Proxies are of special interest to webbot developers because when used correctly, they allow your webbots not only to access websites anonymously but also to appear as if they are operating from another location.
This section describes why these functions are important to webbot developers and how proxies provide this functionality.
As you read in Chapter 26, a developer may have many reasons to cloak the identity of a webbot. Proxies protect the identity of your webbots by showing a different IP address to the websites you visit and by mixing your web traffic with that of many other web surfers, making it difficult to distinguish you from everyone else. For example, on the Internet your IP address identifies you so your web traffic can be accurately routed to and from your computer. If you connect directly to the Internet, without a proxy,[74] you will be the only person using a specific IP address, and all your communication can be easily traced directly back to you (see Figure 27-1).
As you access a website, your IP address serves two purposes. Primarily, your IP address tells the Internet how to route your network traffic. Your IP address also tells the website a little about you. The website might use your IP address to figure out where you’re located and customize web content, usually advertising, depending on the country or region. Additionally, websites routinely record your IP address, time of access, and the resources downloaded in an access log file. If the website is professionally maintained, the access log file will be examined for irregularities like page not found (404) errors and timeouts or to analyze where the site’s web traffic originates for marketing reasons.

For example, let’s say that you are at work and you connect to the Internet through your corporate gateway,[75] which has an IP address of 66.102.7.104. To see how much information can be derived from just an IP address, type this address into one of the many websites that perform IP address lookups.
As shown in Figure 27-2, our example IP address traces back to Google’s Silicon Valley campus, where a web surfer’s access to the Internet originated.

If this individual was directly connected to the Internet—without going through a corporate network gateway—that individual (not the corporation) would be in danger of being identified. Whether the web surfer is an individual or a corporation, the user’s identity is at least partially disclosed when the IP address is not protected.
One of the more interesting examples of people losing their online anonymity was when Virgil Griffith, a CalTech student, became curious about the identities of people making edits to controversial subjects on Wikipedia. His research lead to the creation of a webbot called Wikipedia Scanner,[76] which performed reverse IP address lookups on the people and organizations making Wikipedia edits. Wikipedia Scanner created—and more importantly published—a database of organizations that had made anonymous edits to their own Wikipedia pages to remove negative content. Wikipedia Scanner’s list of organizations included government agencies, corporations, and religious groups. Some organizations were further embarrassed when Wikipedia Scanner documented instances in which they attempted to hide the fact that they were performing a little “gray art” public relations.
Anonymity could have been maintained if, instead of directly accessing the website, the web surfer (or webbot) had gone through a proxy.
In the configuration in Figure 27-3, the website is able to identify only the IP address of the proxy server, not that of your computer. If an IP address lookup is performed, it will reveal information about the proxy server while your identity remains protected.
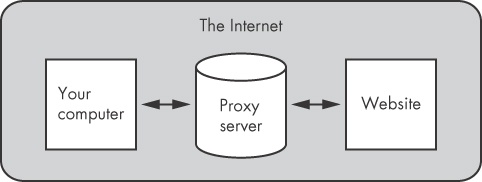
Please note that proxies like the one just mentioned provide reasonable anonymity—but not total anonymity. It is still possible to obtain (subpoena) access records from your gateway, the proxy server, and targeted website to piece together a trail of bits that lead back to you. It is also important to remember that if your data transmissions are not encrypted, a network sniffer could be used to identify you and your transmissions on the network. You’ll learn how to deal with these issues later in this chapter.
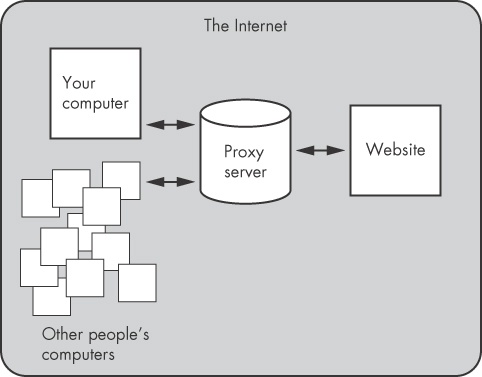
Adding to your anonymity, however, is that fact that proxy servers are typically not used by single web surfers but by many people at the same time. As shown in Figure 27-4, all network traffic accessing a website looks like it originates from the same place, the proxy server. In such a configuration, it is difficult to distinguish one person’s activity from that of anyone else. The more people who use the proxy server, the harder it is to trace activity to its origin, and the more anonymous the web surfers (or webbots) remain.
The other reason to use a proxy server is to virtually transport yourself to the same physical location as your proxy. For example, if you are in Denver but are using a proxy server in Seoul, South Korea, your network traffic will appear to originate from Asia, not from the United States. Using proxy servers in other countries is important when a website’s server gives location-dependent content. For example, as I write this, the video website Hulu.com will not allow people from outside the United States to access particular content. If, however, you are using a proxy server that is in the United States, you can view any of Hulu’s content from anywhere in the world, provided that your proxy is fast enough to facilitate video streaming.
Other reasons for using proxy servers to relocate you (or your webbot) to another virtual locale include the following:
To access websites that are blocked by national governments
To view local news when its content is censored
To access the native versions of foreign websites
To access foreign versions of domestic websites
[74] People generally don’t directly connect to the Internet but instead use a proxy known as a gateway proxy, which changes your IP address to that of your ISP. It may also provide some firewall protection and possibly image caching to speed browsing.
[75] Remember that a corporate gateway is itself a proxy that provides one unified path to, and from, the Internet for many employees.
[76] John Borland, “See Who’s Editing Wikipedia—Diebold, the CIA, a Campaign,” Wired, August 14, 2007, http://www.wired.com/politics/onlinerights/news/2007/08/wiki_tracker.