The most recognizable hallmark of the Web is a simple text string known as the Uniform Resource Locator (URL). Each well-formed, fully qualified URL is meant to conclusively address and uniquely identify a single resource on a remote server (and in doing so, implement a couple of related, auxiliary functions). The URL syntax is the cornerstone of the address bar, the most important user interface (UI) security indicator in every browser.
In addition to true URLs used for content retrieval, several classes of pseudo-URLs use a similar syntax to provide convenient access to browser-level features, including the integrated scripting engine, several special document-rendering modes, and so on. Perhaps unsurprisingly, these pseudo-URL actions can have a significant impact on the security of any site that decides to link to them.
The ability to figure out how a particular URL will be interpreted by the browser, and the side effects it will have, is one of the most basic and common security tasks attempted by humans and web applications alike, but it can be a problematic one. The generic URL syntax, the work of Tim Berners-Lee, is codified primarily in RFC 3986;[94] its practical uses on the Web are outlined in RFCs 1738,[95] 2616,[96] and a couple of other, less-significant standards. These documents are remarkably detailed, resulting in a fairly complex parsing model, but they are not precise enough to lead to harmonious, compatible implementations in all client software. In addition, individual software vendors have chosen to deviate from the specifications for their own reasons.
Let’s have a closer look at how the humble URL works in practice.
Figure 2-1 shows the format of a fully qualified absolute URL, one that specifies all information required to access a particular resource and that does not depend in any way on where the navigation began. In contrast, a relative URL, such as ../file.php?text=hello+world, omits some of this information and must be interpreted in the context of a base URL associated with the current browsing context.
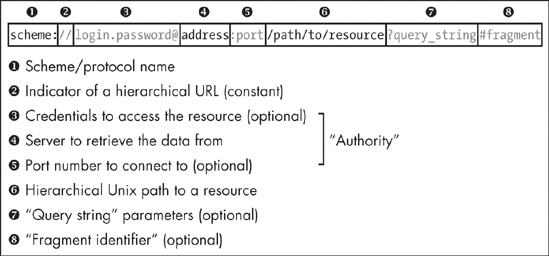
The segments of the absolute URL seem intuitive, but each comes with a set of gotchas, so let’s review them now.
The scheme name is a case-insensitive string that ends with a single colon, indicating the protocol to be used to retrieve the resource. The official registry of valid URL schemes is maintained by the Internet Assigned Numbers Authority (IANA), a body more widely known for its management of the IP address space.[97] IANA’s current list of valid scheme names includes several dozen entries such as http:, https:, and ftp:; in practice, a much broader set of schemes is informally recognized by common browsers and third-party applications, some which have special security consequences. (Of particular interest are several types of pseudo-URLs, such as data: or javascript:, as discussed later in this chapter and throughout the remainder of this book.)
Before they can do any further parsing, browsers and web applications need to distinguish fully qualified absolute URLs from relative ones. The presence of a valid scheme in front of the address is meant to be the key difference, as defined in RFC 1738: In a compliant absolute URL, only the alphanumerics “+”, “−”, and “.” may appear before the required “:”. In practice, however, browsers deviate from this guidance a bit. All ignore leading newlines and white spaces. Internet Explorer ignores the entire nonprintable character range of ASCII codes 0x01 to 0x1F. Chrome additionally skips 0x00, the NUL character. Most implementations also ignore newlines and tabs in the middle of scheme names, and Opera accepts high-bit characters in the string.
Because of these incompatibilities, applications that depend on the ability to differentiate between relative and absolute URLs must conservatively reject any anomalous syntax—but as we will soon find out, even this is not enough.
In order to comply with the generic syntax rules laid out in RFC 1738, every absolute, hierarchical URL is required to contain the fixed string “//” right before the authority section. If the string is missing, the format and function of the remainder of the URL is undefined for the purpose of that specification and must be treated as an opaque, scheme-specific value.
Note
An example of a nonhierarchical URL is the mailto: protocol, used to specify email addresses and possibly a subject line (mailto:user@example.com?subject=Hello+world). Such URLs are passed down to the default mail client without making any further attempt to parse them.
The concept of a generic, hierarchical URL syntax is, in theory, an elegant one. It ought to enable applications to extract some information about the address without knowing how a particular scheme works. For example, without a preconceived notion of the wacky-widget: protocol, and by applying the concept of generic URL syntax alone, the browser could decide that http://example.com/test1/ and wacky-widget://example.com/test2/ reference the same, trusted remote host.
Regrettably, the specification has an interesting flaw: The aforementioned RFC says nothing about what the implementer should do when encountering URLs where the scheme is known to be nonhierarchical but where a “//” prefix still appears, or vice versa. In fact, a reference parser implementation provided in RFC 1630 contains an unintentional loophole that gives a counterintuitive meaning to the latter class of URLs. In RFC 3986, published some years later, the authors sheepishly acknowledge this flaw and permit implementations to try to parse such URLs for compatibility reasons. As a consequence, many browsers interpret the following examples in unexpected ways:
http:example.com/ In Firefox, Chrome, and Safari, this address may be treated identically to http://example.com/ when no fully qualified base URL context exists and as a relative reference to a directory named example.com when a valid base URL is available.
javascript://example.com/%0Aalert(1) This string is interpreted as a valid nonhierarchical pseudo-URL in all modern browsers, and the JavaScript alert(1) code will execute, showing a simple dialog window.
mailto://user@example.com Internet Explorer accepts this URL as a valid nonhierarchical reference to an email address; the “//” part is simply skipped. Other browsers disagree.
The credentials portion of the URL is optional. This location can specify a username, and perhaps a password, that may be required to retrieve the data from the server. The method through which these credentials are exchanged is not specified as a part of the abstract URL syntax, and it is always protocol specific. For those protocols that do not support authentication, the behavior of a credential-bearing URL is simply undefined.
When no credentials are supplied, the browser will attempt to fetch the resource anonymously. In the case of HTTP and several other protocols, this means not sending any authentication data; for FTP, it involves logging into a guest account named ftp with a bogus password.
Most browsers accept almost any characters, other than general URL section delimiters, in this section with two exceptions: Safari, for unclear reasons, rejects a broader set of characters, including “<”, “>”, “{”, and “}”, while Firefox also rejects newlines.[10]
For all fully qualified hierarchical URLs, the server address section must specify a case-insensitive DNS name (such as example.com), a raw IPv4 address (such as 127.0.0.1), or an IPv6 address in square brackets (such as [0:0:0:0:0:0:0:1]), indicating the location of a server hosting the requested resource. Firefox will also accept IPv4 addresses and hostnames in square brackets, but other implementations reject them immediately.
Although the RFC permits only canonical notations for IP addresses, standard C libraries used by most applications are much more relaxed, accepting noncanonical IPv4 addresses that mix octal, decimal, and hexadecimal notation or concatenate some or all of the octets into a single integer. As a result, the following options are recognized as equivalent:
http://127.0.0.1/ This is a canonical representation of an IPv4 address.
http://0x7f.1/ This is a representation of the same address that uses a hexadecimal number to represent the first octet and concatenates all the remaining octets into a single decimal value.
http://017700000001/ The same address is denoted using a 0-prefixed octal value, with all octets concatenated into a single 32-bit integer.
A similar laid-back approach can be seen with DNS names. Theoretically, DNS labels need to conform to a very narrow character set (specifically, alphanumerics, “.”, and “-”, as defined in RFC 1035[98]), but many browsers will happily ask the underlying operating system resolver to look up almost anything, and the operating system will usually also not make a fuss. The exact set of characters accepted in the hostname and passed to the resolver varies from client to client. Safari is most rigorous, while Internet Explorer is the most permissive. Perhaps of note, several control characters in the 0x0A-0x0D and 0xA0-0xAD ranges are ignored by most browsers in this portion of the URL.
Note
One fascinating behavior of the URL parsers in all of the mainstream browsers is their willingness to treat the character “ ” (ideographic full stop, Unicode point U+3002) identically to a period in hostnames but not anywhere else in the URL. This is reportedly because certain Chinese keyboard mappings make it much easier to type this symbol than the expected 7-bit ASCII value.
” (ideographic full stop, Unicode point U+3002) identically to a period in hostnames but not anywhere else in the URL. This is reportedly because certain Chinese keyboard mappings make it much easier to type this symbol than the expected 7-bit ASCII value.
This server port is an optional section that describes a nonstandard network port to connect to on the previously specified server. Virtually all application-level protocols supported by browsers and third-party applications use TCP or UDP as the underlying transport method, and both TCP and UDP rely on 16-bit port numbers to separate traffic between unrelated services running on a single machine. Each scheme is associated with a default port on which servers for that protocol are customarily run (80 for HTTP, 21 for FTP, and so on), but the default can be overridden at the URL level.
Note
An interesting and unintended side effect of this feature is that browsers can be tricked into sending attacker-supplied data to random network services that do not speak the protocol the browser expects them to. For example, one may point a browser to http://mail.example.com:25/, where 25 is a port used by the Simple Mail Transfer Protocol (SMTP) service rather than HTTP. This fact has caused a range of security problems and prompted a number of imperfect workarounds, as discussed in more detail in Part II of this book.
The next portion of the URL, the hierarchical file path, is envisioned as a way to identify a specific resource to be retrieved from the server, such as /documents/2009/my_diary.txt. The specification quite openly builds on top of the Unix directory semantics, mandating the resolution of “/../” and “/./” segments in the path and providing a directory-based method for sorting out relative references in non-fully qualified URLs.
Using the filesystem model must have seemed like a natural choice in the 1990s, when web servers acted as simple gateways to a collection of static files and the occasional executable script. But since then, many contemporary web application frameworks have severed any remaining ties with the filesystem, interfacing directly with database objects or registered locations in resident program code. Mapping these data structures to well-behaved URL paths is possible but not always practiced or practiced carefully. All of this makes automated content retrieval, indexing, and security testing more complicated than it should be.
The query string is an optional section used to pass arbitrary, nonhierarchical parameters to the resource earlier identified by the path. One common example is passing user-supplied terms to a server-side script that implements the search functionality, such as:
http://example.com/search.php?query=Hello+worldMost web developers are accustomed to a particular layout of the query string; this familiar format is generated by browsers when handling HTML-based forms and follows this syntax:
name1=value1&name2=value2...
Surprisingly, such layout is not mandated in the URL RFCs. Instead, the query string is treated as an opaque blob of data that may be interpreted by the final recipient as it sees fit, and unlike the path, it is not encumbered with specific parsing rules.
Hints of the commonly used format can be found in an informational RFC 1630,[99] in a mail-related RFC 2368,[100] and in HTML specifications dealing with forms.[101] None of this is binding, and therefore, while it may be impolite, it is not a mistake for web applications to employ arbitrary formats for whatever data they wish to put in that part of the URL.
The fragment ID is an opaque value with a role similar to the query string but that provides optional instructions for the client application rather than the server. (In fact, the value is not supposed to be sent to the server at all.) Neither the format nor function of the fragment ID is clearly specified in the RFCs, but it is hinted that it may be used to address “subresources” in the retrieved document or to provide other document-specific rendering cues.
In practice, fragment identifiers have only a single sanctioned use in the browser: that of specifying the name of an anchor HTML element for in-document navigation. The logic is simple. If an anchor name is supplied in the URL and a matching HTML tag can be located, the document will be scrolled to that location for viewing; otherwise, nothing happens. Because the information is encoded in the URL, this particular view of a lengthy document could be easily shared with others or bookmarked. In this use, the meaning of a fragment ID is limited to scrolling an existing document, so there is no need to retrieve any new data from the server when only this portion of the URL is updated in response to user actions.
This interesting property has led to another, more recent and completely ad hoc use of this value: to store miscellaneous state information needed by client-side scripts. For example, consider a map-browsing application that puts the currently viewed map coordinates in the fragment identifier so that it will know to resume from that same location if the link is bookmarked or shared. Unlike updating the query string, changing the fragment ID on-the-fly will not trigger a time-consuming page reload, making this data-storage trick a killer feature.
Each of the aforementioned URL segments is delimited by certain reserved characters: slashes, colons, question marks, and so on. To make the whole approach usable, these delimiting characters should not appear anywhere in the URL for any other purpose. With this assumption in mind, imagine a sample algorithm to split absolute URLs into the aforementioned functional parts in a manner at least vaguely consistent with how browsers accomplish this task. A reasonably decent example of such an algorithm could be:
- STEP 1: Extract the scheme name.
Scan for the first “:” character. The part of the URL to its left is the scheme name. Bail out if the scheme name does not conform to the expected set of characters; the URL may need to be treated as a relative one if so.
- STEP 2: Consume the hierarchical URL identifier.
The string “//” should follow the scheme name. Skip it if found; bail out if not.
Note
In some parsing contexts, implementations will be just as happy with zero, one, or even three or more slashes instead of two, for usability reasons. In the same vein, from its inception, Internet Explorer accepted backslashes (\) in lieu of slashes in any location in the URL, presumably to assist inexperienced users.[11] All browsers other than Firefox eventually followed this trend and recognize URLs such as http:\\example.com\.
- STEP 3: Grab the authority section.
Scan for the next “/”, “?”, or “#”, whichever comes first, to extract the authority section from the URL. As mentioned above, most browsers will also accept “\” as a delimiter in place of a forward slash, which may need to be accounted for. The semicolon (;) is another acceptable authority delimiter in browsers other than Internet Explorer and Safari; the reason for this decision is unknown.
- STEP 3A: Find the credentials, if any.
Once the authority section is extracted, locate the at symbol (@) in the substring. If found, the leading snippet constitutes login credentials, which should be further tokenized at the first occurrence of a colon (if present) to split the login and password data.
- STEP 3B: Extract the destination address.
The remainder of the authority section is the destination address. Look for the first colon to separate the hostname from the port number. A special case is needed for bracket-enclosed IPv6 addresses, too.
- STEP 4: Identify the path (if present).
If the authority section is followed immediately by a forward slash—or for some implementations, a backslash or semicolon, as noted earlier—scan for the next “?”, “#”, or end-of-string, whichever comes first. The text in between constitutes the path section, which should be normalized according to Unix path semantics.
- STEP 5: Extract the query string (if present).
If the last successfully parsed segment is followed by a question mark, scan for the next “#” character or end-of-string, whichever comes first. The text in between is the query string.
- STEP 6: Extract the fragment identifier (if present).
If the last successfully parsed segment is followed by “#”, everything from that character to the end-of-string is the fragment identifier. Either way, you’re done!
This algorithm may seem mundane, but it reveals subtle details that even seasoned programmers normally don’t think about. It also illustrates that it is extremely difficult for casual users to understand how a particular URL may be parsed. Let's start with this fairly simple case:
http://example.com&gibberish=1234@167772161/
The target of this URL—a concatenated IP address that decodes to 10.0.0.1—is not readily apparent to a nonexpert, and many users would believe they are visiting example.com instead.[12] But all right, that was an easy one! So let’s have a peek at this syntax instead:
http://example.com\@coredump.cx/
In Firefox, that URL will take the user to coredump.cx, because example.com\ will be interpreted as a valid value for the login field. In almost all other browsers, “\” will be interpreted as a path delimiter, and the user will land on example.com instead.
An even more frustrating example exists for Internet Explorer. Consider this:
http://example.com;.coredump.cx/
Microsoft’s browser permits “;” in the hostname and successfully resolves this label, thanks to the appropriate configuration of the coredump.cx domain. Most other browsers will autocorrect the URL to http://example.com/;.coredump.cx and take the user to example.com instead (except for Safari, where the syntax causes an error). If this looks messy, remember that we are just getting started with how browsers work!
[10] This is possibly out of the concern for FTP, which transmits user credentials without any encoding; in this protocol, a newline transmitted as is would be misinterpreted by the server as the beginning of a new FTP command. Other browsers may transmit FTP credentials in noncompliant percent-encoded form or simply strip any problematic characters later on.
[11] Unlike UNIX-derived operating systems, Microsoft Windows uses backslashes instead of slashes to delimit file paths (say, c:\windows\system32\calc.exe). Microsoft probably tried to compensate for the possibility that users would be confused by the need to type a different type of a slash on the Web or hoped to resolve other possible inconsistencies with file: URLs and similar mechanisms that would be interfacing directly with the local filesystem. Other Windows filesystem specifics (such as case insensitivity) are not replicated, however.
[12] This particular @-based trick was quickly embraced to facilitate all sorts of online fraud targeted at casual users. Attempts to mitigate its impact ranged from the heavy-handed and oddly specific (e.g., disabling URL-based authentication in Internet Explorer or crippling it with warnings in Firefox) to the fairly sensible (e.g., hostname highlighting in the address bar of several browsers).