CHAPTER 6
Network Components
In this chapter, you will
• Install and configure network components, both hardware- and software-based, to support organizational security
Large systems are composed of a highly complex set of integrated components. These components can be integrated into a system designed to perform complex operations. System integration is the set of processes designed to produce synergy from the linkage of all of the components. In most business cases, third parties will be part of the value chain, necessitating the sharing of business information, processes, and data with them. This has security and risk implications that need to be understood before these relationships are established.
Certification Objective This chapter covers CompTIA Security+ exam objective 2.1, Install and configure network components, both hardware- and software-based, to support organizational security.

EXAM TIP This chapter contains topics under exam objective 2.1 that can be tested with performance-based questions. It is not enough to simply learn the terms associated with the material. You should be familiar with installing and configuring the components to support organizational security.
Firewall
A firewall can be hardware, software, or a combination of both whose purpose is to enforce a set of network security policies across network connections. It is much like a wall with a window: the wall serves to keep things out, except those permitted through the window (see Figure 6-1). Network security policies act like the glass in the window; they permit some things to pass, such as light, while blocking others, such as air. The heart of a firewall is the set of security policies that it enforces. Management determines what is allowed in the form of network traffic between devices, and these policies are used to build rulesets for the firewall devices used to filter network traffic across the network.
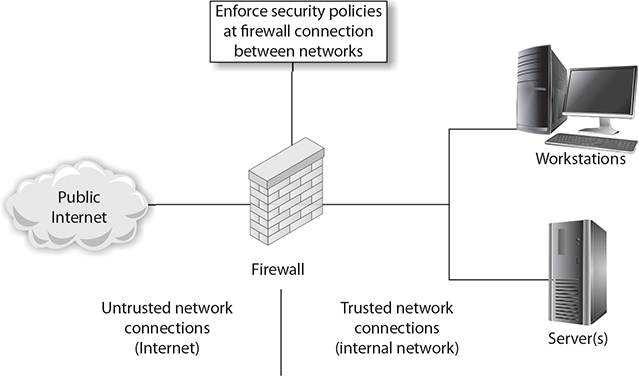
Figure 6-1 How a firewall works
Security policies are rules that define what traffic is permissible and what traffic is to be blocked or denied. These are not universal rules, and many different sets of rules are created for a single organization with multiple connections. A web server connected to the Internet may be configured to allow traffic only on port 80 for HTTP and have all other ports blocked, for example. An e-mail server may have only necessary ports for e-mail open, with others blocked. The network firewall can be programmed to block all traffic to the web server except for port 80 traffic, and to block all traffic bound to the mail server except for port 25. In this fashion, the firewall acts as a security filter, enabling control over network traffic, by machine, by port, and in some cases based on application-level detail. A key to setting security policies for firewalls is the same as for other security policies—the principle of least access: allow only the necessary access for a function; block or deny all unneeded functionality. How an organization deploys its firewalls determines what is needed for security policies for each firewall.
As will be discussed later, the security topology will determine what network devices are employed at what points in a network. At a minimum, your organization’s connection to the Internet should pass through a firewall. This firewall should block all network traffic except that specifically authorized by the organization. Blocking communications on a port is simple—just tell the firewall to close the port. The issue comes in deciding what services are needed and by whom, and thus which ports should be open and which should be closed. This is what makes a security policy useful. The perfect set of network security policies, for a firewall, is one that the end user never sees and that never allows even a single unauthorized packet to enter the network. As with any other perfect item, it will be rare to find the perfect set of security policies for firewalls in an enterprise. When developing rules for a firewall, the principle of least access is best to use; you want the firewall to block as much traffic as possible, while allowing the authorized traffic through.
To develop a complete and comprehensive security policy, you first need to have a complete and comprehensive understanding of your network resources and their uses. Once you know how the network will be used, you will have an idea of what to permit. In addition, once you understand what you need to protect, you will have an idea of what to block. Firewalls are designed to block attacks before they reach a target machine. Common targets are web servers, e-mail servers, DNS servers, FTP services, and databases. Each of these has separate functionality, and each has unique vulnerabilities. Once you have decided who should receive what type of traffic and what types should be blocked, you can administer this through the firewall.
How Do Firewalls Work?
Firewalls enforce the established security policies through a variety of mechanisms, including the following:
• Network Address Translation (NAT)
• Basic packet filtering
• Stateful packet filtering
• Access control lists (ACLs)
• Application layer proxies
One of the most basic security functions provided by a firewall is NAT, which allows you to mask significant amounts of information from outside of the network. This allows an outside entity to communicate with an entity inside the firewall without truly knowing its address. NAT is a technique used in IPv4 to link private IP addresses to public ones. Private IP addresses are sets of IP addresses that can be used by anyone and, by definition, are not routable across the Internet. NAT can assist in security by preventing direct access to devices from outside the firm, without first having the address changed at a NAT device. The benefit is that fewer public IP addresses are needed, and from a security point of view the internal address structure is not known to the outside world. If a hacker attacks the source address, he is simply attacking the NAT device, not the actual sender of the packet.
NAT was conceived to resolve an address shortage associated with IPv4 and is considered by many to be unnecessary for IPv6. However, the added security features of enforcing traffic translation and hiding internal network details from direct outside connections will give NAT life well into the IPv6 timeframe.
Basic packet filtering, the next most common firewall technique, involves looking at packets, their ports, protocols, and source and destination addresses, and checking that information against the rules configured on the firewall. Telnet and FTP connections may be prohibited from being established to a mail or database server, but they may be allowed for the respective service servers. This is a fairly simple method of filtering based on information in each packet header, such as IP addresses and TCP/UDP ports. Packet filtering will not detect and catch all undesired packets, but it is fast and efficient.
EXAM TIP Firewalls operate by examining packets and selectively denying some based on a set of rules. Firewalls act as gatekeepers or sentries at select network points, segregating traffic and allowing some to pass and blocking others.
Firewalls can also act as network traffic regulators in that they can be configured to mitigate specific types of network-based attacks. In denial-of-service and distributed denial-of-service (DoS/DDoS) attacks, an attacker can attempt to flood a network with traffic. Firewalls can be tuned to detect these types of attacks and act as a flood guard, mitigating the effect on the network. Firewalls can be very effective in blocking a variety of flooding attacks, including port floods, SYN floods, and ping floods.
Firewall Rules
Firewalls operate by enforcing a set of rules on the traffic attempting to pass. This set of firewall rules, also called the firewall ruleset, is a mirror of the policy constraints at a particular point in the network. Thus, the ruleset will vary from firewall to firewall, as it is the operational implementation of the desired traffic constraints at each point. Firewall rules state whether the firewall should allow particular traffic to pass through or block it. The structure of a firewall rule can range from simple to very complex, depending upon the type of firewall and the type of traffic. A packet filtering firewall can act on IP addresses and ports, either allowing or blocking based on this information.
EXAM TIP Firewall rules make great performance-based questions—what rules belong on which firewall. Understanding how a rule blocks or permits traffic is essential, but so is seeing the overall network flow picture regulated by the rules. Be able to place rules to a network diagram to meet objectives.
ACL
Access control lists (ACLs) are lists of users and their permitted actions. Users can be identified in a variety of ways, including by a user ID, a network address, or a token. The simple objective is to create a lookup system that allows a device to determine which actions are permitted and which are denied. A router can contain an ACL that lists permitted addresses or blocked addresses, or a combination of both. The most common implementation is for file systems, where named user IDs are used to determine which file system attributes are permitted to the user. This same general concept is reused across all types of devices and situations in networking.
Just as the implicit deny rule applies to firewall rulesets (covered later in the chapter), the explicit deny principle can be applied to ACLs. When using this approach to ACL building, allowed traffic must be explicitly allowed by a permit statement. All of the specific permit commands are followed by a deny all statement in the ruleset. ACL entries are typically evaluated in a top-to-bottom fashion, so any traffic that does not match a permit entry will be dropped by a deny all statement placed as the last line in the ACL.
Application-Based vs. Network-Based
Application-based firewalls (aka application-layer firewalls) can analyze traffic at an even deeper level, examining the application characteristics of traffic and blocking specific actions while allowing others, even inside web-connected applications. This gives application-based firewalls much greater specificity than network-based firewalls that only look at IP addresses and ports.
Some high-security firewalls also employ application layer proxies. Packets are not allowed to traverse the firewall, but data instead flows up to an application that in turn decides what to do with it. For example, a Simple Mail Transfer Protocol (SMTP) proxy may accept inbound mail from the Internet and forward it to the internal corporate mail server. While proxies provide a high level of security by making it very difficult for an attacker to manipulate the actual packets arriving at the destination, and while they provide the opportunity for an application to interpret the data prior to forwarding it to the destination, they generally are not capable of the same throughput as stateful packet inspection firewalls. The trade-off between performance and speed is a common one and must be evaluated with respect to security needs and performance requirements.
Stateful vs. Stateless
The typical network firewall operates on IP addresses and ports, in essence a stateless interaction with the traffic. A stateful packet inspection firewall can act upon the state condition of a conversation—is this a new conversation or a continuation of a conversation, and did it originate inside or outside the firewall? This provides greater capability, but at a processing cost that has scalability implications.
To look at all packets and determine the need for each and its data requires stateful packet filtering. Stateful means that the firewall maintains, or knows, the context of a conversation. In many cases, rules depend on the context of a specific communication connection. For instance, traffic from an outside server to an inside server may be allowed if it is requested but blocked if it is not. A common example is a request for a web page. This request is actually a series of requests to multiple servers, each of which requests can be allowed or blocked. Advanced firewalls employ stateful packet filtering to prevent several types of undesired communications. Should a packet come from outside the network, in an attempt to pretend that it is a response to a message from inside the network, the firewall will have no record of it being requested and can discard it, blocking the undesired external access attempt. As many communications will be transferred to high ports (above 1023), stateful monitoring will enable the system to determine which sets of high port communications are permissible and which should be blocked. A disadvantage of stateful monitoring is that it takes significant resources and processing to perform this type of monitoring, and this reduces efficiency and requires more robust and expensive hardware.
Implicit Deny
All firewall rulesets should include an implicit deny rule that is in place to prevent any traffic from passing that is not specifically recognized as allowed. Firewalls execute their rules upon traffic in a top-down manner, with any allow or block rule whose conditions are met ending the processing. This means the order of rules is important. It also means that the last rule should be a deny all rule, for any traffic that gets to the last rule and has not met a rule allowing it to pass should be blocked.
EXAM TIP To invoke implicit deny, the last rule should be a deny all rule, because any traffic that gets to the last rule and has not met a rule allowing it to pass should be blocked.
Secure Network Administration Principles
Secure network administration principles are the principles used to ensure network security and include properly configuring hardware and software and properly performing operations and maintenance. Networks are composed of a combination of hardware and software, operated under policies and procedures that define desired operating conditions. All of these elements need to be done with security in mind, from planning, to design, to operation.
Rule-Based Management
Rule-based management is a common methodology for configuring systems. Desired operational states are defined in such manner that they can be represented as rules, and a control enforces the rules in operation. This methodology is used for firewalls, proxies, switches, routers, anti-malware, IDS/IPS, and more. As each packet is presented to the control device, the set of rules is applied and interpreted. This is an efficient manner of translating policy objectives into operational use.
EXAM TIP To be prepared for performance-based questions, you should be familiar with installing and configuring the firewall components, including rules, types of firewalls, and administration of firewalls to support organizational security.
VPN Concentrator
A VPN concentrator acts as a VPN endpoint, providing a method of managing multiple separate VPN conversations, each isolated from the others and converting each encrypted stream to its unencrypted, plaintext form, on the network. VPN concentrators can provide a number of services, including but not limited to securing remote access and site-to-site communications. A VPN offers a means of cryptographically securing a communication channel, and the concentrator is the endpoint for this activity. It is referred to as a concentrator because it typically converts many different, independent conversations into one channel. Concentrators are designed to allow multiple, independent encrypted communications across a single device, simplifying network architectures and security.
Remote Access vs. Site-to-Site
VPNs can connect machines from different networks over a private channel. When the VPN is set up to connect specific machines between two networks on an ongoing basis, with no setup per communication required, it is referred to as a site-to-site VPN configuration. If the VPN connection is designed to allow remote hosts to connect to a network, they are called remote access VPNs. Both of these VPNs offer the same protection from outside eavesdropping on the communication channel they protect, the difference is in why they are set up.
IPSec
IPSec is a set of protocols developed by the IETF to securely exchange packets at the network layer (layer 3) of the OSI model (RFCs 2401–2412). Although these protocols work only in conjunction with IP networks, once an IPSec connection is established, it is possible to tunnel across other networks at lower levels of the OSI model. The set of security services provided by IPSec occurs at the network layer of the OSI model, so higher-layer protocols, such as TCP, UDP, Internet Control Message Protocol (ICMP), Border Gateway Protocol (BGP), and the like, are not functionally altered by the implementation of IPSec services.
The IPSec protocol series has a sweeping array of services it is designed to provide, including but not limited to access control, connectionless integrity, traffic-flow confidentiality, rejection of replayed packets, data security (encryption), and data-origin authentication. IPSec has two defined modes—transport and tunnel—that provide different levels of security. IPSec also has three modes of connection: host-to-server, server-to-server, and host-to-host.
The transport mode encrypts only the data portion of a packet, thus enabling an outsider to see source and destination IP addresses. The transport mode protects the higher-level protocols associated with a packet and protects the data being transmitted but allows knowledge of the transmission itself. Protection of the data portion of a packet is referred to as content protection.
Tunnel mode provides encryption of source and destination IP addresses, as well as of the data itself. This provides the greatest security, but it can be done only between IPSec servers (or routers) because the final destination needs to be known for delivery. Protection of the header information is known as context protection.
EXAM TIP In transport mode (end-to-end), security of packet traffic is provided by the endpoint computers. In tunnel mode (portal-to-portal), security of packet traffic is provided between endpoint node machines in each network and not at the terminal host machines.
It is possible to use both methods at the same time, such as using transport within one’s own network to reach an IPSec server, which then tunnels to the target server’s network, connecting to an IPSec server there, and then using the transport method from the target network’s IPSec server to the target host. IPSec uses the term security association (SA) to describe a unidirectional combination of specific algorithm and key selection to provide a protected channel. If the traffic is bidirectional, two SAs are needed and can in fact be different.
Basic Configurations
Four basic configurations can be applied to machine-to-machine connections using IPSec. The simplest is a host-to-host connection between two machines, as shown in Figure 6-2. In this case, the Internet is not a part of the SA between the machines. If bidirectional security is desired, two SAs are used. The SAs are effective from host to host.
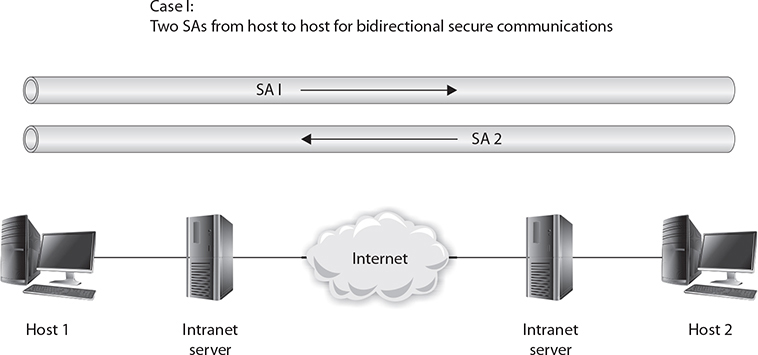
Figure 6-2 A host-to-host connection between two machines
The second case places two security devices in the stream, relieving the hosts of the calculation and encapsulation duties. These two gateways have an SA between them. The network is assumed to be secure from each machine to its gateway, and no IPSec is performed across these hops. Figure 6-3 shows the two security gateways with a tunnel across the Internet, although either tunnel mode or transport mode could be used.
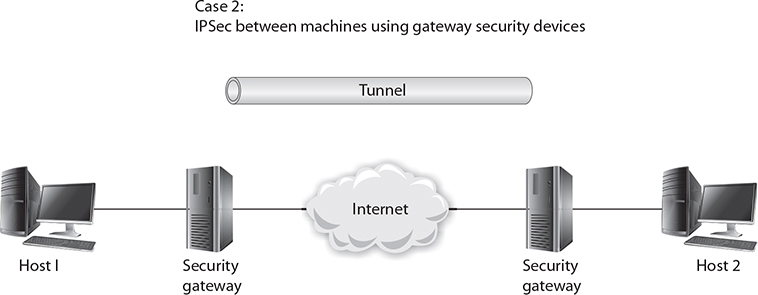
Figure 6-3 Two security gateways with a tunnel across the Internet
The third case combines the first two. A separate SA exists between the gateway devices, but an SA also exists between hosts. This could be considered a tunnel inside a tunnel, as shown in Figure 6-4.
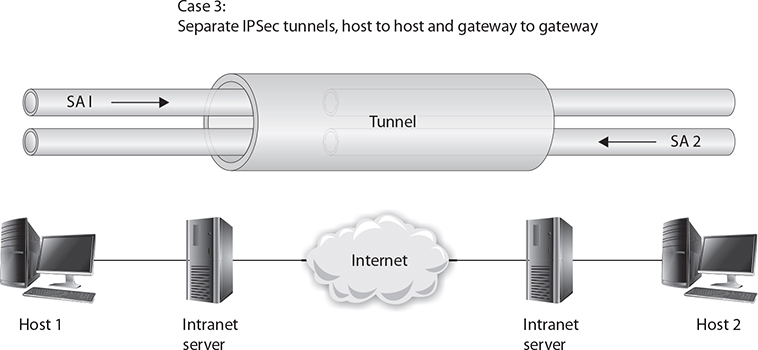
Figure 6-4 A tunnel inside a tunnel
Remote users commonly connect through the Internet to an organization’s network. The network has a security gateway through which it secures traffic to and from its servers and authorized users. In the last case, illustrated in Figure 6-5, the user establishes an SA with the security gateway and then a separate SA with the desired server, if required. This can be done using software on a remote laptop and hardware at the organization’s network.
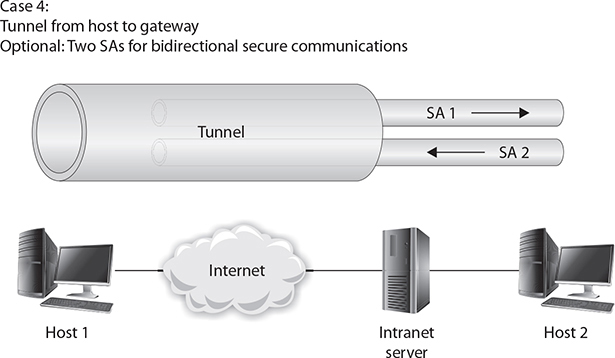
Figure 6-5 Tunnel from host to gateway
Windows can act as an IPSec server, as can routers and other servers. The primary issue is CPU usage and where the computing power should be implanted. This consideration has led to the rise of IPSec appliances, which are hardware devices that perform the IPSec function specifically for a series of communications. Depending on the number of connections, network bandwidth, and so on, these devices can be inexpensive for small office or home office use or quite expensive for large, enterprise-level implementations.
Tunnel Mode
Tunnel mode for IPSec is a means of encapsulating packets inside a protocol that is understood only at the entry and exit points of the tunnel. This provides security during transport in the tunnel, because outside observers cannot decipher packet contents or even the identities of the communicating parties. IPSec has a tunnel mode that can be used from server to server across a public network. Although the tunnel endpoints are referred to as servers, these devices can be routers, appliances, or servers. In tunnel mode, the tunnel endpoints merely encapsulate the entire packet with new IP headers to indicate the endpoints, and they encrypt the contents of this new packet. The true source and destination information is contained in the inner IP header, which is encrypted in the tunnel. The outer IP header contains the addresses of the endpoints of the tunnel.
As mentioned, AH and ESP can be employed in tunnel mode. When AH is employed in tunnel mode, portions of the outer IP header are given the same header protection that occurs in transport mode, with the entire inner packet receiving protection. This is illustrated in Figure 6-6. ESP affords the same encryption protection to the contents of the tunneled packet, which is the entire packet from the initial sender, as illustrated in Figure 6-7. Together, in tunnel mode, AH and ESP can provide complete protection across the packet, as shown in Figure 6-8. The specific combination of AH and ESP is referred to as a security association in IPSec.
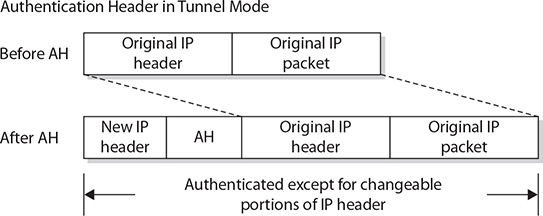
Figure 6-6 IPSec use of AH in tunnel mode
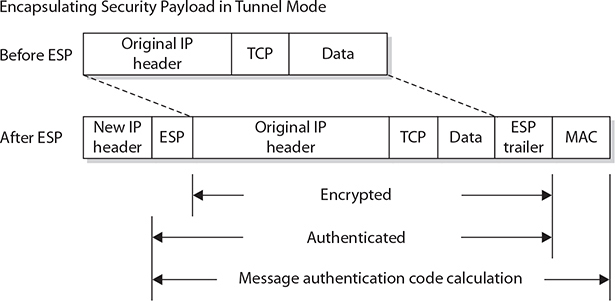
Figure 6-7 IPSec use of ESP in tunnel mode
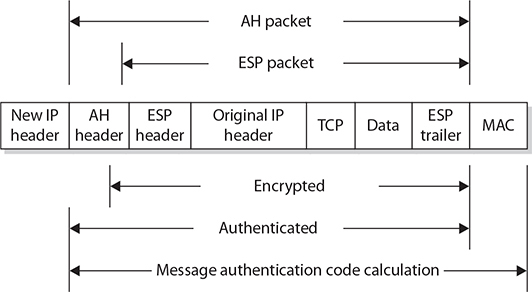
Figure 6-8 IPSec ESP and AH packet construction in tunnel mode
In IPv4, IPSec is an add-on, and its acceptance is vendor driven. It is not a part of the original IP—one of the short-sighted design flaws of the original IP. In IPv6, IPSec is integrated into IP and is native on all packets. Its use is still optional, but its inclusion in the protocol suite will guarantee interoperability across vendor solutions when they are compliant with IPv6 standards.
Transport Mode
In transport mode, the two communication endpoints are providing security primarily for the upper-layer protocols. The cryptographic endpoints, where encryption and decryption occur, are located at the source and destination of the communication channel. For AH in transport mode, the original IP header is exposed, but its contents are protected via the AH block in the packet, as illustrated in Figure 6-9. For ESP in transport mode, the data contents are protected by encryption, as illustrated in Figure 6-10.
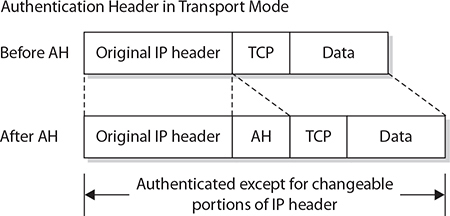
Figure 6-9 IPSec use of AH in transport mode
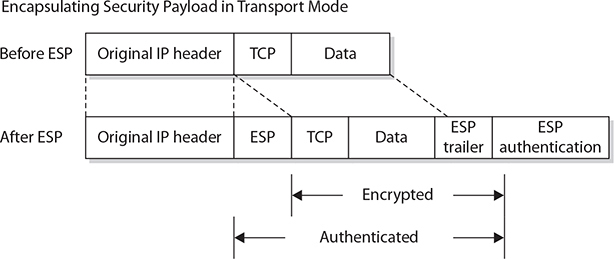
Figure 6-10 IPSec use of ESP in transport mode
AH and ESP
IPSec uses two protocols to provide traffic security:
• Authentication Header (AH)
• Encapsulating Security Payload (ESP)
For key management and exchange, three protocols exist:
• Internet Security Association and Key Management Protocol (ISAKMP)
• Oakley
• Secure Key Exchange Mechanism for Internet (SKEMI)
These key management protocols can be collectively referred to as Internet Key Management Protocol (IKMP) or Internet Key Exchange (IKE).
IPSec does not define specific security algorithms, nor does it require specific methods of implementation. IPSec is an open framework that allows vendors to implement existing industry-standard algorithms suited for specific tasks. This flexibility is key in IPSec’s ability to offer a wide range of security functions. IPSec allows several security technologies to be combined into a comprehensive solution for network-based confidentiality, integrity, and authentication. IPSec uses the following:
• Diffie-Hellman key exchange between peers on a public network
• Public key signing of Diffie-Hellman key exchanges to guarantee identity and avoid man-in-the-middle attacks
• Bulk encryption algorithms, such as IDEA and 3DES, for encrypting data
• Keyed hash algorithms, such as HMAC, and traditional hash algorithms, such as MD5 and SHA-1, for packet-level authentication
• Digital certificates to act as digital ID cards between parties
To provide traffic security, two header extensions have been defined for IP datagrams. The AH, when added to an IP datagram, ensures the integrity of the data and also the authenticity of the data’s origin. By protecting the nonchanging elements in the IP header, the AH protects the IP address, which enables data-origin authentication. The ESP provides security services for the higher-level protocol portion of the packet only, not the IP header.
EXAM TIP IPSec AH protects integrity, but it does not provide privacy. IPSec ESP provides confidentiality, but it does not protect integrity of the packet. To cover both privacy and integrity, both headers can be used at the same time.
AH and ESP can be used separately or in combination, depending on the level and types of security desired. Both also work with the transport and tunnel modes of IPSec protocols.
IPSec uses cryptographic keys in its security process and has both manual and automatic distribution of keys as part of the protocol series. Manual key distribution is included, but it is practical only in small, static environments and does not scale to enterprise-level implementations. The default method of key management, IKE, is automated. IKE authenticates each peer involved in IPSec and negotiates the security policy, including the exchange of session keys. IKE creates a secure tunnel between peers and then negotiates the SA for IPSec across this channel. This is done in two phases: the first develops the channel, and the second the SA.
Split Tunnel vs. Full Tunnel
Split tunnel is a form of VPN where not all traffic is routed via the VPN. Split tunneling allows multiple connection paths, some via the protected route such as the VPN, whereas other traffic from, say, public Internet sources is routed via non-VPN paths. The advantage of split tunneling is the ability to avoid bottlenecks from all traffic having to be encrypted across the VPN. A split tunnel would allow a user private access to information from locations over the VPN and less secure access to information from other sites. The disadvantage is that attacks from the non-VPN side of the communication channel can affect the traffic requests from the VPN side. A full tunnel solution routes all traffic over the VPN, providing protection to all networking traffic.
EXAM TIP For performance-based questions, simply learning the terms associated with VPNs and IPSec in particular is insufficient. You should be familiar with the configuration and use of IPSec components, including types of configurations, and their use to support organizational security.
TLS
Transport Layer Security (TLS), the successor to Secure Sockets Layer (SSL), can be used to exchange keys and create a secure tunnel that enables a secure communications across a public network. TLS-based VPNs have some advantages over IPSec-based VPNs when networks are heavily NAT encoded, because IPSec-based VPNs can have issues crossing multiple NAT domains.
Always-on VPN
One of the challenges associated with VPNs is the establishment of the secure connection. In many cases, this requires additional end-user involvement, either in the form of launching a program, entering credentials, or both. This acts as an impediment to use, as users avoid the extra steps. Always-on VPNs are a means to avoid this issue, through the use of pre-established connection parameters and automation. Always-on VPNs can self-configure and connect once an Internet connection is sensed and provide VPN functionality without user intervention.
NIPS/NIDS
Network-based intrusion detection systems (NIDSs) are designed to detect, log, and respond to unauthorized network or host use, both in real time and after the fact. NIDSs are available from a wide selection of vendors and are an essential part of network security. These systems are implemented in software, but in large systems, dedicated hardware is required as well.
A network-based intrusion prevention system (NIPS) has as its core an intrusion detection system. However, whereas a NIDS can only alert when network traffic matches a defined set of rules, a NIPS can take further actions. A NIPS can take direct action to block an attack, its actions governed by rules. By automating the response, a NIPS significantly shortens the response time between detection and action.
EXAM TIP Recognize that a NIPS has all the same characteristics of a NIDS but, unlike a NIDS, can automatically respond to certain events, such as by resetting a TCP connection, without operator intervention.
Whether network-based or host-based, an IDS will typically consist of several specialized components working together, as illustrated in Figure 6-11. These components are often logical and software-based rather than physical and will vary slightly from vendor to vendor and product to product. Typically, an IDS will have the following logical components:
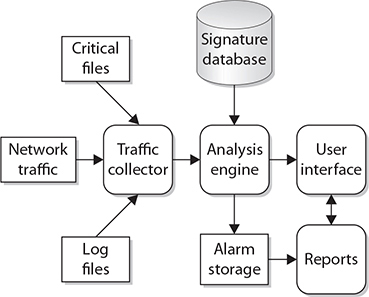
Figure 6-11 Logical depiction of IDS components
• Traffic collector (or sensor) This component collects activity/events for the IDS to examine. On a host-based IDS, this could be log files, audit logs, or traffic coming to or leaving a specific system. On a network-based IDS, this is typically a mechanism for copying traffic off the network link—basically functioning as a sniffer. This component is often referred to as a sensor.
• Analysis engine This component examines the collected network traffic and compares it to known patterns of suspicious or malicious activity stored in the signature database. The analysis engine is the “brains” of the IDS.
• Signature database The signature database is a collection of patterns and definitions of known suspicious or malicious activity.
• User interface and reporting This component interfaces with the human element, providing alerts when appropriate and giving the user a means to interact with and operate the IDS.
Most IDSs can be tuned to fit a particular environment. Certain signatures can be turned off, telling the IDS not to look for certain types of traffic. For example, if you are operating in a pure Linux environment, you may not wish to see Windows-based alarms, as they will not affect your systems. Additionally, the severity of the alarm levels can be adjusted depending on how concerned you are over certain types of traffic. Some IDSs will also allow the user to exclude certain patterns of activity from specific hosts. In other words, you can tell the IDS to ignore the fact that some systems generate traffic that looks like malicious activity, because it really isn’t.
NIDSs/NIPSs can be divided into three categories based on primary methods of detection used: signature-based, heuristic/behavioral-based, and anomaly-based. These are described in the following sections.
Signature-Based
This model relies on a predefined set of patterns (called signatures). The IDS has to know what behavior is considered “bad” ahead of time before it can identify and act upon suspicious or malicious traffic. Signature-based systems work by matching signatures in the network traffic stream to defined patterns stored in the system. Signature-based systems can be very fast and precise, with low false-positive rates. The weakness of signature-based systems is that they rely on having accurate signature definitions beforehand, and as the number of signatures expand, this creates an issue in scalability.
Heuristic/Behavioral
The behavioral model relies on a collected set of “normal behavior”—what should happen on the network and is considered “normal” or “acceptable” traffic. Behavior that does not fit into the “normal” activity categories or patterns is considered suspicious or malicious. This model can potentially detect zero day or unpublished attacks but carries a high false-positive rate because any new traffic pattern can be labeled as “suspect.”
The heuristic model uses artificial intelligence (AI) to detect intrusions and malicious traffic. This is typically implemented through algorithms that help an IDS decide if a traffic pattern is malicious or not. For example, a URL containing a character repeated 10 times may be considered “bad” traffic as a single signature. With a heuristic model, the IDS will understand that if 10 repeating characters is bad, 11 is still bad, and 20 is even worse. This implementation of fuzzy logic allows this model to fall somewhere between signature-based and behavior-based models.
Anomaly
This detection model is similar to behavior-based methods. The IDS is first taught what “normal” traffic looks like and then looks for deviations from those “normal” patterns. An anomaly is a deviation from an expected pattern or behavior. Specific anomalies can also be defined, such as Linux commands sent to Windows-based systems, and implemented via an artificial intelligence–based engine to expand the utility of specific definitions.
Inline vs. Passive
For an NIDS/NIPS to function, it must have a means of examining the network data stream. There are two methods that can be employed, an inline sensor or a passive sensor. An inline sensor monitors the data packets as they actually pass through the device. A failure of an inline sensor would block traffic flow. A passive sensor monitors the traffic via a copying process, so the actual traffic does not flow through or depend upon the sensor for connectivity. Most sensors are passive sensors, but in the case of NIPSs, an inline sensor coupled directly to the NIPS logic allows for the sensor to act as a gate and enable the system to block selected traffic based on rules in the IPS, without additional hardware.
In-Band vs. Out-of-Band
The distinction between in-band and out-of-band NIDS/NIPS is similar to the distinction between inline and passive sensors. An in-band NIDS/NIPS is an inline sensor coupled to a NIDS/NIPS that makes its decisions in-band and enacts changes via the sensor. This has the advantage of high security, but it also has implications related to traffic levels and traffic complexity. In-band solutions work great for protecting network segments that have high-value systems and a limited number of traffic types, such as in front of a set of database servers with serious corporate data, where the only types of access would be via database connections.
An out-of-band system relies on a passive sensor, or set of passive sensors, and has the advantage of greater flexibility in detection across a wider range of traffic types. The disadvantage is the delay in reacting to the positive findings, as the traffic has already passed to the end host.
Rules
NIDS/NIPS solutions make use of an analytics engine that uses rules to determine whether an event of interest has occurred or not. These rules may be simple signature-based rules, such as Snort rules, or they may be more complex Bayesian rules associated with heuristic/behavioral systems or anomaly-based systems. Rules are the important part of the NIDS/NIPS capability equation—without an appropriate rule, the system will not detect the desired condition. One of the things that has to be updated when new threats are discovered is a rule to enable their detection.
EXAM TIP To be prepared for performance-based questions, you should be familiar with the types of NIDS and NIPS configurations and their use to support organizational security.
Analytics
Big data analytics is currently all the rage in the IT industry, with varying claims of how much value can be derived from large datasets. A NIDS/NIPS can certainly create large data sets, especially when connected to other data sources such as log files in a SIEM solution (covered later in this chapter). Using analytics to increase accurate detection of desired events and decrease false positives and false negatives requires planning, testing, and NIDS/NIPS/SIEM solutions that support this level of functionality. In the past, being able to write Snort rules was all that was needed to have a serious NIDS/NIPS solution. Today, it is essential to integrate the data from a NIDS/NIPS with other security data to detect advanced persistent threats (APTs). Analytics is essential today, and tomorrow it will be AI determining how to examine packets.
False Positive
As with all data-driven systems that use a “rule” to determine the presence or absence of an event, there exists a chance of errors in a NIDS/NIPS. If you are testing for the presence of an unauthorized user, and the system says the user is not the authorized person, yet in reality the user is who they say they are, then this is a false positive. The positive result is not really true.
False Negative
False negatives are in essence the opposite of a false positive. If you are looking for a forensic artifact that shows deletion of a file by a user, and the test result is negative, there is no artifact, telling you the user did not delete the file, but in reality they did, then this result is a false negative.
Whenever you get a test result, you should understand the rate of false positives and the rate of false negatives (these rates can be different) and incorporate that information into your decision making based on the test result.
EXAM TIP Understand the specific difference between false-positive and false-negative results with respect to IDS solutions. It is easy to ask this type of question, and depending on the way the question is asked determines the correct solution. Perform the logic on the test presented: What was the expected result? What result was achieved? And compare to reality and see if it was a false positive or false negative.
Router
Routers are network traffic management devices used to connect different network segments together. Routers operate at the network layer of the OSI reference model, routing traffic using the network address and utilizing routing protocols to determine optimal paths across a network. Routers form the backbone of the Internet, moving traffic from network to network, inspecting packets from every communication as they move traffic in optimal paths.
Routers operate by examining each packet, looking at the destination address, and using algorithms and tables to determine where to send the packet next. This process of examining the header to determine the next hop can be done in quick fashion.
One serious operational security issue with routers concerns the access to a router and control of its internal functions. Routers can be accessed using the Simple Network Management Protocol (SNMP) and Telnet/SSH and can be programmed remotely. Because of the geographic separation of routers, this can become a necessity, for many routers in the world of the Internet can be hundreds of miles apart, in separate locked structures. Physical control over a router is absolutely necessary, for if any device, be it server, switch, or router, is physically accessed by a hacker, it should be considered compromised; thus, such access must be prevented. It is important to ensure that the administrative password is never passed in the clear, that only secure mechanisms are used to access the router, and that all of the default passwords are reset to strong passwords. This eliminates methods such as Telnet in managing routers securely; SSH should be used instead.
Just like switches, the most assured point of access for router management control is via the serial control interface port or specific router management Ethernet interface. This allows access to the control aspects of the router without having to deal with traffic-related issues. For internal company networks, where the geographic dispersion of routers may be limited, third-party solutions to allow out-of-band remote management exist. This allows complete control over the router in a secure fashion, even from a remote location, although additional hardware is required.
Routers are available from numerous vendors and come in sizes big and small. A typical small home office router for use with cable modem/DSL service is shown in Figure 6-12. Larger routers can handle traffic of up to tens of gigabytes per second per channel, using fiber-optic inputs and moving tens of thousands of concurrent Internet connections across the network. These routers, which can cost hundreds of thousands of dollars, form an essential part of e-commerce infrastructure, enabling large enterprises such as Amazon and eBay to serve many customers concurrently.

Figure 6-12 A small home office router for cable modem/DSL use
ACLs
Routers use ACLs (access control lists) as a method of deciding whether a packet is allowed to enter the network. With ACLs, it is also possible to examine the source address and determine whether or not to allow a packet to pass. This allows routers equipped with ACLs to drop packets according to rules built in the ACLs. This can be a cumbersome process to set up and maintain, and as the ACL grows in size, routing efficiency can be decreased. It is also possible to configure some routers to act as quasi–application gateways, performing stateful packet inspection and using contents as well as IP addresses to determine whether or not to permit a packet to pass. This can tremendously increase the time for a router to pass traffic and can significantly decrease router throughput. Configuring ACLs and other aspects of setting up routers for this type of use are beyond the scope of this book.
EXAM TIP Establishing and maintaining ACLs can require significant effort. Creating them is a straightforward task, but their judicious use will yield security benefits with a limited amount of maintenance. This can be very important in security zones such as a DMZ and at edge devices, blocking undesired outside contact while allowing known inside traffic.
Antispoofing
One of the persistent problems at edge devices is verifying that the source IP address on a packet matches the expected source IP address at the interface. Many DDoS attacks rely upon bots sending packets with spoofed IP addresses. Antispoofing measures are performed to prevent this type of attack from happening. When a machine in your network begins sending packets with incorrect source IP addresses, one of the primary actions that the gateway router should perform is to recognize that the source IP address on a packet does not match the assigned IP address space for the interface, and not send the packet. In this case, the router should drop the packet. Enabling source IP checking on routers at the edge of networks is done using networking commands associated with your router’s OS, and these commands will vary between vendors, but all vendors support this functionality. It is important to enable source IP checking to prevent spoofing from propagating across a network.
Switch
A switch forms the basis for connections in most Ethernet-based local area networks (LANs). Although hubs and bridges still exist, in today’s high-performance network environment, switches have replaced both. A switch has separate collision domains for each port. This means that for each port, two collision domains exist: one from the port to the client on the downstream side and one from the switch to the network upstream. When full duplex is employed, collisions are virtually eliminated from the two nodes, host and client. This also acts as a security factor in that a sniffer can see only limited traffic, as opposed to a hub-based system, where a single sniffer can see all of the traffic to and from connected devices.
One of the security concerns with switches is that, like routers, they are intelligent network devices and are therefore subject to hijacking by hackers. Should a hacker break into a switch and change its parameters, he might be able to eavesdrop on specific or all communications, virtually undetected. Switches are commonly administered using the SNMP and Telnet protocols, both of which have a serious weakness in that they send passwords across the network in clear text. Just as in the case with routers, secure administrative connections should be by SSH rather than Telnet to prevent clear text transmission of critical data such as passwords.
EXAM TIP Simple Network Management Protocol (SNMP) provides management functions to many network devices. SNMPv1 and SNMPv2 authenticate using a cleartext password, allowing anyone monitoring packets to capture the password and have access to the network equipment. SNMPv3 adds cryptographic protections, making it a preferred solution.
A hacker armed with a sniffer that observes maintenance on a switch can capture the administrative password. This allows the hacker to come back to the switch later and configure it as an administrator. An additional problem is that switches are shipped with default passwords, and if these are not changed when the switch is set up, they offer an unlocked door to a hacker. Commercial-quality switches have a local serial console port or a management Ethernet interface for guaranteed access to the switch for purposes of control. Some products in the marketplace enable an out-of-band network, using these dedicated channels to enable remote, secure access to programmable network devices.

CAUTION To secure a switch, you should disable all access protocols other than a secure serial line or a secure protocol such as Secure Shell (SSH). Using only secure methods to access a switch will limit the exposure to hackers and malicious users. Maintaining secure network switches is even more important than securing individual boxes, for the span of control to intercept data is much wider on a switch, especially if it’s reprogrammed by a hacker.
Port Security
Switches can also perform a variety of security functions. Switches work by moving packets from inbound connections to outbound connections. While moving the packets, it is possible for switches to inspect the packet headers and enforce security policies. Port security is a capability provided by switches that enables you to control which devices and how many of them are allowed to connect via each port on a switch. Port security operates through the use of MAC addresses. Although not perfect—MAC addresses can be spoofed—port security can provide useful network security functionality.
Port address security based on Media Access Control (MAC) addresses can determine whether a packet is allowed or blocked from a connection. This is the very function that a firewall uses for its determination, and this same functionality is what allows an 802.1X device to act as an “edge device.”
Port security has three variants:
• Static learning A specific MAC address is assigned to a port. This is useful for fixed, dedicated hardware connections. The disadvantage is that the MAC addresses need to be known and programmed in advance, making this good for defined connections but not good for visiting connections.
• Dynamic learning Allows the switch to learn MAC addresses when they connect. Dynamic learning is useful when you expect a small, limited number of machines to connect to a port.
• Sticky learning Also allows multiple devices to a port, but also stores the information in memory that persists through reboots. This prevents the attacker from changing settings through power cycling the switch.
Layer 2 vs. Layer 3
Switches operate at the data link layer of the OSI model, while routers act at the network layer. For intranets, switches have become what routers are on the Internet—the device of choice for connecting machines. As switches have become the primary network connectivity device, additional functionality has been added to them. A switch is usually a layer 2 device, operating at the data link layer, but layer 3 switches that operate at the network layer can incorporate routing functionality.
Loop Prevention
Switches operate at layer 2 of the OSI model, and at this level there is no countdown mechanism to kill packets that get caught in loops or on paths that will never resolve. This means that another mechanism is needed for loop prevention. The layer 2 space acts as a mesh, where potentially the addition of a new device can create loops in the existing device interconnections. Open Shortest Path First (OSPF) is a link-state routing protocol that is commonly used between gateways in a single autonomous system. To prevent loops, a technology called spanning trees is employed by virtually all switches. The Spanning Tree Protocol (STP) allows for multiple, redundant paths, while breaking loops to ensure a proper broadcast pattern. STP is a data link layer protocol, and is approved in IEEE standards 802.1D, 802.1w, 802.1s, and 802.1Q. It acts by trimming connections that are not part of the spanning tree connecting all of the nodes.
Flood Guard
One form of attack is a flood. There are numerous types of flooding attacks: ping floods, SYN floods, ICMP floods (Smurf attacks), and traffic flooding. Flooding attacks are used as a form of denial of service to a network or system. Detecting flooding attacks is relatively easy, but there is a difference between detecting the attack and mitigating the attack. Flooding can be actively managed through dropping connections or managing traffic. Flood guards act by managing traffic flows. By monitoring the traffic rate and percentage of bandwidth occupied by broadcast, multicast, and unicast traffic, a flood guard can detect when to block traffic to manage flooding.
EXAM TIP Flood guards are commonly implemented in firewalls and IDS/IPS solutions to prevent DoS and DDoS attacks.
Proxy
Though not strictly a security tool, a proxy server can be used to filter out undesirable traffic and prevent employees from accessing potentially hostile websites. A proxy server takes requests from a client system and forwards them to the destination server on behalf of the client. Several major categories of proxy servers are described in the following sections.
Deploying a proxy solution within a network environment is usually done either by setting up the proxy and requiring all client systems to configure their browsers to use the proxy or by deploying an intercepting proxy that actively intercepts all requests without requiring client-side configuration.
From a security perspective, proxies are most useful in their ability to control and filter outbound requests. By limiting the types of content and websites employees can access from corporate systems, many administrators hope to avoid loss of corporate data, hijacked systems, and infections from malicious websites. Administrators also use proxies to enforce corporate acceptable use policies and track use of corporate resources.
Forward and Reverse Proxy
Proxies can operate in two directions. A forward proxy operates to forward requests to servers based on a variety of parameters, as described in the other portions of this section. A reverse proxy is typically installed on the server side of a network connection, often in front of a group of web servers, and intercepts all incoming web requests. It can perform a number of functions, including traffic filtering, Secure Sockets Layer (SSL)/Transport Layer Security (TLS) decryption, serving of common static content such as graphics, and performing load balancing.
Transparent
Proxy servers can be completely transparent (these are usually called gateways or tunneling proxies), or they can modify the client request before sending it on or even serve the client’s request without needing to contact the destination server.
Application/Multipurpose
Proxies can come in many forms, two of which are application proxies and multipurpose proxies. Application proxies act as proxies for a specific application only, while multipurpose proxies act as a proxy for multiple systems or purposes. Proxy servers can provide a wide range of services in a system including:
• Anonymizing proxy An anonymizing proxy is designed to hide information about the requesting system and make a user’s web browsing experience “anonymous.” This type of proxy service is often used by individuals concerned with the amount of personal information being transferred across the Internet and the use of tracking cookies and other mechanisms to track browsing activity.
• Caching proxy This type of proxy keeps local copies of popular client requests and is often used in large organizations to reduce bandwidth usage and increase performance. When a request is made, the proxy server first checks to see whether it has a current copy of the requested content in the cache; if it does, it services the client request immediately without having to contact the destination server. If the content is old or the caching proxy does not have a copy of the requested content, the request is forwarded to the destination server.
• Content-filtering proxy Content-filtering proxies examine each client request and compare it to an established acceptable use policy (AUP). Requests can usually be filtered in a variety of ways, including by the requested URL, the destination system, or the domain name or by keywords in the content itself. Content-filtering proxies typically support user-level authentication so access can be controlled and monitored and activity through the proxy can be logged and analyzed. This type of proxy is very popular in schools, corporate environments, and government networks.
• Open proxy An open proxy is essentially a proxy that is available to any Internet user and often has some anonymizing capabilities as well. This type of proxy has been the subject of some controversy, with advocates for Internet privacy and freedom on one side of the argument, and law enforcement, corporations, and government entities on the other side. As open proxies are often used to circumvent corporate proxies, many corporations attempt to block the use of open proxies by their employees.
• Web proxy A web proxy is solely designed to handle web traffic and is sometimes called a web cache. Most web proxies are essentially specialized caching proxies.
Load Balancer
Certain systems, such as servers, are more critical to business operations and should therefore be the object of fault-tolerance measures. A common technique that is used in fault tolerance is load balancing through the use of a load balancer, which move loads across a set of resources in an effort not to overload individual servers. This technique is designed to distribute the processing load over two or more systems. It is used to help improve resource utilization and throughput but also has the added advantage of increasing the fault tolerance of the overall system since a critical process may be split across several systems. Should any one system fail, the others can pick up the processing it was handling. While there may be an impact to overall throughput, the operation does not go down entirely. Load balancing is often utilized for systems handling websites, high-bandwidth file transfers, and large Internet Relay Chat (IRC) networks. Load balancing works by a series of health checks that tell the load balancer which machines are operating, and by a scheduling mechanism to spread the work evenly. Load balancing is best for stateless systems, as subsequent requests can be handled by any server, not just the one that processed the previous request.
Scheduling
When a load balancer move loads across a set of resources, it decides which machine gets a request via a scheduling algorithm. There are a couple of commonly used scheduling algorithms: affinity-based scheduling and round-robin scheduling.
Affinity
Affinity-based scheduling is designed to keep a host connected to the same server across a session. Some applications, such as web applications, can benefit from affinity-based scheduling. The method used by affinity-based scheduling is to have the load balancer keep track of where it last balanced a particular session and direct all continuing session traffic to the same server. If it is a new connection, the load balancer establishes a new affinity entry and assigns the session to the next server in the available rotation.
Round-Robin
Round-robin scheduling involves sending each new request to the next server in rotation. All requests are sent to servers in equal amounts, regardless of the server load. Round-robin schemes are frequently modified with a weighting factor to take server load or other criteria into account when assigning the next server.
Active-Passive
For high-availability solutions, having a single load balancer creates a single point of failure. It is common to have multiple load balancers involved in the balancing work. In an active-passive scheme, the primary load balancer is actively doing the balancing while the secondary load balancer passively observes and is ready to step in at any time the primary system fails.
Active-Active
In an active-active scheme, all the load balancers are active, sharing the load balancing duties. Active-active load balancing can have performance efficiencies, but it is important to watch the overall load. If the overall load cannot be covered by N – 1 load balancers (i.e., one fails), then failure of a load balancer will lead to session interruption and traffic loss. Without a standby passive system to recover the lost load, the system will trim load based on capacity, dropping requests that the system lacks capacity to service.
Virtual IPs
In a load balanced environment, the IP addresses for the target servers of a load balancer will not necessarily match the address associated with the router sending the traffic. Load balancers handle this through the concept of virtual IP addresses, virtual IPs, that allow for multiple systems to be reflected back as a single IP address.
EXAM TIP Preparing for performance-based questions requires more than simply learning the terms associated with network-based security solutions such as routers, switches, proxies, and load balancers. You should be familiar with the configuration and use of these components against specific threats such as spoofing, loops, floods, and traffic issues. Understanding how and when to configure each device based on a scenario is important and testable.
Access Point
Wireless access points are the point of entry and exit for radio-based network signals into and out of a network. As wireless has become more capable in all aspects of networking, wireless-based networks are replacing cabled, or wired, solutions. In this scenario, one could consider the access point to be one half of a network interface card (NIC), with the other half being the wireless card in a host.
SSID
The 802.11 protocol designers expected some security concerns and attempted to build provisions into the 802.11 protocol that would ensure adequate security. The 802.11 standard includes attempts at rudimentary authentication and confidentiality controls. Authentication is handled in its most basic form by the 802.11 access point (AP), forcing the clients to perform a handshake when attempting to “associate” to the AP. Association is the process required before the AP will allow the client to talk across the AP to the network.
The authentication function is known as the service set identifier (SSID). This unique 32-character identifier is attached to the header of the packet. Association occurs only if the client has all the correct parameters needed in the handshake, among them the SSID. This SSID setting should limit access to only authorized users of the wireless network. The SSID is broadcast by default as a network name, but broadcasting this beacon frame can be disabled. Many APs also use a default SSID; for example, for many versions of Cisco APs, this default is tsunami, which can indicate an AP that has not been configured for any security. Renaming the SSID and disabling SSID broadcast are both good ideas; however, because the SSID is part of every frame, these measures should not be considered securing the network. As the SSID is, hopefully, a unique identifier, only people who know the identifier will be able to complete association to the AP.
While the SSID is a good idea in theory, it is sent in plaintext in the packets, so in practice the SSID offers little security significance—any sniffer can determine the SSID, and many operating systems—Windows XP and later, for instance—will display a list of SSIDs active in the area and prompt the user to choose which one to connect to. This weakness is magnified by most APs’ default settings to transmit beacon frames. The beacon frame’s purpose is to announce the wireless network’s presence and capabilities so that WLAN cards can attempt to associate to it. This can be disabled in software for many APs, especially the more sophisticated ones. From a security perspective, the beacon frame is damaging because it contains the SSID, and this beacon frame is transmitted at a set interval (ten times per second by default). Since a default AP without any other traffic is sending out its SSID in plaintext ten times a second, you can see why the SSID does not provide true authentication. Scanning programs such as NetStumbler work by capturing the beacon frames, and thereby the SSIDs, of all APs.
EXAM TIP Although not considered the strongest security measures, renaming the SSID and disabling SSID broadcast are important concepts to know for the exam.
MAC Filtering
MAC filtering is the selective admission of packets based on a list of approved Media Access Control (MAC) addresses. Employed on switches, this method is used to provide a means of machine authentication. In wired networks, this enjoys the protection afforded by the wires, making interception of signals to determine their MAC addresses difficult. In wireless networks, this same mechanism suffers from the fact that an attacker can see the MAC addresses of all traffic to and from the access point, and then can spoof the MAC addresses that are permitted to communicate via the access point.
EXAM TIP MAC filtering can be employed on wireless access points, but can be bypassed by attackers observing allowed MAC addresses and spoofing the allowed MAC address for the wireless card.
Signal Strength
The usability of a wireless signal is directly related to its signal strength. Too weak of a signal and the connection can drop out or lose data. Signal strength can be influenced by a couple of factors: the transmitting power level and the environment across which the signal is transmitted. In buildings with significant metal in the walls and roofs, additional power may be needed to have sufficient signal strength at the receivers. Wi-Fi power levels can be controlled by the hardware for a variety of reasons. The lower the power used, the less the opportunity for interference. But if the power levels are too low, then signal strength limits range. Access points can have the power level set either manually or via programmatic control. For most users, power level controls are not very useful, and leaving the unit in default mode is the best option. In complex enterprise setups, with site surveys and planned overlapping zones, this aspect of signal control can be used to increase capacity and control on the network.
Band Selection/Width
In today’s wireless environments, there are multiple different bands employed, each with different bandwidths. Band selection may seem trivial, but with 802.11a, b/g, n, and ac radios, the deployment of access points should support the desired bands based on client needs. Multiband radio access points exist and are commonly employed to resolve these issues. Wi-Fi operates over two different frequencies, 2.4 GHz for b/g and n, and 5 GHz for a, n, and ac.
Antenna Types and Placement
Wi-Fi is by nature a radio-based method of communication, and as such uses antennas to transmit and receive the signals. The actual design and placement of the antennas can have a significant effect on the usability of the radio frequency (RF) medium for carrying the traffic.
Antennas come in a variety of types, each with its own transmission pattern and gain factor. Gain is a measurement of antenna efficiency. High-gain antennas can deal with weaker signals, but also have more-limited coverage. Wide-coverage, omnidirectional antennas can cover wider areas, but at lower levels of gain. The objective of antenna placement is to maximize the coverage over a physical area and reduce low-gain areas. This can be very complex in buildings with walls, electrical interference, and other sources of interference and frequently requires a site survey to determine proper placement.
EXAM TIP Because wireless antennas can transmit outside a facility, tuning and placement of antennas can be crucial for security. Adjusting radiated power through the power level controls will assist in keeping wireless signals from being broadcast outside areas under physical access control.
The standard access point is equipped with an omnidirectional antenna. Omnidirectional antennas operate in all directions, making the relative orientation between devices less important. Omnidirectional antennas cover the greatest area per antenna. The weakness occurs in corners and hard-to-reach areas, as well as boundaries of a facility where directional antennas are needed to complete coverage. Figure 6-13 shows a sampling of common Wi-Fi antennas: 6-13(a) is a common home wireless router, (b) is a commercial indoor wireless access point (WAP), and (c) is an outdoor directional antenna. Indoor WAPs can be visible as shown, or hidden above ceiling tiles.

Figure 6-13 Wireless access point antennas
Wireless networking problems caused by weak signal strength can sometimes be solved by installing upgraded Wi-Fi radio antennas on the access points. On business networks, the complexity of multiple access points typically requires a comprehensive site survey to map the Wi-Fi signal strength in and around office buildings. Additional wireless access points can then be strategically placed where needed to resolve dead spots in coverage. For small businesses and homes, where a single access point may be all that is needed, an antenna upgrade may be a simpler and more cost-effective option to fix Wi-Fi signal problems.
Two common forms of upgraded antennas are the Yagi antenna and the panel antenna. An example of a Yagi antenna is shown in Figure 6-13(c). Both Yagi and panel antennas are directional in nature, spreading the RF energy in a more limited field, increasing effective range in one direction while limiting it in others. Panel antennas can provide solid room performance while preventing signal bleed behind the antennas. This works well on the edge of a site, limiting the stray emissions that could be captured offsite. Yagi antennas act more like a rifle, funneling the energy along a beam. This allows much longer communication distances using standard power. This also enables eavesdroppers to capture signals from much greater distances because of the gain provided by the antenna itself.
Fat vs. Thin
Fat (or thick) access points are standalone access points, while thin access points are controller-based access points. These solutions differ in their handling of common functions such as configuration, encryption, updates, and policy settings. Determining which is more effective requires a closer examination of the difference, presented in the next section, and a particular site’s needs and budget.
Controller-Based vs. Standalone
Small standalone Wi-Fi access points can have substantial capabilities with respect to authentication, encryption, and even, to a degree, channel management. These are also called fat or thick controllers, referring to the level of work the AP performs. As the wireless deployment grows in size and complexity, there are some advantages to a controller-based access point solution. Controller-based, or thin AP, solutions allow for centralized management and control, which can facilitate better channel management for adjacent access points, better load balancing, and easier deployment of patches and firmware updates. From a security standpoint, controller-based solutions offer large advantages in overall network monitoring and security controls. In large-scale environments, controller-based access points can enable network access control (NAC, discussed later in the chapter) based on user identity, managing large sets of users in subgroups. Internet access can be blocked for some users (e.g., clerks), while internal access can be blocked for others (e.g., guests).
SIEM
Security Information and Event Management (SIEM) systems are a combination of hardware and software designed to classify and analyze security data from numerous sources. SIEMs were once considered to be appropriate only for the largest of enterprises, but nowadays the large number of data sources associated with security have made SIEMs essential in almost all security organizations. There is a wide range of vendor offerings in this space, from virtually free to systems large enough to handle any enterprise, with a budget to match.
Aggregation
One of the key functions of a SIEM solution is the aggregation of security information sources. In this instance, aggregation refers to the collecting of information in a central place, in a common format, to facilitate analysis and decision making. The sources that can feed a SIEM are many, including system event logs, firewall logs, security application logs, and specific program feeds from security appliances. Having this material in a central location that facilitates easy exploration by a security analyst is very useful during incident response events.
Correlation
Correlation is the connection of events based on some common basis. Events can correlate based on time, based on common events, based on behaviors, and so on. Although correlation is not necessarily causation, it is still useful to look for patterns, and then use these patterns to find future issues. Many activities are multistep events and determining their presence before they get to the end of their cycle and commit the final act, or early detection, is one of the values of correlation. Correlation can identify things like suspicious IP addresses based on recent behavior. For instance, a correlation rule can identify port scanning, a behavior that in and of itself is not hostile but also is not normal, hence future activity from that IP address would be considered suspect. SIEMs can use multiple rules and patterns with correlation to provide earlier warning of hostile activity.
Automated Alerting and Triggers
SIEMs have the ability through a set of rules and the use of analytical engines to identify specific predetermined patterns and either issue an alert or react to them. Automated alerting can remove much of the time delay between specific activity and security operations reaction. Consider a SIEM like an IDS on steroids, for it can use external information in addition to current traffic information to provide a much richer pattern-matching environment. A trigger event, such as the previously mentioned scanning activity, or the generation of ACL failures in log events, can result in the SIEM highlighting a connection on an analyst’s workstation or, in some cases, responding automatically.
Time Synchronization
Time synchronization is a common problem for computer systems. When multiple systems handle aspects of a particular transaction, having a common time standard for all the systems is essential if you want to be able to compare their logs. This problem becomes even more pronounced when an enterprise has geographically dispersed operations across multiple time zones. Most systems record things in local time, and when multiple time zones are involved, analysts need to be able to work with two time readings synchronously: local time and UTC time. UTC (Coordinated Universal Time) is a global time standard and does not have the issues of daylight saving settings, or even different time zones. UTC is in essence a global time zone. Local time is still important to compare events to local activities. SIEMs can handle both time readings simultaneously, using UTC for correlation across the entire enterprise, and local time for local process meaning.
Event Deduplication
In many cases, multiple records related to the same event can be generated. For example, an event may be noted in both the firewall log and the system log file. As another example, NetFlow data, because of how and where it is generated, is full of duplicate records for the same packet. Having multiple records in a database representing the same event wastes space and processing and can skew analytics. To avoid these issues, SIEMs use a special form of correlation to determine which records are duplicates of a specific event, and then delete all but a single record. This event deduplication assists security analysts by reducing clutter in a dataset that can obscure real events that have meaning. For this to happen, the events records require a central store, something a SIEM solution provides.
EXAM TIP To answer questions regarding how and why an organization would use a SIEM system, keep in mind that SIEMS are designed to aggregate information, correlate events, synchronize times, and deduplicate records/events from numerous systems for the purpose of expediting automated detection, alerting, and triggers.
Logs/WORM
Log files, or logs, exist across a wide array of sources, and have a wide range of locations and details recorded. One of the valuable features of a SIEM solution is the capability to collect these disparate data sources into a standardized data structure that security administrators can then exploit using database tools to create informative reports. Logs are written once into this SIEM datastore, and then can be read many times by different rules and analytical engines for different decision-support processes. This write once read many (WORM) concept is commonly employed to achieve operational efficiencies, especially when working with large data sets, such as log files on large systems.
DLP
Data loss prevention (DLP) refers to technology employed to detect and prevent transfers of data across an enterprise. Employed at key locations, DLP technology can scan packets for specific data patterns. This technology can be tuned to detect account numbers, secrets, specific markers, or files. When specific data elements are detected, the system can block the transfer. The primary challenge in employing DLP technologies is the placement of the sensor. The DLP sensor needs to be able observe the data, so if the channel is encrypted, DLP technology can be thwarted.
USB Blocking
USB devices offer a convenient method of connecting external storage to a system and an easy means of moving data between machines. They also provide a means by which data can be infiltrated from a network by an unauthorized party. There are numerous methods of performing USB blocking, from the extreme of physically disabling the ports, to software solutions that enable a wide range of controls. Most enterprise-level DLP solutions include a means of blocking or limiting USB devices. Typically, this involves preventing the use of USB devices for transferring data to the device without specific authorization codes. This acts as a barrier, allowing USBs to import data but not export data.
Cloud-Based
As data moves to the cloud, so does the need for data loss prevention. But performing cloud-based DLP is not a simple matter of moving the enterprise edge methodology to the cloud. There are several attributes of cloud systems that can result in issues for DLP deployments. Enterprises move data to the cloud for many reasons, but two primary ones are size (cloud data sets can be very large) and availability (cloud-based data can be highly available across the entire globe to multiple parties), and both of these are challenges for DLP solutions. The DLP industry has responded with cloud-based DLP solutions designed to manage these and other cloud-related issues while still affording the enterprise visibility and control over data transfers.
E-mail is a common means of communication in the enterprise, and files are commonly attached to e-mail messages to provide additional information. Transferring information out of the enterprise via e-mail attachments is a concern for many organizations. Blocking e-mail attachments is not practical given their ubiquity in normal business, so a solution is needed to scan e-mails for unauthorized data transfers. This is a common chore for enterprise-class DLP solutions, which can connect to the mail server and use the same scanning technology used for other network connections.
EXAM TIP DLP has become integral in enterprises, is widespread, and has several aspects that can be tested on the exam. DLP solutions can include e-mail solutions, USB solutions, and cloud solutions. DLPs detect the data is moving somewhere using different hooks to block the different paths (file transfers, to and from cloud, e-mail). Read the question carefully to determine what is specifically being asked.
NAC
Networks comprise connected workstations and servers. Managing security on a network involves managing a wide range of issues related not only to the various connected hardware but also to the software operating those devices. Assuming that the network is secure, each additional connection involves risk. Managing the endpoints on a case-by-case basis as they connect is a security methodology known as network access control (NAC). Two main competing methodologies exist: Network Access Protection (NAP) is a Microsoft technology for controlling network access to a computer host, and Network Admission Control (NAC) is Cisco’s technology for controlling network admission.
Microsoft’s NAP system is based on measuring the system health of the connecting machine, including patch levels of the OS, antivirus protection, and system policies. NAP was first utilized in Windows XP Service Pack 3, Windows Vista, and Windows Server 2008, and it requires additional infrastructure servers to implement the health checks. The system includes enforcement agents that interrogate clients and verify admission criteria. The client side is initiated whenever network connections are made. Response options include rejection of the connection request or restriction of admission to a subnet.
Cisco’s NAC system is built around an appliance that enforces policies chosen by the network administrator. A series of third-party solutions can interface with the appliance, allowing the verification of a whole host of options, including client policy settings, software updates, and client security posture. The use of third-party devices and software makes this an extensible system across a wide range of equipment.
Neither Cisco NAC nor Microsoft NAP is widely adopted across enterprises. The client pieces are all in place, but enterprises have been slow to fully deploy the server side of this technology. The concept of automated admission checking based on client device characteristics is here to stay, as it provides timely control in the ever-changing network world of today’s enterprises. With the rise of bring your own device (BYOD) policies in organizations, there is renewed interest in using NAC to assist in protecting the network from unsafe devices.
EXAM TIP For the Security+ exam, the term NAC refers to network access control. The Microsoft and Cisco solutions referenced in this section are examples of this type of control—their names and acronyms are not relevant to the exam. The concept of NAC and what it accomplishes is relevant and testable.
Dissolvable vs. Permanent
The use of NAC technologies requires an examination of a host before allowing it to connect to the network. This examination is performed by a piece of software, frequently referred to as an agent. Agents can be permanently deployed to hosts, so that the functionality is already in place, or provided on an as-needed basis by the endpoint at time of use. When agents are predeployed to endpoints, these permanent agents act as the gateway to NAC functionality. One of the first checks is agent integrity, then machine integrity. In cases where deployment on an as-needed basis is chosen, an agent can be deployed upon request and later discarded after use. These agents are frequently referred to as dissolvable agents, for they in essence disappear after use.
Host Health Checks
One of the key benefits of a NAC solution is the ability to enforce a specific level of host health checks on clients before they are admitted to the network. Some common host health checks include verifying an antivirus solution is present, has the latest patches, and has been run recently, and verifying that the OS and applications are patched. The policy options vary based on implementation, but a client that does not pass the health checks can be denied connection to the network, forced to have its health fixed before connection, or placed on a separate isolated network segment.
Agent vs. Agentless
In recognition that deploying agents to machines can be problematic in some instances, vendors have also developed agentless solutions for NAC. Rather than have the agent wait on the host for activation and use, the agent can operate from within the network itself, rendering the host in effect agentless. In agent-based solutions, code is stored on the host machine for activation and use at time of connection. In agentless solutions, the code resides on the network and is deployed to memory for use in a machine requesting connections, but since it never persists on the host machine, it is referred to as agentless. In most instances, there is no real difference in the performance of agent versus agentless solutions when properly deployed. The real difference comes in the issues of having agents on boxes versus persistent network connections for agentless.
Mail Gateway
E-mail is one of the reasons for connecting networks together, and mail gateways can act as solutions to handle mail-specific traffic issues. Mail gateways are used to process e-mail packets on a network, providing a wide range of e-mail-related services. From filtering spam, to managing data loss, to handling the encryption needs, mail gateways are combinations of hardware and software optimized to perform these tasks in the enterprise.
Spam Filter
The bane of users and system administrators everywhere, spam is essentially unsolicited and undesired bulk electronic messages. While typically conveyed via e-mail, spam can be transmitted via text message to phones and mobile devices, as postings to Internet forums, and by other means. If you’ve ever used an e-mail account, chances are you’ve received spam. Enter the concept of the spam filterg, software that is designed to identify and remove spam traffic from an e-mail stream as it passes through the mail gateway.
From a productivity and security standpoint, spam costs businesses and users billions of dollars each year, and it is such a widespread problem that the U.S. Congress passed the CAN-SPAM Act of 2003 to empower the Federal Trade Commission to enforce the act and the Department of Justice to enforce criminal sanctions against spammers. The act establishes requirements for those who send commercial e-mail, spells out penalties for spammers and companies whose products are advertised in spam if they violate the law, and gives consumers the right to ask spammers to stop spamming them. Despite all our best efforts, however, spam just keeps coming; as the technologies and techniques developed to stop the spam get more advanced and complex, so do the tools and techniques used to send out the unsolicited messages.
Here are a few of the more popular methods used to fight the spam epidemic; most of these techniques are used to filter e-mail but could be applied to other mediums as well:
• Blacklisting Blacklisting is essentially noting which domains and source addresses have a reputation for sending spam, and rejecting messages coming from those domains and source addresses. This is basically a permanent “ignore” or “call block” type capability. Several organizations and a few commercial companies provide lists of known spammers.
• Content or keyword filtering Similar to Internet content filtering, this method filters e-mail messages for undesirable content or indications of spam. Much like content filtering of web content, filtering e-mail based on something like keywords can cause unexpected results, as certain terms can be used in both legitimate and spam e-mail. Most content-filtering techniques use regular expression matching for keyword filtering.
• Trusted servers The opposite of blacklisting, a trusted server list includes SMTP servers that are being “trusted” not to forward spam.
• Delay-based filtering Some SMTP servers are configured to insert a deliberate pause between the opening of a connection and the sending of the SMTP server’s welcome banner. Some spam-generating programs do not wait for that greeting banner, and any system that immediately starts sending data as soon as the connection is opened is treated as a spam generator and dropped by the SMTP server.
• PTR and reverse DNS checks Some e-mail filters check the origin domain of an e-mail sender. If the reverse checks show the mail is coming from a dial-up user, home-based broadband, or a dynamically assigned address, or has a generic or missing domain, then the filter rejects it, as these are common sources of spam messages.
• Callback verification Because many spam messages use forged “from” addresses, some filters attempt to validate the “from” address of incoming e-mail. The receiving server can contact the sending server in an attempt to validate the sending address, but this is not always effective, as spoofed addresses are sometimes valid e-mail addresses that can be verified.
• Statistical content filtering Statistical filtering is much like a document classification system. Users mark received messages as either spam or legitimate mail and the filtering system learns from the users’ input. The more messages that are seen and classified as spam, the better the filtering software should get at intercepting incoming spam. Spammers counteract many filtering technologies by inserting random words and characters into the messages, making it difficult for content filters to identify patterns common to spam.
• Rule-based filtering Rule-based filtering is a simple technique that merely looks for matches in certain fields or keywords. For example, a rule-based filtering system may look for any message with the words “get rich” in the subject line of the incoming message. Many popular e-mail clients have the ability to implement rule-based filtering.
• Egress filtering Some organizations perform spam filtering on e-mail leaving their organization as well, and this is called egress filtering. The same types of anti-spam techniques can be used to validate and filter outgoing e-mail in an effort to combat spam.
• Hybrid filtering Most commercial anti-spam methods use hybrid filtering, a combination of several different techniques, to fight spam. For example, a filtering solution may take each incoming message and match it against known spammers, then against a rule-based filter, then a content filter, and finally against a statistical-based filter. If the message passes all filtering stages, it will be treated as a legitimate message; otherwise, it is rejected as spam.
Much spam filtering is done at the network or SMTP server level. It’s more efficient to scan all incoming and outgoing messages with a centralized solution than it is to deploy individual solutions on user desktops throughout the organization. E-mail is essentially a proxied service by default: messages generally come into and go out of an organization’s mail server. (Users don’t typically connect to remote SMTP servers to send and receive messages, but they can.) Anti-spam solutions are available in the form of software that is loaded on the SMTP server itself or on a secondary server that processes messages either before they reach the SMTP server or after the messages are processed by the SMTP server. Anti-spam solutions are also available in appliance form, where the software and hardware are a single integrated solution. Many centralized anti-spam methods allow individual users to customize spam filtering for their specific inbox, specifying their own filter rules and criteria for evaluating inbound e-mail.
The central issue with spam is that, despite all the effort placed into building effective spam filtering programs, spammers continue to create new methods for flooding inboxes. Spam filtering solutions are good, but are far from perfect, and continue to fight the constant challenge of allowing in legitimate messages while keeping the spam out. The lack of central control over Internet traffic also makes anti-spam efforts more difficult. Different countries have different laws and regulations governing e-mail, which range from draconian to nonexistent. For the foreseeable future, spam will continue to be a burden to administrators and users alike.
DLP
As mentioned previously, data loss prevention (DLP) is also an issue for outgoing mail, particularly e-mail attachments. There are two options for preventing the loss of data via e-mail: use an integrated DLP solution that scans both outgoing traffic and mail, or use a separate standalone system that scans only e-mail. The disadvantage of using a separate standalone system is that it requires maintaining two separate DLP keyword lists. Most enterprise-level DLP solutions have built-in gateway methods for integration with mail servers to facilitate outgoing mail scanning. This allows outgoing mail traffic to be checked against the same list of keywords that other outgoing traffic is scanned against.
Encryption
E-mail is by default a plaintext protocol, making e-mail and e-mail attachments subject to eavesdropping anywhere between sender and receiver. E-mail encryption can protect e-mail from eavesdropping as well as add authentication services. Encrypting e-mail has been a challenge for enterprises, not because the process of encryption is difficult, but due to the lack of a uniform standardized protocol that would allow complete automation of the process, making it transparent to users.
Many e-mail encryption solutions exist, from add-in programs, such as Pretty Good Privacy (PGP) and others, to encryption gateways that handle the process post-mail server, or after the e-mail has passed through the mail server. Each solution has its challenges and limitations, including compatibility across other systems (both sender and receiver have to have the same support). Using the built-in S/MIME (Secure/Multipurpose Internet Mail Extensions) standard provides a means for public key infrastructure (PKI) use across e-mail channels, but challenges still remain. Specifically, to use PKI, one relies upon certificates on both sides, and the passing of certificates, and the maintenance of certificate stores across an enterprise can lead to challenges. This is alleviated within an organization, as the enterprise can handle the certificates. In enterprise situations, there are PKI handlers to handle the certificates, but to standalone external users, the handling of certificates is a challenge that continues to exist.
EXAM TIP E-mail is ubiquitous and has its own set of security issues. Mail gateways can act as a focal point for security concerns, so whether it is spam filtering, DLP functionality, or encryption and signing, it can be accomplished at a mail gateway.
Bridge
A bridge is a network segregation device that operates at layer 2 of the OSI model. It operates by connecting two separate network segments and allows communication between the two segments based on the layer 2 address on a packet. Separating network traffic into separate communication zones can enhance security. Traffic can be separated using bridges, switches, and VLANs. Traffic separation prevents sensitive traffic from being sniffed by limiting the range over which the traffic travels. Keeping highly sensitive traffic separated from areas of the network where less trusted traffic and access may occur prevents the inadvertent disclosure by traffic interception. Network separation can be used to keep development, testing, and production networks separated, preventing accidental cross-pollination of changes.
SSL/TLS Accelerators
The process of encrypting traffic per SSL/TLS protocols can be a computer-intensive effort. For large-scale web servers, this becomes a bottleneck in the throughput of the web server. Rather than continue to use larger and larger servers for web pages, organization with significant SSL/TLS needs use a specialized device that is specifically designed to handle the computations. This device, called an SSL/TLS accelerator, includes hardware-based SSL/TLS operations to handle the throughput, and it acts as a transparent device between the web server and the Internet. When an enterprise experiences web server bottlenecks due to SSL/TLS demands, an accelerator can be an economical solution.
SSL Decryptors
Networks with encrypted traffic entering and leaving pose an interesting dilemma for network security monitoring: how can the traffic be examined if it can’t be seen? SSL decryptors are a solution to this problem. They can be implemented in hardware or software, or in a combination of both, and they act as a means of opening the SSL/TLS traffic using the equivalent of a man-in-the-middle method to allow for the screening of the traffic. Then, the traffic can be re-encrypted and sent on its way. This functionality is included in many high-end next-generation firewall (NGFW) systems and provides the additional ability to selectively determine what traffic is decrypted and screened. Configuration of these channels can be tedious, as most of these devices are limited in their computational power, making complete network-wide decrypting not feasible. Most of these systems use a certificate-copying mechanism to obtain the necessary credentials. If the credentials are not available, the traffic can be flagged for further investigation, such as outbound traffic to unknown destinations—as in an encrypted command and control (C&C) botnet connection.
Media Gateway
One of the elements that the Internet has brought to enterprise networks is digital media channels. A wide range of media protocols exist and have found use in the communication of voice and video signals. Media gateways have been built to handle all of these different protocols, including translating them to other common protocols used in a network. Depending upon desired complexity and throughput needs, these devices can exist as a standalone device or as part of a switch/firewall.
Hardware Security Module
A hardware security module (HSM) is a device used to manage or store encryption keys. It can also assist in cryptographic operations such as encryption, hashing, or the application of digital signatures. HSMs are typically peripheral devices, connected via USB or a network connection. HSMs have tamper protection mechanisms to prevent physical access to the secrets they protect. Because of their dedicated design, they can offer significant performance advantages over general-purpose computers when it comes to cryptographic operations. When an enterprise has significant levels of cryptographic operations, HSMs can provide throughput efficiencies.
EXAM TIP Storing private keys anywhere on a networked system is a recipe for loss. HSMs are designed to allow the use of the key without exposing it to the wide range of host-based threats.
Chapter Review
In this chapter, you became acquainted with the network components used in an enterprise network. This has been a long chapter, with 17 different major topics and numerous subtopics. What is important to focus on when you review this chapter is the objective: Install and configure network components, both hardware- and software-based, to support organizational security. For each of the components covered in the major topic areas, you should understand when and how you would employ the component in response to a scenario that lists some security objective. This is how installation and configuration can be tested. Understanding the similarities and difference between the various components with respect to security objectives is the key to questions for this exam objective.
Questions
To help you prepare further for the CompTIA Security+ exam, and to test your level of preparedness, answer the following questions and then check your answers against the correct answers at the end of the chapter.
1. After you implement a new firewall on your corporate network, a coworker comes to you and asks why he can no longer connect to a Telnet server he has installed on his home DSL line. This failure to connect is likely due to:
A. Network Address Translation (NAT)
B. Basic packet filtering
C. Blocked by policy, Telnet not considered secure
D. A denial-of-service attack against Telnet
2. Why will NAT likely continue to be used even in IPv6 networks?
A. Even IPv6 does not have enough IP addresses.
B. It is integral to how access control lists work.
C. It allows faster internal routing of traffic.
D. It can hide the internal addressing structure from direct outside connections.
3. You are asked to present to senior management virtual private network methodologies in advance of your company’s purchase of new VPN concentrators. Why would you strongly recommend IPSec VPNs?
A. Connectionless integrity
B. Data-origin authentication
C. Traffic-flow confidentiality
D. All of the above
4. Why is Internet Key Exchange preferred in enterprise VPN deployments?
A. IKE automates key management by authenticating each peer to exchange session keys.
B. IKE forces the use of Diffie-Hellman, ensuring higher security than consumer VPNs.
C. IKE prevents the use of flawed hash algorithms such as MD5.
D. IKE mandates the use of the IPSec ESP header.
5. After an upgrade to your VPN concentrator hardware, your manager comes to you with a traffic graph showing a 50 percent increase in VPN traffic since the new hardware was installed. What is a possible cause of this increase?
A. Mandatory traffic shaping.
B. VPN jitter causing multiple IKE exchanges per second.
C. The new VPN defaults to full tunneling.
D. The new VPN uses transport mode instead of tunneling mode.
6. A network-based intrusion prevention system (NIPS) relies on what other technology at its core?
A. VPN
B. IDS
C. NAT
D. ACL
7. You have been asked to prepare a report on network-based intrusion detection systems that compares the NIDS solutions from two potential vendors your company is considering. One solution is signature based and one is behavioral based. Which of the following lists what your report will identify as the key advantage of each?
A. Behavioral: low false-negative rate; Signature: ability to detect zero day attacks
B. Behavioral: ability to detect zero day attacks; Signature: low false-positive rates
C. Behavioral: high false-positive rate; Signature: high speed of detection
D. Behavioral: low false-positive rate; Signature: high false-positive rate
8. Why are false negatives more critical than false positives in NIDS/NIPS solutions?
A. A false negative is a missed attack, whereas a false positive is just extra noise.
B. False positives are indications of strange behavior, whereas false negatives are missed normal behavior.
C. False negatives show what didn’t happen, whereas false positives show what did happen.
D. False negatives are not more critical than false positives.
9. You are managing a large network with several dozen switches when your monitoring system loses control over half of them. This monitoring system uses SNMPv2 to read traffic statistics and to make configuration changes to the switches. What has most likely happened to cause the loss of control?
A. A zero day Cisco bug is being used against you.
B. One of the network administrators may be a malicious insider.
C. An attacker has sniffed the SNMP password and made unauthorized configuration changes.
D. Nothing, just reboot the machine, the switches are likely to reconnect to the monitoring server.
10. How can proxy servers improve security?
A. They use TLS-based encryption to access all sites.
B. They can control which sites and content employees access, lessening the chance of malware exposure.
C. They enforce appropriate use of company resources.
D. They prevent access to phishing sites.
11. List three key functions of a Security Information and Event Management system:
______________, ________________, ________________
12. What technology can check the client’s health before allowing access to the network?
A. DLP
B. Reverse proxy
C. NIDS/NIPS
D. NAC
13. How does a mail gateway’s control of spam improve security?
A. It prevents users from being distracted by spam messages.
B. It can defeat many phishing attempts.
C. It can encrypt messages.
D. It prevents data leakage.
14. Why is e-mail encryption difficult?
A. E-mail encryption prevents DLP scanning of the message.
B. E-mail encryption ensures messages are caught in spam filters.
C. Because of a lack of a uniform standardized protocol and method for encryption.
D. Because of technical key exchange issues.
15. What kind of device provides tamper protection for encryption keys?
A. HSM
B. DLP
C. NIDS/NIPS
D. NAC
Answers
1. C. Because Telnet is considered unsecure, default firewall policies will more than likely block it.
2. D. NAT’s capability to hide internal addressing schemes and prevent direct connections from outside nodes will likely keep NAT technology relevant even with broader adoption of IPv6.
3. D. The IPSec protocol supports a wide variety of services to provide security. These include access control, connectionless integrity, traffic-flow confidentiality, rejection of replayed packets, data security, and data-origin authentication.
4. A. IKE automates the key exchange process in a two-phase process to exchange session keys.
5. C. If a VPN defaults to full tunneling, all traffic is routed through the VPN tunnel, versus split tunneling, which allows multiple connection paths.
6. B. A NIPS relies on the technology of an intrusion detection system at its core to detect potential attacks.
7. B. The key advantage of a behavioral-based NIDS is its ability to detect zero day attacks, whereas the key advantage of a signature-based NIDS is low false-positive rates.
8. A. A false negative is more critical as it is a potential attack that has been completely missed by the detection system; a false positive consumes unnecessary resources to be analyzed but is not an actual attack.
9. C. An attacker has likely sniffed the cleartext SNMP password and used it to access and make changes to the switching infrastructure.
10. B. Proxy servers can improve security by limiting the sites and content accessed by employees, limiting the potential access to malware.
11. SIEM should have these key functions: aggregation, correlation, alerting, time synchronization, event deduplication, and log collection.
12. D. NAC, or network access control, is a technology that can enforce the security health of a client machine before allowing it access to the network.
13. B. A mail gateway that blocks spam can prevent many phishing attempts from reaching your users.
14. C. A lack of a uniform standardized protocol for encryption makes encrypting e-mail end to end difficult.
15. A. A hardware security module (HSM) has tamper protections to prevent the encryption keys they manage from being altered.