6.1 Hurst exponent analysis on real traffic
The following section presents the case study of an analysis of the Hurst exponent. It was done both to demonstrate the results of research and to highlight the value of the graphical estimators for time series with large horizons. The three previous presented graphical estimators are used: domain rescaling, time–dispersion diagram, and the periodogram. In order to implement these methods for determining the Hurst parameter, the MATLAB software package was used, which offers the user a powerful command interpreter as well as a series of predefined functions optimized for numerical computations.
The traffic to be analyzed was captured using the tcpdump utility (Brenner 1997). It spanned over approximately 5 h from a busy time interval of the day. The data capture was done between 11:38 and 16:47 on October 12, 2005 on the premises of the AccessNet, Bucharest (Rothenberg 2006). The network architecture comprises around 20 network stations connected to a router. The captured traffic was split into five parts of an hour each. Every sequence contains 36,000 measurements, and every measurement represents the number of packages sent through the network at every 100 ms. Note that, for time series of such a large horizon, the graphical estimators (domain rescaling and dispersion–time diagram) become quite powerful, thus rendering the self-similarity degree quite precise.
The tcpdump was used for capturing packet-level traffic. The utility attaches to the network socket of the Linux kernel and copies each package that arrives at the network interface. More precisely, it allows for the network packages to be logged. This utility was used to obtain for each particular frame
• Time of arrival to kernel
• Source and destination addresses and port numbers
• Frame size (only user data are reported; in order to obtain real frame sizes, the header of each protocol should be added)
• Type of traffic (tcp, udp, icmp, etc.)
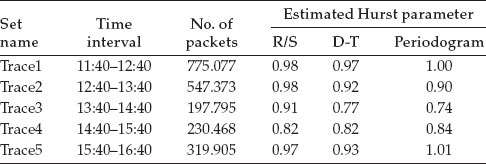
Table 6.1 The Hurst parameter estimated with the three estimator types
The time of arrival is practically the time when the kernel sees the packages and not the time of arrival at the network interface.
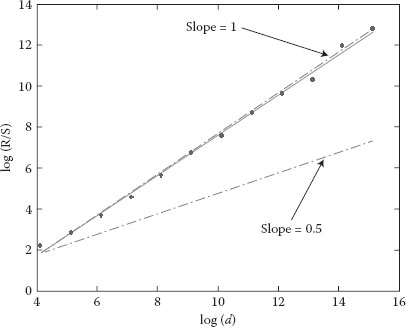
Note that for the first and last sets, the estimated Hurst parameter is close to 1, thus highlighting the strong self-similarity of the network traffic. For the other three sets, the estimated parameter is smaller, but different from 0.5. Judging by the time interval and the number of packets, one can conclude that the self-similarity increases when network usage is higher. In the lunch break (12–14 h) it is expected for the human activity to decrease, thus decreasing the traffic self-similarity (Table 6.1).
6.1.2 Graphical estimators representation
Hurst parameter estimation was performed only for time series composed of the number of packets that arrive in the 100 ms time interval. This chapter does not take into account the case of time series formed of the number of bytes transferred in the time unit. Anyway, estimation methods are identical in both cases.
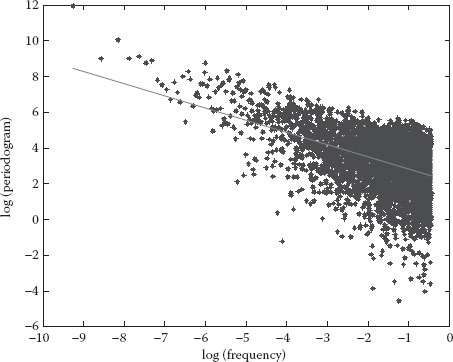
Graphical estimator was used for graphical representation, that is, domain rescaling, dispersion–time diagram, and periodogram. Only six diagrams are provided (Figures 6.1 through 6.6), three for Trace1 and another three for Trace4. Each diagram is represented on a fully logarithmic scale (both axes) and possesses a sequence of reference slopes. Thus, slopes corresponding to 0.5 and 1 values for the Hurst parameter have been drawn on the rescaled domain diagram. On the dispersion–time diagram, a line with −1 slope has been drawn, corresponding to a Hurst parameter of 0.5. The periodogram has no additional lines.
6.2 Inferring statistical characteristics as an indirect measure of the quality of service
6.2.1 Defining an inference model
In order to create a network model of a distributed environment such as the Internet, it is necessary to integrate the data collected from several nodes. Thus, a complete image of the network is obtained for the traffic visualization level. For network management, it is essential to know the dynamic traffic characteristics, for example, for error detection (anomalies, congestion), for monitoring QoS or for selecting servers. In spite of all these, because of the very large size and of the access rights, it is costly and sometimes impossible to measure such characteristics directly. In order to tackle this problem, several methods and instruments can be used for inferring the unseen performance characteristics of the network. In other words, it is necessary to identify and develop indirect traffic measuring techniques, with estimations based on direct measurements in accessible points, in order to define the global behavior in the Internet. Because of the similarities between the inference characteristics of a network and those of a medical tomography, the concept of network tomography was conceived. The method implies the usage of a statistic inference scheme for the unseen variables based on the simultaneous measurement of other, more easy to observe, characteristics from another (sub)network. Thus, the network tomography can be seen as an inverse statistic problem that includes two types of inference: (1) inference of the internal network characteristics based on an end-to-end way (Bestavros et al. 2000) and (2) inference of the aggregated internal flows on an end-to-end way (Cao et al. 2000).
Figure 6.1 Rescaled domain diagram (R/S) for the set Trace1.
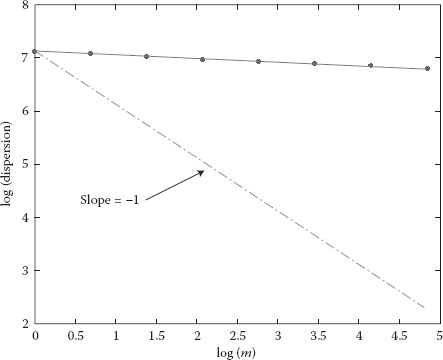
Figure 6.2 Dispersion–time diagram for the set Trace1.
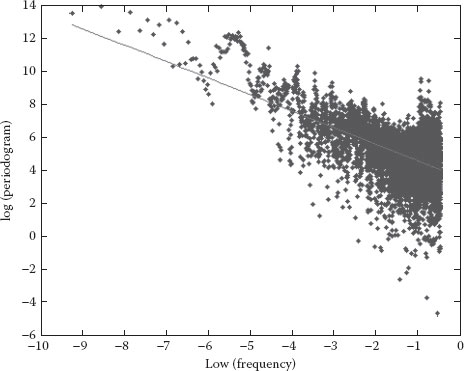
Figure 6.3 Periodogram for the set Trace1.
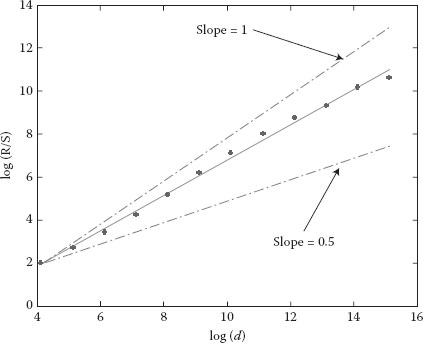
Figure 6.4 Rescaled domain diagram (R/S) for the set Trace4.
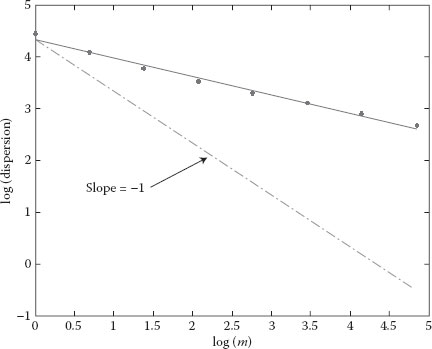
Figure 6.5 Dispersion–time diagram for the set Trace4.
Figure 6.6 Periodogram for the set Trace4.
Without reducing the general level of the problem, the information network examples to be provided will refer to the Internet. The fractal nature of the Internet traffic has been determined through several measurements and statistic studies. This work presents and analyses a stochastic mono-fractal process defined as a limit of the integrated superposition of diffusion process with a differential and linear generator, which indeed is a characteristic of the fractal nature of the network traffic. Technically, the Internet is centered on the IP that supports multiple applications, whose characteristics are mixed with the resources of the network, that is, the network management packets are sent on the same channels as the data packets (there is no separate signaling network). Additionally, there are also flow control packets of the transport protocol (TCP). Thus, traffic analysis is a complex process that must satisfy the following minimal requirement:
• User traffic request evaluation, especially when having different service classes
• Network resource sizing: router processing capacity, datalink transmission flow, and interface buffer sizing
• Checking the QoS offered by the network: packet loss rate, end-toend packet transfer delay for real-time applications, and defining the useful transport flow
• Testing the fitness level of performance models designed through analytical calculations or through simulation.
Network traffic measurements contain two categories: passive and active. For the majority of the following examples, the samples are obtained from passive probes, specifically adapted to provide traffic descriptive parameters.
The most common procedure for inferring traffic characteristics is the one using point to point links, based on the data collected from several routers via SNMP (Sikdar and Vastola 2001). Nevertheless, measuring static characteristics of aggregated flows still represents a problem open for research. The network traffic presents correlations between behaviors at different moments and different places, for various motives. It is already established that in the Internet one can observe daily self-similar patterns. Previous studies also demonstrated self-similarities that depend on the place of implementation (Wolman et al. 1999), nature of services (Lan and Heidemann 2001), and type of transiting data (Floyd and Paxson 2001).
The present approach is based on a dual modeling structure proposed in Lan and Heidemann (2002). In its simplest form, it is assumed that the network traffic (T) can be modeled as a function of three parameter sets: number of users (N), user behavior (U), and application-specific parameters (A). In other words, T = f (N, U, A). User behavior parameters can be packet arrival distribution probability or the number of requested pages, while application-specific parameters can be object size distributions or the number of objects in a Web page. Experimental results show that behavior parameter distributions (U) display a correlation trend in the same network. This statement suggests that the user behavior parameter distributions at time t2 can be modeled based on the ones at time t1 on the same network. In addition, it is already demonstrated that the application-specific parameter distributions (A) of two networks with similar user populations are susceptible of being correlated. More precisely, it is observed that the application-specific parameter distributions of two similar networks tend to be correlated when the traffic is aggregated on a higher level. On a lower traffic level, the application-specific parameter distributions are still correlated but only in their cores. Because a higher level of aggregate traffic can be generated either by a greater number of users or by a longer measurement horizon, we can conclude that similar user populations tend to have similar behaviors in similar applications. On the contrary, for a lower aggregation level, it is more probable for some “dominant” flows to cause large variations in the distributions. Moreover, the traffic in similar networks has the same distribution model every day regarding the number of active users. In other words, the number of active users is also correlated for two similar networks in different moments of the day. The last two statements suggest that, by using a spatial correlation between two similar networks, the application-specific parameter distributions and the number of active users can be inferred based on the measurements performed on the other network.
Starting from the previous statements, the authors propose the following approaches for inferring the traffic in network n1 based on the measurements of n2, considering the two networks n1 and n2 as having similar user populations:
• The first step is to collect the traffic from both networks n1 and n2 over a certain period. Based on these initial measurements, the three traffic parameter sets can be established (N, U, A) for n1 and n2. Afterward, the derived statistics can be compared in order to determine if there exists a spatial correlation between n1 and n2.
• Once the similarity between n1 and n2 has been confirmed and the spatial correlations between them have been calculated, we can establish a model for each of the three traffic parameter sets (N, U, A) for n1 at a given future time based only on measurements done on n2. In particular, the number of active users (N) and the application-specific parameter distributions (A) of network n1 can be inferred based on the measurements performed on network n2 in the same time interval, while the application-specific parameter distributions (U) from n1 can be inferred using the statistics derived from the initial measurements (done at step 1). Note that the first step must be performed only once.
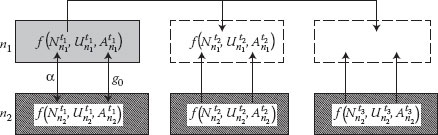
Figure 6.7 illustrates this concept: the colored squares indicate the collected data, while in the striped squares have the inferred data. Based on the initial measurement from time t1 that confirms the similarity between n1 and n2, further measurement in n2 can be used to predict the traffic in n1 at times t2 and t3.
6.2.2 Highlighting network similarity
Intuitively, two networks are “similar” if they have user populations with similar characteristics. For example, the traffic generated in two laboratories of the Faculty of Automatic Control and Computer Science may be similar because the students display common behavior when using the applications. In other words, it can be considered that two networks are similar when there are correlations at the application level in the traffic. However, a formal procedure is needed in order to accomplish traffic parameters inference. First of all, the two networks will be checked for traffic similarities. Then, the distributions for user behavior and application-specific parameter will be calculated. Lastly, the statistical data of the traffic from both networks will be compared both qualitatively and quantitatively, in order to establish if the two are similar.
Figure 6.7 Traffic inference using network similarity.
In order to compare the traffic quantitatively, the graphic of the cumulative distribution function (CDF) is analyzed for the distributions derived from the two networks. For a quantitative comparison, the two distributions are normalized. Three types of tests have been used in order to determine if the two distributions are significantly different regarding the average, variance, and shape. Practically, the Student t-test was used for comparing average, the F test for evaluating variance, and the Kolmogorov–Smirnov test for testing the shape. It is considered that the two distributions are strictly similar if all the three tests output a 95% trust level. Note that all the mentioned tests are exact, and thus hard to apply. In order to relax the testing procedure, approximate similarity is given by the function s that results as a linear combination of the average, variance, and shape differences: s = w1 ⋅ m + w2 ⋅ v + w3 ⋅ D,
where
and
In the previous formulas, μ denotes the average, v denotes the data variance, and D is the value of the Kolmogorov–Smirnov test that represents the largest absolute value between the two data sets. N1 and N2 are data samples taken from the two networks, while w1, w2, and w3 are weights with positive values that allow the user to prioritize certain metrics. The possible values for m, V, and D are between 0 and 1. Intuitively, the two networks are more similar if the value for the function s is closer to 0.
It is clear that the application-specific parameter distributions of two networks are more susceptible of being correlated when the traffic is more intensely aggregated. In spite of this, one can observe that for a lower traffic aggregation level, there are some dominant flows that can cause large variations in the distributions tail. Such variations suggest the necessity of separately modeling the kernel and the tail, especially for traffic distributions with long distribution tails. While these dominant flows account for only a small number of the Internet flows, they consume a significant percent of bandwidth. In order to formally describe the aggregation level (G), it is defined as the product of the quantity of traffic generated by the sources (S) and the length of the measuring period (T), G = S × T. Moreover, S can be described as a function of the number of users and the traffic volume generated by each user. Such a definition implies that the effect of dominant flows in the traffic tail can be reduced, if the user population is larger or if the data is collected over a longer time interval. Network similarity suggests the possibility of inferring traffic data in places where direct data acquisition is otherwise impossible. In other words, user behavior parameter distributions tend to be correlated in the same way as the application-specific parameter distributions defined denoted T = f (N, U, A). By using such a correlation, the behavior parameter distribution can be modeled at t2 based on measurement done at t1 in the same network . The inference procedure obtained from Figure 6.7 can be refined as follows:
• The first step is to collect data traffic from both networks n1 and n2 for a certain period of time (from t0). The three parameter sets (number of active users (N), user behavior parameter distributions (U), and application-specific parameter distributions (A)) can be calculated from traffic traces.
• The similarity between n1 and n2 suggests that it is highly probable for the number of users from network n1 to be proportional to the number of users from n2 at any moment (Nn1 = α × Nn2 with α being a constant). By using traces collected at time t0, the scale factor α can be calculated. Moreover, the similarity between the networks n1 and n2 implies the existence of some functions g1, g2, etc., named correlation functions, so that and . After determining from the initial measurements of the spatial correlations between n1 and n2, the traffic from network n1 can be predicted using only measurements from network n2.
• Lastly, if the user behavior parameters are time correlated, they can be calculated for every moment in time in network n1 based on the statistical data calculated initially at moment t0. Now the relationship can be written as: .
6.2.3 Case study: Interdomain characteristic interference
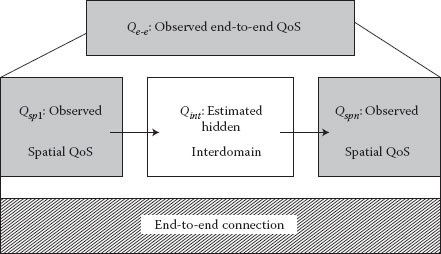
The methodology described earlier was illustrated in a case study that wants to determine by inference the QoS inside the domain based on the measurements done at the end of one communication way. The network tomography technique is based on the assumption that end-to-end QoS time series data, denoted as Qe–e are observable characteristics on every end in the domain. Additional to the Qe–e there can be spatial QoS data series denoted Qspi, i = 1,…, n that are measured on the same route in the interdomain and can be linked to Qe–e for certain time intervals that are of interest for the estimation. The problem of determining the intermediate unobservable characteristics from the interdomain (hidden network) is thus formulated as follows: given time series Qe–e and space series Qspi—the hidden space data series can be calculated.
The scenario for a network tomography is as follows (Figure 6.8):
1. A trust interval (μ1 − μ2) is chosen, which represents the difference between the two averages and contains all the values that will not be rejected in neither one of the two test hypothesis: H0: μ1 − μ2 = 0 and H1: μ1 − μ2 ≠ 0.
2. The measured values that contributed to estimating the average are adjusted, in case they are quasi-independent (correlated, the self-correlation function, ACF(i) ≪ 1 for any i > 0).
3. For normal or highly correlated distributions, the measured values are kept.
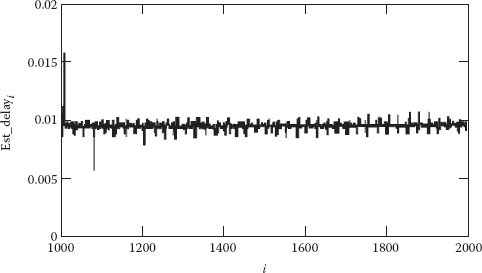
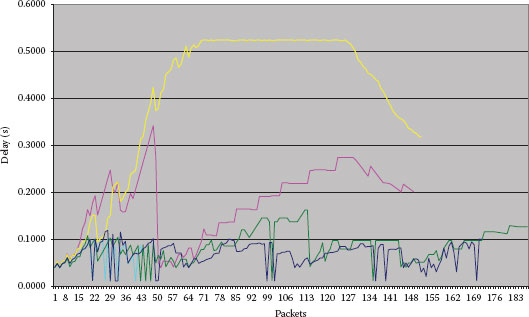
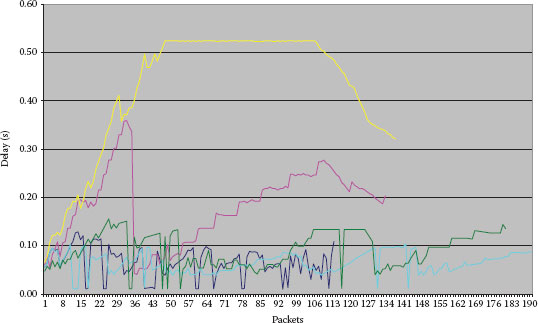
The experiments have been done on an emulation environment requiring only one PC running a Linux operating system configured as a router to create a wide variety of networks and also critical end-to-end performance conditions for different voice over IP (VoIP) traffic classes. Because there was no additional traffic, maximum and minimum values of the average are almost identical. Time series estimated for the interdomain are given in Figure 6.9.
In case the load of the network is high, spatial QoS values can be ignored, while estimating the interdomain delay with the help of the model that reflects such a delay based on an end-to-end pattern. The estimated end-to-end delay is presented in Figure 6.10.
Figure 6.8 Block diagram of the network tomography.
Figure 6.9 Interdomain delay estimation.
Figure 6.10 “Hidden” delay estimation in high traffic environments.
6.3 Modeling nonlinear phenomena in complex networks and detecting traffic anomalies
The potential of fractal analysis for evaluating traffic characteristics, especially detecting traffic anomalies, is demonstrated in this chapter by simulation in a virtual environment. To this end, some original methods are proposed: an Internet traffic model based on graphs of scale-free networks, one method for determining self-similarity in generated traffic, a method that compares the behavior of two subnetworks and a powerful experimental testing method (using a parallel computing platform) running the pdns (parallel/distributed network simulator) on different subnetworks with a scale-free topology.
While the number of nodes, protocols, used ports, and new applications (e.g., Internet multimedia applications) keep increasing, it is more evident for the network administrators that there are not enough instruments for measuring and monitoring traffic and topology in high-speed networks. Even the simulation of such networks is becoming a challenge. Presently, there is no instrument to precisely simulate the Internet traffic.
There are two type of network monitoring: active and passive. During active monitoring, the routers of a domain are polled periodically in order to collect statistics about the general state of the system. This intense data volume is stored so that to extract useful information for monitoring. In the case of passive monitoring, the network is analyzed only on its contour edges. The parameters are determined by applying mathematical formulas on the set of collected data. In this case, the major problems are related to storing and processing the traffic that passes through the nodes on the contour.
Numerous network management applications have traffic processing methods for packets or bytes, differentiate according to the header fields in classes that depend on the application requirements, such as service development, security applications, system engineering, consumer billing, etc.
While for active measuring it is necessary to inject probes in the network traffic and then to extrapolate the network performance based on the performance of the injected traffic, the passive systems are based on observing and logging the network traffic. One characteristic of passive measuring systems is that they generate a large volume of measured data, obtained through inference techniques that exploit traffic self-similarity.
The network tomography (notion coined in (Vardi 1996)) tackles inference problems. It comprises of statistic inference schemes of unobservable characteristics from a network by simultaneously measuring other observable ones. The network tomography includes two typical forms: (1) inference of internal network characteristics based on end-to-end measurements (Coates and Nowak 2001; Pfeiffenberger et al. 2003) and (2) inference of the traffic behavior on the end-to-end path based on aggregated internal flows such as traffic intensity estimation at sender–receiver level based on analyzing link-level traffic measurements (Cao et al. 2000; Coates et al. 2002).
Fractal analysis seems to be suitable for both methods: direct and indirect measurement of network characteristics and anomalies. Previous work (Dobrescu et al. 2004a) is focalized on using fractal techniques in video traffic analysis. In this framework, two analytical methods have been used: self-similarity (Dobrescu et al. 2004b) and multifractal analysis (Dobrescu and Rothenberg 2005a).
The goal of this chapter is to demonstrate, through virtual environment simulations, the potential of fractal analysis techniques for measuring, analyzing, and synthesizing network information in order to determine the normal network behavior, to be used later for detecting traffic anomalies. To this end, the authors propose a model of Internet traffic based on graphs of scale-free networks where one can apply an inference based on self-similarity and fractal characteristics. This model allows for splitting a large network in several networks with quasi-similar behavior and then for applying fractal analysis for detecting traffic anomalies in the network.
The current state of rapid development of advanced technology has led to the emergence and spread of ubiquitous networks and packet data, which gradually began to force the system switching network and at the same time increase the relevance of the traffic self-similarity. The fractal analysis can solve several problems, such as the calculation of the burst for a given flow, the development of algorithms and mechanisms providing quality of service in terms of self-similar traffic and the determination of parameters and indicators of quality of information distribution.
6.3.2 Self-similarity characteristic of the informational traffic in networks
6.3.2.1 SS: Self-similar processes
Mandelbrot introduces an analogy between self-similar and fractal processes (Mandelbrot and Van Ness 1968). For incremental processes, Xs,t = Xt − Xs, the self-similarity is defined by the equation:
Mandelbrot builds its own self-similar process (fBm—fractional Brownian movement) starting from two properties of the Brownian movement (Bm): it has independent increments and it is self-similar with a Hurst parameter H = 0.5.
Denoting Bm as B(t) and fBm as BH(t), below is given a simplified version of the Mandelbrot fBm:
A self-similar process is one with long-range dependence (LRD) if α ∈ (0,1) and C > 0 exist so that:
where ρ(k) is the kth order self-correlation.
When presented in logarithmic coordinates, Equation 6.3 is called the correlogram of the process and has an asymptote at –α. Note that self-similar processes exist that are not LRD, while LRD processes also exist that are not self-similar. Nevertheless, fBm with H > 0,5 is both self-similar and LRD.
In a paper from 1993, Leland et al. report discovering the self-similar nature of local-area network (LAN) traffic in general, and of Ethernet traffic, to be more precise. Note that all methods used in (Leland et al. 1993) (and in numerous previous works) detect and estimate LRD rather than self-similarity. The only proof given by self-similarity is the visual inspection of the data series at different time scales. Since then, self-similarity (LRD) has been reported for different kinds of traffic: LAN, WAN, variable byte rate video, SS7, HTTP, etc.
The lack of access in high-speed, highly aggregated links, as well as the lack of devices capable of measuring traffic parameters have hindered until now the study of Internet informational traffic. In principle, in this case, the traffic can differ quantitatively from the types enumerated earlier, because of factors like: too high aggregation level, end-to-end traffic policing and shaping, and a RTT (round trip time) too large for TCP sessions. Currently, some researchers stated that the Internet traffic aggregation causes a convergence toward a Poisson limit. For reasons previously presented and based on several remarks on a rather short timescale, the authors do not agree on the following: on a short timescale, the effects of network transport protocols are believed to dominate the traffic correlations; and on a long timescale, nonstationary effects such as daily load graphs become significant.
6.3.2.1.1 Self-similarity in network operation In almost all fields of network communications, it is important that the traffic characteristics are understood. In a packet exchange environment, there are no reserved resources for a connection, which would allow for the packets to reach a node with a higher rate than the processing one.
Although, in general, there can be many possible operations, they are split in just two classes: serialized (sending bits outside the link) and internal processing (all the processing is done inside the node: classifying, routing tables parsing, etc). The serialization delays are determined by the speed of the output line. Internal processing delays are random, but data structures and advanced algorithms are employed in order to obtain deterministic performances. As a consequence, the truly random part of the delay is the time a packet spends waiting. The internal processing of a node is relatively well known (through analysis or direct measurements). In contrast, incoming traffic flows are neither fully known nor controllable. Thus, it is of great importance to accurately model these flows and to predict the impact they may have upon the network performance.
It is already demonstrated that a high variability associated with LRD or SS processes can strongly deteriorate network performance, generating queue delays higher than the ones predicted with traditional models. Figure 6.11 illustrates this aspect. The average length of a queue obtained through queue simulation is very different from the one obtained through a simulation model (M/D/1).
In the case of the simple node model, the “D” (determinist) and “1” (no parallel service) hypotheses are feasible, so we would like to identify “M” (Markovian, Poisson exponential process) as one discrepancy cause. In the following section, the aim is to demonstrate that there is a “fBm/s/1” queue distribution model.
6.3.2.1.2 Fractal analysis of Internet traffic When the measurements have fractal properties then this characteristic is expressed through some observations. Self-similarity is a statistic property. Suppose there are (very long) data series, with finite average and variance (covariance of the stationary statistic processes). Self-similarity implies a fractal behavior: it retains its aspect over several scales.
The main characteristics, deduced from the self-similarity, are long-range dependency (LRD), slowly decreasing dispersion. The dispersion–time graph shows a slow decrease. Moreover, the self-correlation function for aggregate processes cannot be identified against the original processes.
Consider that there is available a set of data expressed as a time series. In order to find long-range dependencies, data obtained from the simulation model must be evaluated on different timescales. The same number of cells sample versus time must be cut in lags. Cuts should be performed several times, varying, in the meantime, the number and the cut length. The length of n lags falls in the scope future observations as well as the number of observations in a lag. For each n, a number of lags is randomly selected. This lag number must be identical for all values of n. For the selected lags, two parameters are calculated:
Figure 6.11 Representation limit for simulating a queue with a classical model.
• that is the lag sample range
• S(n) – dispersion of {X1 + X2 + … + Xn} of a lag
For the short-range dependence sets, the expected value for E[R(n)/S(n)] is approximately equal to c0n1/2. On the contrary, for the sets with long-range dependency, E[R(n)/S(n)] is approximately c0nH with 0,5 < H < 1. H is the Hurst parameter and c0 is a constant of relative minor importance.
Hurst designed a normalized, dimensionless measure for characterizing variability, named the rescaled domain (R/S). For an observation data set X = {Xn, n ∈ Z+} with a sample average , sample dispersion S2(n), and domain R(n), the adjusted rescaled domain or the R/S statistics are given by
where
For many natural phenomena, E[R(n)/S(n)] ~ cnH when n → ∞, c being a positive constant, independent of n. By introducing logarithm on both sides, the result is log{E[R(n)/S(n)]} ~ H log(n) + log(c) for n → ∞. Thus, the value of H can be estimated by graphically representing log{E[R(n)/S(n)]} as a function of log(n) (POX diagram), and approximating the resulted points with a straight line of slope H.
The R/S method is not precise; it does only estimate the self-similarity level of a time series.
Figure 6.12 contains an example of a POX diagram. H is the Hurst parameter. If there is no fractal behavior, then H is close to 0.5, while a value higher than 0.5 suggests self-similarity and fractal character.
6.3.3 Using similarity in network management
6.3.3.1 Related work on anomalies detection methods
One of the main goals of fractal traffic analysis is to show the potential to apply signal processing techniques to the problem of network anomaly detection. Application of such techniques will provide better insight for improving existing detection tools as well as provide benchmarks to the detection schemes employed by these tools. Rigorous statistical data analysis makes it possible to quantify network behavior and, therefore, more accurately describe network anomalies. In this context, network behavior analysis (NBA) methods are necessary. Information about a single flow does not usually provide sufficient information to determinate its maliciousness. These methods have to evaluate the flow in the context of the flow set. There are several different approaches that can be classified into groups depending on the field they utilize for the detection.
Figure 6.12 POX diagram example.
6.3.3.1.1 Statistical-based techniques These techniques are widely used for network detection. Flow data represent the behavior of the network by statistical data, like a traffic rate, packet, and flow count for different protocols and ports. Statistical methods typically operate on the basis of a model and keep one traffic profile representing the normal or learned network traffic and a second one representing the current traffic. The anomaly detection is based on comparison of the current profile to the learned one, significant deviation of these two profiles means network anomaly and a possible attack (Garcia-Teodoro et al. 2009).
6.3.3.1.2 Knowledge-based techniques This category includes so-called expert system approach. Expert systems classify the network data according to a set of rules, which are deduced based on the training data. Specification-based anomaly methods use a model, which is manually constructed by a human expert, in terms of a set of rules (the specifications) that determine the normal system behavior.
6.3.3.1.3 Machine learning-based techniques Several tools can be included in this category, the most representative being the following.
Bayesian networks, which are probabilistic graphical models that represent a set of random variables and their conditional dependencies in a form of directed acyclic graph. The Bayesian network learns the casual relations between attributes and class labels from the training data set before it can classify unknown data.
Markov models include two different approaches: Markov chains and hidden Markov models. A Markov chain is a set of interconnected through certain transition probabilities, which determine the topology and the capabilities of the model. The probability of transition is determined during training phase and reflects the normal behavior of the system. Anomalies are detected by comparing the probability of observed sequences with a fixed threshold. The second hidden Markov model assumes that the system of interest is a Markov process with hidden transitions and states. Only the so-called productions are observable.
Decision tree, which can efficiently classify anomalous data. The root of a decision tree is the first attribute with test conditions that split input data toward one of the internal nodes depending on the characteristics of the data. The decision tree has to be first trained with known data before it can be used to classify unknown data.
Fuzzy logic techniques, which are derived from fuzzy set theory. Fuzzy methods can be used as an extension to other approaches like in case of the intrusion detection using fuzzy hidden Markov models. The main disadvantage is high resource requirements.
Clustering and outer detection, which are methods used to separate a set of data into groups which members are similar or close to each other according to given distance metric.
The abovementioned methods for anomaly detection in computer networks have been studied by many researchers.
One of the first surveys about anomaly detection was presented in Coates et al. (2002), which proposed a taxonomy in order to classify anomaly detection systems. On the other hand, it focused on classifying commercial products related to behavioral analysis and proposed a system that collects data from SNMP objects and organizes them as a time series. An autoregressive process is used to model those time series. Then, the deviations are detected by a hypothesis test based in the method generalized likelihood ratio (GLR). The behavior deviations that were detected in each SNMP object are correlated later according to the objects’ characteristics. The first component of the algorithm applies wavelets to detect abrupt changes in the levels of ingress and egress packet counts. The second one searches for correlations in the structures of ingress and egress packets, based on the premise of traffic symmetry in normal scenarios. The last component uses a Bayes network in order to combine the first two components, generating alarms.
In a notable paper (Li et al. 2008), the authors analyzed the traffic flow data using the technique known as principal component analysis (PCA). It separates the measurements into two disjoint subspaces: the normal subspace and the anomalous subspace, allowing the anomaly detection for characterizing the normal network-wide traffic using a spatial hidden Markov model (SHMM), combined with topology information. The CUSUM algorithm (Cumulative Sum) was applied to detect the anomalies. This work proposes the application of simple parameterized algorithms and heuristics in order to detect anomalies in network devices, building a lightweight solution. Besides, the system can configure its own parameters, meeting network administrator’s requirements and decreasing the need for human intervention in management.
Brutlag (2000) used a forecasting model to capture the history of the network traffic variations and to predict the future traffic rate in the form of a confidence band. When the variance of the network traffic continues to fall outside of the confidence band, an alarm is raised. Barford et al. (2002) employed a wavelet-based signal analysis of flow traffic to characterize single-link byte anomalies. Network anomalies are detected by applying a threshold to a deviation score computed from the analysis. Thottan and Ji take management information base (MIB) data collected from routers as time series data and use an auto-regressive process to model the process. Network anomalies are detected by inspecting abrupt changes in the statistics of the data (Thottan and Ji 2001). Wang et al. (2002) take the difference in the number of SYNs (beginning messages) and FINs (end messages) collected within one sampling period as time series data and use a nonparametric cumulative sum method to detect SYN flooding by detecting the change point of the time series. While these methods can detect anomalies, which cause unpredicted changes in the network traffic, they may be deceived by attacks that increase their traffic slowly.
Let us look at other studies related to the use of the machine learning techniques to detect outliers in data sets from a variety of fields. Ma and Perkins present an algorithm using support vector regression to perform online anomaly detection on time-series data (Ma and Perkins 2003). Ihler et al. present an adaptive anomaly detection algorithm that is based on a Markov-modulated Poisson process model, and use Markov chain Monte Carlo methods in a Bayesian approach to learn the model parameters (Ihler et al. 2006).
6.3.3.2 Anomaly detection using statistical analysis of SNMP–MIB
Detecting anomalies is the main reason for monitoring the network. Anomalies represent deviations from the normal behavior. For a basic definition, anomalies can be characterized by correlating changes in measured data during abnormal events (Thottan and Ji 2003). The term “transient changes” refer to abrupt modifications of measured data. Anomalies can be classified into two categories. The first category is related to performance problems and network failure. Typical examples of performance anomalies are file server defects and congestions. In certain cases, software problems can manifest as network anomalies, such as protocol implementation errors that determine increases or decreases of the traffic load characteristic. The second category of anomalies is related to security problems (Wang et al. 2002).
Probing instruments facilitate an instantaneous measurement of the network behavior. Network test samples are obtained with specialized instruments such as ping or traceroute that can used to obtain specific parameters such as packet loss or end-to-end delays.
These methods do not necessitate cooperation between network services providers, but imply a symmetrical route between source and destination. On the Internet, this assumption cannot be guaranteed and thus data obtained through the probing mechanism can be limited in the case of anomaly detection. Other methods have been used for determining the traffic behavior: data routing protocols (Aukia et al. 2000), packet filtering (Cleveland et al. 2000), and data from network management protocols (Stallings 1994). This last category includes simple network management protocol (SNMP) that assures the communication mechanism between a server and hundreds of SNMP agents in the network equipment. The SNMP server holds certain variables, management information base (MIB) ones, in a database. Because of the accuracy provided by the SNMP, it is considered an ideal data source for detecting network anomalies. The most used anomaly detection methods are the rule-based approach (Franceschi et al. 1996), finite state machine models (Lazar et al. 1992), pattern matching (Clegg 2004), and statistical analysis (Duffield 2004). Among these methods, statistical analysis is the only one capable of continually following the network behavior and does not need significant recalibration. For this reason, the proposed anomaly detection method employs statistical analysis based on correlation and similarity in SNMP MIB variable data series.
Network management protocols provide information about network traffic statistics. These protocols support variables that correspond to traffic counts at the device level. This information from the network devices can be passively monitored. The information obtained may not directly provide a traffic performance metric but could be used to characterize network behavior and, therefore can be used for network anomaly detection. In the following will be presented the details of the method for anomaly detection proposed by Thottan and Ji (2003).
Using this type of information requires the cooperation of the service provider’s network management software. However, these protocols provide a wealth of information that is available at very fine granularity. The following subsections will describe this data source in greater detail.
6.3.3.2.1 Simple Network Management Protocol (SNMP) SNMP works in a client–server paradigm. The protocol provides a mechanism to communicate between the manager and the agent. A single SNMP manager can monitor hundreds of SNMP agents that are located on the network devices. SNMP is implemented at the application layer and runs over the UDP. The SNMP manager has the ability to collect management data that is provided by the SNMP agent but does not have the ability to process this data. The SNMP server maintains a database of management variables called the management information base (MIB) variables. These variables contain information pertaining to the different functions performed by the network devices. Although this is a valuable resource for network management, we are only beginning to understand how this information can be used in problems such as failure and anomaly detection.
Every network device has a set of MIB variables that are specific to its functionality. MIB variables are defined based on the type of device as well as on the protocol level at which it operates. For example, bridges that are data link-layer devices contain variables that measure link-level traffic information. Routers that are network-layer devices contain variables that provide network-layer information. The advantage of using SNMP is that it is a widely deployed protocol and has been standardized for all different network devices. Due to the fine-grained data available from SNMP, it is an ideal data source for network anomaly detection.
6.3.3.2.2 SNMP–MIB Variables The MIB variables fall into the following groups: system, interfaces (if), address translation (at), Internet protocol (ip), Internet control message protocol (icmp), transmission control protocol (tcp), user datagram protocol (udp), exterior gateway protocol (egp), and simple network management protocol (snmp). Each group of variables describes the functionality of a specific protocol of the network device.
Depending on the type of node monitored, an appropriate group of variables can be considered. If the node being monitored is a router, then the ip group of variables are investigated. The ip variables describe the traffic characteristics at the network layer. MIB variables are implemented as counters. Time-series data for each MIB variable is obtained by differencing the MIB variables at two subsequent time instances called the polling interval.
There is no single MIB variable that is capable of capturing all network anomalies or all manifestations of the same network anomaly. Therefore, the choice of MIB variables depends on the perspective from which the anomalies are detected. For example, in the case of a router, the ip group of MIB is chosen, whereas for a bridge, the if group is used.
As the network evolves, each of the methods for statistical analysis described above requires significant recalibration or retraining. However, using online learning and statistical approaches, it is possible to continuously track the behavior of the network. Statistical analysis has been used to detect both anomalies corresponding to network failures, as well as network intrusions. Interestingly, both of these cases make use of the standard sequential change point detection approach.
Abrupt changes in time-series data can be modeled using an autoregressive (AR) process. The assumption here is that abrupt changes are correlated in time, yet are short-range dependent. In our approach, we use an AR process of order to model the data in a 5-min window. Intuitively, in the event of an anomaly, these abrupt changes should propagate through the network, and they can be traced as correlated events among the different MIB variables. This correlation property helps distinguish the abrupt changes intrinsic to anomalous situations from the random changes of the variables that are related to the network’s normal function. Therefore, network anomalies can be defined by their effect on network traffic as follows: Network anomalies are characterized by traffic-related MIB variables undergoing abrupt changes in a correlated fashion. Abrupt changes in the generated traffic are detected by comparing the variance of the residues obtained from two sequential data windows: learning and testing (Figure 6.13). Residues are obtained by imposing an AR model on the time series in each window.
It can be seen that in the learning windows there is a change, while in the test one the correlogram remains similar.
6.3.3.3 Subnetwork similarity testing
It can be said that two networks are similar if there are correlations at the application level of the traffic. In order to demonstrate similarity, the method proposed by Lan and Heidemann (2005) is used, which employs a global weight function s to determine if two distributions are significantly similar regarding average, dispersion, and shape: s = w1 · A + w2 · B + w3 · C,
Figure 6.13 Detecting abrupt changes.
where
where μ is the average, σ is the dispersion, and C is the Kolmogorov–Smirnov distance (the greatest absolute difference between the cumulative distributions of the two data sets).
N1 and N2 are samples that come from two different networks, and w1, w2, and w3 are positive, user-defined weights that allow he or she to prioritize some particular metrics (average, dispersion, or shape). Intuitively, two networks are similar if s is close to zero. This method was tested considering the Web traffic simulated on an SFN Internet model (Ulrich and Rothenberg 2005). After generating a large network model, a federalization is performed and the similarities are checked in pairs of subnetworks.
6.3.4 Test platform and processing procedure for traffic analysis
Traffic generation is an essential part of the simulation. Randomly, one to three simultaneous traffic connections are initiated from the client networks, and, for simplicity, ftp sessions are used to randomly select destination servers. It is decided that the links connecting routers must have speed superior to that of the link connecting clients to routers, for example, server-router 1 Gbps, client-router 10 Mbps, router-router 10, 100 Mbps or 1 Gbps depending on the router type. The code generated respecting these two conditions is added to the network description file in order to be processed by the simulator.
A modular solution is used, which permits reusing various components from different parts of the simulator. The same network type generated by the initial script can be used for both single-CPU and distributed simulation, thus offering a comparison between the two simulation setups.
NS2 is a network simulator based on discrete events, discussed already in Sections 4.3.2.3 and 5.1. The current version of NS (version 2) is written in C++ and OTcl (Chung 2011). Multi CPU simulations used the pdns extension of NS2, which has a syntax close to NS2. The main difference is in the number of extensions necessary for parallelizing so that the various instances of pdns to be able to communicate one to another and create the global image of the network to be simulated. All simulation scenarios run for 40 s.
In order to obtain a parallel/distributed environment, it was necessary to build a cluster running Linux. The cluster can run applications using a virtualization environment. Parallel virtual machine (PVM) was used for developing and testing applications. It is a framework of software packages that facilitate the creation of a machine running on multiple CPUs by using available network connections and specific libraries (Grama et al. 2003). The cluster comprises of a main machines and a total of six cluster nodes. The main machine provides all necessary services for the cluster nodes, that is, IP addresses, boot, NFS for data storage, tools for updating, managing, and controlling the images used by the cluster nodes, as well as the access to the cluster. The main computer provides an image of the operating system to be loaded on each of the cluster nodes, because they do not have their own storage. Because the images reside in the memory of each cluster, some special steps are necessary to reduce the dimension of the image and to provide as much free memory as possible for running simulation processes. The application partition is read-only, while the data partition is read-write and accessible to users on all machines, in a similar manner, providing transparent access to user data. In order to access the cluster, the user must connect to a virtual server on the main machine that can behave like a cluster node when it is not needed as an extra computer.
6.3.4.3 Network federalization
In order to use the pdns simulator, the network must be subdivided in quasi-independent subnetworks (Wilkinson and Pearson 2005). Each pdns instance addresses a specific subnetwork, thus the dependencies between them are minimal; there must be as few links as possible between nodes from different subnetworks.
The approach of simulating on a federalized network is used. A federalization algorithm was devised and implemented in order to separate the starting network in several smaller subnetworks. The algorithm generates n components. The pdns script takes as input the generated network and the federalization. Depending on the network connectivity, they are assigned different roles—router or end-user—and corresponding traffic scenarios are associated. Also, a different approach of partitioning a NS script in several pdns is employed, using autopart (Riley et al. 2004), a tool for simulating the partitioning based on the METIS partitioning package (METIS). Autopart takes a NS2 script and creates a number of pdns scripts that are ready to run in parallel on several machines.
6.3.5 Discussion on experimental results of case studies
6.3.5.1 Implementing and testing an SFN model for Internet
A scale-free network (SFN) is a model where the inference based on self-similarity and fractal characteristics can be applied. Scale-free networks are complex networks, in which a few nodes are heavily connected while the majority of the nodes have a very small number of connections. Scale-free networks have a degree distribution of P(k) = k(−λ) where λ can vary from 2 to 3 for the majority of real networks.
Numerous networks display a scale-free behavior including the Internet.
An algorithm was designed and implemented for generating those subsets of scale-free networks that are close to real ones, such as the Internet. This application is able to handle a very large collection of nodes, to control the generation of network cycles and the number of isolated nodes. It was written in Python, thus making it portable. The algorithm starts with a manually created network of a few nodes. By using increase and preferential attachment algorithms new ones are added. An original component is introduced calculating ahead a number of nodes for each level. Preferential attachment is followed by applying the restriction of having the optimal number of nodes per degree.
Table 6.2 Simulations time for a network model of 100,000 nodes and high traffic
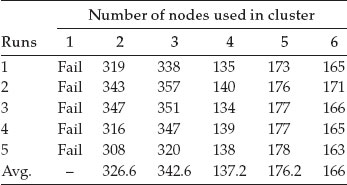
For tests, it was decided to run 40 s traffic simulations for a scale-free networks model with 10,000 nodes. On such a scale, one-node processing is not possible, because the cluster node runs out of memory. In order to obtain valid results, the simulation was run on a different, more stronger machine, with more memory and virtual memory. Table 6.2 shows the time used for simulations(s) for a network model of 100,000 nodes and high traffic.
This scenario was simulated for five times in similar load conditions. During this simulation, it was noted that by adding more nodes (in our case, more than 4), the simulation process is slower. Another remark is that the 2-CPU simulation is swifter than the 3-CPU one, although the optimal number of nodes is not 2.
6.3.5.2 Detecting network anomalies
The statistical technique presented was applied for detecting anomalies for SNMP MIB. A summary of the results obtained through statistical techniques is presented in Table 6.3.
The types of observed anomalies are the following: server disfunctionalities (errors, failures), protocol implementation errors, network access problems. For example, in the case of a server error, the defect was predicted almost 7 min before incidence. In order to detect the anomalies from the point of view of a router, only the IP level is used. Figure 6.14 shows an anomaly of the MIB variable called ipIR (representing the total number of datagrams received for all router interfaces). The defect period is indicated by the dotted vertical line. Note the existence of a drop in the average traffic level reflected in the ipIR variable right after the failure.
Table 6.3 Summary of results obtained through statistical techniques
Type of anomaly |
Mean time of prediction (min) |
Mean time of detection (min) |
Mean time between false alarms (min) |
Server failures |
26 |
30 |
455 |
Access problems |
26 |
23 |
260 |
Protocol error |
15 |
– |
– |
Uncontrollable process |
1 |
– |
235 |
Figure 6.14 MIB anomaly of type ipIR.
Predicting an anomaly implies two situations: (a) In the case of server failures or network access problems, prediction is possible by analyzing the MIB data. (b) In the case of unpredictable errors such as protocol implementation error, early detection is possible as compared to the existing mechanisms such as syslog and defect reports. Any anomaly declaration that does not correspond to a label is declared to be false. The quantities used in the study are shown in Figure 6.15 (after Thottan and Ji 2003). The persistence criterion implies that the alarms need to remain for consecutive lags for an anomaly to be declared.
In the experiments, some example of defects were detected, coming from two networks: an enterprise and a campus network. Both networks have been actively monitored and were designed for the needs of the user. The types of anomaly that were observed were: server errors, protocol implementation errors, and access problems. The majority of these are caused by an abnormal usage activity, with the exception of the protocol implementation errors. Thus, all these cases affect the MIB data characteristic.
Although high-speed traffic on Internet links has an asymptotic self-similarity, its correlation structure at small timescales allows for modeling it as a self-similar processes (as fBm). Based on simulations done on SFN Internet model, one can conclude that the Internet traffic has self-similar properties even when it is heavily aggregated. Experiments revealed the following results:
Figure 6.15 Quantities used in performance analysis.
1. Self-similarity is adaptable to the network traffic and it is not based on a heavy tail transfer distribution.
2. The region of scaling the traffic self-similarity is divided into two timescale regions: short-range dependencies (SRD), determined by the bandwidth, the size of the TCP window and the packet size, and a long-range dependence (LRD), determined by the statistics with a long tail characteristic.
3. In LRD, an increase in the bandwidth does not increase the performance.
4. There is a significant advantage in using fractal analysis methods for solving anomaly detection problems.
An accurate estimation of the Hurst parameter for MIB variables offer a valuable anomaly indicator obtained from the ipIR variable. So, by increasing the prediction capability, it is possible to reduce the time prediction time and to increase the network availability. Regarding the parallel processing methods, it is very important for the network model to be correctly federalized, because there is an optimum point between separating and balancing the federalization—the more separate the networks are, the more unbalanced they become.
The method of testing self-similarity between networks suggests the possibility of inferring traffic data in places where measurements are inaccessible. Considering the results of the discussed method, it has been found to have competitive performance for network traffic analysis, similar with those claimed by Breunig et al. (2000) when using LOF algorithm for computation of similarity between a pair of flows that contain a combination of categorical and numerical features. In comparison, our technique enables meaningful calculation without being computationally intensive, because it directly integrates data sets of previously detected incidents.
One can conclude that the anomaly detection algorithm is also effective in detecting behavior anomalies on a network, which typically translates into malicious activities such as DoS traffic, worms, policy violations, and inside abuse.
6.3.6 Recent trends in traffic self-similarity assessment for Cloud data modeling
Existing modern Cloud data storage, like Cloud data warehousing, do not use its potential capabilities functionality due mainly to the complexity in behavior of network traffic. The quality of service can be increased by building a converged multiservice network. Such a network ought to provide an unlimited range of services to provide flexibility for the management and creation of new services.
The current state of rapid development of high technology has led to the emergence and spread of ubiquitous networks, packet data, which gradually began to force the system switching network and at the same time increase the relevance of the traffic self-similarity. The fractal analysis can solve several problems, such as the calculation of the burst for a given flow, the development of algorithms and mechanisms providing quality of service in terms of self-similar traffic, and the determination of parameters and indicators of quality of information distribution.
6.3.6.1 Anomalies detection in Cloud
Deploying high-assurance services in the Cloud increases security concerns. To address these concerns, a range of security measures must be put in place. An important measure is the ability to detect when a Cloud infrastructure, and the services it hosts, is under attack via the network, for example, from a distributed denial of service (DDoS) attack. A number of approaches to network attack detection exist, based on the detection of anomalies in relation to normal network behavior. An essential characteristic of Cloud computing is the use of virtualization technology (Mell and Grance 2011).
Virtualization supports the ability to migrate services between different underlying physical infrastructure. In some cases, a service must be migrated between geographically and topologically distinct data centers (process known as wide-area migration). When a service is migrated within a data centre, the process is defined as local-area migration. In both cases, there are multiple approaches to ensure the network traffic that is destined for a migrated service is forwarded to the correct location.
Importantly for anomaly detection, service migration may result in observable effects in network traffic—this depends on where network traffic that is to be analyzed is collected in the data center topology, and the type of migration that is carried out. For example, if a local-area migration is executed, the change in traffic could be observable at top-of-rack (ToR) and aggregate switches, but not at the gateway to the data center. Since it is common practice to analyze traffic at the edge of a data center, local-area migration is opaque at this location. However, for wide-area migration, traffic destined to the migrated service will be forwarded to a different data centre, and will stop being received at the origin after the migration process has finished. This will result in potentially observable effects in traffic collected at the edge of a data center, and hamper anomaly detection techniques, so it is important to explore the effect that wide-area service migration has on anomaly detection techniques when network traffic that is used for analysis is collected at the data center edge.
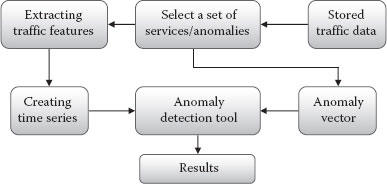
An anomaly detection tool (ADL) that analyses the traffic data for observing similar patterns, along with the injected anomalies and migration is described in Adamova et al. (2014). For the experiments, the authors used network flow data that was collected from the Swiss National Research Network—SWITCH—a medium-sized backbone network that provides Internet connectivity to several universities, research labs, and governmental institutions. The ADL has three inputs: an anomaly vector, which specifies at what times anomalies were injected, and two time-series files—a baseline file and an evaluation file. A time-series file contains entries that summarize each 5 min period of the traffic and is created by extracting the traffic features from a set of preselected services and anomalies. The traffic features are volume-based (the flow, packet, and byte count) and distribution-based (the Shannon entropy of source and destination IP and port distributions). These features are commonly used in flow-based anomaly detection. The baseline time series are created for training data; these are free from anomalies and migration. Conversely, evaluation time series contain anomalies and may contain migration, depending on the experiments we wish to conduct.
Figure 6.16 illustrates the tool chain used for testing the performance of the anomaly detection tool.
It can be seen that using this tool chain one can create evaluation scenarios that include a range of attack behavior, and service migration activity of different magnitudes. These scenarios can then be provided as input to different flow-based anomaly detection techniques. Among them, two are based on traffic self-similarity: spectral analysis, based on PCA, and clustering using expectation-maximization (EM). When using PCA, anomalies are detected based on the difference of the baseline and evaluation profiles. Detection of anomalous behavior based on clustering is realized by assigning data points that have similar features to cluster structures. Items that do not belong to a cluster, or are part of a cluster that is labeled as containing attacks, are considered anomalous.
Figure 6.16 The tool chain used in ADL testing.
6.3.6.2 Combining filtering and statistical methods for anomaly detection
Traffic anomalies such as attacks, flash crowds, large file transfers, and outages occur fairly frequently in the Internet today. Despite the recent growth in monitoring technology and in intrusion detection systems, correctly detecting anomalies in a timely fashion remains a challenging task.
A new approach for anomaly detection in large-scale networks is based on the analysis of traffic patterns using the traffic matrix (Soule et al. 2005). In the first step, a Kalman filter is used to filter out the “normal” traffic. This is done by comparing future predictions of the traffic matrix state to an inference of the actual traffic matrix that is made using more recent measurement data than those used for prediction. In the second step, the residual filtered process is then examined for anomalies. Since any flow will traverse multiple links along its path, it is intuitive that a flow carrying an anomaly will appear in multiple links, thus increasing the evidence to detect it.
A traffic matrix is a representation of the network-wide traffic demands. Each traffic matrix entry describes the average volume of traffic, in a given time interval, that originates at a given source node and is headed toward a particular destination node. Since a traffic matrix is a representation of traffic volume, the types of anomalies, which can be detected via analysis of the traffic matrix, are volume anomalies (Lakhina et al. 2004). Examples of events that create volume anomalies are denial-of-service attacks (DOS), flash crowds, and alpha events (e.g., nonmalicious large file transfers), as well as outages (e.g., coming from equipment failures).
Obtaining traffic matrices was originally viewed as a challenging task since it is believed that directly measuring them is extremely costly as it requires the deployment of monitoring infrastructure everywhere, the collection of fine granularity data at the flow level, and then the processing of large amounts of data. However, in the last few years many inference-based techniques have been developed that can estimate traffic matrices reasonably well given only per-link data such as SNMP data (that is widely available). Let note that usually these techniques focus on estimation and not prediction (Zhang et al. 2003).
A better approach for traffic matrix estimation seems to be that based on predictions of future values of the traffic matrix. A traffic matrix is a dynamic entity that continually evolves over time, thus estimates of a traffic matrix are usually provided for each time interval (most previous techniques focus on 5-min intervals), and the same interval for the prediction step of the traffic matrix will be considered in the following. The procedure consists in two stages. In the first stage, 5 minutes after the prediction is made, one obtain new link-level SNMP measurements, and then what the actual traffic matrix should be is estimated. In the second stage, one examines the difference between the last prediction (made without the most recent link-level measurements) and the estimation (made using the most recent measurements). If the estimates and predictor are good, then this difference should be close to zero. When the difference is necessary to analyze this residual further to determine whether or not an anomaly alert should be generated. In this connection, we recommend to use a generalized likelihood ratio test to identify the moment an anomaly starts, by identifying a change in mean rate of the residual signal. This method is a particular application of known statistical techniques to the anomaly detection domain and will be detailed in the following.
The traffic matrix (TM) that we discuss represents an interdomain view of traffic, and it expresses the total volume of traffic exchanged between pairs of backbone nodes, both edge and internal. Despite the massive growth of the Internet, its global structure is still heavily hierarchical, with a core made of a reduced number of large autonomous systems (ASs), among them some huge public Clouds (Casas et al. 2010). Our contribution regards first TM modeling and estimation, for which a new statistical model and a new estimation method to analyze the origin–destination (OD) flows of a large-scale TM from easily available link traffic measurements, and then regards the detection and localization of volume anomalies in the TM.
The traffic matrix estimation (TME) problem can be stated as follows: assuming a network with m OD flows and r links, Xt = [xt(1), …, xt(m)]T represents the TM organized as a vector, where xt(k), k = 1 … m stands for the volume of traffic of each OD flow at time t. The routing matrix indicates which links are traversed by each OD-flow. The element Rij = 1 if OD flow j takes link i and 0 otherwise. Finally, the vector ϒt = [yt(1), …, yt(r)]T, where yt(i), i = 1 … r represents the total aggregated volume of traffic from those OD-flows that traverse link at time t represents the SNMP measurements vector:
The TME problem consists in the estimation the value of Xt from R and ϒt.
Different methods have been proposed in the last few years to solve the TME problem. They can be classified into two groups. In the first group are included methods that rely exclusively upon SNMP measurements and routing information to estimate a TM, whereas in the second group are included mixed methods which additionally consider the availability of partial flow measurements used for calibration purposes and exploit temporal and spatial correlations among the multiple OD-flows of the TM to improve estimation results.
A mixed TME method named recursive traffic matrix estimation (RTME) will be discussed, which not only uses ϒt to estimate Xt, but also takes advantage of the TM temporal correlation, using a set of past SNMP measurements {ϒt−1, ϒt−2,…, ϒ1} to compute an estimate .
Let first consider the model that is assumed in Soule et al. (2005). In this model, authors consider the OD-flows of the TM as the hidden states of a dynamic system. A linear state space model is adopted to capture the temporal evolution of the TM, and the relation between the TM and the SNMP measurements given by Equation 6.4 is used as the observation process:
In Equation 6.5, matrix Xt characterizes the evolution of the TM. Matrix A is the transition matrix that captures the dynamic behavior of the system, and Wt is an uncorrelated zero-mean Gaussian white noise that accounts both for modeling errors and randomness in the traffic flows. Through the routing matrix the observed links traffic ϒt is related to the unobserved state Xt. The measurement noise Vt is also an uncorrelated zero-mean Gaussian white noise process. Given this model, it is possible to recursively derive the least mean-squares linear estimate of Xt given {ϒt−1, ϒt−2,…, ϒ1}, by using the standard Kalman filter (KF) method. The KF is an efficient recursive filter that estimates the state Xt of a linear dynamic system from a series of noisy measurements {Yt−1, ϒt−2, …, ϒ1}. It consists of two distinct phases, iteratively applied, and the update phase.
The prediction phase uses the state estimate from the previous time-step to produce an estimate of the state at the current time-step t + 1, usually known as the “predicted” state , according to the equation:
where Pt|t and Pt+1|t are the covariance matrices of the estimation error , and the prediction error , respectively.
In the update phase, the measurements vector at current time-step ϒt+1 is used to refine the prediction , computing a more accurate state estimate for current time-step t + 1,
where is the optimal Kalman gain, which minimizes the mean-square error: E(||et+1|t+1||2).
Combining Equations 6.6 and 6.7, the recursive Kalman filter-based estimation (RKFE) method recursively computes from
In his doctoral thesis (Hernandez 2010), Casas Hernandez reported some drawbacks of this model, especially in the case where A is a diagonal matrix, because the first equation in Equation 6.5 is valid only for centered data and false if data are not centered.
In order to have a correct state space model for the case of a diagonal state transition matrix A, he proposed a new model, considering the variations of Xt around its average value mX, that is, the system (6.5) becomes
This state space model is correct for centered TM variations, for both static and dynamic mean, but a problem still remains, because the Kalman filter does not converge to the real value of the traffic matrix if noncentered data ϒt is used in the filter. This problem can be easily solved considering a centered observation process , by adding a new deterministic state to the state model. Let us define a new state variable . In this case, Equation 6.9 becomes
where 0 is the null matrix of correct dimensions. This new model has twice the number of states, augmenting the computation time and complexity of the Kalman filter. However, it presents several advantages
• It is not necessary to center the observations ϒt.
• Matrix A can be chosen as a diagonal matrix, which corresponds to the case of modeling the centered OD-flows as autoregressive AR(1) processes. This is clearly much easier and more stable than calibrating a nondiagonal matrix such that (I − A)mX = 0.
• The Kalman filter estimates the mean value of the OD-flows mX, assumed constant in Equation 6.10.
• This model allows to impose a dynamic behavior to mX, improving the estimation properties of the filter.
Using model, Equation 6.10 with the Kalman filtering technique produces quite good estimation results. However, this model presents a major drawback: it assumes that the mean value of the OD-flows mX is constant in time. It can be improved by adopting a dynamic model for mX, in order to allow small variations of the OD-flows mean value:
where mX(t) represents the dynamic mean value of Xt and ζt is a zero-mean white Gaussian noise process with covariance matrix Qζ. In this context, Equation 6.10 becomes
Hernandez (2010) presented experimental results, which confirm that this model provides more accurate and more stable results.
One can conclude that considering a variable mean value mX(t) produces better results, both as regards accuracy and stability. In all evaluations, the stable evolution of the error shows that the underlying model remains valid during several days when considering such a transition matrix. Therefore, if the underlying model remains stable, it is not necessary to conduct periodical recalibrations, dramatically reducing measurement overheads.
Let us now explain how TM, as a tool for statistical analysis, can be used for optimal anomaly detection and localization and consequently for correctly managing the large and unexpected congestion problems caused by volume anomalies. Volume anomalies represent large and sudden variations in OD-flow traffic. These variations arise from unexpected events such as flash crowds, network equipment failures, network attacks, and external routing modifications among others. Besides being a major problem in itself, a volume anomaly may have a significant impact on the overall performance of the affected network. The focus is only on two main aspects of traffic monitoring: (1) the rapid and accurate detection of volume anomalies and (2) the localization of the origins of the detected anomalies.
The first issue corresponds to the anomaly detection field, with a procedure that consists of identifying patterns that deviate from normal traffic behavior. In order to detect abnormal behaviors, accurate and stable traffic models should be used to describe what constitutes an anomaly-free traffic behavior. This is indeed a critical step in the detection of anomalies, because a rough or unstable traffic model may completely spoil the correct detection performance and cause many false alarms. In this chapter, we focus on network-wide volume anomaly detection, analyzing network traffic at the TM level. In particular, we use SNMP measurements to detect volume anomalies in the OD-flows that comprise a TM. The TM is a volume representation of OD-flow traffic, and thus the types of anomalies that we can expect to detect from its analysis are volume anomalies. As each OD-flow typically spans multiple network links, a volume anomaly in one single OD-flow is simultaneously visible on several links. This multiple evidence can be exploited to localize the anomalous OD-flows.
The second addressed issue is the localization of the origins of a detected anomaly. The localization of an anomaly consists in inferring the exact location of the problem from a set of observed anomaly indications. This represents another critical task in network monitoring, given that a correct localization may represent the difference between a successful or a failed countermeasure. Traffic anomalies are exogenous unexpected events (flash crowds, external routing modifications, and external network attacks) that significantly modify the volume of one or multiple OD flows within the monitored network. For this reason, the localization of the anomaly consists in finding the OD-flows that suffer such a variation, referred to from now on as the anomalous OD-flows. The method that we discuss locates the anomalous OD-flows from SNMP measurements, taking advantage of the multiple evidence that these anomalous OD-flows leave through the traversed links.
The method proposed before for anomaly detection uses the recursive Kalman filtering technique, but instead of computing an estimated TM, it uses the Kalman filter to detect volume anomalies as large estimation errors. Since the Kalman filter method can properly track the evolution of the TM in the absence of anomalies, estimation errors should be small most of the time. A volume anomaly is then flagged when the estimation error exceeds certain detection threshold. The method analyses the estimation error , where represents the estimated TM using all the SNMP measurements until time t, namely {ϒt−1, ϒt−2, …, ϒ1}. The problem with this approach is that the real value of the TM, namely Xt, cannot be directly measured. Fortunately, the Kalman filter equations 6.6 and 6.7 allow to us compute the estimation error indirectly, using the inferred process ιt + 1. The inferred process represents the difference between the observed SNMP measurements vector ϒt + 1 and its predicted value, obtained from the predicted TM :
Under the Kalman filtering hypotheses, the innovation process is a zero-mean Gaussian process, whose covariance matrix Γt + 1 can be easily derived from Equations 6.5 through 6.7:
where Pt + 1|t is the covariance matrix of the prediction error and is the covariance matrix of the observation noise process Vt + 1.
Finally, we discuss the computational complexity for applying the Kalman-based method for the detection of anomalies (KDA). The KDA complexity corresponds to that of the standard Kalman filter recursive equations. The method must store in memory an m × m state transition diagonal matrix that models the evolution of the anomaly free traffic matrix, the routing matrix R, and the noise covariance matrices associated with the observation and the evolution processes, the last being also a diagonal matrix. This accounts for a total of 2(r2 + m) variables in memory. The recursive nature of the Kalman filter implies to keep in memory two additional matrices, the m × r Kalman gain matrix and the m × m prediction error covariance matrix. The use of the KDA for online anomaly detection implies to update the Kalman gain, the estimation covariance error, and the residual error. This involves matrix multiplications and inversions, and thus the associated cost is O(m3). One can see that the KDA method is largely more expensive than most of the algorithms for anomaly detection, which comes directly from using the Kalman filter with large matrices, but the detection and localization algorithms are more efficient than current methods, allowing a robust growth of the network monitoring field. Its utilization will confirm that the results of decision theory applied to the field of network monitoring will provide methods that rely on coarse-grained, easily available SNMP data to detect and locate network-wide volume anomalies in OD-flows traffic. This is a main advantage in order to develop light monitoring systems without the necessity of direct flow measurement technology, particularly in the advent of the forecast massive traffic to analyze in the near future.
6.4 Optimization of quality of services by monitoring Cloud traffic
6.4.1 Monitoring the dynamics of network traffic in Cloud
Traffic monitoring is a fundamental function block for Cloud services, so well contoured that can define a specific concept, Monitoring as a Services (MaaS). One of the key challenges for wide deployment of MaaS is to provide better balance among a set of critical quality and performance parameters, such as accuracy, cost, scalability, and customizability.
On a high level, a monitoring system (in any large-scale network) consists of n monitoring nodes and one central node, that is, data collector. Each monitoring node has a set of observable attributes Ai = {ai | i ∈ [1, m]. We consider an attribute as a continuously changing variable, which gives a new value as output in every unit time. For simplicity, we assume all attributes are of the same size a. Each node I has a capacity bi (considered as a resource constraint of node i) for receiving and transmitting monitoring data. Each message transmitted in the system is associated with a per-message overhead C, so the cost of transmitting a message with x values is C + ax. This cost model considers both per-message overhead and the cost of payload (Meng 2012). Figure 6.17 shows the structure of a monitoring planner, which organizes the monitoring nodes (according a given list of node–attribute pairs) into a cluster of monitoring trees where each node collects values for a set of attributes. The planner considers the aforementioned per-message overhead as well as the cost of attributes transmission to avoid overloading certain monitoring nodes in the generated monitoring topology. In addition, it also optimizes the monitoring topology to achieve maximum monitoring data delivery efficiency. Within a monitoring tree T, each node i periodically sends an update message to its parent. As application state monitoring requires collecting values of certain attributes from a set of nodes, such update messages include both values locally observed by node i and values sent by i’s children, for attributes monitored by T. Thus, the size of a message is proportional to the number of monitoring nodes in the subtree rooted at node i. This process continues upward in the tree until the message reaches the central data collector node.
Figure 6.17 Structure of monitoring planning. (After Meng, S. Monitoring as a Service in the Cloud, PhD thesis, Georgia Institute of Technology, 2012.)
From the users’ perspective, monitoring results should be as accurate as possible, suggesting that the underlying monitoring network should maximize the number of node–attribute pairs received at the central node. In addition, such a monitoring network should not cause the excessive use of resource at any node. Accordingly, we define the monitoring planning problem (MP) as follows:
For a set of node–attribute pairs ωq for monitoring Ω = {ω1,…, ωp} where ωq = (I, j), i ∈ N, j ∈ A, q ∈ [1, p], and resource constraint bi for each associated node, find a parent f(i j), ∀i, j, where j ∈ Ai such that node i forwards attribute j to node f(i,j) that maximizes the total number of node–attribute pairs received at the central node and the resource demand di of node i, satisfies di ≤ bi, ∀i ∈ N.
The monitoring planning problem raises two fundamental issues: (1) how to determine the number of monitoring trees and the set of attributes on each and (2) how to determine the topology for nodes in each monitoring tree under node level resource constraints. Therefore, constructing monitoring trees subject to resource constraints at nodes is a nontrivial problem and the choice of topology can significantly impact node resource usage.
A particular solution for the monitoring planning problem, namely a provisioning planning method for prediction-based multitier Cloud application is presented in the following.
Many Infrastructure-as-a-Service (IaaS) users are interested in deploying a multitier web application in the Cloud to meet a certain performance goal with minimum virtual instance renting cost. There are some difficulties in achieving this goal, first because the information with regarding the performance capacities and rental rates of different virtual server instances offered by the market is sometimes insufficient, second because the relation between cluster configuration (e.g., the number of member nodes, the distribution of workloads among member nodes) and performance (load balance, scalability, and fault tolerance) is application-dependent and must be carefully chosen for each particular application.
To meet a given performance goal, users often overprovision a multitier Web application by renting high-end virtual server instances and employing large clusters. Overprovisioning introduces high instance renting cost, which may make Cloud deployment a less desirable option compared with traditional deployment options. To avoid this drawback, one can propose a prediction-based provisioning planning method, which can find the most cost-effective provisioning plan for a given performance goal by searching the space of candidate plans with performance prediction. This procedure utilizes historical performance monitoring data (including self-similar patterns of time series) and data collected from a small set of automatic experiments to build a composite performance prediction model that takes as input different application workloads, types of virtual server instances, and cluster configuration, and gives the predicted performance as the output. This method was proposed by Meng, in his doctoral thesis (Meng 2012), and only the structure and the main advantages are presented here.
The proposed method avoids exhaustively performing experiments on all candidate deployments to build a performance prediction model by using a two-step performance prediction procedure. Instead of directly predicting the performance of an arbitrary deployment (target), it first predicts the performance on a known deployment (base) and then predicts the performance differences between the target deployment and the base deployment. It combines the predicted base performance and the predicted performance changes to obtain the performance on the target deployment. To achieve efficiency, the procedure predicts the performance change based on the deployment difference between the base deployment and the target deployment within each tier. By considering each tier independently, the method avoids the need for exploring all deployments that represent combinations of deployment changes cross-tiers.
The overall flow of the method has the following steps:
1. An user submits a request to deploy a multitier Cloud application in an Infrastructure-as-a-Service Cloud environment. The request also describes the expected range of workloads and expected performance.
2. The application is first deployed in an overprovisioned setting.
3. While the application running in the Cloud infrastructure, its workloads and performance are monitored and the corresponding monitoring data are stored.
4. The collected workloads and performance data are used to train a cross-tier performance model.
5. The application is replicated for a set of automatic experiments that deploy the application with different provisioning plans and measure the corresponding performance with different workloads. The goal of the automatic experiments is to learn the performance characteristics of different deployment options (e.g., virtual machine types and the number of virtual machines in a cluster).
6. The workloads and performance data collected in the automatic experiments are used to train a per-tier performance model.
7. The method explores all candidate provisioning plans and predicts the corresponding performance (for the user-specified workload range) using both the cross-tier and the per-tier performance model.
8. Among all candidate provisioning plans, the one that meets the user-specified performance goal and has the lowest virtual machine instance renting cost is selected as the suggested deployment for the user.
The implementation of the method implies three algorithms: (1) a prediction algorithm that takes workloads and deployment as input, and gives as output the predicted application performance; (2) an algorithm that captures the changes of perceived workloads across different deployments; and (3) a planning algorithm that explores all candidate provisioning plans and outputs the optimal one.
The idea of the prediction techniques to first predict the response time for a given workload on an overprovisioned deployment (referred to as the base deployment), and then modify the predicted response time considering changes introduced by the difference between the overprovisioned deployment and the actual targeted deployment. Correspondingly, two performance models are employed to accomplish this task: a cross-tier performance model, which captures the relation between workload and response time for the base deployment, and a per-tier performance model that captures the relation between deployment changes (to the base deployment) and corresponding changes of the response time.
A cross-tier model has the following form: Θc (w) → r, where w is the workload and r is the average response time of requests. The cross-tier model takes workload as input and outputs the response time on the base deployment. As a nonparametric technique, it does not specify a certain linear between w and r, but produces a nonlinear relation between w and r that best fits the observed performance data.
A per-tier model has the form: , where t denotes the object tier, v is the virtual machine type, c is the cluster size, and rd is the change of response time compared with the base deployment. The per-tier model is actually a set of models where each model is trained for a particular tier. Each per-tier model takes the workload, the type, and the number of virtual machine used at the object tier as input, and sends as output the changes of response time introduced by this tier over that of the base deployment.
To predict the response time for a target deployment and a given workload, first one uses the per-tier model to estimate the differences of response time introduced at each tier due to the deployment differences between the target deployment and the based deployment.
The work flow of the prediction process has the following steps:
Step 1. Select a candidate plan
Step 2. Predict the base performance using the cross-tier model
Step 3. Use the per-tier differential performance model to predict the performance change at the current tier
Step 4. Combining the predicted base performance and the predicted performance changes at all tiers
Step 5. Test if all tiers were explored. If no, return to step 3. If yes, go to step 6
Step 6. Test if all candidate plans were explored. If no, return to step 2. If yes, go to step 7
Step 7. Output the candidate plan that meets the performance goal with the lowest cost
The cross-tier model and the per-tier model are trained separately in two steps. The training of the cross-tier model requires only performance monitoring data on the base deployment. Specifically, the training data set should include the request rates spanning from light workloads to peak workloads and the corresponding average response time. Typically, the base deployment is overprovisioned to ensure the request response time meets the performance goal. The base deployment is also used as contrasts to generate training data for the per-tier model.
The per-tier models are trained in a tier-by-tier basis based on performance data collected on a series of automatic experiments. Specifically, first a duplicate of the based deployment is created and referred as the background deployment. For a per-tier model on tier t, we vary the configuration of tier t on the background deployment by changing the virtual machine type and the number of virtual machines, and leave the configuration of other tiers unchanged (same as the configuration in the base deployment). This leads to mn different background deployments where m is the total number of virtual machine types and n is the maximum number of virtual machines in tier t. For each resulting background deployment (with virtual machine type v(t) and virtual machine number c(t) in tier t), different levels of workloads are introduced (from light level to peak level just as those in the cross-tier model training dataset) to the deployment and the difference of response time rd between the background deployment and the base deployment for each level of workload w is recorded. The resulting data points (w, v(t), c(t), rd) are used to train the per-tier model .
6.4.1.2 Algorithm for capturing cross-deployment workload changes
The above prediction method makes an implicit assumption that the actual workloads perceived at each tier do not change across different deployments. However, the perceived workload at a tier may not be the same as the workload introduced to the application due to prioritization, rate limiting mechanisms implemented at different tiers. For instance, an application may drop certain low-priority requests when a certain tier becomes a performance bottleneck, which in turn causes the change of workload at other tiers. Even for applications without prioritization mechanisms, a bottleneck tier may limit the overall system throughput and introduce changes to the workload on other tiers.
Performance prediction without considering such workload changes may lead to significant prediction accuracy loss. As another example, a database tier of a Web application configured with a single low-end virtual machine can be a performance bottleneck when the Web application is fed with a peak workload wp. As a result, the actual workloads perceived at each tier w′ is often less than wp as a certain amount of requests are queued due to database overloading. Clearly, using the data (wp, v, c, rd) for training would introduce error to the per-tier model. To address this issue, a throughput model for a tier t is introduced with the following form: , where w′ is the actual workload perceived by all tiers. When making performance predictions, we apply the throughput model to obtain the predicted workload at each tier, and use the lowest predicted workload as the input of the per-tier model. Specifically, with the throughput model, the per-tier model has the following form: , where the input workload w is replaced with the actual workload predicted by the throughput model. Note that the data used for training the throughput model is (w, v, c, w′) and w′ can be easily measured by counting the number of responses within a time window.
6.4.1.3 Provisioning planning algorithm
In order to find the optimal provisioning plan for an application, it is enough only exploring all candidate provisioning plans and estimating the cost (such as virtual machine renting fee) and performance (obtained by the prediction method) of each candidate plan. The optimal plan is the one with the lowest cost and performance that satisfies the performance goal. In addition, the performance prediction model, once trained, can be repeated used for different planning tasks with different performance goals.
The entire procedure for prediction-based multitier Cloud applications has better performance than single-deployment performance modeling. Existing approaches based on single-deployment often apply queuing models and regression techniques, which use instrumentation at the middleware level to obtain critical model parameters such as per-request service time. This often limits the applicability of these approaches in the Cloud environment where middleware may not be a valid option for Cloud users. These approaches build models for a specific hardware/software deployment (fixed machines and cluster configurations) and focus on the impact of workload changes on performance.
The resulting models often produce poor prediction results on a different hardware/software deployment. On the contrary, the above discussed multitier deployment method not only considers workload changes, but also deployment changes. This cross-deployment feature is important for Cloud application provisioning due to the large number of available deployment options (e.g., different virtual machines types and different cluster configurations). Another distinct feature of this approach is that it utilizes a per-tier model to capture the performance difference introduced by deployment changes at each tier. This allows us to predict performance changes for any combination of deployment changes at different tiers without collecting performance data from the corresponding deployment, which saves tremendous amount of experiment time and cost.
The discussed method is only one step toward a truly scalable and customizable MaaS solution. Many other issues need to be investigated for MaaS to be a successful service for Cloud state management. Some of these important open problems in providing MaaS are mentioned as further research topics: monitoring heterogeneity (important for tracking anomalies and locating root causes, especially in distributed environments); flow-based monitoring (useful in distributed multitier applications, for tracking the execution of a request across nodes); smart Cloud management (by utilizing performance monitoring data to automate performance-driven Cloud application provisioning); exploring all automation opportunities (Cloud applications evolve over its lifetime in the form of reconfiguration, feature enrichment, automatic bug localization and fixing, new functionalities implementation, disturbance-free patching, scheduling, etc.); security and privacy (virtual machines running on the same host are vulnerable to performance attacks, so MaaS should also provide new monitoring functionalities to address such security and privacy issues in Cloud environments).
6.4.2 Coping with traffic uncertainty for load balancing in Cloud
Load balancer is a key element in resource provisioning for highly available Cloud solutions and its performance depends on the load offered by the traffic. These resources are expected to provide high performance, high availability, and secure and scalable solutions to support hosted applications. Many content-intensive applications show elastic load behavior that might scale up beyond the potential processing power of a single server. At the same time, service providers need a dynamic capacity of server resources to deploy as many servers as needed seamlessly and transparently. In Cloud, server load balancing structures multiple servers as a single virtual server.
Cloud balancing approach extends the architectural deployment model of traditional load balanced servers to be used in conjunction with global load balanced servers off the Cloud (Fayoumi 2011). This approach increases the application routing options, which are associated with decisions based on both technical and business goals of deploying load-balanced global application. Because many empirical studies have shown that heavy-tailed Pareto distribution, typical for self-similar traffic, provides a good fit for a number of important characteristics of communication networks and Web servers, it is justified to consider that the sizes of user requests and the service times of packets handled in Cloud satisfy heavy-tailed distributions.
The performance of the Internet itself depends, in large part, on the operation of the underlying routing protocols. Routing optimization becomes increasingly challenging due to the dynamic and uncertain nature of current traffic. The currently utilized routing protocols in IP networks compute routing configurations based on the network topology and some rough knowledge of traffic demands (e.g., worst-case traffic, average traffic, and long-term forecasts), without considering the current traffic load on routers and links or possible traffic misbehaviors and therefore without paying special attention to the traffic uncertainty issue. Large-scale networks are usually overprovisioned, and routing modifications due to traffic variations do not occur that often. Research studies in the field of routing optimization agree that today’s approach may no longer be suitable to manage current traffic patterns and more reliable routing mechanisms are necessary to perform and maintain networks functions in the case of component failures, in particular in the case of unexpected traffic events, represented by volume anomalies.
Given a single known traffic matrix (TM), routing optimization consists in computing a set of origin–destination paths and a traffic distribution among these paths in order to optimize some performance criterion, usually expressed by means of a cost function. Traditional routing optimization approaches have addressed the problem relying on either a small group of representative TMs or estimated TMs to compute optimal and reliable routing configurations. These techniques usually maintain a history of observed TMs in the past, and optimize routing for the representative traffic extracted from the observed TMs during a certain history window. In this sense, we shall refer to traditional algorithms as prediction-based Routing. The most well-known and traditionally applied prediction-based routing approach is to optimize routing for a worst-case traffic scenario, using for example the busy-hour TM seen in the history of traffic. This may not be a cost-effective solution, but operators have traditionally relied on the overprovisioning of their networks to support the associated performance loss. Better solutions are (1) to optimize routing for an estimated TM; this approach can provide more efficient solutions, but it highly depends on the goodness of the estimation technique and (2) to optimize routing for multiple TMs simultaneously, using for example a finite number of TMs from a previous day, from the same day of a previous week, etc. In both approaches, it must use different methods to find routing configurations with good, average, and worst-case performance over these TMs, knowing well that the worst case is only among the samples used in the optimization, and not among all possible TMs. All these traditional approaches tend to work reasonably well, but they certainly require a lot of management effort to ensure robustness against unexpected traffic variations.
Two new different approaches have emerged to cope with both the traffic increasing dynamism and uncertainty and the need for cost-effective solutions: robust routing (RR) (Mardani and Giannakis 2013) and dynamic load balancing (DLB) (Katiyar and Grover 2013). RR approach copes with traffic uncertainty in an offline preemptive fashion, computing a fixed routing configuration that is optimized for a large set of possible traffic demands. On the contrary, dynamic load balancing delivers traffic among multiple fixed paths in an online reactive fashion, adapting to traffic variations.
In robust routing, traffic uncertainty is taken into account directly within the routing optimization, computing a single routing configuration for all traffic demands within some uncertainty set where traffic is assumed to vary. This uncertainty set can be defined in different ways, depending on the available information: busy-hour traffic, largest values of links load previously seen, a set of previously observed traffic demands, etc. The criteria to search for this unique routing configuration is generally to minimize the maximum link utilization over all demands of the corresponding uncertainty set. Accurate estimation of origin-to-destination (OD) traffic flows provides valuable input for network management tasks. However, lack of flow-level observations as well as intentional and unintentional anomalies pose major challenges toward achieving this goal. Leveraging the low intrinsic-dimensionality of OD flows and the sparse nature of anomalies, a robust balancing algorithm allows to estimate the nominal and anomalous traffic components, using a small subset of (possibly anomalous) flow counts in addition to link counts and can exactly recover sufficiently low-dimensional nominal traffic and sparse enough anomalies when the traffic matrix is vague. The results offer valuable insights about the measurement types and network scenarios giving rise to accurate traffic estimation.
Dynamic load balancing copes with traffic uncertainty and variability by splitting traffic among multiple paths online. In this dynamic scheme, each origin–destination pair of nodes within the network is connected by several a priori configured paths, and the problem is simply how to distribute traffic among these paths in order to optimize a certain cost function. DLB is generally defined in terms of a link–cost function, where the portions of traffic are adjusted by each origin–destination pair of nodes in order to minimize the total network cost. For the sake of efficient resource utilization, load balancing system problem needs more attention in Cloud computing, due to its nature of on-demand computing. Cloud Computing considers shared pool of configurable computing resources, which requires proper resource distribution among the tasks; otherwise in some situations resources may be overutilized or underutilized. The dynamic load balancing approach, in which each agent plays very important role, which is a software entity and usually defined as an independent software program that runs on behalf of a network administrator, reduces the communication cost of servers, accelerates the rate of load balancing, which indirectly improves the throughput and response time of the Cloud.
A comparative analysis between robust load balancing algorithms and dynamic load balancing mechanisms leads to the following conclusions. The proponents who promote DLB mechanisms highlight among others the fact that it represents the most resource-efficient solution, adapting to current network load in an automated and decentralized fashion. On the other hand, those who advocate the use of RR claim that there is actually no need to implement supposedly complicated dynamic routing mechanisms, and that the incurred performance loss for using a single routing configuration is negligible when compared with the increase in complexity. An interesting characteristic of RR relies on the use of a single fixed routing configuration, avoiding possible instabilities due to routing modifications. In practice, network operators are reluctant to use dynamic mechanisms and prefer fixed routing configurations, as they claim they have a better pulse on what is going on in the network.
The first shortcoming that we identify in a RR paradigm is the associated cost efficiency. Using a single routing configuration for long time periods can be highly inefficient. The definition of the uncertainty set in RR defines a critical tradeoff between performance and robustness: larger sets allow to handle a broader group of traffic demands, but at the cost of routing inefficiency; conversely, tighter sets produce more efficient routing schemes, but subject to poor performance guarantees.
For the case of volume anomalies, a dynamic extension of RR known as reactive robust routing (RRR) can obviate this drawback. The RRR approach uses the sequential volume anomaly detection/localization method discussed in the previous section to rapidly detect and localize abrupt changes in traffic demands and decide routing modifications. A load balancing approach for RRR, in which traffic is balanced among fixed paths according to a centralized entity that controls the fractions of traffic sent on each path can solve the issue.
The second drawback that we identify in current RR is related to the objective function it intends to minimize. Optimization under uncertainty is generally more complex than classical optimization, which forces the use of simpler optimization criteria such as the maximum link utilization (MLU), that is, minimize the load of the most utilized link in the network. The MLU is by far the most popular traffic engineering objective function, but clearly it is not the most suitable network-wide optimization criterion; setting the focus too strictly on MLU often leads to worse distributions of traffic, adversely affecting the mean network load and thus the total network end-to-end delay, an important QoS indicator (Hernandez 2010). It is easy to see that the minimization of the MLU in a network topology with heterogeneous link capacities may lead to poor results as regards global network performance. To avoid this issue, it is possible to minimize the mean link utilization instead of the MLU. The mean link utilization provides a better image of network-wide performance, as it does not depend on the particular load or capacity of each single link in the network but on the average value. Despite this advantage, a direct minimization of the mean link utilization does not assure a bounded MLU, so for its utilization is necessary to limit MLU by a certain utilization threshold.
In DLB, traffic is split among fixed a priori established paths in order to optimize a certain cost function. For example, a link cost function based on measurements of the queuing delay can lead to better global performance from a QoS perspective. DLB presents a desirable property—that of keeping routing adapted to dynamic traffic. However, DLB algorithms present a tradeoff between adaptability and stability, which might be particularly difficult to address under significant and abrupt traffic changes.
As regards a comparative study between RR and DLB, the best method seems to be the dynamic approach, which consists of computing an optimal routing for each traffic demand i and evaluate its performance with the following traffic demand i + 1, on the basis of a given time series of traffic demands. This dynamic approach allows us to avoid two important shortcomings of DLB simulation:
1. Adaptation in DLB is iterative and never instantaneous.
2. In all DLB mechanisms, paths are set a priori and remain unchanged during operation, because each new routing optimization may change not only traffic portions but paths themselves.
Finally, a comprehensive analysis of different plausible solutions to the problem, including traditional prediction-based routing optimization, robust routing optimization, and dynamic load balancing led to the following conclusions:
1. Using a single routing configuration is not a cost-effective solution when traffic is relatively dynamic. Traditional prediction-based routing optimization may provide quite inefficient or even infeasible routing configurations when traffic is uncertain and difficult to forecast. Stable robust routing optimization offers performance guarantees against traffic uncertainty, but the associated tradeoff between robustness and routing efficiency may be particularly difficult to manage with a single routing configuration.
2. It is clear that some form of dynamism is necessary, either in the form of reactive robust routing and load balancing (RRLB) or dynamic load balancing (DLB). RRLB computes a nominal operation robust routing configuration, and provides an alternative robust routing configuration (using the same paths than in normal operation) for every possible single OD-flow anomalous situation. In order to detect these anomalous situations, link load measurements have to be gathered and processed by a centralized entity. On the other hand, DLB gathers the same measurements but also requires updating load balancing in a relatively small timescale. The added complexity is then to distribute these measurements to all ingress routers and to update the load balancing online.
3. The additional complexity involved in DLB is not justified when traffic variability is not very significant. In the case of large volume anomalies, DLB algorithms generally provide better results than RRLB after convergence, but they present an undesirable transient behavior. On the other hand, RRLB algorithms do not suffer from this problem, basically because the load balancing fractions are computed offline in a robust basis, taking advantage of the goodness of the robust routing paradigm.
4. The use of DLB algorithms becomes very appealing when volume anomalies are difficult to locate. The transient behavior that they present under large traffic modifications can be effectively controlled, or at least alleviated, by simple mechanisms, which results in a somewhat bigger maximum link utilization, but a generally much better global performance.
5. A local performance criterion such as the maximum link utilization does not represent a suitable objective function as regards global network performance and QoS provisioning. The maximum link utilization is widely used in current network optimization problems, thus this should be considered in enhanced future implementations.
6. By using a simple combination of performance indicators such as the maximum and the mean link utilization, one can obtain a robust routing configuration that definitely outperforms current implementations from a global end-to-end perspective, while achieving very similar results as regards worst-case link utilization, In fact, it means that objective optimization functions can be kept simple, and yet better network-wide performance can be attained.
7. A major drawback of RR is its inherent dependence on the definition of the uncertainty set: larger sets allow to handle a broader group of traffic demands, but at the cost of routing inefficiency; conversely, tighter sets produce more efficient routing schemes, but subject to poor performance guarantees.
6.4.3 Wide-area data analysis for detection changes in traffic patterns
Traffic monitoring is crucial to network operation to detect changes in traffic patterns often indicating signs of flash crowds, misconfigurations, DDoS attacks, etc. Flow-based traffic monitoring has been most widely used for traffic monitoring. A “flow” is defined by a unique 5-tuple (source and destination IP addresses, source and destination ports, and protocol), and used to identify a conversation between nodes. A challenge for flow-based traffic monitoring is how to extract significant flows in constantly changing traffic and produce a concise summary.
A simple and common way to extract significant flows is by observing traffic volume and/or packet counts, and reporting the top ranking flows. However, a significant event often consists of multiple flows, leading to the concentration of flows originating from one node. To this end, individual flows with common attributes in 5-tuple can be classified into an aggregated flow. A limitation is that it can identify only predefined flows and cannot detect unexpected or unknown flows.
To overcome the limitation of predefined rules, automatic flow aggregation has been proposed (Kato et al. 2012). The basic idea is to perform flow clustering on the fly in order to adapt aggregated flows to traffic changes. Although the idea is simple, it is not easy to search the best matching aggregated flow in a five-dimensional space, especially because traffic information is continuously generated so that the clustering process needs to keep up with incoming traffic information in near real time.
To solve the problem of flow aggregation requires analyzing data that is continuously created across wide-area networks, and in particular in Cloud computing. Queries on such data often have real-time requirements that need the latency between data generation and query response to be bounded. If the monitoring system is based on a single data center, where data streams are processed inside a high-bandwidth network, probably it will not perform well in the wide area, where limited bandwidth availability makes it impractical to backhaul all potentially useful data to a central location. Instead, a system for wide-area analytics must prioritize which data to transfer in the face of time-varying bandwidth constraints. Such a system must incorporate structured storage that facilitates aggregation, combining related data together into succinct summaries. On the other hand, it must also incorporate degradation that allows trading data size against fidelity.
For performing wide-area data analysis, a large amount of data is stored at edge locations that have adequate compute and storage capacity, but there is limited or unpredictable bandwidth available to access the data. Today’s analytics pipelines lack visibility into network conditions, and do not adapt dynamically if available bandwidth changes. As a result, the developer must specify in advance which data to store or collect based on pessimistic assumptions about available bandwidth, which ultimately leads to overprovisioning compared to average usage, and so capacity is not used efficiently.
The goal of a specialized wide-area data analysis system (WDAS) is to enable real-time analysis by reducing the volume of data being transferred. Storing and aggregating data where it is generated helps, but does not always reduce data volumes sufficiently. Thus, such system includes besides aggregation also degradations. Integrating aggregation and degradation into a streaming system require addressing three main challenges:
• Incorporating storage into the system while supporting real-time aggregation. Aggregation for queries with real-time requirements is particularly challenging in an environment where data sources have varying bandwidth capacities and may become disconnected.
• Dynamically adjusting data volumes to the available bandwidth using degradation mechanisms. Such adaptation must be performed on a timescale of seconds to keep latency low.
• Allowing users to formulate policies for collecting data that maximize data value and that can be implemented effectively by the system. The policy framework must be expressive enough to meet the data quality needs of diverse queries. In particular, it should support combining multiple aggregation and degradation mechanisms.
In meeting these challenges, the main function of WDAS is that it adjusts data quality to bound the latency of streaming queries in bandwidth-constrained environments. Previous and current systems, by ignoring bandwidth limitations, force users to make an unappealing choice: either be optimistic about available bandwidth and backhaul too much data, or they can be pessimistic about bandwidth and backhaul only limited data. By integrating durable storage into the dataflow and supporting dynamic adjustments to data quality, WDAS allows a user to focus on two different tradeoffs: deciding which query results are needed in real time and which inaccuracies are acceptable to maintain real-time performance.
For WDAS design, one must take into account several essential rules: (i) the system integrates data storage at the edge to allow users to collect data that may be useful for future analysis without necessarily transferring it to a central location; (ii) users can define ad-hoc queries as well as standing queries, which can be used to create centralized data structures to optimize the performance of common queries; and (iii) a standing query has a hard real-time requirement: if the query cannot handle the incoming data rate, then queues and queuing delays will grow, which means that the system must keep latency bounded.
Since WDAS aims to provide low-latency results on standing queries, the designer can use the basic computation model of traditional stream-processing systems. A worker process runs on each participating compute node. A query is implemented by a set of linked dataflow operators that operate on streams of tuples. Each operator is placed on a particular host and performs some transformations on the data. The system routes tuples between operators, whether on the same host or connected by the network.
Integrating structured storage into a streaming operator graph solves several problems. Ideally, WDAS should handle several different forms of aggregation in a unified way. Windowed aggregation combines data residing on the same node across time. Tree aggregation combines data residing on different nodes for the same period. This can be applied recursively: data can be grouped within a data center or point of presence, and then data from multiple locations is combined at a central point. Both these forms of aggregation can be handled by inserting data into structured storage and then extracting it by appropriate queries. A solution for structured storage is a cube interface similar with that of OLAP data warehouses (Rabkin et al. 2014). However, cubes in data warehouses typically involve heavy precomputation, incurring high ingest times to support fast data. In contrast, for WDAS one can uses cubes for edge storage and aggregation and for that only maintain a primary-key index. This reduces ingest overhead and allows cubes to be effectively used inside a streaming computation. Integrating storage with distributed streaming requires new interfaces and abstractions. Cubes can have multiple sources inserting data and multiple unrelated queries reading results. In a single-node or data center system, it is clear when all the data has arrived, but in a wide-area system, synchronization is costly, particularly if nodes are temporarily unavailable.
A good solution seems to be the practical methodology for recursive multidimensional flow aggregation proposed in Kato et al. (2012). The key insight is that, once aggregated flow records are created, they can be efficiently reaggregated with coarser temporal and spatial granularity. The advantage is that an operator can monitor only coarse-grained aggregated flows to identify anomalies and, if necessary, he can look into more fine-grained aggregated flows by changing aggregation granularity. The algorithm ensures a two-stage flow aggregation: the primary aggregation stage focuses on efficiency while the secondary aggregation stage focuses on flexibility.
The primary aggregation stage reads raw traffic records and produces rudimentary aggregated flow records on the fly. The secondary aggregation stage reads the output of the primary aggregation stage, and produces concise summaries for operators. In both aggregation stages, from the 5-tuple of attributes, source and destination IP addresses are used as main attributes, and protocol and ports as subattributes, following the operational practices. Although it is possible to treat each attribute equally, it is more expensive and the use case is fairly limited. To identify significant flows, both traffic volume and packet counts are used, in order to detect both volume-based and packet count-based anomalous flows.
In order to maximize data quality, it is desirable to apply data reduction only when necessary to conserve bandwidth. Keeping this in mind, WDAS includes specialized tunable degradation operators. The system automatically adjusts these operators to match available bandwidth, thus minimizing the impact on data quality. Because the system dynamically changes degradation levels, it needs a way to indicate the fidelity of the data it is sending downstream. Therefore, the system has the ability to send metadata messages both upstream and downstream, which are ordered with respect to data messages. This mechanism is useful to signal congestion and also to implement multiround protocols within the operator graph.
Degradation operators can be either standard operators that operate on a tuple-by-tuple basis, or cube subscribers that produce tuples by querying cubes. A degradation operator is associated with a set of degradation levels, which defines its behavior on data streams. Even with partial aggregation at sources, some queries will require more bandwidth than is available. To keep latency low, WDAS allows queries to specify a graceful degradation plan that trades a little data quality for reduced bandwidth. Similarly, quantitative data can be degraded by increasing the coarseness of the aggregation or using sampling. Since degradations impose an accuracy penalty, they should only be used to the extent necessary. This is achieved by using explicit feedback control, through which WDAS can detect congestion before queues fill up, enabling it to respond in a timely manner. Moreover, this feedback reflects the degree of congestion, allowing to tune the degradation to the right level. This avoids expensive synchronization over the wide area, but it also means that sources may send data at different degradation levels, based on their bandwidth conditions at the time.
The best degradation for a given application depends not only on the statistics of the data, but also on the set of queries that may be applied to the data. As a result, the system cannot choose the best degradation without knowing this intended use. Some guidelines to use degradations in different circumstances are as follows:
• For data with synopses that can be degraded, degrading the synopsis will have predictable bandwidth savings and predictable increases in error terms.
• If the dimension values for the data have a natural hierarchy, then aggregation can effectively reduce the data volume for many distributions.
• For long-tailed distributions, a filter can remove the large, but irrelevant tail.
• A global value threshold gives exact answers for every item whose total value is above a threshold; a local threshold will have worse error bounds, but can do well in practice in many cases.
• Consistent samples help to analyze relationships between multiple aggregates.
• Users can specify an initial degradation with good error bounds, and a fall-back degradation to constrain bandwidth regardless.
• The operators have flexibility in how they estimate the bandwidth savings; levels can be (i) dynamically changed by the operator; (ii) statically defined by the implementation; and (iii) configurable at runtime.
Anyway, it is obvious that no single degradation technique is always best; a combination of techniques can perform better than any individual technique. By combining multiple techniques in a modular and reusable way using adaptive policies, it is possible to create a powerful framework for streaming wide-area analysis.
6.4.4 Monitoring Cloud services using NetFlow standard
The advantages of Cloud services, such as reduced costs, easy provisioning, and high scalability, led to heightened interest from organizations in migrating services (especially file storage and e-mail) to Cloud providers. However, such migration also has its drawbacks. Cloud services have been repeatedly involved major failures, including data center outages, loss of connectivity, and performance degradation. The goal of this section is to investigate to what extent the performance of Cloud services can be monitored using standard monitoring programs.
In the early 2000s, the IPFIX Working Group was formed in the IETF, to standardize protocols to export IP flows. While originally targeting some key applications (Zseby et al. 2009), such as accounting and traffic profiling, flow data have proven to be useful for several network management activities. A reference architecture for measuring flows is presented in Sadasivan et al. (2009). Three main components are part of this architecture
1. IPFIX devices that measure flows and export the corresponding records. IPFIX devices include at least one exporting process and, normally, observation points and metering processes. Metering processes receive packets from observation points and maintain flow statistics. Exporting processes encapsulate flow records and control information (e.g., templates) in IPFIX messages, and send the IPFIX messages to flow collectors.
2. Collectors that receive flow records and control information from IPFIX devices and take actions to store or further process the flows.
3. Applications that consume and analyze flows.
Because flow records are the primary source of information in applications analysis and since any flow-based application requires flow data of good quality to perform its tasks satisfactorily, it is essential to understand how flows are measured in practice.
Figure 6.18 illustrates the typical tasks of an IPFIX device (Sadasivan et al. 2009). First, packets are captured in an observation point and timestamped by the metering process. Then, the metering process can apply functions to sample or filter packets. Filters select packets deterministically based on a function applied to packet contents. Samplers, in contrast, combine such functions with techniques to randomly select packets. Sampling and filtering play a fundamental role in flow monitoring because of the continuous increase in network speeds.
By reducing the amount of packets to be examined by metering processes, sampling and filtering make flow monitoring feasible under higher network speeds. On the other hand, these techniques might imply loss of information, which restrict the usage of flow data substantially. Packets that pass the sampling and filtering stages update entries in the flow cache, according to predefined templates. Flow records are held in the cache until they are considered expired, following the reasons described next. Expired records are made available by the metering process to exporting processes, where they are combined into IPFIX messages and sent out to flow collectors.
Figure 6.18 Functions performed by a network monitoring device. (After Sadasivan, G. et al., Architecture for IP flow information export, RFC 5470, 2009.)
IPFIX devices are also called flow exporters—for example, when only exporting processes are present, and their use in flow monitoring is defined as a flow export technologies. Cisco NetFlow is one of the widely deployed flow export technologies, compatible with the standardization effort IPFIX.
Network traffic monitoring standards such as sFlow (Phaal et al. 2001) and NetFlow/IPFIX (Claise 2004; Leinen 2004) have been conceived at the beginning of the last decade. Both protocols have been designed for being embedded into physical network devices such as routers and switches where the network traffic is flowing. In order to keep up with the increasing network speeds, sFlow natively implements packet sampling in order to reduce the load on the monitoring probe. While both flow and packet sampling is supported in NetFlow/IPFIX, network administrators try to avoid these mechanisms in order to have accurate traffic measurement. These principles do not entirely apply in Cloud computing. Physical devices cannot monitor virtualized environments because inter-VM traffic is not visible to the physical network interface. However, virtualization software developers have created virtual network switches with the ability to mirror network traffic from virtual environments into physical Ethernet ports where monitoring probes can be attached. Recently, virtual switches such as VMware vSphere Distributed Switch or Open vSwitch natively support NetFlow/sFlow for inter-VM communications (Deri et al. 2014), thus facilitating the monitoring of virtual environments. Network managers need traffic monitoring tools that are able to spot bottlenecks and security issues while providing accurate information for troubleshooting the cause. This means that while NetFlow/sFlow can prove a quantitative analysis in terms of traffic volume and TCP/UDP ports being used, they are unable to report the cause of the problems.
Because modern services use dynamic TCP/UDP ports, the network administrator needs to know what ports map to what application. The result is that traditional device-based traffic monitoring devices need to move toward software-based monitoring probes that increase network visibility at the user and application level. As this activity cannot be performed at network level (i.e., by observing traffic at a monitoring point that sees all traffic), software probes are installed on the physical/virtual servers where services are provided. This enables probes to observe the system internals and collect information (e.g., what user/process is responsible for a specific network connection) that would be otherwise difficult to analyze outside the system’s context just by looking at packets.
Network administrators can then view virtual and Cloud environments in real time. The flow-based monitoring paradigm is by nature unable to produce real-time information. Flows statistics such as throughput can be computed in flow collectors only for the duration of the flow. This means that using the flow paradigm, network administrators cannot have a real-time traffic view due to the latency intrinsic to this monitoring architecture and also because flows can only report average values.
Flow measurements have been successfully employed in a variety of applications that require scalable ways to collect data in high-speed networks, such as to detect network intruders, to perform traffic engineering, and to discover connectivity problems in production networks. NetFlow, in particular, is a widely deployed technology for measuring flows, often available at enterprise and campus networks. Therefore, NetFlow seems to be an alternative to provide immediate and scalable means for customers to monitor their services in the Cloud, without the burdens of instrumenting end-user devices and, more importantly, without any interference from Cloud providers. However, although the use of NetFlow to monitor Cloud services is intuitively appealing, NetFlow measurements are known to be unrelated to high-level metrics usually employed to report the performance of applications, such as availability and response time.
In the rest of this section, the use of NetFlow to monitor Cloud services will be analyzed, on the basis of a method proposed by Drago (2013) that (i) normalizes NetFlow data exported under different settings and (ii) calculates a simple performance metric to indicate the availability of Cloud services.
Method description. Figure 6.19 illustrates a deployment scenario of the method, assuming that a set of routers is exporting flow records while handling the traffic from a group of end users, with aim of using these data to monitor Cloud services. In this example, users in an enterprise network interact with two Cloud services (i.e., Service A and B in the figure). The link between the enterprise network and the Internet is monitored by a flow exporter. The exporter processes the traffic mirrored from the network and forwards flow records to collectors, from where the records are accessible to analysis applications.
Figure 6.19 Deployment scenario of flow monitoring method. (After Drago, I. Understanding and Monitoring Cloud Services, PhD thesis, Centre for Telematics and Information Technology, 2013.)
This example makes clear that a single enterprise does not have access to all traffic related to the services, but it can still observe a significant fraction, generated by its own users. Users trying to contact unavailable services will generate traffic with particular characteristics that can be exploited to reveal the status of the Cloud services. Considering such traffic as unhealthy, it is a need for a method to estimate a health index, defined as the fraction of healthy traffic to a service in a given time interval. Applying this procedure means to receive batches of NetFlow records from flow collectors and compute the health index for selected services by performing the following steps:
Step 1. The traffic related to the services is filtered using either predefined lists of server IP addresses or names of IP owners.
Step 2. The data are normalized to remove the effects of parameter settings of flow exporters (for example, the effects of packet sampling or flow expiration policies). This is achieved by estimating the total number of TCP connections n and the number of healthy TCP connections nh for each service. A TCP connection is considered healthy if it could exchange transport layer payload—that is, if the connection has a complete TCP handshake. Next, before reaching the step 3, the procedure follows two routes, depending on the flow records nature: nonsampled or packet-sampled. These intermediary sub-steps will be described later in detail.
Step 3. The health index hi = nh/n, determined as the fraction of healthy TCP connections in the network, is returned for each service. The health index is correlated to the service availability as follows. When a service is fully available, client TCP connections are expected to be normally established, making the index to approach 1; when the service becomes partially or fully unavailable, failed client connection attempts decrease the index. An upper bound for determining the actual service status is necessary. The health index decreases only if a service is unavailable. A high index, however, does not guarantee that a service is operating, since the method does not take application layer errors into account. Now let see how the method handles nonsampled and packet-sampled flows.
When packet sampling is disabled, all packets are taken into account, and flow records provide a summary of the observed TCP flags. Since different TCP connections are not reported in a single flow record, it is possible to monitor the status of TCP connections by identifying the flow records that belong to each connection. Hence, the normalization of nonsampled flow data is executed in two steps: (1) records that report information about the same TCP connection are aggregated and (2) the information about TCP flags are evaluated to determine n and nh.
Aggregating method means that flow records with identical keys—that is, sharing the same IP addresses and port numbers—are merged until the original TCP connection is considered complete. Since NetFlow is usually unidirectional, flow records from both traffic directions are also aggregated. The critical step for this heuristic is to determine when a TCP connection is complete, such that later records sharing the same key start a new connection. Normally, a TCP connection is complete if an idle timeout has elapsed or if records with TCP FIN flag set have been observed from both end-points and a short timeout has elapsed. Therefore, the new records sharing the same key are part of a new TCP connection, even if the time interval between the TCP connections is shorter than the previous timeout parameter.
Finally, the evaluation of the aggregated records is performed. The total number of TCP connections n as well as the number of healthy connections nh can be trivially counted from the aggregated flow records. More precisely, all TCP connections are counted as healthy, except for failed attempts (when clients send a TCP SYN packet and do not obtain any reply) or for rejected TCP connections (when servers reset connections without completing the handshake).
6.4.4.2 Packet-sampled flow data
The flow data exported under sampling are normalized as follows. First, it estimates the total number of TCP connections and the number of healthy TCP connections directly from the raw packet-sampled flow records. Owing to sampling, those numbers are realizations of random variables. In order to compare the quantities in a meaningful way, confidence intervals are determined and taken into account: if the intervals overlap, or if there is not enough evidence of unhealthy TCP connections in the network. Therefore, we make and the index is reported to be 1; otherwise, the health index is calculated using and .
For estimating the original number of TCP connections from raw packet-sampled flows, we recommend the method described in Drago (2013). If packets are sampled independently with probability p = 1/N, then , where ks is the number of observed records with SYN flag set, is proven to be an unbiased estimator for the number f of TCP flows, under the assumption of one single SYN packet per TCP connection. In a similar reasoning, mode is estimated the number of healthy TCP connections. Because healthy connections must have a complete TCP handshake, we assume that these connections have exactly one SYN packet from both originators and responders, while unhealthy TCP connections have exactly one SYN packet from originators, but none from responders.
Let korig and kresp be the number of observed flow records with SYN flag set from originators and responders, respectively, in a time interval. Then, and are unbiased estimations of the total number of TCP connections n and of the number of healthy TCP connections nh in that time interval.
The expected values of are equal if a service is available. However, a system can only be considered unhealthy if the difference between is statistically significant. We evaluate the difference between by estimating the probability distributions of n and nh and calculating the confidence intervals. If confidence intervals for a given level of significance show a high probability that nh < n, then are returned. Otherwise, we make and the service is considered healthy.
The method assumes that n and nh are constant over r consecutive time intervals, which is a reasonable approximation for highly loaded services in short time intervals.
There are some conclusions to formulate in order to understand not only the advantages, but the limitations of using NetFlow to monitor Cloud services and so provide appropriate guidelines for using this tool.
1. Most procedures require to filter traffic based on IP addresses and IP owners. These methods perform well only if flow records are filtered properly, otherwise they are ineffective.
2. All methods must identify flows generated by an application. In particular, the limited information normally exported by NetFlow makes it hard to isolate the traffic of Cloud services in flow datasets, but this limitation can be overcomed by augmenting flow measurements with other information that can be passively observed in the network as well.
3. One cannot ignore the application layer semantics. Even if a method is informative to reveal the most severe availability problems, in which clients cannot establish communication with providers, it is very common that servers are still able to handle part of users’ requests when suffering performance degradation. In such situations, a mix of healthy traffic, unhealthy traffic at the transport layer, and unhealthy traffic at the application layer can be observed in the network.
4. Application-specific knowledge has to be taken into account as well, if the precise identification of all availability problems is necessary. Such advanced monitoring requires flow exporters that can measure and export customized information per application.
5. A new idea can be taken into account regarding how to monitor problems in Cloud services. Most traditional methods rely on active measurements to analyze the performance of services or to benchmark Cloud providers. Other methods focus on measuring the performance of the infrastructure providing the services. The new approach differs from those in several aspects, because it do not focus on a specific service, but instead propose a generic method applicable to a variety of Cloud services. It is a passive approach to Cloud monitoring because the active alternatives lack the ability to capture the impact of problems on actual end users. On the other hand, in contrast to active methods, a passive method can only identify problems in a Cloud service if end users are interacting with it. Consequently the use of NetFlow for measuring the availability of a remote service is central to this method.
6. Usually incoming/outgoing flow records are matched and alerts are triggered when the number of records without a match increases. We consider that is better to apply the differentiation when dealing with nonsampled data or with sampled data. When dealing with nonsampled data, we rely on a technique for aggregating flow records, using the normalization of the flow data, thus removing the effects of timeout parameters. For postprocessing packet-sampled flows, the recommendation is to estimate several properties of the original data stream, such as the flow length distribution, using packet-sampled flow records only.
7. There are limiting factors for the use of NetFlow to monitor Cloud services. These factors include the difficulties for filtering traffic and the need for more information in flow records.
As final conclusion, let note that the method discussed in this chapter for determining the health of a remote service solely from flow measurements is by no means a comprehensive solution to all monitoring needs of Cloud customers. However, by focusing on serious performance problems and by relying on flows exported by a widely deployed technology, it delivers an essential and immediate first layer of monitoring to Cloud customers, while being applicable to a wide range of services and scalable to high-speed networks.
6.4.5 Implementing Cloud services in the automation domain
The latest challenge in the industrial sector is oriented to developing Cloud architectures and services that will provide not only increased storage space and increased reliability but also high computing power and accessibility to advanced process control applications that can be used as services for modeling and optimization of industrial plants. The main challenges identified in this domain come from the variable access times and possible accessibility problems that arise from the virtualization of the Cloud components.
When integrating a process control application in a Cloud environment, we need to identify a generic, flexible solution adaptable to different application domains, programming environments, and hardware equipment. This section presents as original solution a model for integrating an advanced process control library in a Cloud-based environment.
Cloud computing is a technology that provides computational resources as a commodity. It enables seamless provisioning of both the computing infrastructure and software platforms. It is also an efficient way to manage complex deployments, as most of the installation and configuration task are automatically handled by the Cloud provider.
There are currently three main models for providing Cloud services: Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS). IaaS Cloud solutions provide basic building blocks of the infrastructure—computing, storage, and network as a service. The PaaS Cloud solutions provide a high-level stack of services that enables application-specific environments. SaaS applications are hosted on the physical or virtual infrastructure and the computing platform is managed by the Cloud provider. They can run on the PaaS and IaaS layers as this is transparent to the customer who is only able to access and use the SaaS application.
The proposed system represents a Cloud-based support platform for process control engineers in the use and integration of advanced algorithms and control strategies. The architecture of the proposed system is illustrated in Figure 6.20. The system functionality is organized in relation to three levels: the user level, the Cloud level, and the process level.
Figure 6.20 System architecture.
The library is organized as a modular structure, one for each service provided, with a clear decomposition of the functionality encapsulated at each component. The intermodule communication uses SOA services, while the communication with the process level uses OPC-UA as middleware for an easier integration with existing hardware equipment and SCADA applications.
Based on the authentication credentials, user’s rights vary from requesting the download or execution of available strategies, to access to Cloud historian, to use the Cloud collaborative platform to upload new strategies or update the existing ones.
Four types of services are defined in this structure: (1) Model as a Service (MaaS): the user can request a model of the process based on specific data retrieved from the plant; (2) Data as a Service (DaaS): the platform can be used as a process data historian, providing increased reliability, security, and a large storage space; (3) Control as a Service (CaaS): the platform enables the remote execution of any algorithm or strategy available in the library, providing benefits in implementing advanced control algorithms; and (4) Algorithm as a Service (AaaS): the algorithms and strategies available in the library can be downloaded as standardized function blocks.
The strategies database stores all the available functions, algorithms, and strategies as XML files.
Their representation is based on the IEC 61499 standard. The execution module provides the functionality of a superior control level. For each CaaS service requested for a specific algorithm the execution module implements a virtual controller responsible with the execution that sends the results to a device in the controlled plant. A strategy can call the execution of another strategy.
Also, because of the use of the IEC 61499 standard, the execution can be distributed between several nodes of the Cloud architecture. A strategy execution takes place in real time but the virtualization of the Cloud environment can influence the execution time. For that reason, this functionality can be used only in noncritical control applications. The process data storage module can be accessed as a DaaS service by a library user and is also accessed by adjacent modules in case of modeling algorithms execution or process model optimization.
The modeling and optimization module runs complex computing applications for offline process model identification and performance optimization.
The process level implements standard automation control systems: sensor and actuator elements, PLC, DCS, or RTU controllers and SCADA applications. The interaction with the process is done using secured channels. This level is responsible for local control of an industrial plant and for implementing intelligent communication interfaces for the integration with the Cloud level (Ionescu 2014).
In order to take advantage of the main benefits that are provided by the Cloud infrastructures, such as the dynamic provisioning of computing resources, scalability, on-demand access, reliability, and elasticity, it is proposed to perform the deployment of the virtual controllers in a PaaS infrastructure.
The remote execution module can be used for real-time model identification or for offline model improvement. Considering the process parameters as input variables in the model execution, we compute the model response and compare it to the real process information to see if the accuracy indicators are met. Figure 6.21 illustrates the implementation details of the remote execution module.
When a user accesses the Web library web interface for executing an algorithm, the web server receives his request, parses the information regarding the execution details (sequence ID, remote device communication parameters, algorithm execution), and creates a new instance of the execution container.
Each user is assigned a different container instance. A container contains one application manager module and a number of algorithm execution modules associated to all the execution started by a specific user. If the processor effort on a container is overloaded, new instances can be further deployed. A container is terminated when all sequences finished their execution. A service orchestration module is responsible for container creation, termination, and management based on a user-IP table that keeps track of running containers and their associated users.
The communication with the process level is done using OPC-UA for easier integration with existing SCADA applications. The architecture for a library of process control strategies managed in a Cloud environment offer an extension of the current research in the automation domain by moving advanced control applications to a Cloud environment for increased processing power and storage space.
6.5 Developing and validating strategies for traffic monitoring on RLS models
In last part of this work, the behavior of the most used planning algorithms is analyzed in terms of guaranteeing the performance and the fairness between the traffic flows. As it was already shown in previous chapters, resource planning is an important element in QoS assurance. Both differentiated (DS) and integrated (IS) services use to some extent various planning algorithms. Features particular to each type of service impose using different algorithms. For example, in the case of IS, fair planning algorithms (FQ, DRR) are preferred and in the case of SD, while in the case of DS, active queue algorithms are chosen.
Figure 6.21 Architecture of the strategy execution module.
For simulating, the open source network simulator ns was used, running on a Linux distribution (openSuse). ns is one of the most popular network simulators through the academic environment because of its extendibility (open source model) and its vast available documentation. It can be used for simulating routing and multicast protocols, both in fixed and in mobile networks. The development of ns started in 1989 as a variant to the network simulator REAL. Until 1995, ns received the support of DARPA, VINT project of LBL, Xerox PARC, UCB, and USC/ISI.
The chosen topology is that of a star (Figure 6.22), in which the nodes 0 through 4 are directly connected to the output node 5 that provides a link with the outside through node 6. This topology is typical for a small size network that shares one Internet gateway. The problem of resource planning manifests at node 5 that must receive all the network-generated traffic and send it to node 6. As it can be seen, the speed of the internal links is much higher than for the outer link, resulting in it being easily saturated.
In order to comparatively test the algorithm performance, four traffic sources have been used that should accomplish a high enough load. Two of them generated constant traffic (CBR) over UDP and the other two acted in bursts over TCP. The UDP traffic simulates a streaming application (voice, video) that is sensitive to delays and delay variations. Every one of the UDP traffic sources generate fixed size packets at a rate of 200 kbit/s. Considering the external link to be of 1 Mbit/s and the presence of four traffic sources, the fair share of each flux is of 250 kbit/s. So, the traffic generated by the two sources is lower than their share and, in the case of a correct bandwidth planning, should not experience delays or transfer rate variations.
Figure 6.22 Network topology.
The TCP traffic sources simulate Web-based traffic, which is defined by bursts of data and a rather constant transfer rate. For generating this traffic, a Pareto distribution source was used. Each of the TCP sources is configured to send packets on the output link at a mean transfer rate of 200 kb/s. Because of the traffic characteristics, sometimes the transfer rate can reach higher values, especially when sending burst packets.
For simulation, the following script was used to create the network and the traffic sources, plan the network traffic and monitor the queue of node 5 using various algorithms. For each algorithm, the changes were minor, replacing only the queue type from the initial declaration between nodes 5 and 6 and the size of the queue so that it is the same for each algorithm.
These scripts were run using ns, and the results were processed to obtain information related to delay, average transfer rate and delay variation for each data flow.
#Create a new simulator object
set ns [new Simulator]
#Define a different colour for each flow (for NAM)
$ns color 1 Blue
$ns color 2 Red
$ns color 3 Green
#Open the log file for NAM
set nf [open out.nam w]
$ns namtrace-all $nf
#Open log file
set tf [open out.tr w]
$ns trace-all $tf
set f0 [open cbr1.tr w]
set f1 [open tcp1.tr w]
set f2 [open tcp2.tr w]
set f3 [open cbr2.tr w]
#Define exit procedure
proc finish {} {
global ns nf tf
$ns flush-trace
close $nf
close $tf
exec nam out.nam &
exec xgraph cbr1.tr tcp1.tr tcp2.tr cbr2.tr &
exit 0
}
#Define the recording procedure for the average data rates
proc record {} {
global null2 sink1 sink0 null1 f0 f1 f2 f3
set ns [Simulator instance]
set time 0.5
set bw0 [$null2 set bytes_]
set bw1 [$sink1 set bytes_]
set bw2 [$sink0 set bytes_]
set bw3 [$null1 set bytes_]
set now [$ns now]
puts $f0 “$now [expr $bw0/$time*8/1000000]”
puts $f1 “$now [expr $bw1/$time*8/1000000]”
puts $f2 “$now [expr $bw2/$time*8/1000000]”
puts $f3 “$now [expr $bw3/$time*8/1000000]”
$null2 set bytes_0
$sink1 set bytes_0
$sink0 set bytes_0
$null1 set bytes_0
$ns at [expr $now + $time] “record”
}
#Create nodes
set n0 [$ns node]
set n1 [$ns node]
set n2 [$ns node]
set n3 [$ns node]
set n4 [$ns node]
set n5 [$ns node]
set n6 [$ns node]
#Create links between nodes
$ns duplex-link $n0 $n5 10Mb 10ms DropTail
$ns duplex-link $n1 $n5 10Mb 10ms DropTail
$ns duplex-link $n2 $n5 10Mb 10ms DropTail
$ns duplex-link $n3 $n5 10Mb 10ms DropTail
$ns duplex-link $n4 $n5 10Mb 10ms DropTail
$ns duplex-link $n5 $n6 1Mb 20ms DropTail
$ns queue-limit $n5 $n6 30
$ns duplex-link-op $n0 $n5 orient down
$ns duplex-link-op $n1 $n5 orient right-down
$ns duplex-link-op $n2 $n5 orient right
$ns duplex-link-op $n3 $n5 orient right-up
$ns duplex-link-op $n4 $n5 orient up
$ns duplex-link-op $n5 $n6 orient right
$ns duplex-link-op $n5 $n6 queuePos 0.5
#Create traffic sources
#The first TCP traffic source
set tcp0 [new Agent/TCP]
$tcp0 set class_2
$ns attach-agent $n0 $tcp0
set sink0 [new Agent/TCPSink]
$ns attach-agent $n6 $sink0
$ns connect $tcp0 $sink0
$tcp0 set fid_1
set par [new Application/Trafic/Pareto]
$par attach-agent $tcp0
$par set packetSize_210
$par set burst_time_50ms
$par set idle_time_50ms
$par set rate_200kb
$par set shape_1.5
#The second TCP traffic source
set tcp1 [new Agent/TCP]
$tcp1 set class_3
$ns attach-agent $n4 $tcp1
set sink1 [new Agent/TCPSink]
$ns attach-agent $n6 $sink1
$ns connect $tcp1 $sink1
$tcp1 set fid_1
set par1 [new Application/Trafic/Pareto]
$par1 attach-agent $tcp1
$par1 set packetSize_210
$par1 set burst_time_50ms
$par1 set idle_time_50ms
$par1 set rate_200kb
$par1 set shape_1.5
#The first UDP traffic source
set udp1 [new Agent/UDP]
$ns attach-agent $n1 $udp1
set null1 [new Agent/LossMonitor]
$ns attach-agent $n6 $null1
$ns connect $udp1 $null1
$udp1 set fid_2
set cbr1 [new Application/Trafic/CBR]
$cbr1 attach-agent $udp1
$cbr1 set type_CBR
$cbr1 set packet_size_100
$cbr1 set rate_200kb
$cbr1 set random_false
#The second UDP traffic source
set udp2 [new Agent/UDP]
$ns attach-agent $n2 $udp2
set null2 [new Agent/LossMonitor]
$ns attach-agent $n6 $null2
$ns connect $udp2 $null2
$udp2 set fid_2
set cbr2 [new Application/Trafic/CBR]
$cbr2 attach-agent $udp2
$cbr2 set type_CBR
$cbr2 set packet_size_100
$cbr2 set rate_200kb
$cbr2 set random_false
#Planning events
$ns at 0.0 “record”
$ns at 0.1 “$cbr1 start”
$ns at 0.3 “$cbr2 start”
$ns at 1.0 “$par start”
$ns at 1.1 “$par1 start”
$ns at 4.0 “$par1 stop”
$ns at 4.1 “$par stop”
$ns at 4.2 “$cbr2 stop”
$ns at 4.5 “$cbr1 stop”
$ns at 4.5 “$ns detach-agent $n0 $tcp0; $ns detach-agent $n6 $sink0”
$ns at 4.5 “$ns detach-agent $n4 $tcp1; $ns detach-agent $n6 $sink1”
$ns at 5.5 “finish”
#Run the simulation
$ns run
6.5.2 Algorithms ran in simulation
DropTail is one of the simplest algorithms, also named FIFO (first in first out). It is also one of the most implemented and used algorithms. Additionally, it is the de facto standard routing method in the Linux kernel and in the majority of all the routers in the world. It employs a single tail to serve packets. The processing applied to flows is equal. Packets are extracted from the tail in the order of arrival (Figure 6.23).
Figure 6.23 DropTail algorithm.
6.5.2.1.1 Advantages
For software routing, DropTail needs very few resources compared to more elaborate algorithm.
The behavior is very predictable, the packets are not reordered and the maximum delay depends on the depth of the tail.
While the size of the tail is small, DropTail provides a simple management of resources without a significant delay at each node.
6.5.2.1.2 Disadvantages
Having a single tail for all incoming packets, it does not allow for organizing stored packets and applying different processing to traffic flows.
The single tail affects all the flows because the medium delay of each one increases when congestion appears.
DropTail planning increases the delay, the delay variation, and the rate of lost packets for real-time applications that cross the tail.
During congestion periods, DropTail tends to favor UDP flows to the disadvantage of TCP flows. When a TCP application detects massive packet losses due to congestion, it will try to reduce the data rate, while UDP transmissions are impassable to such events, thus keeping their nominal transmission rate.
Because the reduction of transfer rate for TCP applications in order to cope with the network conditions, the congestion avoidance mechanism can produce increasing delays, delay variation, and decreasing bandwidth for TCP applications that pass through the tail.
A burst data flow can easily fill the tail, and from that moment on the node rejects packets from other flows while the burst is processed. This leads to an increasing delay and delay variation for all other TCP and UDP applications that behave correctly.
Deficit round robin, known also as deficit-weighted round robin (DWRR), is a modified form of the weighted round robin (WRR) planning algorithm. It was proposed by Shreedhar and Varghese in 1995.
WRR is a variant of the generalized processor sharing (GPS) algorithm. While GPS serves a small quantity of each tail that is not empty, WRR serves a number of packets from each tail that is not empty.
The number of packets = norming (weight/average packet size)
In order to obtain a normalized set of weights, the average packet weight must be known. Only then can WRR correctly estimate GPS. It is best for this parameter to be known before hand. This is not easy to do in real networks, so it must be estimated, which is quite tough to do in the GPS context.
An improved variant of WRR is DRR that can serve variable size packets without needing to know an average size. The maximum dimension of the packets is extracted from the packets in the tail. Packets that are even larger and arrive after determining this value must wait for a new pass of the planner.
While WRR serves every tail that is not empty, DRR serves each tail that is not empty and has a deficit higher than the packet size. If the packet is greater than the deficit, then it is incremented with a value named quantum and the packet is kept waiting. For each flow, the algorithm sends so many packets as the value of the quantum allows. The quantum that remains unused is added to the deficit of the specific tail. The quanta can be allocated based on a tail weight in order to emulate WFQ, and when a flow is waiting and has no packets to send, the quantum is canceled because it had the chance to send packets and it has lost it.
A simple variation of DRR is credit round robin (CRR). In the case of CRR, when a flow has a packet in the tail, but does not have enough quantum to send the packet, the planner sends but it will record the extra quantum in the credit of the flow.
Fair queuing (FQ) was proposed by John Nagle in 1987. FQ is the foundation for an entire class of planning disciplines oriented toward assuring that each flow has a fair access to the network resources and preventing the burst traffic from consuming more than its fair share from the output bandwidth. In FQ, the packets are firstly classified in flows and assigned to a tail dedicated to a certain flow. The tails are then served one packet at a time. Empty tails are not served. FQ is also referred to as flow-based planning.
FQ is sometimes compared to WFQ (weighted FQ). The WFQ algorithms are explained by the fluid model. In this model, it is assumed that the traffic is infinitely dividable and a node can serve simultaneously several flows. In real networks, packets are processed one at a time. So the size of the packets will affect the planning system. Nevertheless, the simplification from the fluid model allows for viewing more easily the planning disciplines operations and, in many cases, is accurate enough to extend the results to a packet system from a fluid model (Figure 6.24).
Figure 6.24 FQ algorithm.
SFQ is part of the class of algorithm based on the FQ algorithm. This algorithm was proposed by John Nagle in 1987. SFQ is a simple implementation of fair queuing algorithm. It is more accurate than other but it needs fewer computations, while still being almost perfectly fair.
The key point in SFQ is the conversation or the data flow, that corresponds to a TCP session or a UDP flow. The traffic is divided into a large enough FIFO tails, one for each conversation. It is then sent in a round robin manner, giving each session the chance of sending data one at a time.
This leads to a very fair behavior and avoids situations when a conversation suffocates the rest of the traffic. SFQ is deemed stochastic because it really does not allocate a tail for each session, rather it employs an algorithm that splits the traffic into a finite number of tails using a hashing method.
Because of this hash, several sessions can be allocated to the same tail, which also cuts in half the change of each session to send packets, thus reducing available speed. In order to prevent this to become noticeable, SFQ changes the hashing function frequent enough, so that two colliding sessions will only do it for a limited time.
It is important to note that SFQ is useful only if the output interface is under a heavy load. Otherwise, no tail will exist and its effects will not be visible.
RED is an active tail management algorithm. It is also a congestion avoidance method (Figure 6.25).
RED was developed in conjunction with TCP to provide early warning on a potential congestion. RED computes the length of a tail Qmean using an average weight, as follows:
Figure 6.25 RED algorithm processing flow.
The averaging process smoothens the temporal traffic fluctuations and offers a stable indicator for traffic trends on the long term. RED keeps two limit values per tail: MinThreshold and MaxThreshold. Once the tail length drops under MinThreshold, incoming packets are rejected with a probability of p. The rejection probability increases linearly towards 1 as the average size of the queue over MaxThreshold. These parameters provide the service providers with fine tune mechanisms for acting against congestions.
When consecutive packets are rejected due to the overloading of the buffer memory, one can observe the synchronizing of the transfer rates for the systems involved in the congestion, as all detect the congestion quasi-simultaneous. Such a synchronization may lead to fluctuations of the queue size. The random rejection in RED helps reduce the synchronization phenomenon. Also, it increases the fairness in rejecting the packets; since the rejection is random, the emitter that sends more packets will be refused more packets in case of a congestion.
Transfer rate, delay, and delay variation were measured in order to analyze the performance of each algorithm. The same simulation conditions are used for all the five algorithms. The results of these measurements are commented in the following pages.
6.5.3.1 Transfer rate analysis
The transfer rate is an important parameter to be monitored in the field of QoS. It is important for the majority of applications that use the Internet. Thus, a proper usage of available bandwidth is essential.
In general practice, the max–min planning policy is respected, meaning the maximizing of the minimum rate that a flow receives when participating in a connection. This implies that each flow obtains at least its fair part of the physical bandwidth, and when the load is small and there is some amount of unused bandwidth, the flow is allowed to occupy these resources.
In the case of this analysis, the average transfer rate on the five to six links is monitored for every flow. The graphics are drawn using the Xgraph utility. On the OX is shown the simulation time (0–5 s), and on the Oϒ is shown the scaled transfer rate value.
The curves on the graph represent:
• Red—traffic to be generated by node 1 of type CBR1
• Green—traffic to be generated by node 2 of type CBR2
• Yellow—traffic to be generated by node 0 of type web TCP1
• Blue—traffic to be generated by node 4 of type web TCP2
6.5.3.1.1 DropTail case As already mentioned in the description of the algorithm, DropTail is not fair and does not offer equal chances to traffic flows that compete for the bandwidth. This can be seen from the significant variation registered for the UDP traffic. The UDP traffic is generated at a constant rate of 200 kB/s, adding to 400 kB/s on the outgoing link. This traffic can be compared to a video/audio conference with a constant rate. Note that when the TCP sources start to emit in bursts and the tail is full, the UDP flows are affected. Their transfer rate begins to oscillate and drops under 200 kB/s. In the moments of “peace” for the network, the transfer rate manages to return to its nominal value (Figure 6.26).
Such a behavior is inacceptable for a loss-sensitive transfer. Each time the data rate drops, the difference up to the nominal value is made of lost packets. In conclusion, DropTail does not manage to provide minimum guarantees for QoS in a network, and thus it is inappropriate for modern applications. Nevertheless, it constitutes a reference point for studying more complicated algorithms due to its simplicity.
Figure 6.26 DropTail transfer rate.
6.5.3.1.2 DRR case Compared to DropTail, DRR offers fairness in traffic planning. Note that the UDP-generated traffic reaches and remains at the nominal transfer rate (Figure 6.27). Also, for an equal sharing of bandwidth among the four flows, each should get around 250 kB/s, so the 200 kB/s generated by each of the UDP sources are under this threshold and should not be affected by the traffic variation of the other sources. This happens in the case of DDR, which has a good fairness stability.
Another notable thing is that the TCP flows are equal. Each flow manages to occupy its own space without affecting the behavior of the other. The occasional bandwidth spikes are followed by periods when each flow occupies only its share of bandwidth, 300 kB/s.
6.5.3.1.3 FQ case FQ is one of the algorithms that offer and guarantee a fair planning. As DRR, FQ manages to fairly share the bandwidth between all four sources. The UDP traffic remains at a value of 200 kB/s for each source. This time, the variations are smaller than in the case of DRR. Note that for the TCP traffic the flows are equal, each one receiving 300 kB/s. An interesting detail is the symmetry between the TCP flows.
Figure 6.27 DDR transfer rate.
In general, the behavior of FQ is better than all other algorithms, managing to reach the best resource sharing in the fairest way. Nevertheless, FQ is quite a complex algorithm (Figure 6.28).
6.5.3.1.4 RED case RED is an active tail management algorithm that rejects packages with a specified probability. In the test, RED managed to shut down completely one of the TCP traffic sources, in the favor of the other one. This is due to the early trying of the source to increase significantly the transfer rate and the traffic burst sent at that moment. The congestion reduction algorithm gradually lowered the transferred rate, allowing the second TCP source to seize all the bandwidth without causing a significant tail increase that would have been penalized by RED. Note that the UDP flows are affected because of the rejection of packages with a higher probability as the tail size increases. The moments when the UDP rate drops coincide with the moments when the TCP traffic increases, when the tail is full and packets begin to be rejected, including UDP packets (Figure 6.29).
Figure 6.28 FQ transfer rate.
Compared to FQ and DDR, RED does not accomplish to eliminate the interdependency between flows. The suppression of the TCP2 traffic is unacceptable.
6.5.3.1.5 SFQ case Although part of the FQ algorithms, SFQ displays the worst behavior regarding the UDP bandwidth. This can be due to a collision: the two UDP traffic sources end up in the same SFQ tail and the bandwidth for each one is halved. Although the SFQ algorithm has protection mechanism to prevent such events by changing the hashing method once at a couple of seconds, in our example, the time interval was too short to allow for a reconfiguration (Figure 6.30).
Figure 6.29 RED transfer rate.
Figure 6.30 SFQ transfer rate.
Regarding the TCP traffic, there is some fairness among the sources. They share the available bandwidth equally. In this case of traffic, the hashing method works.
UDP flow delays is important for applications that require a QoS. They need, beside a minimum bandwidth, a guaranteed delay. The delay of packets is due to a fixed component (processing, propagation time) and to time spent waiting in the tail. For providing quality services, it is good for this delay to be a priori known in terms of the maximum and average values (Figures 6.31 and 6.32).
For the analysis of the UDP delay, Figures 6.31 and 6.32 present side by side the delay of the two UDP flows in the five cases. On the OX axis is the packet number and on the Oϒ axis the delay of the respective packet. Because of the difference between the total numbers of packets transferred in each case, the length of the graphs is not equal.
Figure 6.31 UDP 1 source delay.
Figure 6.32 UDP2 source delay.
Consider the following legend:
DropTail—dark blue
DRR—red
FQ—yellow
RED—light blue
SFQ—green
As expected, in the analysis made on the transfer rate the algorithms that behaved best were the FQ and the DRR, with an advantage for FQ. The average delay for these algorithms was approximately 0.03 s. The small oscillations that appear in the graph are due to the synchronization of the UDP sources. Both of them transmit a packet at the same time, but the packets cannot be sent simultaneous, so one of them is delayed with a time necessary for sending one packet. This phenomenon alternates between flows. Note that the TCP flows, traffic bursts, do not affect the delay of the UDP packets. This is confirmed by the simulation when in the tail of node 5 there were mostly TCP packets.
In the case of the other algorithms, the delay becomes quite large at some points and it varies strongly. The worst behavior is the one of SFQ. Because of the phenomenon that also affects the transfer rate the UDP packets are delayed for a long time. Note that for these algorithms the TCP bursts also affect the delay of UDP. If for RED and DropTail the delay has a maximum of 0.1 s, for SFQ it can reach even 0.2 for the UDP1 source. A strange thing is the different treatment applied by SFQ to the UDP sources, in favor of the second source. In fact, the behavior of SFQ for source 2 is similar to some extent to RED and DropTail.
For the TCP traffic analysis, the same way of presenting results will be used, by figuring in a structured manner the delay on both TCP flows in all the five cases (Figures 6.33 and 6.34).
Consider the same legend
DropTail—dark blue
DRR—red
FQ—yellow
RED—light blue
SFQ—green
The first noticeable thing for both traffic sources is that the algorithms that offer the best fairness and are the most correct when allocating bandwidth and packet priority are also the same that introduce the greatest delays in the TCP traffic. This is explainable because in their attempt to occupy as much bandwidth as possible, these flows penalize themselves by large delays and packet losses. Because of the nature of the applications that generate such a traffic, Web browsing, ftp, and so on, the large delay is not a major disadvantage. Note that DRR accomplishes a better distribution of the delay even if it reaches a higher fairness level than FQ.
Regarding the other planning algorithms, DropTail, RED, and SFQ their delay is quite small for the TCP traffic because they do not differentiate so strongly as FQ and DRR do. The lack of packets for the TCP1 flow on the RED algorithm is caused by the traffic choking phenomenon, presented in the transfer rate analysis. Another noteworthy detail is that the delay introduced by these algorithms for the TCP traffic is approximately just as large as the one for UDP, thus highlighting the lack of a preferential treatment of flows.
Figure 6.33 TCP1 source delay.
Figure 6.34 TCP2 source delay.
Considering the way the Internet is growing now, service providers are barely managing to cope with the high demand. The proliferation of broadband connections like DSL, cable, or fiber optics increased the bandwidth for accessing the Internet tenfold. Service providers must cope with this increase by adding more bandwidth to their own networks. The short life of network equipment and the continuous upgrade of network infrastructure help implement QoS on the long term. This will facilitate next implementations and the service providers will experiment and develop new services using the capabilities of the new equipment.