YOU MAY ALREADY KNOW THAT GENES are made of DNA (short for deoxyribonucleic acid). More interesting than knowing this is understanding how we know that DNA is the basis for heredity and understanding the importance of the structure of DNA for inheritance. You will see in this chapter that DNA and its structure are the keys to understanding inheritance.
DNA has a fascinating history. The Swiss scientist Friedrich Miescher discovered DNA near the end of the nineteenth century. Miescher never knew that the substance he had isolated from sperm and pus (yes, pus!) would turn out to be so critical to the understanding of life. He died several decades before the function of DNA and its famous double-helical structure were uncovered. After Miescher, other scientists tried to identify the chemical composition of sperm, reasoning that sperm must carry the genetic material to the next generation. These scientists also reasoned that sperm cells have very little excess cellular material other than the hereditary material found in the sperm head. In fact, DNA constitutes over 60 percent of the sperm head; the remainder is mostly protein.
For a long time after Miescher’s discovery, DNA was thought to be a simple molecule, consisting of nucleotides strung together like beads on a string. Each nucleotide is composed of a sugar (deoxyribose) chemically linked to phosphorus atoms and one of four different nitrogenous bases (so called because they contain a significant number of nitrogen atoms). The nitrogenous bases are adenine, guanine, cytosine, and thymine. These four bases are abbreviated as A, G, C, and T. Nothing known about the DNA molecule suggested that it could play any role in heredity. The structure of DNA seemed much too simple to account for the many already known hereditary traits. But then scientists found that the building blocks of DNA—the nucleotides—were repeated hundreds of times in the DNA molecule. As techniques to isolate DNA from living cells improved, the number of nucleotides in a DNA molecule was found to be in the thousands, and then in the hundreds of thousands. Scientists had discovered that DNA is a polymer, much like many plastics such as polyethylene and polypropylene, except that DNA is a very long polymer with millions of nucleotides, As, Gs, Cs, and Ts.
Yet nobody knew what living cells did with this polymer, nor did anybody know the structure of the DNA molecule. In fact, some scientists believed that only animals and bacterial cells possessed DNA and that plants were devoid of it. Since plants, as well as animals and bacteria, all had well-defined genetic characteristics (for example, flower color for plants, shape for animals, and pathogenicity for bacteria), DNA could not be the genetic material, so the logic went. We now know that plants do contain DNA, and that the failure to isolate it from them was due to the use of crude techniques. In fact, for geneticists, plants, animals, and bacteria are largely similar in spite of their great diversity. This is because their hereditary properties are all based on the existence of one substance: DNA.
An important step in the development of ideas about the chemical nature of the genetic material was the ability to stain DNA. In the 1920s, German biochemist Robert Feulgen developed a way to specifically stain DNA. He then used this method to stain DNA in living tissue. The Feulgen reaction, as it is now called, specifically colors DNA purple. The stained cells can then be viewed under the microscope. Feulgen used this technique on all kinds of tissues from animals, plants, and protozoa. Under the microscope, the purple DNA stain was found in a central compartment of all these cells. The compartment is given the name nucleus, plural nuclei. Feulgen found that the nuclei of all of these cells, including the nuclei of plant cells, became stained. This definitively proved that plants had DNA and that the DNA of cells is located in the nucleus.
With the Feulgen stain, scientists had a tool to measure the amount of DNA present in cells. In 1950, in a paper entitled “Constancy of DNA in Plant Nuclei,” Hewson Swift at the University of Chicago showed that all cells from different parts of a corn plant had a constant amount of DNA. Furthermore, the amount of DNA in pollen was half that found in, for example, the leaf and root cells. He found that rapidly dividing cells in the root tip and other cells prior to cell division had twice as much as DNA. These are what one would expect of the genetic material (see chapter 2). If DNA was the genetic material, its amount should be constant in all the cells of the organism regardless of the size of the cell.
An even more interesting observation was made using the Feulgen stain: DNA changes shape as cells divide. Most of the time, the Feulgen stain showed an amorphous purple sphere in the nucleus, without any substructure. But just before cells divide, the DNA becomes condensed into sausage-looking structures called chromosomes. It was found that the number and shape of these condensed chromosomes was the same in different body cells of the same organism. Furthermore, one could see that in sperm cells the number of chromosomes was halved. We would expect that the amount of hereditary material in the gametes, sperm or pollen and egg or ova, would be half that found in the nonreproductive cells of the organism.
That DNA is indeed the genetic material was demonstrated in bacteria in 1944. A team led by the Canadian Oswald Avery at Rockefeller University in New York made this landmark discovery. Their biological material was the bacterium Streptococcus pneumoniae, which, as its name indicates, causes pneumonia. Avery’s laboratory possessed two strains of these bacteria. One strain infects mice with pneumonia (the “virulent” strain), and the other strain does not (the “avirulent” strain). The two strains look different when growing in a petri dish: The virulent strain grows as a smooth, slimy, large collection of cells known as a colony. The avirulent strain produced small, well-defined, rough-looking colonies (figure 1.1). Thus the bacterial strains are distinguishable by two characteristics: physical appearance and the strain’s ability or inability to cause pneumonia. These characteristics are hereditary. Avery knew this because he grew the two bacterial strains for a long time, during which the cells divided many times, but this produced no change in the bacteria’s ability to cause pneumonia or the bacteria’s physical appearance.

Figure 1.1 Virulent and Avirulent Streptococcus Pneumoniae Colonies on an Agar Plate. The large, slimy, smooth colonies on the left are virulent, and the small, distinct colonies on the right are avirulent. Plate and photograph courtesy of Kirstin Malm.
Avery did an experiment that suggested that hereditary properties like virulence and appearance could be exchanged between cells. He knew, as we do, that heating bacterial cells kills them. Indeed, when the smooth, virulent bacteria are heated, they are killed and no longer infect mice with pneumonia. But when one mixes these heat-killed virulent bacteria with live, avirulent rough bacteria, one finds that this mixture can kill mice. Avery reasoned that the genetic material from the heat-killed virulent bacteria changed the properties of the rough strain. In this case, he reasoned, DNA purified from the smooth strain would change the characteristics of the rough strain, but only if the DNA could get into the rough, avirulent bacteria. Avery’s research team purified DNA from the smooth, slimy strain and added the purified DNA to the rough cells. They observed that a few smooth and slimy cells appeared in the culture of rough cells exposed to the DNA! This “transformation,” as they called it, was stable over many cell divisions. Avery and his team interpreted these observations to mean that DNA was the genetic material.
However, to make sure that the DNA did not contain contaminants that could have been the true genetic material, they did further experiments with a variety of enzymes. Suffice it to say that enzymes are proteins that catalyze all sorts of reactions. Biologists commonly give names to these enzymes by putting the suffix “-ase” after the name of the substances they act upon. For example, deoxyribonuclease is an enzyme that destroys DNA by cutting it into its nucleotide building blocks. Similarly, a protease is an enzyme that destroys proteins. When Avery and his coworkers added deoxyribonuclease to their purified DNA and then added this mixture to rough cells, no smooth, slimy cells were recovered. This meant that destroying DNA destroyed the transforming activity. On the other hand, adding proteases to the DNA had no effect on its transforming activity. If contaminating proteins in their DNA samples had been responsible for the transforming activity, the addition of proteases should have destroyed this activity. It did not. This means that proteins were not responsible for the observed transformation. There it was: the genetic material—the genes—of Streptococcus pneumoniae was not made of proteins, but of DNA.
Avery’s work had been done under carefully controlled conditions, and his conclusions were straightforward. Yet nobody at the time believed him! Why was that so? It turns out that as recently as the late 1940s, scientists were convinced that protein, not DNA, was the genetic material. Why? Proteins seemed like a much more likely candidate to be the genetic material. Proteins existed in innumerable varieties that differed enormously among living species. For this reason, proteins were thought to constitute the true genetic material. Another factor is that in 1944 World War II was still raging, and Avery’s discovery must have been seen as of little consequence when people were dying on the battlefields and in bombed-out cities. Finally, some people thought that DNA was possibly the genetic material of some rare bacterial species, but certainly it could not be responsible for the hereditary properties of higher life forms, such as animals and plants. Of course, the skeptics were dead wrong, as we know. Such an important discovery should have earned its authors a Nobel Prize. However, Avery was sixty-seven at the time he made this important discovery, and he died eleven years later. Recognition of important discoveries often takes decades. Since the Nobel Prize is not granted posthumously, Avery was unable to be recognized for his important work.
We know today that DNA is an almost universal genetic material, and that genes present in simple viruses, bacteria, plants, and animals are all made of DNA. Amazingly, some viruses are made of a chemical very similar to DNA, ribonucleic acid (RNA), where the base thymine (T) is replaced by uracil (U) and where the sugar is ribose, not deoxyribose.
By the late 1940s biochemists knew that DNA was a very long polymer made up of millions of nucleotides. Each nucleotide contains one of the four nitrogenous bases (A, T, G, or C) linked to a deoxyribose unit, in turn linked to a chemical group containing a phosphorus atom. DNA is held together by bonds between the phosphate and the deoxyribose units. Therefore, one speaks of the DNA’s “sugar-phosphate backbone” (figure 1.2.A). In those years, it was also known that in all DNA samples isolated from widely different species (human, yeast, and bacteria, for example), the amount of adenine (A) was always equal to the amount of thymine (T). Similarly, guanine (G) was always equal to cytidine (C). Nobody knew how to explain this, but the observation suggested some regularity in the DNA molecule.
A breakthrough occurred when Rosalind Franklin, a researcher at King’s College in London, England, succeeded in crystallizing DNA in the early 1950s. Crystals are formed when identical molecules are packed in a very organized fashion. This is rather simple to do for a small molecule. Perhaps you have made sugar crystals by putting a string into a solution saturated with sugar. This happens because the rough structure of the string initiates crystal formation. Once some sugar molecules attach to the string, other sugar molecules can fit in like bricks in a wall. Because DNA is such a large molecule, it does not form crystals readily. Why was it so important to obtain DNA crystals? One can take advantage of the very regular arrangement of the same molecules in a crystal to determine their structure. There existed at the time a well-established technique used to determine the arrangement of atoms inside a crystal. This technique is called X-ray crystallography, and, as its name indicates, it consists of illuminating a target crystal with X rays. The regular arrangement of atoms in a crystal deflects X rays and forms spots in concentric rings on a photographic film. The more organized the structure, the more spots are formed farther out in the ring. By noting the location and intensity of these spots, one can then determine the relative positions of the atoms in the crystal and determine the three-dimensional structure of the crystallized molecules. Thus, Rosalind Franklin obtained the first high-quality X-ray data for a DNA crystal (figure 1.3).

Figure 1.2 Diagrams of DNA. A. A flat diagram shows two strands of DNA each with four bases. Note that each strand is held together by a “sugar-phosphate backbone.” The two strands run in opposite directions, thus the left-hand strand is shown upside down. The strands are held together by weak bonds, called hydrogen bonds, between the bases. B. A diagram of the double-helix structure of DNA. Note the sugar-phosphate backbone in opposite directions shown by the arrows. The rungs of the ladder represent the bases held together by the weak hydrogen bonds. C. A detailed diagram of two bases from two opposing strands of DNA. The phosphates are shown as shaded circles and sugars as shaded pentagons. The dotted lines connecting the bases are weak hydrogen bonds.
At this time, James Watson, a young American postdoctoral scientist, and Francis Crick, an English physicist working on his Ph.D. dissertation, were both at Cambridge University. These two struck up a collaboration to solve the problem of the structure of DNA. Neither of them had done any previous work with DNA. They were thus novices, although Crick knew the theory of X-ray crystallography very well. Indeed, Watson and Crick never did a single experiment to solve the structure of DNA. All the experimental results had been obtained by Rosalind Franklin and later repeated by her boss, Maurice Wilkins. One day, while he was visiting the King’s College researchers, Watson saw a photograph of DNA made by Franklin. The arrangement of the spots radiating out in an X shape immediately suggested to him that DNA must be a helical molecule. Back in Cambridge, Watson convinced Crick of that interpretation, and model building started. After a few days of trial and error, they had a helical molecule that was also consistent with Franklin’s X-ray crystallography data. DNA was a double helix in which the sugar-phosphate backbones are on the outside, while the bases are on the inside of the molecule (figure 1.2.B). This structure was held together by weak bonds between an A and a T, indicated by the dotted lines in the figure, and similarly G was held to a C. This pairing of A with T and G with C is called “complementary base pairing.” This explained why the number of As was always equal to the number of Ts, and Gs always equal to Cs. The discovery of the double-helical structure of DNA was published in a short report in 1953, and Watson, Crick, and Wilkins received the Nobel Prize in 1962.
A very sad aspect to this story is that Rosalind Franklin did not receive recognition at the time for her major contribution. She died in 1958 at the young age of thirty-seven of ovarian cancer, unable to share the honors unquestionably due to her too.
Figure 1.3 Photograph of the X-ray diffraction pattern of DNA. Produced by Rosalind Franklin.
In their short article, Watson and Crick announced cryptically that “it has not escaped our notice that the specific [base] pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.” What did they mean by that? First, since DNA is the genetic material, it contains all the instructions necessary to “tell” a living cell what it is supposed to do. Next, as cells divide, as for example in the case of bacteria or human cells, the progeny of a cell must contain the same genetic instructions as the original cell. Thus, there must exist a mechanism that copies DNA faithfully, to ensure that progeny cells contain the same genetic material as the maternal cell. When Watson and Crick envisioned a copying mechanism for DNA, none of the details of this mechanism was known. However, simply by looking at the double-helical structure of DNA, they understood the basics of the replication process. To understand how they arrived at this interpretation, we must go back to the complementary base pairing that holds the DNA double helix together: an A always faces a T and a G always faces a C.
If DNA is the genetic material, cells must contain the necessary machinery (like enzymes) that can “read” the base sequence in DNA. With the structure of DNA depicted in figure 1.2, we realize that if the two DNA strands become separated, each strand has the information to specify the order of A, T, G, and C in the other strand. What is the result of this “reading” process? Figure 1.2.C shows that because of the A-T and G-C complementary base-pair arrangement, whenever an A is read in one of the strands of the original DNA molecule, the cellular machinery must incorporate a T in the newly growing opposite strand. But, since the A in the original molecule faced a T, the T in that strand must be read in such a way that the cellular machinery incorporates an A in the other growing strand. The result is that an original A-T pair is now copied into two A-T pairs, each new one present in the two replicated DNA molecules. This copying mechanism occurs at the level of each individual base pair, ensuring that the two resultant double-helical molecules are identical to the original DNA double helix. We say that the two DNA strands are used as templates for the synthesis of two complementary, new DNA strands.
We now know that this is how DNA replicates. The machinery that performs DNA replication is very complex and involves dozens of proteins. One key enzyme in the process of DNA replication is called DNA polymerase. This enzyme “reads” the bases present in the template strands and incorporates the complementary bases into the growing new strands. DNA replication is extremely accurate, but it is not absolutely perfect. Mistakes made by DNA polymerase result in the incorporation of a “wrong” base (like putting in a G opposite an A instead of a T), and these errors are one of the causes of spontaneous mutations, the ultimate source of genetic variation.
Geneticists now have a good understanding of the many ingredients that are necessary for DNA replication. We need to have the enzyme DNA polymerase to do the job, as well as the building blocks of DNA, nucleotides. In the natural process of DNA replication, the two strands of DNA are separated and the enzyme DNA polymerase binds to short double-stranded stretches positioned next to the single-stranded DNA to be copied.
Today, it is possible to make significant amounts of DNA in the test tube, using a method that partially imitates the mechanism used by living cells. This method is called the polymerase chain reaction (PCR) and was invented in 1986 by Kary Mullis. Mullis won the Nobel Prize in 1993 and candidly confesses that he came up with the idea on a surfing trip, while high on drugs.
We have seen that each strand of a double-stranded DNA is used as template for DNA replication. DNA normally is held together as a double-stranded molecule by weak bonds between the complementary bases (figure 1.2). It turns out that we can separate the two strands of double-stranded DNA simply by heating up a DNA solution close to the boiling point. At high temperature, the weak bonds that link the two strands together are broken, and the two strands of DNA separate. If the solution is cooled, the double-stranded DNA can reform. As in the cell, DNA polymerase in the test tube needs to have short stretches of double-stranded structure to copy the single stranded regions. By 1986, chemists could make short pieces of single-stranded DNA of a predetermined nucleotide sequence. If we know the base sequence of a piece of DNA, it is possible to synthesize a short piece of DNA whose base sequence is complementary. When the solution is cooled, short strands of DNA can more easily find their complementary strand than long strands. To reform the original long double-stranded DNA, the solution must be cooled slowly. Thus if the solution is fast-cooled, the process of short pieces making a partial double-stranded structure wins out over the long, complementary DNA sequences coming together (figure 1.4.C).
The short pieces of DNA that form the short double-stranded regions are known as “primers.” In order to copy both strands of the double-stranded DNA, each strand must have a primer. The relative position of the complementary regions to these primers determines the size of the DNA piece that will be made. As we just saw, these primers can be made in the lab, and they will form weak bonds with single-stranded DNA with a complementary sequence. Therefore, by adding DNA polymerase together with the building blocks of DNA (nucleotides, A, T, G, and C), one can copy DNA in the test tube (figure 1.4). The problem, though, is that one can copy DNA only once under those circumstances; once a DNA double helix is completed, the system stops because the DNA is now double-stranded and lacks regions that are partially double-stranded, the necessary condition for DNA synthesis.
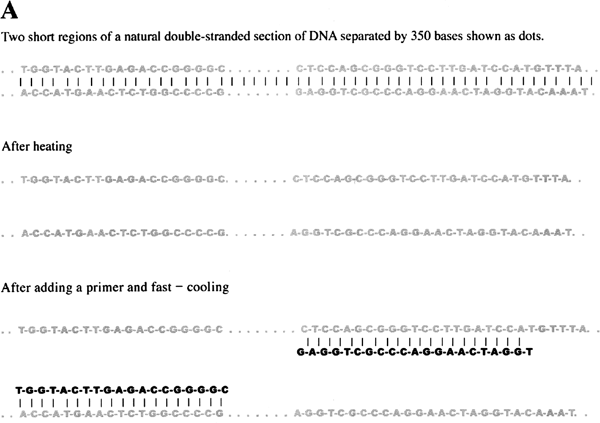
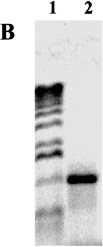
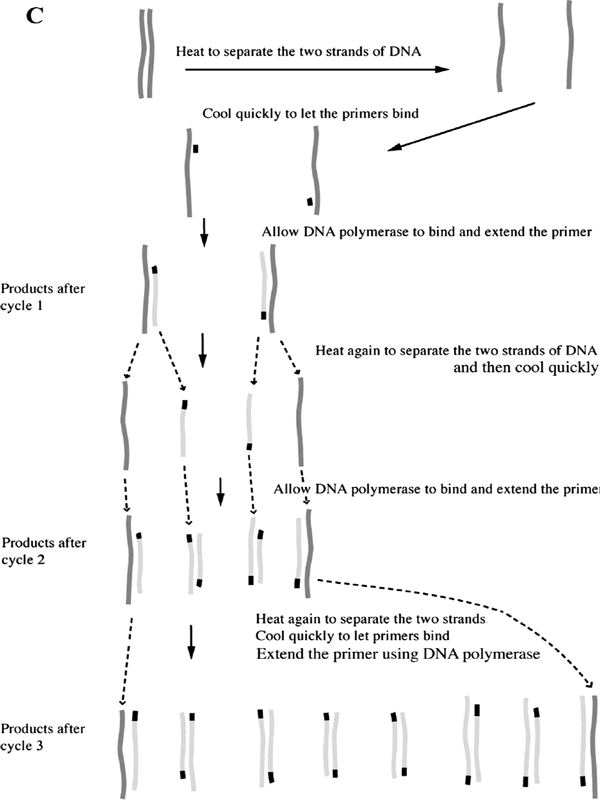
Figure 1.4 Polymerase Chain Reaction. A. Beginning of a PCR reaction. The top frame depicts a short region of a much longer double-stranded DNA with middle piece of 350 bases represented by dots. When heated, weak bonds between the two strands are broken and the strands separate as shown in the middle frame. When the solution is fast-cooled, primers in the solution bind to the complementary sequences as shown in the bottom frame. Because the primers in this example are 19 and 21 bases long and are separated by 350, this set of primers will make a DNA product that is 390 base pairs long. B. A photograph of the result from a PCR reaction. The DNA runs in a gel from the top toward the bottom during the application of an electric current. 1: DNA size markers with the largest DNA pieces towards the top. 2: PCR product. C. The first three cycles of a PCR reaction. The original DNA is shown in dark gray, the primers in black, newly synthesized DNA in light gray. Each step first involves heating to separate the double strands of DNA, then fast-cooling to allow primers to bind, and finally allowing the DNA polymerase to synthesize a new strand of DNA off of the primer. Dotted lines after the product of cycle 1 shows how the product of one cycle provides the template for the next cycle. The first cycle results in two double-stranded DNA, each composed of an original and the new, second, shorter piece with the primer at one end. The second cycle results in four double-stranded DNA; two are like those after the first cycle. The other two strands are both newly synthesized DNA extended from primers. Because two of these new strands are made off of a strand ending with the other primer, their lengths are determined by where the primers bind. The third cycle, shown only as the final products, results in eight double-stranded DNA molecules; two are similar to the results of the first cycle; four are like those just described for cycle 2; and finally, the lengths of two full pairs of strands are defined by the two primers. With each successive cycle after this, the amount of double-stranded DNA doubles. Thus this reaction is called polymerase chain reaction. As the cycle number increases, the amount of DNA defined by the two primers increases. This chain reaction allows one to make a great deal of DNA of a specific size and visualize it on a gel.
This is where Mullis’s creativity came to the rescue. He figured that if more primers were available, and if one could separate the two newly formed DNA strands by heating after the first round of replication and then cool the solution rapidly, the newly synthesized DNA would make new bonds with more primers. The DNA polymerase would then make more DNA by using the partially double-stranded regions formed by the primers. Thus by repeating the cycles of heating and cooling, one could make a lot of DNA identical to the DNA that began the process. There was one big problem, however. The DNA polymerase enzyme used to replicate DNA, like most enzymes, was completely destroyed by the heat necessary to separate the double-stranded DNA molecules. Fortunately, biologists had discovered, practically at the same time, that DNA polymerase extracted from the heat-loving bacteria found in hot places did resist heating very well. These bacteria live in extreme environments, such as boiling volcanic fumaroles in Yellowstone Park and midoceanic hydrothermal vents.
This is how PCR works: DNA to be copied is mixed with two short, complementary, single-stranded primers, along with nucleotides and heat-resistant DNA polymerase. The solution is heated to separate the DNA strands and cooled rapidly to allow the primers to bind. DNA polymerase then copies the primed DNA strands once. After a few minutes, the mixture is again heated so that the DNA separates into strands, and these are again fast-cooled to allow primers to bind. A second round of replication has taken place. After a few hours, the original piece of DNA has been copied thousands of times. This process is called the polymerase chain reaction because at each cycle, the number of DNA molecules is doubled.
The size of the piece that is copied is determined by the region of the original DNA to which the primers are complementary. Since the majority of the product of PCR matches the size of the DNA bracketed by the primers, this piece can be visualized using gel electrophoresis. Gel electrophoresis is a common way to study DNA. It is called “gel” because a thin sheet of Jell-O-like medium is used to separate DNA by size, with the smaller size DNA moving faster while the larger pieces move more slowly. It is called electrophoresis because the DNA moves through the medium due to an electric current run between the ends of the gel. We can then see the DNA pieces by using a stain.
The PCR technique can be used to amplify trace amounts of DNA from drops of dried blood, saliva, or a single hair follicle. It is also used to make DNA from scarce or degraded material, for example, mummies or fossils.
We will never forget the horrible events of September 11, 2001, that took place in New York City and Washington, D.C., in which close to three thousand innocent victims were blindly massacred. Yet, thanks to the science of genetics, many surviving relatives have had the solace of knowing that their loved ones’ remains were identified. This may bring to many some sense of closure. You probably heard on TV that friends and families of the victims were requested to provide hair- and toothbrushes known to belong to those who died. This is because DNA recovered from a single hair follicle or the very few cells present on a toothbrush can be used to type a person, to obtain this person’s “DNA fingerprint.”
There is not enough DNA in a hair follicle or a few cells to allow direct genetic typing. However, we have seen that the PCR reaction can amplify DNA samples tens of millions of times. This is what was done in the case of the 9/11 victims where, in many instances, only body parts could be recovered, making other types of identification impossible. DNA was first isolated from hair follicles, for example, and subsequently amplified by PCR with primers known to correspond to extremely variable regions of the human genome. Human DNA contains extensive stretches that do not carry genes. The lengths of these regions vary greatly from individual to individual. Yet these stretches are flanked by other sequences that do not vary much. The principle here is to use primers that bind to the conserved regions and amplify the regions of variable length. This can be done with several sets of primers that amplify a number of different variable regions. The amplified DNA is then characterized by gel electrophoresis.
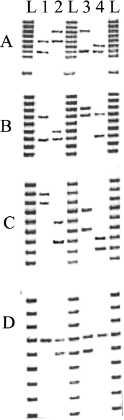
Figure B.1.1 DNA Fingerprinting. Gel electrophoresis of DNA samples from four individuals, represented by lanes 1–4, amplified using sets of PCR primers to four variable regions in the DNA, labeled here as A, B, C, and D. The lanes labeled L provide identical reference markers used to calibrate the distances that the DNA bands traveled in samples 1–4. Note that only one single band in D is shared by all four individuals.
Next, DNA was extracted from the remains of the victims and processed in the same way. By comparing the length of amplified DNA from the remains with those from the hairbrush, it is possible to provide positive identification of the victims (see figure B.1.1). This application shows that genetic technology is now indispensable to solving forensic problems. The same approach is used in paternity cases.
Another example of DNA typing is of historical importance and has helped uncover an impostor posing as a member of an imperial family. In 1918, Nicholas II Romanov, the last tsar of Russia, his wife Alexandra, and their children were assassinated by Bolshevik revolutionaries. Their bodies were dumped into a shallow unmarked grave. In 1993, their bones were dug up and identified by DNA typing. This was possible because Prince Philip of Edinburgh, the husband of Queen Elizabeth II, is a relative of the deceased Alexandra. Their DNA profiles matched.
Interestingly, shortly after the assassination took place, rumors started circulating that one of the daughters of Nicholas II and Alexandra, Anastasia, had survived. In 1922, a woman claiming to be Anastasia surfaced in Berlin and was able to convince many émigrés of the Russian nobility that she was indeed Anastasia. Some, however, were not convinced. Later, this woman emigrated to the United States under the name of Anna Anderson. She died in 1984. Thanks to preserved tissue samples that were kept in a hospital where she had undergone surgery, her DNA could be typed. The results were negative; Empress Alexandra and Prince Philip were not related to her. Why Anna Anderson claimed to be Anastasia is unclear. She maintained till her death that she was a Romanov. However, she never benefited, monetarily or otherwise, from her lies. We know now that she was simply an impostor.
We have learned in this chapter about the chemical composition of DNA, its double-helical structure, and its role as genetic blueprint. We also can see from its double-helical structure, based on complementary base pairing, how DNA can be copied. This understanding of DNA replication has led to the discovery of a technique, PCR, that allows the production of substantial amounts of DNA from very small amounts. PCR is now used on a routine basis in laboratories doing basic research and in forensic laboratories.
Have you wondered what DNA looks like? It is fairly easy to extract DNA using common equipment and materials found in your kitchen. The following is one recipe for isolating DNA. The recipe mentions onion but you can use other vegetables, such as lettuce or celery.
Ingredients
1 small onion
meat tenderizer
dishwashing detergent
cheesecloth
denatured alcohol (can be purchased at a pharmacy)
Directions
Peel and chop up 1 onion and place in blender.
Add twice the amount of water and blend until fine.
Add 1–2 tablespoons dishwashing detergent. This is to emulsify the membranes around cells that are made of lipids.
Add 1 tablespoon meat tenderizer. Meat tenderizer is typically made from papaya or other fruits that contain protease, an enzyme that breaks down proteins. This helps to release the DNA from proteins.
Gently (so that the mixture does not become foamy) mix in the detergent and meat tenderizer.
Filter through cheesecloth to get rid of plant debris.
Gently layer cold denatured alcohol on top of the clear filtered juice.
The white material at the interface is DNA!
If you want to collect the DNA, try spooling it up with a chopstick.
