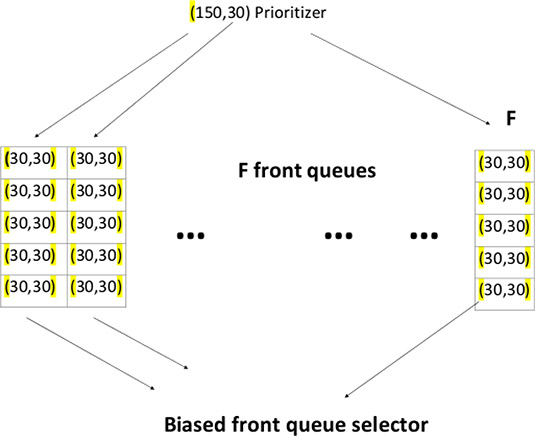
Figure 13.1: Biased front queue of crawl frontier
Web-based applications have increased enormously in the last few years. Use of search engines, online simulations, language translators, games, AI-based Web pages continues to grow and new technology continues to develop. Advances such as crawl frontiers, posting list intersections, text retrievals via inverted indices, and autocomplete functions using tries have revolutionized Web access. This chapter summarizes some of the methods and their corresponding data structures.
Objective 13.1 This chapter addresses the applications of priority queues (crawl frontiers), skiplists, skip pointers and tries. It contains case studies of priority queues and posting list intersections. The final sections cover text retrieval through inverted indices and autocomplete using tries.
Crawl frontier is a data structure (also known as a priority queue) designed to store URLs and support their addition and crawl selection functions. The crawl frontier on a node receives a URL from its crawl feature or a host separator from another crawl. The crawl frontier retains the URLs and releases them in a certain order whenever a search thread seeks a URL.
Two important issues govern the order in which the frontier returns the URLs:
1.Pages that change frequently are given priority for frequent scans; page priority combines quality and rate of change. The combination is essential because each search means processing large numbers of changing pages.
2.Politeness [172] is another crawl frontier feature. Repeated fetch requests in a short period should be avoided, primarily because the requests impact many URLs linked on a single host. A URL frontier implemented as a simple priority queue may cause a burst of fetch requests to a host.
This scenario may even occur if a constraint is imposed on a crawler so that at most one thread could fetch from any single host at any time. A heuristic approach is to insert a gap between two consecutive fetch requests to that host which has an order of magnitude larger than the time taken for the most recent fetch from that host. Figures 13.1 and 13.2 depict details of a crawl frontier [169]–[171], [174].
Figure 13.1: Biased front queue of crawl frontier
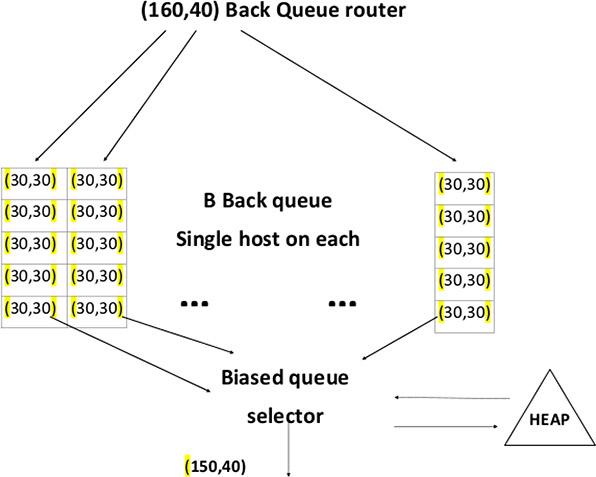
Figure 13.2: Back queue of crawl frontier
13.2 Posting List Intersection
The basic operation of a posting list intersection is to walk through the two postings lists, in linear time within a total number of postings entries. If the list lengths of entries are m and n, then the intersection will take O(m + n) operations. Now the question is, can it be done better than this? Can the process postings list intersection be done in sublinear time? The answer to both questions is yes provided the indexes are not changed frequently. One way to deal with it to use skip list (augmenting postings lists with skip pointers) as illustrated in Figure 13.2. Skip pointers (Figure 13.3) avoid processing but the issues of placing and merging them must also be handled. Information about operations of skiplists and skip pointers can be found at https://nlp.stanford.edu/IR-book/html/htmledition/faster-postings-list-intersection-via-skip-pointers-1.html.
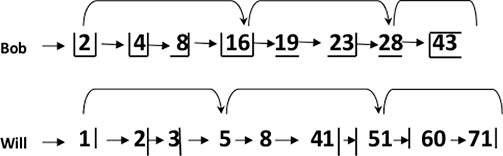
Figure 13.3: Data structure of skip pointer
13.3 Text Retrieval from Inverted Index
Retrieval involves a search for lists postings corresponding to query terms (document score and return of results to the user). Searching for postings involves the random search of the disk, since postings may be too large to fit in memory (without considering cached storage and other special cases). Searching at this level is beyond the capability of many systems. The best solution is breaking down indices and distributing retrieval results over a number of machines.
The two main partitioning approaches for distributed data retrieval are document partitioning and term partitioning. In document partitioning, the entire collection is broken into multiple sub-collections and then assigned to the server. In term partitioning, each server is responsible for the subset of the entire collection, i.e., the server holds the postings for all documents in the collection for the subset of terms. The two techniques use different retrieval techniques and present different trade-offs. Document partitioning uses a query broker that forwards a user query to all partition servers, then merge the partitions results and returns them. Document partitioning typically yields shorter query latencies as they operate independently and they traverse postings in parallel.
13.4 Auto Complete Using Tries
Auto complete functionality is used widely in mobile applications and text editor. A trie is an efficient data structure commonly used to implement auto complete functionality. Trie provides an easy way to search for the possible dictionary words to complete a query for the following reasons. Looking up data in a trie is faster in the worst case O(n) (n = size of the string involved in the operation) time compared to an imperfect hash table. An imperfect hash table can have key collisions. A key collision is the hash function mapping of different keys to the same position in a hash table. A trie can provide an alphabetical ordering of the entries by key. Searching in a trie helps trace pointers to reach a node entered by the user. By exploring a trie traversing down the tree, we can easily enumerate all strings that complete the user input. The steps for resolving a query are:
1.Search for given query using the standard trie search algorithm.
2.If query prefix is not present, indicate it by returning −1.
3.If a query is the end of a word in trie, print the query. The end of the query can be checked quickly by checking whether the last matching node has an end word flat. Tries use such flags to mark the ends of word nodes during searches.
4.If last matching node of query has no children, return.
5.Otherwise, recursively print all nodes under subtree of last matching node.
Project 13.1 — Document Sentiment Analysis. The aim of sentiment analysis is to detect the attitude of a writer, speaker or another subject with respect to some topic or context. Sentiment analysis utilizes natural language processing to extract subjective information from the content. Write a project for document sentiment analysis. The project should involve scanning of user documents and breaking down of comments to check the sentiment in the documents. If the keywords are found, the comments contain sentiment. [Hint: for morphological analysis, tries can be useful.]
Project 13.2 — Twitter Trend Analysis. The hashtag (#) has become an important medium for sharing common interests. Enough individual participation in social media eventually creates a social trend. Through the social trends government and other institutions get an idea of the popularity of any event or activity in a specific moment. Consider a Twitter microblogging site and introduce a typology that includes the following four types of uses: news, ongoing events, memes, and commemoratives. Input will be given by the user in the form of a keyword that will be used to search for latest trends. The system will search for the similar words in the database and it will summarize the total count of the trending tweets associated with the keyword. The summarized trending tweets will be displayed on the screen.
Project 13.3 — Website Evaluation Using Opinion Mining. Propose an advanced website evaluation system for an electronic commerce company. The project must rate the company’s website based on user and customer opinions. The evaluation criteria should consider the following factors: (1) timely delivery of product; (2) website support; (3) accuracy and scope of the website. The proposed system should rate the website by evaluating the opinions and comments of users and customers. [Hint: use opinion mining methodology and database of sentiment based keywords. Positive and negative weights in the database are evaluated and sentiment keywords of users are used for ranking].
Project 13.4 — Detecting E Banking Phishing Websites. The number of online banking users has increased greatly over the past few years. Banks that provide online transactions ask their customers to submit certain credentials (user name, password, credit card data). Malicious users may try to obtain credentialing information by disguising themselves as trustworthy entities; their operations are known as phishing websites.
Propose a system based on a classification data mining algorithm to predict and detect e-banking phishing websites. The system should detect URL, domain identity, security features, and encryption criteria characteristics. [Hint: Read the 2020 paper of Aburrous et al. [196].]