19 Inside the Cloud
In previous chapters we have discussed the sending of messages between parties that are far away from each other, but so far we have been pretty vague about how the message transport really happens. This vague approach actually has its own name: we call this nonspecific network a cloud.
In figure 19.1, boxes represent the two communicating parties. They each communicate with the cloud, and the cloud somehow gets the message across to the other party. There may be lots of communicating parties that are interconnected “somehow.” The cloud provides that interconnection without specifying exactly how things work. One party sends a message into this network cloud, and somehow the message comes out to the right recipient. This network cloud is different from cloud computing, although the two ideas are related—we’ll encounter cloud computing in the next chapter.

Two communicating endpoints and a network cloud.
This data-network cloud is not so different from a postal system or telephone system. In those more familiar systems, we likewise don’t really need to know the details of how a letter gets from sender to receiver, or how a phone call is set up. Although we don’t have to know those details, it can still be helpful to have at least some idea of the sorting stages in a postal system, or the switching stages in a telephone system. With that knowledge, we have a better understanding of the ways in which the system might break down, or otherwise not meet our expectations.
The communicating entities outside the cloud are typically computers of various kinds, possibly including phones and tablets. Although we’ve referred to them informally as communicating parties or counterparts, a better technical term is endpoints. We’ve previously talked about clients and servers—both clients and servers are endpoints. Endpoints are different from all the various cooperating devices that are operating inside the cloud, implementing the network’s delivery machinery. We’ll refer to those devices inside the cloud as network devices. Network devices usually look quite different from endpoints; they go by different names and come from different manufacturers. In spite of those surface differences, it’s worth keeping in mind that under the covers they are all step-taking machines running various kinds of programs. Like other kinds of step-taking machines, they can fail in different ways. Fortunately, the network includes mechanisms so that messages can be delivered in spite of those failures. We’ll examine those mechanisms further in this chapter.
Figure 19.2 depicts the same situation as the previous picture, but it replaces the cloud with a collection of network devices. This view is closer to what really exists as the communication mechanism between the parties.

Two communicating endpoints and various network devices.
Wires and Jacks
We can think about communication as a fairly abstract process of transferring a message from one endpoint to another, but we can also think about the network at a physical level. At that physical level, we can think of the network as providing a wire to each endpoint. In the modern world, lots of computers are actually using wireless connections or shared wires of various kinds. However, we’ll ignore those complexities. For our purposes, those are just like different kinds of wire, and the overall flow of communication works much the same way regardless of those details.
So we can think of an endpoint as having a single wire on which it can send and receive messages. Then we can think of a network device as having multiple wires on which it can send and receive messages. A network device has to be prepared to receive a message on more than one wire, whereas an endpoint only ever receives a message on its one wire. A network device may also have to decide which one of its multiple wires to use when sending a message, whereas an endpoint only ever sends a message on its one wire. The problem of sending a message from endpoint A to endpoint B is to somehow get it from A’s wire to B’s wire. Unless A is wired directly to B, getting the message from A to B will involve some number of intermediate devices passing the message along and making the right choices among their multiple wires.
Router
Let’s look at a typical simple router, the sort of device that might be used in a home or small office. It most likely has an internet connection, some wired connections, and the capacity to operate as a wireless access point. With the right configuration of information in the router and the right arrangement of connecting wires, such a router allows endpoints to exchange messages both locally and remotely (across the internet).
For simplicity, we’re going to ignore both the internet connection and the wireless network. Instead we’ll focus only on the wired connections, because they’re easier to understand. (Despite that simplification, we’ll work our way back to the internet by the end of the chapter.)
We’ll draw a router as a simple box with 4 ports or jacks along the bottom edge (figure 19.3) A single router like this allows communication among endpoints connected to the jacks. It works like a little cloud for those connected endpoints. (A networking professional might get fussy and say this is a switch, not a router. For our purposes that distinction isn’t important, but it’s worth being aware that people will sometimes be picky about whether something is dealing with mostly local destinations or mostly remote destinations. They will then tend to call a mostly local device a switch, and a mostly remote device a router.)

BlueBox and RedBox are connected to the simple router.
Consider the case of two devices that we’ll call BlueBox and RedBox, attached to the router by wires. In figure 19.3, the wires are shown as simple connecting lines. Physically, the wires we would use in this situation look a little like telephone wires. We’ll treat them as though they were phone lines. Like telephone wires, these wires plug into jacks on the router. However, if you find yourself hooking these devices up, it’s worth knowing that these aren’t phone lines. Instead, they’re like super phone lines. They have a couple of additional wires inside the insulation, and slightly wider jacks and plugs accordingly. They’re also built more carefully so they don’t distort the high-speed digital signals used on networks. With appropriate adapters, you can use networking cable to carry phone signals; but you can’t generally use ordinary phone lines to wire up data networks.
On our example router, each of the jacks is numbered. We can distinguish among the multiple otherwise-similar jacks by referring to jack 1, jack 2, and so on. Now assume that we have attached the endpoint we’re calling BlueBox to network jack 1 of the router. We’ve also attached the endpoint we’re calling RedBox to network jack 2 of the router. We’d like to have a way for BlueBox to send messages to RedBox and vice versa.
The router itself has some kind of ability to receive messages on jack 1 and send them to jack 2, and vice versa. But even if RedBox knows something about BlueBox, it doesn’t necessarily know which jack it’s using. In fact, BlueBox might get unplugged from jack 1 and plugged into jack 4, so we don’t want the communication to be in terms of the local jack numbers.
Ethernet
This interbox communication problem is not so different from what is familiar in the telephone system. In our everyday conversations, we might think of a telephone number as tied to a particular address (for a landline) or tied to a particular device (for a mobile phone). However, we also know that telephone numbers are portable—within some limits, they can be transferred across telephone companies or geographies, or moved from an “old” device to a “new” device.
Calling the exact same phone number can ring a phone at one house one day, and then ring a phone at a completely different house the next day. So we know that the telephone number is not attached permanently to the wires at the first house. Instead, there must be some kind of a table with entries about phone numbers and their corresponding wires. When a phone number is moved from one house to another, or from one mobile device to another, it’s really the entries in that table that are changed.
The local communication problem between RedBox and BlueBox uses a similar kind of table lookup. When you plug two different endpoints like BlueBox and RedBox into the two different jacks, each endpoint provides the router with its own unique identifying number—a little like a telephone number—and the router builds a little table matching those numbers with the jacks. (A networking professional might quibble here that there are other ways for the routing to happen that don’t involve the router building a table—but this explanation is good enough for our purposes.) The identifying numbers are most often related to a particular local-network technology called Ethernet.
In Ethernet, the counterpart of a phone number is called an Ethernet address. However, Ethernet addresses are “baked into” the devices that use them, which is pretty different from phone numbers. Every device using Ethernet communication has its own unique Ethernet address. Every manufacturer of devices using Ethernet communication gets a batch of unique numbers and uses each one only once. If RedBox and BlueBox know each other’s Ethernet addresses, and communicate in terms of those addresses, then it doesn’t matter which jack each one is using. The router can sort it all out.
Interconnecting Networks
The router is using this Ethernet addressing scheme locally, and we’ve said that all Ethernet addresses are distinct—every different Ethernet device has its own unique address. An obvious question here is, Why can’t we just use those Ethernet addresses to get messages around between any two devices in the world? The answer is that we might be able to do that if every device in the world used Ethernet; but there are many other ways of performing local addressing and communication. In fact, for both short distances and long distances, there are lots of different choices of communication technologies. It might seem simpler to just pick one single technology and insist on using it everywhere, but that would be a little like saying there should only be one kind of motor vehicle. Instead of having only a single type of motor vehicle, we know that there are cars, trucks, and motorcycles, with further divisions within each category. With motor vehicles we recognize that the different kinds of vehicles, and different models within each category, reflect real differences in capabilities and value. And so it is with networking technologies.
Let’s consider some other networking scheme that’s not Ethernet—call it “Othernet.” It has its own wires and ports and addresses that are different from Ethernet. Let’s also assume we have two other endpoints GreenBox and YellowBox that can plug into Othernet but not Ethernet. In much the same way that RedBox and BlueBox were plugged into an Ethernet router, GreenBox and YellowBox plug into some similar little router and communicate with each other via Othernet.
But now consider what it means for RedBox to communicate with GreenBox, or BlueBox to communicate with YellowBox. RedBox “speaks” Ethernet, but GreenBox doesn’t. Likewise YellowBox “speaks” Othernet, but BlueBox doesn’t. Even if we could move the endpoints between routers, or plug them into both routers at once, that seems complex and expensive. And if the RedBox/BlueBox/router group is in Massachusetts on one side of the country while the GreenBox/YellowBox/router group is in California on the other side of the country, those kinds of manual swapping or double-connecting approaches can’t work at all.
We might imagine that we can have the two routers talk to each other, but what do they speak in terms of? The Ethernet router doesn’t understand Othernet, and vice versa. The solution is to interconnect the networks—to build an internet (figure 19.4).

Connecting the routers to form a simple internet.
Internet Protocol (IP)
Almost everyone has heard of the internet, even if they might be a little fuzzy about what it really is or why it matters. For many people, it’s the most familiar and most important example of a computer data network. When we consider communicating between our Ethernet router and our Othernet router, we can see where the name “internet” comes from. In much the same way that “international” means crossing national boundaries, “internetwork” means crossing network boundaries. The internet protocol or IP serves as a common language—a lingua franca, if you prefer—of networking across technologies and across distance. IP ensures that endpoints can communicate identically regardless of whether they are near or far, and regardless of the local-networking technology in use by each endpoint.
One important feature of IP is that each endpoint is numbered. The number of an endpoint serves to distinguish and identify the specific endpoint. That number is called an internet address or IP address. In some ways, this scheme is just like what we saw with Ethernet: Ethernet communication happens in terms of Ethernet addresses, and likewise IP communication happens in terms of IP addresses. But unlike what we saw in Ethernet, the IP address isn’t permanently baked into the device. Indeed, in IP it’s possible to reuse the exact same number for a completely different device. That might seem kind of weird when compared to the way that Ethernet works, but it’s not so strange when we realize that it’s like the way that phone numbers work. Sometimes this flexibility of IP addresses can be useful for sophisticated purposes, where one device intentionally takes on the role of another one—we’ll see a little of that later in this chapter. But sometimes, reusability of IP addresses just means that there are occasional glitches in network operations, in which two different devices are simultaneously trying to use the same IP address.
At one level an IP address is just an integer, and that’s where we’ll focus for the moment. So let’s assume that we assign the number 3782 to BlueBox and 2901 to RedBox. There’s a special way to write IP addresses, which we’ll learn shortly—in practice, it would be strange to write an IP address in this way, as “just” a number. But for the moment, it’s enough to say that BlueBox and RedBox each have their own special IP address number.
Internet Routing
As with our previous Ethernet example, we now have two endpoints communicating in terms of identifying numbers, although now those numbers are IP addresses instead of Ethernet addresses. The problem of working out the right path of wires from the relevant IP addresses is called internet routing or IP routing. In this particular case, communication between BlueBox and RedBox will be pretty easy. When we compare IP-based communication to Ethernet-based communication for the case of BlueBox and RedBox, there are differences in the details but not much difference in the big picture. The merits of IP become more apparent, and routing gets more interesting, when we start considering communication between devices that are not attached to the same network device—like when RedBox is communicating with GreenBox.
To begin, we’ll look at the internet as it was originally designed—with one distinct IP address assigned to each endpoint. (We’ll refine our understanding to be more like the modern internet in a later section.)
Routing as a Network Service
To understand how and why IP routing works as it does, it’s helpful to think of a kind of network growth story. The point here isn’t that any particular network developed in exactly this way, but more that thinking about this mythical network helps us understand the issues.
At a small scale, IP routing is not very complicated. Let’s first assume a handful of different endpoints that want to communicate. Let’s further assume that these endpoints are all quite near each other, and that changes to the group of communicating endpoints don’t happen very often. Under those circumstances, it’s possible to do routing by just keeping track of which endpoint corresponds to each address in some kind of local table—like the one that we already considered when thinking about how the phone company keeps track of phone numbers, or like how a router matches Ethernet addresses to jacks.
Computer scientists call this kind of information a routing table. This particular type of routing table is organized by IP address; for each IP address, the entry stored in the table is some kind of choice. At a minimum, that choice is just how to get one step closer to the destination from the current location. Alternatively, the entry might be the whole series of steps to get to the destination. Either way, the information in the routing table is useful for reaching the specified IP address from the current location.
In simple cases, it’s not clear why it’s worth bothering with IP addresses and IP routing at all—they’re just an extra layer of work. It seems like we might as well just identify each possible destination endpoint directly, perhaps by listing out the sequence of wires required to get there.
But now consider what happens as the number of different endpoints starts to grow. It becomes harder for each endpoint to maintain one of these routing tables for itself. Each table is larger, and thus consumes more space at each endpoint.
In the first part of figure 19.5, A and B each have a routing table that lists the two possible destinations on the network. We don’t show any detail of what information is in the routing table for each destination, since that doesn’t much matter for this discussion.

The evolution of routing tables.
In the second part of figure 19.5, there are lots more destinations on the network, and so these routing tables are getting very long. Although we aren’t showing it in the picture, each of the new destinations C, D, etc., must also have a routing table of similar size.
Eventually, it’s too much trouble for the endpoints to keep the routing tables. Instead, the endpoints hand over that bookkeeping and lookup work, leaving them to the network itself. In the last part of figure 19.5, the destinations are no longer trying to keep their own copy of a routing table. If the network is doing the lookups and routing work, each endpoint needs to know only its own IP address and the IP addresses of any other endpoints it wants to contact. The network now handles any work required to transform IP addresses to paths through the network.
We can see the attraction of such an arrangement for an endpoint, but why would the network agree to take on the work of routing? The network can take advantage of a trick that’s not available to the endpoints. The network can operate as a single logical entity with a common shared view of routing, while maintaining only relevant fragments of the total routing table in different locations. This fragmented or federated approach to the routing table can be more efficient than the maintenance of separate tables per endpoint. Indeed, the advantage of this network trick grows as the size, complexity, and volatility of the network increase.
DHCP
In a simple view of routing, every device needs to know its IP address and give it to the network. Since those IP addresses aren’t baked into each device when it’s manufactured, that means that at some point someone had to assign IP addresses consistently to all the various devices on the network. Manually assigning those addresses is a hassle and a frequent source of errors, particularly if two different devices are accidentally given the same IP address. Can we do better?
Yes, we can avoid many of these problems, at least for client endpoints. Recall that clients initiate connections to servers; client endpoints are typically the mobile devices or laptops of users, while servers are providing some kind of service(s) to those clients. There’s an important difference between clients and servers in terms of IP address usage. Clients have to know server IP addresses somehow, so the clients can start the conversation (by doing the network equivalent of saying “hi”). Typically clients find those servers via names stored in DNS, as we already examined for browsing (chapter 15).
In contrast, servers don’t need to find clients. Servers can just sit and wait for clients to ask for services, and each such request from a client already includes the client’s IP address. So whereas the server’s IP address may need to be relatively stable and relatively well known (so that clients can send requests to the server), any client’s IP address can be assigned on the fly as long as it doesn’t conflict with other clients.
Who does this assignment of IP addresses? Typically, the requester’s closest router does the assignment. (A network professional might insist here that the address assignment is actually a specialized service that’s unrelated to carrying network messages—and that’s correct. However, in most environments that service looks like a part of the router.) The device and the router have a conversation using yet another protocol, this one called Dynamic Host Configuration Protocol (DHCP). A successful DHCP conversation ends with the device and the router agreeing on the new IP address of the device, and a period of time for which that assignment is valid. After that time ends, the router takes back the IP address—the router is effectively “leasing” the IP address to the device for a limited time, not letting the device “own” it. This leasing arrangement is why you can sometimes fix a networking problem by restarting or resetting your device’s network service: your device has drifted out of synchronization with the local address assignments, but getting a “new” address brings you back into alignment with the current arrangement.
Advertising
At this point we know that each router knows the IP addresses of any attached endpoints. Each of those endpoints can give the router messages for other endpoints, identified by IP address. We can see how this message exchange works at a single router with endpoints that are directly attached, but we haven’t yet explained anything more. So at this point, using IP is no improvement over what we already had. With Ethernet, we already had the capacity for the router to send messages among locally attached endpoints. But how do we expand or modify that approach, so the router can help send messages among endpoints that are not locally attached?
The broad solution is that routers share addressing information with each other. The first step is to think in terms of routers sharing only their locally attached addresses. Earlier, we saw that an individual endpoint declares its (single) IP address to its (single) local router. We can have each router do a kind of multiple-address version of that same address-declaration operation, which we’ll call advertising. In the same way that an endpoint has some kind of physical connection to a local router, each router has some kind of connection to another router, like a telephone line. (In the early days of the internet, these connections literally were a kind of telephone line. Now they are digital data lines—but they’re still often supplied by a telephone company.)
Instead of advertising only a single IP address, the router advertises all of the IP addresses of locally attached endpoints. It sends that advertisement to all of its immediate-neighbor routers—those that are separated from it by only a single connection.
Let’s give the name OurRouter to the router with BlueBox and RedBox attached. This name is just for our convenience in explaining; nothing about the operation of the network requires the router to have a name. When it’s speaking to another router, OurRouter doesn’t bother to advertise which jack BlueBox or RedBox is attached to—that’s not useful information for other routers. What it does advertise is that it knows how to get traffic to the IP addresses 3782 and 2901. Any other router that needs to send traffic to either of those addresses knows to send it to OurRouter.
Longer Routes
This advertising scheme greatly increases the flexibility of the network, but it doesn’t quite give us the right solution yet. Our first IP routing mechanism only let us communicate with other endpoints on the exact same router—what we might call “one router away.” With this second mechanism, routers are advertising their directly connected endpoints. That arrangement means that endpoints can communicate with other endpoints that are attached to a different router—as long as that router is directly attached to our router. So we now know how to communicate with a party that is “two routers away.” But as soon as there are three or more routers between endpoints, our local router won’t know how to reach that endpoint.
Fortunately, it doesn’t take much more to get the right solution. For both senders and receivers, it doesn’t matter (much) if an advertised IP address is directly attached to the router that’s advertising it.
We know in our example that OurRouter has both RedBox and BlueBox directly attached. But now assume that we move BlueBox (with IP address 3782) to a different router (let’s call it YourRouter). That doesn’t necessarily mean that OurRouter has to stop advertising that it knows how to get traffic to IP address 3782. As long as OurRouter still knows what to do with that kind of traffic, it can still be advertising that it knows how to get traffic to 3782.
Of course, OurRouter has to change its behavior when it receives traffic for 3782. When BlueBox was directly attached to OurRouter, then OurRouter sent 3782’s traffic to jack 1. When BlueBox moves to YourRouter, then OurRouter sends 3782’s traffic to YourRouter. But OurRouter’s advertisement doesn’t need to change.
And note that BlueBox might move again to YetAnotherRouter. OurRouter might find out about that change, in which case it would update its routing table so that 3782 traffic is sent to YetAnotherRouter. Alternatively, OurRouter might be left knowing only that YourRouter knows how to reach 3782; so it would continue to send 3782’s traffic to YourRouter, which would then need to send it on to YetAnotherRouter. As you can probably already see from this small example, there are some tricky issues like avoiding loops. We will just note that as another area where computing professionals earn their pay.
Scaling Up
Although this simple scheme lets endpoints reach each other with any number of routers in between, it doesn’t work very well at large scale. As we’ve outlined it so far, every router has to provide every other router with a list of every distinct address that it knows about, even if it’s only an indirect path. That would lead to two problems: first, there are lots of addresses; and second, most of the available paths aren’t very good.
How many addresses would need to be considered? To answer that question, we first note that there are two different kinds of IP addresses. The “old” style is called IPv4 (that’s version 4 of the IP protocol) and the “new” style is called IPv6 (for version 6 of the IP protocol … and no, there is no IPv5).
There is general agreement that there aren’t enough of the older IPv4 addresses, which is a large part of the reason why a transition to IPv6 has been slowly taking place. Even so, there are roughly 4 billion different IPv4 addresses. The scheme we’ve sketched so far would potentially mean that every network device is potentially sending updates about any of those billions of addresses. That might be possible, but it doesn’t seem like a very smart approach. And then when we look at the newer IPv6 addresses, we find the scale is mind-numbing. Not only can you assign billions of IPv6 addresses, but there are enough addresses so that every one of those billions of addresses could be communicating with its own distinct collection of billions of devices … and there’d still be addresses left over! That’s a great feature in some ways, because it means we aren’t likely to have a problem with running out of IPv6 addresses—but it does mean that the routers have to be smarter about managing these updates.
IP Address Notation
Although we’ve talked about an IPv4 address as though it were just an integer, it’s more typical to think of it as a sequence of four bytes. A byte is eight bits, which is enough to represent numbers from 0 to 255. So each of the four bytes of an IPv4 address can be any value from 0 to 255. The bytes of an IPv4 address are written separated by dots, so the lowest possible IPv4 address is 0.0.0.0. Similarly, the highest possible IPv4 address is 255.255.255.255. Writing it this way doesn’t change the meaning or value of the address. You can think of it as being a little like saying that the phone number 6175551212 is more easily understood when written as 617–555–1212. We haven’t changed the numbers provided to the telephone network when you dial that number, we’re just viewing and presenting it differently.
This notation lets us write a single endpoint’s IP address. What if we want to write the addresses of two different endpoints? One solution would be just to write out two separate addresses, like when we wrote 0.0.0.0 and 255.255.255.255 above. But a different trick is available if we confine ourselves to groups of addresses that are adjacent—that is, sequential numbers.
Our approach is essentially the same as what we can use for printing part of a multipage document. We can list multiple individual page numbers like “3, 7, 22” or we can talk about a page range like “7–22.” The page range has the nice property that our specification of the pages can be similar in size, whether we are talking about only a few pages or a very large number of pages. For example, the page range “1002–1003” and the page range “1002–5003” are the same length in this sentence, even though the second range refers to thousands more pages than the first.
In the same way that we can refer to a sequence of adjacent pages, we can refer to a collection of adjacent addresses. But instead of listing the starting and ending page numbers, we provide an IP address and a netmask—a notation that indicates how many of the IP address bits must have exactly the values provided. What’s a little weird about netmask notation is that it mixes two different ways of thinking about the IP address. The dotted notation like “192.163.7.1” represents the 32 bits of an IP address as four decimal numbers, one for each of the four 8-bit bytes. The netmask written with a slash like “/31” is also a decimal number, but refers to the binary representation. To understand what /31 really means, we can’t somehow apply “31” to one of those numbers in the dotted address, like “192” or “7.” Instead we have to think about the address “192.163.7.1” written out as 32 bits:
11000000.10100011.00000111.00000001
(the dots are included only for clarity)
The netmask /31 means that we hold the left 31 bits fixed, but let the remainder (only 1 bit in this case) vary. Similarly, a netmask /8 would mean that we hold the left 8 bits fixed and let the remaining 24 bits vary. Again, this may seem esoteric—but it’s basically accomplishing the same effect as specifying a page range of “7–22” in a document, just within the different world of network addresses.
The simplest examples are ones that no one would really use, but they’re worth examining just to understand the notation. If we write 255.255.255.255/32, that means the same as just writing 255.255.255.255—that is, it’s a single IP address where all four bytes have the maximum value. The /32 at the end says that all 32 bits must match exactly.
What happens if we change the netmask to be /31? That means only the top 31 bits need to match exactly. So 255.255.255.255/31 means two addresses: 255.255.255.254 and 255.255.255.255.
We’re not limited to doing this only at the top end of the possible IP addresses. For example, 192.128.7.0/31 is also a pair of addresses: one address is 192.128.7.0, and the other address is 192.128.7.1. If we use the next smaller netmask number, we double the number of addresses represented. So 192.128.7.0/30 is a quartet of addresses:
192.128.7.0
192.128.7.1
192.128.7.2
192.128.7.3
and similarly, 192.128.7.0/24 is the set of 256 addresses from 192.128.7.0 to 192.128.7.255.
Summarizing and Filtering
Instead of sharing every individual detail, routers summarize their routing information. Rather than sending information about every individual IP address, a router will group the addresses into subnets. Subnets are specified by the netmask notation we just introduced. All of the IP addresses in a subnet are “routed alike,” at least until they reach the router that has been summarizing them in its advertisements.
Summarizing means that routers can advertise a lot of contiguous addresses with only a small amount of information. That’s one part of how the network can manage a lot of routing information. In addition, a router is not obliged to advertise everything it knows; so routers don’t just summarize, they also filter their routing information. Although a router may be able to reach a particular destination, it may not want to advertise that ability if it doesn’t want to receive and handle traffic for a destination. In addition, it may not be helpful to advertise destinations for which the router is a poor choice.
Distributed Management
We now understand something about how the network does routing at large scale. A further wrinkle is that the management of routing tables is not performed centrally. We can imagine what would happen if we did manage the tables centrally: we would collect advertisements from all of the network devices, mush them all together in some kind of global routing table, and then distribute the relevant pieces. Unfortunately, we would find that the computation of new routes was getting slower and slower as the network got bigger.
Instead, the routing computation is distributed across the routers. Each router makes local decisions based on what it knows locally and what it learns from its neighbors. Those local decisions determine both how the router handles traffic that it receives, and also what information it shares with its neighbors. The distributed computation can scale up in a way that the centralized computation can’t. But the trade-off is that decisions have to be made with less information. Each router is making decisions based only on its local knowledge, not a full global view.
Network Address Translation (NAT)
We initially made a simplifying assumption that every endpoint has a unique IP address, but we also noted that there are only about 4 billion IPv4 addresses. However, there have been more than 4 billion internet-connected devices for a long time—indeed, estimates for the count of internet-connected devices were already in the neighborhood of 10 billion in 2014. Obviously we can’t give each of those 10 billion devices a different address if there are only 4 billion total addresses. So how does IP communication work if we have to somehow share and reuse IP addresses?
The solution is a technology called network address translation or NAT (pronounced like “gnat” or the first syllable of the word “natty”). NAT is a little like forwarding postal mail: we can cross out the original address and write in a new one instead. However, we can see that there must be something more than just crossing out one 32-bit address and writing in a new 32-bit address: that won’t solve the problem that a 32-bit address only lets you reach 4 billion different destinations.
Crucially, there’s a kind of subaddressing at each endpoint. A connection goes between two IP addresses, but that’s not the whole story of addressing. In addition to the IP address, there is a port number at each end of the connection. A port is an integer that just serves to distinguish among connections at each end. We mentioned ports previously when we were explaining the mechanics of browsing (chapter 15), but now we’re looking at the more general usage of ports. Broadly, we use ports to ensure that when there are two or more connections between the same IP addresses (say, Alice and Bob) neither end gets confused about which messages belong to which connection.
If we just want to distinguish the connections, we could simply increment the port number on either side to make sure that it’s different from other connections. That might mean that the first connection from Alice to Bob is actually marked as “Alice:0” (Alice’s IP address, port 0) for its sender while the second connection from Alice to Bob is marked as “Alice:1” (still Alice’s IP address, but now port 1). Once we have that arrangement in place, we don’t have to worry about confusing the two connections on Bob’s side, because even though they have identical IP addresses for their source, Bob actually distinguishes connections based on the combination of IP and port.
The actual port assignment rules are a little more complicated than this example, but not by much. In general, the party starting the connection (the client) picks a number that is locally unique for its client port. However, the client also picks the port number for the other end of the connection, choosing a number that indicates what kind of service is desired. For example, port 80 usually means “I would like a web server to respond.”
Once the connection is set up, each packet has four different items of addressing information. Two of them relate to the source (sender) of the packet, while the other two relate to the destination (receiver) of the packet. This set of four items (source address, source port, destination address, destination port) is sometimes called a quad. See figure 19.6.

A quad.
The trick of NAT, then, is that there really isn’t (only) a 32-bit space of IP addresses, even if we confine ourselves to the older IPv4 scheme. Each end of a conversation is really identified by the combination of a 32-bit IP address and a 32-bit port. Whereas 32 bits only let us have 4 billion different addresses, each additional bit doubles that number (we saw the power of successive doubling with the emperor and the chessboard in chapter 7). As we mentioned earlier, a 64-bit address space is really huge. So if we’re willing to do some bookkeeping, we can use this larger address space by translating between quads at convenient boundaries.
In an IP network, messages with the same quad are treated alike. If there are multiple messages with the same quad in the network, they must be different parts of what is logically a single flow of information between the communicating parties. The game of NAT is to shift the traffic from using one quad to another without inadvertently colliding with any other quad in use.
Effective use of NAT usually requires us to distinguish between public IP addresses and private IP addresses. A public IP address must be globally unique and can’t be reused, but private IP addresses are visible only inside an organization and can be reused by many different organizations. For a private IP address to connect outside the organization, its connection goes via a public IP address. Outgoing traffic from a private address is translated (“natted”) to a public IP address and port. Correspondingly, incoming traffic to that public IP address and port is natted back to the private address and port.
Routing Failure
The last layer of interconnection is easiest to understand in terms of routing failure. Is routing failure a real issue? Yes. One famous problem in the early days of networking happened when a router partly failed. Each of the routers maintained a table of costs that it used for making routing decisions. Unfortunately, one router’s hardware failed in a very particular way: that table of costs always seemed to contain zeros. The faulty (all-zero) information in the local routing table meant that the router had faulty (all-zero) costs for reaching every other known destination.
When the router advertised that zero-cost information to its neighbors, they updated their routing tables accordingly. The broken router’s neighbors then forwarded that information to their neighbors in turn. Soon the entire network had learned that this one defective router was the best route to every network destination. The natural, if unfortunate, result was that every other router sent all of its traffic to that one router. And the further natural, if unfortunate, result was that the defective router “crashed” due to overload, so no one’s traffic reached its destination. The network would have recovered if the defective router had stayed down—if it had conformed to a simple fail-stop model. Instead, this is a vivid real-world example of a Byzantine failure. The router restarted and again tried to participate in the routing protocol with its neighbors: it again advertised that it had zero-cost routes to everywhere. A single failure in a single router meant that the entire network failed to deliver any traffic. Network service was only restored when the faulty router was identified and turned off.
Although this particular network failure was an unusual case, it does point to the next level of challenge in building networks. So far we have assumed that the routing is distributed but homogeneous. But the global internet is actually composed not only of distinct technologies for local networking, but also distinct technologies for routing. As a result, even a routing failure like the one we described will typically only affect a part of the internet, rather than the whole internet at once. Although the internet is an extremely complex system and parts of it have failed from time to time, it’s unlikely that an internet-wide failure would ever eliminate networking service for everyone. The internet is actually structured as a federation of autonomous networks, and we examine that structure next.
Interconnecting Different Routing
Looking inside a particular single network, we will find that all the routers of that network participate in the same kind of computation. Looking inside an entirely different single network, we will again find that all the routers participate in the same kind of computation. But looking across those two networks, we often find that a router in one network is behaving very differently from a router in the other network. To build an internet, we have to do more than bridge between different local-networking technologies. We also have to bridge between networks that are using different kinds of routing. As with local network technologies, we don’t expect that the different routing mechanisms can talk to each other directly. Instead, we need to have special devices that know how to “talk” to both sides (see figure 19.7).

Connecting networks with different routing mechanisms.
If we think of the two networks as being like fenced fields, a router with two different sides facing the two different networks is like a gate. A router operating in this way is sometimes called a gateway to distinguish it from an ordinary router.
Although this is a conceptually simple solution, it’s expensive and complex in practice. In fact, we encounter much the same problem here that we had a little earlier when we wanted to communicate effectively across different local-networking technology. In the case of interconnecting local-network technologies, we concluded that it was foolish to build a collection of two-way gateways, and instead we would have a single consistent bridging format. In the case of the local networking technologies like Ethernet and “Othernet,” that bridging format is IP. In a similar fashion, when we want to interconnect differently routed networks, we have them communicate via a consistent bridging layer. So just as we saw that IP is a common layer that bridges among local-network technologies, so we now want to have a common layer that bridges among routing technologies. The common layer is a sort of “inter-internet protocol,” if you like.
That common layer between differently routed IP networks is actually called the Border Gateway Protocol, or BGP. An IP network may contain a huge number of nodes and different local-network technologies, spread all over the world; but from the perspective of BGP that whole network is a single entity if it is operating under a single shared routing computation. In BGP, such a single entity is called an Autonomous System or AS. BGP defines how an AS shares routing information with another AS. At this point you will likely not be surprised to know that each AS is identified by a unique number. For example, one of MIT’s networks is AS number 3; Microsoft controls a network with AS number 3598; Apple controls a network with AS number 714; and so on. There’s no system to the number allocation, they’re just assigned in the order that organizations requested them. Figure 19.8 shows a three-AS network.
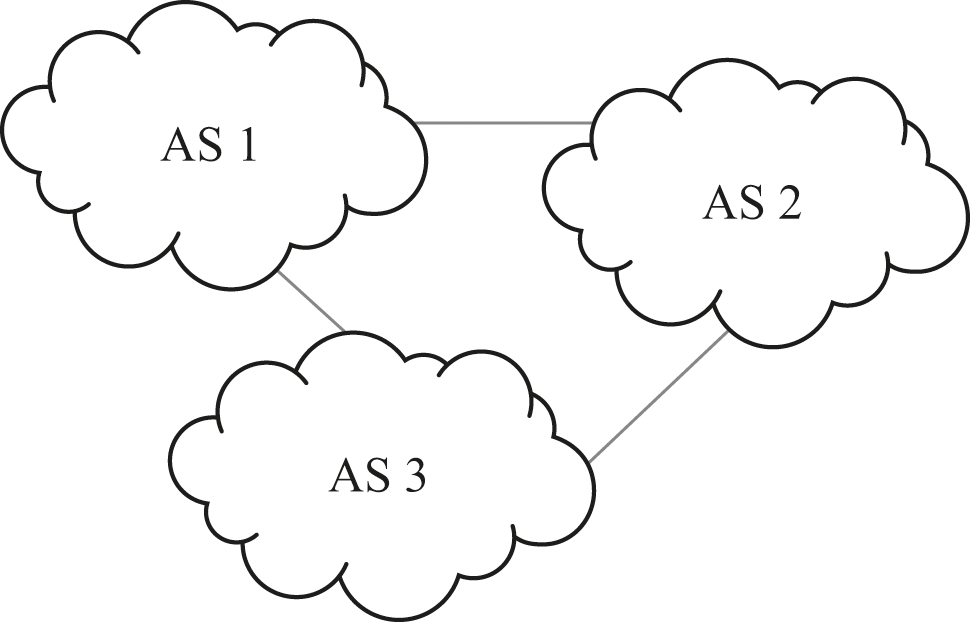
Three interconnected Autonomous Systems.
In roughly the same way that a router advertises the endpoints that it can reach, an AS advertises the endpoints that it can reach. But BGP advertisements typically contain much less detail than what a router advertises for routing, because the advertisements summarize an entire network as a single entity.
Within an AS, a router is constrained to cooperate closely with its peer routers; it is not free to pick and choose what it does, or else the routing computation becomes unreliable. In contrast, each AS is free to choose its degree of interaction with another AS. Thus the reason why the “A” of AS means “autonomous”—BGP is the level of networking at which choices can be made for pure economic or policy reasons, and no other entity’s cooperation or agreement is required.
At the BGP level, the question of what to advertise is related to commercial considerations. For understanding these kinds of issues, it’s useful to keep three general guidelines in mind:
- 1. Networks are generally happy to accept traffic to or from their paying customers.
- 2. Networks are generally OK with accepting traffic to or from other networks with similar volumes of traffic.
- 3. Networks are generally unhappy with being asked to deliver lots of traffic for some other network’s customers.
Networks typically adjust what information they advertise, and to whom they advertise that information, so as to reflect these principles.
What determines the boundary of an AS? An AS could reach around the world (in a multinational network provider, like one of the big telecommunication companies) or it might be just a few machines in a lab. A particular network belongs in an AS if it shares control and routing policy with the other networks in that AS. Correspondingly, a particular network does not belong in a particular AS if that network’s control and/or routing policy are distinct from that AS.
In much the same way that we worried about possibly running out of IP addresses, we might worry about running out of AS numbers. Fortunately, as with IP addresses, there is a useful distinction between public and private AS numbers. Public AS numbers are globally visible and carefully allocated, while private AS numbers are reusable in many different private networks because they can’t be seen on the wider (public) internet.
The simple-seeming network cloud thus turns out to have at least three different layers of standardized formats and protocols. Over short distances, a local-networking technology like Ethernet allows messages to be sent among devices—even if a device is unplugged from one jack and then plugged into another one. Over long distances and across different local-networking technology, IP allows messages to be sent regardless of the physical distances and local-network details. And finally, BGP allows multiple autonomous IP networks to cooperate (or ignore each other) despite differences in their routing algorithms, commercial goals, or policies.