The Organization and Inheritance of MHC Genes
Every vertebrate species studied to date possesses the tightly linked cluster of genes that constitute the MHC. As we have just discussed, MHC molecules have the important job of deciding which fragments of an antigen, both foreign and self, will be “seen” by the host T cells. In general terms, MHC molecules face a ligand-binding challenge similar to that faced, collectively, by B-cell and T-cell receptors: they must be able to bind a wide variety of antigens and they must do so with relatively strong affinity. However, these immunologically relevant molecules meet this challenge using very different strategies. Although B- and T-cell receptor diversity is generated through genomic rearrangement and gene editing (described in Chapter 6), MHC molecules use a combination of peptide-binding promiscuity (discussed previously) and the expression of several different MHC molecule variants on every cell (described in this section). Using this clever combined strategy, the immune system has evolved a way of maximizing the chances that many different regions, or epitopes, of an antigen will be recognized.
Studies of the MHC gene cluster originated from two observations related to the study of transplantation that coalesced in the early twentieth century. The first was that human red blood cells (RBCs) carried biochemical surface markers that differed between individuals, and these molecules could be detected by antibodies in the serum of others. The second was that cancer cells transplanted between animals of different genetic backgrounds were quickly rejected. The biochemical markers on RBCs were identified by Karl Landsteiner as the ABO blood group antigens, a discovery that paved the way for a medical breakthrough in blood transfusions and resulted in a Nobel Prize for Landsteiner in 1930 (see Table 1-2).
Blood group antigens were also being studied by scientists interested in why some tumor transfers between animals were rejected and others were not. As luck and experimental rigor would have it, British scientist Peter Gorer took up this question and happened to have three inbred strains of mice at his disposal. He identified four groups of genes that encode blood-cell antigens, designated I through IV. Work carried out in the 1940s and 1950s by Gorer and George Snell established that antigens encoded by the genes in group II were responsible for the rejection of transplanted tumors and other tissue, as these antigens were present throughout the body (with another Nobel Prize, this time for Snell in 1980; see Table 1-2). Snell called these histocompatibility genes; leading to their current designation as histocompatibility-2 (H2) genes. Thus Gorer’s original group II blood-cell antigens are today synonymously referred to histocompatibility antigens, MHC antigens, or MHC molecules, regardless of species.
The MHC Locus Encodes the Three Major Classes of MHC Molecules
The major histocompatibility complex is a collection of genes arrayed within a long continuous stretch of DNA on chromosome 6 in humans and on chromosome 17 in mice. The MHC is also referred to as the human leukocyte antigen (HLA) complex in humans and as the H2 complex (previously H-2) in mice, the two species in which these regions have been most studied. Although the arrangement of genes is somewhat different in the two species, in both cases the MHC genes are organized into regions encoding three classes of molecules (Figure 7-6). Within these regions are genes that are considered to be prototypic examples of each class, which are called classical MHC genes, as well as some that are considered nonclassical MHC genes. We describe each in turn in the following sections.
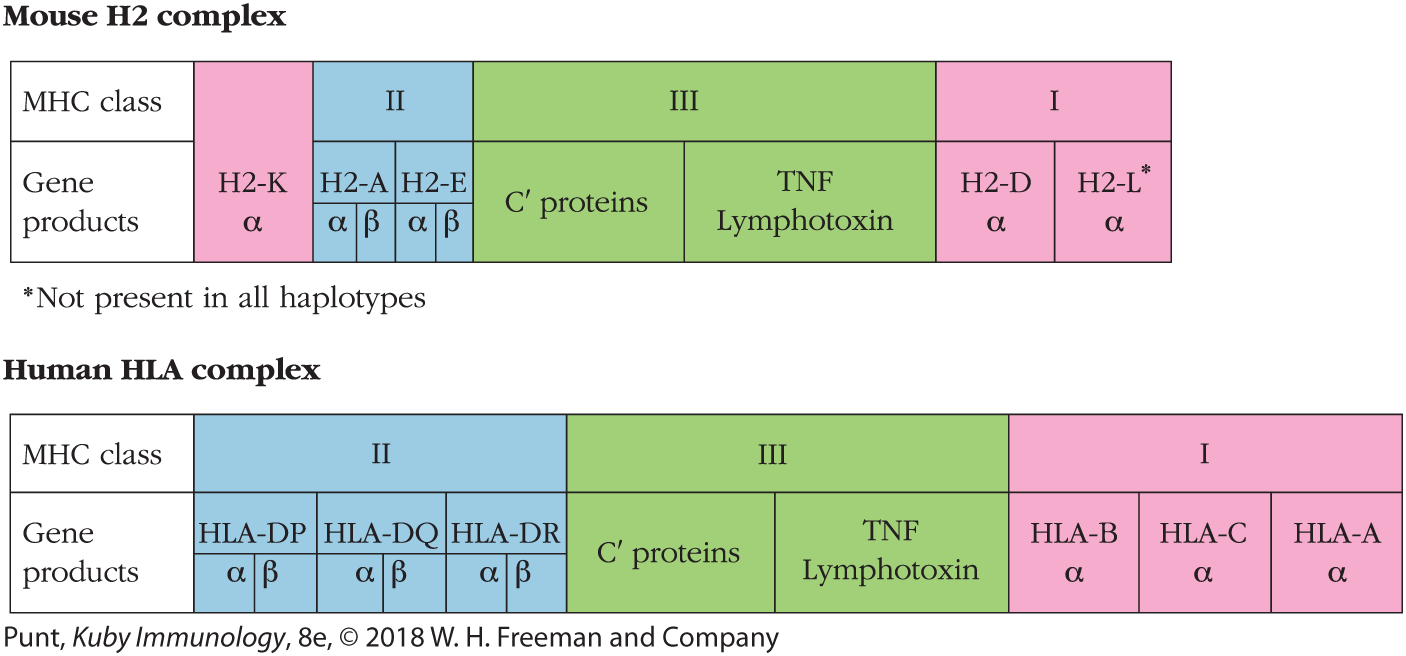
FIGURE 7-6 Comparison of the organization of the major histocompatibility complex (MHC) in mice and humans. The MHC is referred to as the H2 (formerly H-2) complex in mice and as the HLA complex in humans. In both species, the MHC is organized into a number of regions encoding class I (pink), class II (blue), and class III (green) gene products. The class I and II gene products shown in this figure are considered to be the classical MHC molecules. The class III gene products include other immune function–related compounds such as the complement proteins (C’) and tumor necrosis factors (TNF and lymphotoxin).
Classical MHC Genes
The first of the identified and characterized groups of MHC genes, and those that will receive the most attention in any immunology textbook, are the classical MHC genes. These are divided into three groups or classes:
- MHC class I genes encode glycoproteins expressed on the surface of nearly all nucleated cells; the major function of the class I gene products is presentation of endogenous (cytosolic) peptide antigens to CD8+ T cells.
- MHC class II genes encode glycoproteins expressed predominantly on APCs (macrophages, dendritic cells, and B cells), where they primarily present exogenous (extracellular) peptide antigens to CD4+ T cells.
- MHC class III genes encode a diverse set of proteins, some of which have immune functions, but that do not play a direct role in presenting antigen to T cells.
MHC class I molecules were the first to be discovered and are expressed in the widest range of cell types. The protein products from this region of the MHC can be found on virtually every nucleated cell in humans and mice. Unlike in humans, this region in mice is noncontinuous, interrupted by the class II and III regions (Figure 7-7; also see Figure 7-6). Recall that there are two chains to the MHC class I molecule: the more variable and antigen-binding α chain, and the common β2-microglobulin chain. The α-chain molecules are encoded by the H2-K and H2-D genes in mice, with an additional H2-L locus found in some strains. Likewise, the HLA-A, HLA-B, and HLA-C loci in humans encode MHC class I genes. β2-Microglobulin is encoded outside the MHC locus, on a separate chromosome altogether (chromosome 15 in humans and chromosome 2 in mice). Collectively, these α chains are referred to as classical class I molecules; all possess the functional capability of presenting protein fragments of antigen to CD8+ T cells.
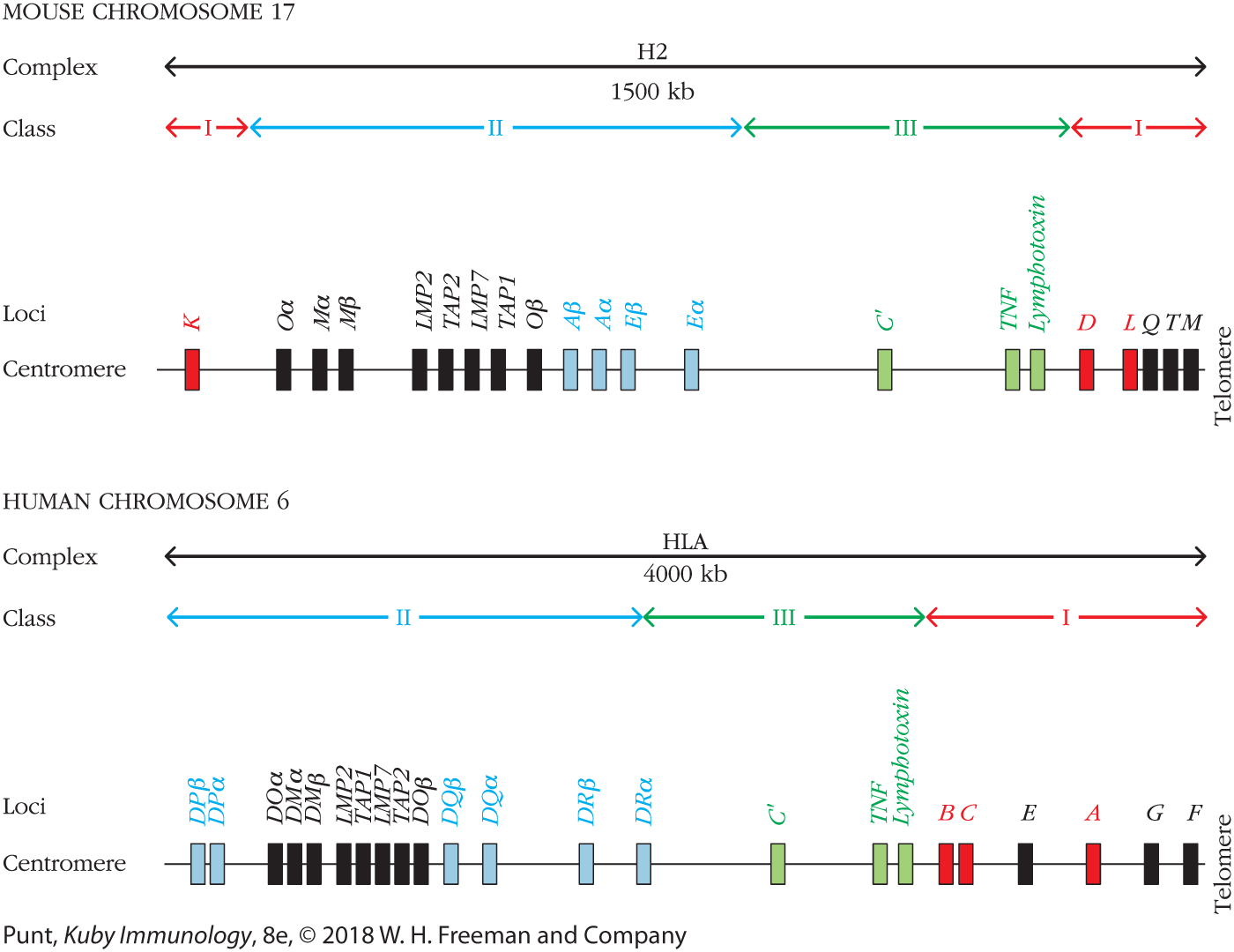
FIGURE 7-7 Simplified map of the mouse and human MHC loci. The classical MHC class I genes are colored red, classical MHC class II genes are colored blue, and genes in MHC class III are colored green. Nonclassical MHC genes are labeled in black. Note: The concept of classical and nonclassical does not apply to class III. Only some of the nonclassical class I genes are shown; the functions of only some of their proteins are known.
MHC class II proteins show a more limited tissue distribution and more varied expression levels (as we will see shortly). In general, class II molecules are primarily found on the surface of professional APCs, cells with the unique capacity to alert T cells to the presence of a specific antigen. Recall that MHC class II molecules are composed of two polymorphic chains, α and β, both of which contribute to creating a peptide-binding site. The class II region of the MHC contains three loci in humans, called HLA-DP, HLA-DQ, and HLA-DR. Within each of these three loci is the coding sequence for both an α chain and a β chain. In mice there are two loci that encode MHC class II α and β chains, called H2-A and H2-E. In some cases multiple genes are present for either or both chains within a locus. For example, individuals can possess more than one DR β-chain gene on one or both chromosomes, and all of these are expressed simultaneously in the cell. Furthermore, any DR α-chain gene product can pair with any DR β-chain product. Since the antigen-binding groove of class II is formed by a combination of the α and β chains, this can create several unique antigen-presenting MHC class II DR molecules on the cell.
MHC class III molecules bear no structural or functional similarity to classical class I and II molecules, all of which (so far) seem to have direct roles in antigen processing and presentation. Proteins encoded in the class III region are involved in other critical immune functions. For instance, the complement components C4, C2, and factor B (see Chapter 5), as well as several inflammatory cytokines, such as the tumor necrosis factor proteins (TNF and lymphotoxin), lie within the class III region. While the genes in the class III region are much less polymorphic than those in the class I and II regions, allelic variants of some class III genes have been linked to certain diseases. For example, polymorphisms within the TNF gene, which encodes a cytokine involved in many immune processes (see Chapter 3), have been linked to susceptibility to certain infectious diseases and some forms of autoimmunity, including Crohn’s disease and rheumatic arthritis. Despite its differences from class I and class II genes, the class III gene cluster is conserved in all species with an MHC locus, suggesting similar evolutionary pressures have come to bear on this cluster of genes.
Finally, it is worth noting that the nomenclature of the MHC locus is an ever-changing and complicated business. For example, the mouse MHC class II regions called H2-A and H2-E were previously designated H2-IA and H2-IE. The human MHC class II regions are called DP, DQ, and DR, but the D locus in mice encodes MHC class I molecules. Likewise, the mouse class II region has an A locus (formerly called IA), easily confused with the A locus in the class I region of humans (see Figure 7-6). Clearly, like biological evolution, the evolution of nomenclature is messy business!
Nonclassical MHC Genes
Additional genes within the MHC locus encode nonclassical molecules. These have a more restricted tissue expression, less diversity, and more varied roles in immunity. Unlike classical molecules, nonclassical class I proteins are expressed only on the surface of specific cell types with more specialized functions. In some cases these molecules play a role in self/nonself discrimination. One example is the HLA-G class I molecule in humans (see Figure 7-7). These are present on the surface of fetal cells at the maternal-fetal interface and are credited with inhibiting rejection by maternal CD8+ T cells by protecting the fetus from identification as foreign, which may occur when paternally derived antigens begin to appear on the developing fetus.
As with the class I region, additional nonclassical class II molecules exhibiting little polymorphism and specialized immune functions are encoded within the class II region. For instance, the human DM genes are expressed in all antigen-presenting cells and encode a class II–like molecule (HLA-DM) that facilitates the intracellular loading of antigenic peptides into MHC class II molecules. Likewise, class II DO molecules are also involved in antigen processing and presentation. These molecules have a more limited expression profile, found only in specific regions of the thymus, in B cells during certain stages of development, and (discovered more recently) in subsets of dendritic cells. In all cases, DO molecules are believed to serve as an intracellular regulator of class II antigen processing and presentation. In fact, DM and DO are known to associate with one another and seem to appear only at intracellular locations. It is now believed that DO may be involved in inhibiting or otherwise modifying the function of DM in cells that express both of these proteins. We will encounter these nonclassical MHC molecules again shortly when we turn to antigen processing and presentation.
Allelic Forms of MHC Genes Are Inherited in Linked Groups Called Haplotypes
As we have already mentioned, genes that reside within the MHC locus are highly polymorphic; that is, many alternative forms of each gene, or alleles, exist within the population. This polymorphism clusters in the DNA regions that encode amino acids likely to lie in the antigen-binding groove and therefore likely to come into contact with peptide. Genetic variations outside this region, for instance, in the membrane-proximal or transmembrane domains, are very rare.
The individual genes of the MHC locus (class I, II, and III) lie so close together that their inheritance is linked. Crossover, or recombination between genes, is more likely when genes are far apart. The recombination frequency within the mouse H2 complex (i.e., the frequency of chromosome crossover events during meiosis, indicative of the distance between given genes) is only 0.5%. Thus, crossover occurs only about once in every 200 meiotic cycles. For this reason, most individuals inherit all the alleles encoded by these genes as a set (known as linkage disequilibrium). This set of linked alleles is referred to as a haplotype. An individual inherits one haplotype from the mother and one haplotype from the father, or two sets of alleles.
In outbred populations, such as humans, the offspring are generally heterozygous at the MHC locus, with different alleles contributed by each of the parents. If, however, a population is highly inbred the offspring can become homozygous, expressing identical MHC molecules because the maternal and paternal haplotypes are identical. Certain mouse strains have been intentionally inbred in this manner (to be homozygous at the MHC) and are employed as prototype strains; that is, sets or strains of mice that are homozygous at the MHC locus for particular alleles. The unique MHC haplotype (in this case, also the genotype) expressed by each of these strains is designated by an arbitrary italic superscript after the H2 designation for the MHC region of mice (e.g., H2a, H2b, etc.). These haplotype designations are shorthand for the entire set of inherited H2 alleles within a strain without having to individually list the specific allele at each locus (Table 7-2). Different inbred mouse strains may share the same set of alleles, or MHC haplotype, with another strain (e.g., CBA, AKR, and C3H) but will differ in genes outside the H2 complex.
| H2 ALLELES | ||||||
|---|---|---|---|---|---|---|
| Prototype strain | Other strains with the same haplotype | Haplotype | K | A | E | D |
CBA |
AKR, C3H, B10.BR, C57BR |
k |
k |
k |
k |
k |
DBA/2 |
BALB/c, NZB, SEA, YBR |
d |
d |
d |
d |
d |
C57BL/10 (B10) |
C57BL/6, C57L, C3H.SW, LP, 129 |
b |
b |
b |
b |
b |
A |
A/He, A/Sn, A/Wy, B10.A |
a |
k |
k |
k |
d |
B10.A (2R)* |
h2 |
k |
k |
k |
b |
|
B10.A (3R) |
i3 |
b |
b |
k |
d |
|
B10.A (4R) |
h4 |
k |
k |
b |
b |
|
A.SW |
B10.S, SJL |
s |
s |
s |
s |
s |
A.TL |
t1 |
s |
k |
k |
d |
|
DBA/1 |
STOLI, B10.Q, BDP |
q |
q |
q |
q |
q |
Mice in a traditional inbred mouse strain are said to be syngeneic, or identical at all genetic loci. Two strains are congenic if they are bred to be genetically identical everywhere except at a single genetic region. For example, MHC congenic strains have the same genotype everywhere except at the MHC locus, where they differ. These mice are produced by a series of crosses and backcrosses between two inbred strains that differ at the MHC locus, with selection for particular MHC alleles in the progeny. For example, a frequently used congenic strain, designated B10.A, is derived from B10 mice (normally H2b) genetically manipulated to possess the H2a haplotype at the MHC locus. Other than at the MHC locus, B10 and B10.A mice are genetically identical. Therefore, any phenotypic differences between these congenic strains must come from the protein products of the MHC locus. Examples of common H2 congenic mouse strains are shown in the list in Table 7-2.
MHC Molecules Are Codominantly Expressed
The genes within the MHC locus exhibit a codominant form of expression. This means that both maternal and paternal gene products (both haplotypes) are expressed at the same time and in the same cells. Therefore, if two mice from inbred strains possessing different MHC haplotypes are mated, the F1 generation inherits both parental haplotypes and will express all these MHC alleles; twice as many as either parent. For example, if an H2b strain is crossed with an H2k strain, then the F1 generation inherits both parental sets of alleles and is said to be H2b/k (Figure 7-8a). Because such an F1 generation expresses the MHC proteins of both parental strains on its cells, it is said to be histocompatible, or MHC matched, with both parental strains. This means offspring are able to accept grafts from either parental source, each of which expresses MHC alleles viewed as “self” (Figure 7-8b). However, neither of the inbred parental strains can accept a graft from its F1 offspring because half of the MHC molecules (those coming from the other parent) will be viewed as “nonself,” or foreign, and thus subject to recognition and rejection by the immune system.

FIGURE 7-8 Illustration of inheritance of MHC haplotypes in inbred mouse strains and in humans. (a) The letters b/b designate a mouse homozygous for the H2b MHC haplotype, k/k a mouse homozygous for the H2k haplotype, and b/k a heterozygote. Because the MHC genes are closely linked and inherited as a set, the MHC haplotype of F1 progeny from the mating of two different inbred strains can be predicted easily. (b) Acceptance or rejection (indicated by the large blue X) of skin grafts is controlled by the MHC type of the inbred mice. The progeny of the cross between two inbred strains with different MHC haplotypes (H2b and H2k) will express both haplotypes (H2b/k) and will accept grafts from either parent and from one another. However, neither parent strain will accept grafts from the offspring. (c) Inheritance of HLA haplotypes in a hypothetical human family. For ease, the human paternal HLA haplotypes are arbitrarily designated A and B, maternal as C and D. Note that a new haplotype, R (recombinant), can arise from rare recombination of a parental haplotype (maternal shown here).
In an outbred population such as humans, each individual is generally heterozygous at each locus, and all alleles are expressed simultaneously. As in mice, the human HLA complex is highly polymorphic, MHC genes are closely linked, and alleles are inherited as a haplotype. When the father and mother have different haplotypes, as in the example shown in Figure 7-8c, there is a one-in-four chance that any two siblings will inherit the same paternal and maternal haplotypes, making them histocompatible with one another (i.e., genetically identical at the MHC loci, or MHC matched).
Although the rate of recombination by crossover is low within the HLA complex, it still contributes significantly to the diversity of the loci in human populations. Genetic recombination can generate new allelic combinations, and thus new haplotypes (see haplotype R in Figure 7-8c), and the high number of intervening generations since the appearance of humans as a species has allowed extensive recombination. As a result of recombination and other mechanisms for generating mutations, it is rare for any two unrelated individuals to have identical sets of HLA alleles. This makes transplantation between individuals who are not identical twins quite challenging! To address this, clinicians begin by looking for family members who will be at least partially histocompatible with the patient, or they rely on donor databases. Even with partial matches, physicians still need to administer heavy doses of immunosuppressive drugs to inhibit the strong rejection responses that typically follow tissue transplantation (see Chapter 16).
Class I and Class II Molecules Exhibit Diversity at Both the Individual and Species Levels
As noted earlier, any particular MHC molecule can bind many different peptides (called promiscuity), which gives the host an advantage in responding to pathogens. Rather than relying on just one gene for this task, the MHC region has evolved to include multiple genetic loci encoding proteins with the same function. In humans, class I HLA-A, -B, or -C molecules can all present peptides to CD8+ T cells and class II HLA-DP, -DQ, or -DR molecules present to CD4+ T cells. The MHC region is thus said to be polygenic because it contains multiple genes with the same function but with slightly different structures. Since the MHC alleles are also codominantly expressed, heterozygous individuals will express the gene products encoded by both alleles at each MHC gene locus. In a fully heterozygous individual this amounts to six unique classical class I molecules on each nucleated cell. An F1 mouse, for example, expresses the H2-K, -D, and -L class I molecules from each parent (six different MHC class I molecules) on the surface of each of its nucleated cells (Figure 7-9). The expression of so many individual MHC class I molecules, each with its own promiscuity of binding, allows a cell to display or present a large number of different peptides.

FIGURE 7-9 Diagram illustrating the various MHC molecules expressed on antigen-presenting cells of a heterozygous H2k/d mouse. Both the maternal and paternal MHC genes are expressed (codominant expression). Because the class II molecules are heterodimers, new molecules containing one maternal-derived and one paternal-derived chain are also produced, increasing the diversity of MHC class II molecules on the cell surface. The β2-microglobulin component of class I molecules (salmon) is encoded by a nonpolymorphic gene on a separate chromosome and may be derived from either parent.
MHC class II molecules have even greater potential for diversity. Each of the classical MHC class II molecules is composed of two different polypeptide chains encoded by different loci, which come together to form one class II binding pocket. Therefore, a heterozygous individual can express α-β combinations that originate from the same chromosome (maternal only or paternal only) as well as class II molecules arising from unique chain pairing derived from separate chromosomes (new maternal-paternal α-β combinations). For example, an H2k mouse expresses Ak and Ek class II molecules, whereas an H2d mouse expresses Ad and Ed molecules. The F1 progeny resulting from crosses of these two strains express four parental class II molecules (identical to their parents) and also four new molecules that are mixtures from their parents, containing one parent’s α chain and the other parent’s β chain (as shown in Figure 7-9). Since the human MHC contains three classical class II loci (DP, DQ, and DR), a heterozygous individual expresses six class II molecules identical to the parents and six molecules containing new α and β chain combinations, allowing for the construction of a total of 12 different class II molecules. In some instances the number of different class II molecules expressed by an individual can be further increased by the occasional presence of an additional α- or β-chain gene within a given locus. The diversity generated by these new MHC molecules likely increases the number of different antigenic peptides that can be presented and is therefore advantageous to the organism in fighting infection.
The variety of peptides displayed by MHC molecules echoes the diversity of antigens bound by antibodies and T-cell receptors. This evolutionary pressure to diversify comes from the fact that both need to be able to interact with antigen fragments they have never before seen, or that may not yet have evolved. However, the strategy for generating diversity within MHC molecules and the antigen receptors on T and B cells is not the same. Antibodies and T-cell receptors are generated by several somatic processes, including gene rearrangement and the somatic mutation of rearranged genes (see Chapters 6 and 11). Thus, the generation of T- and B-cell receptors is dynamic, changing over time within an individual. By contrast, the MHC molecules expressed by an individual are fixed. However, promiscuity of antigen binding ensures that even “new” proteins are likely to contain at least some fragments that can associate with any given MHC molecule. Collectively, this builds in enormous flexibility within the host for responding to unexpected environmental changes that might arise in the future—an elegant evolutionary strategy.
Countering this limitation on the range of peptides that can be presented by any one individual is the vast array of peptides that can be presented at the species level, thanks to the diversity of the MHC in any outbred population. The MHC possesses an extraordinarily large number of different alleles at each locus and is one of the most polymorphic genetic complexes known in higher vertebrates. These alleles differ in their DNA sequences by 5% to 10%. This means that the number of amino acid differences between MHC alleles can be quite significant, with up to 20 amino acid residues contributing to the unique structural nature of each allele. As of January 2017, analysis of the human HLA locus has identified over 15,000 alleles (Table 7-3 shows the number of protein products for each gene; not all alleles encode expressed proteins). In mice, the polymorphism is similarly enormous. There has been a significant increase in the number of recognized HLA alleles in the past 5 years. This may be due to recent efforts to collect data from a broader range of worldwide populations. Earlier HLA allele estimates were primarily based on individuals of European descent. There is an effort underway to collect more representative data sets, specifically from India and Africa, regions where the currently available genome data are not representative of the population size. Thus, while contemporary calculations of diversity in the human HLA may be a better approximation of diversity, they may still significantly underestimate the true degree of polymorphism in the human MHC locus. This disparity in available data can have significant impacts in the clinical realm. For instance, black Americans wait longer for and have lower success rates following kidney transplantation than their Caucasian counterparts. In addition to racial bias and socioeconomic factors, differences in HLA polymorphism rates among the African American population as well as the clinical guidelines routinely used by physicians for HLA matching may contribute to these discrepancies. Important changes in policy and practice can come from a greater appreciation for and implementation of more inclusive guidelines.
| MHC region | HLA locus | Number of allotypes (proteins) |
|---|---|---|
Class I |
A |
2480 |
B |
3221 |
|
C |
2196 |
|
E |
8 |
|
F |
4 |
|
G |
18 |
|
Class II |
DMα |
4 |
DMβ |
7 |
|
DOα |
3 |
|
DOβ |
5 |
|
DPα1 |
22 |
|
DPβ1 |
591 |
|
DQα1 |
34 |
|
DQβ1 |
678 |
|
DRα |
2 |
|
DRβ1 |
1440 |
|
DRβ3 |
106 |
|
DRβ4 |
42 |
|
DRβ5 |
39 |
This enormous polymorphism results in a tremendous diversity of MHC molecules within a species. Even just considering the most polymorphic of the HLA class I genes (A, B, and C), the theoretical number of potential class I haplotypes in the human population is over 40 billion (see Table 7-3). If the most polymorphic class II loci are considered, the numbers are even more staggering, with over 1013 different possible class II haplotypes. Because each HLA haplotype contains both class I and class II genes, theoretically, there could be as many as 1023 possible ways to combine HLA class I and II alleles within the human population. Combined with the promiscuity of peptide binding for each of these MHC molecules, this represents an enormous number of different vantage points for TCRs to engage with antigen.
Some evidence suggests that a reduction in MHC polymorphism within a species may predispose that species to disease (see Evolution Box 7-1). In one example, captive cheetahs and certain other wild cats, such as Florida panthers, show very limited genome diversity, theoretically due to episodes of past genetic bottlenecks. An apparent increased susceptibility of captive cheetahs to various viruses, to which close cousin species of cats show very low mortality, may result from a reduction in the number of different MHC molecules and a corresponding limitation in the range of processed antigens with which these MHC molecules can interact. Interestingly, this was first discovered when veterinarians noticed that captive cheetahs could receive skin grafts from unrelated members of their species without rejection! Wild cheetah populations do not appear to exhibit this same degree of MHC homogeneity and are also less susceptible to infectious disease. This suggests that this conservation of high levels of MHC polymorphism in most outbred species, including humans, may provide a survival advantage. Although some individuals within a species may not be able to develop a robust immune response to a given pathogen and therefore will be susceptible to infection, polymorphism in the population ensures that at least some members of a species will be resistant to that disease. In this way, MHC diversity at the population level may help protect the species as a whole from extinction due to infectious diseases.
MHC Polymorphism Is Primarily Limited to the Antigen-Binding Groove
Although the sequence divergence among alleles of the MHC within a species is very high, this variation is not randomly distributed along the entire polypeptide chain. Instead, polymorphism in the MHC is clustered in short stretches, largely within the membrane-distal α1 and α2 domains of class I molecules (Figure 7-10a). Similar patterns of diversity are observed in the α1 and β1 domains of class II molecules.

FIGURE 7-10 Variability in the amino acid sequences of allelic HLA class I molecules. (a) Most of the variability between MHC class I molecules lies in the membrane-distal α1 and α2 domains. (b) Polymorphic amino acid residues (red) in the α1/α2 domain of a human MHC class I molecule map to the peptide binding pocket. [Data from Sodoyer, R., et al. 1984. Complete nucleotide sequence of a gene encoding a functional human class I histocompatibility antigen (HLA-CW3). EMBO Journal 3:879.]
Structural comparisons have located the polymorphic residues within the three-dimensional structure of the membrane-distal domains in MHC class I and II molecules and have related allelic differences to functional differences (Figure 7-10b). For example, of 17 amino acids previously shown to display significant polymorphism among HLA-A molecules, 15 were shown by x-ray crystallographic analysis to be in the peptide-binding groove of this molecule. The location of so many polymorphic amino acids within the binding site for processed antigen strongly suggests that allelic differences contribute to the observed differences in the ability of MHC molecules to interact with a given peptide ligand. Polymorphisms that lie outside these regions and might affect basic domain folding are rare. This clustering of polymorphisms around regions that make contact with antigen also suggests possible reasons why certain MHC genes or haplotypes can become associated with certain diseases (see Clinical Focus Box 7-2).
The preceding discussion points to additional parallels between MHC molecules and lymphocyte antigen receptors. The somatic hypermutations seen in B-cell receptor genes are also not randomly arrayed within the molecule, but instead are clustered in the regions most likely to interact directly with peptide (see Chapter 11), providing yet another example of how the immune system has solved a similar functional dilemma using a very different strategy.