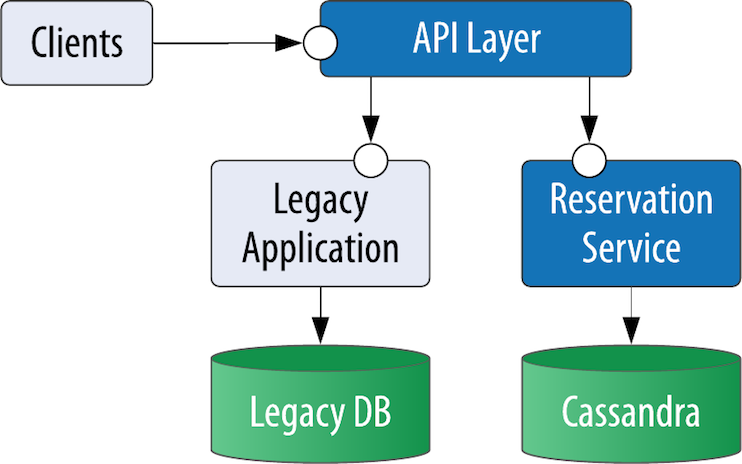
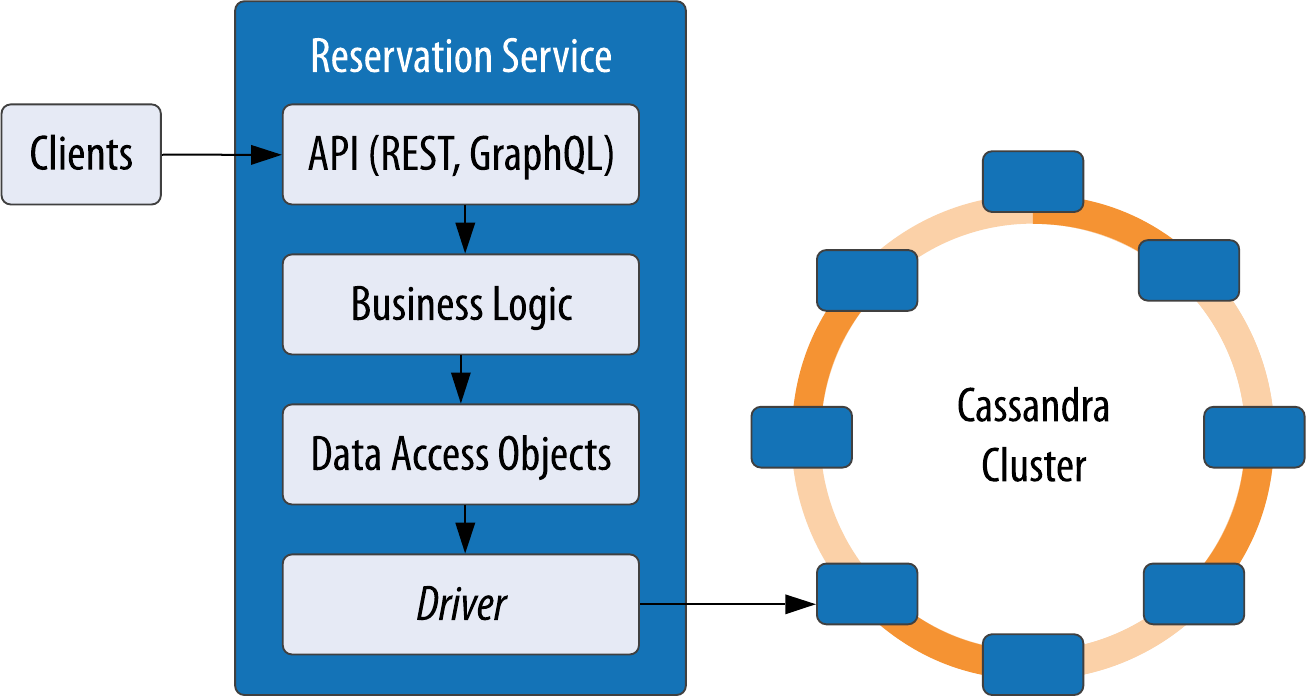
Maintaining Consistency
As you write or update data access code, you’ll need to consider the consistency needs of your application. Developers familiar with relational technology are accustomed to using transactions to accomplish writes to multiple related tables and often have concerns related to consistency in writing and reading data, including:
-
“I’ve heard Cassandra is ‘eventually consistent.’ How can I make sure that I can read data immediately after it is written?”
-
“How can I avoid race conditions when inserting or updating a row, or maintain consistency across writes to multiple tables without ACID transactions?”
-
“How can I efficiently read data from multiple tables without joins?”
As you’ve learned in this book, Cassandra provides several mechanisms that allow you to gain a bit more control over the consistency of your reads and writes. Let’s quickly review them here:
- Configuring consistency levels to achieve strong consistency
-
Let’s recap how you can use Cassandra’s tuneable consistency to achieve the level of consistency you need. Cassandra allows you to specify a replication strategy at the keyspace level which includes the number of replicas of your data that will be stored per data center. You specify a consistency level on each CQL statement that describes how many of those nodes must respond; typically this includes setting a default consistency level in the driver you’re using, and overriding on individual statements as needed.
We introduced the available consistency levels in Chapter 9 and discussed how you can achieve strong consistency (that is, the ability to guarantee that a read gets the most recently written data) using the
QUORUMorLOCAL_QUORUMconsistency level for both reads and writes. If your use case doesn’t require this level of consistency, you can use lower consistency levels such asONEorLOCAL_ONEto increase write throughput. - Using batches to coordinate writes to multiple tables
-
New Cassandra users accustomed to relational databases are often uncomfortable with the idea of storing multiple copies of data in denormalized tables. Typically users become comfortable with the idea that storage is relatively cheap in modern cloud architectures and are less concerned with these additional copies than with how to ensure data is written consistently across these different tables.
Cassandra provides a
BATCHquery that allows you to group mutations to multiple tables in a single query. You can include CQLINSERT,UPDATE, and evenDELETEstatements in a batch. The guarantee of a batch is that if all the statements are valid CQL, once any of the statements complete successfully, the coordinator will continue to work in the background to make sure that all the statements are executed successfully, using mechanisms such as hinted handoff (see “Hinted Handoff”) where needed.Keep in mind the amount of data that is in a batch. Thankfully, Cassandra provides a configurable threshold
batch_size_warn_threshold_in_kbproperty that you can use to detect when clients are submitting large batches, as discussed in Chapter 9 and Chapter 11. - Using lightweight transactions for exclusivity and uniqueness
-
One of the first things relational users learn about Cassandra is that it does not support transactions with ACID semantics due to the challenges of implementing the required locking in a distributed system. However, Cassandra provides a more limited capability called a lightweight transaction that is scoped to a single partition; a small number of nodes are involved in the lightweight transaction.
As you learned in Chapter 9, Cassandra provides two forms of lightweight transactions: one for guaranteeing unique rows, and one for implementing check-and-set style operations. You can use the
IF NOT EXISTSsyntax on anINSERTstatement to make sure a row with the same primary key does not already exist. For example, when inserting into thereservations_by_confirmationtable, you can use this syntax to ensure the confirmation number is unique. You use theIF <conditions>syntax to ensure that one or more values satisfy the conditions you supply before performing anUPDATE, for example, making sure that an available inventory count matches your expected value before decrementing it. - Using denormalization to avoid joins
-
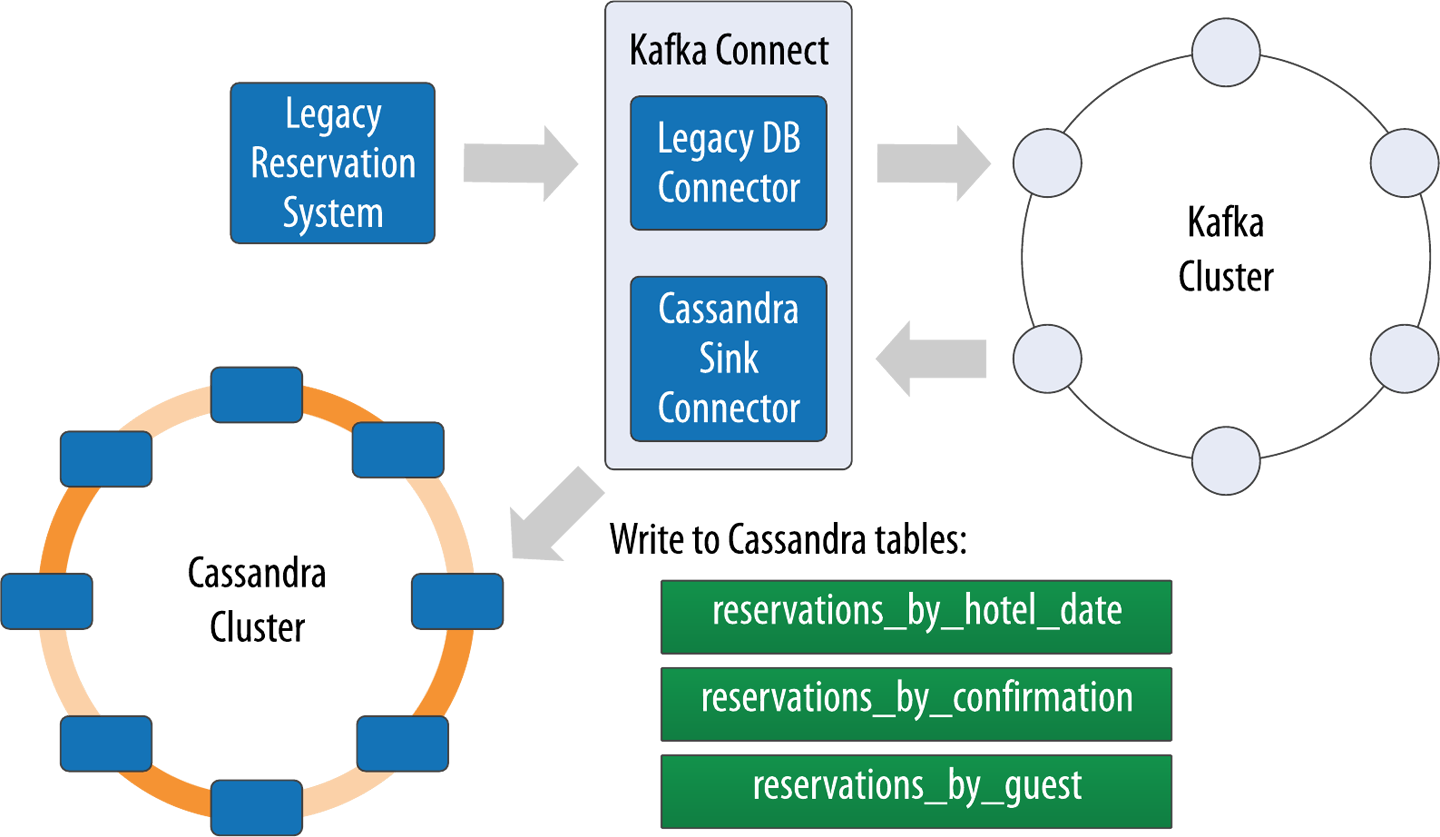
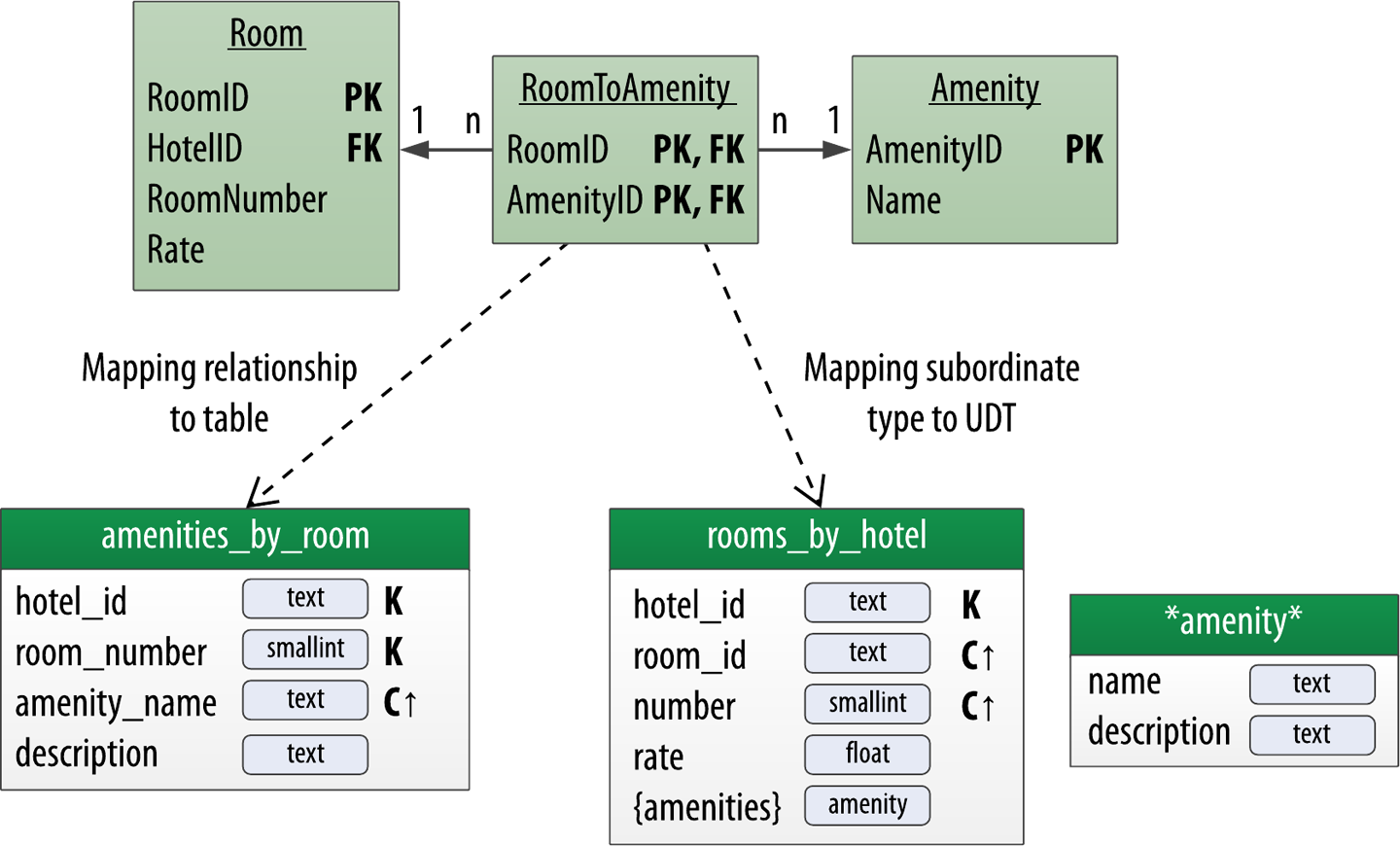
Working around Cassandra’s lack of joins actually begins back in data modeling, prior to application development. You saw an example of this in the design of the
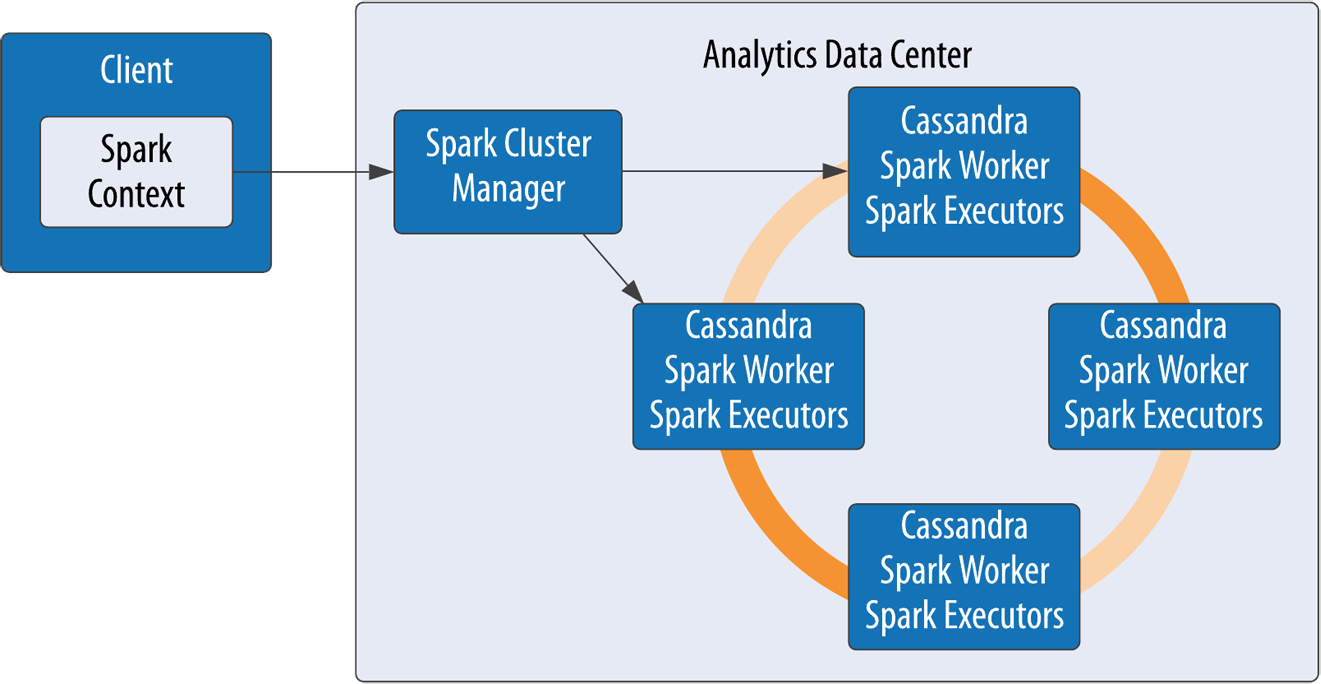
amenities_by_roomtable, which is intended to allow the retrieval of information about a hotel room and its amenities in a single query. This avoids the need for a join onroomsandamenitiestables.There may be cases where you can’t anticipate the joins that will be needed in the future. In microservice architectures, separate data types may be owned by different services with their own data stores, meaning that you wouldn’t have been able to join the data in any case. In both of these situations you’ll most likely end up implementing application-level joins. The emergence of GraphQL as a standard for interfaces has helped application-level joins feel less threatening. We’ll address more complex analytics queries in “Analyzing Data with Apache Spark”.