12 Virtualization
In the previous chapter, we recognized the need to sometimes interrupt a computation to perform some short urgent task. That approach is also useful in other settings, where the connection to interrupts might not be obvious. Interrupts are vital to sustaining certain kinds of useful illusions.
We can make a historic reference here to “Potemkin villages.” The phrase and associated story are familiar to many, although historians dispute whether any of it actually happened. In the late eighteenth century, Catherine the Great was the ruler of Russia. According to the story, she was traveling with her court and foreign ambassadors through Ukraine and Crimea, shortly after those areas had been conquered. Grigory Potemkin was the recently appointed governor of the territory, which had been devastated by the military campaigns. The queen’s party was traveling by barge down the Dnieper River. To create a better impression for the Russian monarch and the ambassadors, Potemkin arranged for a small number of mobile fake villages to be placed on the banks of the river, populated by Potemkin’s men pretending to be peasants. As the royal party passed, the village would be dismantled and moved downstream to look like another village. The effect was to create an illusion of population and wealth where both were severely lacking.
In a roughly similar fashion, certain specialized kinds of software can create the illusion of an unshared, enormous computer when the actual computer available is small and shared. Such software takes advantage of interrupts that happen whenever an event occurs that threatens to break the illusion. By handling each interrupt appropriately, the software quickly fixes each threat.
We have previously observed that our step-taking machinery usually emphasizes speedy simple steps rather than slower, more sophisticated steps. Instead of building ever more elaborate hardware machinery, we use software to extend the capabilities of this underlying machinery. Broadly speaking, virtualization is about building better versions of the step-taking machinery by adding one or more layers of software. The general pattern is to start with some underlying “real” thing and then make a new, more-flexible “virtual” version of that thing.
Thus we can have a “real machine” built of hardware or a “virtual machine” that is built of software wrapped around the real machine. We can likewise have a “real memory” that is built of hardware or a “virtual memory” that is built of software wrapped around the real memory. We can have a “real network” that is built of hardware or a “virtual network” that is built of software wrapped around the real network. In each of these cases, the virtual version is typically more flexible but slower than the real version. But since computer systems typically have plenty of “spare steps” or “unused speed,” building something slower but more flexible is often a good trade.
The real physical step-taking machinery is still focused on supplying fast, simple steps. So those capabilities are still available for programs that primarily need lots of raw speed. Virtualization is a way to have sophisticated facilities even though the underlying machinery is simple—a kind of way to have our cake and eat it too.
Managing Storage
We have described virtualization generally; we will next consider virtual memory specifically. When we have a computational problem to solve, it’s handy to be able to work on it without worrying too much about space limitations. That’s the problem that virtual memory solves.
Let’s start by assuming that you have the problem of dealing with luggage at a family reunion. Lots of people are coming from all over the world with lots of luggage, and you have to find places to put it. Because they’re your family, you probably know something about their quirks (such as who will need their luggage when). If you’re familiar with the venue, you know something about the spaces available and how to best use them. But even with all of that familiarity, it’s still a lot of work and you still make mistakes—you can’t predict all of your family’s behaviors in advance. Worse is that even after you survive one family reunion, that doesn’t necessarily give you any advantage for the next family reunion, because that will take place at a different venue with different storage spaces and with different family members in attendance.
In figure 12.1, there are some boxes on the left to fit into the spaces on the right.

The boxes need to be stored in the available spaces.
Figure 12.2 shows a solution that packs the boxes into the spaces. Of course, this particular solution doesn’t necessarily help us much if we are presented with a different collection of boxes and/or a different set of spaces.

One solution to the box storage problem.
It’s a similar experience when dealing with limited space for programming: the space-related arrangement that works in one setting may not be relevant for another. If we work out how to fit our data structures into (say) 16 megabytes of space, that set of arrangements isn’t likely to be useful if we then try running the exact same problem on a computer with half as much space. We’d have to redo the work of figuring out how to fit the data into the space available. We can also have the reverse problem: if we find ourselves using a computer that has twice as much space, we won’t be able to use the extra space if we stick with our detailed 16-megabyte layout. So we’d likely have to redo the work of figuring out how to best use the available space in that case too.
An alternative to working out a data layout for each size of memory could be to put even more work into an adaptive scheme that would expand and contract our use of space to match what was physically available. In the luggage-storage world, this approach would correspond to developing better skills at learning where storage space was and how to use it.
But as we develop such an adaptive scheme, we are likely to realize that many different programs share the goal of adapting to the space available. We don’t really want to be managing the data layout ourselves. We want there to be a service to take care of it for us.
In the luggage-storage example, we’re just working to support a family reunion. We don’t actually want to spend time and effort to get better at storing luggage. Instead, we would really prefer a bellhop or similar service that will take care of the details for us. That service might be less efficient than what we could do if we were willing to work hard and use our knowledge of our relatives’ particular quirks. But broadly speaking we’d rather hand the job to someone who specializes in it, and devote our energies to something else.
Virtual Memory
To avoid at least some of these space-related problems, operating systems often implement an analog to the luggage-space-managing service that we imagined. The operating system version of that service is virtual memory. With virtual memory, each executing program has a simple view of the space available: each program appears to have as much memory available as the machine is capable of holding. So every program apparently has sole possession of a computer full of memory. Meanwhile, the physical reality is that the computer may have far less than the maximum possible amount of memory. In addition, not all of the physical memory is necessarily available; the operating system and/or other programs may occupy a substantial fraction of it.
So how is it possible to create this illusion of a full, and fully available, memory? Our good fortune in the modern era is that our step-taking machinery typically has unused speed; our machines spend much of their time idle. This available speed is a part of what lets virtual memory work.
Our examples so far have only needed to deal with a small number of locations at a time, but that’s somewhat misleading. A modern computer actually has a vast number of memory locations, each with its own unique numeric address. We can talk about the whole range of such numeric addresses as the address space, and in principle the computer can examine any element of the address space at any time. However, a conventional computer has no way to survey the entire field of possible memory locations in a single step. Although it can request any address at any time, the program examines only one or two addresses at any one step. The address space is not a huge field laid out in bright sunshine so that the program can take it all in with a single sweeping glance.
Instead, it’s like a huge dark closet full of individual slots. The executing program has one or two flashlights, each with a beam that’s just wide enough to illuminate one slot at a time. As the program ranges its flashlights over the slots, each slot contains whatever the program has put there and expects to see there.
So what, you might ask? We can divide up the available storage among the multiple processes. The trick is to use a small amount of the physical memory for each process, rearranging that physical memory as needed to support the process’s actions in its much-larger virtual memory space. We let every process “pretend” that it has the whole address space, and fill in bits of physical memory as needed to sustain the illusion. We are taking advantage of the computer’s extreme speed, finding ways to switch back-and-forth fast enough that we can create illusions of whole systems from parts of systems.
Virtual Addresses and Real Addresses
To build virtual memory, we separate the process’s memory space into parts that are present vs. parts that are missing.
In figure 12.3, processes P1 and P2 both have large virtual address spaces—they have the illusion of being able to use all of the address space indicated. However, only a section of each virtual address space is present in the physical machine’s real address space. Notice that the location of a chunk of virtual address space within the real address space may not have any relationship to where that chunk is within the virtual address space. In order to effectively share the real machine, most application programs are relocatable—an address translation step allows them to operate in much the same way regardless of which real addresses they are using. The bookkeeping required to get the right addresses is simultaneously very important, very confusing, and very tedious. So we will skip it, apart from noting that this is the kind of area in which operating system programmers really earn their pay.
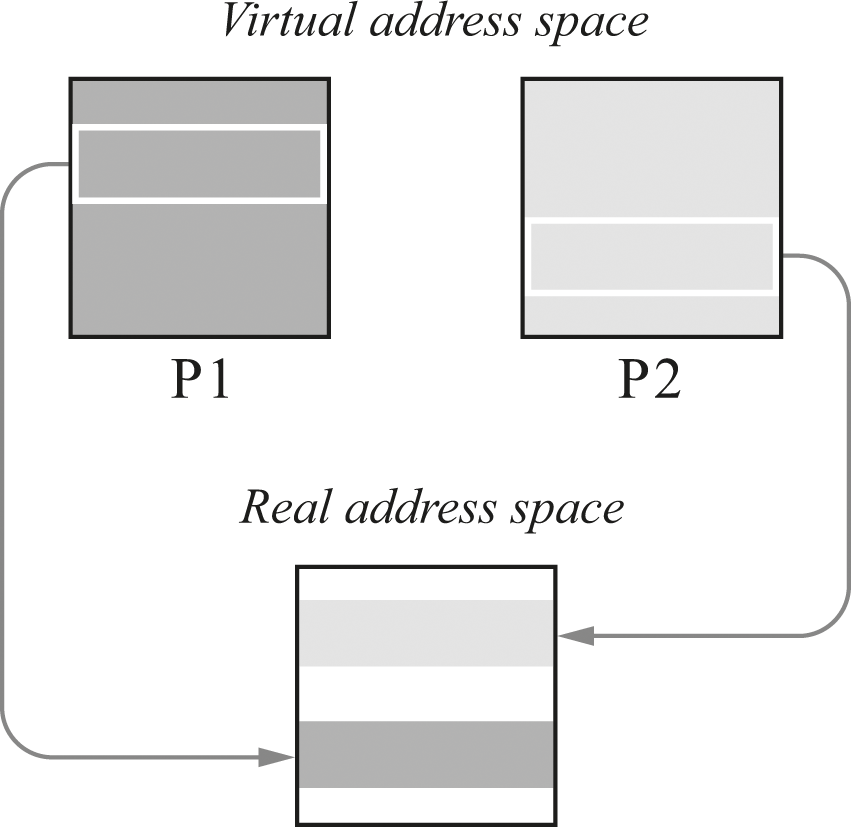
Two virtual address spaces sharing one real address space.
For an ordinary application, the step-taking machinery checks each read or write of memory to determine whether it’s related to an address that’s missing. If the relevant piece of memory is missing, an interrupt happens. The interrupt handler does the fixup required to bring in the relevant memory and make it present. Because space is limited, the machine might not have enough space available for what needs to be brought in. Finding enough space might require evicting something else and marking it as missing.
Marvelously, this test for absent memory can use the exact same arrangement as the one that we already saw for protection. From chapter 11, we already know how to keep an executing application away from the operating system’s memory: the machine checks each memory access and causes an interrupt whenever an ordinary application is trying to use part of the operating system’s space. To solve this new virtual-memory problem, we can treat all of the missing memory locations as belonging to the operating system. When an interrupt occurs because the process is apparently messing with operating-system memory, the interrupt handler can distinguish between a reference to absent memory and a genuine reference to operating system space. If the interrupt is caused by a reference to missing memory, the interrupt handler can make the necessary fixes so the memory is present; then the process can resume. If the triggering access really is a reference to the operating system’s memory, the interrupt handler doesn’t try to “fix” it. Instead, the process has somehow gone wrong, and the handler takes whatever actions are required to stop it.
Virtual Machines
A different kind of virtualization provides a bigger illusion. Whereas virtual memory supports the illusion of a whole memory dedicated to a single process, a virtual machine supports the illusion of an entire physical machine. That may not seem very impressive; after all, we already know that an operating system can present a shared machine to multiple application programs, each with the illusion of exclusive control. So we have to explain a little more about why a virtual machine is special.
Let’s first consider an operating system in a little more detail. In figure 12.4, two processes (process 1 and process 2) are both using services of a single operating system that is in turn running on a single machine.

Two processes sharing a single machine via an operating system.
The operating system provides an illusion of exclusive access to both processes, while actually mediating their shared use of the single underlying machine. It also provides a variety of shared services that make it more convenient for each process.
For example, an operating system often has a file system that makes permanent storage more convenient. Magnetic disks are useful permanent storage devices, but they are awkward to use. They come in many different sizes, and each one allows the reading or writing of only a fairly large fixed-size block of storage at a time. Even worse, each of those blocks is named only in terms of a numeric disk address. A file system hides all of these annoying details and makes it possible to think instead about variable-length files with user-friendly naming.
Now consider what would be involved in providing an illusion of exclusive access to the machine—but providing that illusion to operating systems, not ordinary applications. The program that achieves this kind of illusion is a hypervisor. One way to think of a hypervisor is that it’s an “operating system for operating systems.” As we’ll see shortly, that can be a misleading summary.
In figure 12.5, two different operating systems OS1 and OS2 are interacting with a single hypervisor, on a single machine. For completeness, we should show some processes in those operating systems to clarify the similarities and differences with how an operating system works.
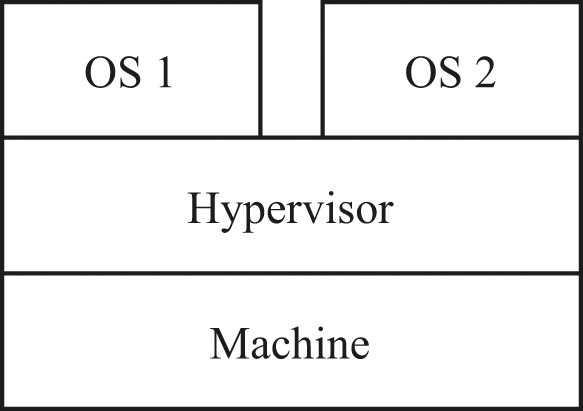
Two operating systems sharing a single machine via a hypervisor.
In figure 12.6, processes P1 and P2 each have an illusion of exclusive access, provided by operating system OS1, which also provides them with a variety of other convenience features. Processes P8 and P9 likewise each have an illusion of exclusive access, plus whatever features are provided by operating system OS2. Both OS1 and OS2 are designed to be in total control of the physical machine. But in this configuration, they are instead being fooled by the hypervisor.
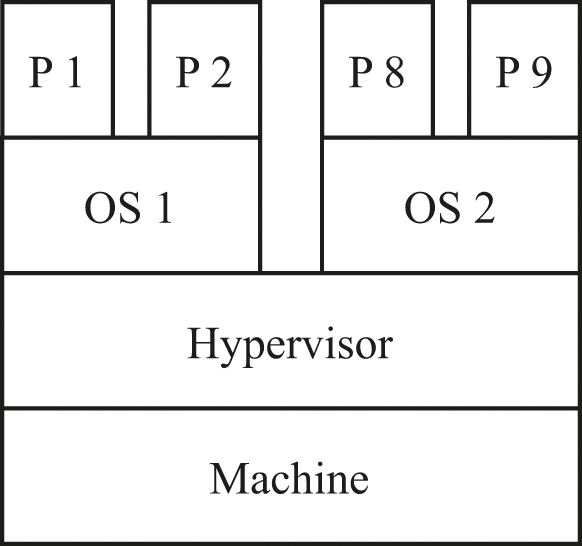
Different processes in different operating systems on one machine.
Although both operating systems and hypervisors are software infrastructure layers that provide useful illusions to their users, they are otherwise aiming at completely opposite goals:
• An operating system is providing services beyond the hardware, so as to make the hardware more convenient and easier to use; it is typically providing an extended or enhanced environment for programs. An operating system both provides facilities that are missing from the hardware, and hides or smooths over inconvenient realities of the hardware.
• In contrast, a hypervisor is intended to present the illusion of the exact, complete machine to a program that expects to have full control of that machine.
There is a seeming paradox here: in building a hypervisor, we are building a complex, expensive piece of software to produce an illusion of exactly what we already have (a physical machine). What is the point, and why is it a good idea?
Sharing Servers
Once we have a functioning hypervisor, we have virtual machines. Once we have virtual machines, there are all sorts of interesting possibilities. One important motivation is purely economic. Let’s first assume that we have some collection of what computer scientists call servers. A server can be any collection of functionality that is valuable enough and difficult enough to occupy an entire machine. The most common example of a server for most people is a web server—we will look at the mechanics of web services in chapters 15 and 20. However, there are many other kinds of servers like mail servers, file servers, and servers that don’t have any special name because they’re just a part of some complex application. The word “server” is also used to refer to the kind of machine used for a server—people will talk about “buying a new server,” for example.
In the most common arrangement, a software server runs on a single hardware server. However, with virtual machines, it’s possible to take two or more entire (software) servers and run them simultaneously on a single shared machine. This consolidation is possible even though each server potentially includes a distinct operating system and multiple applications. Virtual machines offer a good arrangement for the many servers that don’t demand a very large fraction of the hardware’s available resources.
Although we were concerned in chapter 7 about the way in which some problems can grow without bound, not all problems grow that way. For many important problems, their computational requirements remain approximately steady over time; meanwhile, Moore’s law keeps ratcheting hardware performance higher, with the inevitable result that what might once have been a demanding application becomes a relatively undemanding application.
In the abstract, we might think that Moore’s law means that machines of a roughly fixed capability get ever cheaper over time—and that does happen to some extent. But the more conspicuous, better-established pattern is the inverse: machines at a roughly fixed price get better over time. That means that the smallest machine we can economically buy tends to be better each time we go to purchase. So you don’t really ever get to buy a whole computer for a nickel, no matter what Moore’s law says. Instead, the computer you buy for a few tens or hundreds of dollars becomes increasingly impressive. This phenomenon isn’t surprising if we reflect that many of the components of a computer are not items that improve with Moore’s law. Even if the step-taking piece gets much better, the display, power supply, and similar “boring” components probably still cost roughly what they did before.
In the absence of virtual machines, we would need to deploy each of these relatively undemanding software servers on its own separate machine. Each of those machines would be underutilized. With virtual machines, we can consolidate servers onto fewer physical machines, saving money while not affecting performance. Virtual machines also enable cloud computing, which we will consider in chapter 20.
Building a Hypervisor
A hypervisor is conceptually simple, but it is hard to make one that’s efficient. If we want the fastest virtual machine possible, every step of the real machine should also be a step of the virtual machine. However, we know the virtual machine can’t always run at exactly the same speed as the underlying physical machine. At least some of the time, the hypervisor will need to behave differently from the hardware.
For example, an operating system running on a hypervisor can’t really interact directly with a keyboard, even though the operating system ordinarily handles keyboard interactions (as we saw in chapter 11). Instead, the hypervisor interacts with shared resources like a keyboard so that multiple different “guest” operating systems can each have their own virtual keyboard. At the point where a guest operating system is attempting to use the keyboard directly, the hypervisor has to take control and make the right things happen so that the operating system sees the right effects, even though the operating system doesn’t really have control of that keyboard.
That situation sounds a lot like what we already encountered with virtual memory. And a situation where “most of the time” we want to do the ordinary thing but “occasionally” we need to splice in a different behavior is a lot like what we already encountered with I/O and error conditions.
Indeed, modern efficient hypervisors depend on some of the same tricks of interrupts that we’ve already seen. The same interrupt-fixup-return idiom turns out to support not only unexpected timing of interactions with the outside world, but also a variety of useful illusions like virtual memory and virtual machines.