Chapter 14. Security
Making data accessible has been one of the key tenets of the Big Data movement, enabling huge strides in data analytics and bringing tangible benefits to business, academia, and the general public. At the same time, this data accessibility is held in tension with growing security and privacy demands. Internet-scale systems are exposed to an ever-changing collection of attacks, most of which target the data they hold. We’re all aware of high-profile breaches resulting in significant losses of data, including personal data, payment information, military intelligence, and corporate trade secrets. And these are just the breaches that have made the news.
One result of this heightened threat environment has been increased regulatory and compliance regimens in many regions and industries:
-
The European Union’s General Data Protection Regulation (GDPR), which took effect in 2018, specifies data protections and privacy for all EU citizens, including limitations on transfer of personal data outside the EU. The California Consumer Privacy Act (CCPA), effective January 2020, is a similar provision reflecting trends toward data privacy in the United States.
-
The US Health Insurance Portability and Accountability Act (HIPAA) of 1996 prescribes controls for the protection and handling of individual health information.
-
The Payment Card Industry Data Security Standard (PCI DSS), first released in 2006, is an industry-defined set of standards for the secure handling of payment card data.
-
The US Sarbanes-Oxley Act of 2002 regulates corporate auditing and reporting, including data retention, protection, and auditing.
These are just a few examples of regulatory and compliance standards. Even if none of these examples apply directly to your application, chances are there are regulatory guidelines of some kind that impact your system.
All of this publicity and regulatory rigor has resulted in a much increased level of visibility on enterprise application security in general, and more pertinently for our discussions, on NoSQL database security. Although a database is by definition only a part of an application, it certainly forms a vital part of the attack surface of the application, because it serves as the repository of the application’s data.
Is Security a Weakness of NoSQL?
A 2012 Information Week report took the NoSQL community to task for what the authors argue is a sense of complacency, arguing that NoSQL databases fail to prioritize security. While the security of many NoSQL technologies, including Cassandra, has improved significantly since then, the paper serves as a healthy reminder of our responsibilities and the need for continued vigilance.
Fortunately, the Cassandra community has demonstrated a commitment to continuous improvement in security. Cassandra’s security features include authentication, role-based authorization, encryption, and audit logging, as shown in Figure 14-1.
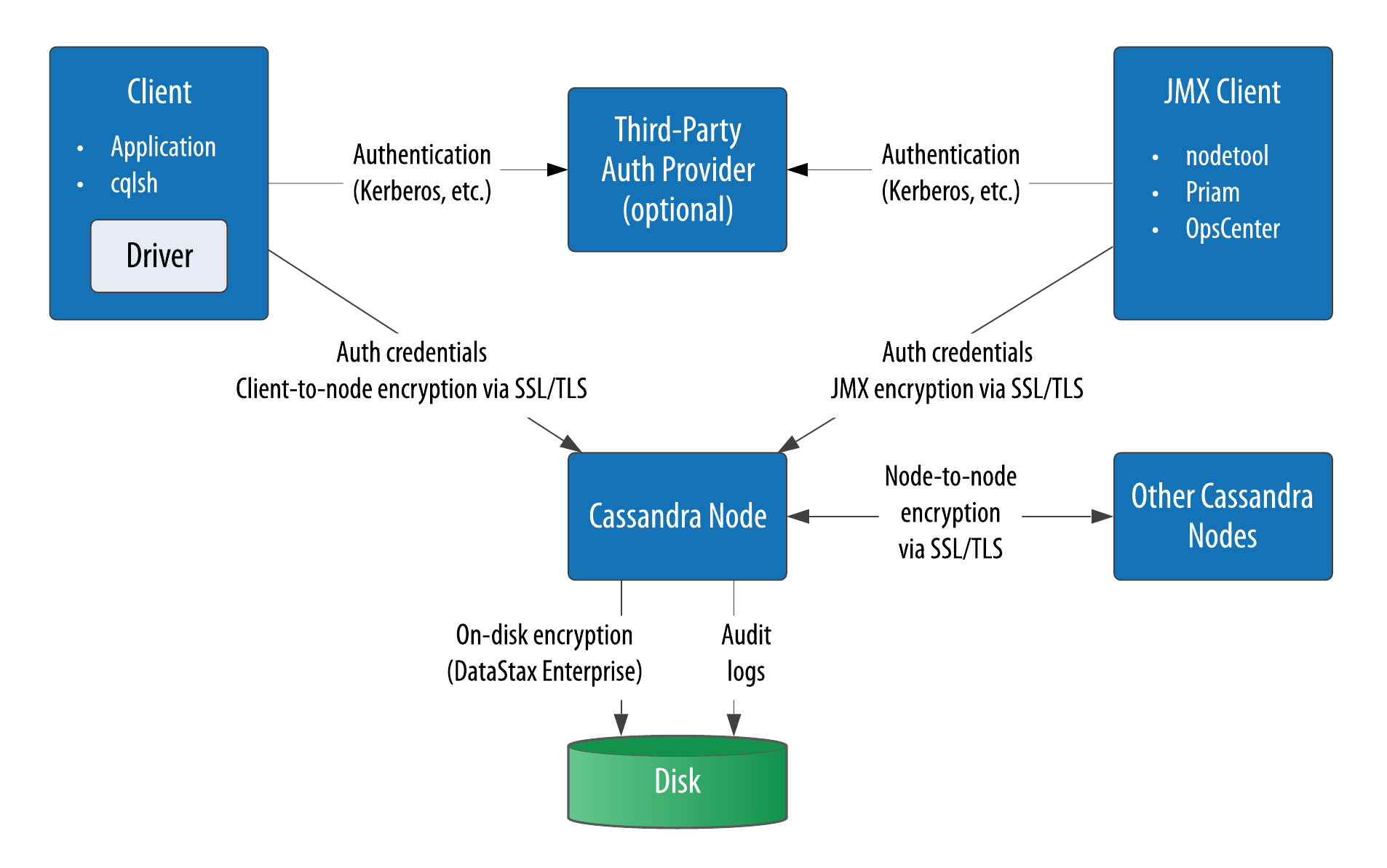
Figure 14-1. Cassandra’s security features
In this chapter, we’ll explore these security features and how to access them via cqlsh and other clients, with some thoughts along the way for how Cassandra fits into a broader application security strategy that protects against attack vectors such as unauthorized access and eavesdropping.
Authentication and Authorization
Let’s take a look at Cassandra’s authentication and authorization features.
Password Authenticator
By default, Cassandra allows any client on your network to connect to your cluster. This does not mean that no security is set up out of the box, but rather that Cassandra is configured to use an authentication mechanism that allows all clients, without requiring that they provide credentials. The security mechanism is pluggable, which means that you can easily swap out one authentication method for another, or write your own.
The authenticator that’s plugged in by default is the org.apache.cassandra.auth.AllowAllAuthenticator. If you want to force clients to provide credentials, another alternative ships with Cassandra, the org.apache.cassandra.auth.PasswordAuthenticator. In this section, you’ll learn how to use this second authenticator.
Configuring the authenticator
First, shut down your cluster so that you can change the security configuration. Open the cassandra.yaml file and search for “authenticator.” You’ll find the following line:
authenticator: AllowAllAuthenticator
Change this line to use the PasswordAuthenticator:
authenticator: PasswordAuthenticator
You’ll want to repeat this action on each node in the cluster. If you’re using Cassandra 2.2 or later, you’ll see a note in the cassandra.yaml file indicating that the CassandraRoleManager must be used if the PasswordAuthenticator is used. The CassandraRoleManager is part of Cassandra’s authorization capability, which we’ll discuss in more depth momentarily.
Additional authentication providers
You can provide your own method of authenticating to Cassandra, such as a Kerberos ticket, or store passwords in a different location, such as an LDAP directory. In order to create your own authentication scheme, simply implement the IAuthenticator interface. DataStax Enterprise Edition provides additional authentication integrations, and Instaclustr has made its LDAP and Kerberos authenticators open source.
Cassandra also supports pluggable authentication between nodes via the IInternodeAuthenticator interface. The default implementation AllowAllInternodeAuthenticator performs no authentication, but you are free to implement your own authenticator as a way to protect a node from making connections to untrusted nodes.
Adding users
Now, save the cassandra.yaml file, restart your node or cluster, and try logging in with cqlsh. Immediately you run into a problem:
$ bin/cqlsh
Connection error: ('Unable to connect to any servers',
{'127.0.0.1': AuthenticationFailed('Remote end requires
authentication.',)})
Prior versions of Cassandra might allow login, but would not allow any access. Versions of Cassandra 2.2 and later require a password even to log in. Cassandra comes with a default user known as cassandra, with “cassandra” as the password. Let’s try logging in again with these credentials:
$ bin/cqlsh -u cassandra -p cassandra Connected to reservation_cluster at 127.0.0.1:9042. [cqlsh 5.0.1 | Cassandra 4.0-alpha3 | CQL spec 3.4.5 | Native protocol v4] Use HELP for help. cassandra@cqlsh>
Once you’ve logged in successfully, you’ll see that the prompt indicates that you are logged in as the user cassandra. One of the first things you’ll want to do to begin securing your installation is to change the password for this very important user. We’ve used a random password generator here as an example:
cassandra@cqlsh> ALTER USER cassandra WITH PASSWORD 'Kxl0*nGpB6';
Make sure to store the cassandra user’s password in a secure location.
Don’t Forget to Clear cqlsh History
Remember that cqlsh stores a history of your commands under your home directory at .cassandra/cqlsh_history, so the full clear-text password you provide is preserved there. You’ll want to remove the command from the history after setting a password.
For a microservice-style application, as we’ve used for the examples in this book, you might want to create a user account specifically to give the service access to a single keyspace. To create this new user, you’ll start by specifying a username and password. The password is optional, but of course recommended:
cassandra@cqlsh> CREATE USER reservation_service WITH PASSWORD 'i6XJsj!k#9';
The CREATE USER command also supports the IF NOT EXISTS syntax to avoid errors on multiple attempts to create a user. Now, check to see that you’ve created the user successfully by using the LIST USERS command:
cassandra@cqlsh> LIST USERS ;
name | super | datacenters
---------------------+-------+-------------
cassandra | True | ALL
reservation_service | False | ALL
(2 rows)
You’ll note that the user cassandra is listed as being a superuser. The superuser designates the ability to perform all supported actions. Only a superuser can create other users. You’ve already changed the password for the built-in user cassandra. You may also want to create another superuser and remove the cassandra account’s superuser status for additional security. This is considered a best practice for securing Cassandra.
Configuring Automatic Login
To avoid having to enter a username and password on every login to cqlsh, create a file in your home directory called .cqlshrc. You can enter login credentials with lines like this:
; Sample ~/.cqlshrc file. [authentication] username = reservation_service password = i6XJsj!k#9
Obviously, you’ll want to make sure this file is secure so that only authorized users (such as your account) have access to the password.
Other operations on users include the ALTER USER command, which allows you to change a user’s password or superuser status, as well as the DROP USER command, which you use to delete a user. A nonsuperuser can alter their own password using the ALTER USER command, but all other operations require superuser status.
You can use the LOGIN command to switch users within cqlsh without restart:
cassandra@cqlsh> login reservation_service 'i6XJsj!k#9' reservation_service@cqlsh>
You may choose to omit the password from the command, in which case cqlsh will prompt you to enter the password. It’s preferable to enter passwords at the shell prompt, rather than the command line, as cqlsh saves all of your commands to a file called .cassandra/cqlsh_history under your home directory, including any passwords you include on the command line when using the LOGIN command.
Authenticating via the DataStax Java Driver
Of course, your applications don’t use cqlsh to access Cassandra, so it will be helpful to learn how to authenticate to the client using the DataStax client drivers. Building on the Reservation Service from Chapter 8, use the CqlSessionBuilder.withCredentials() operation to provide the username and password when you construct your Cluster instance:
CqlSession = CqlSession.builder().addContactPoint("127.0.0.1").
withAuthCredentials("reservation_service", "i6XJsj!k#9").
build();
The login syntax is quite similar for other DataStax drivers. This is a simple example that hardcodes the login credentials, but you could just as easily use values provided by an application user or stored in a secure configuration file:
datastax-java-driver {
advanced.auth-provider {
username = reservation_service
password = i6XJsj!k#9
}
If you’ve configured an authenticator on your nodes other than the default, you’ll also need to configure a compatible authenticator in your clients. Client authentication providers implement the com.datastax.oss.driver.api.core.auth.AuthProvider interface. The default implementation is the PlainTextAuthProvider class, an instance of which is registered when you call the CqlSessionBuilder.withCredentials() operation. You can override the provider when constructing your Cluster object by calling the CqlSessionBuilder.withAuthProvider() operation.
Using CassandraAuthorizer
It is certainly possible to only use authentication, although in most cases you’ll want to make use of Cassandra’s authorization capabilities as well. Cassandra’s out-of-the-box configuration authorizes all clients to access all keyspaces and tables in your cluster. As with authentication, the authorization mechanism is pluggable.
The authorizer that’s plugged in by default is the org.apache.cassandra.auth.AllowAllAuthorizer. To enable Cassandra’s role-based access control, you’ll need to configure the org.apache.cassandra.auth.CassandraAuthorizer.
Again, you’ll shut down the cluster to change the authorizer. In the cassandra.yaml file, search for “authorizer.” You’ll find the line:
authorizer: AllowAllAuthorizer
and change it to:
authorizer: CassandraAuthorizer
Once you restart the cluster, you can log in to cqlsh again as your regular user to see what you can access, making use of the reservation data stored in your cluster in previous chapters:
$ cqlsh -u reservation_service –p 'i6XJsj!k#9' ... reservation_service@cqlsh> DESCRIBE KEYSPACES; system_schema system system_traces system_virtual_schema system_auth system_distributed reservation system_views reservation_service@cqlsh> USE reservation; reservation_service@cqlsh:reservation> DESCRIBE TABLES; reservations_by_confirmation reservations_by_hotel_date reservations_by_guest reservation_service@cqlsh:reservation> SELECT * FROM reservations_by_confirmation; Unauthorized: Error from server: code=2100 [Unauthorized] message="User reservation_service has no SELECT permission on <table reservation.reservations_by_confirmation> or any of its parents"
As you can see, you are able to navigate through cqlsh to view the names of the various keyspaces and tables, but once you attempt to access data, you are denied access.
To fix this, you’ll need to switch back into a superuser role and grant your user some permissions. For example, let’s allow the user to access tables in the reservations keyspace:
cassandra@cqlsh> GRANT SELECT ON KEYSPACE reservation TO reservation_service; cassandra@cqlsh> GRANT MODIFY ON KEYSPACE reservation TO reservation_service;
This allows your Reservation Service account to read and write data, but no other operations. You could also have granted SELECT ON TABLE or MODIFY ON TABLE permissions to allow access to a specific table. Now, if you log back in as your regular user and run the SELECT command again, you’ll see the data you stored previously.
Getting Help with Permissions
The cqlsh commands HELP GRANT and HELP PERMISSIONS provide additional information on configuring permissions such as:
CREATE,ALTER,DROP-
These permissions allow users to
CREATE,ALTER, andDROPkeyspaces, tables, functions and roles. SELECT-
These permissions allow the ability to
SELECTdata from tables and keyspaces, as well as the ability to callget()operations on MBeans. MODIFY-
These permissions group the
INSERT,UPDATE,DELETEandTRUNCATEcommands for modifying tables, as well as the ability to callset()operations on MBeans. AUTHORIZE-
These permissions deal with the ability to
GRANTandREVOKEother permissions. These are commonly used to create users and roles that have administrative privileges over some or all keyspaces, but not the ability to manage access of other accounts. DESCRIBE-
Since it is possible for the database schema itself to contain sensitive information, these permissions restrict access to the various CQL
DESCRIBEoperations. EXECUTE-
These permissions control the ability to execute functions and MBean actions.
The Cassandra Query Language specification contains a detailed listing of grantable permissions by CQL command and the resources to which they apply, which include keyspaces, tables, MBeans, functions (introduced in Chapter 15), and roles (which we discuss next).
Role-Based Access Control
In a large Cassandra cluster, there might be a lot of different keyspaces and tables, with many different potential users. It would be difficult to keep track of the permissions assigned to them all. While it’s tempting to share login information with multiple support staff, there is a better way.
Starting with the 2.2 release, Cassandra provides role-based access control (RBAC). This allows you to create roles and assign permissions to these roles. Roles can be granted to individual users in any combination. Roles can themselves contain other roles.
It’s a good practice to create separate roles in order to keep permissions to the minimum required for each user. For example, you might also wish to create a reservation_maintenance role that has permissions to modify the reservation keyspace and its tables, but not all of the power of the cassandra administrator role:
cassandra@cqlsh> CREATE ROLE reservation_maintenance; cassandra@cqlsh> GRANT ALL ON KEYSPACE reservation TO reservation_maintenance;
You’ve created a simple role here to which you can’t log in to directly. You can also create roles that have superuser privileges, and roles that support login and take a password. Now you could apply this role to some user account jeff:
cassandra@cqlsh> GRANT reservation_maintenance TO jeff;
Roles are additive in Cassandra, meaning that if any of the roles granted to a user have a specific permission granted, then that permission is granted to the user.
Behind the scenes, Cassandra stores users and roles in the system_auth keyspace. If you’ve configured authorization for your cluster, only administrative users can access this keyspace, so let’s examine its contents in cqlsh using the administrator login:
cassandra@cqlsh> DESCRIBE KEYSPACE system_auth
CREATE KEYSPACE system_auth WITH replication = {'class': 'SimpleStrategy',
'replication_factor': '1'} AND durable_writes = true;
...
We’ve truncated the output, but if you run this command, you’ll see the tables that store the roles, their permissions, and role assignments. There is actually no separate concept of a user at the database level—Cassandra uses the role concept to track both users and roles.
Changing the system_auth Replication Factor
The system_auth keyspace is configured out of the box to use the SimpleStrategy with a replication factor of one.
This means that by default, any users, roles, and permissions you configure will not be distributed across the cluster until you reconfigure the replication strategy of the system_auth keyspace to match your cluster topology and run repair on the system_auth keyspace.
Encryption
Protecting user privacy is an important aspect of many systems, especially those that handle health, financial, and other personal data. Typically you protect privacy by encrypting data, so that if the data is intercepted, it is unusable to an attacker who does not have the encryption key. Data can be encrypted as it moves around the public internet and within internal systems, also known as data in motion, or it can be encrypted on systems where it is persisted (known as data at rest).
Starting with the 2.2.4 release, Cassandra provides the option to secure data in motion via encryption between clients and servers (nodes), and encryption between nodes using Secure Sockets Layer (SSL). As of Cassandra 4.0, encryption of datafiles (data at rest) is not supported; however, it is offered by DataStax Enterprise releases of Cassandra and can also be achieved by using storage options that support full-disk encryption, such as encrypted EBS volumes on AWS.
Datafile Encryption Roadmap
There are several Cassandra Jira requests targeted for the 3.X release series that provide encryption features. For example, the following were added in the 3.4 release:
- CASSANDRA-11040
-
Encryption of hints
- CASSANDRA-6018
-
Encryption of commit logs
See also CASSANDRA-9633 on encryption of SSTables, and CASSANDRA-7922, which serves as an umbrella ticket for file-level encryption requests.
Before you start configuring nodes to enable encryption, there is some preparation work to do to create security certificates that are a key part of the machinery.
SSL, TLS, and Certificates
Cassandra uses Transport Layer Security (TLS) for encrypting data in motion. TLS is often referenced by the name of its predecessor, Secure Sockets Layer (SSL). TLS is a cryptographic protocol for securing communications between computers to prevent eavesdropping and tampering. More specifically, TLS makes use of public key cryptography (also known as asymmetric cryptography), in which a pair of keys is used to encrypt and decrypt messages between two endpoints: a client and a server.
Prior to establishing a connection, each endpoint must possess a certificate containing a public and private key pair. Public keys are exchanged with communication partners, while private keys are not shared with anyone.
To establish a connection, the client sends a request to the server indicating the cipher suites it supports. The server selects a cipher suite from the list that it also supports and replies with a certificate that contains its public key. The client validates the server’s public key. The server may also require that the client provide its public key in order to perform two-way validation. The client uses the server’s public key to encrypt a message to the server in order to negotiate a session key. The session key is a symmetric key generated by the selected cipher suite that is used for subsequent communications.
For most applications of public key cryptography, the certificates are obtained from a certificate authority, and this is the recommended practice for production Cassandra deployments as well. However, for small development clusters, you may find it useful to create your own certificates.
Generating Certificates for Development Clusters
Let’s examine how to create your own certificates for development clusters. The following command gives an example of how you can use the -genkey switch on the JDK’s keytool to generate a public/private key pair (substituting different keystore and key passwords and distinguished name when you run this yourself):
$ keytool -genkey -keyalg RSA -alias node1 -keystore node1.keystore -storepass cassandra -keypass cassandra -dname "CN=192.168.86.29, OU=None, O=None, L=Scottsdale, C=USA" Warning: The JKS keystore uses a proprietary format. It is recommended to migrate to PKCS12 which is an industry standard format using "keytool -importkeystore -srckeystore node1.keystore -destkeystore node1.keystore -deststoretype pkcs12".
This command generates the key pair for one of your Cassandra nodes, node1, and places the key pair in a keystore file called node1.keystore. You provide passwords for the keystore and for the key pair, and a distinguished name specified according to the Lightweight Directory Access Prototol (LDAP) format. It’s recommended to use the IP address of the host for the common name (CN).
The example command shown here provides the bare minimum set of attributes for generating a key. You could also provide fewer attributes on the command line and allow keytool to prompt you for the remaining ones, which is more secure for entering passwords.
PKCS12 and the Java Cryptography Extension
You probably noticed the warning message in this output, which indicates a preference for using the the industry standard PKCS12 (.pfx) format over the Java keystore (JKS) format. When creating certificates for development clusters, the Java keystore (JKS) format is typically sufficient. However, if you’re planning to use cqlsh with the development cluster or are developing clients in languages that don’t support the JKS format, you’ll want to import your server public keys into a PKCS12-compatible truststore for client use.
Once you have a certificate for each node, export the public key of each certificate to a separate file:
$ keytool -export -alias node1 -file node1.cer -keystore node1.keystore Enter keystore password: Certificate stored in file <node1.cer>
You identify the key you want to export from the keystore via the same alias as before, and provide the name of the output file. keytool prompts you for the keystore password and generates the certificate file. Repeat this procedure to generate keys for each node and client.
Then, configure options for a file similar to the keystore called the truststore. You’ll generate a truststore for each node containing the public keys of all the other nodes in the cluster. For example, to add the certificate for node1 to the keystore for node2, you would use the command:
$ keytool -import -v -trustcacerts -alias node1 -file node1.cer -keystore node2.truststore Enter keystore password: Re-enter new password: Owner: CN=192.168.86.29, OU=None, O=None, L=Scottsdale, C=USA Issuer: CN=192.168.86.29, OU=None, O=None, L=Scottsdale, C=USA Serial number: 3cc50090 Valid from: Mon Dec 16 18:08:57 MST 2019 until: Sun Mar 15 18:08:57 MST 2020 Certificate fingerprints: MD5: 3E:1A:1B:43:50:D9:E5:5C:7A:DA:AA:4E:9D:B9:9E:2A SHA1: B4:58:21:73:43:8F:08:3C:D5:D6:D7:22:D9:32:04:7C:8F:E2:A6:C9 SHA256: 00:A4:64:E9:C9:CA:1E:69:18:08:38:6D:8B:5B:48:6F:4C:9D:DB:62:17: 8C:79:CC:ED:24:23:B8:81:04:41:59 Signature algorithm name: SHA256withRSA Subject Public Key Algorithm: 2048-bit RSA key Version: 3 Extensions: #1: ObjectId: 2.5.29.14 Criticality=false SubjectKeyIdentifier [ KeyIdentifier [ 0000: 0E 95 97 B1 69 CF 57 50 C1 98 87 F4 06 28 A7 C1 ....i.WP.....(.. 0010: 51 AC 35 18 Q.5. ] ] Trust this certificate? [no]: y Certificate was added to keystore [Storing truststore.node1]
keytool prompts you to enter a password for the new truststore and then prints out summary information about the key you’re importing.
Once you have the keystore and truststore files for each node, deploy them to the nodes using remote copy or secure copy protocol (SCP) tools as per your environment. If you also intend to require certificates for your clients, the process of generating keystores and truststores is quite similar, and of course you’ll want to add the client public certificates to your server truststores as well.
For more detailed instructions on generating your own certificates using keytool, see the DataStax documentation.
Generating Certificates for Production Clusters
For managing production clusters (or even larger development clusters), it’s recommended to use a certificate authority (CA) to generate your certificates. The DataStax documentation provides detailed instructions for creating a self-signed root CA using openssl and using that to sign the certificates for your nodes (and clients, if desired).
The procedure for creating distinguished names is similar to that described earlier, although you may wish to use the fully qualified domain name (FQDN) of the node or client as the CN, and the IP address as a subject alternative name (SAN), so that the certificate protects the IP address in addition to the domain name.
Whether you are using a self-signed root CA or a publicly trusted CA, you’ll need to ensure there is a truststore for each node that provides the chain of trust for the CA. If you’re using a public CA, it’s likely that the CA’s root certificate will be present in your JDK’s default truststore. If you’re using a self-signed CA, a common practice is to use the package manager for your operating system to install the CA on your nodes as part of your infrastructure deployment.
As with development clusters, you’ll want to ensure you use a secure method to install certificates on your nodes and clients. Whatever scheme you choose to manage your certificates, the overall security of your Cassandra cluster depends on limiting access to the computers on which your nodes are running so that the configuration can’t be tampered with.
Node-to-Node Encryption
Once you have keys for each of your Cassandra nodes, you are ready to enable node-to-node configuration by setting the server_encryption_options in the cassandra.yaml file:
server_encryption_options:
enabled: false
optional: false
enable_legacy_ssl_storage_port: false
internode_encryption: none
keystore: conf/.keystore
keystore_password: cassandra
truststore: conf/.truststore
truststore_password: cassandra
# protocol: TLS
# store_type: JKS
# cipher_suites: [TLS_RSA_WITH_AES_128_CBC_SHA,...]
# require_client_auth: false
# require_endpoint_verification: false
First, set the enabled option to true. You can also set the optional option to true to indicate that both encrypted and unencrypted connections should be allowed on the storage port; otherwise only encrypted connections will be allowed.
Deprecated SSL Storage Port
Versions of Cassandra prior to 4.0 used a separate ssl_storage_port for encrypted communications between nodes. Since Cassandra 4.0 and later may be configured to allow both encrypted and unencrypted connections on the storage port, the secure port is only needed in the context of upgrading a 3.x cluster to 4.0. In this case, the ssl_storage_port should be configured and enable_legacy_ssl_storage_port set to true.
Next, set the internode_encryption option. You can select all to encrypt all internode communications, dc to encrypt between data centers, and rack to encrypt between racks. Provide the password for the keystore and set its path, or place the keystore file you created earlier at the default location in the conf directory.
The cassandra.yaml file also presents you with a series of “advanced” options to configure the cryptography. These options provide you with the ability to select from Java’s menu of supported cryptographic algorithms and libraries. For example, for Java 8, you can find the descriptions of these items in this Oracle documentation.
The defaults will be sufficient in most cases, but it’s helpful to understand what options are available. You can see how these options are used in Cassandra by examining the class org.apache.cassandra.security.SSLFactory, which Cassandra uses to generate secure sockets.
The protocol option specifies the protocol suite that will be used to instantiate a javax.net.ssl.SSLContext. As of Java 8, the supported values include SSLv2, SSLv3, TLSv1, TLSv1.1, or TLSv1.2. You can also use the shortcuts SSL or TLS to get the latest supported version of either suite.
The store_type option specifies the setting provided to obtain an instance of java.security.KeyStore. The default value JKS indicates a keystore built by keytool, but you can also use PKCS12 keystores as discussed previously.
The cipher_suites option is a list of encryption algorithms in order of preference. The cipher suite to use is determined by the client and server in negotiating their connection, based on the priority specified in this list. The same technique is used by your browser in negotiating with web servers when you visit websites using https: URLs. As demonstrated by the defaults, you’ll typically want to prefer stronger cipher suites by placing them at the front of the list.
You can also enable two-way certificate authentication between nodes, in which the server node authenticates the client node, by setting require_client_auth to true. If require_endpoint_verification is set to true, Cassandra will verify whether the client node that is connecting matches the name in its certificate.
Client-to-Node Encryption
Client-to-node encryption protects data as it moves from client machines to nodes in the cluster. The client_encryption_options in the cassandra.yaml file are quite similar to the node-to-node options:
client_encryption_options:
enabled: false
optional: false
keystore: conf/.keystore
keystore_password: cassandra
# require_client_auth: false
# truststore: conf/.truststore
# truststore_password: cassandra
# More advanced defaults below:
# protocol: TLS
# store_type: JKS
# cipher_suites: [TLS_RSA_WITH_AES_128_CBC_SHA,...]
The enabled option serves as the on/off switch for client-to-node encryption, while optional indicates whether clients may choose either encrypted or unencrypted connections.
The keystore and truststore settings will typically be the same as those in the server_encryption_options, although it is possible to have separate files for the client options.
Note that setting require_client_auth for clients means that the truststore for each node will need to have a public key for each client that will be using an encrypted connection.
The cipher_suites option works the same as for the server options. If you don’t have total control over your clients, you may wish to remove weaker suites entirely to eliminate the threat of a downgrade attack.
JMX Security
You learned how Cassandra exposes a monitoring and management capability via Java Management Extensions (JMX) in Chapter 11. In this section, you’ll learn how to make that management interface secure, and what security-related options you can configure using JMX.
Securing JMX Access
By default, Cassandra only makes JMX accessible from the local host. This is fine for situations where you have direct machine access, but if you’re running a large cluster, it may not be practical to log in to the machine hosting each node in order to access them using tools such as nodetool.
For this reason, Cassandra provides the ability to expose its JMX interface for remote access. Of course, it would be a waste to invest your efforts in securing access to Cassandra via the native transport, but leave a major attack surface like JMX vulnerable. So let’s see how to enable remote JMX access in a way that is secure.
First, stop your node or cluster and edit the conf/cassandra-env.sh file (or cassandra-env.ps1 on Windows). Look for the setting LOCAL_JMX, and change it as follows:
LOCAL_JMX=no
Setting this value to anything other than “yes” causes several additional properties to be set, including properties that enable the JMX port to be accessed remotely:
JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT" JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
There are also properties that configure remote authentication for JMX:
JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.authenticate=true" JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.password.file= /etc/cassandra/jmxremote.password"
The location of the jmxremote.password file is entirely up to you. You’ll configure the jmxremote.password file in just a minute, but first finish up your configuration edits by saving the cassandra-env.sh file.
Your JRE installation comes with a template jmxremote.password file under the jre/lib/management directory. Typically you will find installed JREs under C:\Program Files\Java on Windows, /Library/Java/JavaVirtualMachines on macOS, and /usr/lib/java on Linux. Copy the jmxremote.password file to the location you set previously in cassandra-env.sh and edit the file, adding a line with your administrator username and password, as shown in bold here:
...
# monitorRole QED
# controlRole R&D
cassandra cassandra
You’ll also edit the jmxremote.access file under the jre/lib/management directory to add read and write MBean access for the administrative user:
monitorRole readonly
controlRole readwrite \
create javax.management.monitor.*,javax.management.timer.* \
unregister
cassandra readwrite
Configure the permissions on the jmxremote.password and jmxremote.access. Ideally, the account under which you run Cassandra should have read-only access to this file, and other nonadministrative users should have no access.
Finally, restart Cassandra and test that secure access is configured correctly by calling nodetool:
$ nodetool status -u cassandra -pw cassandra
You can also configure SSL for your JMX connection. To do this, you’ll need to add a few more JVM options in the cassandra-env file:
JVM_OPTS="${JVM_OPTS} -Dcom.sun.management.jmxremote.ssl=true"
JVM_OPTS="${JVM_OPTS} -Djavax.net.ssl.keyStore=conf/node1.keystore"
JVM_OPTS="${JVM_OPTS} -Djavax.net.ssl.keyStorePassword=cassandra"
JVM_OPTS="${JVM_OPTS} -Djavax.net.ssl.trustStore=conf/node1.truststore"
JVM_OPTS="${JVM_OPTS} -Djavax.net.ssl.trustStorePassword=cassandra"
JVM_OPTS="${JVM_OPTS} -Dcom.sun.management.jmxremote.ssl.need.client.auth=true"
Security MBeans
You learned about the various MBeans exposed by Cassandra in Chapter 11. For understandable reasons, not many security-related configuration parameters are accessible remotely via JMX, but there are some capabilities exposed via the org.apache.cassandra.auth domain.
Authentication cache MBean
By default, Cassandra caches information about permissions, roles, and login credentials as a performance optimization, since it could be quite expensive to retrieve these values from internal tables or external sources on each call.
For example, the org.apache.auth.PermissionsCache caches permissions for the duration set in the cassandra.yaml file by the permissions_validity_in_ms property. This value defaults to 2,000 (2 seconds), and you can disable the cache entirely by setting the value to 0. There is also a permissions_update_interval_in_ms, which defaults to the same value as permissions_validity_in_ms. Setting a lower value configures an interval after which accessing a permission will trigger an asynchronous reload of the latest value.
Similarly, the RolesCache manages a cache of roles assigned to each user. It is configured by the roles_validity_in_ms and roles_update_interval_in_ms properties.
The CredentialsCache caches the password for each user or role so that they don’t have to be reread from the PasswordAuthenticator. Since the CredentialsCache is tied to Cassandra’s internal PasswordAuthenticator, it will not function if another implementation is used. It is configured by the credentials_validity_in_ms and credentials_update_interval_in_ms properties.
The AuthCacheMBean allows you to override the configured cache validity and refresh values, and also provides a command to invalidate all of the permissions in the cache. This could be a useful operation if you need to change permissions in your cluster and need them to take effect immediately.
Unified Authentication Caching
In releases prior to Cassandra 3.4, the permissions cache and roles cache were separate concepts with separate MBeans. In the Cassandra 3.4 release, the class AuthCache was introduced as a base class for all authentication-related classes, and the PermissionsCacheMBean and RolesCacheMBean were deprecated and replaced by the AuthCacheMBean.
Audit Logging
Once you’ve configured security settings such as access control, you may need to verify that they’ve been implemented correctly, perhaps as part of a compliance regime. Fortunately, Cassandra 4.0 added an audit logging feature that you can use to satisfy these requirements. This logging capability is to be as lightweight as possible in order to minimize the impact on read and write latency without compromising the strict accuracy requirements of compliance laws.
Audit logging shares some of its implementation with full query logging (see “Full Query Logging”), also included in the 4.0 release. The code for both features is found in the org.apache.cassandra.audit package. The IAuditLogger interface describes a pluggable interface for audit loggers. Available implementations include the FileAuditLogger, which generates human-readable messages, and the BinAuditLogger, which writes in a compact binary format that can be read using the fqltool introduced in Chapter 11. The AuditLogManager provides a central location for managing registered implementations of the IAuditLogger interface. The AuditLogManager.log() operation exposes a single API for logging used by various portions of the Cassandra codebase that perform writes, reads, schema management, and other operations.
While full query logging and audit logging share some implementation, the concerns they address are distinct. While the full query logger focuses on the syntax of SELECT, INSERT, UPDATE, and DELETE queries, it ignores other CQL queries and does not include success or failure indications, or information about the source of queries.
Audit logging settings are found in the cassandra.yaml file:
audit_logging_options:
enabled: false
logger: BinAuditLogger
# audit_logs_dir:
# included_keyspaces:
# excluded_keyspaces: system, system_schema, system_virtual_schema
# included_categories:
# excluded_categories:
# included_users:
# excluded_users:
# roll_cycle: HOURLY
# block: true
# max_queue_weight: 268435456 # 256 MiB
# max_log_size: 17179869184 # 16 GiB
## archive command is "/path/to/script.sh %path" where %path is replaced
with the file being rolled:
# archive_command:
# max_archive_retries: 10
To enable audit logging, set the enabled option to true and select the desired logger. You can include (whitelist) or exclude (blacklist) specific keyspaces or users in order to narrow the focus of audit logging.
Audit log messages are grouped into categories that can also be included or excluded:
QUERY-
Messages generated for CQL
SELECToperations DML(or data manipulation language)-
Messages for CQL
UPDATE,DELETE, andBATCHoperations DDL(or data definition language)-
Messages for operations on keyspaces, tables, user-defined types, triggers, user-defined functions, and aggregates. These latter items will be discussed in Chapter 15
PREPARE-
Messages concerning prepared statements (as you learned in Chapter 8)
DCL(or data control language)-
Messages generated for operations related to users, roles, and permissions
AUTH-
Messages tracking login success, failure, and unauthorized access attempts
ERROR-
Messages for logging CQL request failure
OTHER-
The final category, currently used only to track the CQL
USEcommand
In addition to the configuration in cassandra.yaml, you can also enable and disable audit logging through nodetool using the enableauditlog and disableauditlog operations. The enableauditlog also allows you to update options on specific audit loggers such as the included or excluded categories, keyspaces, and users.
If you’re using the BinAuditLogger, binary audit logs will be written to files in the specified directory, which defaults to the logs directory under the Cassandra installation. The options for audit file rolling and archiving are similar to those described for full query logging in Chapter 11.
As an example, you could configure the use of the FileQueryLogger to log operations on a node related to the reservation keyspace:
audit_logging_options:
enabled: true
logger: FileAuditLogger
included_keyspaces: reservation
included_categories: QUERY,DML
Then restart the node. After inserting some data, you will see entries in the logs/system.log file, like this:
INFO [Native-Transport-Requests-1] 2019-12-17 19:57:33,649 FileAuditLogger.java:49 - user:reservation_service| host:127.0.0.2:7000|source:/127.0.0.2|port:52614| timestamp:1576637853616|type:SELECT|category:QUERY| ks:reservation|scope:reservations_by_hotel_date| operation:SELECT * FROM reservations_by_hotel_date
As you can see, audit logging statements include not only the actual text of the CQL statement but also the timestamp, identity of the user, and IP address of the source that made the query. You can direct audit logging statements to their own dedicated file by configuring the Log4j settings according to instructions provided in the Cassandra documentation.
Summary
Cassandra is just one part of an enterprise application, but it performs an important role. In this chapter, you learned how to configure Cassandra’s pluggable authentication and authorization capabilities, and how to manage and grant permissions to users and roles. You enabled encryption between clients and nodes, and learned how to secure the JMX interface for remote access. Finally, you learned how to use Cassandra’s audit log feature to help ensure compliance. This should put you in a great position for our next topic: integrating Cassandra with other technologies.