Chapter 16
Using SQL within Applications
IN THIS CHAPTER
 Using SQL within an application
Using SQL within an application
Combining SQL with procedural languages
Avoiding interlanguage incompatibilities
Embedding SQL in your procedural code
Calling SQL modules from your procedural code
Invoking SQL from a RAD tool
Previous chapters address SQL statements mostly in isolation. For example, questions are asked about data, and SQL queries are developed that retrieve answers to the questions. This mode of operation, interactive SQL, is fine for discovering what SQL can do — but it’s not how SQL is typically used.
Even though SQL syntax can be described as similar to that of English, it isn’t an easy language to master. The overwhelming majority of computer users are not fluent in SQL — and you can reasonably assume that they never will be, even if this book is wildly successful. When a database question comes up, Joe User probably won’t sit down at his terminal and enter an SQL SELECT statement to find the answer. Systems analysts and application developers are the people who are likely to be comfortable with SQL, and they typically don't make a career out of entering ad hoc queries into databases. Instead, they develop applications to make those queries.
 If you plan to perform the same operation repeatedly, you shouldn’t have to rebuild it every time from your keyboard. Write an application to do the job and then run it as often as you like. SQL can be a part of an application, but when it is, it works a little differently than it does in an interactive mode.
If you plan to perform the same operation repeatedly, you shouldn’t have to rebuild it every time from your keyboard. Write an application to do the job and then run it as often as you like. SQL can be a part of an application, but when it is, it works a little differently than it does in an interactive mode.
SQL in an Application
In Chapter 2, SQL is presented to you as an incomplete programming language. To use SQL in an application, you have to combine it with a procedural language such as Visual Basic, C, C++, C#, Java, COBOL, or Python. Because of the way it’s structured, SQL has some strengths and weaknesses. Procedural languages are structured differently from SQL, and consequently have different strengths and weaknesses.
Happily, the strengths of SQL tend to make up for the weaknesses of procedural languages, and the strengths of the procedural languages are in those areas where SQL is weak. By combining the two, you can build powerful applications with a broad range of capabilities. Recently, object-oriented rapid application development (RAD) tools, such as Microsoft’s Visual Studio and the open-source Eclipse environment, have appeared, which incorporate SQL code into applications developed by manipulating onscreen objects instead of writing procedural code.
Keeping an eye out for the asterisk
In the interactive SQL discussions in previous chapters, the asterisk (*) serves as a shorthand substitute for “all columns in the table.” If the table has numerous columns, the asterisk can save a lot of typing. However, using the asterisk this way is problematic when you use SQL in an application program. After your application is written, you or someone else may add new columns to a table or delete old ones. Doing so changes the meaning of “all columns.” When your application specifies “all columns” with an asterisk, it may retrieve columns other than those it thinks it’s getting.
Such a change to a table doesn’t affect existing programs until they have to be recompiled to fix a bug or make some change, perhaps months after the change was made. Then the effect of the * wildcard expands to include all the now-current columns. This change may cause the application to fail in a way unrelated to the bug fix (or other change made), creating your own personal debugging nightmare.
To be safe, specify all column names explicitly in an application instead of using the asterisk wildcard. (For more about wildcard characters, see Chapter 6.)
SQL strengths and weaknesses
SQL is strong in data retrieval. If important information is buried somewhere in a single-table or multi-table database, SQL gives you the tools you need to retrieve it. You don't need to know the order of the table’s rows or columns because SQL doesn’t deal with rows or columns individually. The SQL transaction-processing facilities ensure that your database operations are unaffected by any other users who may be simultaneously accessing the same tables that you are.
A major weakness of SQL is its rudimentary user interface. It has no provision for formatting screens or reports. It accepts command lines from the keyboard and sends retrieved values to the monitor screen, one row at a time.
Sometimes a strength in one context is a weakness in another. One strength of SQL is that it can operate on an entire table at once. Whether the table has one row, a hundred rows, or a hundred thousand rows, a single SELECT statement can extract the data you want. SQL can’t easily operate on one row at a time, however — and sometimes you do want to deal with each row individually. In such cases, you can use SQL’s cursor facility (described in Chapter 19) or you can use a procedural host language.
Procedural languages’ strengths and weaknesses
In contrast to SQL, procedural languages are designed for one-row-at-a-time operations, which give the application developer precise control over the way a table is processed. This detailed control is a great strength of procedural languages. But a corresponding weakness is that the application developer must have detailed knowledge about how the data is stored in the database tables. The order of the database’s columns and rows is significant and must be taken into account.
 Because of the step-by-step nature of procedural languages, they have the flexibility to produce user-friendly screens for data entry and viewing. You can also produce sophisticated printed reports with any desired layout.
Because of the step-by-step nature of procedural languages, they have the flexibility to produce user-friendly screens for data entry and viewing. You can also produce sophisticated printed reports with any desired layout.
Problems in combining SQL with a procedural language
It makes sense to try to combine SQL and procedural languages in such a way that you can benefit from their mutual strengths and not be penalized by their combined weaknesses. As valuable as such a combination may be, you must overcome some challenges before you can achieve this perfect marriage in a practical way.
Contrasting operating modes
A big problem in combining SQL with a procedural language is that SQL operates on tables a set at a time, whereas procedural languages work on them a row at a time. Sometimes this issue isn’t a big deal. You can separate set operations from row operations, doing each with the appropriate tool.
But if you want to search a table for records meeting certain conditions and perform different operations on the records depending on whether they meet the conditions, you may have a problem. Such a process requires both the retrieval power of SQL and the branching capability of a procedural language. Embedded SQL gives you this combination of capabilities. You can simply embed SQL statements at strategic locations within a program that you have written in a conventional procedural language. (See “Embedded SQL,” later in this chapter, for more information.)
Data type incompatibilities
Another hurdle to the smooth integration of SQL with any procedural language is that SQL’s data types differ from the data types of all the major procedural languages. This circumstance shouldn’t be surprising, because the data types defined for any one procedural language are different from the types for the other procedural languages.
You can look high and low, but you won’t find any standardization of data types across languages. In SQL releases before SQL-92, data-type incompatibility was a major concern. In SQL-92 (and also in subsequent releases of the SQL standard), the CAST statement addresses the problem. Chapter 9 explains how you can use CAST to convert a data item from the procedural language's data type to one recognized by SQL, as long as the data item itself is compatible with the new data type.
Hooking SQL into Procedural Languages
Although you face some potential hurdles when you integrate SQL with procedural languages, mark my words — the integration can be done successfully. In fact, in many instances, you must integrate SQL with procedural languages if you intend to produce the desired result in the allotted time — or produce it at all. Luckily, you can use any of several methods for combining SQL with procedural languages. Three of the methods — embedded SQL, module language, and RAD tools — are outlined in the next few sections.
Embedded SQL
The most common method of mixing SQL with procedural languages is called embedded SQL. Wondering how embedded SQL works? Take one look at the name and you have the basics down: Drop SQL statements into the middle of a procedural program, wherever you need them.
Of course, as you may expect, an SQL statement that suddenly appears in the middle of a C program can present a challenge for a compiler that isn’t expecting it. For that reason, programs containing embedded SQL are usually passed through a preprocessor before being compiled or interpreted. The EXEC SQL directive warns the preprocessor of the imminent appearance of SQL code.
As an example of embedded SQL, look at a program written in Oracle’s Pro*C version of the C language. The program, which accesses a company’s EMPLOYEE table, prompts the user for an employee name and then displays that employee's salary and commission. It then prompts the user for new salary and commission data — and updates the employee table with it:
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
VARCHAR ename[10];
FLOAT salary, comm;
SHORT salary_ind, comm_ind;
EXEC SQL END DECLARE SECTION;
main()
{
int sret; /* scanf return code */
/* Log in */
strcpy(uid.arr,"FRED"); /* copy the user name */
uid.len=strlen(uid.arr);
strcpy(pwd.arr,"TOWER"); /* copy the password */
pwd.len=strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR STOP;
EXEC SQL WHENEVER NOT FOUND STOP;
EXEC SQL CONNECT :uid;
printf("Connected to user: percents \n",uid.arr);
printf("Enter employee name to update: ");
scanf("percents",ename.arr);
ename.len=strlen(ename.arr);
EXEC SQL SELECT SALARY,COMM INTO :salary,:comm
FROM EMPLOY
WHERE ENAME=:ename;
printf("Employee: percents salary: percent6.2f comm:
percent6.2f \n",
ename.arr, salary, comm);
printf("Enter new salary: ");
sret=scanf("percentf",&salary);
salary_ind = 0;
if (sret == EOF !! sret == 0) /* set indicator */
salary_ind =-1; /* Set indicator for NULL */
printf("Enter new commission: ");
sret=scanf("percentf",&comm);
comm_ind = 0; /* set indicator */
if (sret == EOF !! sret == 0)
comm_ind=-1; /* Set indicator for NULL */
EXEC SQL UPDATE EMPLOY
SET SALARY=:salary:salary_ind
SET COMM=:comm:comm_ind
WHERE ENAME=:ename;
printf("Employee percents updated. \n",ename.arr);
EXEC SQL COMMIT WORK;
exit(0);
}
You don’t have to be an expert in C to understand the essence of what this program is doing (and how it intends to do it). Here’s a rundown of the order in which the statements execute:
- SQL declares host variables.
- C code controls the user login procedure.
- SQL sets up error handling and connects to the database.
- C code solicits an employee name from the user and places it in a variable.
- An SQL
SELECTstatement retrieves the data for the named employee’s salary and commission, and the statement stores the data in the host variables:salaryand:comm. - C then takes over again and displays the employee's name, salary, and commission and then solicits new values for salary and commission. It also checks to see whether an entry has been made, and if one has not, it sets an indicator.
- SQL updates the database with the new values.
- C then displays an
Operation completemessage. - SQL commits the transaction, and C finally exits the program.
You can mix the commands of two languages like this because of the preprocessor. The preprocessor separates the SQL statements from the host language commands, placing the SQL statements in a separate external routine. Each SQL statement is replaced with a host-language CALL of the corresponding external routine. The language compiler can now do its job.
The way the SQL part is passed to the database depends on the implementation. You, as the application developer, don't have to worry about any of this. The preprocessor takes care of it. You should be concerned about a few things, however, that do not appear in interactive SQL — things such as host variables and incompatible data types.
Declaring host variables
Some information must be passed between the host language program and the SQL segments. You pass this data with host variables. In order for SQL to recognize the host variables, you must declare them before you use them. Declarations are included in a declaration segment that precedes the program segment. The declaration segment is announced by the following directive:
EXEC SQL BEGIN DECLARE SECTION ;
The end of the declaration segment is signaled by this line:
EXEC SQL END DECLARE SECTION ;
Every SQL statement must be preceded by an EXEC SQL directive. The end of an SQL segment may or may not be signaled by a terminator directive. In COBOL, the terminator directive is "END-EXEC", and in C, it's a semicolon.
Converting data types
Depending on the compatibility of the data types supported by the host language and those supported by SQL, you may have to use CAST to convert certain types. You can use host variables that have been declared in the DECLARE SECTION. Remember to prefix host variable names with a colon (:) when you use them in SQL statements, as in the following example:
INSERT INTO FOODS
(FOODNAME, CALORIES, PROTEIN, FAT, CARBOHYDRATE)
VALUES
(:foodname, :calories, :protein, :fat, :carbo) ;
Module language
Module language provides another method for using SQL with a procedural programming language. With module language, you explicitly put all the SQL statements into a separate SQL module.
An SQL module is simply a list of SQL statements. Each SQL statement is included in an SQL procedure and is preceded by a specification of the procedure's name and the number and types of parameters.
Each SQL procedure contains only one SQL statement. In the host program, you explicitly call an SQL procedure at whatever point in the host program you want to execute the SQL statement in that procedure. You call the SQL procedure as if it were a subprogram in the host language.
Thus you can use an SQL module and the associated host program to explicitly hand-code the result of the SQL preprocessor for embedded syntax.
Embedded SQL is much more common than module language. Most vendors offer some form of module language, but few emphasize it in their documentation. Module language does have several advantages:
- SQL programmers don’t have to be experts in the procedural language. Because the SQL is completely separated from the procedural language, you can hire the best SQL programmers available to write your SQL modules, whether or not they have any experience with your procedural language. In fact, you can even defer deciding which procedural language to use until after your SQL modules are written and debugged.
- You can hire the best programmers who work in your procedural language, even if they know nothing about SQL. It stands to reason that if your SQL experts don’t have to be procedural language experts, certainly the procedural language experts don’t have to worry themselves over learning SQL.
- No SQL is mixed in with the procedural code, so your procedural language debugger works. This can save you considerable development time.
Once again, what can be looked at as an advantage from one perspective may be a disadvantage from another. Because the SQL modules are separated from the procedural code, following the flow of the logic isn’t as easy as it is in embedded SQL when you’re trying to understand how the program works.
Module declarations
The syntax for the declarations in a module is as follows:
MODULE [module-name]
[NAMES ARE character-set-name]
LANGUAGE {ADA|C|COBOL|FORTRAN|MUMPS|PASCAL|PLI|SQL}
[SCHEMA schema-name]
[AUTHORIZATION authorization-id]
[temporary-table-declarations…]
[cursor-declarations…]
[dynamic-cursor-declarations…]
procedures…
The square brackets indicate that the module name is optional. Naming it anyway is a good idea if you want to keep things from getting too confusing.
The optional NAMES ARE clause specifies a character set. If you don’t include a NAMES ARE clause, the default set of SQL characters for your implementation is used. The LANGUAGE clause tells the module which language it will be called from. The compiler must know what the calling language is, because it will make the SQL statements appear to the calling program as if they are subprograms in that program's language.
Although the SCHEMA clause and the AUTHORIZATION clause are both optional, you must specify at least one of them. Or you can specify both. The SCHEMA clause specifies the default schema, and the AUTHORIZATION clause specifies the authorization identifier. The authorization identifier establishes the privileges you have. If you don't specify an authorization ID, the DBMS uses the authorization ID associated with your session to determine the privileges that your module is allowed. If you don’t have the privileges needed to perform the operation your procedure calls for, your procedure isn’t executed.
If your procedure requires temporary tables, declare them with the temporary-table declaration clause. Declare cursors and dynamic cursors before you declare any procedures that use them. Declaring a cursor after a procedure starts executing is permissible as long as that procedure doesn’t use the cursor. Declaring cursors to be used by later procedures may make sense. (You can find more in-depth information on cursors in Chapter 19.)
Module procedures
Following all the declarations I discuss in the previous section, the functional parts of the module are the procedures. An SQL module language procedure has a name, parameter declarations, and executable SQL statements. The procedural language program calls the procedure by its name and passes values to it through the declared parameters. Procedure syntax looks like this:
PROCEDURE procedure-name
(parameter-declaration [, parameter-declaration]…
SQL statement ;
[SQL statements] ;
The parameter declaration should take the following form:
parameter-name data-type
or
SQLSTATE
The parameters you declare may be input parameters, output parameters, or both. SQLSTATE is a status parameter through which errors are reported. (You can delve deeper into parameters by heading to Chapter 21.)
Object-oriented RAD tools
By using state-of-the-art RAD tools, you can develop sophisticated applications without knowing how to write a single line of code in C++, C#, Python, Java, or any procedural language, for that matter. Instead, you choose objects from a library and place them in appropriate spots on the screen.
Objects of different standard types have characteristic properties, and selected events are appropriate for each object type. You can also associate a method with an object. The method is a procedure written in (well, yeah) a procedural language. Building useful applications without writing any methods is possible, however.
Although you can build complex applications without using a procedural language, sooner or later you’ll probably need SQL. SQL has a richness of expression that is difficult, if not impossible, to duplicate with object-oriented programming. As a result, full-featured RAD tools offer you a mechanism for injecting SQL statements into your object-oriented applications. Microsoft’s Visual Studio is an example of an object-oriented development environment that offers SQL capability. Microsoft Access is another application development environment that enables you to use SQL in conjunction with its procedural language, VBA.
Chapter 4 shows you how to create database tables with Access. That operation represents only a small fraction of Access’s capabilities. Access is a tool, and its primary purpose is to develop applications that process the data in database tables. Using Access, you can place objects on forms and then customize the objects by giving them properties, events, and methods. You can manipulate the forms and objects with VBA code, which can contain embedded SQL.
 Although RAD tools such as Access can deliver high-quality applications in less time, they usually don’t work across all platforms. Access, for example, runs only with the Microsoft Windows operating system. You may get lucky and discover that the RAD tool you chose works on a few platforms, but if building platform-independent functionality is important to you — or if you think you may want to migrate your application to a different platform eventually — beware.
Although RAD tools such as Access can deliver high-quality applications in less time, they usually don’t work across all platforms. Access, for example, runs only with the Microsoft Windows operating system. You may get lucky and discover that the RAD tool you chose works on a few platforms, but if building platform-independent functionality is important to you — or if you think you may want to migrate your application to a different platform eventually — beware.
RAD tools such as Access represent the beginning of the eventual merger of relational and object-oriented database design. The structural strengths of relational design and SQL will both survive. They will be augmented by the rapid — and comparatively bug-free — development that comes from object-oriented programming.
Using SQL with Microsoft Access
The primary audience for Microsoft Access is people who want to develop relatively simple applications without programming. If that describes you, you might want to put my Access 2013 All-In-One For Dummies on your shelf as a reference book. The procedural language VBA (Visual Basic for Applications) and SQL are both built into Access, but are not emphasized in either advertising or documentation. If you want to use VBA and SQL to develop more sophisticated applications, try my book, Access 2003 Power Programming with VBA, also published by Wiley. The programming aspect of Access hasn’t changed much over the past decade. Be aware though, that the SQL in Access is not a full implementation — and you almost need the detective skills of Sherlock Holmes to even find it.
I mention the three components of SQL — Data Definition Language, Data Manipulation Language, and Data Control Language — in Chapter 3. The subset of SQL contained in Access primarily implements the Data Manipulation Language. You can do table creation operations with Access SQL, but they are a lot easier to do with the RAD tool I describe in Chapter 4. The same goes for implementing security features, which I cover in Chapter 14.
To get a look at some Access SQL, you need to sneak up on it from behind. Consider an example taken from the database of the fictitious Oregon Lunar Society, a nonprofit research organization. The Society has several research teams, one of which is the Moon Base Research Team (MBRT). A question has arisen as to which scholarly papers have been written by members of the team. A query was formulated using Access’s Query By Example (QBE) facility to retrieve the desired data. The query, shown in Figure 16-1, pulls data from the RESEARCHTEAMS, AUTHORS, and PAPERS tables with the help of the AUTH-RES and AUTH-PAP intersection tables that were added to break up many-to-many relationships.
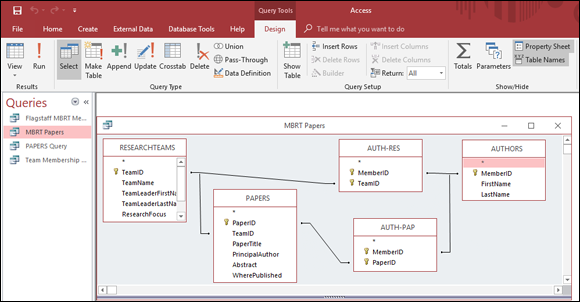
FIGURE 16-1: The Design View of MBRT Papers query.
After clicking on the Home tab to access the toolbar, you can click the View icon drop-down menu in the upper left corner of the window to reveal the other available views of the database. One of the choices is SQL View. (See Figure 16-2.)

FIGURE 16-2: One of your View menu options is SQL View.
When you click SQL View, the SQL editing window appears, showing the SQL statement that Access has generated, based on the choices you made using QBE.
This SQL statement, shown in Figure 16-3, is what actually gets sent to the database engine. The database engine, which interfaces directly with the database itself, understands only SQL. Any information entered into the QBE environment must be translated into SQL before it is sent on to the database engine for processing.
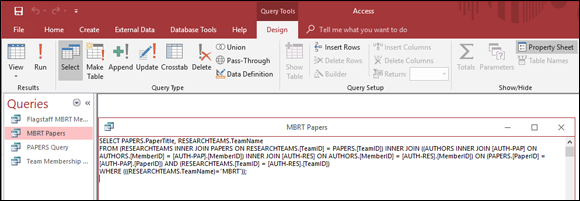
FIGURE 16-3: An SQL statement that retrieves the names of all the papers written by members of the MBRT.
You may notice that the syntax of the SQL statement shown in Figure 16-3 differs somewhat from the syntax of ANSI/ISO-standard SQL. Take the old adage, “When in Rome, do as the Romans do,” to heart here. When working with Access, use the Access dialect of SQL. That advice also goes for any other environment that you may be working in. All implementations of SQL differ from the standard in one respect or another.
If you want to write a new query in Access SQL — one that has not already been created using QBE, that is — you can simply erase some existing query from the SQL editing window and type in a new SQL SELECT statement. Click the DESIGN tab and then the red Exclamation Point (Run) icon on the toolbar at the top of the screen to run your new query. The result appears onscreen in Datasheet View.