Unlike basic authentication, in which login credentials are sent each time a page is downloaded, session authentication validates users once and creates a session value that represents that authentication. The session values (instead of the actual username and password) are passed to each subsequent page fetch to indicate that the user is authenticated. There are two basic methods for employing session authentication—with cookies and with query strings. These methods are nearly identical in execution and work equally well. You’re apt to encounter both forms of sessions as you gain experience writing webbots.
Cookies are small pieces of information that servers store on your hard drive. Cookies are important because they allow servers to identify unique users. With cookies, websites can remember preferences and browsing habits (within the domain), and use sessions to facilitate authentication.
Servers send cookies in HTTP headers. It is up to the client software to parse the cookie from the header and save the cookie values for later use. On subsequent fetches within the same domain, it is the client’s responsibility to send the cookies back to the server in the HTTP header of the page request. In our cookie authentication example, the cookie session can be viewed in the header returned by the server, as shown in Example 20-2.
Example 20-2. Cookies returned from the server in the HTTP header
HTTP/1.1 302 Found
Date: Fri, 09 Sep 2011 16:09:03 GMT
Server: Apache/2.0.58 (FreeBSD) mod_ssl/2.0.58 OpenSSL/0.9.8a PHP/5
X-Powered-By: PHP/5
Set-Cookie: authenticate=1157818143
Location: index0.php
Content-Length: 1837
Content-Type: text/html; charset=ISO-8859-1The line in bold typeface defines the name of the cookie and its value. In this case there is one cookie named authenticate with the value 1157818143.
Sometimes cookies have expiration dates, which is an indication that the server wants the client to write the cookie to a file on the hard drive. Other times, as in our example, no expiration date is specified. When no expiration date is specified, the server requests that the browser save the cookie in RAM and delete it when the browser closes. For security reasons, authentication cookies typically have no expiration date and are stored in RAM.
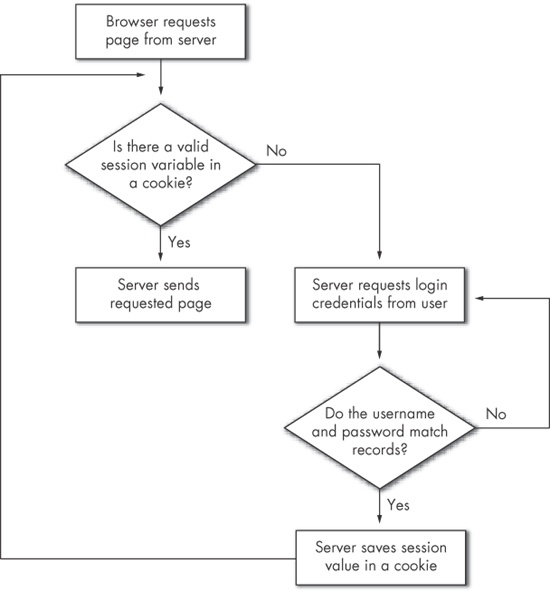
When authentication is done using a cookie, each successive page within the website examines the session cookie, and, based on internal rules, determines whether the web agent is authorized to download that web page. The actual value of the cookie session is of little importance to the webbot, as long as the value of the cookie session matches the value expected by the target webserver. In many cases, as in our example, the session also holds a time-out value that expires after a limited period. Figure 20-4 shows a typical cookie authentication session.
Unlike basic authentication, where the login criteria are sent in a generic (browser-dependent) form, cookie authentication uses custom forms, as shown in Figure 20-5.
Regardless of the authentication method used by your target web page, it’s vitally important to explore your target screens with a browser before writing self-authenticating webbots. This is especially true in this example, because your webbot must emulate the login form. You should take this time to explore the cookie authentication pages on this book’s website. View the source code for each page, and see how the code works. Use your browser to monitor the values of the cookies the web pages use. Now is also a good time to preview Chapter 21.
Figure 20-6 shows an example of the screens that lay beyond the login screen.

A webbot must do the following to authenticate itself to a website that uses cookie sessions:
Download the web page with the login form
Emulate the form that gathers the login credentials
Capture the cookie written by the server
Provide the session cookie to the server on each page request
The script in Example 20-3 first downloads the login page as a normal user would with a browser. As it emulates the form that sends the login credentials, it uses the CURLOPT_COOKIEFILE and CURLOPT_COOKIEJAR options to tell PHP/CURL where the cookies should be written and where to find the cookies that are read by the server. To most people (myself included), it seems redundant to have one set of outbound cookies and another set of inbound cookies. In every case I’ve seen, webbots use the same file to write and read cookies. It’s important to note that PHP/CURL will always save cookies to a file, even when the cookie has no expiration date. This presents some interesting problems, which are explained in Chapter 21.
Example 20-3. Auto-authentication with cookie sessions
<? # Define target page $target = "http://www.WebbotsSpidersScreenScrapers.com/cookie_authentication/index.php"; # Define the login form data $form_data="enter=Enter&username=webbot&password=sp1der3"; # Create the PHP/CURL session $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $target); // Define target site curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE); // Return page in string curl_setopt($ch, CURLOPT_COOKIEJAR, "cookies.txt"); // Tell PHP/CURL where to write cookies curl_setopt($ch, CURLOPT_COOKIEFILE, "cookies.txt"); // Tell PHP/CURL which cookies to send curl_setopt($ch, CURLOPT_POST, TRUE); curl_setopt($ch, CURLOPT_POSTFIELDS, $form_data); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, TRUE); // Follow redirects # Execute the PHP/CURL session and echo the downloaded page $page = curl_exec($ch); echo $page; # Close the PHP/CURL session curl_close($ch); ?>
Once the session cookie is written, your webbot should be able to download any authenticated page, as long as the cookie is presented to the website by your PHP/CURL session. Just one word of caution: Depending on your version of PHP/CURL, you may need to use a complete path when defining your cookie file.
Query string sessions are nearly identical to cookie sessions, the difference being that instead of storing the session value in a cookie, the session value is stored in the query string. Other than this difference, the process is identical to the protocol describing cookie session authentication (outlined in Figure 20-4). Query sessions create additional work for website developers, as the session value must be tacked on to all links and included in all form submissions. Yet some web developers (myself included) prefer query sessions, as some browsers and proxies restrict the use of cookies and make cookie sessions difficult to implement.
This is a good time to manually explore the test pages for query authentication on the website. Once you enter your username and password, you’ll notice that the authentication session value is visible in the URL as a GET value, as shown in Figure 20-7. However, this may not be the case in all situations, as the session value could also be in a POST value and invisible to the viewer.

Like the cookie session example, the query session example first emulates the login form. Then it parses the session value from the authenticated result and includes the session value in the query string of each page it requests. A script capable of downloading pages from the practice pages for query session authentication is shown in Example 20-4.
Example 20-4. Authenticating a webbot on a page using query sessions
<?
# Include libraries
include("LIB_http.php");
include("LIB_parse.php");
# Request the login page
$domain = "http://www.WebbotsSpidersScreenScrapers.com/";
$target = $domain."query_authentication";
$page_array = http_get($target, $ref="");
echo $page_array['FILE']; // Display the login page
sleep(2); // Include small delay between page fetches
echo "<hr>";
# Send the query authentication form
$login = $domain."query_authentication/index.php";
$data_array['enter'] = "Enter";
$data_array['username'] = "webbot";
$data_array['password'] = "sp1der3";
$page_array = http_post_form($login, $ref=$target, $data_array);
echo $page_array['FILE']; // Display first page after login page
sleep(2); // Include small delay between page fetches
echo "<hr>";
# Parse session variable
$session = return_between($page_array['FILE'], "session=", "\"", EXCL);
# Request subsequent pages using the session variable
$page2 = $target . "/index2.php?session=".$session;
$page_array = http_get($page2, $ref="");
echo $page_array['FILE']; // Display page two
?>