So far, we have looked at a fair number of well-intentioned browser features that, as the technology matured, proved to be short-sighted and outright dangerous. But now, brace for something special: In the history of the Web, nothing has proven to be as misguided as content sniffing.
The original premise behind content sniffing was simple: Browser vendors assumed that in some cases, it would be appropriate—even desirable—to ignore the normally authoritative metadata received from the server, such as the Content-Type header. Instead of honoring the developer’s declared intent, implementations that support content sniffing may attempt to second-guess the appropriate course of action by applying proprietary heuristics to the returned payload in order to compensate for possible mistakes. (Recall from Chapter 1 that during the First Browser Wars, vendors turned fault-tolerance compatibility into an ill-conceived competitive advantage.)
It didn’t take long for content-sniffing features to emerge as a substantial and detrimental aspect of the overall browser security landscape. To their horror and disbelief, web developers soon noticed that they couldn’t safely host certain nominally harmless document types like text/plain or text/csv on behalf of their users; any attempt to do so would inevitably create a risk that such content could be misinterpreted as HTML.
Perhaps partly in response to these concerns, in 1999 the practice of unsolicited content sniffing was explicitly forbidden in HTTP/1.1:
If and only if the media type is not given by a Content-Type field, the recipient may attempt to guess the media type via inspection of its content and/or the name extension(s) of the URI used to identify the resource.
Alas, this uncharacteristically clear requirement arrived a bit too late. Most browsers were already violating this rule to some extent, and absent a convenient way to gauge the potential consequences, their authors hesitated to simply ditch the offending code. Although several of the most egregious mistakes were cautiously reverted in the past decade, two companies—Microsoft and Apple—largely resisted the effort. They decided that interoperability with broken web applications should trump the obvious security problems. To pacify any detractors, they implemented a couple of imperfect, secondary security mechanisms intended to mitigate the risk.
Today, the patchwork of content-handling policies and the subsequently deployed restrictions cast a long shadow on the online world, making it nearly impossible to build certain types of web services without resorting to contrived and sometimes expensive tricks. To understand these limitations, let’s begin by outlining several scenarios where a nominally passive document may be misidentified as HTML or something like it.
The simplest and the least controversial type of document detection heuristics, and the one implemented by all modern browsers, is the logic implemented to handle the absence of the Content-Type header. This situation, which is encountered very rarely, may be caused by the developer accidentally omitting or mistyping the header name or the document being loaded over a non-HTTP transport mechanism such as ftp: or file:.
For HTTP specifically, the original RFCs explicitly permit the browser to examine the payload for clues when the Content-Type value is not available. For other protocols, the same approach is usually followed, often as a natural consequence of the design of the underlying code.
The heuristics employed to determine the type of a document typically amount to checking for static signatures associated with several dozen known file formats (such as images and common plug-in-handled files). The response will also be scanned for known substrings in order to detect signatureless formats such as HTML (in which case, the browser will look for familiar tags—<body>, <font>, etc). In many browsers, noncontent signals, such as trailing .html or .swf strings in the path segment of the URL, are taken into account as well.
The specifics of content-sniffing logic vary wildly from one browser to another and are not well documented or standardized. To illustrate, consider the handling of Adobe Flash (SWF) files served without Content-Type: In Opera, they are recognized unconditionally based on a content signature check; in Firefox and Safari, an explicit .swf suffix in the URL is required; and Internet Explorer and Chrome will not autorecognize SWF at all.
Rest assured, the SWF file format is not an exceptional case. For example, when dealing with HTML files, Chrome and Firefox will autodetect the document only if one of several predefined HTML tags appears at the very beginning of the file; while Firefox will be eager to “detect” HTML based solely on the presence of an .html extension in the URL, even if no recognizable markup is seen. Internet Explorer, on the other hand, will simply always default to HTML in the absence of Content-Type, and Opera will scan for known HTML tags within the first 1000 bytes of the returned payload.
The assumption behind all this madness is that the absence of Content-Type is an expression of an intentional wish by the publisher of the page—but that assumption is not always accurate and has caused a fair number of security bugs. That said, most web servers actively enforce the presence of a Content-Type header and will insert a default value if one is not explicitly generated by the server-side scripts that handle user requests. So perhaps there is no need to worry? Well, unfortunately, this is not where the story of content sniffing ends.
The HTTP RFC permits content sniffing only in the absence of Content-Type data; the browser is openly prohibited from second-guessing the intent of the webmaster if the header is present in any shape or form. In practice, however, this advice is not taken seriously. The next small step taken off the cliff was the decision to engage heuristics if the server-returned MIME type was deemed invalid in any way.
According to the RFC, the Content-Type header should consist of two slash-delimited alphanumeric tokens (type/subtype), potentially followed by other semicolon-delimited parameters. These tokens may contain any non-whitespace, seven-bit ASCII characters other than a couple of special “separators” (a generic set that includes characters such as “@”, “?”, and the slash itself). Most browsers attempt to enforce this syntax but do so inconsistently; the absence of a slash is seen almost universally as an invitation to content sniffing, and so is the inclusion of whitespaces and certain (but not all) control characters in the first portion of the identifier (the type token). On the other hand, the technically illegal use of high-bit characters or separators affects the validity of this field only in Opera.
The reasons for this design are difficult to understand, but to be fair, the security impact is still fairly limited. As far as web application developers are concerned, care must be exercised not to make typos in Content-Type values and not to allow users to specify arbitrary, user-controlled MIME types (merely validated against a blacklist of known bad options). These requirements may be unexpected, but usually they do not matter a lot. So, what are we ultimately getting at?
The first clear signal that content sniffing was becoming truly dangerous was the handling of a seemingly unremarkable MIME type known as application/octet-stream. This specific value is not mentioned at all in the HTTP specification but is given a special (if vague) role deep in the bowels of RFC 2046:[221]
The recommended action for an implementation that receives an application/octet-stream entity is to simply offer to put the data in a file, with any Content-Transfer-Encoding undone, or perhaps to use it as input to a user-specified process.
The original intent of this MIME type may not be crystal clear from the quoted passage alone, but it is commonly interpreted as a way for web servers to indicate that the returned file has no special meaning to the server and that it should not have one to the client. Consequently, most web servers default to application/octet-stream on all types of opaque, nonweb files, such as downloadable executables or archives, if no better Content-Type match can be found. However, in rare cases of administrator errors (for example, due to deletion of the essential AddType directives in Apache configuration files), web servers may also fall back to this MIME type on documents meant for in-browser consumption. This configuration error is, of course, very easy to detect and fix, but Microsoft, Opera, and Apple nevertheless chose to compensate for it. The browsers from these vendors eagerly engage in content sniffing whenever application/octet-stream is seen.[60]
This particular design decision has suddenly made it more difficult for web applications to host binary files on behalf of the user. For example, any code-hosting platform must exercise caution when returning executables or source archives as application/octet-stream, because there is a risk they may be misinterpreted as HTML and displayed inline. That’s a major issue for any software hosting or webmail system and for many other types of web apps. (It’s slightly safer for them to use any other generic-sounding MIME type, such as application/binary, because there is no special case for it in the browser code.)
In addition to the special treatment given to application/octet-stream, a second, far more damaging exception exists for text/plain. This decision, unique to Internet Explorer and Safari, traces back to RFC 2046. In that document, text/plain is given a dual function: first, to transmit plaintext documents (ones that “do not provide for or allow formatting commands, font attribute specifications, processing instructions, interpretation directives, or content markup”) and, second, to provide a fallback value for any text-based documents not otherwise recognized by the sender.
The distinction between application/octet-stream and text/plain fallback made perfect sense for email messages, a topic that this RFC originally dealt with, but proved to be much less relevant to the Web. Nevertheless, some web servers adopted text/plain as the fallback value for certain types of responses (most notably, the output of CGI scripts).
The text/plain logic subsequently implemented in Internet Explorer and Safari in order to detect HTML in such a case is really bad news: It robs web developers of the ability to safely use this MIME type to generate user-specific plaintext documents and offers no alternatives. This has resulted in a substantial number of web application vulnerabilities, but to this day, Internet Explorer developers seem to have no regrets and have not changed the default behavior of their code.
Safari developers, on the other hand, recognized and tried to mitigate the risk while keeping the functionality in place—but they failed to appreciate the complexity of the Web. The solution implemented in their browser is to rely on a secondary signal in addition to the presence of a plausible-looking HTML markup in the document body. The presence of an extension such as .html or .xml at the end of the URL path is interpreted by their implementation as a sign that content sniffing can be performed safely. After all, the owner of the site wouldn’t name the file this way otherwise, right?
Alas, the signal they embraced is next to worthless. As it turns out, almost all web frameworks support at least one of several methods for encoding parameters in the path segment of the URL instead of in the more traditionally used query part. For example, in Apache, one such mechanism is known as PATH_INFO, and it happens to be enabled by default. By leveraging such a parameter-passing scheme, the attacker can usually append nonfunctional garbage to the path, thereby confusing the browser without affecting how the server will respond to the submitted request itself.
To illustrate, the following two URLs will likely have the same effect for websites running on Apache or IIS:
http://www.fuzzybunnies.com/get_file.php?id=1234
and
http://www.fuzzybunnies.com/get_file.php/evil.html?id=1234In some less-common web frameworks, the following approach may also work:
http://www.fuzzybunnies.com/get_file.php;evil.html?id=1234Despite the evident trouble with text/plain, the engineers working on Internet Explorer decided to take their browser’s heuristics even further. Internet Explorer applies both content sniffing and extension matching[61] not only to a handful of generic MIME types but also to any document type not immediately recognized by the browser. This broad category may include everything from JSON (application/json) to multimedia formats such as Ogg Vorbis (audio/ogg).
Such a design is, naturally, problematic and causes serious problems when hosting any user-controlled document formats other than a small list of universally supported MIME types registered internally in the browser or when routed to a handful of commonly installed external applications.
Nor do the content-sniffing habits of Internet Explorer finally end there: The browser will also resort to payload inspection when dealing with internally recognized document formats that, for any reason, can’t be parsed cleanly. In Internet Explorer versions prior to 8, serving a user-supplied but nonvalidated file claiming to be an JPEG image can lead to the response being treated as HTML. And it gets even more hilarious: Even a subtle mistake, such as serving a valid GIF file with Content-Type: image/jpeg, triggers the same code path. Heck, several years ago, Internet Explorer even detected HTML on any valid, properly served PNG file. Thankfully, this logic has since been disabled—but the remaining quirks are still a minefield.
Note
In order to fully appreciate the risk of content sniffing on valid images, note that it is not particularly difficult to construct images that validate correctly but that carry attacker-selected ASCII strings—such as HTML markup—in the raw image data. In fact, it is relatively easy to construct images that, when scrubbed, rescaled, and recompressed using a known, deterministic algorithm, will have a nearly arbitrary string appear out of the blue in the resulting binary stream.
To its credit, in Internet Explorer 8 and beyond, Microsoft decided to disallow most types of gratuitous content sniffing on known MIME types in the image/* category. It also disallowed HTML detection (but not XML detection) on image formats not recognized by the browser, such as image/jp2 (JPEG2000).
This single tweak aside, Microsoft has proven rather unwilling to make meaningful changes to its content-sniffing logic, and its engineers have publicly defended the need to maintain compatibility with broken websites.[222] Microsoft probably wants to avoid the wrath of large institutional customers, many of whom rely on ancient and poorly designed intranet apps and depend on the quirks of the Internet Explorer-based monoculture on the client end.
In any case, due to the backlash that Internet Explorer faced over its text/plain handling logic, newer versions offer a partial workaround: an optional HTTP header, X-Content-Type-Options: nosniff, which allows website owners to opt out of most of the controversial content heuristics. The use of this header is highly recommended; unfortunately, the support for it has not been backported to versions 6 and 7 of the browser and has only a limited support in other browsers. In other words, it cannot be depended on as a sole defense against content sniffing.
Note
Food for thought: According to the data collected in a 2011 survey by SHODAN and Chris John Riley,[223] only about 0.6 percent of the 10,000 most popular websites on the Internet used this header on a site-wide level.
The Content-Disposition header, mentioned several times in Part I of this book, may be considered a defense against content sniffing in some use cases. The function of this header is not explained satisfactorily in the HTTP/1.1 specification. Instead, it is documented only in RFC 2183,[224] where its role is explained only as it relates to mail applications:
Bodyparts can be designated “attachment” to indicate that they are separate from the main body of the mail message, and that their display should not be automatic, but contingent upon some further action of the user. The MUA[62] might instead present the user of a bitmap terminal with an iconic representation of the attachments, or, on character terminals, with a list of attachments from which the user could select for viewing or storage.
The HTTP RFC acknowledges the use of Content-Disposition: attachment in the web domain but does not elaborate on its intended function. In practice, upon seeing this header during a normal document load, most browsers will display a file download dialog, usually with three buttons: “open,” “save,” and “cancel.” The browser will not attempt to interpret the document any further unless the “open” option is selected or the document is saved to disk and then opened manually. For the “save” option, an optional filename parameter included in the header is used to suggest the name of the download, too. If this field is absent, the filename will be derived from the notoriously unreliable URL path data.
Because the header prevents most browsers from immediately interpreting and displaying the returned payload, it is particularly well suited for safely hosting opaque, downloadable files such as the aforementioned case of archives or executables. Furthermore, because it is ignored on type-specific subresource loads (such as <img> or <script>), it may also be employed to protect user-controlled JSON responses, images, and so on against content sniffing risks. (The reason why all implementations ignore Content-Disposition for these types of navigation is not particularly clear, but given the benefits, it’s best not to question the logic now.)
One example of a reasonably robust use of Content-Disposition and other HTTP headers to discourage content sniffing on a JSON response may be
Content-Type: application/json; charset=utf-8
X-Content-Type-Options: nosniff
Content-Disposition: attachment; filename="json_response.txt"
{ "search_term": "<html><script>alert('Hi mom!')</script>", ... }The defensive use of Content-Disposition is highly recommended where possible, but it is important to recognize that the mechanism is neither mandated for all user agents nor well documented. In less popular browsers, such as Safari Mobile, the header may have no effect; in mainstream browsers, such as Internet Explorer 6, Opera, and Safari, a series of Content-Disposition bugs have at one point or another rendered the header ineffective in attacker-controlled cases.
Another problem with the reliance on Content-Disposition is that the user may still be inclined to click “open.” Casual users can’t be expected to be wary of viewing Flash applets or HTML documents just because a download prompt gets in the way. In most browsers, selecting “open” puts the document in a file: origin, which may be problematic on its own (the recent improvements in Chrome certainly help), and in Opera, the document will be displayed in the context of the originating domain. Arguably, Internet Explorer makes the best choice: HTML documents are placed in a special sandbox using a mark-of-the-web mechanism (outlined in more detail in Chapter 15), but even in that browser, Java or Flash applets will not benefit from this feature.
Most content-related HTTP headers, such as Content-Type, Content-Disposition, and X-Content-Type-Options, have largely no effect on type-specific subresource loads, such as <img>, <script>, or <embed>. In these cases, the embedding party has nearly complete control over how the response will be interpreted by the browser.
Content-Type and Content-Disposition may also not be given much attention when handling requests initiated from within plug-in-executed code. For example, recall from Chapter 9 that any text/plain or text/csv documents may be interpreted by Adobe Flash as security-sensitive crossdomain.xml policies unless an appropriate site-wide metapolicy is present in the root directory on the destination server. Whether you wish to call it “content sniffing” or just “content-type blindness,” the problem is still very real.
Consequently, even when all previously discussed HTTP headers are used religiously, it is important to always consider the possibility that a third-party page may trick the browser into interpreting that page as one of several problematic document types; applets and applet-related content, PDFs, stylesheets, and scripts are usually of particular concern. To minimize the risk of mishaps, you should carefully constrain the structure and character set of any served payloads or use “sandbox” domains to isolate any document types that can’t be constrained particularly well.
The behavior of HTTP headers such as Content-Type, Content-Disposition, and X-Content-Type-Options may be convoluted and exception ridden, but at the very least, they add up to a reasonably consistent whole. Still, it is easy to forget that in many real-world cases, the metadata contained in these headers is simply not available—and in that case, all bets are off. For example, the handling of documents retrieved over ftp:, or saved to disk and opened over the file: protocol, is highly browser- and protocol-specific and often surprises even the most seasoned security experts.
When opening local files, browsers usually give precedence to file extension data, and if the extension is one of the hardcoded values known to the browser, such as .txt or .html, most browsers will take this information at face value. Chrome is the exception; it will attempt to autodetect certain “passive” document types, such as JPEG, even inside .txt documents. (HTML, however, is strictly off-limits.)
When it comes to other extensions registered to external programs, the behavior is a bit less predictable. Internet Explorer will usually invoke the external application, but most other browsers will resort to content sniffing, behaving as though they loaded the document over HTTP with no Content-Type set. All browsers will also fall back to content sniffing if the extension is not known (say, .foo).
The heavy reliance on file extension data and content sniffing for file: documents creates an interesting contrast with the normal handling of Internet-originating resources. On the Web, Content-Type is by and large the authoritative descriptor of document type. File extension information is ignored most of the time, and it is perfectly legal to host a functional JPEG file at a location such as http://fuzzybunnies.com/gotcha.txt. But what happens when this document is downloaded to disk? Well, in such case, the effective meaning of the resource will unexpectedly change: When accessing it over the file: protocol, the browser may insist on rendering it as a text file, based strictly on the extension data.
The example above is fairly harmless, but other content promotion vectors, such as an image becoming an executable, may be more troubling. To that effect, Opera and Internet Explorer will attempt to modify the extension to match the MIME type for a handful of known Content-Type values. Other browsers do not offer this degree of protection, however, and may even be thoroughly confused by the situation they find themselves in. Figure 13-1 captures Firefox in one such embarrassing moment.
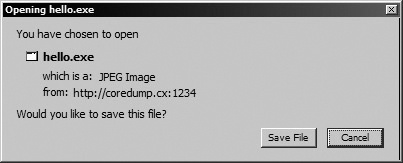
Figure 13-1. Prompt displayed by Firefox when saving a Content-Type: image/jpeg document served with Content-Disposition: attachment. The “hello.exe” filename is derived by the browser from a nonfunctional PATH_INFO suffix appended by the attacker at the end of the URL. The prompt incorrectly claims that the .exe file is a “JPEG Image.” In fact, when saved to disk, it will be an executable.
This problem underscores the importance of returning an explicit, harmless filename value whenever using a Content-Disposition attachment, to prevent the victim from being tricked into downloading a document format that the site owner never intended to host.
Given the complex logic used for file: URLs, the simplicity of ftp: handling may come as a shock. When accessing documents over FTP, most browsers pay no special attention to file extensions and will simply indulge in rampant content sniffing. One exception is Opera, where extension data still takes precedence. From the engineering point of view, the prevalent approach to FTP may seem logical: The protocol can be considered roughly equivalent to HTTP/0.9. Nevertheless, the design also violates the principle of least astonishment. Server owners would not expect that by allowing users to upload .txt documents to an FTP site, they are automatically consenting to host active HTML content within their domain.
[60] In Internet Explorer, this implemented logic differs subtly from a scenario where no Content-Type is present. Instead of always assuming HTML, the browser will scan the first 256 bytes for popular HTML tags and other predefined content signatures. From the security standpoint, however, it’s not a very significant difference.
[61] Naturally, path-based extension matching is essentially worthless for the reasons discussed in the previous section; but in the case of Internet Explorer 6, it gets even worse. In this browser, the extension can appear in the query portion of the URL. Nothing stops the attacker from simply appending ?foo=bar.html to the requested URL, effectively ensuring that this check is always satisfied.
[62] MUA stands for “mail user agent,” that is, a client application used to retrieve, display, and compose mail messages.