Chapter 14. Publishing Your API
Publishing an API is about so much more than just making some endpoints available. In fact, it would be easy to argue that if you’re not going to also provide tests and monitoring to ensure the quality of your tools, and excellent documentation so that your users can actually use them, then you could save a lot of time and effort by not setting out to build the API in the first place! Delivering a project is about getting it done, but also creating everything that goes with a successful API. This chapter aims to cover what makes a complete API and show some ways you can deliver this.
Documentation Is Key
Documentation is the magic ingredient that will make your API both useful and usable. Without it, nobody can begin to use or understand the masterpiece you have built. With it, they can build on your offerings and create masterpieces (or at least reliable working software) of their own. Perhaps this chapter should have been the first, not the last, because it does make up a major part of shipping a successful API.
There are many types of documentation, and a great web service probably needs a bit of all of them. The following sections will look at the various kinds of documentation that are useful to accompany a web service and give some suggestions of tools you can use to generate and maintain these.
Overview Documentation
This is the welcoming committee of your API; it gets people over the threshold and gives them confidence that they are about to have a good time. The overview documentation will set the tone of the API and provide some pointers for where to find more detailed information. It could include:
-
The main or root endpoint URL
-
Information about available formats
-
Whether rate limits apply and if results can/should be cached
-
Authentication
-
Client libraries
-
Troubleshooting and further help
In general, overview documentation shows the style and layout of the API and states the protocol(s) that are available. There will probably be some simple examples of requests and responses for common operations to show off the headers and body formats that should be needed. Showing the HTTP for both requests and responses is very useful, because it means that anyone running into problems can fire up a debugger and compare their results with the examples shown.
The overview documentation will also cover how users can identify themselves to the system, if they need to. Many services will allow some public access, while others will ask that users link an API key to their login information on a website. If users need to actually log in, this overview section will cover how to do this, and the method will be the same across all the various parts of the API. This might be a username and password, or an OAuth process to follow, again with clear examples (bonus points if you can manage a real working guest account they can try) showing which credentials go where, where to get any necessary tokens, or how to craft a URL to which they can forward a user.
Information about error states belongs here in the overview, since they will be the same throughout the application. If the error states in your system aren’t consistent, then go and read Chapter 13 before reading any further. If you use error codes, provide information about where to find more information about what they mean. If there will be information in the status code or headers, it is helpful to mention it here for any consumers not realizing that they need to look beyond the body text (although this should also contain useful information). Alongside the information about errors, you may also like to include some support information.
Generated API Documentation
Automatically generated documentation can be very helpful if it contains enough information to be useful. The main advantage of this model is that the documentation is maintained inline with the API itself and is therefore more likely to be updated regularly. The jury is still out on whether outdated documentation is actually worse than no documentation at all—personally I think it might be!
In the RPC services, it is common for the entry points to the service to be contained in a single class, and hopefully that class will have inline code documentation. If it does, and especially if this service is for an internal or technical audience, it may be possible to generate API documentation using phpDocumentor and supply this as a reference to your users. This describes all the methods and parameters in the underlying class, but the PHP SOAP extension, for example, simply provides a very lightweight wrapper, so the generated documentation for the API of that class may well be a very useful artifact to generate and share. Do take care, however, that you’re not exposing any undesirable information—for example, implementation details within protected methods.
As an example, we’ll use the Event class from Chapter 7 and apply phpDocumentor to it. This tool is very easy to get started with, you can install via PEAR or Composer, but for this example I just grabbed the phpDocumentor.phar from the project website and pointed it at the directory with Event.php in it. You can see the output in Figure 14-1.
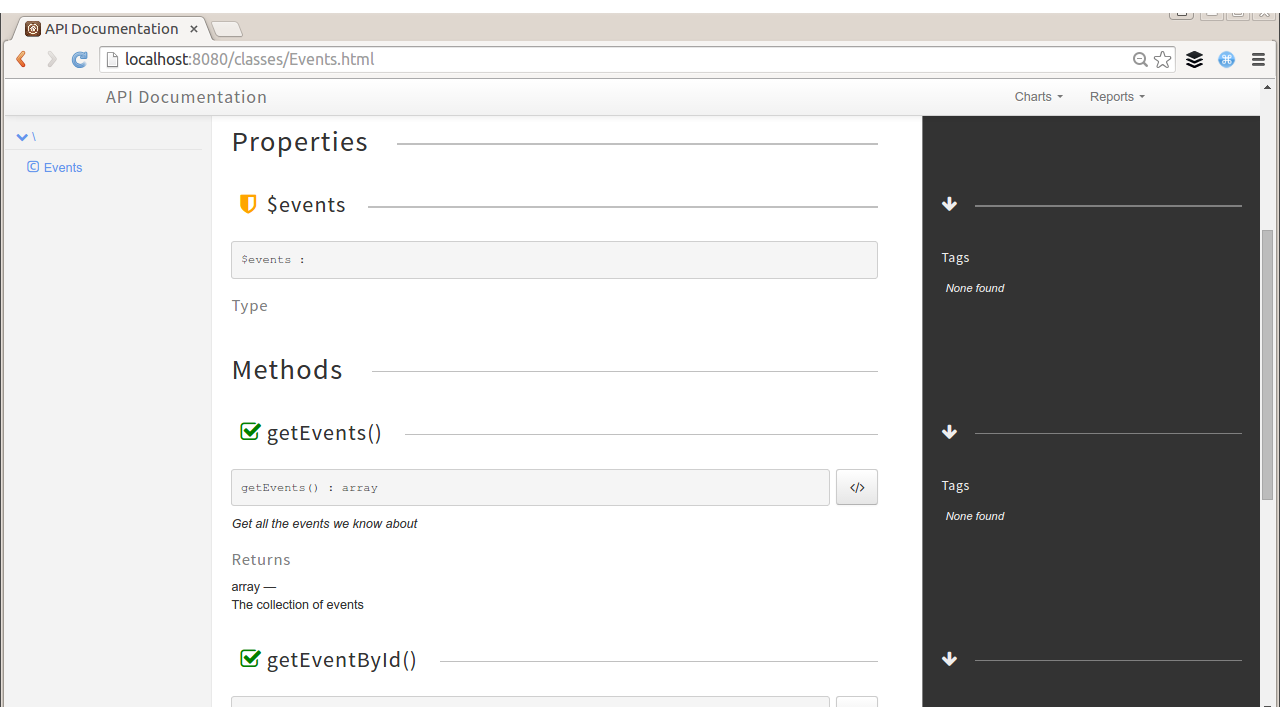
Figure 14-1. API documentation generated by phpDocumentor
This does show which methods can be called and the documentation of both the methods and their respective parameters. It won’t be useful in every situation, but phpDocumentor is one of the tools in the proverbial toolbox for offering documentation to users.
Another way of documenting the simple method/parameter outline of SOAP services is to supply a WSDL file, which was covered in Chapter 7.
For a RESTful service it is harder to generate documentation from our PHP code, but existing tools we have in our project can still be used and maintained alongside the API by linking our documentation to our other tools. There are a number of tools that allow you to describe your service using specific formats, and these can integrate with documentation tools. Many of those are also interactive documentation, which we’ll move on to look at next.
Interactive Documentation
Some of the best documentation in existence for APIs allows a user to actually try out the request from the documentation page. One great example is Flickr, which offers an API Explorer that allows the user to enter data into the fields and then make the request from the online documentation itself (see Figure 14-2). This allows the user to try the feature as herself or as an anonymous user and set any of the available parameters for a particular method. Flickr gets extra points for technical merit, as they include some handy reference numbers, such as your own user ID and some recent photos uploaded to your account on the same page.
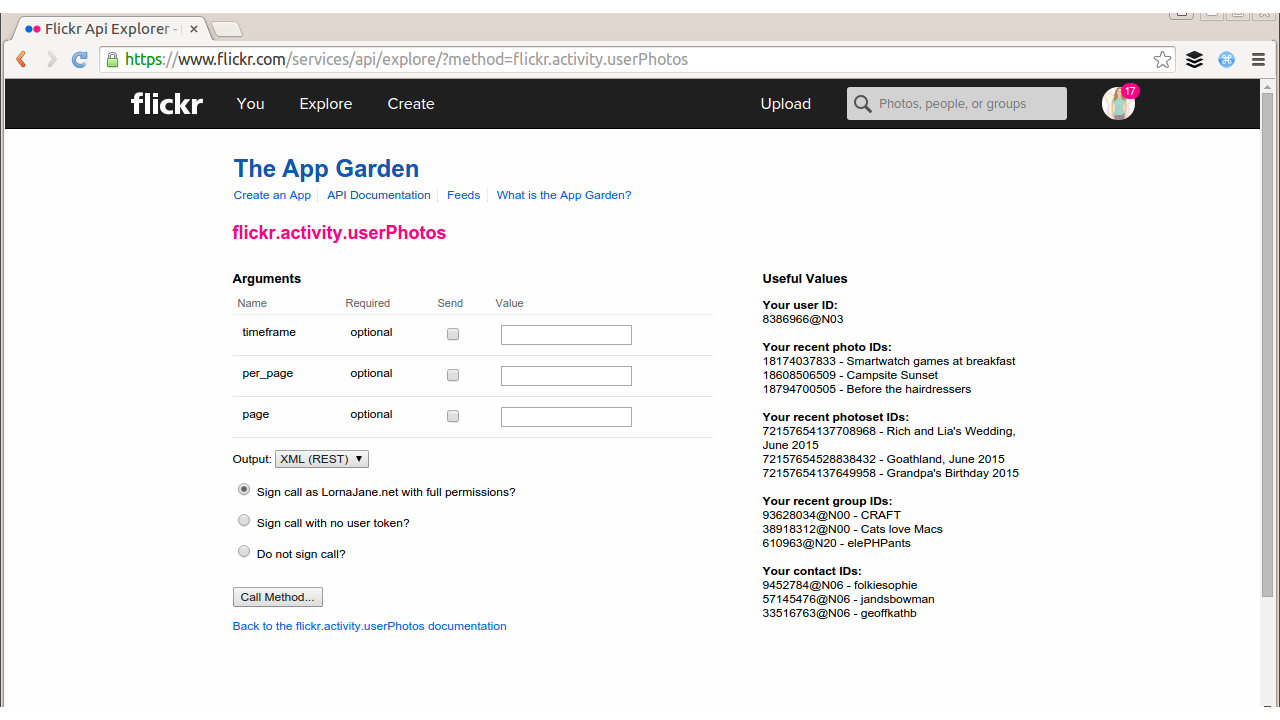
Figure 14-2. Flickr offers interactive API documentation
There are plenty of tools available to help create something similar for another project. One of my preferred approaches is to write a traditional longhand documentation with lots of cURL examples, but instead of just displaying code samples, use hurl.it to create textboxes where you can edit and send the cURL requests from the page itself. An example from the Joind.in API documentation is in Figure 14-3 and offers an easy way to show users how to perform a specific request and amend it themselves.
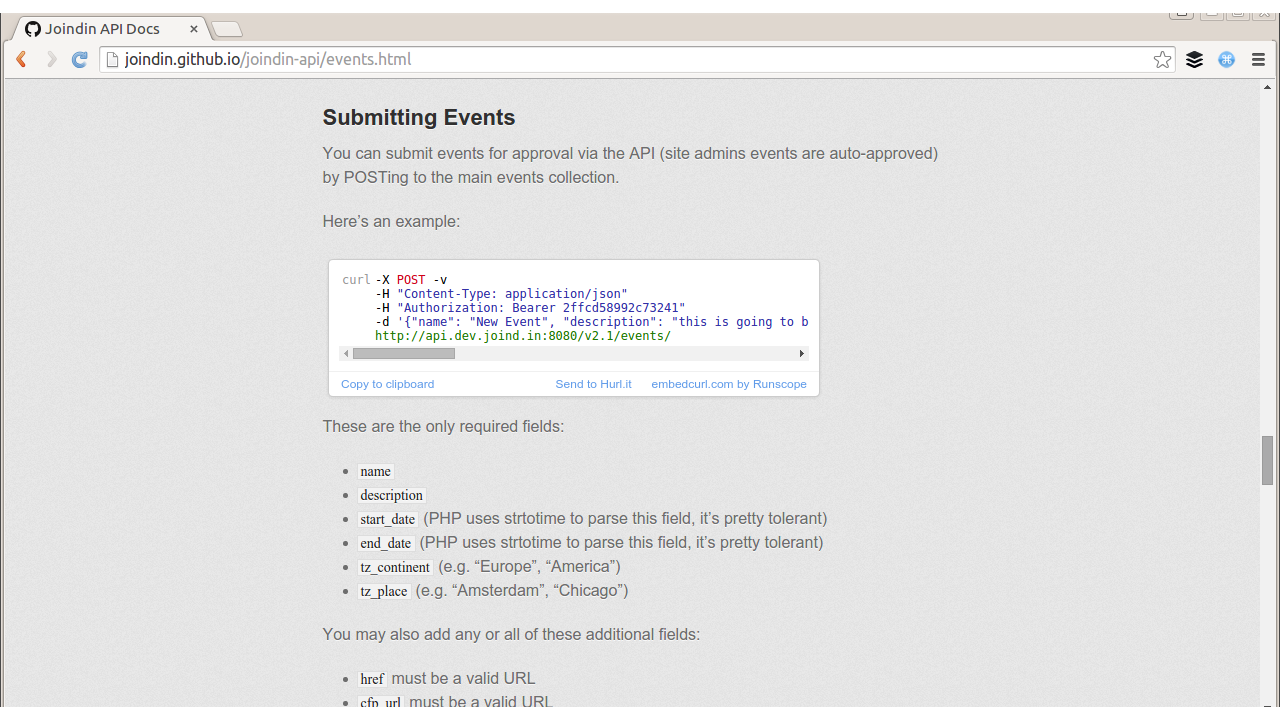
Figure 14-3. Using hurl.it to make a live cURL example in API documentation
Another tool that produces interactive documentation is the I/O Docs tool. It’s written in Node.js and the code is open source and available on GitHub, so you can amend it as you need to. You create a configuration file describing how your API can be used, which URLs can be called, what format and parameters to use, and so on. Once you are done, I/O Docs creates a page showing these available actions and parameters as a web form, and allows users to click the alluringly named “Try it!” button to try making a request and viewing the response. This is used by a few online APIs; for example, Klout (Twitter metric tools) uses it to document its API, as you can see in Figure 14-4. A tool like this is simple to set up and can be hosted either on your own servers or on a cloud hosting provider such as Heroku.
To use I/O Docs for your own project, you will need to create a configuration file describing the endpoints for your API, which parameters should be sent, which format and authentication should be used, and so on. The project ships with examples for Klout and other well-known APIs, but essentially it’s a JSON format.
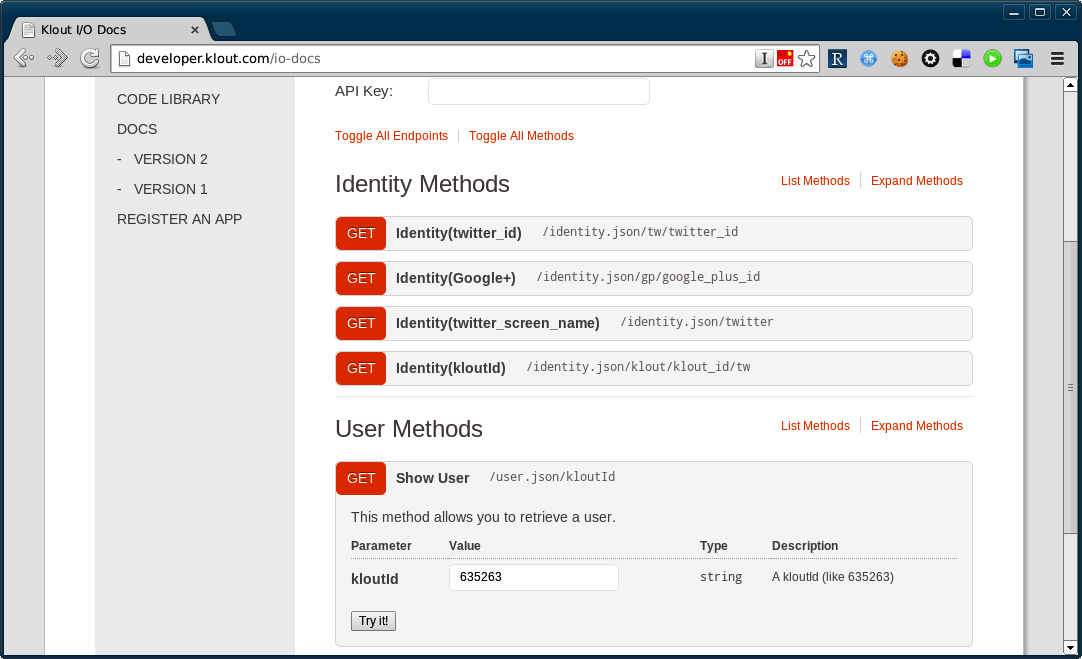
Figure 14-4. Klout uses I/O Docs to create its interactive documentation
API Description Languages
The I/O Docs tool and the idea that you can just describe your API in a known format, then pass that format to an external tool, is an approach that we’re seeing more and more often, with hosted or cloud tools as well as offerings for you to host yourself. This approach can be an excellent way of maintaining documentation because it allows you to keep the description files in the same repository as the API source code—so you’d expect to see for any API change a corresponding change in the API description files, therefore helping to keep the two in sync. When you deploy a new version of your API, your build tools can also ship the updated API description file to the tools that use it.
There are a number of competing formats around, and they’re all pretty straightforward to work with. In particular you might like to look at API Blueprint, which is a specific markdown format describing an API. In fact, you can create the description and use apiary.io to mock your API to see how it works out before you even build it! There are a number of other tools that integrate with API Blueprint and the list is growing all the time—with your API described, you can expect to find tools to generate documentation, wrapper classes, tests, and various other artifacts from the API Blueprint.
Another markdown-based API description format is RAML (it stands for RESTful API Modeling Language), which has various tools associated with it but which is widely used with APIMatic to create SDK libraries for developers to quickly integrate an API into their project. The markdown formats also serve as a detailed technical specification in their own right, which can make them very useful to produce as part of a project whether your own tooling integrates closely with them or not.
Finally, Swagger is also worth a mention although it has rather a different feel as it uses a JSON format so it’s more machine-readable than human-readable. Just like the markdown formats though, once you have recorded the metadata about your API, a raft of tools becomes available for users to explore and work with your API.
Automated Testing Tools
In Chapter 10 we saw good ways to store, alter, and replay requests against an API. Many developers find it helpful to keep a library of useful API calls handy and perhaps even to run these as a test suite. In fact we can apply much of what we know about automated testing of websites to our APIs. Techniques you are probably already using such as unit testing are absolutely applicable here. It’s also useful to have some integration tests that make HTTP requests against your API and check that everything responds as you’d expect it to; if not, then you know you’ve made an inadvertent change to your application. There are many, many different tools you could use for this so I’ve picked two to show you as examples.
Note
While it might seem a bit odd to have JavaScript tools in a PHP book, the reality is that very many of the best tools in this space are written in node.js! For this section on frisby.js you will need both node.js and its package manager npm installed on your system.
We’ll start with frisby.js which, as the name suggests, is a JavaScript tool. Frisby is a lightweight extension to the node.js testing tool jasmine, which is aimed at making it easier to test API calls and their responses. You can see a snippet of a frisby.js test suite in Example 14-1; you cue up each request and can parse the response to use variables for your next request.
Example 14-1. Use frisby.js to test APIs
functiontestNonexistentUser(){frisby.create('Non-existent user').get(baseURL+"/v2.1/users/100100100").expectStatus(404).expectHeader("content-type","application/json; charset=utf8").expectJSON(["User not found"]).toss();}functiontestExistingUser(){frisby.create('Existing user').get(baseURL+"/v2.1/users/1").expectStatus(200).expectHeader("content-type","application/json; charset=utf8").afterJSON(function(allUsers){if(typeofallUsers.users=="object"){for(varuinallUsers.users){varuser=allUsers.users[u];datatest.checkUserData(user);}}}).toss();}
The example shown checks how the API will respond when a user is requested, both in the case where the user is known to exist, and in the case where the user is known to not exist. To run these tests, we add some configuration for where to find the API endpoint and create a file outlining which functions to call, as shown in Example 14-2.
Example 14-2. Set up frisby.js to run tests (my_spec.js)
varapitest=require('./api_read');varbaseURL;baseURL="http://api.dev.joind.in";apitest.init(baseURL);apitest.testNonexistentUser();apitest.testExistingUser();
Use the installation instructions on frisbyjs.com to get frisby installed and then you can run this example yourself. The output is pretty much as you’d expect, just a few lines reporting the outcome:
$ jasmine-node my_spec.js .. Finished in 0.111 seconds 2 tests, 23 assertions, 0 failures, 0 skipped
This also makes it very easy to include in a build process. API tests, like integration tests, can’t be run on a codebase until it is deployed and can be reached via HTTP. I have the test runs set up as Jenkins jobs so that it is super-easy to run the tests against either the test or live platforms (nondestructive tests only!) when you have just deployed a new version. It is also well worth the investment of time to make these tests trivially easy to run on development platforms so that developers can very easily verify they haven’t accidentally broken anything—as well as testing their own new tests alongside their features of course.
A similar approach might be to create a new PHPUnit test suite to include in your application and have it just make API calls and check the responses (remember to check what happens in the failure case as well), using a library such as Guzzle that has been used elsewhere in the book. One advantage of this is that you probably already have PHPUnit in use in your project for unit tests, so it saves learning another tool for other tests such as API or functional integration tests.
Another alternative for API testing is to use a hosted tool. For this example, I’ve chosen Runscope, as I find it very easy to get started and it tells me very clearly exactly what is wrong if something does break. The way it works is that you create some tests, which can be whole sequences of API requests, with variables fetched and stored between them, and save them. Runscope will then allow you to use this interface to run the tests, but can also run them periodically from a variety of locations around the world, allowing you to check your performance from a selection of geographical regions.
I’ve set up a test that just creates a user and then fetches the new record; you can see the configuration in Figure 14-5. I have it set to run automatically and email me if there are any failures; I only visit the site to add more tests or to investigate in the event of a failure.
Having automated API testing, whether on your own build servers or from another service, is really valuable to make sure that there are no regressions, bad data, or other issues cropping up in your application. You can also use standard monitoring and health-check tools to make sure that your APIs are as available as they should be, or to alert you if there are any problems.
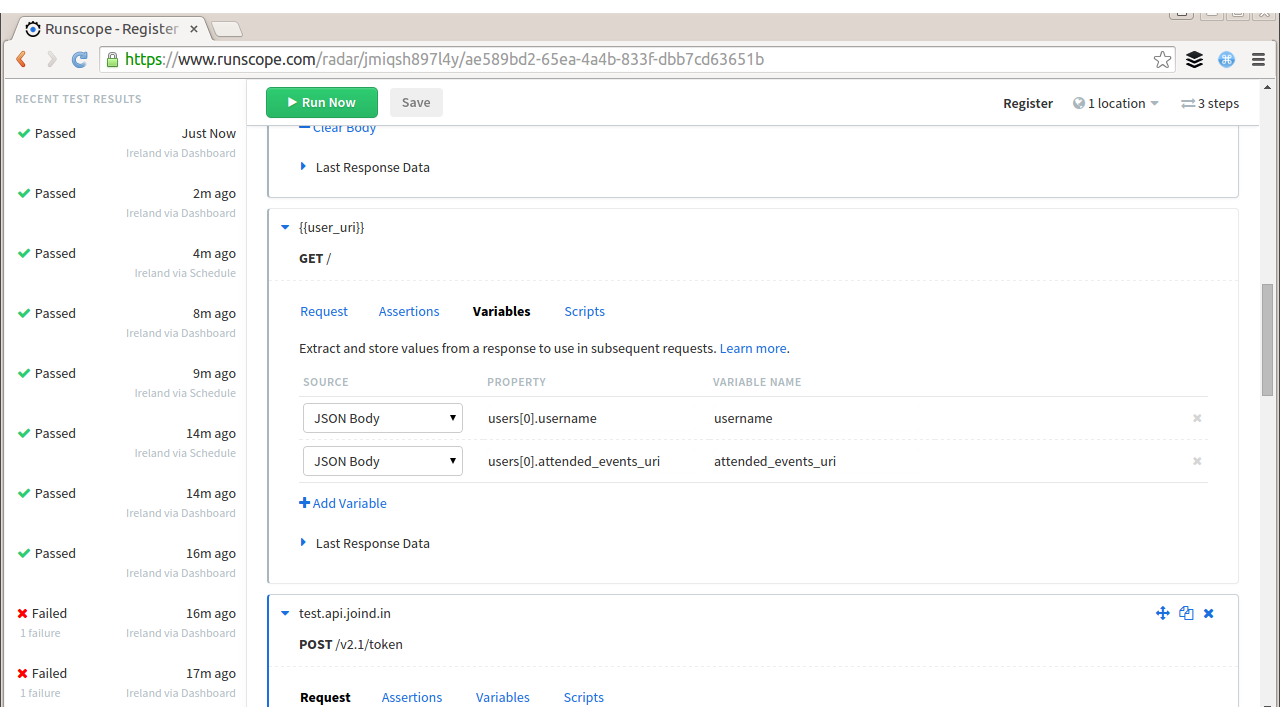
Figure 14-5. Configuring a Runscope test
Tutorials and the Wider Ecosystem
Documentation is about so much more than lists of accessible functionality. It is about showing how the API actually solves problems, and how it looks when it is used in the real world. A common criticism of software library documentation is that, while each function is documented, it can be very hard to know which function you want to use. Giving practical tutorial examples is really useful, even when they are not exactly what a user was looking for. In creating these tutorials you have essentially two choices: write them yourself, or keep an eye out and encourage your community to contribute.
When writing tutorials, there are some key points that can help create useful, readable additions to your existing documentation. Focus in each tutorial on just one particular skill or technique (for example, I wrote a very specific blog post for interacting with JIRA’s API). If you need to refer to other skills, then link out to documentation on doing that (how to set up your SSH keys, how to configure your editor, etc.). Sometimes this means that writing one tutorial can mean you end up writing a miniseries with three or four articles in it to produce the content that works as a whole. Splitting things up into focused chunks both allows the user to more easily find what they need but also keeps the articles short enough that an average user stands a chance of getting to the end. The other thing to remember is that more information is always helpful. So spell it out with detailed examples, full code samples (with syntax highlighting), screenshots, and plenty of subheadings to break up long reams of text. It’s hard to know which small detail a user might have missed; and more information helps them to put the clues together and achieve their goals.
Make sure your users know where they can go for support; then go and find where they actually ask for help. While you may set up user forums to help people with their queries and make those details public so that other people can find answers to common questions, users often don’t follow the paths you set for them. Sometimes it is necessary to “pave the cowpaths” and follow where they lead. To this end, set up a search alert for your product or application name with a search engine, and make sure that when questions do pop up in other places (such as StackOverflow), someone is able to respond.
Having documentation outside of your own control is a very positive thing, although it can feel a little frightening at first. Users are the word of mouth that spread influence, and often they can become your biggest advocates and very effectively help one another. Welcome those users who contribute to the wider project and credit them where you can; documentation from any angle is a resource that’s valuable to any project and it’s vital for anything public. It is referred to as the “ecosystem” because it’s the world your application exists in.