The same-origin policy is the most important mechanism we have to keep hostile web applications at bay, but it’s also an imperfect one. Although it is meant to offer a robust degree of separation between any two different and clearly identifiable content sources, it often fails at this task.
To understand this disconnect, recall that contrary to what common sense may imply, the same-origin policy was never meant to be all-inclusive. Its initial focus, the DOM hierarchy (that is, just the document object exposed to JavaScript code) left many of the peripheral JavaScript features completely exposed to cross-domain manipulation, necessitating ad hoc fixes. For example, a few years after the inception of SOP, vendors realized that allowing third-party documents to tweak the location.host property of an unrelated window is a bad idea and that such an operation could send potentially sensitive data present in other URL segments to an attacker-specified site. The policy has subsequently been extended to at least partly protect this and a couple of other sensitive objects, but in some less clear-cut cases, awkward loopholes remain.
The other problem is that many cross-domain interactions happen completely outside of JavaScript and its object hierarchy. Actions such as loading third-party images or stylesheets are deeply rooted in the design of HTML and do not depend on scripting in any meaningful way. (In principle, it would be possible to retrofit them with origin-based security controls, but doing so would interfere with existing websites. Plus, some think that such a decision would go against the design principles that made the Web what it is; they believe that the ability to freely cross-reference content should not be infringed upon.)
In light of this, it seems prudent to explore the boundaries of the same-origin policy and learn about the rich life that web applications can lead outside its confines. We begin with document navigation—a mechanism that at first seems strikingly simple but that is really anything but.
On the Web, the ability to steer the browser from one website to another is taken for granted. Some of the common methods of achieving such navigation are discussed throughout Part I of this book; the most notable of these are HTML links, forms, and frames; HTTP redirects; and JavaScript window.open(...) and location.* calls.
Actions such as pointing a newly opened window to an off-domain URL or specifying the src parameter of a frame are intuitive and require no further review. But when we look at the ability of one page to navigate another, existing document—well, the reign of intuition comes to a sudden end.
In the simple days before the advent of HTML frames, only one document could occupy a given browser window, and only that single window would be under the document’s control. Frames changed this paradigm, however, permitting several different and completely separate documents to be spliced into a single logical view, coexisting within a common region of the screen. The introduction of the mechanism also necessitated another step: To sanely implement certain frame-based websites, any of the component documents displayed in a window needed the ability to navigate its neighboring frames or perhaps the top-level document itself. (For example, imagine a two-frame page with a table of contents on the left and the actual chapter on the right. Clicking a chapter name in the left pane should navigate the chapter in the right pane, and nothing else.)
The mechanism devised for this last purpose is fairly simple: One can specify the target parameter on <a href=...> links or forms, or provide the name of a window to the JavaScript method known as window.open(...), in order to navigate any other, previously named document view. In the mid-1990s, when this functionality first debuted, there seemed to be no need to incorporate any particular security checks into this logic; any page could navigate any other named window or a frame displayed by the browser to a new location at will.
To understand the consequences of this design, it is important to pause for a moment and examine the circumstances under which a particular document may obtain a name to begin with. For frames, the story is simple: In order to reference a frame easily on the embedding page, virtually all frames have a name attribute (and some browsers, such as Chrome, also look at id). Browser windows, on the other hand, are typically anonymous (that is, their window.name property is an empty string), unless created programmatically; in the latter case, the name is specified by whoever creates the view. Anonymous windows do not necessarily stay anonymous, however. If a rogue application is displayed in such a window even briefly, it may set the window.name property to any value, and this effect will persist.
The aforementioned ability to target windows and frames by name is not the only way to navigate them; JavaScript programs that hold window handles pointing to other documents may directly invoke certain DOM methods without knowing the name of their target at all. Attacker-supplied code will not normally hold handles to completely unrelated windows, but it can traverse properties such as opener, top, parent, or frames[] in order to locate even distant relatives within the same navigation flow. An example of such a far-reaching lookup (and subsequently, navigation) is
opener.opener.frames[2].location.assign("http://www.bunnyoutlet.com/");These two lookup techniques are not mutually exclusive: JavaScript programs can first obtain the handle of an unrelated but named window through window.open(...) and then traverse the opener or frames[] properties of that context in order to reach its interesting relatives nearby.
Once a suitable handle is looked up in any fashion, the originating context can leverage one of several DOM methods and properties in order to change the address of the document displayed in that view. In every contemporary browser, calling the <handle>.location.replace(...) method, or assigning a value to <handle>.location or <handle>.location.href properties, should do the trick. Amusingly, due to random implementation quirks, other theoretically equivalent approaches (such as invoking <handle>.location.assign(...) or <handle>.window.open(..., "_self")) may be hit-and-miss.
Okay, so it may be possible to navigate unrelated documents to new locations—but let’s see what could possibly go wrong.
The ability for one domain to navigate windows created by other sites, or ones that are simply no longer same-origin with their creator, is usually not a grave concern. This laid-back design may be an annoyance and may pose some minor, speculative phishing risk,[56] but in the grand scheme of things, it is neither a very pronounced issue nor a particularly distinctive one. This is, perhaps, the reason why the original authors of the relevant APIs have not given the entire mechanism too much thought.
Alas, the concept of HTML frames alters the picture profoundly: Any application that relies on frames to build a trusted user interface is at an obvious risk if an unrelated site is permitted to hijack such UI elements without leaving any trace of the attack in the address bar! Figure 11-1 shows one such plausible attack scenario.
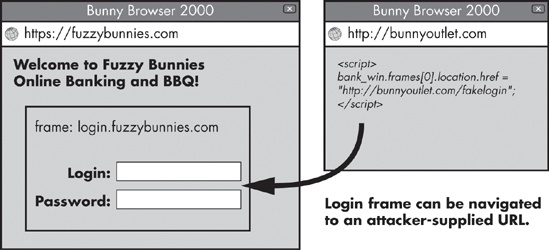
Figure 11-1. A historically permitted, dangerous frame navigation scenario: The window on the right is opened at the same time as a banking website and is actively subverting it.
Georgi Guninski, one of the pioneering browser security researchers, realized as early as 1999 that by permitting unconstrained frame navigation, we were headed for some serious trouble. Following his reports, vendors attempted to roll out frame navigation restrictions mid-2000.[198] Their implementation constrained all cross-frame navigation to the scope of a single window, preventing malicious web pages from interfering with any other simultaneously opened browser sessions.
Surprisingly, even this simple policy proved difficult to implement correctly. It was only in 2008 that Firefox eliminated this class of problems,[199] while Microsoft essentially ignored the problem until 2006. Still, these setbacks aside, we should be fine—right?
The simple security restriction discussed in the previous session was not, in fact, enough. The reason was a new class of web applications, sometimes known as mashups, that combined data from various sources to enable users to personalize their working environment and process data in innovative ways. Unfortunately for browser vendors, such web applications frequently relied on third-party gadgets loaded through <iframe> tags, and their developers could not reasonably expect that loading a single frame from a rogue source would put all other frames on the page at risk. Yet, the simple and elegant window-level navigation policy amounted to permitting exactly that.
Around 2006, Microsoft agreed that the current approach was not sustainable and developed a more secure descendant policy for frame navigation in Internet Explorer 7. Under this policy, navigation of non-same-origin frames is permitted only if the party requesting the navigation shares the origin with one of the ancestors of the targeted view. Figure 11-2 shows the navigation scenario permitted by this new policy.
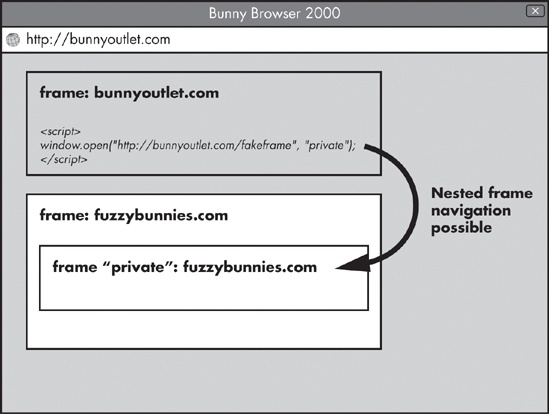
As with many other security improvements, Microsoft never backported this policy to the still popular Internet Explorer 6, and it never convincingly pressured users to abandon the older and increasingly insecure (but still superficially supported) version of its browser. On a more positive note, by 2009, three security researchers (Adam Barth, Collin Jackson, and John C. Mitchell) convinced Mozilla, Opera, and WebKit to roll out a similar policy in their browsers,[200] finally closing the mashup loophole for a good majority of the users of the Internet.
Well, almost closing it. Even the new, robust policy has a subtle flaw. Notice in Figure 11-2 that a rogue site, http://bunnyoutlet.com/, can interfere with a private frame that http://fuzzybunnies.com/ has created for its own use. At first glance, there is no harm here: The attacker’s domain is shown in the address bar, so the victim, in theory, should not be fooled into interacting with the subverted UI of http://fuzzybunnies.com/ in any meaningful way. Sadly, there is a catch: Some web applications have learned to use frames not to create user interfaces but to relay programmatic messages between origins. For applications that need to support Internet Explorer 6 and 7, where postMessage(...) is not available, the tricks similar to the approach shown in Figure 11-3 are commonplace.

Figure 11-3. A potential cross-domain communication scheme, where the top-level page encodes messages addressed to the embedded gadget in the fragment identifier of the gadget frame and the gadget responds by navigating a subframe that is same-origin with the top-level document. If this application is framed on a rogue site, the top-level document controlled by the attacker will be able to inject messages between the two parties by freely navigating send_to_parent and send_to_child.
If an application that relies on a similar hack is embedded by a rogue site, the integrity of the communication frames may be compromised, and the attacker will be able to inject messages into the stream. Even the uses of postMessage(...) may be at risk: If the party sending the message does not specify a destination origin or if the recipient does not examine the originating location, hijacking a frame will benefit the attacker in exactly the same way.
The previous discussion of cross-frame navigation highlights one of the more interesting weaknesses in the browser security model, as well as the disconnect between the design goals of HTML and the aim of the same-origin policy. But that’s not all: The concept of cross-domain framing is, by itself, fairly risky. Why? Well, any malicious page may embed a third-party application without a user’s knowledge, let alone consent. Further, it may obfuscate this fact by overlaying other visual elements on top of the frame, leaving visible just a small chunk of the original site, such as a button that performs a state-changing action. In such a setting, any user logged into the targeted application with ambient credentials may be easily tricked into interacting with the disguised UI control and performing an undesirable and unintended action, such as changing sharing settings for a social network profile or deleting data.
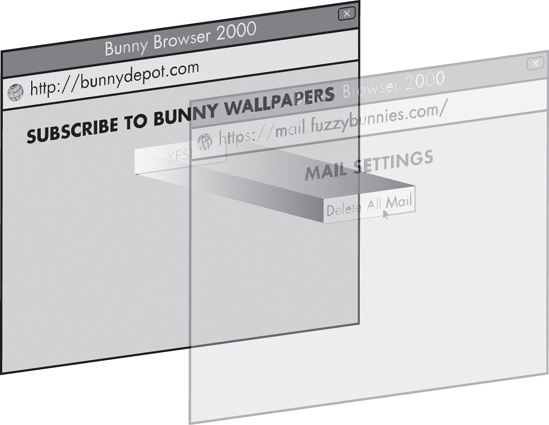
This attack can be improved by the rogue site leveraging a CSS2 property called opacity to make the targeted frame completely invisible without affecting its actual behavior. Any click in the area occupied by such a see-through frame will be delivered to the UI controls contained therein (see Figure 11-4). Too, by combining CSS opacity with JavaScript code to make the frame follow the mouse pointer, it is possible to carry out the attack fairly reliably in almost any setting: Convincing the user to click anywhere in the document window is not particularly hard.
{kind=link}
Figure 11-4. A simplified example of a UI-splicing attack that uses CSS opacity to hide the document the user will actually interact with
Researchers have recognized the possibility of such trickery to some extent since the early 2000s, but a sufficiently convincing attack wasn’t demonstrated until 2008, when Robert Hansen and Jeremiah Grossman publicized the issue broadly.[201] Thus, the term clickjacking was born.
The high profile of Hansen and Grossman’s report, and their interesting proof-of-concept example, piqued vendors’ interest. This interest proved to be short-lived, however, and there appears to be no easy way to solve this problem without taking some serious risks. The only even remotely plausible way to mitigate the impact would be to add renderer-level heuristics to disallow event delivery to cross-domain frames that are partly obstructed or that have not been displayed long enough. But this solution is complicated and hairy enough to be unpopular.[202] Instead, the problem has been slapped with a Band-Aid. A new HTTP header, X-Frame-Options, permits concerned sites to opt out of being framed altogether (X-Frame-Options: deny) or consent only to framing within a single origin (X-Frame-Options: same-origin).[203] This header is supported in all modern browsers (in Internet Explorer, beginning with version 8),[57] but it actually does little to address the vulnerability.
Firstly, the opt-in nature of the defense means that most websites will not adopt it or will not adopt it soon enough; in fact, a 2011 survey of the top 10,000 destinations on the Internet found that barely 0.5 percent used this feature.[204]
To add insult to injury, the proposed mechanism is useless for applications that want to be embedded on third-party sites but that wish to preserve the integrity of their UIs. Various mashups and gadgets, those syndicated “like” buttons provided by social networking sites, and managed online discussion interfaces are all at risk.
As the name implies, the clickjacking attack outlined by Grossman and Hansen targets simple, single-click UI actions. In reality, however, the problem with deceptive framing is more complicated than the early reporting would imply. One example of a more complex interaction is the act of selecting, dragging, and dropping a snippet of text. In 2010, Paul Stone proposed a number of ways in which such an action could be disguised as a plausible interaction with an attacker’s site,[205] the most notable of which is the similarity between drag-and-drop and the use of a humble document-level scrollbar. The same click-drag-release action may be used to interact with a legitimate UI control or to unwittingly drag a portion of preselected text out of a sensitive document and drop it into an attacker-controlled frame. (Cross-domain drag-and-drop is no longer permitted in WebKit, but as of this writing other browser vendors are still debating the right way to address this risk.)
An even more challenging problem is keystroke redirection. Sometime in 2010, I noticed that it was possible to selectively redirect keystrokes across domains by examining the code of a pressed key using the onkeydown event in JavaScript. If the pressed key matched what a rogue site wanted to enter into a targeted application, HTML element focus could be changed momentarily to a hidden <iframe>, thereby ensuring the delivery of the actual keystrokes to the targeted web application rather than the harmless text field the user seems to be interacting with.[206] Using this method, an attacker can synthesize arbitrarily complex text in another domain on the user’s behalf—for example, inviting the attacker as an administrator of the victim’s blog.
Browser vendors addressed the selective keystroke redirection issue by disallowing element focus changes in the middle of a keypress, but doing so did not close the loophole completely. After all, in some cases, an attacker can predict what key will be pressed next and roughly at what time, thereby permitting a preemptive, blindly executed focus switch. The two most obvious cases are a web-based action game or a typing-speed test, since both typically involve rapid pressing of attacker-influenced keys.
In fact, it gets better: Even if a malicious application only relies on free-form text entry—for example, by offering the user a comment-submission form—it’s often possible to guess which character will be pressed next based on the previous few keystrokes alone. English text (and text in most other human languages) is highly redundant, and in many cases, a considerable amount of input can be predicted ahead of time: You can bet that a-a-r-d-v will be followed by a-r-k, and almost always you will be right.
[56] One potential attack is this: Open a legitimate website (say, http://trusted-bank.com/) in a new window, wait for the user to inspect the address bar, and then quickly change the location to an attacker-controlled but similarly named site (e.g., http://trustea-bank.com/). The likelihood of successfully phishing the victim may be higher than when the user is navigating to the bad URL right away.
[57] In older versions of Internet Explorer, web application developers sometimes resort to JavaScript in an attempt to determine whether the window object is the same as parent, a condition that should be satisfied if no higher-level frame is present. Unfortunately, due to the flexibility of JavaScript DOM, such checks, as well as many types of possible corrective actions, are notoriously unreliable.