Shaping DataSet XML
The default format used for the DataSet XML works
perfectly well when you create a new cross-platform application.
However, most systems include legacy clients that require data in a
set format. Unfortunately, even a minute difference between the
expected and the actual XML file format can prevent a client from
successfully reading the data.
ADO.NET offers limited ways to customize the generated XML for a
DataSet. Before writing your own custom code, you
should begin by examining these features. If you need to perform more
significant changes, you need to perform these additional operations
using the .NET XML classes or XLST transformation.
Attributes and Elements
One recurring question in XML modeling is the question of whether to use attributes to store data or contained elements. For example, here’s a category row that uses only elements:
<Categories> <CategoryID>1</CategoryID> <CategoryName>Beverages</CategoryName> <Description>Soft drinks, coffees, teas, beers, and ales</Description> </Categories>
And here’s the same row with attributes:
<Categories CategoryID="1" CategoryName="Beverages" Description="Soft drinks, coffees, teas, beers, and ales" />
With ADO.NET, you can configure whether column values are stored in
attributes or elements. Best of all, you can do it on a per-column
basis (for example, storing the unique identity column as an
attribute and all other columns as elements). All you need to do is
set the DataColumn.ColumnMapping property to one
of the values shown in Table 17-4.
The following code snippet iterates through all the column objects in
a DataSet and configures them to use
attribute-based representation. You can add this code to Example 17-1 earlier in this chapter to try out the
technique.
foreach (DataColumn col in ds.Table["Categories"].Columns)
{
col.ColumnMapping = MappingStyle.Attribute;
}Unfortunately, there is no easy way to use a different element or
attribute name. If you don’t want to use the default
DataColumn.ColumnName, you have to create an
export routine that manually renames columns before serializing the
DataSet.
Relational XML Data
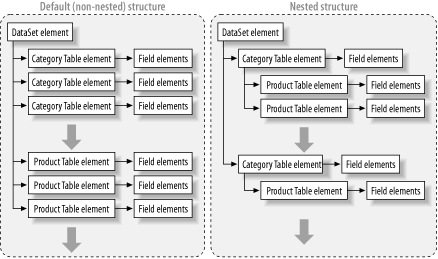
Relational databases organize information into tables, in which each row represents an independent item. To relate different types of items (such as customers and orders), table relations are added. XML, on the other hand, often uses a hierarchical model. For example, you can model a list of products by creating product elements inside category elements. This type of organization is more efficient for some operations (for example, finding all the products in a given category), and less flexible for others (for example, creating a composite list of products).
By default, when writing a DataSet with multiple
tables to XML, ADO.NET places the row elements for each table
consecutively. For example, in XML, a table with rows from the
Categories and Products tables
is stored with the following format:
<?xml version="1.0" standalone="yes"?>
<Northwind>
<Categories>
<CategoryID>1</CategoryID>
<CategoryName>Beverages</CategoryName>
<Description>Soft drinks, coffees, teas, beers, and ales</Description>
</Categories>
<Categories>
<CategoryID>2</CategoryID>
<CategoryName>Condiments</CategoryName>
<Description>Sweet and savory sauces, relishes, spreads, and
seasonings</Description>
</Categories>
<!-- Other categories omitted. -->
<Products>
<ProductID>1</ProductID>
<ProductName>Chai</ProductName>
<CategoryID>1</CategoryID>
</Products>
<Products>
<ProductID>2</ProductID>
<ProductName>Chang</ProductName>
<CategoryID>1</CategoryID>
</Products>
<!-- Other products omitted. -->
</Northwind>Alternatively, you can create XML using a tree-based structure with
relations. All you need to do is create the
DataRelation and set the
DataRelation.Nested property to
true. In this case, the format is hierarchical,
based on the parent-child relationship, and products are grouped by
categories:
<?xml version="1.0" standalone="yes"?>
<Northwind>
<Categories>
<CategoryID>1</CategoryID>
<CategoryName>Beverages</CategoryName>
<Description>Soft drinks, coffees, teas, beers, and ales</Description>
<Products>
<ProductID>1</ProductID>
<ProductName>Chai</ProductName>
<CategoryID>1</CategoryID>
</Products>
<Products>
<ProductID>2</ProductID>
<ProductName>Chang</ProductName>
<CategoryID>1</CategoryID>
</Products>
<!-- Other products in this category omitted. -->
</Categories>
<Categories>
<CategoryID>2</CategoryID>
<CategoryName>Condiments</CategoryName>
<Description>Sweet and savory sauces, relishes, spreads, and
seasonings</Description>
<Products>
<ProductID>3</ProductID>
<ProductName>Aniseed Syrup</ProductName>
<CategoryID>2</CategoryID>
</Products>
<!-- Other products in this category omitted. -->
</Categories>
<!-- Other categories omitted. -->
</Northwind>Figure 17-2 diagrams the difference.
This is all well and good for a one-to-many relationship, but what
about a many-to-many relationship, which is always implemented by
three tables? For example, in the Northwind database, there are
Territories, Employees, and
linking EmployeeTerritories tables.
The hierarchical tree-based model isn’t well suited
to show this relationship. If you nest Territory
elements in EmployeeTerritory elements, which in
turn are placed inside Employee elements, you
quickly end up with duplicate Territory elements.
If you use a tree starting with Territory
elements, you end up with a duplicate employee under more than one
territory branch. ADO.NET avoids this problem by disallowing it. If
you try to set the Nested property on both
columns, you receive an ArgumentException.