Spiders, also known as web spiders, crawlers, and web walkers, are specialized webbots that—unlike traditional webbots with well-defined targets—download multiple web pages across multiple websites. As spiders make their way across the Internet, it’s difficult to anticipate where they’ll go or what they’ll find, as they simply follow links they find on previously downloaded pages. Their unpredictability makes spiders fun to write because they act as if they almost have minds of their own.
The best known spiders are those used by the major search engine companies (Google, Yahoo!, and Bing) to identify online content. And while spiders are synonymous with search engines for many people, the potential utility of spiders is much greater. You can write a spider that does anything any other webbot does, with the advantage of targeting the entire Internet. This creates a niche for developers that design specialized spiders that do very specific work. Here are some potential ideas for spider projects:
Discover sales of original copies of 1963 Spider-Man comics. Design your spider to email you with links to new findings or price reductions.
Periodically create an archive of your competitors’ websites.
Invite every Facebook member living in Cleveland, Ohio to be your friend.[54]
Send a text message when your spider finds jobs for Miami-based fashion photographers who speak Portuguese.
Validate that all the links on your website point to active web pages.
Perform a statistical analysis of noun usage across the Internet.
Search the Internet for musicians that recorded new versions of your favorite songs.
Purchase collectible Playboy magazines when your spider detects one priced substantially below the collectible price listed on Amazon.com.
This list could go on, but you get the idea. To a business, a well-purposed spider is like additional staff, easily justifying the one-time development cost.
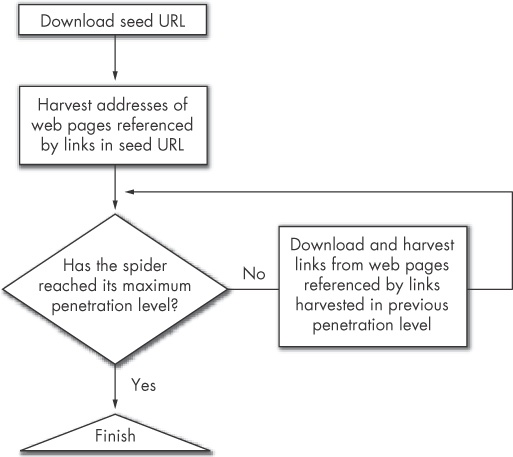
Spiders begin harvesting links at the seed URL, the address of the initial target web page. The spider uses these links as references to the next set of pages to process, and as it downloads each of those web pages, the spider harvests more links. The first page the spider downloads is known as the first penetration level. In each successive level of penetration, additional web pages are downloaded as directed by the links harvested in the previous level. The spider repeats this process until it reaches the maximum penetration level. Figure 17-1 shows a typical spider process.
[54] This is only listed here to show the potential for what spiders can do. Please don’t actually do this! Automated agents like this violate Facebook’s terms of use. Develop webbots responsibly.