy rate for January, this could be considered information. However, for the hospital executive who is interested in knowing the trend of the bed occupancy rate over time or how the facility’s bed occupancy rate compares to that of other, similar facilities, this is not yet information.
Knowledge is seen by some as the highest level in a hierarchy with data at the bottom and information in the middle (Figure 2.1). Knowledge is defined by Johns(1997, 53) as “a combination of rules, relationships, ideas, and experience.” Another way of thinking about knowledge is that it is information applied to rules, experiences, and relationships, with the result that it can be used for decision making. A journal article that describes the use of bed occupancy rates in decision making or one health care facility’s experience with improving its occupancy rates might be an example of knowledge.
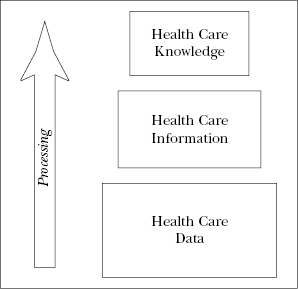
Figure 2.1. From data to knowledge
Where do health care data end and where does health care information begin? Information is an extremely valuable asset at all levels of the health care organization. Health care executives, clinical staff, and others rely on information to get their jobs accomplished. An interesting point to think about is that the same data may provide different information to different users. One person’s data may be another person’s information. Think back to our bed occupancy example. The health care executive needing verification of the rate for January has found her information. The health care executive needing trend analysis that includes this rate has not. In the second case, the rate for January is data needing to be processed further. The goal of this discussion is not to pinpoint where data end and information begins but rather to further an understanding of the relationship between health care data and information—health care data are the beginnings of health care information. You cannot create information without data (Lee, 2002).
PROBLEMS WITH POOR-QUALITY DATA
Now that we have established the relationship between health care data and health care information, we can look at some of the problems associated with having poor-quality data. Health care data are the source of health care information, so it stands to reason that a health care organization cannot have high-quality health care information without first establishing that it has high-quality health care data. Data quality must be established at the most granular level. Much health care information is gathered through patient care documentation by clinical providers and administrative staff either through manual or electronic systems. As was discussed in Chapter One, the patient record is the source for most of the clinical information generated by the health care organization. This clinical information is in turn coded for purposes of reimbursement and research. We also saw that medical record information is shared across many providers and payers, aggregated, and used to make comparisons relevant to health care and related issues.
This increased reliance on networked health care data brings new challenges in ensuring and maintaining high-quality data. The Markle Foundation’s Connecting for Health Collaborative identifies five negative effects of “dirty” (inaccurate, out-of-date, incomplete, and similar) health care data (Markle Foundation, 2006, p. 1):
- Affects the quality of care
- Introduces privacy and other civil liberty concerns
- Increases costs and inefficiencies
- Creates liability risks
- Undermines the reliability and benefits of information technology (IT) investments
Where do these “dirty” health care data originate? There are two essential components needed to ensure data quality: content and form. First, to ensure quality content, the data must have all of the characteristics outlined in the AHIMA Data Quality Model (discussed later in this chapter). In addition to these characteristics, however, the data must be stored and presented in a manner that makes it usable. This is form.
Problems with health care data content can generally be traced to documentation practices. This is not a problem limited to health care. The Markle Foundation notes that “76 percent of all errors, across sectors and settings, result from data entry” (2006, p 3).
Sharon Schott(2003) has summarized some of the common problems associated with poor-quality medical record documentation (see the following Perspective). She focuses on the medical record used as evidence in court, but the same problems can affect the quality of care, create civil liberty concerns, and increase costs.
The problems with poor-quality patient care data are not limited to the patient medical record or other data collected and used at the organizational level. The Medical Records Institute (MRI), a professional organization dedicated to the improvement of patient records through technology, has identified five major functions that are negatively affected by poor-quality documentation (MRI, 2004). These problems are found not only at the organizational level but also across organizations and throughout the overall health care environment:
- Patient safety is affected by inadequate information, illegible entries, misinterpretations, and insufficient interoperability.
- Public safety, a major component of public health, is diminished by the inability to collect information in a coordinated, timely manner at the provider level in response to epidemics and the threat of terrorism.
- Continuity of patient care is adversely affected by the lack of shareable information among patient care providers.
- Health care economics are adversely affected, with information capture and report generation costs currently estimated to be well over $50 billion annually.
- Clinical research and outcomes analysis is adversely affected by a lack of uniform information capture that is needed to facilitate the derivation of data from routine patient care documentation [MRI, 2004, p. 2].
This same report identifies health care documentation as having two parts: information capture and report generation. Information capture is “the process of recording representations of human thought, perceptions, or actions in documenting patient care, as well as device-generated information that is gathered and/or computed about a patient as part of health care” (MRI, 2004, p. 2). Some means of information capture in health care organizations are handwriting, speaking, typing, touching a screen or pointing and clicking on words or phrases, videotaping, audio recording, and generating images through X-rays and scans. Report generation “consists of the formatting and/or structuring of captured information. It is the process of analyzing, organizing, and presenting recorded patient information for authentication and inclusion in the patient’s healthcare record” (MRI, 2004, p. 2). In order to have high-quality documentation resulting in high-quality data, both information capture and report generation must be considered.
ENSURING DATA AND INFORMATION QUALITY
The importance of having quality health care information available to providers and health care executives cannot be overstated. Health care decision makers rely on high-quality information. The issue is not whether quality information is important but rather how it can be achieved. Before an organization can measure the quality of the information it produces and uses, it must establish data standards. That is, data can be identified as high quality only when they conform to a recognized standard. Ensuring this conformance is not as easy as it might seem because, unfortunately, there is no universally recognized set of health care data quality standards in existence today. One reason for this is that the quality of the data needed in any situation is driven by the use to which the data or the information that comes from the data will be put. For example, in a patient care setting the margin of error for critical lab tests must be zero or patient safety is in jeopardy. However, a larger margin of error may be acceptable in census counts or discharge statistics. Health care organizations must establish data quality standards specific to the intended use of the data or resulting information.
Although we have no nationally recognized data quality standards, two organizations have published guidance that can assist a health care organization in establishing its own data quality standards: the Medical Records Institute (MRI) has published a set of “essential principles of healthcare documentation,” and the American Health Information Management Association (AHIMA) has published a data quality management tool. These two guides are summarized in the following sections.
MRI Principles Of Health Care Documentation
The MRI argues that there are many steps that must be taken to create systems that ensure quality health care documentation. It has developed the following key principles that should be adhered to as these systems (and their accompanying policies) are established:
- Unique patient identification must be assured within and across healthcare documentation systems.
- Healthcare documentation must be
 Accurate and consistent.
Accurate and consistent.- Complete.
- Timely.
- Interoperable across types of documentation systems.
- Accessible at any time and at any place where patient care is needed.
- Auditable.
- Confidential and secure authentication and accountability must be provided [MRI, 2004, p. 3].
The MRI takes the position that when practitioners interact with electronic resources, they have an increased ability to meet these guidelines (MRI, 2004).
AHIMA Data Quality Model
AHIMA(2012) has developed and published a set of health care data quality characteristics. You will note similarities between these characteristics and the MRI principles. The AHIMA data quality characteristics can serve as the basis for establishing data quality standards because they represent common dimensions of health care data that should always be present, regardless of the use of the data or resulting information.
- Data accuracy. Data that reflect correct, valid values are accurate. Typographical errors in discharge summaries and misspelled names are examples of inaccurate data.
- Data accessibility. Data that are not available to the decision makers needing them are of no use.
- Data comprehensiveness. All of the data required for a particular use must be present and available to the user. Even relevant data may not be useful when they are incomplete.
- Data consistency. Quality data are consistent. Use of an abbreviation that has two different meanings is a good example of how lack of consistency can lead to problems. For example, a nurse may use the abbreviation CPR to mean cardiopulmonary resuscitation at one time and use it to mean computer-based patient record at another time, leading to confusion.
- Data currency. Many types of health care data become obsolete after a period of time. A patient’s admitting diagnosis is often not the same as the diagnosis recorded upon discharge. If a health care executive needs a report on the diagnoses treated during a particular time frame, which of these two diagnoses should be included?
- Data definition. Clear definitions of data elements must be provided so that both current and future data users will understand what the data mean. One way to supply clear data definitions is to use data dictionaries. A case described by A. M. Shakir(1999) offers an excellent example of the need for clear data definitions. (See the following Perspective.)
- Data granularity. Data granularity is sometimes referred to as data atomicity. That is, individual data elements are “atomic” in the sense that they cannot be further subdivided. For example, a typical patient’s name should generally be stored as three data elements (last name, first name, middle name—“Smith” and “John” and “Allen”), not as a single data element (“John Allen Smith”). Again, granularity is related to the purpose for which the data are collected. Although it is possible to subdivide a person’s birth date into separate fields for the month, the date, and the year, this is usually not desirable. The birth date is at its lowest practical level of granularity when used as a patient identifier. Values for data should be defined at the correct level for their use.
- Data precision. Precision often relates to numerical data. Precision denotes how close to an actual size, weight, or other standard a particular measurement is. Some health care data must be very precise. For example, in figuring a drug dosage it is not all right to round up to the nearest gram when the drug is to be dosed in milligrams.
- Data relevancy. Data must be relevant to the purpose for which they are collected. We could collect very accurate, timely data about a patient’s color preferences or choice of hairdresser, but are these matters relevant to the care of the patient?
- Data timeliness. Timeliness is a critical dimension in the quality of many types of health care data. For example, critical lab values must be available to the health care provider in a timely manner. Producing accurate results after the patient has been discharged may be of little or no value to the patient’s care.
Types and Causes of Data Errors
Failures of data to meet established quality standards are called data errors. A data error will have a negative impact on one or more of the characteristics of quality data. For example, if a final diagnosis is coded incorrectly, that datum is no longer accurate. If the same diagnosis is coded in several different ways, those data are not consistent. Both examples represent data errors. Data errors are often discussed in terms of two types of underlying cause—systematic errors and random errors (Table 2.1). Systematic errors are errors that can be attributed to a flaw or discrepancy in adherence to standard operating procedures or systems. The diagnosis coding errors just described would be systematic errors if they resulted from incorrect programming of the encoding software or improper training of the individuals assigning the codes. Systematic health care data errors can also be caused by unclear data definitions or a failure to comply with the established data collection protocols, such as leaving out required information. If the diagnosis coding errors were the result of poor handwriting or transcription errors, they would be considered random errors. Carelessness rather than lack of training leads to random errors (Arts, DeKeizer, & Scheffer, 2002).
Table 2.1. Some causes of poor health care data quality
Source: Adapted from Arts, DeKeizer, & Scheffer, 2002, p. 604.
| Systematic | Random |
| Unclear data definitions | Illegible handwriting in data source |
| Unclear data collection guidelines | Typing errors |
| Poor interface design | Lack of motivation |
| Programming errors | Frequent personnel turnover |
| Incomplete data source | Calculation errors (not built into the system) |
| Unsuitable data format in the source | |
| Data dictionary is lacking or not available | |
| Data dictionary is not adhered to | |
| Guidelines or protocols are not adhered to | |
| Lack of sufficient data checks | |
| No system for correcting detected data errors | |
| No control over adherence to guidelines and data definitions |
Preventing, Detecting, and Fixing Data Errors
Both systematic and random errors lead to poor-quality data and information. Both types need to be prevented to the extent possible. Errors that are not preventable need to be detected so that they can be corrected. There are multiple points during data collection and processing where system design can reduce data errors. The Markle Foundation recommends the following strategies to improve data quality. These combine automated and human strategies (2006, p. 4):
- Standardize data entry fields and processes for entering data
- Institute real-time quality checking, including the use of validation and feedback loops
- Design data elements to avoid errors (for example, use check digits and checking algorithms on numeric identifiers where human entry is involved and use well-designed user interfaces)
- Develop and adhere to guidelines for documenting the care that was provided to the patient
- Review automated billing software
- Build human capacity, including training, awareness building, and organizational change
In addition to these specific recommendations, the group urges the development of a “data quality culture” within health care organizations.
Arts, DeKeizer, and Scheffer(2002) have published a useful framework for ensuring data quality in a centralized health care database (or medical registry, as these authors call it). Although the entire framework is not reproduced here, several key aspects are outlined in Figure 2.2. This framework illustrates that there are multiple reasons for data errors and multiple approaches to preventing and correcting these errors.

Figure 2.2. Activities for improving data quality
Source: Adapted from Arts, DeKeizer, & Scheffer, 2002, p. 605.
Using IT to Improve Data Quality
Information technology has tremendous potential as a tool for improving health care data quality. To date some of this potential has been realized, but many opportunities remain that are not commonly employed by health care organizations. Clearly, electronic health records (EHRs) improve legibility and accessibility of health care data and information. But what about the remaining dimensions of health care data quality? As noted in the Perspective that follows, a recent GAO report (2007) found that many of the data in existing EHR systems were recorded in an unstructured format—“in narrative form or other text, rather than in data fields designated to contain specific pieces of information.” Physician notes and discharge summaries are often dictated and transcribed. This lack of structure limits the ability of an EHR to be a data quality improvement tool. In systems requiring structured data input, data comprehensiveness, relevance, and consistency can be improved. When health care providers respond to a series of prompts, rather than dictating a free-form narrative, they are reminded to include all necessary elements of a health record entry. Data precision and accuracy are improved when these systems also incorporate error checking. A clear example of data improvement achieved through information technology is the result seen from incorporating medication administration systems designed to prevent medication error (see Chapter Five). With structured data input and sophisticated error prevention, these systems can significantly reduce medication errors.
SUMMARY
Without health care data and information, there would be no need for health care information systems. Health care information is a valuable asset in health care organizations and it must be managed like other assets. To manage information effectively, health care executives should have an understanding of health care data and information and recognize the importance of ensuring data quality. Health care decisions, both clinical and administrative, are driven by data and information. Data and information are used to provide patient care and to monitor facility performance. It is critical that the data and information be of high quality. After all, the most sophisticated of information systems cannot overcome the inherent problems associated with poor-quality source data and data collection or entry errors. The data characteristics and frameworks presented here can be useful tools in the establishment of mechanisms for ensuring the quality of health care data.
The challenge of health care organizations today is to implement information technology solutions that work to improve the quality of their health care data.
KEY TERMS
- Data
- Data accessibility
- Data accuracy
- Data comprehensiveness
- Data consistency
- Data currency
- Data definition
- Data errors
- Documentation
- Government Accountability Office (GAO)
- Information
- Information capture
- Knowledge
- Random errors
- Report generation
- Systematic errors
- Unique patient identifier
LEARNING ACTIVITIES
- Contact a health care facility (hospital, nursing home, physicians’ office, or other facility) to ask permission to view a sample of the health records they maintain. These records may be in paper or electronic form. For each record, answer the following questions about data quality:
- How would you assess the quality of the data in the patient’s record? Use the MRI’s key principles and AHIMA’s data characteristics as guides.
- What proportion of the data in the patient’s medical record is captured electronically? What information is recorded manually? Do you think the method of capture affects the quality of the information?
- How does the data quality compare with what you expected?
- Visit a health care organization to explore the ways in which the facility monitors or evaluates data quality.
- Consider the following scenarios and the questions they raise about data quality. What should an organization do? How does one create an environment that promotes data quality? What are some of the problems associated with having poor-quality data?
- late entry is written to supply information that was omitted at the time of the original entry. It should be done only if the person completing it has total recall of the omission. For example, a nurse completed her charting on December 12 and forgot to note that the physician had talked with the patient. When she returned to work on December 13, she wrote a late entry for the day before and documented the physician visit. The clinician must enter the current date and the documentation must be identified as a late entry including the date of the omission. Additionally, a late entry should be added as soon as possible.
- late entry cannot be used to supplement a record because of a negative clinical outcome that occurs after the original entry. For example, while a patient received an antibiotic for two days, the nurse charted nothing unusual. Yet, on the third day, the patient had an acute episode of shortness of breath and chest pain and died later that same day. At the time of death, documentation revealed that the patient had a dark red rash on his chest.
- An investigation into the cause of death was conducted and all the nurses who provided care during the three days were interviewed and asked whether they had seen the rash prior to the patient’s death. None of the nurses remembered the rash. However, one nurse wrote a late entry for each of the first two days that the patient was receiving the antibiotic stating that there was no rash on those days. This is an incorrect late entry. Her statement is part of the investigation conducted after the fact and was not an omission from her original entry [Schott, 2003, pp. 23–24].
REFERENCES
American Health Information Management Association. (2012). Data quality management mode (updated). Journal of AHIM, 83(7), 62–67. Retrieved August 2012 from library.ahima.org
Arts, D., DeKeizer, N., & Scheffer, G. (2002). Defining and improving data quality in medical registries: A literature review, case study, and generic framework. Journal of the American Medical Informatics Association, 9(6), 600–611.
Government Accountability Office. (2007, April). Hospital data quality: HHS should specify steps and time frame for using information technology to collect and submit data (GOA-07–320). Retrieved July 2008 from www.gao.gov/cgi-bin/getrpt?GAO-07–320
Johns, M. (1997). Information management for health professionals. Albany, NY: Delmar.
Lee, F. W. (2002). Data and information management. In K. LaTour & S. Eichenwald (Eds.), Health information management concepts, principles, and practice (pp. 83–100). Chicago: American Health Information Management Association.
Markle Foundation. (2006). T5 background issues on data quality. Connecting for Health Common Framework. Retrieved March 2012 from www.policyarchive.org/handle/10207/bitstreams/15515.pdf
Medical Records Institute. (2004). Healthcare documentation: A report on information capture and report generation. Boston: Author.
Schott, S. (2003, April). How poor documentation does damage in the courtroom. Journal of AHIMA, 74(4), 20–24.
Shakir, A. (1999). Tools for defining data. Journal of AHIMA, 70(8), 48–53.