During the 1840s, more than 1.7 million immigrants arrived in the United States—almost three times as many as had come in the preceding decade. Many headed to farmland in the upper Midwest, traveling mostly on rutted roads to their homesteads. State governments had little money to build and maintain roads; there had been an economic crash in the 1830s. Then in 1844, word spread that someone in Toronto had invented a new technology, a better, cheaper way to build roads. Roads surfaced with wooden planks—widely available in the densely forested upper Midwest—cost a third as much as gravel roads. According to the hype, plank roads would provide a much smoother ride, so loads could be twice as heavy and travel time could be cut in half. Maintenance would be minimal; the planks would last for eight to ten years. Return on investment was projected to be 20% per year. And best of all, plank roads would be good for society. Neighbors could visit each other and families could make it to church even in bad weather.
For the next several years, there was a massive boom in plank road construction. Completion of a road was accompanied by great civic fanfare. Travel was fast and the plank roads quickly became popular. Success stories fueled intense interest across the Midwest. New companies formed, shares were sold to thousands of local investors, and in a few short years, 10,000 miles of plank roads were built. And for a few short years, everyone was pleased with the roads.
But it didn’t take long for the planks to rot—perhaps three or four years. Rotted planks tripped horses and toppled carriages. But the tolls had yet to generate enough revenue to pay for repairs, so deteriorating plank roads were neglected and became more and more dangerous. People started evading tolls on degenerated roads, and income plummeted. By 1853 plank road construction had stopped and companies began abandoning their roads in droves. State governments took over the legacy road system and switched to dirt and gravel for repairs.
“Plank Road Fever is a good example of an information cascade,”3 James Surowiecki wrote in The Wisdom of Crowds. “The first plank roads were a huge success. People looking for a solution to the road problem found one ready-made at hand. As more people built plank roads, their legitimacy became more entrenched and the desire to consider alternate solutions shrank. It was years before the fundamental weakness of plank roads—they didn’t last long enough—became obvious.”
Over the years we have seen our share of plank roads in software development. There’s the good idea, the hype, the initial successes, the bandwagon, and, after a few years, the rotting planks. Given this history, we expect there may be some contemporary plank roads; so how do we recognize them? To answer this question, we decided to study software history and look for patterns in the way key issues were framed, so that we could see which frames turned into fads. We didn’t have far to go; our bookshelves are overflowing with software books dating back into the 1960s. To get started, we pulled out eight books with structured in the title. We don’t hear much about structured programming anymore. Could it be that “structure” was an early software plank road?
Arguably, structured programming had its beginnings at the 1968 NATO Conference on Software Engineering in Garmisch, Germany, where some of the greatest minds in software development came together to discuss “the software crisis.” Why was it so difficult to create reliable large software systems? Edsger W. Dijkstra, a professor from Technological University in Eindhoven, the Netherlands, presented a paper titled “Complexity Controlled by Hierarchical Ordering of Function and Variability.4” In this paper he proposed that complex systems should be constructed as a sequence of levels of abstraction, or a hierarchy of layers, where each layer acts as a virtual machine for the layer above.
At about the same time as the conference, Dijkstra published “A Constructive Approach to the Problem of Program Correctness,”5 perhaps his most misunderstood contribution to software development. In 1975, Peter Freeman summarized this concept:6
The second procedural suggestion of Dijkstra is more subtle and seems to have been missed by many of those attempting to follow his suggestions.... Dijkstra suggests the following procedure for constructing correct programs: analyze how a proof can be given that a class of computations obeys certain requirements— that is, explicitly state the conditions which must hold if we are to prove that an algorithm performs correctly; then write a program that makes the conditions come true.
Thus structured programming is a way of thinking that leads to constructive programming; it is not an exact process that can be precisely specified... to develop a more explicit definition of structured programming may be detrimental; we have no desire to impede the process of discovering structures and techniques to help us program constructively.
Today hierarchical layers very similar to those described by Dijkstra lie at the core of many of our systems, from Internet protocols to multitiered architectures. But Freeman was correct; hierarchical layers are not the only way to program constructively. Dijkstra’s constructionist approach was a precursor of today’s test-driven development, in which one starts by describing or writing examples of what the code must do in order to perform correctly (also known as tests), then writes the code that causes each example to behave as expected.
Dijkstra summed up his philosophy this way: “Those who want really reliable software will discover that they must find means of avoiding the majority of bugs to start with, and as a result the programming process will become cheaper. If you want more effective programmers, you will discover that they should not waste their time debugging—they should not introduce bugs to start with.”7 This is the holy grail of software development, and so the goal of structured development was enthusiastically embraced. But techniques for constructing error-free code were often flawed, as we shall see later.
Harlan Mills, a fellow at IBM, read Dijkstra’s work with keen interest and deep understanding.8 He experimented with ways to build programs “from the point of view of provability” as Dijkstra suggested. Mills discovered that in order to always know that a program is correct, the statements have to be developed in a particular order; a statement should not depend on future statements for its correctness. This means that programmers should take a recursive approach: Start with a statement that works, add a new statement and make sure that they both work, then add another and be sure all three work, and so on. He generalized this idea: If it held for statements, it should also hold for programs. So, for example, code to open files should be written before code to access the files. In particular, the job control code for a system should be written first and then programs added incrementally, exactly the opposite of practice at the time. Mills tested this idea on a major project for the New York Times; he started with a working skeleton of a system and added modules one at a time, checking after each addition that the overall system still worked. The results were widely reported—the project had impressive quality and productivity, with almost no defects discovered during integration, acceptance testing, and the first year of operation.9
Mills realized that trying to resolve discrepancies discovered during integration was an unsolvable problem, so he recommended that Top Down Programming-modules should be integrated into a system as they are written, rather than at the end. His approach might be called “stepwise integration,” a precursor of today’s continuous integration. Mills noted that those who used this technique experienced a dramatic improvement in the integration process. “There was simply no integration crunch at the end of software development.”10
But to most people at the time, “top down programming” was a catchphrase that lent itself to many interpretations, few related to the stepwise integration that Mills had in mind. He wrote, “I am happy that people are using the term. I will be even happier when they begin using the idea.” Mills said he could tell whether or not people were using his idea: “My principal criterion for judging whether top down programming was actually used is [the] absence of any difficulty at integration. The proof of the pudding is in the eating!”11
From 1970 until 1980, everything had to be structured. It was as if structured programming and its derivatives were the answer to every problem that existed in software development. In 1982 Gerald Weinberg complained that structured programming could be used interchangeably with our latest computer in statements like this:12
If you are having problems in data processing, you can solve them by installing our latest computer. Our latest computer is more cost effective and easier to use. Your people will love our latest computer, although you won’t need so many people once our latest computer has been installed. Conversion? No problem! With our latest computer, you’ll start to realize savings in a few weeks, at most.
And as we have seen, there was a very good reason why structured programming was popular: It was framed by core technical concepts that have withstood the test of time, concepts such as hierarchical layers and stepwise integration. Constructive programming followed a more torturous path. Various methods for constructing proofs of correctness were devised, including Hoare logic and Bertrand Meyer’s Design by Contract. But these proved to be too difficult to be widely adopted. It wasn’t until xUnit frameworks became available in the late 1990s that a practical approach to constructive programming evolved.
The theories of Dijkstra and Mills—build code from the point of view of provability and avoid big-bang integration—were difficult to apply in practice, especially with the computers and tools that were available at the time. Without a good implementation of these core technical fundamentals, structured programming lost some of its potential, and it never quite lived up to the hype that made it so popular in the first place.
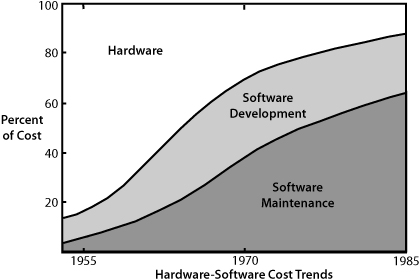
While Dijkstra and Mills framed the software problem as establishing confidence that code is correct, David Parnas created a new frame to address the emerging and potentially bigger problem: software maintenance. As we see in Figure 2-1, maintenance costs were half of all computer costs by 1970 and growing rapidly.
Figure 2-1 The growing impact of maintenance (From Boehm, “Software Engineering,” 1976, pp. 1226–41. Used with permission.)
Both Dijkstra and Parnas understood that the basic problems with software were its complexity and the inability of a human mind to understand in detail the complexities of a large system. But while Dijkstra counted on a hierarchy of abstractions to organize the complexity into understandable layers, Parnas realized that this was not the only solution to the complexity problem. He agreed with Dijkstra’s “divide and conquer” mantra, but he proposed a new criterion for decomposing systems into modules that would render the software easier to maintain. He called this principle information hiding.13
Parnas noted that the most common criterion used for system decomposition was the flow of the program, but this approach resulted in modules with complex interfaces. Worse, typical changes in things such as input format or storage location would require a change in every module. He proposed that instead, the criteria for decomposition should be such that each module has knowledge of (and responsibility for) a single design decision that it hides from all other modules. In addition, interfaces should be chosen to reveal as little as possible about the inner workings of the module. Later writers rephrased these criteria: Modules should have high cohesiveness within themselves and loose coupling between each other.
In the 1960s, Ole-Johan Dahl and Kristen Nygaard developed the programming language Simula at the Norwegian Computer Center in Oslo. Simula, the first object-oriented language, was specifically designed for doing simulations. It introduced many now-familiar concepts such as objects, classes, subclasses, inheritance, and dynamic object creation. In 1972, Dahl, Dijkstra, and Hoare published a book called Structured Programming.14 At the time, structured programming was considered to include the concepts of object orientation, but over time the term structured became limited to hierarchical structures, and object-orientated programming was left out of most writing on structured development.
Smalltalk, created at Xerox PARC and modeled on Simula, was a popular general-purpose object-oriented programming language in the 1980s. Despite its enthusiastic following, Smalltalk was not widely supported and was supplanted, first by C++ and then by Java in the late 1990s.
In 1994, more than 20 years after his first article on information hiding, Parnas wrote, “The first step in controlling software aging is applying the old slogan, ‘design for change.’ Since the early 70’s we have known how to design software for change. The principle to be applied is known by various names, e.g. ‘information hiding,’ ‘abstraction,’ ‘separation of concerns,’ ‘data hiding,’ or most recently, ‘object orientation.’”15
Over those two decades, IT departments had discovered that the cost of maintenance and integration increasingly dominated all other costs. When they discovered that hierarchical structure did not necessarily produce maintainable code, they turned to object-oriented development. Because the basis for modularization and factoring is the likelihood of future change, in theory at least, object-oriented software is designed from the start in a way that should be easy to maintain.
But many developers found object-oriented thinking difficult, and it took time to learn to produce well-factored object-oriented code. Moreover, good patterns for programming with objects had to be developed, disseminated, and used effectively. Thus while in theory object-oriented development produces code that is easy to change, in practice, object-oriented systems can be as difficult to change as any other, especially when information hiding is not deeply understood and effectively used.
It’s interesting to contemplate that in 1970, most systems were written in assembly language, aided by macros for common control structures. It’s not that high-level languages didn’t exist. In the mid-1950s, Grace Hooper developed FLOW-MATIC, a precursor of COBOL, and John Backus led the development of FORTRAN. However, at that time computers were highly constrained in memory, storage, and processing power, so assembly language was considered necessary to optimize hardware usage. In fact, on Barry Boehm’s first day as a programmer in 1955, his supervisor said to him: “Now listen. We’re paying this computer six hundred dollars an hour, and we’re paying you two dollars an hour, and I want you to act accordingly.”16 With that kind of economics, assembly language made a lot of sense.
But as computers grew bigger, faster, and cheaper, the cost of software first equaled and then began to rapidly outstrip the cost of the hardware (see Figure 2-1). The objective shifted from optimizing hardware to optimizing people, and high-level languages came into widespread use. Most people expected that this would lead to productivity and quality improvements in software even as they enabled people with less technical experience to program computers. And at first, that’s more or less what happened.
Dijkstra summarized the impact of high-level languages thus: “COBOL was designed with the avowed intention that it should make programming by professional programmers superfluous by allowing the ‘user’... to write down what he wanted in ‘plain English’ that everyone could read and understand. We all know that that splendid dream did not come true.... COBOL, instead of doing away with professional programmers, became the major programming vehicle for ever growing numbers of them.”17 He explained that high-level languages removed drudgery from programming, which made the job more complex and required higher-caliber people who “still produced, as willingly as before, large chunks of un-understandable code, the only difference being that now they did it on a more grandiose scale, and high-level bugs had replaced low-level ones.”
Later, even higher-level languages such as SQL, MAPPER, and PowerBuilder came into fashion, and you only have to replace COBOL in Dijkstra’s statement with these names to figure out how they fared. Like plank roads, most high-level languages produced immediate, impressive improvements at a low cost. But it didn’t take long for the shine to wear off. While it was relatively easy to create initial applications, there was often little appreciation of how to design maintainable applications. In a short time—much shorter than anticipated—the initial software started to age, and maintenance was much more expensive than anticipated. Unlike plank roads, high-level languages provided lasting benefits, but the longest-term benefits came only when solid technical approaches to managing complexity were used at the same time.
At the beginning of the 1970s, programming and software development were thought of as one and the same thing. But by the end of the decade, programming had become just one step in a larger process called the software life cycle. This happened at the same time that the cost of computing was undergoing a seismic shift, as we saw in the graph in Figure 2-1. With the relative cost of software to hardware growing rapidly and the cost of software maintenance dominating that growth, the search was on for a way to control these costs.
In the mid-1970s, Michael Fagan of IBM published “Design and Code Inspections to Reduce Errors in Program Development.”18 He reported that over half of the time spent on a program was wasted in non-value-adding layers of testing and claimed that rework in the first half of development is 10 to 100 times less expensive than rework done in the second half. Like Dijkstra and Mills, Fagan felt that the solution was to find and fix errors as early as possible. However, Fagan’s approach was different. He framed development as three processes: design, coding, and testing, each process with an input and an output. At the end of each process, he added a formal inspection step to be sure that the output met predefined exit criteria. Fagan’s work helped to establish the frame of thinking that casts software development as a series of sequential input-process-output steps, with formal validation at the end of each step.
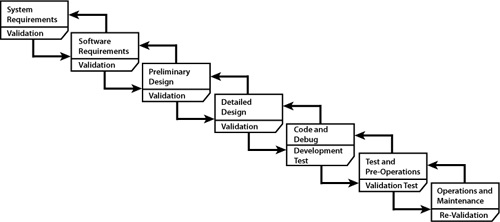
Barry Boehm extended Fagan’s approach by emphasizing four more processes. In his 1976 “Software Engineering” article19 he drew a classic waterfall picture, as seen in Figure 2-2.20 Boehm called this series of processes the “software life cycle.” He cited Fagan’s work and his own studies to show that the biggest opportunity for cost reduction was finding errors as soon as possible, by inserting a formal inspection at the end of each process.
The problem with the life cycle concept is not the idea that it is good to find defects early; it certainly is! The problem is twofold. First, large batches of work tend to queue up during each process step, and so defects are not detected at the point of insertion; they have to wait to be uncovered in a batch validation step. Dijkstra’s idea was to code the program in such a way that at every step of program construction, one had confidence in the program’s correctness. Dijkstra’s approach to thinking about eliminating defects in software development was exactly the opposite of the life cycle process: State a condition that must hold if you are to prove that code performs correctly, and then write code that makes the condition come true.
The second problem with the life cycle concept is the separation of design from implementation. Dijkstra said, “Honestly, I cannot see how these activities [design and programming] allow a rigid separation if we are going to do a decent job.... I am convinced that the quality of the product can never be established afterwards. Whether the correctness of a piece of software can be guaranteed or not depends greatly on the structure of the thing made. This means that the ability to convince users, or yourself, that the product is good, is closely intertwined with the design process itself.”21
Figure 2-2 Boehm’s original version of the software life cycle (From Boehm, “Software Engineering,” 1976. Used with permission.)
Dijkstra was not the only one who felt you cannot separate design from implementation. In 1982 William Swartout and Robert Balzer, who once thought sequential development was a good idea, wrote in “On the Inevitable Intertwining of Specification and Implementation”:22
For several years we and others have been carefully pointing out how important it is to separate specification from implementation. In this view, one first completely specifies a system in a formal language at a high level of abstraction in an implementation-free manner. Then, as a separate phase, the implementation issues are considered and a program realizing the specification is produced....
All current software methodologies have adopted a common model that separates specification from implementation. Unfortunately, this model is overly naive, and does not match reality. Specification and implementation are, in fact, intimately intertwined.
It didn’t take long for a serious outcry against the life cycle concept to be heard. It came from no less than Dan McCracken, author of computer language textbooks and former president of ACM, and Michael Jackson, inventor of a system development method framed around objects. In 1982 they published the note “Life Cycle Concept Considered Harmful” in ACM SIGSOFT. They said:23
1. Any form of life cycle is a project management structure imposed on system development. To contend that a life cycle scheme, even with variations, can be applied to all system development is either to fly in the face of reality or to assume a life cycle so rudimentary as to be vacuous.
The elaborate life cycle [similar to Boehm’s] may have seemed to be the only possible approach in the past when managing huge projects with inadequate development tools. (That it seemed to be the only choice, obviously did not prevent many such projects from failing.)...
2. The life cycle concept perpetuates our failure so far, as an industry, to build an effective bridge across the communication gap between end-user and systems analyst. In many ways it constrains future thinking to fit the mold created in response to failures of the past. It ignores such factors as...
-- An increasing awareness that systems requirements cannot ever be stated fully in advance, not even in principle, because the user doesn’t know them in advance—not even in principle. To assert otherwise is to ignore the fact that the development process itself changes the user’s perceptions of what is possible, increases his or her insights into the applications environment, and indeed often changes that environment itself. We suggest an analogy with the Heisenberg Uncertainty Principle: any system development activity inevitably changes the environment out of which the need for the system arose. System development methodology must take into account that the user, and his or her needs and environment, change during the process.
3. The life cycle concept rigidifies thinking, and thus serves as poorly as possible the demand that systems be responsive to change. We all know that systems and their requirements inevitably change over time. In the past, severely limited by inadequate design and implementation tools as we were, there was little choice but to freeze designs much earlier than desirable and deal with changes only reluctantly and in large packets.... To impose the [life cycle] concept on emerging methods in which much greater responsiveness to change is possible, seems to us to be sadly shortsighted.
In 1981, Tom Gilb published the article “Evolutionary Development.”24 He noted that there was a tremendous thirst for a theory of how to plan and develop evolutionary systems, but there was very little literature on the subject except that coming from Harlan Mills in IBM’s Federal Systems Division. Gilb proposed that instead of developing detailed requirements, one should start with a short summary of the measurable business goals of the system (he called this Design by Objectives)25 and proceed with incremental deliveries. He pointed out that incremental deliveries are not prototypes, but real software delivering real value to real people.
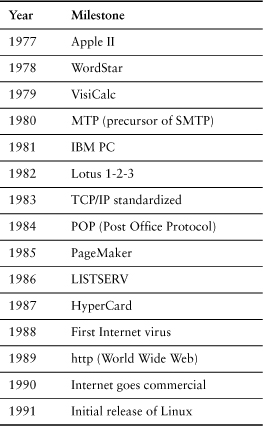
As Gilb noted, during the 1980s most of the computing literature was focused on languages and life cycles, while some of the most interesting advancements in software development were taking place almost unnoticed by corporate IT departments—in the world of ARPANET, Internet, and personal computers (see Table 2-1).
Table 2-1 Some Milestones in the Evolution of Internet and PC Software
During the 1980s useful PC software exploded, fueled by newly available low-cost PCs and a favorable climate for entrepreneurship. Start-up companies found ways to maintain and upgrade software packages on a regular basis to generate more revenue. Since software packages were largely independent of each other, PC owners could pick and choose from a wide array of programs that could live in the same computer, mostly without destroying each other. A wildly successful domain-specific language—the spreadsheet—was the killer application that brought PCs into many companies.
At the same time, Internet development was being driven by noncommercial forces; for two decades, government and academic bodies had joined forces to develop ARPANET as an academic and military communication platform. Only after commercial use was allowed in 1990 did commercial forces take over, and by then e-mail had been invented and ARPANET’s low-dependency architecture had proven to be extremely robust.
“The Internet? That’s not software!” we often heard in the late 1990s. Like any disruptive technology, the Internet was widely ignored by mainstream software development for a long time, because it broke prevailing paradigms about software. As Ward Cunningham, inventor of the Wiki, said, “The Internet really favors text. It doesn’t want to send objects around, it wants to send text.”26 How could moving around pages of text be software?
Spreadsheets and e-mail were not considered software either, and open-source software was widely ignored for years. But while fourth-generation languages had largely failed in “making programming by professional programmers superfluous,” the Internet, personal computing, and, in the 1990s, open-source software succeeded in turning a vast amount of programming over to users.
These are classic examples of disruptive technologies—technologies that do not solve prevailing problems but instead find an unmet need in a low-end niche where the existing technology is too expensive or cumbersome to be considered. After establishing a foothold in the low-end niche, disruptive technologies grow stronger and more powerful and eventually become capable of doing the job of the established technology, but at a lower cost, size, power consumption, complexity, or something like that. It is the nature of disruptive technologies to evolve over time; thus the Internet, PC software, and open-source software are all case studies in successful evolutionary development.
What made it possible for PCs, the Internet, and open-source software to create an explosion of successful software almost under the radar of the mainstream software development?
Internet
1. Technical vision: Perhaps no one was more visionary than J. C. R. Licklider, who saw the computer as a way for people to communicate more effectively. He conceived of, found funding for, and managed the early development of ARPANET. And there were many other visionaries who worked alongside Licklider or followed in his footsteps.
2. Robustness: ARPANET’s design goal was to provide reliable communication between computers of different types, even if any part of the network failed. The novel solution to this problem was to launch a packet of data from one computer and let it find its own way to another computer based on the packet address, without any administration or control.
3. Emergent standards: E-mail originated as a communication mechanism between administrators of various computers on ARPANET. As new administrators with different types of computers joined the network, the mail protocol was modified to accommodate the newcomers. Over the years, the essential elements of e-mail headers emerged.
PCs
1. Minimized dependencies: Early PC software consisted of focused applications that had no dependencies on other applications, so programs had to coexist without doing harm to each other. The expectation rapidly developed that one should be able to add a new program to a PC without experiencing any unintended consequences.
2. Staged deployment: PCs were comparatively inexpensive, and the first vendors of PC programs were entrepreneurs with limited funds; therefore, early programs were rudimentary and aimed at generating revenue and getting feedback from the market. If software packages were successful, a new release followed in perhaps a year. Over time the expectation developed that useful software would have regular new releases.
3. Experimentation: The early PC software market was a vast experiment; for example, Intuit’s popular Quicken software was the forty-seventh financial package to be released for PCs when it came to market in 1984. A decade later, the Internet experienced the same high level of commercial experimentation. James Surowiecki explains that all emerging markets act this way; he wrote, “No system seems to be all that good at picking winners in advance.... What makes the system successful is its ability to generate lots of losers and then to recognize them as such and kill them off.”27
Open Source
1. Personal investment: People who write open-source software write it to solve a problem they are experiencing, as well as to contribute to the community. Developers understand their problem well and are personally invested in the integrity of their solution because they will use it. In addition, their work will be open for public scrutiny.
2. Common purpose: Open-source contributors care about their work because they are mutually committed to achieving a common purpose. They collaborate constantly, on a global basis, through simple text messaging tools, simple rules, and the code base itself.
Today, each of these eight factors remains core to the creation of valuable software-intensive systems.
By the mid-1990s PC software had grown up, the Internet was bursting with possibilities, and open-source software was beginning to be useful. But back in the corporate IT departments of the world, a serious threat started draining off vast amounts of attention and money; it was called Y2K. There was great fear that all of the software upon which the world had come to depend would fall apart as the date changed from 1999 to 2000. So instead of looking into emerging technologies, IT departments, especially in large companies, focused intense efforts on checking out the plumbing of existing applications, or replacing key software before the turn of the century. By the time Y2K was past and those same IT departments had time to come up for air, the world of software development had forever changed.
As we look at the history of software development, we see a consistent goal: Avoid the high cost of discovering defects late in the development process by discovering them as early in the development process as possible. However, we see a big difference of opinion on how to go about achieving this goal. On the one hand we have people like Dijkstra and Mills, who framed establishing correctness as an ongoing activity of system development. On the other hand, we have the life cycle concept, which framed establishing correctness as a project management activity. We recall what Daniel McCracken and Michael Jackson said in 1982: “Any form of life cycle is a project management structure imposed on system development.” Historically, we have seen that these two were often confused (see Table 2-2).
Table 2-2 A Lesson from History

The history of software system development gives us technical concepts such as hierarchical layers, early integration (the precursor of continuous integration), information hiding (the precursor of object-oriented programming), and even constructive programming (the precursor of test-driven development) that are considered essential today. We see that simple, low-dependency architectures and skilled technical implementation are the never-changing ingredients of successful software development. We discover that solid technical leadership and incremental deliveries that provide feedback are essential. These technically focused practices for developing good software have never become less critical—although they may have occasionally been forgotten. When they are rediscovered, they prove just as effective as ever, and sometimes even more so with modern tools. The technical concepts have been robust over time.
On the other hand, when we look at the history of project management in software development, we find practices that have proven to be fragile over time. Ensuring that requirements are correct before proceeding ends up creating big batches of untested code. Phased systems that separate design from implementation don’t work because they do not allow for feedback. When system development time is longer than the likelihood of change in the environment, or the system itself will change that environment, phased systems don’t work. Waiting for testing at the end of phases violates the mandate that quality be built into the software in the first place. Maturity levels have not necessarily proven to be an indication of technical capability.
So where does agile software development fit into this picture? We suspect that the aspects of agile software development that reside in the project management frame are likely to change over time and are therefore a matter of choice. On the other hand, agile development has extended many practices from the system development frame. These technical practices have withstood the test of time and they will continue to be highly effective long into the future. So if you are using agile software development—or even if you are not—start with the system development frame. It is fundamental; it is not a fad.
The complexity of software is an essential property, not an accidental one.... The classic problems of developing software products derive from this essential complexity and its nonlinear increase with size.
—Fred Brooks28
The history of software development is a history of attempts to conquer its complexity. But in his landmark paper “No Silver Bullet,” Fred Brooks claimed that no silver bullet will ever exist that can put an end to “the software crisis,” because software is inherently complex. He wrote:29
Einstein repeatedly argued that there must be simplified explanations of nature, because God is not capricious or arbitrary. No such faith comforts the software engineer. Much of the complexity he must master is arbitrary and complex, forced without rhyme or reason by the many human institutions and systems to which his interfaces must conform. These differ from interface to interface, and from time to time, not because of necessity but only because they were designed by different people, rather than by God.
There wasn’t much argument, historically, about how to deal with software’s inherent complexity; everyone agreed that the answer was to divide and conquer. The real question was “Along what lines should we divide software so as to conquer its complexity?”
Edsger Dijkstra believed that the best way to control complexity was by creating hierarchical ordering, creating layers that treated the next-lower layer as a virtual machine. We might call this Divide by Structure. Dave Parnas suggested that such a division might work to begin with but was not the right division criterion for maintaining software, so he advocated Divide by Responsibility. In the end, division by responsibility has proven to be the most valuable technique for designing maintainable code, although there certainly are many cases where layered architectures are used as the essential simplifying technique.
Barry Boehm recommended that we Divide by Process, with verification steps after each process. However, this approach has not effectively dealt with the internal complexity of software. Tom Gilb recommended that we Divide by Value instead, an approach that has withstood the test of time.
The strategy of divide and conquer is fundamental, but in practice, determining the best axes of division is not so simple. It is essential to devise an architecture that will effectively deal with the complexity in the context of the domain, and not all domains are alike. Thus the starting point for conquering complexity over the long term is an architecture that appropriately fits the domain. Consider, for example, the architecture of the Internet.
On January 1, 1983, the 12-year-old ARPANET architecture was declared obsolete; any of the 200 sites that wanted to stay on the network had to switch to the new TCP/IP protocol. The initial ARPANET architecture depended on interface message processors (IMPs)—by then aging computers—and a network control protocol (NCP) that was being strained to its limits. To overcome limitations of the original protocol, TCP/IP was aimed at creating a network of networks—thus the name “Internet.” The new protocol had four main design goals:30
• Network connectivity: Each distinct network had to stand on its own, and no internal changes could be required of any such network before being connected to the Internet.
• Error recovery: Communications would be on a best-effort basis. If a packet didn’t make it to the final destination, it would quickly be retransmitted from the source.
• Black box design: Black boxes (later called gateways and routers) would be used to connect the networks. No information would be retained by the gateways about individual flows of packets passing through them, keeping them simple and avoiding complicated adaptation and recovery from various failure modes.
• Distribution: There would be no global control at the operations level.
These design goals were brilliant in their breadth and simplicity; fundamentally, the underlying architecture of the Internet is expressed in these four design goals. At first the designers—Robert Kahn and Vinton Cerf—thought of TCP/ IP as a prototype that would eventually be reengineered. But once it was developed and deployed, “it just continued to spread without stopping.”31 And the rest, as they say, is history.
As the software industry has grown, it has become apparent that the vast majority of the money spent on software is for maintenance—that is, making changes to existing systems. The logical conclusion to draw from this is that good software architecture32 must support change over time. This means, as Dave Parnas first observed in 1972, that a good architecture has a partitioning scheme that puts things that are likely to change together into the same subsystem (high cohesiveness) and insulates subsystems from changes in other subsystems (loose coupling). Over time it has become abundantly clear that change is easiest and least expensive when these rules are followed; a good architecture is necessarily low-dependency.
There is no substitute for low-dependency architecture; no amount of planning or foresight can take its place. Minimizing (or breaking) dependencies should be a top technical priority, especially in organizations that wish to use agile software development. We have often found companies trying to employ agile practices to maintain a monolithic code base with massive interdependencies, but we have rarely seen this work well. Why? In agile development, change is encouraged rather than avoided. But with a tightly coupled architecture, change is both risky and expensive. Thus, attempting agile development in a large system with a tightly coupled architecture creates a dissonance that cannot be easily reconciled.
The classic rationale for a tightly coupled architecture has been efficiency: Fewer interfaces should mean fewer instructions to execute and less jumping around in the code. David Parnas noted in his 1972 paper that information hiding would demand a lot more processing power as the program flow transferred frequently between modules.33 But when you compare the skyrocketing cost of maintenance with the relentless increase in processing power and its decrease in price, the rationale for tightly coupled architectures makes little sense. These days there is rarely an excuse to sacrifice ease of change for execution speed, with the exception of some embedded or network-intensive software.
If you are struggling with a tightly coupled architecture, take a leaf out of the Internet playbook and work to pay off this technical debt.34 However, do not spend large amounts of time defining a new architecture in great detail; after all, the underlying architecture of the Internet can be expressed in four well thought-out rules. If you spend a lot of time developing an architectural framework, the world will pass you by long before it’s implemented. Settle on a solid, low-dependency technical vision and evolve in that direction.
“Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations,” Mel Conway wrote in 1968.36 He went on to say that the architecture that first occurs to designers is almost never the best possible design, so companies should be prepared to change both their product architecture and their organizational structure.
One of the reasons why high-dependency architectures seem so intractable is that they usually reflect the organization’s structure, and changing the organizational structure is often not considered an option. But it should be. We regularly find companies struggling to implement agile practices with functional teams, that is, teams organized along technology lines. For example, there might be a database team, a mainframe team, a Web server team, even a testing team. Invariably these technology (or functional) teams find that they are dependent on the work of several other teams, so delivering even a small feature set requires a large amount of communication and coordination. The complexity of the communication adds time and increases the likelihood of error, and the added overhead cost makes small incremental releases impractical.37
It is difficult for agile development to flourish in a highly interdependent environment, because teams cannot independently make and meet commitments. Agile development works best with cross-functional teams in which a single team or small group of teams has the skill and authority necessary to deliver useful feature sets to customers independent of other teams. This means that whenever possible, teams should be formed along the lines of features or services. Of course, this is most useful if those features or services are relatively small and have clean interfaces. Conway’s Law is difficult to escape.
Another big mistake we see in organizational structures is the separation of software development from the larger system supported by the software. For example, when hardware and software are involved, we often find separate hardware and software (and sometimes firmware) teams. This is similar to forming teams along technology layer lines. Conway’s Law says that it might be better to organize teams (or groups of teams) that are responsible for both the hardware and the software of a subsystem of the product.
Consider, for example, a digital camera with a picture-capture subsystem to set exposure, capture, and process pictures; a storage subsystem to store and retrieve pictures to a memory card; an electronic interface subsystem to transfer pictures to a computer; and possibly a smart lens subsystem. Each subsystem is software-intensive, but the camera should not be divided into a hardware subsystem and a software subsystem. Why? Suppose there were a change to the camera’s focusing system. With subsystem teams, only the picture-capture team would be involved in the change. With hardware and software teams, both teams would be involved and the change would not be obviously limited to a few people. When changes can be limited to a smaller subsystem, the cost and risk of change are significantly reduced.
Similarly, when business processes are being changed, it is often best to place software developers on the business process redesign team, rather than have separate software development teams. This is not to imply that the software developers would no longer have a technical home with technical colleagues and management. As we will see later, maintaining technical competencies and good technical leadership is essential. The organizational challenge is to provide people with a technical base even as they work on cross-functional teams. We will take up this challenge again at the end of the chapter.
If you want more effective programmers, you will discover that they should not waste their time debugging—they should not introduce bugs to start with.38
—Edsger W. Dijkstra
Virtually all software development methodologies share the same objective: Lower the cost of correcting mistakes by discovering them as soon as they are made and correcting them immediately. However, as we demonstrated earlier, various methodologies differ dramatically in the way they frame this goal. The sequential life cycle approach is to create a complete, detailed design so as to find defects by inspection before any coding happens—because fixing design defects before coding is supposedly less expensive than fixing design defects later on. This theory has a fundamental problem: It separates design from implementation. A careful reading of the 1968 NATO conference minutes shows that separating design from implementation was regarded as a bad idea even as the term software engineering was coined.39
But it gets worse. Sequential development leaves testing until the end of the development process—exactly the wrong time to find defects. There is no question that finding and fixing defects late in the development cycle is very expensive; this is a premise of sequential development in the first place. And yet, sequential approaches have brought about exactly the result they are trying to prevent: They delay testing until long after defects are injected into the code. In fact, people working in sequential processes expect to discover defects during final testing; often a third or more of a software release cycle is reserved to find and fix defects after coding is theoretically “complete.” The irony is that sequential processes are designed to find and fix defects early, but in most cases they end up finding and fixing defects much later than necessary.
Where did we get the idea that finding and fixing defects at the end of the development process is appropriate? Just about every quality approach we know of teaches exactly the opposite. We should know that it is best to avoid defects in the first place, or at least to find defects immediately after they have been inserted into the code. It’s the same as losing your keys: If you lost your keys a few seconds ago, look down. If you lost them a few minutes ago, retrace your steps. If you lost them a week ago, change the locks.40 And yet we wait until the end of the development process to test our code, and by that time we need a lot of locksmiths. Why do we do this?
Part of the reason why we delay testing is because testing has historically been labor-intensive and difficult to perform on an incomplete system. With a lean frame of mind, we can no longer accept this historical mental model; we must change it. In fact, changing the historical mindset regarding testing is probably the most important characteristic we have seen in successful agile development initiatives. You can put all of the agile project management practices you want in place, but if you ignore the disciplines of test-driven development and continuous integration, your chances of success are greatly diminished. These so-called engineering disciplines are not optional and should not be left to chance.
So how do you keep from introducing defects into code? Dijkstra was clear on that; you have to construct programs “from the point of view of provability.” This means that you start by stating the conditions that must hold if the program is to perform correctly. Then you write the code that makes the conditions come true.41 In fact, formal methods for constructing correct code have been around a long time, but they have been historically difficult to use and have not found practical widespread application. So what has changed?
In 1994, Kent Beck published “Simple Smalltalk Testing” in the Smalltalk Report.42 In three pages he outlined a framework for testing Smalltalk code along with suggestions for how to use the testing framework. In 1997, Kent Beck and Erich Gamma wrote a version of the same testing framework for Java and called it JUnit. Many more xUnit frameworks have been written for other languages, and these have become the first widely used—and practical—tools for constructing correct programs.
How can testing be considered a tool for constructing a correct program? Isn’t testing after-the-fact? It is a bit of a misnomer to call the xUnit frameworks testing frameworks, because the recommended approach is to use these frameworks to write design specifications for the code. xUnit “tests” state what the code must do in order to perform correctly; then the code is written that makes these “tests” pass. While specifications written in xUnit frameworks may be less rigorous than formal methods such as Design by Contract, their simplicity and flexibility have led to widespread adoption. A well-considered xUnit test harness, developed and run wisely, makes quality by construction an achievable goal.
xUnit “tests,” or their equivalent using some other tool, are the software specification; they specify, from a technical perspective, how the smallest units of code will work, and how these units will interact with each other to form a component. These specifications are written by developers as a tool for designing the software. They are not—ever—written in a big batch that is completed before (or after) the code is written. They are written one test at a time, just before the code is written, by the developer writing the code.
There are tools to measure what percentage of a code base is covered by xUnit tests, but 100% code coverage is not the point; good design is the point. You should experiment to find out what level of code coverage generates good design in your environment. On the other hand, 100% of the xUnit tests you have in a harness should always pass. If they don’t pass, the policy must be: Stop. Find and fix the problem, or else back out the code that caused the failure. A unit test harness with tests that always pass means that when there is a failure, the fault was triggered by the last code checked into the system. This eliminates large amounts of time wasted on debugging; Dijkstra’s challenge has been met.
Unit tests are not universally applicable. For example, code produced by code generators—perhaps fourth-generation languages or domain-specific languages— is often not amenable to unit testing; you will probably have to use some form of acceptance testing instead. In addition, it is usually not practical to write unit tests for existing code bases, except for code that you are changing.
For new code, or for changes to existing code, xUnit tests or their equivalent should be considered mandatory. Why? Because writing tests first, then writing the code to pass the tests, means that the code will be testable code. If you want to change the code in the future, you will want testable code so you can make changes with confidence. Of course, this means that the tests have to be maintained over time, just like other code.
In many organizations, a relatively detailed specification of what software is supposed to do from a customer’s perspective is written before code is written. This specification should be written by people who truly understand the details of what the system is supposed to do, assisted by the members of the development team who will implement the features. The details of the specification should not be written long before the code; no doubt they will change, and the effort will be wasted. The detailed specification should be written iteratively, in a just-in-time manner.
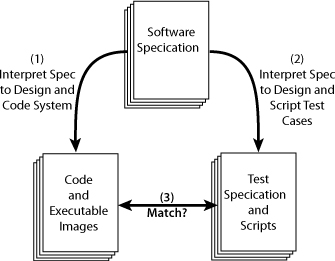
There are traditionally two uses of a software specification: Developers write code to meet the specification, and testers create various types of tests and write test scripts to assure that the code meets the specification. The problem is, the two groups usually work separately, and worse, the testers don’t write the tests until after the code is written. Under this scenario, the developers invariably interpret the details of the specification somewhat differently than the testers, so the code and tests do not match. Well after the code is written, the tests are run and these discrepancies are discovered. This is not a mistake-proofing process; this is a defect-injection process (see Figure 2-3).
Figure 2-3 A defect-injection process
To mistake-proof this process, the order of development needs to be changed. Tests should be created first—before the code is written. Either the tests are derived from the specification, or better yet, the tests are the specification. In either case, coding is not done until the tests for that section of code are available, because then developers know what it is they are supposed to code. This is not cheating; it is mistake-proofing the process (see Figure 2-4).
Figure 2-4 A mistake-proofed process
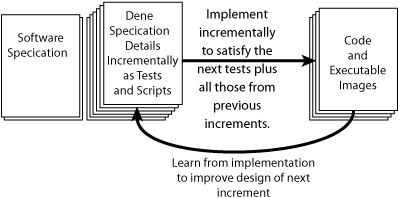
The preferred approach to specifying the details of a software product or application is to write acceptance tests. These tests are end-to-end tests that specify what the application is supposed to do from a business perspective, so they are quite different from unit tests. When the specification is written as executable tests, it can be run repeatedly as small parts of the code are written, and defects can thus be detected and fixed the moment they are injected into the system.
Of course, not all specifications can be written as automated tests, and automated tests must be created with insight or they will become a complex burden just as fast as any other software. However, creating an intelligent harness for testing that the code does what it is supposed to do is the best way we know of to produce code that—by definition—meets the specification.
Executable tests (specifications, actually), whether they are acceptance tests or xUnit tests or other tests, are the building blocks of mistake-proofing the software development process. These tests are put into a test harness, and then every time new code is written, the code is added to the system and the test harness is run. If the tests pass, you know not only that the new code works, but also that everything that used to work is still working. If the tests don’t pass, it’s clear that the last code you added has a problem or at least has exposed a problem, so it’s backed out and the problem is immediately addressed.
If this sounds easy, rest assured that it is not. Deciding what to automate, writing good tests, automating them, running them at the right time, and maintaining them is every bit as challenging as writing good code. It requires a good test architecture, sensible choices as to what to include in various test suites, and ongoing updating of tests so that they always match the current code.
Automation scripts need to be developed to support running tests early and often, and the discipline to stop and fix defects the moment they are discovered must be adopted. And although methods to do all of these things exist, they are new and have a serious learning curve. If you are going to spend money for training and tools for agile development (and you should), this is the first place to invest.43
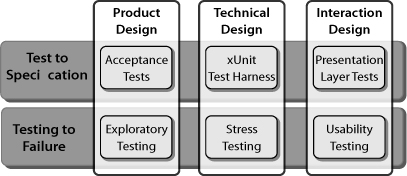
The Presentation Layer In most cases automated tests should not be run through the user interface, because this interface usually executes slowly; and it invariably changes very frequently, making the maintenance of such tests almost impossible. Just as it is a good idea to separate the user interaction layer from the layer that performs the business functions, it is also a good idea to test the presentation layer separately from the rest of the code. With a thin presentation layer, the presentation layer tests can be a simple verification that a screen action sends the correct result to the next layer of code. Other tests that are automated can then be run beneath the user interface, rather than through it.
The constructionist approach to developing software assures you that the software will do what it is supposed to do. However, you cannot be so sure that the software will not do what it is not supposed to do. In fact, you can’t even list all of the things that you do not want the software to do—no matter how hard you try, software will always find another way to surprise you. The classic approach to assuring that a system is robust is to push it to failure on all fronts that can be imagined, and then design the system to operate well inside the failure envelope.
Exploratory Testing Make sure your organization has some testers with devious minds who love to break systems. When they are successful, everyone should be pleased that they have found a weakness, and a test should be devised so that the failure mode will be detected by normal testing in the future. In addition, the cause of the failure should be examined to see if a better design approach can be used to avoid such a failure in the future, or if there is a boundary condition to steer clear of. Exploratory testing should be done early and often during development because it often uncovers design flaws, and the earlier a design flaw is found, the easier it is to remedy.
Usability Testing If a system is behaving exactly the way it was specified, but users can’t figure out how to use it effectively, the system is not going to be very useful. High training costs, low productivity, and high user error rates are all signs of poor interaction design. Human-interaction capabilities should be validated through usability testing. This validation is often done initially with simple paper models, then perhaps prototypes, and in the end with the actual system—again, the earlier, the better.
Stress Testing Performance, load, scalability, security, resilience, stability, reliability, compatibility, interoperability, maintainability—these are various aspects of stress testing that should be done as appropriate in your world. Generally you want to push your system over a cliff during this testing so that you know where the cliff is, and then stay away from that cliff in normal operation. Once again: Do these tests as early and as often as possible.
Figure 2-5 summarizes the various types of application testing we have discussed in this section.
Figure 2-5 Application testing
Code does not exist in a vacuum; if it did, software development would be easy. Code exists in a social setting, and arguably the biggest problem we have in software development is that code isn’t always a good neighbor. Thus integration is often the biggest problem with software, and when it is, leaving integration to the end of development is another example of a defect-injection process. Harlan Mills figured this out in 1970—and he found a solution. First he developed a skeleton of a system, and then he added small programs one at a time and made sure each of them worked before adding the next program. He called this top down programming, but somehow the underlying idea got lost in translation and few people really understood what Mills meant by the term.
Today our term for what Mills called top down programming would be step-wise integration. And with the test harness frameworks that we have available today, we can go further and integrate more or less continuously. We can use the same criterion for judging its effectiveness as Harlan Mills used: If you have a big-bang integration problem—or even a little-bang integration problem— you are not doing continuous integration very effectively.
Where did we get the idea that we should wait until the end of development to put the pieces of the system together? This is just another example of saving up all of our hidden defects and not trying to find them until the end of development. This violates every known good testing practice in the book. How can we possibly think it makes sense? Why do we do this?
The explanation lies partly in the distorted logic of the sequential frame of reference, but mainly in the sheer difficulty of testing software after every tiny integration step. In the past, testing has been mostly manual and therefore laborious, and moreover, testing partially done code has an annoying tendency to raise false negatives. In addition, as we raise the level of integration to larger system environments, the testing becomes all the more complex, because we have to test across a wider span of programs. And finally, it is impossible, really, to find everything that could go wrong, and testing for even a subset of the possibilities can be a long process, and thus one that cannot be undertaken very frequently.
So it should come as no surprise that continuous integration is not easy, and as integration escalates to higher system levels, it becomes a huge challenge. But consider the benefits: Many companies set aside 30% or more of each release cycle for a series of integration tests and the associated repairs necessary when the tests uncover defects. On the other hand, the best companies budget no more than 10% of a release cycle for final verification, and they do this with increasingly short release cycles. They can do this because the defects have been uncovered earlier in the development process; if they find defects at final verification, they are surprised and work to discover ways to keep those defects from escaping to the final verification step in the future.
Quite often, additional integration testing is required after a product is delivered. This is appropriate, as long as the integration flows smoothly and does not uncover defects. However, if customers have problems integrating the software you deliver, there is work to do to make your product more consumable. Integration problems anywhere in the value chain should challenge you to find and fix the true cause of the problem, so that such problems don’t occur in the future.
Enabling continuous integration for complex systems constrains architectural choices. Easily testable, low-dependency choices are much preferred.
Over the past decade, many tools and techniques have been developed to make early and frequent integration possible at the unit, application, and system levels. But it is not always practical to integrate all of the code all of the time. Furthermore, with a low-dependency architecture, it may not be necessary to run integration tests on truly independent parts of the code. How often you integrate and test depends on what it takes to find defects as soon as they are injected into the code, including defects that will affect other parts of the system once integration occurs. So the proof that you are integrating frequently enough lies in your ability to integrate rapidly at any time, without finding defects. That being said, there are some commonly used integration cadences that you might consider.
Every Few Minutes It is a common practice for agile developers to check their code into a configuration management system very frequently. Before they check in code, they download the most recent build and run a test harness locally. Then they check in their code, which triggers an automatic build and test cycle, which can be expected to pass. On the rare occasions when the build and test fail, the developer who checked in the code backs it out immediately and remedies the problem locally. With this discipline, the cause of defects should be easy to spot, because only a small amount of code is changed before a test harness is run; thus if a problem arises, it’s clear that the latest code has introduced the problem. This is about as easy as debugging gets, but it requires the absolute discipline of always maintaining a test harness where 100% of the tests pass.
It is very important for a test harness that is used this often to run quickly, or else developers will delay check-in (it takes too much time), which means that more time elapses before any defects are uncovered—and this creates a vicious circle. Therefore, wise decisions on the structure and content of this test harness are essential, because a fast-running test harness cannot cover the entire application.
Every Day At the end of the day, it’s time to run tests that are too lengthy to run continuously. This may mean running an acceptance test harness. Acceptance testing tools differ from xUnit testing tools in several ways. First, the tool must be able to distinguish between tests that should pass and tests that are not expected to pass because the code is not yet done. Second, acceptance tests often require the capability to set up a scenario in the database, or perhaps to run on a real database. Third, these tests will take longer—often they run overnight—and when developers come in the next day, the first order of business should be to stop and fix anything that went wrong overnight. If everything was working the day before and something went wrong overnight, only yesterday’s code could be the culprit. The failed test may be in some unexpected portion of the code, but the failure was most likely caused by something exposed by yesterday’s code.
Acceptance testing is often done with a “clean” database. In practice, the production database is going to be messy, so acceptance tests run on a clean database are inadequate for finding all of the problems. Nevertheless, running an acceptance test harness every day and fixing whatever is wrong (as far as practical) will bring great benefits. But sooner rather than later, the system should be tested on a more reasonable facsimile of the actual production database.
Every Iteration When software is ready for release, there are generally some staging activities that take place. For example, system testing—including such things as end-to-end scenario testing, running the system on a copy of the production database, and running in a user environment—is done to make sure that the code is ready for release. In general, it is a mistake to delay all staging activity until the system is ready for release. It is far better, for example, to run system tests as early as possible and find the problems when they are introduced, not later. On the other hand, system testing a partially done application can be a real problem. The complexity of setting up system tests can be large, they can take a very long time to run, and incomplete features that give false failure indications can waste a lot of time. But it is well worthwhile to try to change this reality and find ways to do valid system tests on partially done applications. Consider improving the architecture of systems that make setting up system testing difficult.
At the end of every iteration44—or even sooner—the development team should strive to produce a system-testable application. The application may not be done from a user perspective, but features should be complete enough to stage into a system test and successfully pass this test. Of course, this may not be practical unless much of the system testing is automated, especially if the tests are lengthy. Therefore, test automation is important, including test setup, test execution, and defect reporting. Finally, a clear mechanism to determine what features should work and what features are not yet complete must be a part of any system testing done before the application is complete.
Stress testing at the system level is also important. There will no doubt be an assortment of stress tests to run. It is a good idea to start running these at the end of each iteration so that if anything is wrong, you will find it earlier rather than later. This is particularly true because failure of these tests is quite often expensive to rectify later in the development process.
User acceptance tests (UATs) are also good candidates for running early and often—but getting cooperation from users can be problematic. However, if early UATs mean much faster delivery with many fewer defects, the benefits can be significant. Even if users are not willing to allow you into their environment for early UATs, creating a simulated user environment can go a long way toward helping to find the defects that will otherwise be revealed much later in the process.
Despite your best efforts, defects will occasionally escape into production. If you have done all of the testing we just mentioned, this should happen much less frequently than before. But when defects do escape, look upon it as a good opportunity for the development team to discover what it is about its design approach and development process that caused the defects and allowed them to escape. We recommend that developers, or at least representatives of the development team, follow their system to production and work with the people responsible for supporting the system to find the root causes of problems. This will help to give developers insight into how the system is used, as well as help them to improve their designs so that the same kind of problems will not escape in the future.45 There is wisdom in the approach of Amazon.com (see the sidebar “If You Need to Reach Agreement—You’re Lost”), where each service team is responsible for operations as well as development.
The final ingredient of quality by construction is simplicity. In a nutshell, mistakes hide in complexity, and they are exposed in simple, well-factored code. The time and effort it takes to deliver, maintain, and extend software are directly related to the clarity of the code. Lack of clarity is technical debt that will eventually have to be paid off with interest, debt that can overwhelm your ability to develop new features. Failure to pay off technical debt often results in bankruptcy: The system must be abandoned because it is no longer worth maintaining. It is far better not to go into debt in the first place. Keep it simple, keep it clear, and keep it clean.
In the book Clean Code, Robert Martin interviewed several world-class programming experts and asked them how they recognize clean code.46
Bjarne Stroustrup, inventor of C++:
I like my code to be elegant and efficient. The logic should be straightforward and make it hard for bugs to hide, the dependencies minimal to ease maintenance, error handling complete according to an articulated strategy, and performance close to optimal so as not to tempt people to make the code messy with unprincipled optimizations. Clean code does one thing well.
Grady Booch, author of Object-Oriented Analysis and Design with Applications:
Clean code is simple and direct. Clean code reads like well-written prose. Clean code never obscures the designers’ intent but rather is full of crisp abstractions and straightforward lines of control.
“Big” Dave Thomas, founder of OTI and godfather of the Eclipse strategy:
Clean code can be read, and enhanced by a developer other than its original author. It has unit and acceptance tests. It has meaningful names. It provides one way rather than many ways for doing one thing. It has minimal dependencies, which are explicitly defined, and provides a clear and minimal API. Code should be literate since, depending on the language, not all necessary information can be expressed clearly in code alone.
Michael Feathers, author of Working Effectively with Legacy Code:
I could list all of the qualities that I notice in clean code, but there is one overarching quality that leads to all of them. Clean code always looks like it was written by someone who cares. There is nothing obvious that you can do to make it better. All of those things were thought about by the code’s author, and if you try to imagine improvements, you are led back to where you are, sitting in appreciation of the code someone left for you—code written by someone who cared deeply about the craft.
Ward Cunningham, inventor of Wiki and Fit, co-inventor of Extreme Programming. The force behind Design Patterns. Smalltalk and OO thought leader. The godfather of all those who care about code.
You know you are working with clean code when each routine you read turns out to be pretty much what you expected. You can call it beautiful code when the code also makes it look like the language was made for the problem.
No one expects the first draft of a book to be perfect, and you should not expect the first draft of code be perfect either. More important, virtually all useful code bases will eventually need to be changed (and this is good, not bad). Code must be kept simple and clear, even as developers understand the problem more clearly and as the problem itself undergoes change. Therefore, code must be continuously refactored to deal with any duplication or ambiguities that were discovered through deeper understanding or introduced by the latest change. An increasing number of tools are available to assist with refactoring, but tools are not usually the issue here. The important thing is that developers must expect refactoring to be a normal part of their work. Like continuous testing, continuous refactoring is not optional. Choosing not to refactor is choosing not to pay down technical debt that will eventually show up as increased failure demand.
Peter Denning has been around software for a long time. He contributed to the understanding of operating system principles and has held just about every leadership position at ACM.47 In 2008 he and two colleagues wrote a position paper about why very large system development projects—the kind that are dealt with at the Navy Postgraduate School of Computer Science where the authors work—are so often unsuccessful. They said:48
If development time is shorter than the environment change time, the delivered system is likely to satisfy its customers. If, however, the development time is long compared to the environment change time, the delivered system becomes obsolete, and perhaps unusable, before it is finished. In government and large organizations, the bureaucratic acquisition process for large systems can often take a decade or more, whereas the using environments often change significantly in as little as 18 months (Moore’s Law)....
The traditional acquisition process tries to avoid risk and control costs by careful preplanning, anticipation, and analysis. For complex systems, this process usually takes a decade or more. Are there any alternatives that would take much less time and still be fit for use? Yes. Evolutionary system development produces large systems within dynamic social networks. The Internet, World Wide Web, and Linux are prominent examples. These successes had no central, preplanning process, only a general notion of the system’s architecture, which provided a framework for cooperative innovation.... The astonishing success of evolutionary development challenges our common sense about developing large systems....
Evolutionary development is a mature idea that... could enable us to build large critical systems successfully. Evolutionary approaches deliver value incrementally. They continually refine earlier successes to deliver more value. The chain of increasing value sustains successful systems through multiple short generations.
Denning and his colleagues talk about two kinds of evolution. First there is the evolution of a system as it goes through a series of releases. This can work, they say, as long as the releases are close together. When releases stretch out beyond the environment change time, this strategy does not work. A second kind of evolution occurs when multiple systems that compete with each other are created and only the fittest survive.49 To test the multiple-options approach, two projects were launched by the World Wide Consortium for the Grid (W2COG) to develop a secure service-oriented architecture system; one used a standard procurement and development process, and the other project ran as a limited technology experiment (LTE) using an evolutionary development process.
Both received the same government-furnished software for an initial baseline. Eighteen months later, the LTE’s process delivered a prototype open architecture that addressed 80% of the government requirements, at a cost of $100K, with all embedded software current, and a plan to transition to full COTS software within six months. In contrast, after 18 months, the standard process delivered only a concept document that did not provide a functional architecture, had no working prototype, deployment plan, or timeline, and cost $1.5M.50
Evolutionary development is not new. As we have seen, it was named by Tom Gilb in 1981 and has been the primary framework for developing PC, Internet, and open-source software. Evolutionary development is the preferred approach for reducing risk, because it confronts risk rather than avoiding it. Evolutionary development attempts to discover the systems that are best able to handle risk, either by rapidly adapting the current system to handle risks as they present themselves, or by fielding multiple systems and selecting the best alternative.
At the heart of the evolutionary approach is an ongoing series of short cycles of discovery, each cycle delivering one or more “experiments.” The experiments are constructed so as to fail fast, that is, to quickly indicate any weaknesses to the development team so team members can improve the system based on this feedback. Each cycle of discovery has three phases: ethnography, collaborative modeling, and quick experimentation (see Figure 2-6).
Figure 2-6 Cycles of discovery
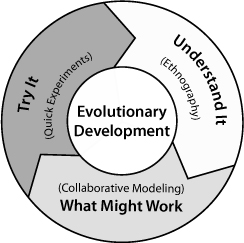
Ethnography “brings new learning and insights into the organization by observing human behavior and developing a deep understanding of how people interact physically and emotionally with products, services, and spaces,”51 writes Tom Kelley, IDEO general manager. He insists that fieldwork is the most important step in design. Various members of the development team—people with different backgrounds and jobs—spend time observing people grappling with the problem that their system is supposed to solve. They look, with a beginner’s mind, for things that annoy people, things that get in their way as they try to do the job. They create a bug list of everything that is wrong about the current experience.
Ethnography is not about gathering requirements or holding focus groups. It’s not about a product owner or product manager telling the development team what the system should do. It’s about several development team members with diverse backgrounds going to the place where the system will be used and talking to the people who will use it. It’s about observing firsthand how those people do their job now, what annoyances they have—even the little unspoken ones—and how they cope. Ethnography is about focusing on what works and what doesn’t. And it’s about constantly asking why? Why do people behave the way they do? Why are they annoyed by the way things work? Why are products and services designed the way they are? Why are they difficult (or easy) to use? It pays to observe outliers—people who don’t follow the rules and use a product in an unusual way, people who either love or hate a product and aren’t afraid to talk about why.
The biggest cause of failure in software-intensive systems is not technical failure; it’s building the wrong thing. We know this. Study after study confirms it. And yet we continue to put intermediaries between the development team and its customers. We might call these intermediaries systems analysts or product owners, but all too often they represent a handover of information. Secondhand information about the problem to be solved handicaps the people making the detailed decisions about how the system will behave. A critical role for product managers and product owners is to build bridges between customers and development team members, so they can talk to each other.
The information gained from ethnography should be digested by a thoughtful team which then works out what to do with it. This is the time for imagination, brainstorming, and storytelling. The team needs to develop a model of what the next step toward improving the customers’ experience might be. They might write some use cases and then break them down into stories with tests. They might update the product road map or create a mind map.
Quick prototypes are useful during modeling. Team members might sketch a picture or create a paper prototype that everyone can see, move around, modify, improve. Developers might try development spikes to investigate risky technical problems. Some team members might prototype part of a new business process or run database load projections through a simulator to see how the system might respond.
In the book The Elegant Solution,53 Matthew May says that one of the 12 practices of great innovators is to think in pictures. This is very useful in software development, because software is invisible to anyone who doesn’t read the code. By making mental models visible with pictures, diagrams, charts, and so on, the development team members can more easily communicate with one another, with customers, and with others who are interested in their work. For example, use paper prototypes instead of computer-generated ones to model a user interface. The only caution is not to invest too heavily in drawing the picture. If a model is too perfect or too laborious to produce, it will discourage change—and the purpose of a model is to encourage discussion and change.
Experimentation goes beyond creating prototypes for modeling; in this phase you actually implement portions of the real system. In other words, experimentation is implementation with the acknowledgment that what is implemented is probably going to change, or that another solution may prove to be superior. TCP/IP was considered an experiment, for example, although it turned out to be so good that we are still using it 30 years later. Even TCP/IP has evolved through several versions over the years.
In software development, there are two general approaches to experimentation. The more common approach is to develop in iterations, implementing the highest-risk and highest-priority software first. With the iterative approach, it is important to think of the software developed in early iterations as an experiment and make that code easy to change as the system grows to include more and more features. Software design should be focused on making change easy in any case, so low-dependency architecture and test harnesses should be part of the iterative process.
However, it is important not to make critical, expensive-to-change design decisions early in the iterative development process; difficult-to-change decisions should be handled with a set-based approach. Set-based design is often used in hardware development, where change is typically more difficult than in software development. With set-based design, decisions are scheduled for the last responsible moment—the point in time when the decision must be made or it will be made by default—and several options are developed at the same time. Typically the options being developed cover as much of the design space as possible, so as to allow experimentation with several significantly different approaches. When the time for the decision arrives, the choice is made based on which is best from a system perspective.
Both iterative development and set-based development are low-risk approaches that add predictability to the development process, as counterintuitive as that may sound. With iterative development, you develop the high-risk and high-value features first, all the while gaining a lot of knowledge about the capability and capacity of the development team as well as obtaining customer feedback. It is then much easier to predict when the system will be ready or to stop development at any time and still have a very useful system. With set-based development, decision points are scheduled and there is always an option that will work when the decision time arrives, again, reducing risk and protecting the schedule. We recommend that you consider a combination of both approaches to evolutionary development.
With the experiments done, it’s time to repeat the cycle: Try the experiments out in the field to discover how well they really work, then use ethnography, collaborative modeling, and experimentation again. We realize that full deployment of every experiment is not always possible or necessarily desirable, but come as close as you can. We also realize that ethnography is not always possible, especially in contracting situations. We understand that sometimes an intermediary is required instead of having the team connect directly with customers. If your world doesn’t allow each phase to be completed the way we describe, come as close as you can to the principles:
1. Work in cross-functional teams.
2. Be sure the team deeply understands the customer’s situation.
3. Have the team work together to come up with solutions.
4. Model the solution in some way—text, diagrams, sketches, prototypes, whatever works—to produce a shared direction.
5. Try out solutions quickly in an environment that is as close to the real one as is practical.
6. Think of the solutions as experiments and expect to modify them.
7. Work in small steps, preferably at a regular cadence.
8. Do it again.
The bottom line of evolutionary development is this: You cannot afford to develop systems of a size and timeline that stretch beyond your environment change time. If you are using lengthy planning processes to increase predictability, you can confidently predict this: If the system development time is greater than the environment change time, the system will fail.
Is a programmer an author or a translator?
Is code written for a machine or for a person?
Some people frame programming as a job of translation: Take a text-based specification and translate it into a language that a machine can understand. But is this the correct mental model? Two programmers working independently will create very different solutions to the same problem, often with large differences in interpretation. Similarly, two authors will produce widely different interpretations of the same topic, often with large differences in interpretation. However, two translators will produce relatively similar interpretations of the same work. If you think of programming as translating specifications into software, you probably aren’t a programmer. Very few people who “write code” think of themselves as translators; they think of themselves as authors of the code they write.
Some people, especially those who have never written code, assume that programmers write code for machines to read. Nothing could be farther from the truth; programmers write code for people to read. Programmers write initially for themselves, but more important, they write for the people who must interact with or change their code in the future. Good programmers work hard to clarify their intent as they write; they want their audience, the people who read their code, to know what they intended the code to do.
When you read something written in your native language, you can quickly tell what’s being said, but when you look at writing in a language you don’t understand, you have no clue what it’s all about. Programmers write in a peculiar language, and they write for people who understand that language; those who can’t read the language aren’t part of the audience. Sometimes we see demands for documentation from people who can’t read the code, but we know that anyone who seriously expects to change the code is going to have to read it. We believe that for most purposes, it is much more important for code to speak for itself than for documentation to translate its meaning.
“Software construction is a creative process,”54 Fred Brooks wrote. “Great designs come from great designers.... Study after study shows that the very best designers produce structures that are faster, smaller, simpler, cleaner, and produced with less effort. The differences between the great and the average approach an order of magnitude.”
If writing software were a translation process, you could hire a couple of great designers, have them design a great system, give the design to a team of translators, and expect excellent results. But attempts to do this have a dismal track record. By now we should have learned that in software development, we cannot separate design from implementation. Why? Because writing code is a creative process. People who write code are authors, not translators; they make design decisions constantly. “How do I handle a buffer to prevent overflow? What is the best way to group these ten things? How do I spot subtle duplication and remove it? How do I make a remote call that will never hang the system under any circumstances? Oops! That’s what caused a customer’s system to crash a couple of years ago; better not use it here.” And so on. Just about every ten minutes another design decision is made.
Expertise is needed at every level of a development organization. Sure, you should have a few great designers, but they must share their vision and their expertise with the people implementing the system. Otherwise, their great designs will never be realized and their expertise will not find its way into the software. If you want systems that are “faster, smaller, simpler, cleaner, and produced with less effort”; systems that delight customers; systems that are easy to maintain and extend—then you must have design expertise at the point where design decisions are actually made. Technical excellence comes from a conscious and well-planned effort to develop and sustain expertise at every level of the organization.
If you were a passenger on U.S. Airways flight 1549 as it lost power in both engines on take-off from LaGuardia Airport on January 15, 2009, you couldn’t have chosen a better pilot. Captain Chesley B. Sullenberger III, age 58, got his pilot’s license when he was 14. For seven years he flew F-4 Phantoms for the air force where he was a flight leader and training officer. He started flying commercial aircraft in 1980 and had accumulated 19,000 hours of flight experience by 2009. He worked with federal aviation officials investigating aircraft crashes and devised improved methods for handling emergencies. He even flew gliders; and on that cold January day, he glided his powerless Airbus to a perfect landing in the Hudson River.
The biggest danger in water landings is that the aircraft will flip or break up if water catches the aircraft unevenly, so the landing has to be perfect. In this landing, one engine (below the wing) sheared off, but the wings remained intact and the plane floated while 150 passengers congregated on the wings or huddled in life rafts. Nearby ferries rushed to the rescue, and within minutes everyone was safe. When the pilot was congratulated on his amazing landing, he replied, “That’s what we’re trained to do.”
There is an interesting number in this story: 19,000. People who study expertise have learned that it doesn’t matter if we are talking about pilots, musicians, lawyers, golfers, or software designers; the evidence is clear: It takes elite performers a minimum of 10,000 hours of deliberate, focused practice to become experts. That means it takes about ten years just to arrive at the top level. And world-class performers don’t stop practicing once they reach the top; they keep up their deliberate practice, continually putting effort into getting better than others in their field. Elite performers make their own luck. The passengers of flight 1549 were indeed lucky; they were lucky that Captain Sullenberger was in the cockpit, paired with Jeffrey Skiles, a 49-year-old copilot who had 26 years of commercial aviation experience and had been a pilot since he was 15. And then there were the three flight attendants, who among them had a total of 92 years of experience. It was the skill of these experts that brought the plane down and evacuated it safely.
You do not want to trust your software systems to luck. Technical excellence is not a matter of luck; it is a matter of skill, and that skill takes time to develop. If you are developing systems—and if you want excellent systems— focus on growing a cadre of skilled developers. Everyone does not have to be an expert; you should have some experts, some on their way to expertise, and some beginners. You need to be sure they are all continually increasing their expertise, especially in a technology area that changes as rapidly as software.
There is broad consensus among researchers of expert performance that inborn talent does not account for much more than a threshold; you have to have a minimum amount of natural ability to get started in a sport or profession. After that, the people who excel are the ones who work the hardest. They have to put in a good ten years of deliberate practice to become experts. Deliberate practice is not about putting in hours; it’s about deliberately working to improve performance. Deliberate practice works like this:
1. Identify a specific skill that needs improvement.
2. Devise—or learn from a teacher—an exercise designed to improve the skill.
3. Practice repeatedly.
4. Obtain immediate feedback on the results of each effort and adjust accordingly.
5. Concentrate on pushing the limits, and expect repeated failures.
6. Practice regularly and intensely, perhaps three hours a day.
Deliberate practice does not mean doing what you are good at; it means challenging yourself, doing what you are not—yet—good at. So it’s not necessarily fun. Keeping up this kind of practice day in and day out requires passion on the part of the participant. It also requires encouragement from people who matter (parents and peers, for example) and a teacher who can identify the skills to be improved and knows the latest practice techniques (at least at first).
Unfortunately, our organizations are not set up to develop experts. First of all, work assignments are rarely structured to provide challenges so developers can push the limits of their competence. Instead we tend to assign people things to do that they are already good at. Second, we rarely provide managers with the technical depth to understand the work they manage and provide regular, focused feedback so developers can improve. Nor do we provide an alternate way to generate this kind of feedback, for example, by providing technical mentors or experienced teammates and a thoughtful review process. Finally, we tend to keep developers at arm’s length from their customers, rather than allowing them to get immediate feedback and become deeply engaged in the overall success of their efforts.
You don’t want an inexperienced developer working without guidance on critical software any more than you want an inexperienced captain piloting your airplane. You can hire experienced developers, but if their experience is not in your domain, it’s probably not sufficient. Degrees and certifications are indications that the person has met the threshold to become an expert, but developing true expertise still takes years.
The ten-year rule has been found to hold in almost every complex domain investigated; it takes that much deliberate practice to become an elite performer in any field. In half as much time, you get competent but not brilliant performance. Expertise is domain-specific; people who move to a similar domain may have a head start, but they will not immediately be top performers. And ten years of experience doing the same thing does not necessarily indicate expertise; if the experience didn’t involve deliberate efforts to improve weaknesses and try new things, it probably doesn’t count toward developing expertise.
So it’s unlikely that new college graduates are going to be great designers or great programmers, unless they have been writing software for many years before college. In order to become great, those new hires right out of school need time, mentors, and ongoing focused practice. Just writing code is not sufficient. Learning happens through writing code that solves a problem in an effective manner, code with elegant style and clarity, code that is better than the last attempt. In order to make this happen, new developers need teachers or mentors, challenging work assignments, immediate feedback, and, most of all, work they can become engaged in. You need some experts to guide those developing their programming prowess. And you have to have a way for those who are practicing to know when they have done a good job and where they can improve.
“Right,” you say. “Have you ever heard about turnover? How am I going to keep anyone around for ten years?” Turnover comes in two flavors; there is systemic turnover that you probably can’t control, and there is turnover that might be reduced if your organization were a more attractive place to work. Let’s start with systemic turnover. Military organizations experience very high turnover; most recruits join the military for a couple of years and then move on to other careers. Certain countries—India comes to mind—experience similarly high turnover among new software development recruits. If this is your situation, investigate the way in which top military organizations handle high turnover. First of all, they build the capability to rapidly bring new recruits up to speed through focused training and carefully designed work assignments. Second, they maintain a core of leaders who stay in the organization over many years, and their programs for developing expertise are concentrated on these medium-and long-term members.
With the exception of systemic turnover, we observe that retention is often a matter of a self-fulfilling prophecy: If you don’t think retention is important or achievable, it won’t be. But if you work to provide a place where people are challenged and helped to reach their full potential, it will be a place where passionate people prefer to work.
Why do people working on open-source projects contribute so much effort for free? In part it is because open-source work provides exactly the kind of deliberate practice that is not available in most companies. Developers take on challenging assignments and submit code that is reviewed by an expert committer, who provides immediate feedback. If the code is committed, more—sometimes harsh—feedback is provided by the open-source community—exactly what a person who passionately wants to become an expert really needs. Open-source developers care deeply about their work, as do expert authors, pilots, and trumpet players. We believe that one of the best ways to retain people who are growing their expertise is to provide them with the opportunity to improve their skills and to become passionate about their work. We will discuss this further in Chapter 5.
Standards are the baseline of current good practice in an organization that everyone is expected to achieve. They are sort of like learning the scales in music. One of the roles of experts is to make sure that standards are in place. Those who have learned through hard experience the best way of doing things in their environment should make sure that others don’t have to reinvent the wheel. But standards are never perfect and need to be constantly challenged and improved. So once someone has mastered a standard practice, a good learning exercise would be for a mentor to help that person challenge aspects of the standard that need improvement and come up with a better way of doing things. We will discuss this at length in Chapter 4.
Code reviews are a good way of turning programming into deliberate practice. Having code reviewed by an expert (equivalent to a committer) or a colleague (for example, in pair programming) provides immediate feedback on style, clarity, robustness—whatever is important in your domain. This feedback is often accompanied by ideas for improvement. Anyone who views programming as a skill to be constantly improved will appreciate the feedback that comes from reviews that focus on developing expertise. Common code ownership also contributes to the feedback and improvement process, because those who write code knowing that colleagues will read and change it will pay attention to code style and clarity. Junior people can not only see but also work with examples of code written by more experienced colleagues.
The way to develop expertise throughout your organization is to provide the environment that nurtures expertise and helps people reach their full potential:
1. Create time and space for wise experts to act as mentors for those who are learning.
2. Provide many opportunities for deliberate practice with interesting challenges and effective feedback.
3. Make it possible for people to be passionate about their work.
In 2006, Jeff Immelt talked about the five traits he is looking for in leaders at GE: external focus, clear thinking, imagination, inclusiveness, and domain expertise.56 “Why domain expertise?” he was asked. “The most successful parts of GE are places where leaders have stayed in place a long time.... The places where we’ve churned people... are where we’ve failed.” Immelt explained that leaders with domain expertise make the important decisions correctly because they can rely on their deep knowledge of the business. We think the same principle applies to competency leaders: The best decisions and the best guidance come from leaders with solid expertise in the technical fields for which they are responsible.
What do competency leaders actually do? First and foremost, they are committed to developing excellent technology in their organization. They begin by framing good software development in terms of an enabling architecture, mistake-proofed processes, evolutionary development, and technical expertise. They ensure that a low-dependency architecture is in place. They make sure that test-driven development and continuous integration are used effectively. They provide for cycles of learning with iterative development and set-based design, and they advise when each is appropriate. They set standards, insist on code clarity, and make sure code reviews are focused on enhancing learning.
Probably the most important role of a competency leader is that of a teacher who guides the purposeful practice necessary to develop expertise. The role of teacher is considered essential in developing musical and athletic expertise, and it is also found in education: Graduate students work under the guidance of a major professor in their field. Teachers provide goals, challenging work, and immediate feedback. They help their students get better by providing opportunities for them to test their developing expertise. Teachers may not be elite performers in their field, but they are aware of the best techniques and training methods and use these to guide their students.
If you want the people in your organization to develop their expertise to its full potential, you have to provide teachers. Not just training, but teachers— teachers who match the work to the person, who find challenging assignments so that each individual can improve, who pay close attention to the work being done and provide feedback. You might call these people mentors or managers, but in this book we will call them competency leaders.
Competency leaders are often line managers, but line managers are not always competency leaders. Sometimes we find line managers with 50 or 60 people reporting to them. It’s hard to imagine how these managers can play the role of teacher. Who will watch out for the technical development of all these people, care about their career paths, make sure they are developing to their full potential? And who is watching out for the core technologies that constitute the company’s competitive advantage?
Critical technologies need leaders. Someone has to train new people in the technology, set and improve standards, make sure the technology is expanded to keep ahead of the competition. Assume that you have the fastest Web response time in your market niche, or a superb capability to develop ultra-secure transactions, or some similar competitive advantage. What’s going to keep you ahead of the competition over time? Your current expertise resides in people who need to see where their future lies, and your future expertise lies with new people who need to be recruited and mentored. This is the job of the competency leader. It is a critically important and very challenging job. And unfortunately, it is all too often absent in our organizations.
1. What percentage of your release cycle is spent in “hardening,” system testing, user acceptance testing, and similar activities? What is the average age of a defect when it is first discovered? What are you doing to drive these numbers toward zero?
2. Is Conway’s Law—organizations that design systems are constrained to produce designs that are copies of the communication structures of these organizations— evident in your organization?
3. Would you consider your basic system architecture low-dependency or tightly coupled? If it is not low-dependency, answer the following questions:
a. How many people have to get involved in delivering a new medium-sized feature?
b. How many teams have to get involved? How do they communicate with each other?
c. How rapidly do you implement a new medium-sized feature using a normal process?
d. Do you have any competitors who routinely implement new features significantly faster?
4. Watch the video “The Yawning Crevasse of Doom” by Martin Fowler and Dan North (www.infoq.com/news/2008/08/Fowler-North-Crevasse-of-Doom). This video discusses the pitfalls of separating developers from customers. How many handovers separate developers from customers in your organization?
5. Review the following list of basic disciplines and give yourself/your team a score of 0 to 5 on each discipline. (0 means you’ve never heard of it; 5 means you could teach a course on it.) Look at any score of 3 or below and consider how to improve in that discipline.
a. Coding standards (for code clarity)
b. Design/code reviews c. Configuration/version management
d. One-click build (private and public)
e. Continuous integration
f. Automated unit tests
g. Automated acceptance tests
h. Stop if the tests don’t pass
i. System testing with each iteration
j. Stress testing (application- and system-level)
k. Automated release/install packaging
l. Escaped defect analysis and feedback
6. Every year SANS Institute publishes the 25 most dangerous programming errors. The following list was published in January 2009 (see www.sans.org/top25errors/#s4). Which of the errors do your developers recognize? Which errors does everyone know how to prevent? Who is making sure that your organization does not make any of these errors? What kind of training or mentoring program exists, and what coding standards are in place to prevent these (and similar) errors?
CATEGORY: Insecure Interaction Between Components
1. Improper Input Validation
2. Improper Encoding or Escaping of Output
3. Failure to Preserve SQL Query Structure (aka “SQL Injection”)
4. Failure to Preserve Web Page Structure (aka “Cross-site Scripting”)
5. Failure to Preserve OS Command Structure (aka “OS Command Injection”)
6. Cleartext Transmission of Sensitive Information
7. Cross-Site Request Forgery (CSRF)
8. Race Condition
9. Error Message Information Leak
CATEGORY: Risky Resource Management
10. Failure to Constrain Operations within the Bounds of a Memory Buffer
11. External Control of Critical State Data
12. External Control of File Name or Path
13. Untrusted Search Path
14. Failure to Control Generation of Code (aka “Code Injection”)
15. Download of Code Without Integrity Check
16. Improper Resource Shutdown or Release
17. Improper Initialization
18. Incorrect Calculation
CATEGORY: Porous Defenses
19. Improper Access Control (Authorization)
20. Use of a Broken or Risky Cryptographic Algorithm
21. Hard-Coded Password
22. Insecure Permission Assignment for Critical Resource
23. Use of Insufficiently Random Values
24. Execution with Unnecessary Privileges
25. Client-Side Enforcement of Server-Side Security
7. What are the three most important technical competencies in your organization, for example, competencies that create a competitive advantage for your company? Who is responsible for ensuring that each of those competencies is being used well, preserved, and expanded? Who hires and mentors new people in these competencies?
