Performing a Query with a DataReader
To
retrieve records with a Command and
DataReader, you need to use the SELECT statement,
which identifies the table and rows you want to retrieve, the filter
and ordering clauses, and any table joins:
SELECTcolumnsFROMtablesWHEREsearch_conditionORDER BYorder_expression ASC | DESC
When writing a SELECT statement with a large table, you may want to limit the number of returned results to prevent your application from slowing down dramatically as the database grows. Typically, you accomplish this by adding a WHERE clause that limits the results.
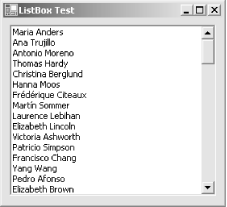
Example 5-1 shows a sample Windows application that fills a list box with the results of a query. The designer code is omitted.
// DataReaderFillForm.cs - Fills a ListBox
using System;
using System.Windows.Forms;
using System.Data.SqlClient;
public class DataReaderTest : Form
{
private ListBox lstNames;
private string connectionString = "Data Source=localhost;" +
"Initial Catalog=Northwind;Integrated Security=SSPI";
public DataReaderTest()
{
lstNames = new ListBox();
lstNames.Dock = DockStyle.Fill;
Controls.Add(lstNames);
Load += new EventHandler(DataReaderTest_Load);
}
public static void Main()
{
DataReaderTest t = new DataReaderTest();
Application.Run(t);
}
private void DataReaderTest_Load(object sender, System.EventArgs e)
{
string SQL = "SELECT ContactName FROM Customers";
// Create ADO.NET objects.
SqlConnection con = new SqlConnection(connectionString);
SqlCommand cmd = new SqlCommand(SQL, con);
SqlDataReader r = null;
// Execute the command.
try
{
con.Open();
r = cmd.ExecuteReader();
// Iterate over the results.
while (r.Read())
{
lstNames.Items.Add(r["ContactName"]);
}
}
catch (Exception err)
{
MessageBox.Show(err.ToString());
}
finally
{
if (r != null) r.Close();
con.Close();
}
}
}The results are shown in Figure 5-1.
Using Column Ordinals
The previous
example retrieved field values using a column name. Internally,
however, the DataReader stores field information
using a zero-based index. When you supply a column name, the
DataReader performs a lookup in a
Hashtable collection behind the scenes and then
determines the appropriate ordinal. This adds a slight overhead,
which increases the time required to read a column by up to 30%.
You can avoid this overhead by using the column ordinal when selecting a column:
// Display the value from the first column. Console.WriteLine(r[0]);
Of course, this adds a tighter level of coupling between the data
source and your code. For example, imagine you are writing your code
as part of an enterprise-level distributed application. You are
probably retrieving your query through a stored procedure. The order of
DataReader columns is determined by the order of
column names in the SELECT statement that the stored procedure uses.
If the stored procedure changes, your code could fail. (A similar
problem occurs if you are using name-based lookup, and the column
names are changed, but this problem is typically easier to spot.)
To manage the possible confusion, you can retrieve the column
ordinals after executing the query. This way, you perform the name
lookup once and can use the better-performing index numbers for the
remainder of your code, without exposing your code to unnecessary
risk if the database changes. The DataReader
provides a GetOrdinal( )
method for this purpose:
// Read and store all the ordinals you need.
int ID = r.GetOrdinal("CustomerID");
int Name = r.GetOrdinal("ContactName");
while (r.Read())
{
// Use the ordinals when retrieving field values.
Console.Write(r[ID]);
Console.WriteLine(r[Name]);
}This code realizes a fairly modest performance increase.
Using Typed Accessors
Databases use their own proprietary
data
types, which map
closely, but not exactly, to .NET data types. Internally, the
DataReader uses a type as close as possible to the
database-specific data type. If needed, you can cast this type to a
.NET framework type, or you can use the strongly typed accessor
methods such as GetInt32( ) and
GetString( ), which perform this step
automatically.
In some cases, these conversions can conceivably introduce minute
rounding errors, loss of precision, or a minor
performance slowdown. To
circumvent these problems, some DataReader
implementations provide additional methods that let you retrieve data
types in their native form. For example, the SQL Server provider
includes the types in the System.Data.SqlTypes
namespace. These types map directly to SQL Server database types
(such as money, smalldatetime,
and varchar). To see the exact mapping, refer to
Appendix A.
The SqlDataReader also provides corresponding
methods for each data type, such as GetSqlMoney( )
and GetSqlDataTime( ). To use this method, you
must supply the column index (the column name isn’t
supported).
Example 5-2 shows how you might retrieve information from the Orders table using native SQL Server data types.
// NativeSqlServer.cs - Retrieves data as native SQL Server types.
using System;
using System.Data.SqlClient;
using System.Data.SqlTypes;
public class NativeSqlServer
{
public static void Main()
{
// Query string to get some records from Orders table
string SQL = "SELECT OrderID, CustomerID, " +
"OrderDate, Freight FROM Orders";
// First column OrderID is int datatype in SQL Server.
SqlInt32 orderID;
// Second column CustomerID is nchar in SQL Server.
SqlString customerID;
// Third column OrderDate is datetime in SQL Server.
SqlDateTime orderDate;
// Fourth column Freight is money in SQL Server.
SqlMoney freight;
// Create the ADO.NET objects.
SqlConnection con = new SqlConnection("Data Source=localhost;" +
"Initial Catalog=Northwind;Integrated Security=SSPI");
SqlCommand cmd = new SqlCommand(SQL, con);
SqlDataReader r;
con.Open();
// Perform the query.
r = cmd.ExecuteReader();
// Read the rows from the query result.
while (r.Read())
{
// Get the columns as native SQL types.
orderID = r.GetSqlInt32(0);
customerID = r.GetSqlString(1);
orderDate = r.GetSqlDateTime(2);
freight = r.GetSqlMoney(3);
// You can now do something with the data.
// This example just prints out the row.
Console.Write(orderID.ToString() + ", ");
Console.Write(customerID + ", ");
Console.Write(orderDate.ToString() + ", ");
Console.Write(freight.ToString() + ", ");
Console.WriteLine();
}
}
}In this example, the advantage of using the SQL Server-specific types is minimal. In fact, all the SQL Server types map quite closely to their .NET equivalents. However, if you use a data source that exposes data in a unique format, this approach may become very important.
Tip
Each SQL data type provides a set of methods for comparison, data conversion, and (for numeric data) mathematical manipulations. See Part III for more information.
The managed
Microsoft Oracle provider includes some specialized structures (e.g.,
OracleDateTime) in the
System.Data.OracleClient namespace. You can use
these structures to retrieve data using the dedicated methods of the
OracleDataReader class.
The OLE DB managed provider doesn’t include any specialized structures for OLE DB types. Refer to Appendix A for more information about the mapping between OLE DB types and .NET framework types.
Retrieving Null Values
A common database convention is to use the null value to represent missing data. Some fields may refuse nulls, while others may allow them, indicating that data doesn’t need to be entered for this column.
.NET value types can’t legally contain a null value.
Thus, if you try to retrieve a null value through a
DataReader and assign it to a value type, you will
receive an InvalidCastException. However, the data
types in the DataReader
can
contain null values. (Otherwise, simply trying to read a row that
contains a null value generates an error, rendering the
DataReader useless).
There are several ways to code around the null value problem:
If you use SQL Server, you can retrieve native SQL Server data types with the appropriate
DataReadermethods. Every SQL Server data type implements theSystem.Data.SqlTypes.INullableinterface, allowing them to legally contain a null value. However, a problem will occur if you try to cast a null value to a base .NET type.You can call the
ToString( )method on the value, as shown in Example 5-2. Types that contain the null value simply return an empty string. This approach works well when you only need to display the data.You can explicitly check the value before attempting to assign it to another variable.
The final approach is useful if you need to store the value in
another variable. However, you can’t just test the
field for a null reference. The problem here is that the column value
does in fact exist: it isn’t null. However, it
represents a null value because it
doesn’t contain any information. The .NET framework
includes the System.DBNull class for this purpose,
which allows you to distinguish between a null reference and a null
database value. If the column value is equal to
DBNull.Value, it represents a null database field.
The syntax is shown here:
int rowVal;
if (r[i] != DBNull.Value)
{
// Use default value. Row is null.
rowVal = 0;
}
else
{
// Use database value.
rowVal = (int)r[i];
}There’s another way to explicitly test for a null
value: using the IsDbNull( ) method of the
DataReader. This code is equivalent:
int rowVal;
if (r.IsDbNull(i))
{
// Use default value. Row is null.
rowVal = 0;
}
else
{
// Use database value.
rowVal = (int)r[i];
}Returning Multiple Result Sets
It is possible to execute a query that returns multiple result sets. This technique can improve performance because you need to contact the database only once to initiate the query. All data is then retrieved in a read-only stream from start to finish.
There are two ways to return more than one result set. You might be executing stored procedures that contain more than one SELECT statement. Alternatively, you might set up a batch query to execute multiple SQL statements by separating them with a semicolon:
// Define a batch query. string SQL = "SELECT * FROM Categories; SELECT * FROM Products"; SqlConnection con = new SqlConnection(connectionString); SqlCommand cmd = new SqlCommand(SQL, con); con.Open(); // Execute the batch query. SqlDataReader r = cmd.ExecuteReader();
You need only one DataReader to process multiple
result sets. To move from the first result set to the second, use the
DataReader.NextResult( ) method:
while (reader.Read())
{
// (Process the category rows here.)
}
reader.NextResult();
while (reader.Read())
{
// (Process the product rows here.)
}Showing All Columns with the DataReader
The OLE DB, ODBC, Oracle, and SQL Server providers all add a
FieldCount
property to the
DataReader.
This property allows you to retrieve the number of fields in the
current row. Using this information, you can write a generic code
routine to display the results of a query by index number, rather
than by hard-coding field names. The disadvantage of this approach is
that you are forced to use the order in which the columns were
retrieved, which may not make the most sense for display purposes.
Generally, the more your application knows about the structure of
your data, the better it can present it—and the more difficult
your life becomes when the database changes.
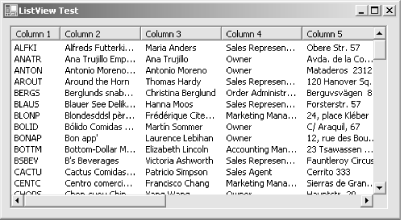
Example 5-3 shows an example that fills a
ListView details grid with the results of the
current query, regardless of the number or type of columns.
// ListViewFillForm.cs - Fills a ListView
public class DataReaderTest : System.Windows.Forms.Form
{
private System.Windows.Forms.ListView lvCustomers;
private string connectionString = "Data Source=localhost;" +
"Initial Catalog=Northwind;Integrated Security=SSPI";
// (Windows designer code omitted.)
private void DataReaderTest_Load(object sender, System.EventArgs e)
{
string SQL = "SELECT * FROM Customers";
lvCustomers.View = View.Details;
// Create ADO.NET objects.
SqlConnection con = new SqlConnection(connectionString);
SqlCommand cmd = new SqlCommand(SQL, con);
SqlDataReader r = null;
// Execute the command.
try
{
con.Open();
r = cmd.ExecuteReader();
// Add the columns to the ListView.
for (int i = 0; i <= r.FieldCount - 1; i++)
{
lvCustomers.Columns.Add("Column " + (i + 1).ToString(),
100, HorizontalAlignment.Left);
}
// Add rows of data to the ListView.
while (r.Read())
{
// Create the ListViewItem row with the first column.
ListViewItem lvItem = new ListViewItem(r[0].ToString());
// Add the data for the other columns.
for (int i = 1; i <= r.FieldCount - 1; i++)
{
lvItem.SubItems.Add(r[i].ToString());
}
// Add the completed row.
lvCustomers.Items.Add(lvItem);
}
}
catch (Exception err)
{
MessageBox.Show(err.ToString());
}
finally
{
if (r != null) r.Close();
con.Close();
}
}
}The results for this example are shown in Figure 5-2.
Reading Single Rows with a DataReader
Command
objects also provide another
variation of the ExecuteReader( )
method that accepts a combination of
values from the
CommandBehavior
enumeration. These values provide
additional information about how the command should be executed.
The CommandBehavior enumeration is useful if you
need to read large binary data sequentially, as described in the next
section. However, it can also offer some
performance
improvement in cases when you know a SELECT statement will return
only a single record (for example, if you include a WHERE clause
specifying a value from a unique column). In this case, you can use
CommandBehavior.SingleRow to inform the provider:
r = cmd.ExecuteReader(CommandBehavior.SingleRow);
This extra step certainly won’t harm performance, but its potential benefit depends on the specific implementation in the data provider.
Retrieving BLOB Data
The CommandBehavior
enumeration is useful if you need to retrieve a BLOB from the
database. In this situation, the
DataReader’s default behavior,
which is to load the entire row into memory before providing it to
your code, is dangerously inefficient. By specifying
CommandBehavior.SequentialAccess, you indicate
that your code will read through the data in a row sequentially, from
start to finish. Thus, only a single field of data is read into
memory at a time, instead of the entire row, reducing the memory
overhead of your code. This benefit is trivial if row sizes are small
but important if they are large.
When using CommandBehavior.SequentialAccess, you
must read the fields in the same order they are returned by your
query. For example, if your query returns three columns, the third of
which is a BLOB, you must return the values of the first and second
fields before accessing the binary data in the third field. If you
access the third field first, you can’t access the
first two fields.
When dealing with binary data, you typically use the
DataReader.GetBytes( )
method, which fills a byte array with a
portion of the data, according to the buffer size and starting
position you specify. The GetBytes( ) method
returns an Int64 value that indicates the number
of bytes that were retrieved. To determine the total number of bytes
in the BLOB, pass a null reference to the GetBytes( ) method.
Example 5-4 demonstrates a console application that reads a list of records, and then reads a large binary field and writes it to disk as a bitmap file. This example uses the pubs database.
// BLOBTest.cs - Writes binary data to a file
using System;
using System.Data.SqlClient;
using System.Data;
using System.IO;
public class ConnectionTest
{
private static string connectionString = "Data Source=localhost;" +
"Initial Catalog=pubs;Integrated Security=SSPI";
private static string SQL = "SELECT pub_id, logo FROM pub_info";
public static void Main()
{
int bufferSize = 100; // Size of the BLOB buffer.
byte[] bytes = new byte[bufferSize]; // The BLOB byte[] buffer.
long bytesRead; // The number of bytes read.
long readFrom; // The starting index.
SqlConnection con = new SqlConnection(connectionString);
SqlCommand cmd = new SqlCommand(SQL, con);
// Open the connection and execute a sequential DataReader.
con.Open();
SqlDataReader r =
cmd.ExecuteReader(CommandBehavior.SequentialAccess);
while (r.Read())
{
string filename = "logo" + r.GetString(0) + ".bmp";
Console.WriteLine("Creating file " + filename);
// Create a file stream and binary writer for the data.
FileStream fs = new FileStream(filename, FileMode.OpenOrCreate,
FileAccess.Write);
BinaryWriter bw = new BinaryWriter(fs);
// Reset the starting position for the new BLOB.
readFrom = 0;
// Read the field 100 bytes at a time.
do
{
bytesRead = r.GetBytes(1, readFrom, bytes, 0, bufferSize);
bw.Write(bytes);
bw.Flush();
readFrom += bufferSize;
} while (bytesRead == bufferSize);
// Close the output file.
bw.Flush();
bw.Close();
fs.Close();
}
r.Close();
con.Close();
}
}